 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Lightweight Image Codec via Multi-Grid Multi-Block-Size Vector Quantization (MGBVQ)
Sep 25, 2022
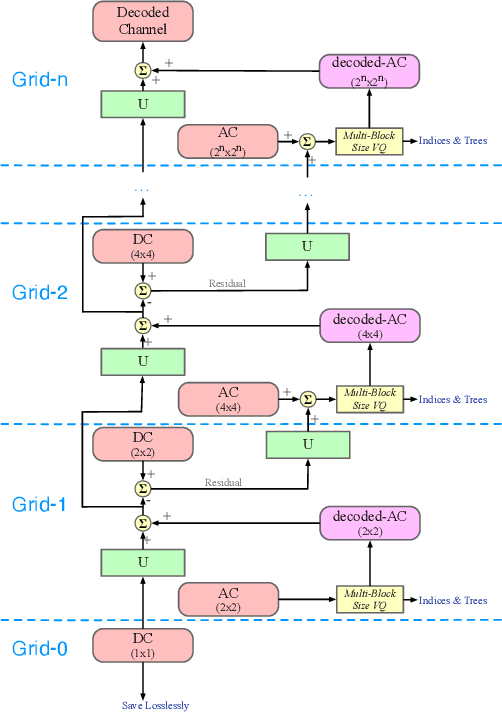
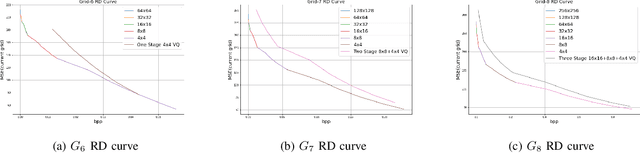


A multi-grid multi-block-size vector quantization (MGBVQ) method is proposed for image coding in this work. The fundamental idea of image coding is to remove correlations among pixels before quantization and entropy coding, e.g., the discrete cosine transform (DCT) and intra predictions, adopted by modern image coding standards. We present a new method to remove pixel correlations. First, by decomposing correlations into long- and short-range correlations, we represent long-range correlations in coarser grids due to their smoothness, thus leading to a multi-grid (MG) coding architecture. Second, we show that short-range correlations can be effectively coded by a suite of vector quantizers (VQs). Along this line, we argue the effectiveness of VQs of very large block sizes and present a convenient way to implement them. It is shown by experimental results that MGBVQ offers excellent rate-distortion (RD) performance, which is comparable with existing image coders, at much lower complexity. Besides, it provides a progressive coded bitstream.
Structure and Content-Guided Video Synthesis with Diffusion Models
Feb 06, 2023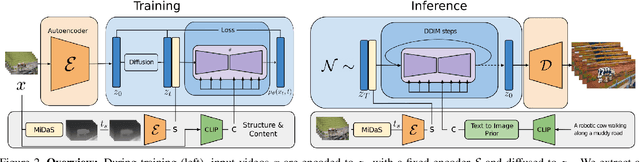
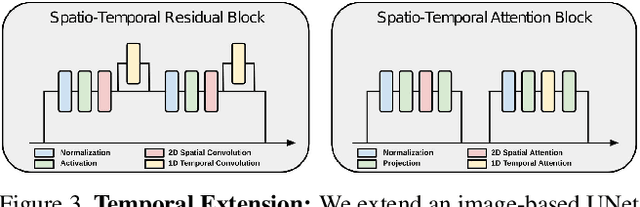


Text-guided generative diffusion models unlock powerful image creation and editing tools. While these have been extended to video generation, current approaches that edit the content of existing footage while retaining structure require expensive re-training for every input or rely on error-prone propagation of image edits across frames. In this work, we present a structure and content-guided video diffusion model that edits videos based on visual or textual descriptions of the desired output. Conflicts between user-provided content edits and structure representations occur due to insufficient disentanglement between the two aspects. As a solution, we show that training on monocular depth estimates with varying levels of detail provides control over structure and content fidelity. Our model is trained jointly on images and videos which also exposes explicit control of temporal consistency through a novel guidance method. Our experiments demonstrate a wide variety of successes; fine-grained control over output characteristics, customization based on a few reference images, and a strong user preference towards results by our model.
TherapyView: Visualizing Therapy Sessions with Temporal Topic Modeling and AI-Generated Arts
Feb 21, 2023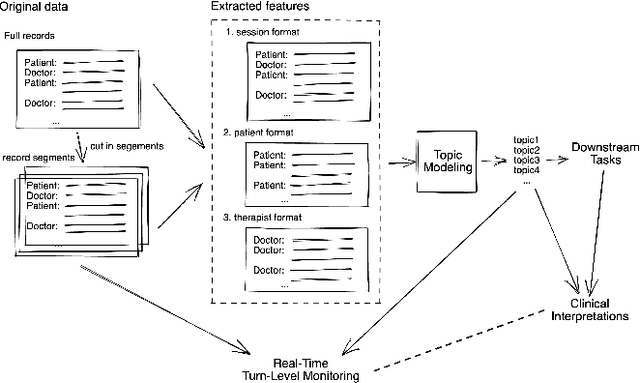
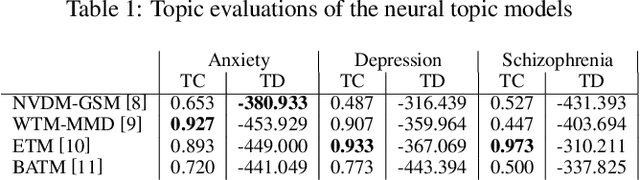
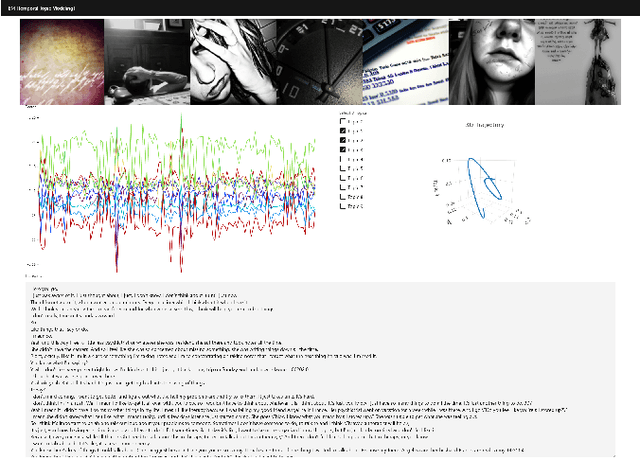
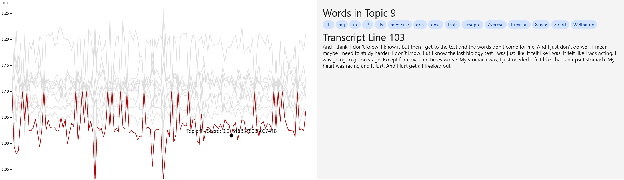
We present the TherapyView, a demonstration system to help therapists visualize the dynamic contents of past treatment sessions, enabled by the state-of-the-art neural topic modeling techniques to analyze the topical tendencies of various psychiatric conditions and deep learning-based image generation engine to provide a visual summary. The system incorporates temporal modeling to provide a time-series representation of topic similarities at a turn-level resolution and AI-generated artworks given the dialogue segments to provide a concise representations of the contents covered in the session, offering interpretable insights for therapists to optimize their strategies and enhance the effectiveness of psychotherapy. This system provides a proof of concept of AI-augmented therapy tools with e in-depth understanding of the patient's mental state and enabling more effective treatment.
Speech Privacy Leakage from Shared Gradients in Distributed Learning
Feb 21, 2023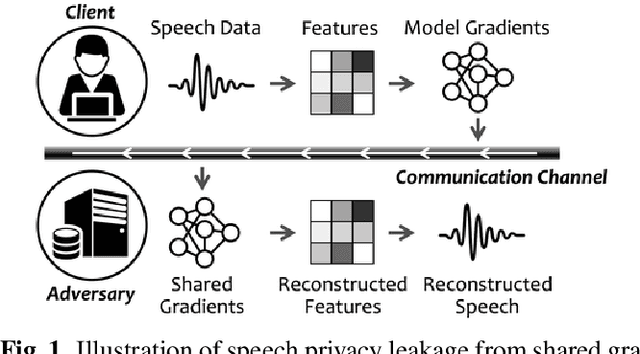
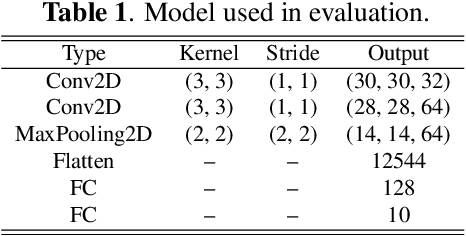
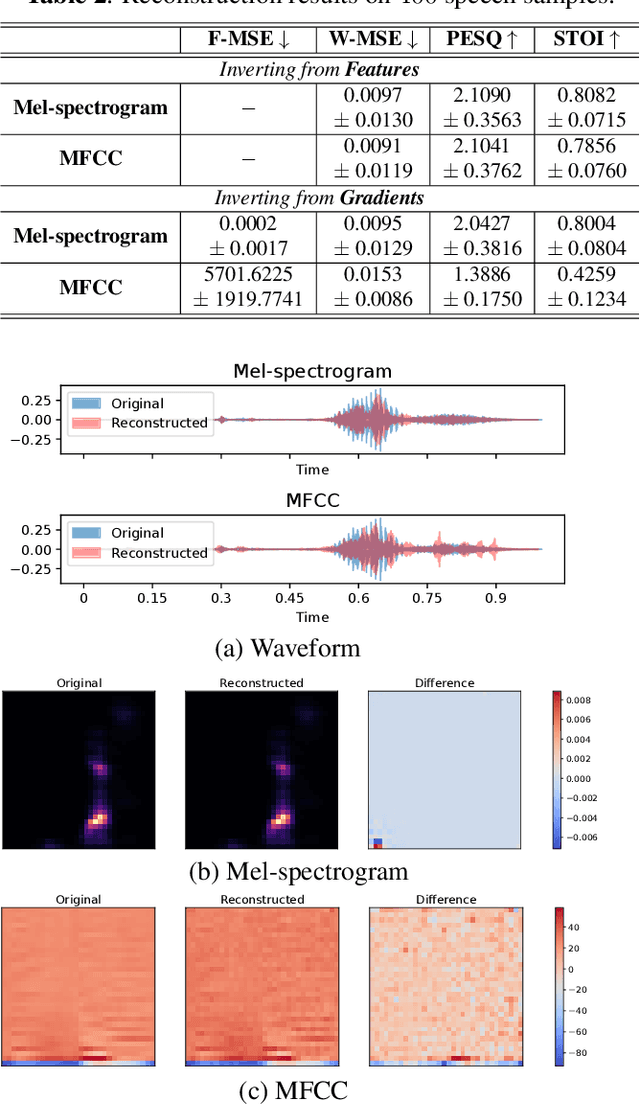
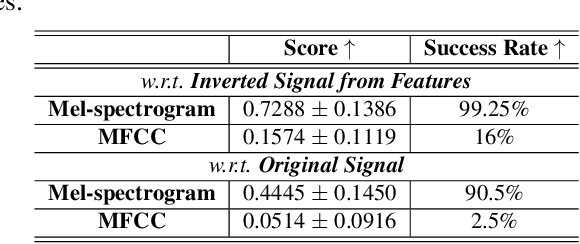
Distributed machine learning paradigms, such as federated learning, have been recently adopted in many privacy-critical applications for speech analysis. However, such frameworks are vulnerable to privacy leakage attacks from shared gradients. Despite extensive efforts in the image domain, the exploration of speech privacy leakage from gradients is quite limited. In this paper, we explore methods for recovering private speech/speaker information from the shared gradients in distributed learning settings. We conduct experiments on a keyword spotting model with two different types of speech features to quantify the amount of leaked information by measuring the similarity between the original and recovered speech signals. We further demonstrate the feasibility of inferring various levels of side-channel information, including speech content and speaker identity, under the distributed learning framework without accessing the user's data.
Futuristic Variations and Analysis in Fundus Images Corresponding to Biological Traits
Feb 08, 2023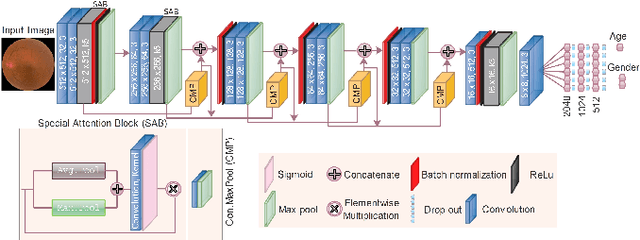
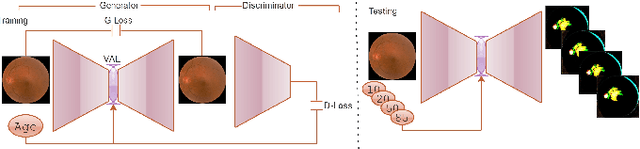
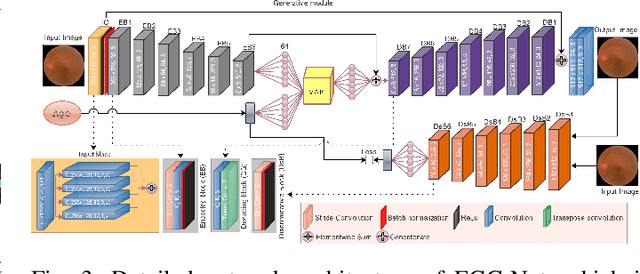

Fundus image captures rear of an eye, and which has been studied for the diseases identification, classification, segmentation, generation, and biological traits association using handcrafted, conventional, and deep learning methods. In biological traits estimation, most of the studies have been carried out for the age prediction and gender classification with convincing results. However, the current study utilizes the cutting-edge deep learning (DL) algorithms to estimate biological traits in terms of age and gender together with associating traits to retinal visuals. For the traits association, our study embeds aging as the label information into the proposed DL model to learn knowledge about the effected regions with aging. Our proposed DL models, named FAG-Net and FGC-Net, correspondingly estimate biological traits (age and gender) and generates fundus images. FAG-Net can generate multiple variants of an input fundus image given a list of ages as conditions. Our study analyzes fundus images and their corresponding association with biological traits, and predicts of possible spreading of ocular disease on fundus images given age as condition to the generative model. Our proposed models outperform the randomly selected state of-the-art DL models.
Improving End-to-End Text Image Translation From the Auxiliary Text Translation Task
Oct 08, 2022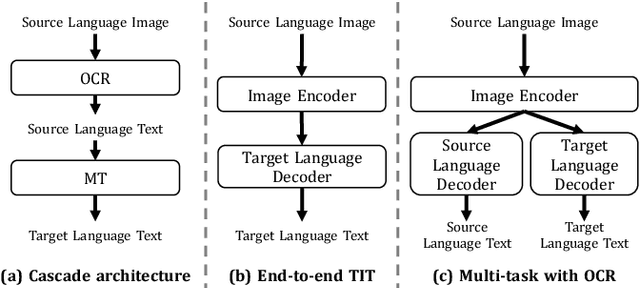
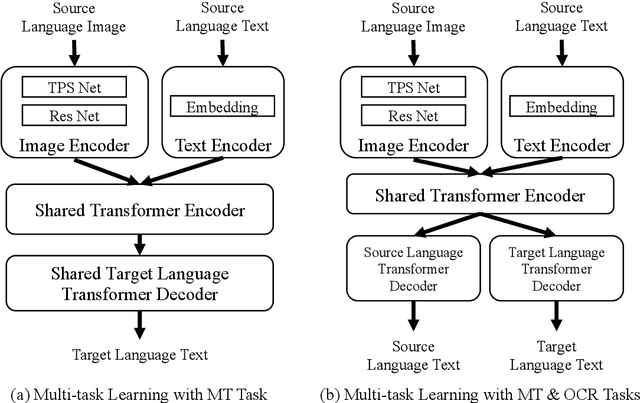
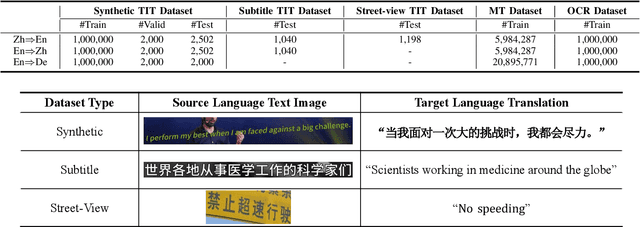
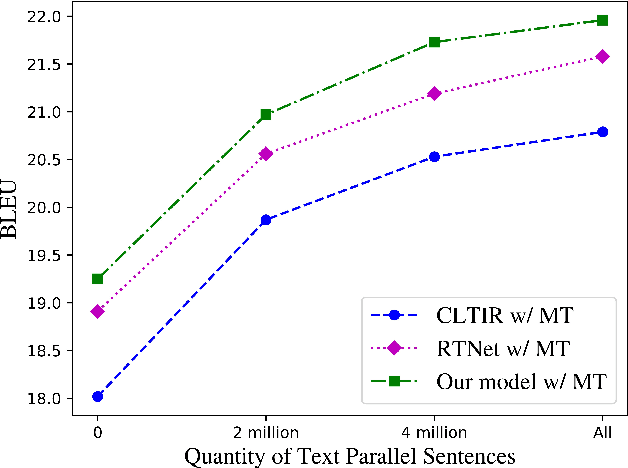
End-to-end text image translation (TIT), which aims at translating the source language embedded in images to the target language, has attracted intensive attention in recent research. However, data sparsity limits the performance of end-to-end text image translation. Multi-task learning is a non-trivial way to alleviate this problem via exploring knowledge from complementary related tasks. In this paper, we propose a novel text translation enhanced text image translation, which trains the end-to-end model with text translation as an auxiliary task. By sharing model parameters and multi-task training, our model is able to take full advantage of easily-available large-scale text parallel corpus. Extensive experimental results show our proposed method outperforms existing end-to-end methods, and the joint multi-task learning with both text translation and recognition tasks achieves better results, proving translation and recognition auxiliary tasks are complementary.
A Tale of Two Latent Flows: Learning Latent Space Normalizing Flow with Short-run Langevin Flow for Approximate Inference
Jan 23, 2023

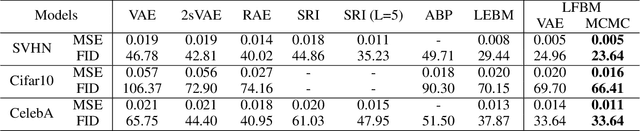

We study a normalizing flow in the latent space of a top-down generator model, in which the normalizing flow model plays the role of the informative prior model of the generator. We propose to jointly learn the latent space normalizing flow prior model and the top-down generator model by a Markov chain Monte Carlo (MCMC)-based maximum likelihood algorithm, where a short-run Langevin sampling from the intractable posterior distribution is performed to infer the latent variables for each observed example, so that the parameters of the normalizing flow prior and the generator can be updated with the inferred latent variables. We show that, under the scenario of non-convergent short-run MCMC, the finite step Langevin dynamics is a flow-like approximate inference model and the learning objective actually follows the perturbation of the maximum likelihood estimation (MLE). We further point out that the learning framework seeks to (i) match the latent space normalizing flow and the aggregated posterior produced by the short-run Langevin flow, and (ii) bias the model from MLE such that the short-run Langevin flow inference is close to the true posterior. Empirical results of extensive experiments validate the effectiveness of the proposed latent space normalizing flow model in the tasks of image generation, image reconstruction, anomaly detection, supervised image inpainting and unsupervised image recovery.
PalGAN: Image Colorization with Palette Generative Adversarial Networks
Oct 20, 2022
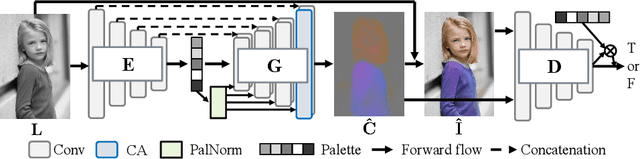
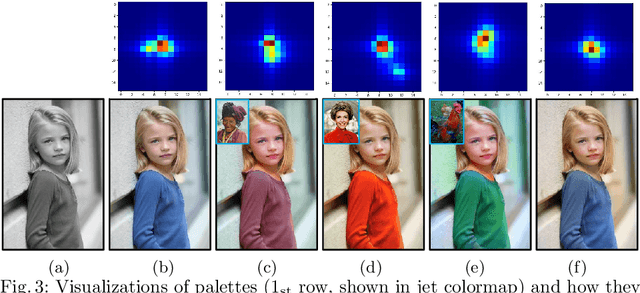
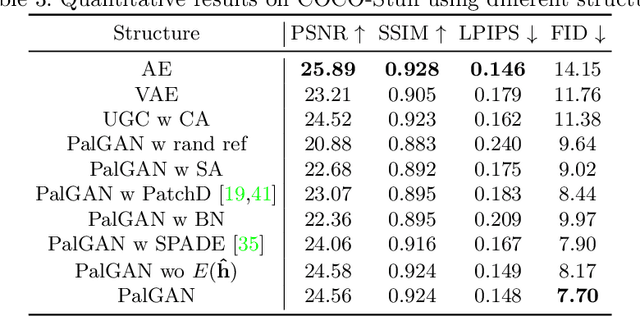
Multimodal ambiguity and color bleeding remain challenging in colorization. To tackle these problems, we propose a new GAN-based colorization approach PalGAN, integrated with palette estimation and chromatic attention. To circumvent the multimodality issue, we present a new colorization formulation that estimates a probabilistic palette from the input gray image first, then conducts color assignment conditioned on the palette through a generative model. Further, we handle color bleeding with chromatic attention. It studies color affinities by considering both semantic and intensity correlation. In extensive experiments, PalGAN outperforms state-of-the-arts in quantitative evaluation and visual comparison, delivering notable diverse, contrastive, and edge-preserving appearances. With the palette design, our method enables color transfer between images even with irrelevant contexts.
Image Classification using Sequence of Pixels
Sep 23, 2022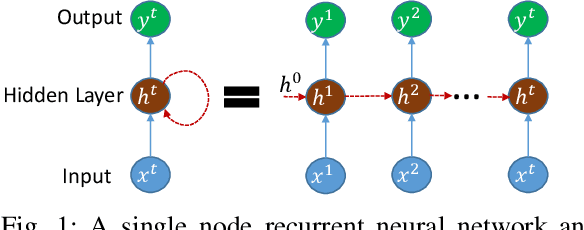
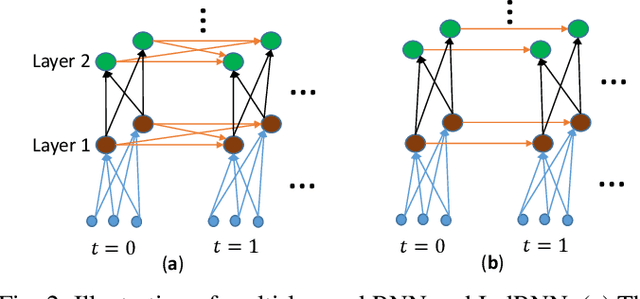

This study compares sequential image classification methods based on recurrent neural networks. We describe methods based on recurrent neural networks such as Long-Short-Term memory(LSTM), bidirectional Long-Short-Term memory(BiLSTM) architectures, etc. We also review the state-of-the-art sequential image classification architectures. We mainly focus on LSTM, BiLSTM, temporal convolution network, and independent recurrent neural network architecture in the study. It is known that RNN lacks in learning long-term dependencies in the input sequence. We use a simple feature construction method using orthogonal Ramanujan periodic transform on the input sequence. Experiments demonstrate that if these features are given to LSTM or BiLSTM networks, the performance increases drastically. Our focus in this study is to increase the training accuracy simultaneously reducing the training time for the LSTM and BiLSTM architecture, but not on pushing the state-of-the-art results, so we use simple LSTM/BiLSTM architecture. We compare sequential input with the constructed feature as input to single layer LSTM and BiLSTM network for MNIST and CIFAR datasets. We observe that sequential input to the LSTM network with 128 hidden unit training for five epochs results in training accuracy of 33% whereas constructed features as input to the same LSTM network results in training accuracy of 90% with 1/3 lesser time.
Invariant Target Detection in Images through the Normalized 2-D Correlation Technique
Feb 22, 2023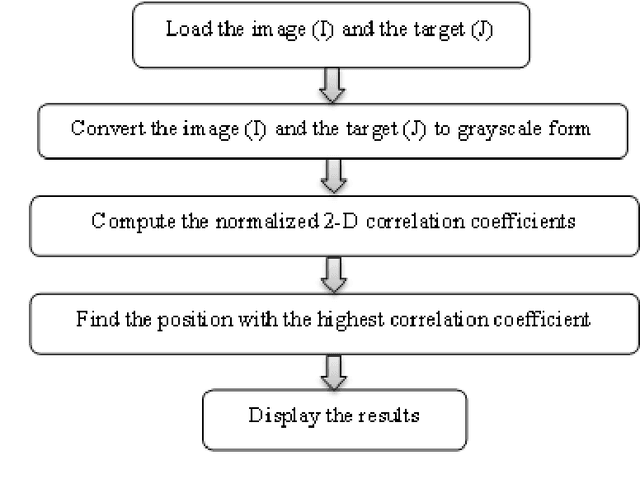

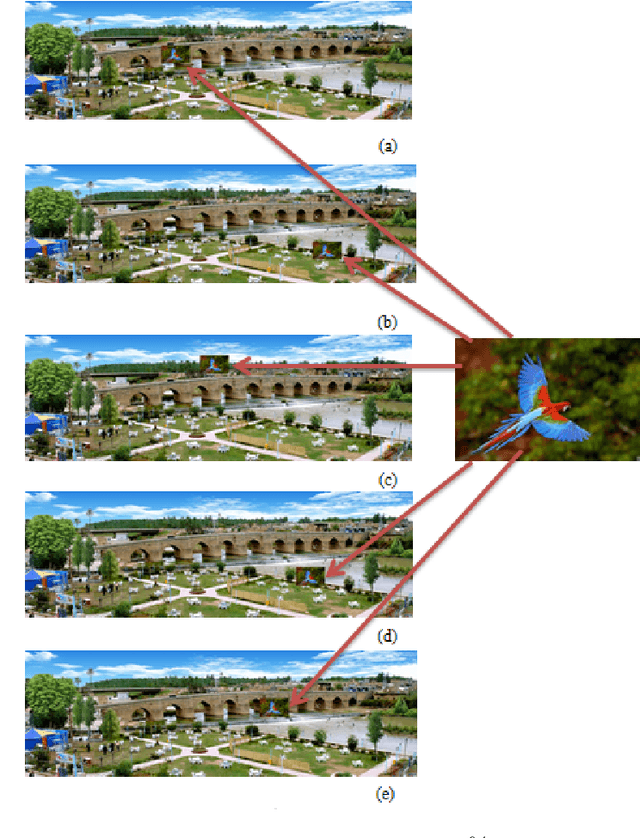

The normalized 2-D correlation technique is a robust method for detecting targets in images due to its ability to remain invariant under rotation, translation, and scaling. This paper examines the impact of translation, and scaling on target identification in images. The results indicate a high level of accuracy in detecting targets, even when they are exhibit variations in location and size. The results indicate that the similarity between the image and the two used targets improves as the resize ratio increases. All statistical estimators demonstrate a strong similarity between the original and extracted targets. The elapsed time for all scenarios falls within the range (44.75-44.85), (37.48-37.73) seconds for bird and children targets respectively, and the correlation coefficient displays stable relationships with values that fall within the range of (0.90-0.98) and (0.87-0.93) for bird and children targets respectively.