 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Scaling Robot Learning with Semantically Imagined Experience
Feb 22, 2023

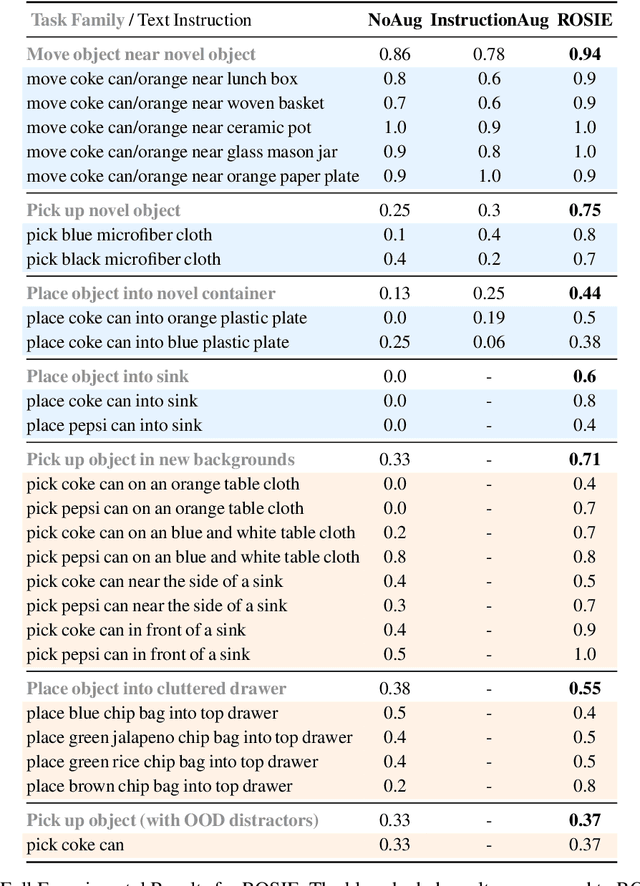
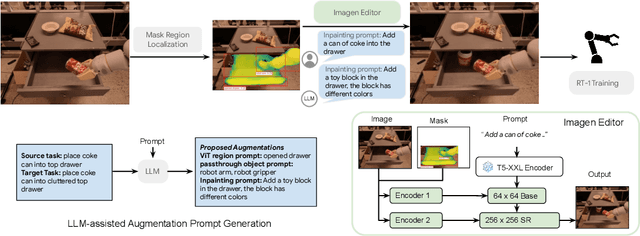

Recent advances in robot learning have shown promise in enabling robots to perform a variety of manipulation tasks and generalize to novel scenarios. One of the key contributing factors to this progress is the scale of robot data used to train the models. To obtain large-scale datasets, prior approaches have relied on either demonstrations requiring high human involvement or engineering-heavy autonomous data collection schemes, both of which are challenging to scale. To mitigate this issue, we propose an alternative route and leverage text-to-image foundation models widely used in computer vision and natural language processing to obtain meaningful data for robot learning without requiring additional robot data. We term our method Robot Learning with Semantically Imagened Experience (ROSIE). Specifically, we make use of the state of the art text-to-image diffusion models and perform aggressive data augmentation on top of our existing robotic manipulation datasets via inpainting various unseen objects for manipulation, backgrounds, and distractors with text guidance. Through extensive real-world experiments, we show that manipulation policies trained on data augmented this way are able to solve completely unseen tasks with new objects and can behave more robustly w.r.t. novel distractors. In addition, we find that we can improve the robustness and generalization of high-level robot learning tasks such as success detection through training with the diffusion-based data augmentation. The project's website and videos can be found at diffusion-rosie.github.io
Memory-aided Contrastive Consensus Learning for Co-salient Object Detection
Mar 11, 2023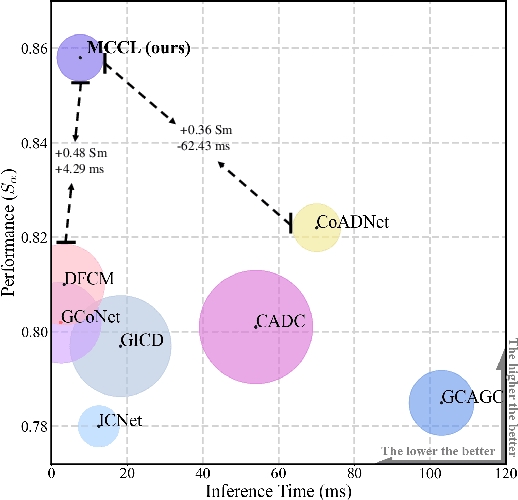
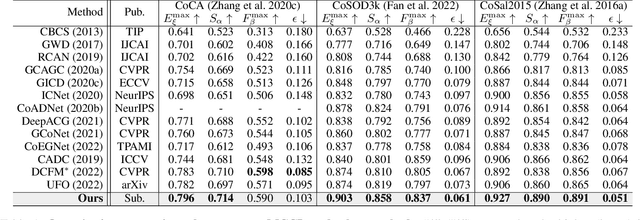
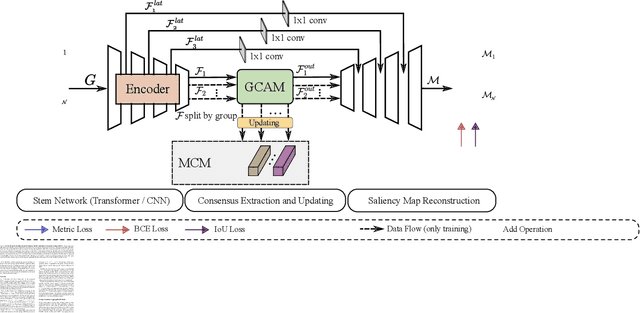

Co-Salient Object Detection (CoSOD) aims at detecting common salient objects within a group of relevant source images. Most of the latest works employ the attention mechanism for finding common objects. To achieve accurate CoSOD results with high-quality maps and high efficiency, we propose a novel Memory-aided Contrastive Consensus Learning (MCCL) framework, which is capable of effectively detecting co-salient objects in real time (~150 fps). To learn better group consensus, we propose the Group Consensus Aggregation Module (GCAM) to abstract the common features of each image group; meanwhile, to make the consensus representation more discriminative, we introduce the Memory-based Contrastive Module (MCM), which saves and updates the consensus of images from different groups in a queue of memories. Finally, to improve the quality and integrity of the predicted maps, we develop an Adversarial Integrity Learning (AIL) strategy to make the segmented regions more likely composed of complete objects with less surrounding noise. Extensive experiments on all the latest CoSOD benchmarks demonstrate that our lite MCCL outperforms 13 cutting-edge models, achieving the new state of the art (~5.9% and ~6.2% improvement in S-measure on CoSOD3k and CoSal2015, respectively). Our source codes, saliency maps, and online demos are publicly available at https://github.com/ZhengPeng7/MCCL.
Learned Lossless Compression for JPEG via Frequency-Domain Prediction
Mar 05, 2023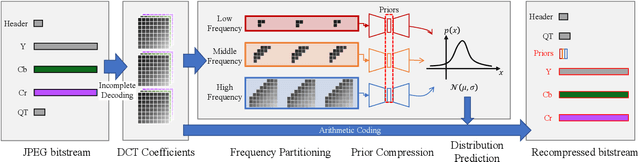
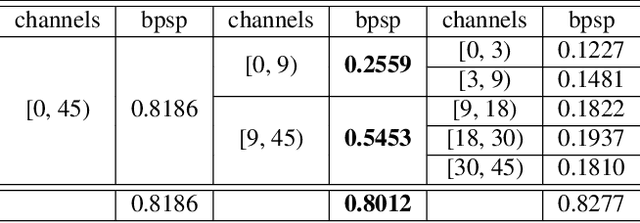
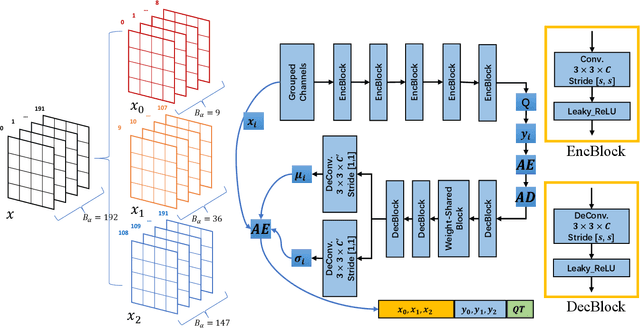

JPEG images can be further compressed to enhance the storage and transmission of large-scale image datasets. Existing learned lossless compressors for RGB images cannot be well transferred to JPEG images due to the distinguishing distribution of DCT coefficients and raw pixels. In this paper, we propose a novel framework for learned lossless compression of JPEG images that achieves end-to-end optimized prediction of the distribution of decoded DCT coefficients. To enable learning in the frequency domain, DCT coefficients are partitioned into groups to utilize implicit local redundancy. An autoencoder-like architecture is designed based on the weight-shared blocks to realize entropy modeling of grouped DCT coefficients and independently compress the priors. We attempt to realize learned lossless compression of JPEG images in the frequency domain. Experimental results demonstrate that the proposed framework achieves superior or comparable performance in comparison to most recent lossless compressors with handcrafted context modeling for JPEG images.
HyperPose: Camera Pose Localization using Attention Hypernetworks
Mar 05, 2023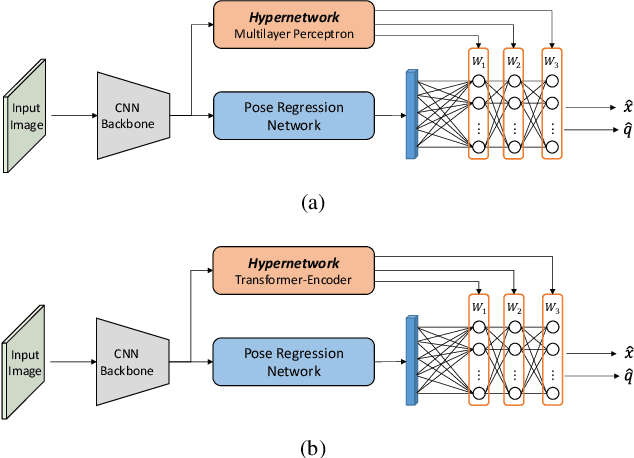
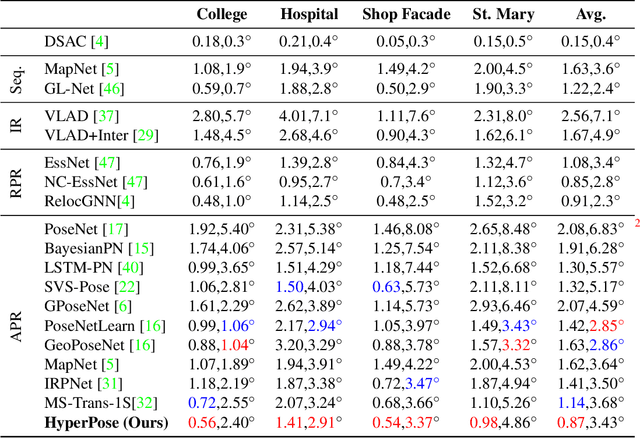
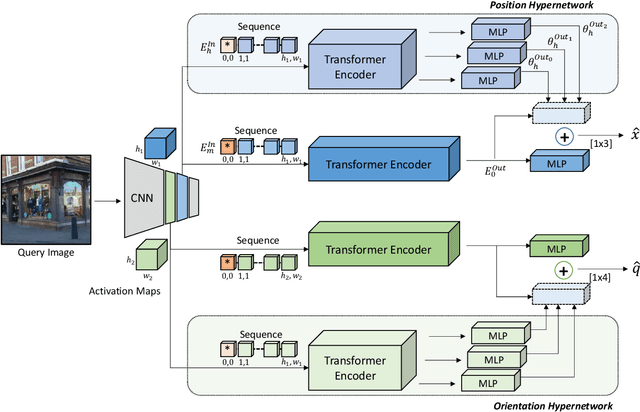
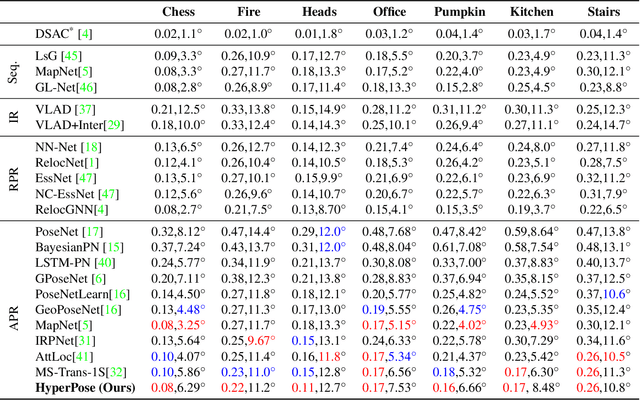
In this study, we propose the use of attention hypernetworks in camera pose localization. The dynamic nature of natural scenes, including changes in environment, perspective, and lighting, creates an inherent domain gap between the training and test sets that limits the accuracy of contemporary localization networks. To overcome this issue, we suggest a camera pose regressor that integrates a hypernetwork. During inference, the hypernetwork generates adaptive weights for the localization regression heads based on the input image, effectively reducing the domain gap. We also suggest the use of a Transformer-Encoder as the hypernetwork, instead of the common multilayer perceptron, to derive an attention hypernetwork. The proposed approach achieves superior results compared to state-of-the-art methods on contemporary datasets. To the best of our knowledge, this is the first instance of using hypernetworks in camera pose regression, as well as using Transformer-Encoders as hypernetworks. We make our code publicly available.
Securing Biomedical Images from Unauthorized Training with Anti-Learning Perturbation
Mar 05, 2023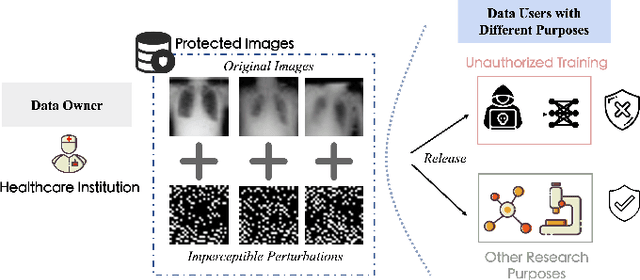
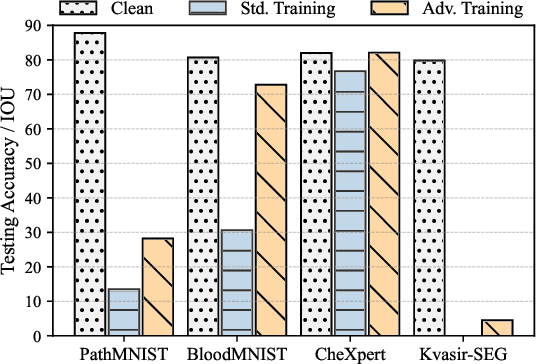
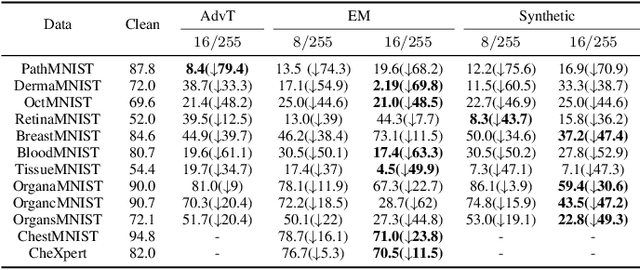
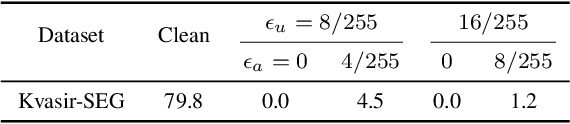
The volume of open-source biomedical data has been essential to the development of various spheres of the healthcare community since more `free' data can provide individual researchers more chances to contribute. However, institutions often hesitate to share their data with the public due to the risk of data exploitation by unauthorized third parties for another commercial usage (e.g., training AI models). This phenomenon might hinder the development of the whole healthcare research community. To address this concern, we propose a novel approach termed `unlearnable biomedical image' for protecting biomedical data by injecting imperceptible but delusive noises into the data, making them unexploitable for AI models. We formulate the problem as a bi-level optimization and propose three kinds of anti-learning perturbation generation approaches to solve the problem. Our method is an important step toward encouraging more institutions to contribute their data for the long-term development of the research community.
OAIR: Object-Aware Image Retargeting Using PSO and Aesthetic Quality Assessment
Sep 11, 2022
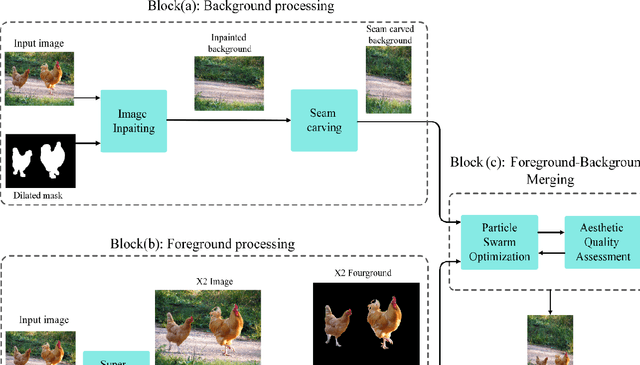

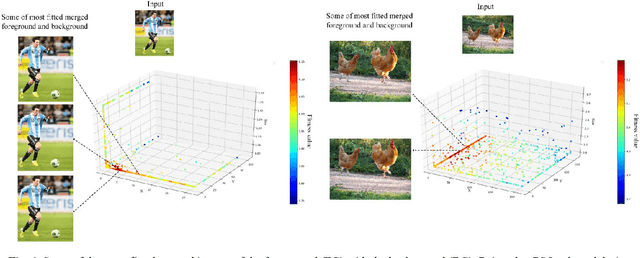
Image retargeting aims at altering an image size while preserving important content and minimizing noticeable distortions. However, previous image retargeting methods create outputs that suffer from artifacts and distortions. Besides, most previous works attempt to retarget the background and foreground of the input image simultaneously. Simultaneous resizing of the foreground and background causes changes in the aspect ratios of the objects. The change in the aspect ratio is specifically not desirable for human objects. We propose a retargeting method that overcomes these problems. The proposed approach consists of the following steps. Firstly, an inpainting method uses the input image and the binary mask of foreground objects to produce a background image without any foreground objects. Secondly, the seam carving method resizes the background image to the target size. Then, a super-resolution method increases the input image quality, and we then extract the foreground objects. Finally, the retargeted background and the extracted super-resolued objects are fed into a particle swarm optimization algorithm (PSO). The PSO algorithm uses aesthetic quality assessment as its objective function to identify the best location and size for the objects to be placed in the background. We used image quality assessment and aesthetic quality assessment measures to show our superior results compared to popular image retargeting techniques.
Federated Domain Generalization for Image Recognition via Cross-Client Style Transfer
Oct 03, 2022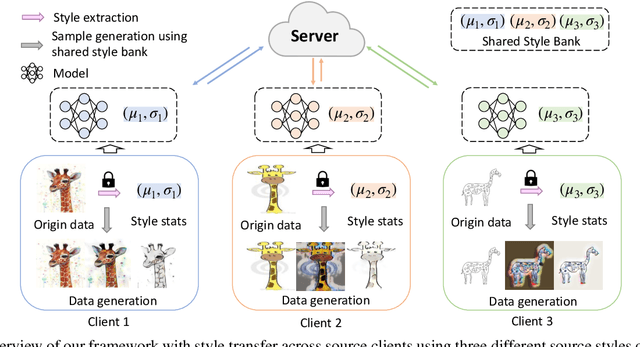
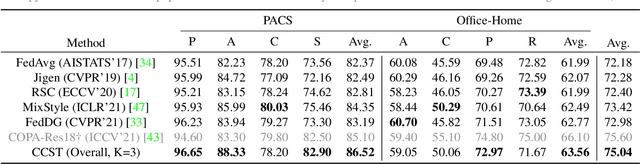
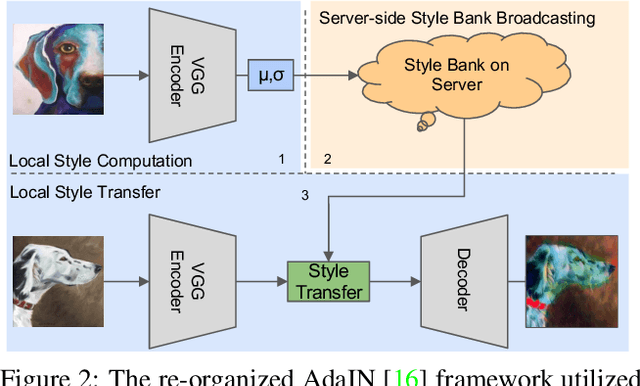
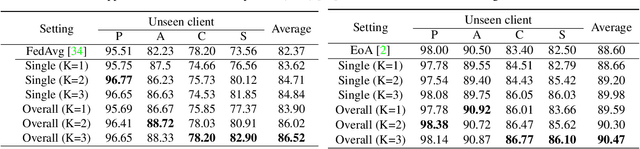
Domain generalization (DG) has been a hot topic in image recognition, with a goal to train a general model that can perform well on unseen domains. Recently, federated learning (FL), an emerging machine learning paradigm to train a global model from multiple decentralized clients without compromising data privacy, brings new challenges, also new possibilities, to DG. In the FL scenario, many existing state-of-the-art (SOTA) DG methods become ineffective, because they require the centralization of data from different domains during training. In this paper, we propose a novel domain generalization method for image recognition under federated learning through cross-client style transfer (CCST) without exchanging data samples. Our CCST method can lead to more uniform distributions of source clients, and thus make each local model learn to fit the image styles of all the clients to avoid the different model biases. Two types of style (single image style and overall domain style) with corresponding mechanisms are proposed to be chosen according to different scenarios. Our style representation is exceptionally lightweight and can hardly be used for the reconstruction of the dataset. The level of diversity is also flexible to be controlled with a hyper-parameter. Our method outperforms recent SOTA DG methods on two DG benchmarks (PACS, OfficeHome) and a large-scale medical image dataset (Camelyon17) in the FL setting. Last but not least, our method is orthogonal to many classic DG methods, achieving additive performance by combined utilization.
Novel Fundus Image Preprocessing for Retcam Images to Improve Deep Learning Classification of Retinopathy of Prematurity
Feb 16, 2023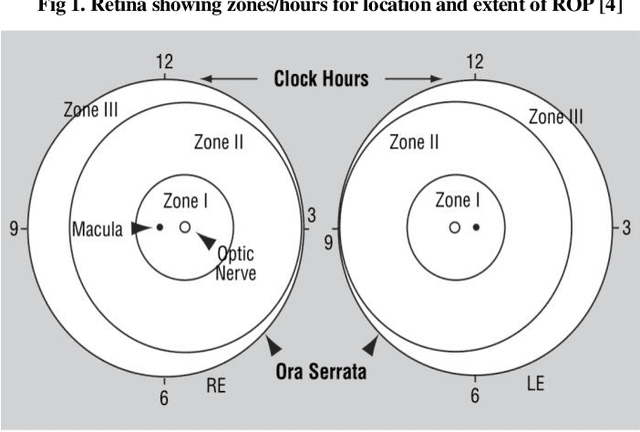
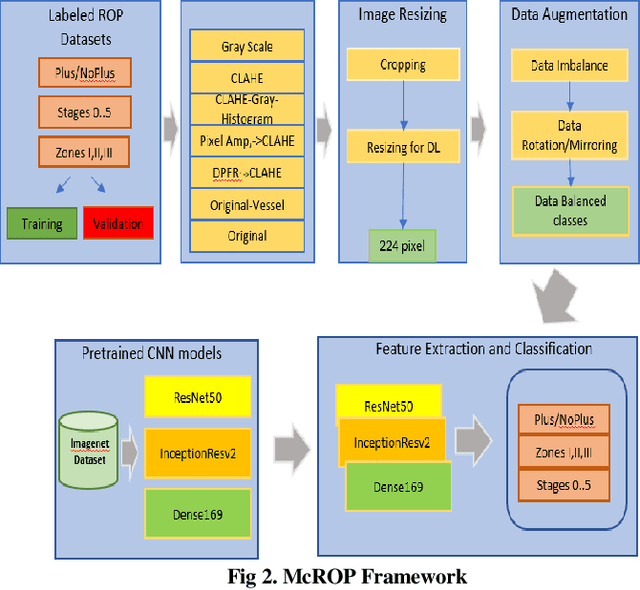
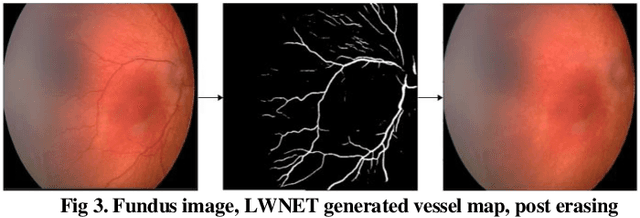
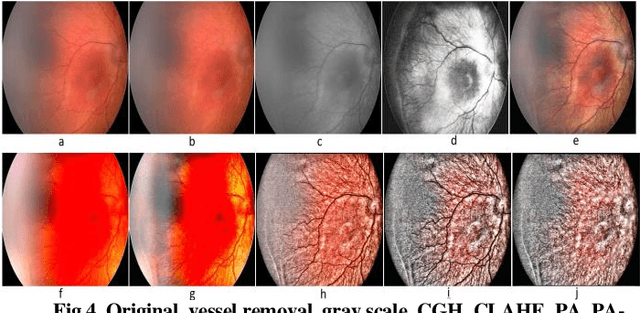
Retinopathy of Prematurity (ROP) is a potentially blinding eye disorder because of damage to the eye's retina which can affect babies born prematurely. Screening of ROP is essential for early detection and treatment. This is a laborious and manual process which requires trained physician performing dilated ophthalmological examination which can be subjective resulting in lower diagnosis success for clinically significant disease. Automated diagnostic methods can assist ophthalmologists increase diagnosis accuracy using deep learning. Several research groups have highlighted various approaches. This paper proposes the use of new novel fundus preprocessing methods using pretrained transfer learning frameworks to create hybrid models to give higher diagnosis accuracy. The evaluations show that these novel methods in comparison to traditional imaging processing contribute to higher accuracy in classifying Plus disease, Stages of ROP and Zones. We achieve accuracy of 97.65% for Plus disease, 89.44% for Stage, 90.24% for Zones with limited training dataset.
Retinex Image Enhancement Based on Sequential Decomposition With a Plug-and-Play Framework
Oct 11, 2022
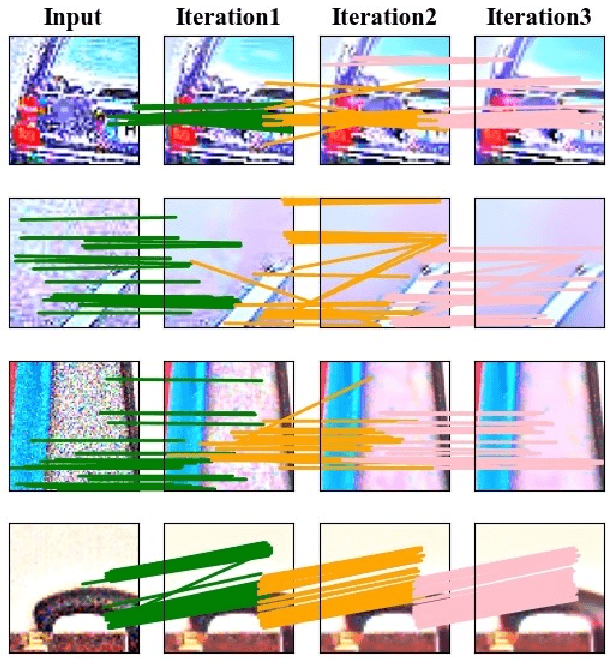


The Retinex model is one of the most representative and effective methods for low-light image enhancement. However, the Retinex model does not explicitly tackle the noise problem, and shows unsatisfactory enhancing results. In recent years, due to the excellent performance, deep learning models have been widely used in low-light image enhancement. However, these methods have two limitations: i) The desirable performance can only be achieved by deep learning when a large number of labeled data are available. However, it is not easy to curate massive low/normal-light paired data; ii) Deep learning is notoriously a black-box model [1]. It is difficult to explain their inner-working mechanism and understand their behaviors. In this paper, using a sequential Retinex decomposition strategy, we design a plug-and-play framework based on the Retinex theory for simultaneously image enhancement and noise removal. Meanwhile, we develop a convolutional neural network-based (CNN-based) denoiser into our proposed plug-and-play framework to generate a reflectance component. The final enhanced image is produced by integrating the illumination and reflectance with gamma correction. The proposed plug-and-play framework can facilitate both post hoc and ad hoc interpretability. Extensive experiments on different datasets demonstrate that our framework outcompetes the state-of-the-art methods in both image enhancement and denoising.
Energy-Inspired Self-Supervised Pretraining for Vision Models
Feb 02, 2023
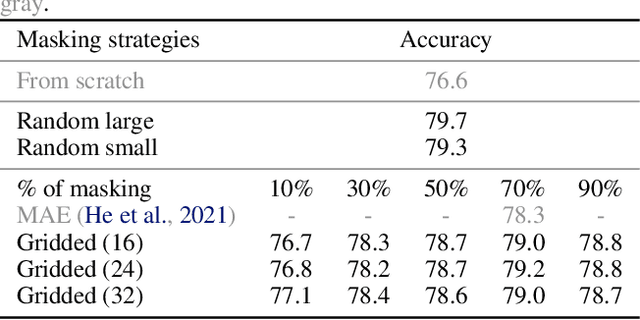
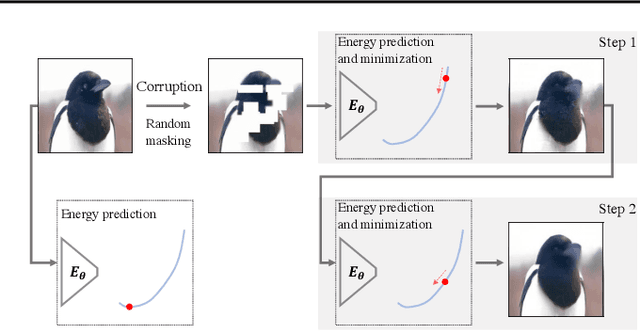
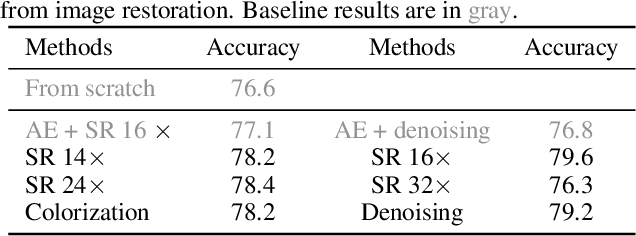
Motivated by the fact that forward and backward passes of a deep network naturally form symmetric mappings between input and output representations, we introduce a simple yet effective self-supervised vision model pretraining framework inspired by energy-based models (EBMs). In the proposed framework, we model energy estimation and data restoration as the forward and backward passes of a single network without any auxiliary components, e.g., an extra decoder. For the forward pass, we fit a network to an energy function that assigns low energy scores to samples that belong to an unlabeled dataset, and high energy otherwise. For the backward pass, we restore data from corrupted versions iteratively using gradient-based optimization along the direction of energy minimization. In this way, we naturally fold the encoder-decoder architecture widely used in masked image modeling into the forward and backward passes of a single vision model. Thus, our framework now accepts a wide range of pretext tasks with different data corruption methods, and permits models to be pretrained from masked image modeling, patch sorting, and image restoration, including super-resolution, denoising, and colorization. We support our findings with extensive experiments, and show the proposed method delivers comparable and even better performance with remarkably fewer epochs of training compared to the state-of-the-art self-supervised vision model pretraining methods. Our findings shed light on further exploring self-supervised vision model pretraining and pretext tasks beyond masked image modeling.