 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
How is Visual Attention Influenced by Text Guidance? Database and Model
Apr 12, 2024
The analysis and prediction of visual attention have long been crucial tasks in the fields of computer vision and image processing. In practical applications, images are generally accompanied by various text descriptions, however, few studies have explored the influence of text descriptions on visual attention, let alone developed visual saliency prediction models considering text guidance. In this paper, we conduct a comprehensive study on text-guided image saliency (TIS) from both subjective and objective perspectives. Specifically, we construct a TIS database named SJTU-TIS, which includes 1200 text-image pairs and the corresponding collected eye-tracking data. Based on the established SJTU-TIS database, we analyze the influence of various text descriptions on visual attention. Then, to facilitate the development of saliency prediction models considering text influence, we construct a benchmark for the established SJTU-TIS database using state-of-the-art saliency models. Finally, considering the effect of text descriptions on visual attention, while most existing saliency models ignore this impact, we further propose a text-guided saliency (TGSal) prediction model, which extracts and integrates both image features and text features to predict the image saliency under various text-description conditions. Our proposed model significantly outperforms the state-of-the-art saliency models on both the SJTU-TIS database and the pure image saliency databases in terms of various evaluation metrics. The SJTU-TIS database and the code of the proposed TGSal model will be released at: https://github.com/IntMeGroup/TGSal.
Detecting AI-Generated Images via CLIP
Apr 12, 2024As AI-generated image (AIGI) methods become more powerful and accessible, it has become a critical task to determine if an image is real or AI-generated. Because AIGI lack the signatures of photographs and have their own unique patterns, new models are needed to determine if an image is AI-generated. In this paper, we investigate the ability of the Contrastive Language-Image Pre-training (CLIP) architecture, pre-trained on massive internet-scale data sets, to perform this differentiation. We fine-tune CLIP on real images and AIGI from several generative models, enabling CLIP to determine if an image is AI-generated and, if so, determine what generation method was used to create it. We show that the fine-tuned CLIP architecture is able to differentiate AIGI as well or better than models whose architecture is specifically designed to detect AIGI. Our method will significantly increase access to AIGI-detecting tools and reduce the negative effects of AIGI on society, as our CLIP fine-tuning procedures require no architecture changes from publicly available model repositories and consume significantly less GPU resources than other AIGI detection models.
Evaluating Text-to-Image Synthesis: Survey and Taxonomy of Image Quality Metrics
Mar 29, 2024
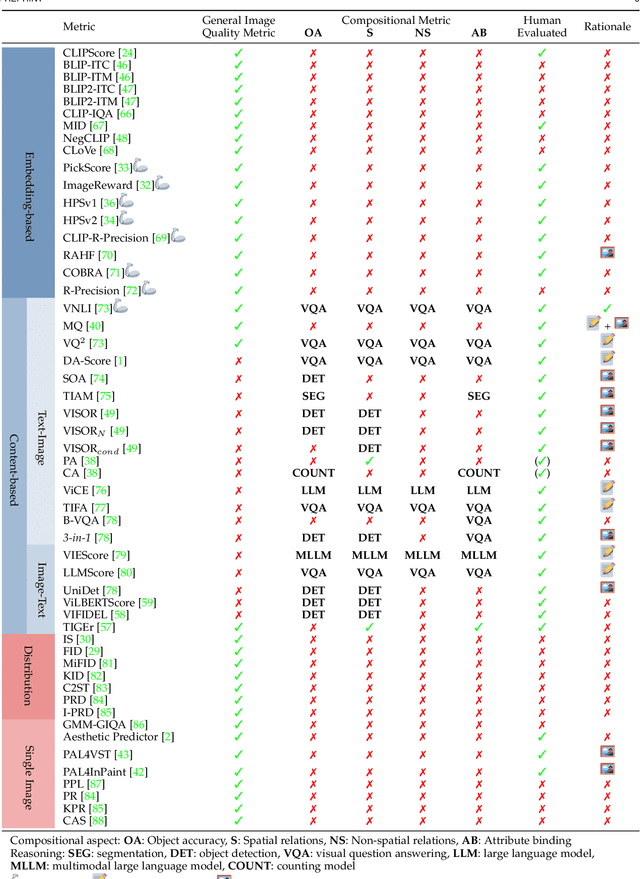
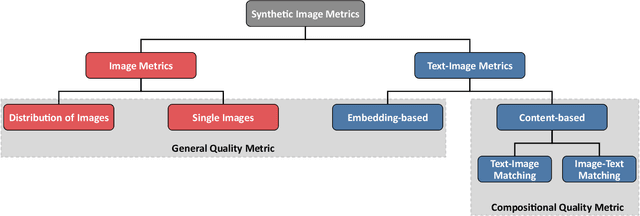
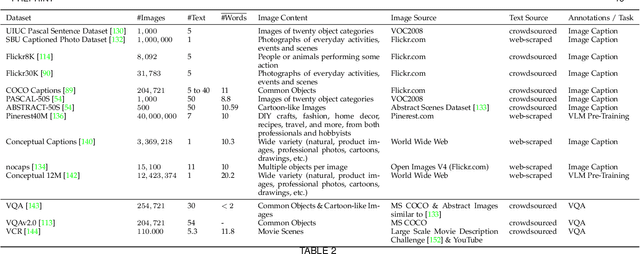
Recent advances in text-to-image synthesis enabled through a combination of language and vision foundation models have led to a proliferation of the tools available and an increased attention to the field. When conducting text-to-image synthesis, a central goal is to ensure that the content between text and image is aligned. As such, there exist numerous evaluation metrics that aim to mimic human judgement. However, it is often unclear which metric to use for evaluating text-to-image synthesis systems as their evaluation is highly nuanced. In this work, we provide a comprehensive overview of existing text-to-image evaluation metrics. Based on our findings, we propose a new taxonomy for categorizing these metrics. Our taxonomy is grounded in the assumption that there are two main quality criteria, namely compositionality and generality, which ideally map to human preferences. Ultimately, we derive guidelines for practitioners conducting text-to-image evaluation, discuss open challenges of evaluation mechanisms, and surface limitations of current metrics.
Fast Fishing: Approximating BAIT for Efficient and Scalable Deep Active Image Classification
Apr 13, 2024Deep active learning (AL) seeks to minimize the annotation costs for training deep neural networks. BAIT, a recently proposed AL strategy based on the Fisher Information, has demonstrated impressive performance across various datasets. However, BAIT's high computational and memory requirements hinder its applicability on large-scale classification tasks, resulting in current research neglecting BAIT in their evaluation. This paper introduces two methods to enhance BAIT's computational efficiency and scalability. Notably, we significantly reduce its time complexity by approximating the Fisher Information. In particular, we adapt the original formulation by i) taking the expectation over the most probable classes, and ii) constructing a binary classification task, leading to an alternative likelihood for gradient computations. Consequently, this allows the efficient use of BAIT on large-scale datasets, including ImageNet. Our unified and comprehensive evaluation across a variety of datasets demonstrates that our approximations achieve strong performance with considerably reduced time complexity. Furthermore, we provide an extensive open-source toolbox that implements recent state-of-the-art AL strategies, available at https://github.com/dhuseljic/dal-toolbox.
Differentiable Search for Finding Optimal Quantization Strategy
Apr 15, 2024To accelerate and compress deep neural networks (DNNs), many network quantization algorithms have been proposed. Although the quantization strategy of any algorithm from the state-of-the-arts may outperform others in some network architectures, it is hard to prove the strategy is always better than others, and even cannot judge that the strategy is always the best choice for all layers in a network. In other words, existing quantization algorithms are suboptimal as they ignore the different characteristics of different layers and quantize all layers by a uniform quantization strategy. To solve the issue, in this paper, we propose a differentiable quantization strategy search (DQSS) to assign optimal quantization strategy for individual layer by taking advantages of the benefits of different quantization algorithms. Specifically, we formulate DQSS as a differentiable neural architecture search problem and adopt an efficient convolution to efficiently explore the mixed quantization strategies from a global perspective by gradient-based optimization. We conduct DQSS for post-training quantization to enable their performance to be comparable with that in full precision models. We also employ DQSS in quantization-aware training for further validating the effectiveness of DQSS. To circumvent the expensive optimization cost when employing DQSS in quantization-aware training, we update the hyper-parameters and the network parameters in a single forward-backward pass. Besides, we adjust the optimization process to avoid the potential under-fitting problem. Comprehensive experiments on high level computer vision task, i.e., image classification, and low level computer vision task, i.e., image super-resolution, with various network architectures show that DQSS could outperform the state-of-the-arts.
CLIPtone: Unsupervised Learning for Text-based Image Tone Adjustment
Apr 01, 2024Recent image tone adjustment (or enhancement) approaches have predominantly adopted supervised learning for learning human-centric perceptual assessment. However, these approaches are constrained by intrinsic challenges of supervised learning. Primarily, the requirement for expertly-curated or retouched images escalates the data acquisition expenses. Moreover, their coverage of target style is confined to stylistic variants inferred from the training data. To surmount the above challenges, we propose an unsupervised learning-based approach for text-based image tone adjustment method, CLIPtone, that extends an existing image enhancement method to accommodate natural language descriptions. Specifically, we design a hyper-network to adaptively modulate the pretrained parameters of the backbone model based on text description. To assess whether the adjusted image aligns with the text description without ground truth image, we utilize CLIP, which is trained on a vast set of language-image pairs and thus encompasses knowledge of human perception. The major advantages of our approach are three fold: (i) minimal data collection expenses, (ii) support for a range of adjustments, and (iii) the ability to handle novel text descriptions unseen in training. Our approach's efficacy is demonstrated through comprehensive experiments, including a user study.
Language Guided Domain Generalized Medical Image Segmentation
Apr 03, 2024Single source domain generalization (SDG) holds promise for more reliable and consistent image segmentation across real-world clinical settings particularly in the medical domain, where data privacy and acquisition cost constraints often limit the availability of diverse datasets. Depending solely on visual features hampers the model's capacity to adapt effectively to various domains, primarily because of the presence of spurious correlations and domain-specific characteristics embedded within the image features. Incorporating text features alongside visual features is a potential solution to enhance the model's understanding of the data, as it goes beyond pixel-level information to provide valuable context. Textual cues describing the anatomical structures, their appearances, and variations across various imaging modalities can guide the model in domain adaptation, ultimately contributing to more robust and consistent segmentation. In this paper, we propose an approach that explicitly leverages textual information by incorporating a contrastive learning mechanism guided by the text encoder features to learn a more robust feature representation. We assess the effectiveness of our text-guided contrastive feature alignment technique in various scenarios, including cross-modality, cross-sequence, and cross-site settings for different segmentation tasks. Our approach achieves favorable performance against existing methods in literature. Our code and model weights are available at https://github.com/ShahinaKK/LG_SDG.git.
Convolutional neural network classification of cancer cytopathology images: taking breast cancer as an example
Apr 12, 2024Breast cancer is a relatively common cancer among gynecological cancers. Its diagnosis often relies on the pathology of cells in the lesion. The pathological diagnosis of breast cancer not only requires professionals and time, but also sometimes involves subjective judgment. To address the challenges of dependence on pathologists expertise and the time-consuming nature of achieving accurate breast pathological image classification, this paper introduces an approach utilizing convolutional neural networks (CNNs) for the rapid categorization of pathological images, aiming to enhance the efficiency of breast pathological image detection. And the approach enables the rapid and automatic classification of pathological images into benign and malignant groups. The methodology involves utilizing a convolutional neural network (CNN) model leveraging the Inceptionv3 architecture and transfer learning algorithm for extracting features from pathological images. Utilizing a neural network with fully connected layers and employing the SoftMax function for image classification. Additionally, the concept of image partitioning is introduced to handle high-resolution images. To achieve the ultimate classification outcome, the classification probabilities of each image block are aggregated using three algorithms: summation, product, and maximum. Experimental validation was conducted on the BreaKHis public dataset, resulting in accuracy rates surpassing 0.92 across all four magnification coefficients (40X, 100X, 200X, and 400X). It demonstrates that the proposed method effectively enhances the accuracy in classifying pathological images of breast cancer.
Uncovering the Text Embedding in Text-to-Image Diffusion Models
Apr 01, 2024The correspondence between input text and the generated image exhibits opacity, wherein minor textual modifications can induce substantial deviations in the generated image. While, text embedding, as the pivotal intermediary between text and images, remains relatively underexplored. In this paper, we address this research gap by delving into the text embedding space, unleashing its capacity for controllable image editing and explicable semantic direction attributes within a learning-free framework. Specifically, we identify two critical insights regarding the importance of per-word embedding and their contextual correlations within text embedding, providing instructive principles for learning-free image editing. Additionally, we find that text embedding inherently possesses diverse semantic potentials, and further reveal this property through the lens of singular value decomposition (SVD). These uncovered properties offer practical utility for image editing and semantic discovery. More importantly, we expect the in-depth analyses and findings of the text embedding can enhance the understanding of text-to-image diffusion models.
MaSkel: A Model for Human Whole-body X-rays Generation from Human Masking Images
Apr 13, 2024The human whole-body X-rays could offer a valuable reference for various applications, including medical diagnostics, digital animation modeling, and ergonomic design. The traditional method of obtaining X-ray information requires the use of CT (Computed Tomography) scan machines, which emit potentially harmful radiation. Thus it faces a significant limitation for realistic applications because it lacks adaptability and safety. In our work, We proposed a new method to directly generate the 2D human whole-body X-rays from the human masking images. The predicted images will be similar to the real ones with the same image style and anatomic structure. We employed a data-driven strategy. By leveraging advanced generative techniques, our model MaSkel(Masking image to Skeleton X-rays) could generate a high-quality X-ray image from a human masking image without the need for invasive and harmful radiation exposure, which not only provides a new path to generate highly anatomic and customized data but also reduces health risks. To our knowledge, our model MaSkel is the first work for predicting whole-body X-rays. In this paper, we did two parts of the work. The first one is to solve the data limitation problem, the diffusion-based techniques are utilized to make a data augmentation, which provides two synthetic datasets for preliminary pretraining. Then we designed a two-stage training strategy to train MaSkel. At last, we make qualitative and quantitative evaluations of the generated X-rays. In addition, we invite some professional doctors to assess our predicted data. These evaluations demonstrate the MaSkel's superior ability to generate anatomic X-rays from human masking images. The related code and links of the dataset are available at https://github.com/2022yingjie/MaSkel.