 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
In-context learning enables multimodal large language models to classify cancer pathology images
Mar 12, 2024
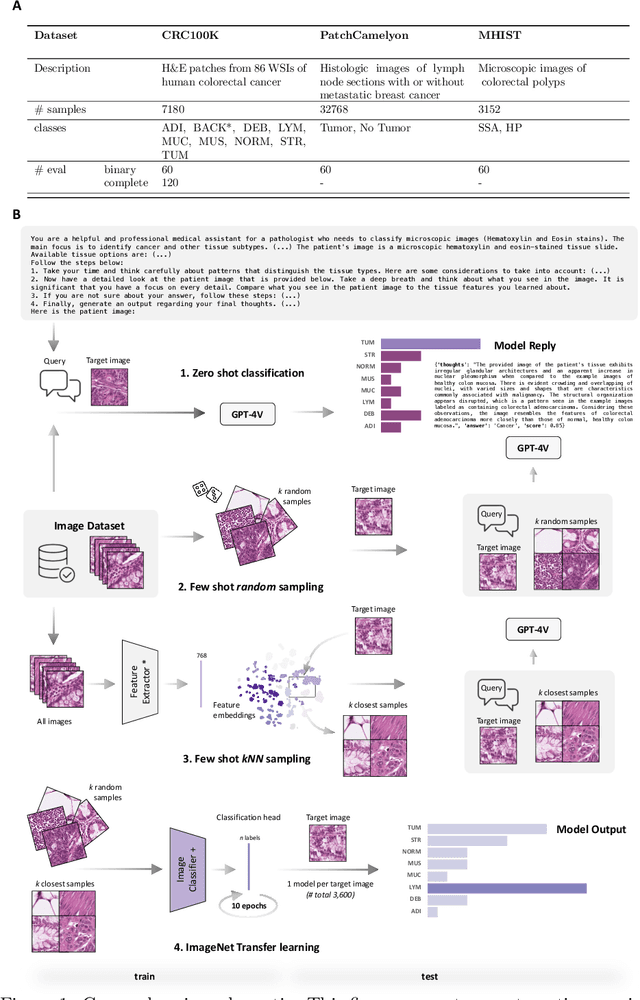
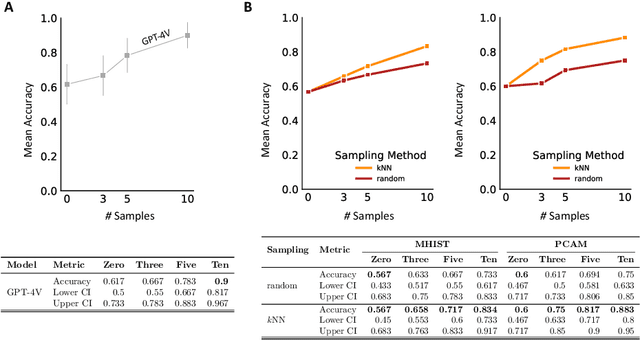
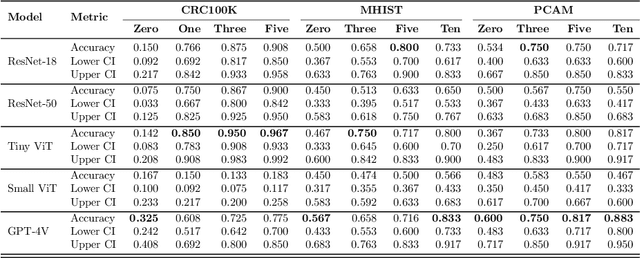
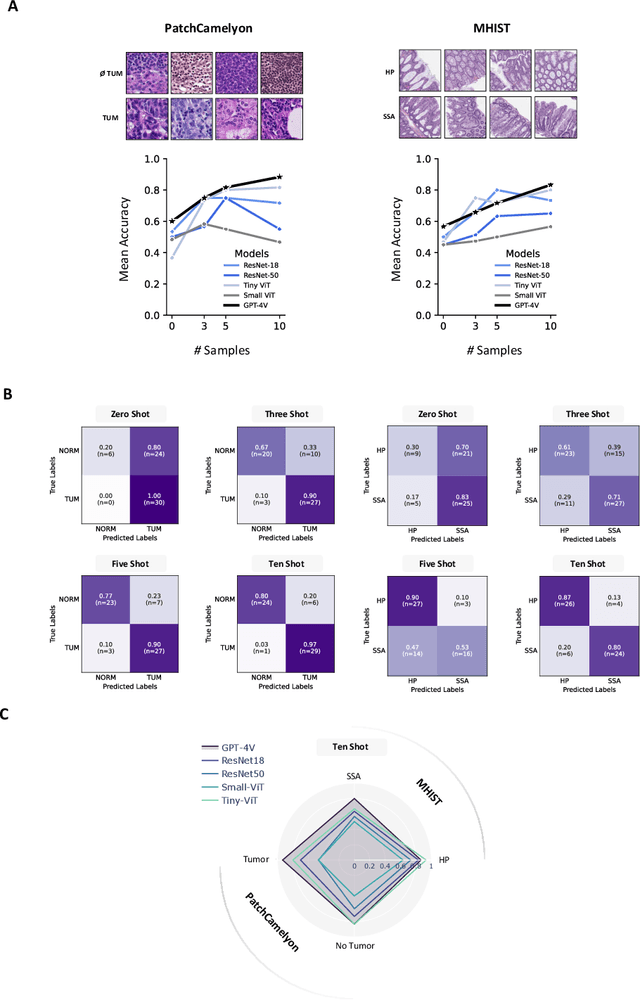
Medical image classification requires labeled, task-specific datasets which are used to train deep learning networks de novo, or to fine-tune foundation models. However, this process is computationally and technically demanding. In language processing, in-context learning provides an alternative, where models learn from within prompts, bypassing the need for parameter updates. Yet, in-context learning remains underexplored in medical image analysis. Here, we systematically evaluate the model Generative Pretrained Transformer 4 with Vision capabilities (GPT-4V) on cancer image processing with in-context learning on three cancer histopathology tasks of high importance: Classification of tissue subtypes in colorectal cancer, colon polyp subtyping and breast tumor detection in lymph node sections. Our results show that in-context learning is sufficient to match or even outperform specialized neural networks trained for particular tasks, while only requiring a minimal number of samples. In summary, this study demonstrates that large vision language models trained on non-domain specific data can be applied out-of-the box to solve medical image-processing tasks in histopathology. This democratizes access of generalist AI models to medical experts without technical background especially for areas where annotated data is scarce.
Black-box Adversarial Attacks Against Image Quality Assessment Models
Feb 28, 2024The goal of No-Reference Image Quality Assessment (NR-IQA) is to predict the perceptual quality of an image in line with its subjective evaluation. To put the NR-IQA models into practice, it is essential to study their potential loopholes for model refinement. This paper makes the first attempt to explore the black-box adversarial attacks on NR-IQA models. Specifically, we first formulate the attack problem as maximizing the deviation between the estimated quality scores of original and perturbed images, while restricting the perturbed image distortions for visual quality preservation. Under such formulation, we then design a Bi-directional loss function to mislead the estimated quality scores of adversarial examples towards an opposite direction with maximum deviation. On this basis, we finally develop an efficient and effective black-box attack method against NR-IQA models. Extensive experiments reveal that all the evaluated NR-IQA models are vulnerable to the proposed attack method. And the generated perturbations are not transferable, enabling them to serve the investigation of specialities of disparate IQA models.
Uncertainty-Calibrated Test-Time Model Adaptation without Forgetting
Mar 18, 2024
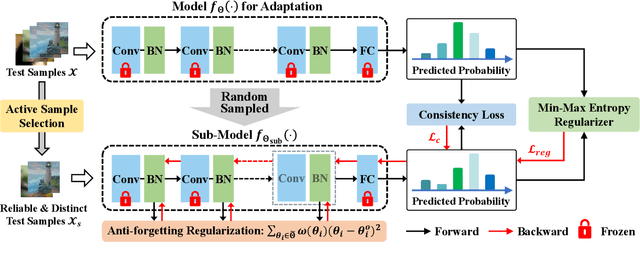
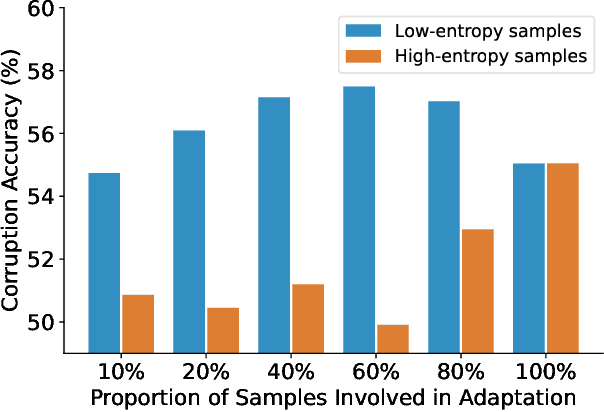
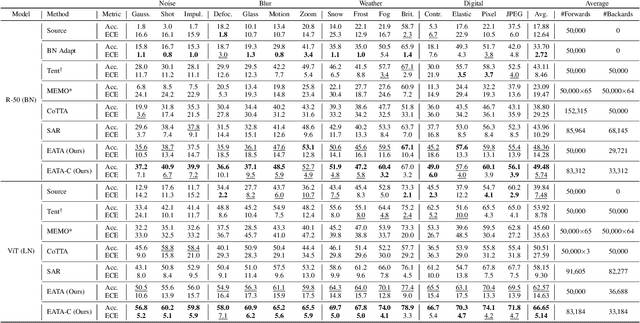
Test-time adaptation (TTA) seeks to tackle potential distribution shifts between training and test data by adapting a given model w.r.t. any test sample. Although recent TTA has shown promising performance, we still face two key challenges: 1) prior methods perform backpropagation for each test sample, resulting in unbearable optimization costs to many applications; 2) while existing TTA can significantly improve the test performance on out-of-distribution data, they often suffer from severe performance degradation on in-distribution data after TTA (known as forgetting). To this end, we have proposed an Efficient Anti-Forgetting Test-Time Adaptation (EATA) method which develops an active sample selection criterion to identify reliable and non-redundant samples for test-time entropy minimization. To alleviate forgetting, EATA introduces a Fisher regularizer estimated from test samples to constrain important model parameters from drastic changes. However, in EATA, the adopted entropy loss consistently assigns higher confidence to predictions even for samples that are underlying uncertain, leading to overconfident predictions. To tackle this, we further propose EATA with Calibration (EATA-C) to separately exploit the reducible model uncertainty and the inherent data uncertainty for calibrated TTA. Specifically, we measure the model uncertainty by the divergence between predictions from the full network and its sub-networks, on which we propose a divergence loss to encourage consistent predictions instead of overconfident ones. To further recalibrate prediction confidence, we utilize the disagreement among predicted labels as an indicator of the data uncertainty, and then devise a min-max entropy regularizer to selectively increase and decrease prediction confidence for different samples. Experiments on image classification and semantic segmentation verify the effectiveness of our methods.
Histo-Genomic Knowledge Distillation For Cancer Prognosis From Histopathology Whole Slide Images
Mar 18, 2024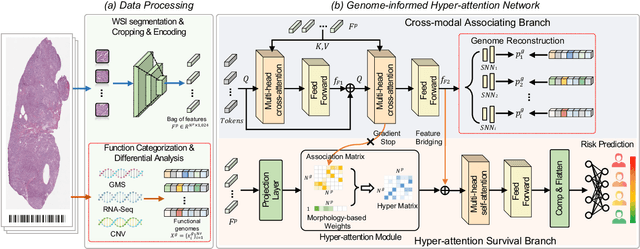
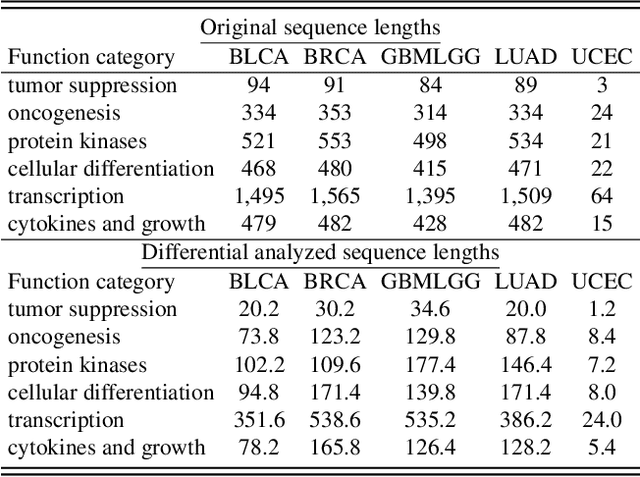
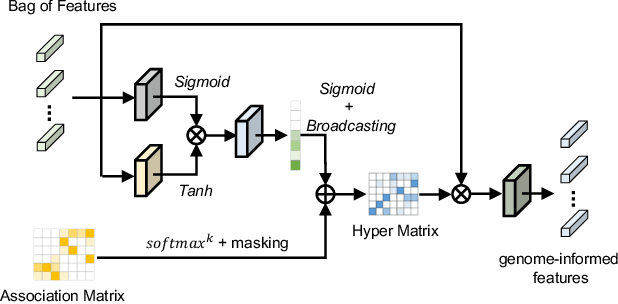
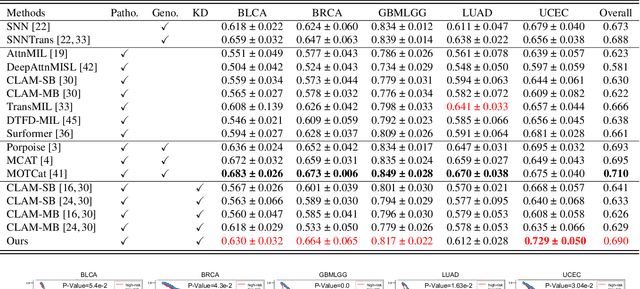
Histo-genomic multi-modal methods have recently emerged as a powerful paradigm, demonstrating significant potential for improving cancer prognosis. However, genome sequencing, unlike histopathology imaging, is still not widely accessible in underdeveloped regions, limiting the application of these multi-modal approaches in clinical settings. To address this, we propose a novel Genome-informed Hyper-Attention Network, termed G-HANet, which is capable of effectively distilling the histo-genomic knowledge during training to elevate uni-modal whole slide image (WSI)-based inference for the first time. Compared with traditional knowledge distillation methods (i.e., teacher-student architecture) in other tasks, our end-to-end model is superior in terms of training efficiency and learning cross-modal interactions. Specifically, the network comprises the cross-modal associating branch (CAB) and hyper-attention survival branch (HSB). Through the genomic data reconstruction from WSIs, CAB effectively distills the associations between functional genotypes and morphological phenotypes and offers insights into the gene expression profiles in the feature space. Subsequently, HSB leverages the distilled histo-genomic associations as well as the generated morphology-based weights to achieve the hyper-attention modeling of the patients from both histopathology and genomic perspectives to improve cancer prognosis. Extensive experiments are conducted on five TCGA benchmarking datasets and the results demonstrate that G-HANet significantly outperforms the state-of-the-art WSI-based methods and achieves competitive performance with genome-based and multi-modal methods. G-HANet is expected to be explored as a useful tool by the research community to address the current bottleneck of insufficient histo-genomic data pairing in the context of cancer prognosis and precision oncology.
VideoMV: Consistent Multi-View Generation Based on Large Video Generative Model
Mar 18, 2024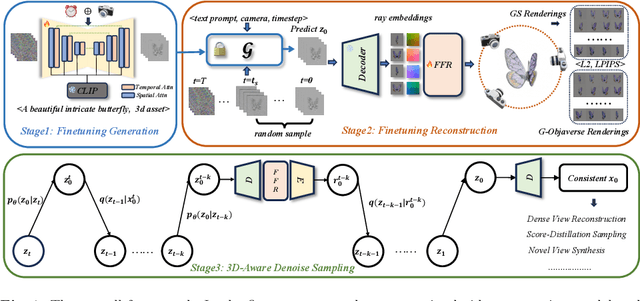
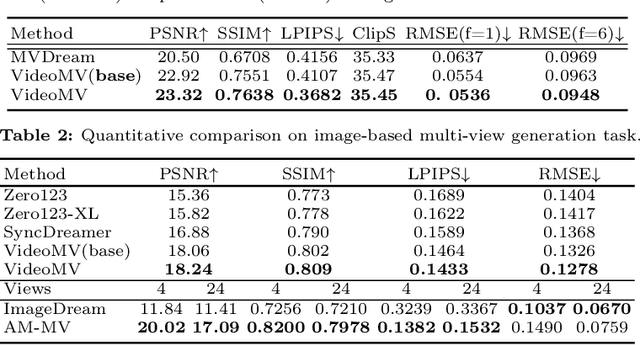


Generating multi-view images based on text or single-image prompts is a critical capability for the creation of 3D content. Two fundamental questions on this topic are what data we use for training and how to ensure multi-view consistency. This paper introduces a novel framework that makes fundamental contributions to both questions. Unlike leveraging images from 2D diffusion models for training, we propose a dense consistent multi-view generation model that is fine-tuned from off-the-shelf video generative models. Images from video generative models are more suitable for multi-view generation because the underlying network architecture that generates them employs a temporal module to enforce frame consistency. Moreover, the video data sets used to train these models are abundant and diverse, leading to a reduced train-finetuning domain gap. To enhance multi-view consistency, we introduce a 3D-Aware Denoising Sampling, which first employs a feed-forward reconstruction module to get an explicit global 3D model, and then adopts a sampling strategy that effectively involves images rendered from the global 3D model into the denoising sampling loop to improve the multi-view consistency of the final images. As a by-product, this module also provides a fast way to create 3D assets represented by 3D Gaussians within a few seconds. Our approach can generate 24 dense views and converges much faster in training than state-of-the-art approaches (4 GPU hours versus many thousand GPU hours) with comparable visual quality and consistency. By further fine-tuning, our approach outperforms existing state-of-the-art methods in both quantitative metrics and visual effects. Our project page is aigc3d.github.io/VideoMV.
Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis
Feb 28, 2024Diffusion model is a promising approach to image generation and has been employed for Pose-Guided Person Image Synthesis (PGPIS) with competitive performance. While existing methods simply align the person appearance to the target pose, they are prone to overfitting due to the lack of a high-level semantic understanding on the source person image. In this paper, we propose a novel Coarse-to-Fine Latent Diffusion (CFLD) method for PGPIS. In the absence of image-caption pairs and textual prompts, we develop a novel training paradigm purely based on images to control the generation process of the pre-trained text-to-image diffusion model. A perception-refined decoder is designed to progressively refine a set of learnable queries and extract semantic understanding of person images as a coarse-grained prompt. This allows for the decoupling of fine-grained appearance and pose information controls at different stages, and thus circumventing the potential overfitting problem. To generate more realistic texture details, a hybrid-granularity attention module is proposed to encode multi-scale fine-grained appearance features as bias terms to augment the coarse-grained prompt. Both quantitative and qualitative experimental results on the DeepFashion benchmark demonstrate the superiority of our method over the state of the arts for PGPIS. Code is available at https://github.com/YanzuoLu/CFLD.
3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation
Mar 14, 2024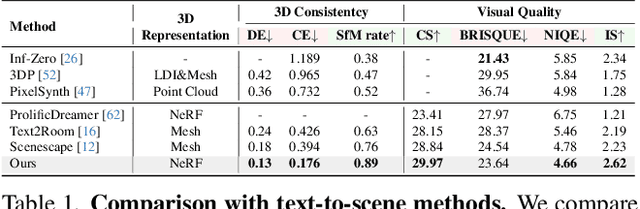
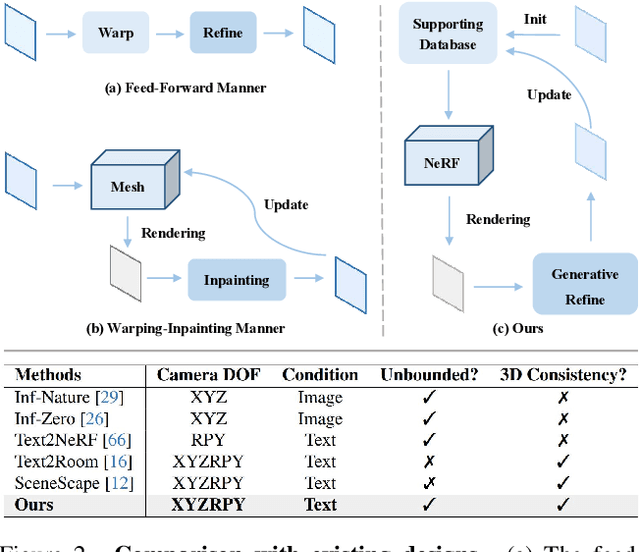
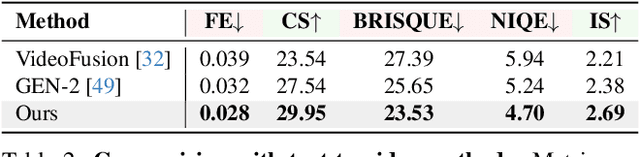
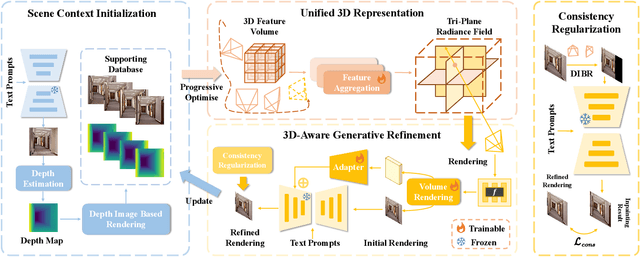
Text-driven 3D scene generation techniques have made rapid progress in recent years. Their success is mainly attributed to using existing generative models to iteratively perform image warping and inpainting to generate 3D scenes. However, these methods heavily rely on the outputs of existing models, leading to error accumulation in geometry and appearance that prevent the models from being used in various scenarios (e.g., outdoor and unreal scenarios). To address this limitation, we generatively refine the newly generated local views by querying and aggregating global 3D information, and then progressively generate the 3D scene. Specifically, we employ a tri-plane features-based NeRF as a unified representation of the 3D scene to constrain global 3D consistency, and propose a generative refinement network to synthesize new contents with higher quality by exploiting the natural image prior from 2D diffusion model as well as the global 3D information of the current scene. Our extensive experiments demonstrate that, in comparison to previous methods, our approach supports wide variety of scene generation and arbitrary camera trajectories with improved visual quality and 3D consistency.
WDM: 3D Wavelet Diffusion Models for High-Resolution Medical Image Synthesis
Feb 29, 2024Due to the three-dimensional nature of CT- or MR-scans, generative modeling of medical images is a particularly challenging task. Existing approaches mostly apply patch-wise, slice-wise, or cascaded generation techniques to fit the high-dimensional data into the limited GPU memory. However, these approaches may introduce artifacts and potentially restrict the model's applicability for certain downstream tasks. This work presents WDM, a wavelet-based medical image synthesis framework that applies a diffusion model on wavelet decomposed images. The presented approach is a simple yet effective way of scaling diffusion models to high resolutions and can be trained on a single 40 GB GPU. Experimental results on BraTS and LIDC-IDRI unconditional image generation at a resolution of $128 \times 128 \times 128$ show state-of-the-art image fidelity (FID) and sample diversity (MS-SSIM) scores compared to GANs, Diffusion Models, and Latent Diffusion Models. Our proposed method is the only one capable of generating high-quality images at a resolution of $256 \times 256 \times 256$.
Asymmetric Feature Fusion for Image Retrieval
Mar 01, 2024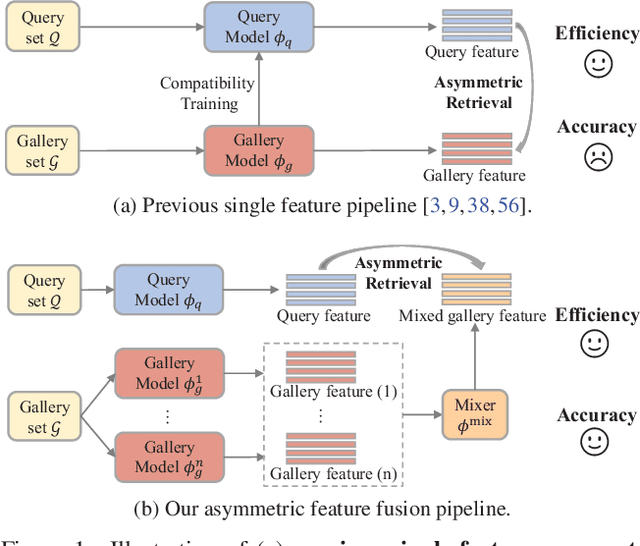
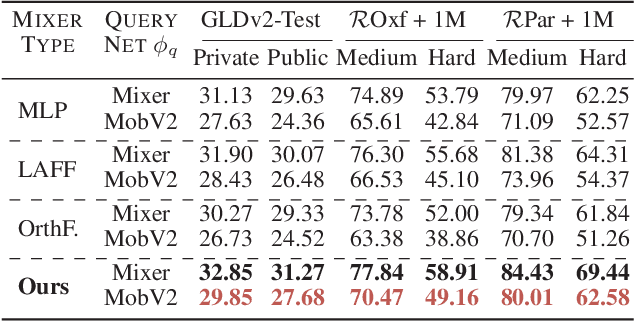
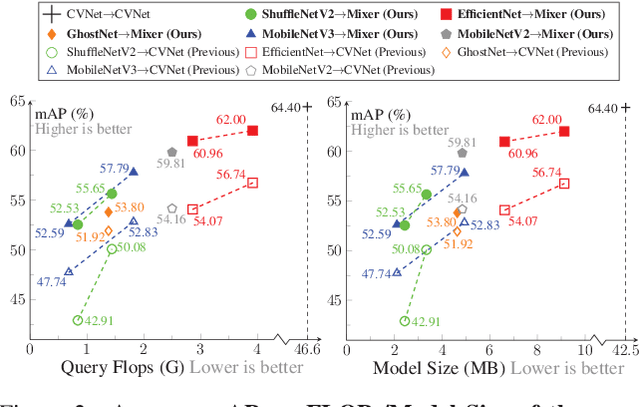
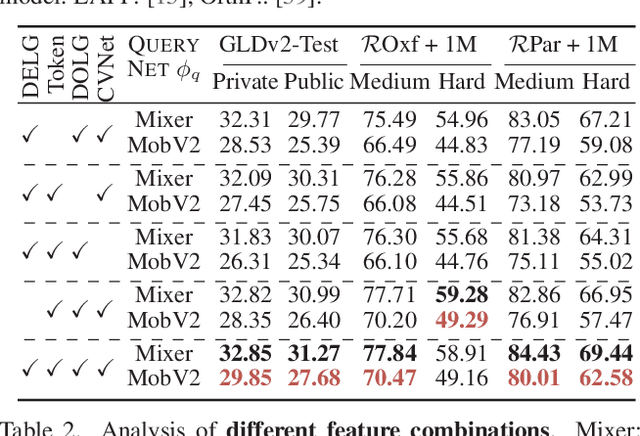
In asymmetric retrieval systems, models with different capacities are deployed on platforms with different computational and storage resources. Despite the great progress, existing approaches still suffer from a dilemma between retrieval efficiency and asymmetric accuracy due to the limited capacity of the lightweight query model. In this work, we propose an Asymmetric Feature Fusion (AFF) paradigm, which advances existing asymmetric retrieval systems by considering the complementarity among different features just at the gallery side. Specifically, it first embeds each gallery image into various features, e.g., local features and global features. Then, a dynamic mixer is introduced to aggregate these features into compact embedding for efficient search. On the query side, only a single lightweight model is deployed for feature extraction. The query model and dynamic mixer are jointly trained by sharing a momentum-updated classifier. Notably, the proposed paradigm boosts the accuracy of asymmetric retrieval without introducing any extra overhead to the query side. Exhaustive experiments on various landmark retrieval datasets demonstrate the superiority of our paradigm.
Decomposing Disease Descriptions for Enhanced Pathology Detection: A Multi-Aspect Vision-Language Matching Framework
Mar 12, 2024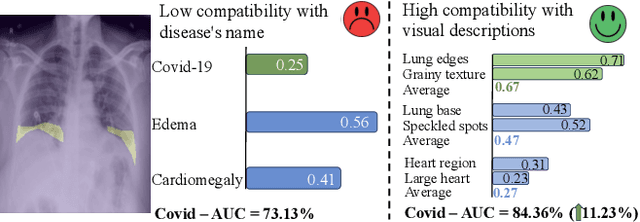
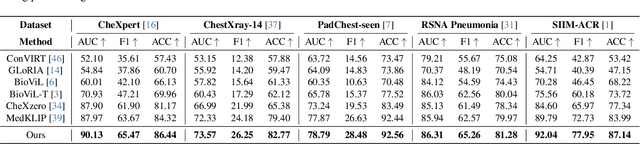

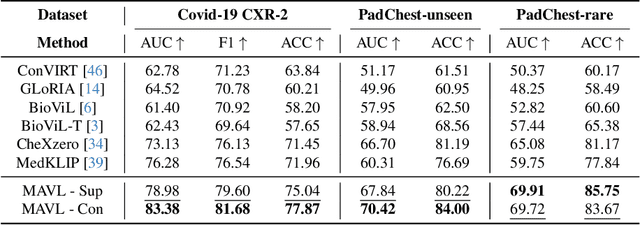
Medical vision language pre-training (VLP) has emerged as a frontier of research, enabling zero-shot pathological recognition by comparing the query image with the textual descriptions for each disease. Due to the complex semantics of biomedical texts, current methods struggle to align medical images with key pathological findings in unstructured reports. This leads to the misalignment with the target disease's textual representation. In this paper, we introduce a novel VLP framework designed to dissect disease descriptions into their fundamental aspects, leveraging prior knowledge about the visual manifestations of pathologies. This is achieved by consulting a large language model and medical experts. Integrating a Transformer module, our approach aligns an input image with the diverse elements of a disease, generating aspect-centric image representations. By consolidating the matches from each aspect, we improve the compatibility between an image and its associated disease. Additionally, capitalizing on the aspect-oriented representations, we present a dual-head Transformer tailored to process known and unknown diseases, optimizing the comprehensive detection efficacy. Conducting experiments on seven downstream datasets, ours outperforms recent methods by up to 8.07% and 11.23% in AUC scores for seen and novel categories, respectively. Our code is released at \href{https://github.com/HieuPhan33/MAVL}{https://github.com/HieuPhan33/MAVL}.