 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning from Mixed Datasets: A Monotonic Image Quality Assessment Model
Sep 21, 2022

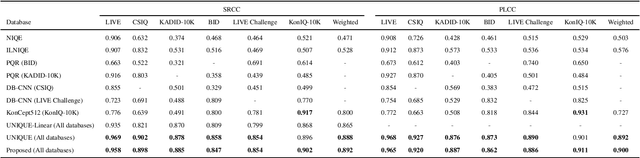
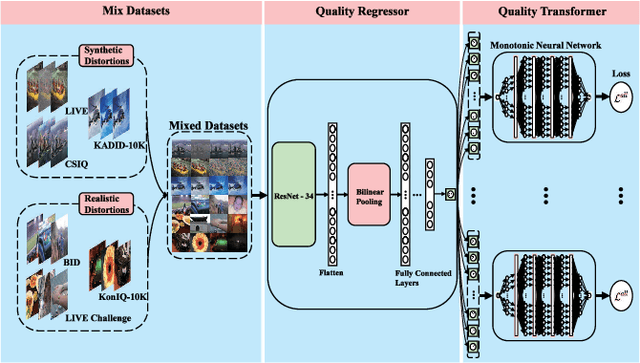

Deep learning based image quality assessment (IQA) models usually learn to predict image quality from a single dataset, leading the model to overfit specific scenes. To account for this, mixed datasets training can be an effective way to enhance the generalization capability of the model. However, it is nontrivial to combine different IQA datasets, as their quality evaluation criteria, score ranges, view conditions, as well as subjects are usually not shared during the image quality annotation. In this paper, instead of aligning the annotations, we propose a monotonic neural network for IQA model learning with different datasets combined. In particular, our model consists of a dataset-shared quality regressor and several dataset-specific quality transformers. The quality regressor aims to obtain the perceptual qualities of each dataset while each quality transformer maps the perceptual qualities to the corresponding dataset annotations with their monotonicity maintained. The experimental results verify the effectiveness of the proposed learning strategy and our code is available at https://github.com/fzp0424/MonotonicIQA.
Medical Image Understanding with Pretrained Vision Language Models: A Comprehensive Study
Sep 30, 2022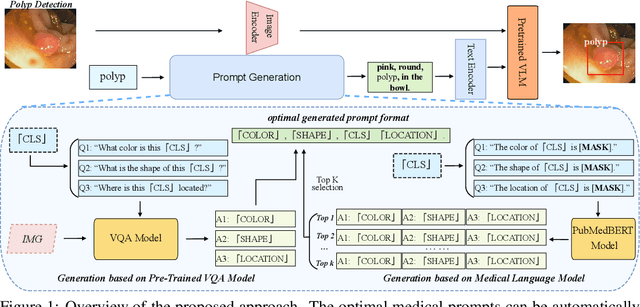
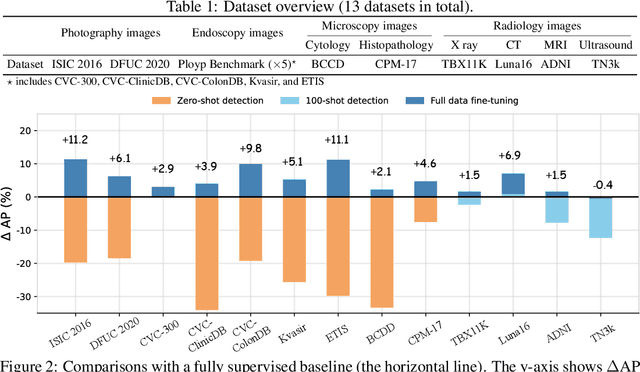
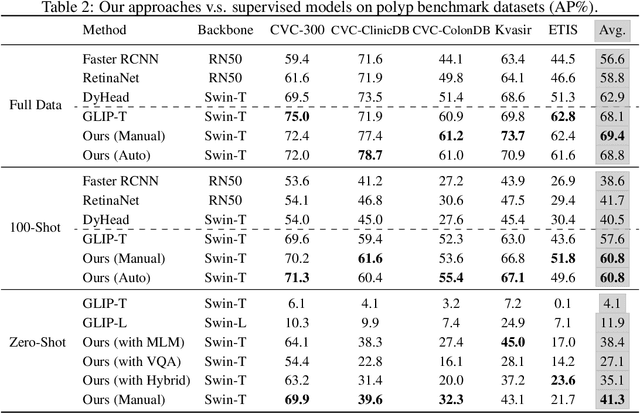
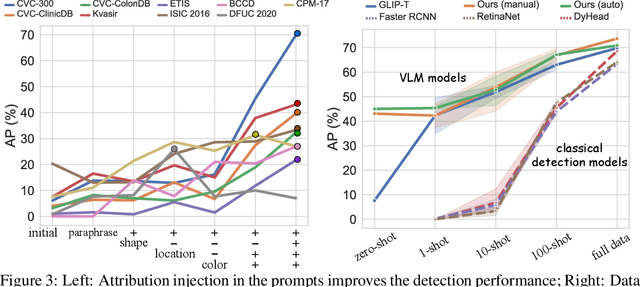
The large-scale pre-trained vision language models (VLM) have shown remarkable domain transfer capability on natural images. However, it remains unknown whether this capability can also apply to the medical image domain. This paper thoroughly studies the knowledge transferability of pre-trained VLMs to the medical domain, where we show that well-designed medical prompts are the key to elicit knowledge from pre-trained VLMs. We demonstrate that by prompting with expressive attributes that are shared between domains, the VLM can carry the knowledge across domains and improve its generalization. This mechanism empowers VLMs to recognize novel objects with fewer or without image samples. Furthermore, to avoid the laborious manual designing process, we develop three approaches for automatic generation of medical prompts, which can inject expert-level medical knowledge and image-specific information into the prompts for fine-grained grounding. We conduct extensive experiments on thirteen different medical datasets across various modalities, showing that our well-designed prompts greatly improve the zero-shot performance compared to the default prompts, and our fine-tuned models surpass the supervised models by a significant margin.
Deep Age-Invariant Fingerprint Segmentation System
Mar 06, 2023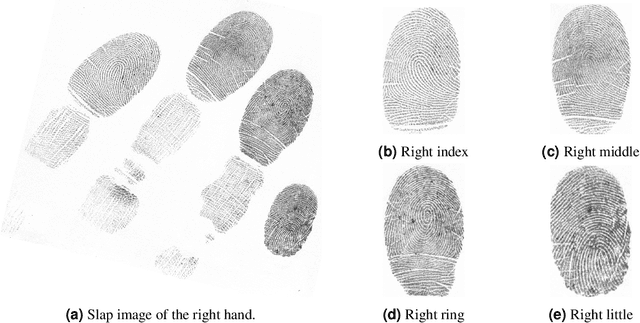

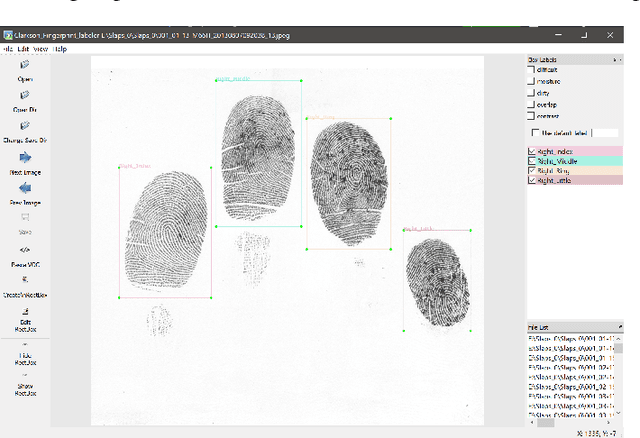

Fingerprint-based identification systems achieve higher accuracy when a slap containing multiple fingerprints of a subject is used instead of a single fingerprint. However, segmenting or auto-localizing all fingerprints in a slap image is a challenging task due to the different orientations of fingerprints, noisy backgrounds, and the smaller size of fingertip components. The presence of slap images in a real-world dataset where one or more fingerprints are rotated makes it challenging for a biometric recognition system to localize and label the fingerprints automatically. Improper fingerprint localization and finger labeling errors lead to poor matching performance. In this paper, we introduce a method to generate arbitrary angled bounding boxes using a deep learning-based algorithm that precisely localizes and labels fingerprints from both axis-aligned and over-rotated slap images. We built a fingerprint segmentation model named CRFSEG (Clarkson Rotated Fingerprint segmentation Model) by updating the previously proposed CFSEG model which was based on traditional Faster R-CNN architecture [21]. CRFSEG improves upon the Faster R-CNN algorithm with arbitrarily angled bounding boxes that allow the CRFSEG to perform better in challenging slap images. After training the CRFSEG algorithm on a new dataset containing slap images collected from both adult and children subjects, our results suggest that the CRFSEG model was invariant across different age groups and can handle over-rotated slap images successfully. In the Combined dataset containing both normal and rotated images of adult and children subjects, we achieved a matching accuracy of 97.17%, which outperformed state-of-the-art VeriFinger (94.25%) and NFSEG segmentation systems (80.58%).
A Unified Algebraic Perspective on Lipschitz Neural Networks
Mar 06, 2023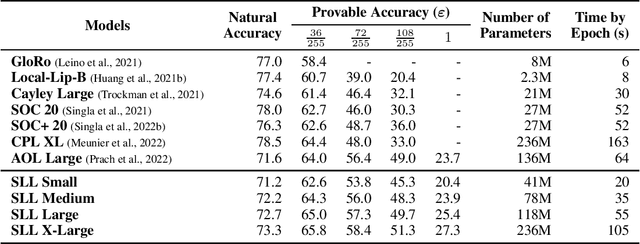
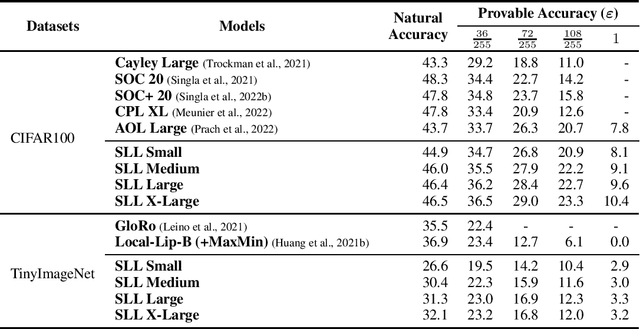
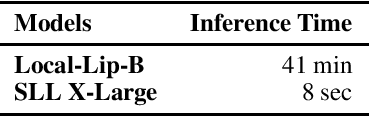
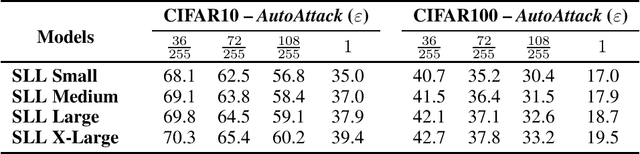
Important research efforts have focused on the design and training of neural networks with a controlled Lipschitz constant. The goal is to increase and sometimes guarantee the robustness against adversarial attacks. Recent promising techniques draw inspirations from different backgrounds to design 1-Lipschitz neural networks, just to name a few: convex potential layers derive from the discretization of continuous dynamical systems, Almost-Orthogonal-Layer proposes a tailored method for matrix rescaling. However, it is today important to consider the recent and promising contributions in the field under a common theoretical lens to better design new and improved layers. This paper introduces a novel algebraic perspective unifying various types of 1-Lipschitz neural networks, including the ones previously mentioned, along with methods based on orthogonality and spectral methods. Interestingly, we show that many existing techniques can be derived and generalized via finding analytical solutions of a common semidefinite programming (SDP) condition. We also prove that AOL biases the scaled weight to the ones which are close to the set of orthogonal matrices in a certain mathematical manner. Moreover, our algebraic condition, combined with the Gershgorin circle theorem, readily leads to new and diverse parameterizations for 1-Lipschitz network layers. Our approach, called SDP-based Lipschitz Layers (SLL), allows us to design non-trivial yet efficient generalization of convex potential layers. Finally, the comprehensive set of experiments on image classification shows that SLLs outperform previous approaches on certified robust accuracy. Code is available at https://github.com/araujoalexandre/Lipschitz-SLL-Networks.
A Large-scale Film Style Dataset for Learning Multi-frequency Driven Film Enhancement
Jan 21, 2023
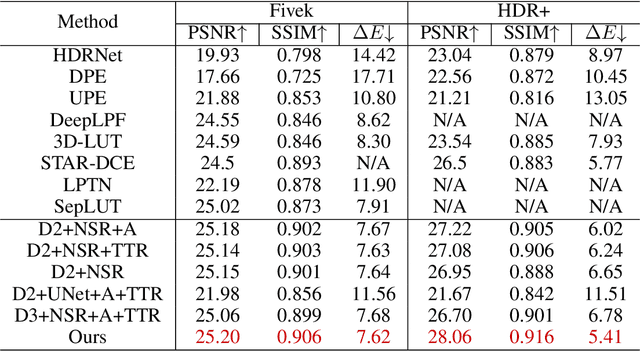

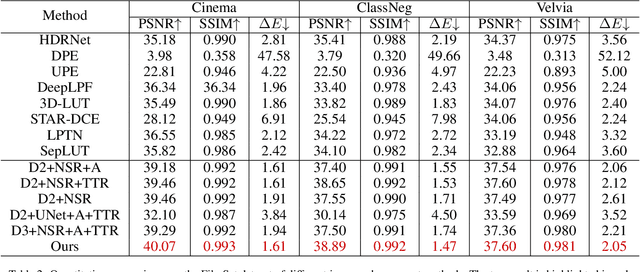
Film, a classic image style, is culturally significant to the whole photographic industry since it marks the birth of photography. However, film photography is time-consuming and expensive, necessitating a more efficient method for collecting film-style photographs. Numerous datasets that have emerged in the field of image enhancement so far are not film-specific. In order to facilitate film-based image stylization research, we construct FilmSet, a large-scale and high-quality film style dataset. Our dataset includes three different film types and more than 5000 in-the-wild high resolution images. Inspired by the features of FilmSet images, we propose a novel framework called FilmNet based on Laplacian Pyramid for stylizing images across frequency bands and achieving film style outcomes. Experiments reveal that the performance of our model is superior than state-of-the-art techniques. Our dataset and code will be made publicly available.
On the Feasibility of Machine Learning Augmented Magnetic Resonance for Point-of-Care Identification of Disease
Jan 27, 2023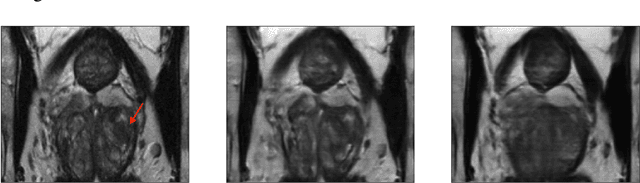

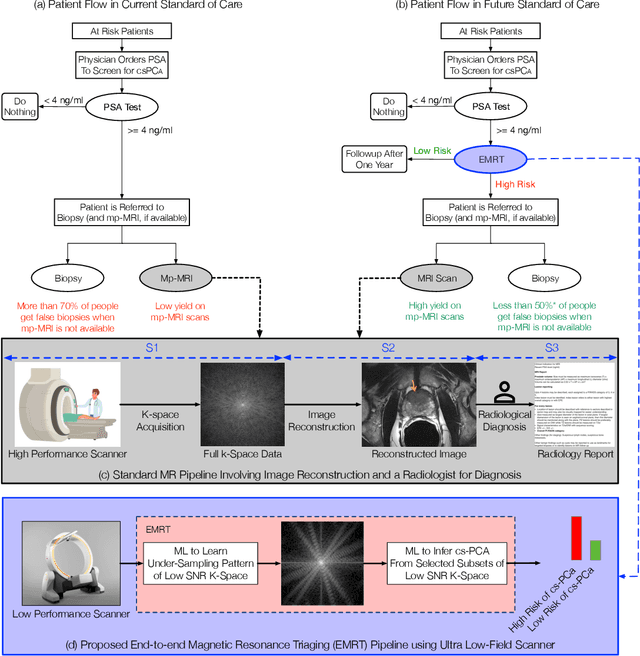

Early detection of many life-threatening diseases (e.g., prostate and breast cancer) within at-risk population can improve clinical outcomes and reduce cost of care. While numerous disease-specific "screening" tests that are closer to Point-of-Care (POC) are in use for this task, their low specificity results in unnecessary biopsies, leading to avoidable patient trauma and wasteful healthcare spending. On the other hand, despite the high accuracy of Magnetic Resonance (MR) imaging in disease diagnosis, it is not used as a POC disease identification tool because of poor accessibility. The root cause of poor accessibility of MR stems from the requirement to reconstruct high-fidelity images, as it necessitates a lengthy and complex process of acquiring large quantities of high-quality k-space measurements. In this study we explore the feasibility of an ML-augmented MR pipeline that directly infers the disease sidestepping the image reconstruction process. We hypothesise that the disease classification task can be solved using a very small tailored subset of k-space data, compared to image reconstruction. Towards that end, we propose a method that performs two tasks: 1) identifies a subset of the k-space that maximizes disease identification accuracy, and 2) infers the disease directly using the identified k-space subset, bypassing the image reconstruction step. We validate our hypothesis by measuring the performance of the proposed system across multiple diseases and anatomies. We show that comparable performance to image-based classifiers, trained on images reconstructed with full k-space data, can be achieved using small quantities of data: 8% of the data for detecting multiple abnormalities in prostate and brain scans, and 5% of the data for knee abnormalities. To better understand the proposed approach and instigate future research, we provide an extensive analysis and release code.
Image Quality Assessment with Gradient Siamese Network
Aug 08, 2022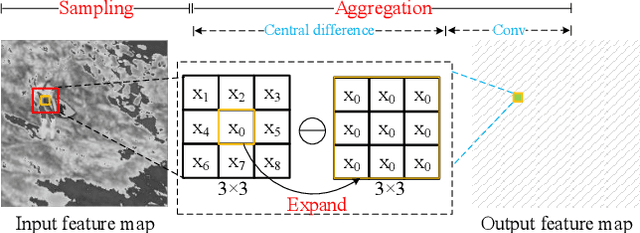
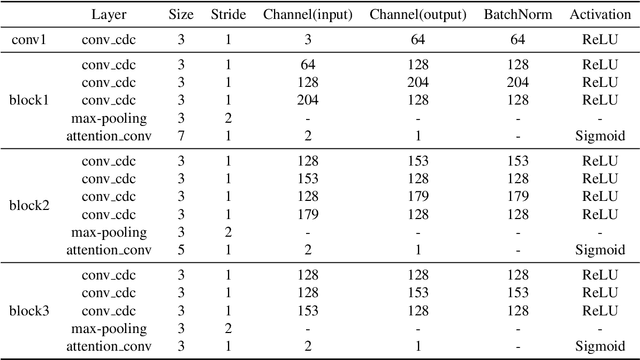
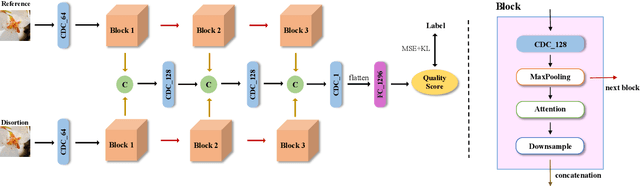
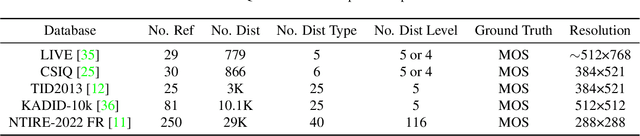
In this work, we introduce Gradient Siamese Network (GSN) for image quality assessment. The proposed method is skilled in capturing the gradient features between distorted images and reference images in full-reference image quality assessment(IQA) task. We utilize Central Differential Convolution to obtain both semantic features and detail difference hidden in image pair. Furthermore, spatial attention guides the network to concentrate on regions related to image detail. For the low-level, mid-level and high-level features extracted by the network, we innovatively design a multi-level fusion method to improve the efficiency of feature utilization. In addition to the common mean square error supervision, we further consider the relative distance among batch samples and successfully apply KL divergence loss to the image quality assessment task. We experimented the proposed algorithm GSN on several publicly available datasets and proved its superior performance. Our network won the second place in NTIRE 2022 Perceptual Image Quality Assessment Challenge track 1 Full-Reference.
* 10 pages, 5 figures, Computer Vision and Pattern Recognition (CVPR) Workshops
Extensions to Generalized Annotated Logic and an Equivalent Neural Architecture
Feb 23, 2023
While deep neural networks have led to major advances in image recognition, language translation, data mining, and game playing, there are well-known limits to the paradigm such as lack of explainability, difficulty of incorporating prior knowledge, and modularity. Neuro symbolic hybrid systems have recently emerged as a straightforward way to extend deep neural networks by incorporating ideas from symbolic reasoning such as computational logic. In this paper, we propose a list desirable criteria for neuro symbolic systems and examine how some of the existing approaches address these criteria. We then propose an extension to generalized annotated logic that allows for the creation of an equivalent neural architecture comprising an alternate neuro symbolic hybrid. However, unlike previous approaches that rely on continuous optimization for the training process, our framework is designed as a binarized neural network that uses discrete optimization. We provide proofs of correctness and discuss several of the challenges that must be overcome to realize this framework in an implemented system.
EVA3D: Compositional 3D Human Generation from 2D Image Collections
Oct 10, 2022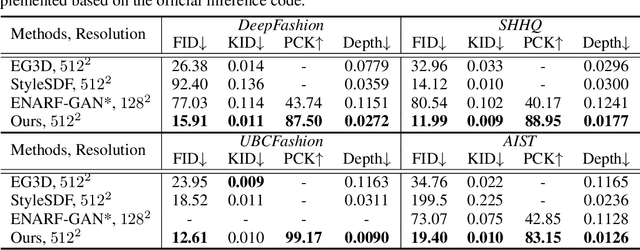
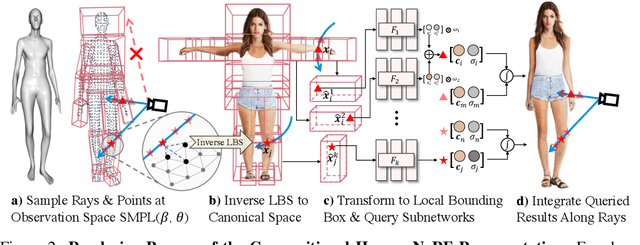
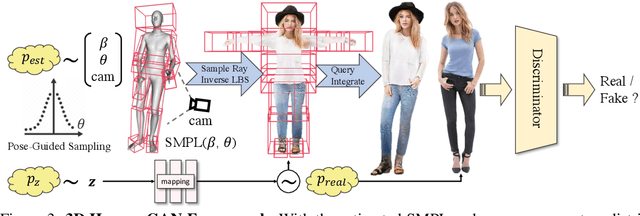

Inverse graphics aims to recover 3D models from 2D observations. Utilizing differentiable rendering, recent 3D-aware generative models have shown impressive results of rigid object generation using 2D images. However, it remains challenging to generate articulated objects, like human bodies, due to their complexity and diversity in poses and appearances. In this work, we propose, EVA3D, an unconditional 3D human generative model learned from 2D image collections only. EVA3D can sample 3D humans with detailed geometry and render high-quality images (up to 512x256) without bells and whistles (e.g. super resolution). At the core of EVA3D is a compositional human NeRF representation, which divides the human body into local parts. Each part is represented by an individual volume. This compositional representation enables 1) inherent human priors, 2) adaptive allocation of network parameters, 3) efficient training and rendering. Moreover, to accommodate for the characteristics of sparse 2D human image collections (e.g. imbalanced pose distribution), we propose a pose-guided sampling strategy for better GAN learning. Extensive experiments validate that EVA3D achieves state-of-the-art 3D human generation performance regarding both geometry and texture quality. Notably, EVA3D demonstrates great potential and scalability to "inverse-graphics" diverse human bodies with a clean framework.
Has the Virtualization of the Face Changed Facial Perception? A Study of the Impact of Augmented Reality on Facial Perception
Mar 01, 2023
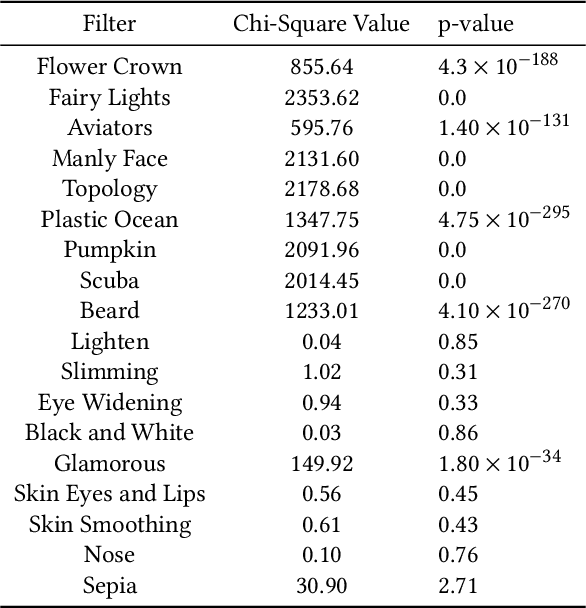

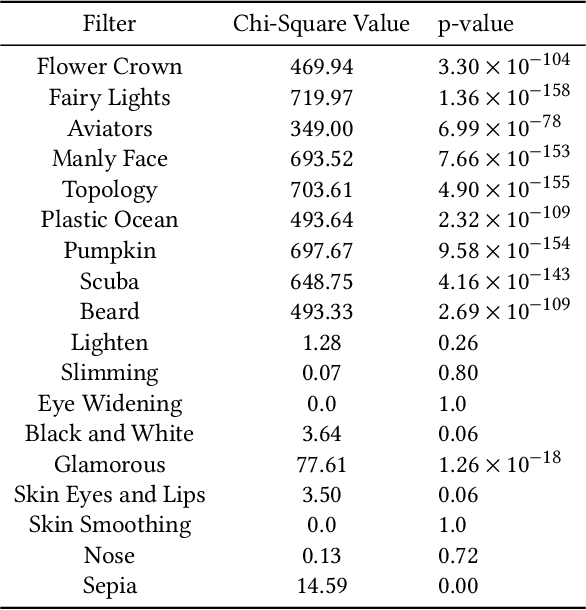
Augmented reality and other photo editing filters are popular methods used to modify images, especially images of faces, posted online. Considering the important role of human facial perception in social communication, how does exposure to an increasing number of modified faces online affect human facial perception? In this paper we present the results of six surveys designed to measure familiarity with different styles of facial filters, perceived strangeness of faces edited with different facial filters, and ability to discern whether images are filtered or not. Our results indicate that faces filtered with photo editing filters that change the image color tones, modify facial structure, or add facial beautification tend to be perceived similarly to unmodified faces; however, faces filtered with augmented reality filters (\textit{i.e.,} filters that overlay digital objects) are perceived differently from unmodified faces. We also found that responses differed based on different survey question phrasings, indicating that the shift in facial perception due to the prevalence of filtered images is noisy to detect. A better understanding of shifts in facial perception caused by facial filters will help us build online spaces more responsibly and could inform the training of more accurate and equitable facial recognition models, especially those trained with human psychophysical annotations.