 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Ki-67 Index Measurement in Breast Cancer Using Digital Image Analysis
Sep 27, 2022
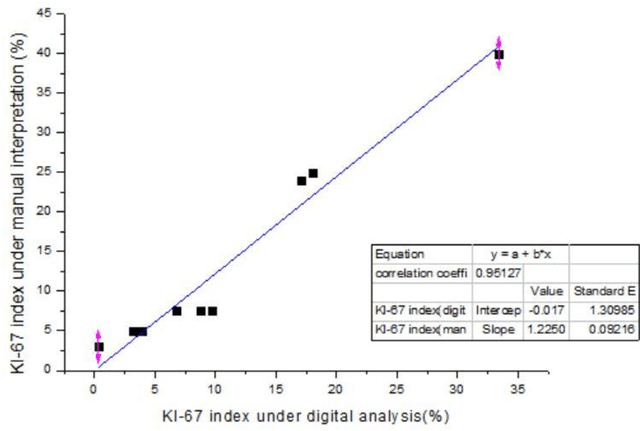
Ki-67 is a nuclear protein that can be produced during cell proliferation. The Ki67 index is a valuable prognostic variable in several kinds of cancer. In breast cancer, the index is even routinely checked in many patients. Currently, pathologists use the immunohistochemistry method to calculate the percentage of Ki-67 positive malignant cells as Ki-67 index. The higher score usually means more aggressive tumor behavior. In clinical practice, the measurement of Ki-67 index relies on visual identifying method and manual counting. However, visual and manual assessment method is timeconsuming and leads to poor reproducibility because of different scoring standards or limited tumor area under assessment. Here, we use digital image processing technics including image binarization and image morphological operations to create a digital image analysis method to interpretate Ki-67 index. Then, 10 breast cancer specimens are used as validation with high accuracy (correlation efficiency r = 0.95127). With the assistance of digital image analysis, pathologists can interpretate the Ki67 index more efficiently, precisely with excellent reproducibility.
A Robust and Low Complexity Deep Learning Model for Remote Sensing Image Classification
Nov 05, 2022
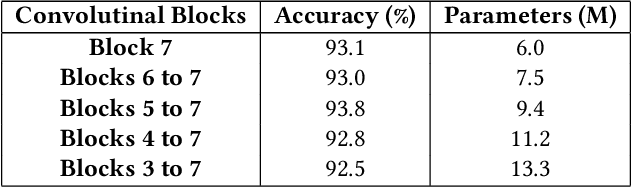

In this paper, we present a robust and low complexity deep learning model for Remote Sensing Image Classification (RSIC), the task of identifying the scene of a remote sensing image. In particular, we firstly evaluate different low complexity and benchmark deep neural networks: MobileNetV1, MobileNetV2, NASNetMobile, and EfficientNetB0, which present the number of trainable parameters lower than 5 Million (M). After indicating best network architecture, we further improve the network performance by applying attention schemes to multiple feature maps extracted from middle layers of the network. To deal with the issue of increasing the model footprint as using attention schemes, we apply the quantization technique to satisfies the number trainable parameter of the model lower than 5 M. By conducting extensive experiments on the benchmark datasets NWPU-RESISC45, we achieve a robust and low-complexity model, which is very competitive to the state-of-the-art systems and potential for real-life applications on edge devices.
MoVQ: Modulating Quantized Vectors for High-Fidelity Image Generation
Sep 19, 2022
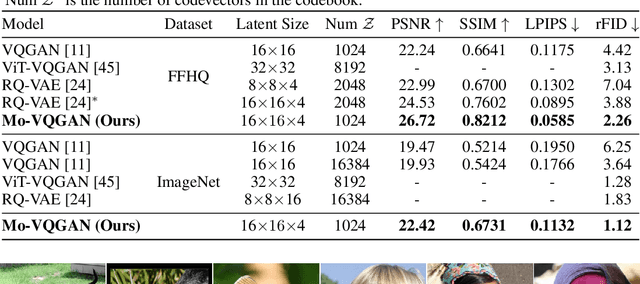
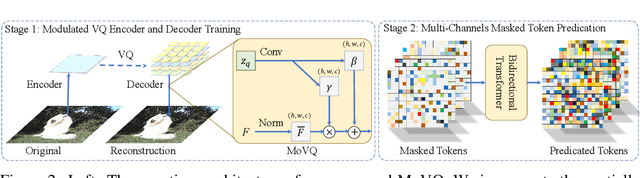
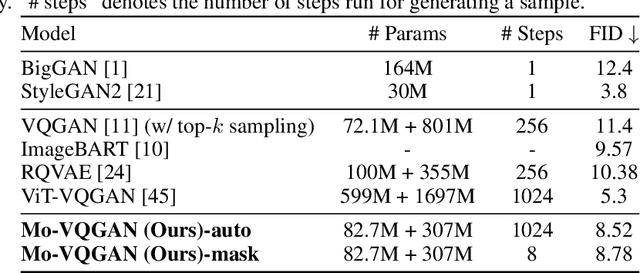
Although two-stage Vector Quantized (VQ) generative models allow for synthesizing high-fidelity and high-resolution images, their quantization operator encodes similar patches within an image into the same index, resulting in a repeated artifact for similar adjacent regions using existing decoder architectures. To address this issue, we propose to incorporate the spatially conditional normalization to modulate the quantized vectors so as to insert spatially variant information to the embedded index maps, encouraging the decoder to generate more photorealistic images. Moreover, we use multichannel quantization to increase the recombination capability of the discrete codes without increasing the cost of model and codebook. Additionally, to generate discrete tokens at the second stage, we adopt a Masked Generative Image Transformer (MaskGIT) to learn an underlying prior distribution in the compressed latent space, which is much faster than the conventional autoregressive model. Experiments on two benchmark datasets demonstrate that our proposed modulated VQGAN is able to greatly improve the reconstructed image quality as well as provide high-fidelity image generation.
A Plot is Worth a Thousand Words: Model Information Stealing Attacks via Scientific Plots
Feb 23, 2023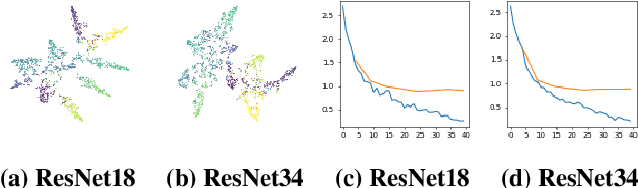
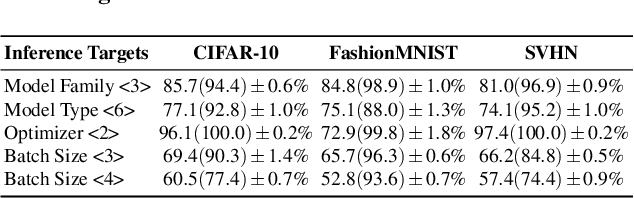

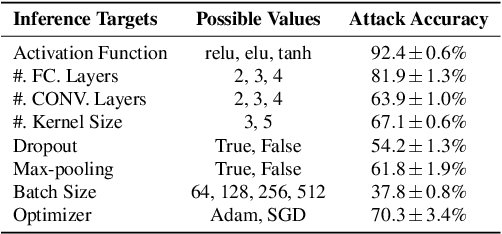
Building advanced machine learning (ML) models requires expert knowledge and many trials to discover the best architecture and hyperparameter settings. Previous work demonstrates that model information can be leveraged to assist other attacks, such as membership inference, generating adversarial examples. Therefore, such information, e.g., hyperparameters, should be kept confidential. It is well known that an adversary can leverage a target ML model's output to steal the model's information. In this paper, we discover a new side channel for model information stealing attacks, i.e., models' scientific plots which are extensively used to demonstrate model performance and are easily accessible. Our attack is simple and straightforward. We leverage the shadow model training techniques to generate training data for the attack model which is essentially an image classifier. Extensive evaluation on three benchmark datasets shows that our proposed attack can effectively infer the architecture/hyperparameters of image classifiers based on convolutional neural network (CNN) given the scientific plot generated from it. We also reveal that the attack's success is mainly caused by the shape of the scientific plots, and further demonstrate that the attacks are robust in various scenarios. Given the simplicity and effectiveness of the attack method, our study indicates scientific plots indeed constitute a valid side channel for model information stealing attacks. To mitigate the attacks, we propose several defense mechanisms that can reduce the original attacks' accuracy while maintaining the plot utility. However, such defenses can still be bypassed by adaptive attacks.
Towards Universal Vision-language Omni-supervised Segmentation
Mar 12, 2023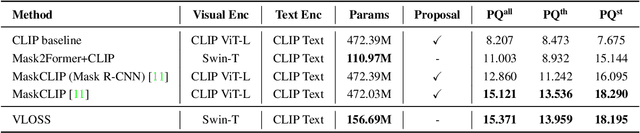
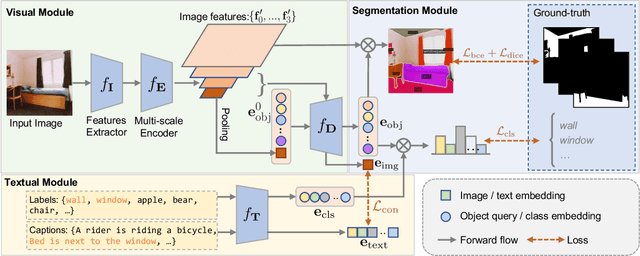
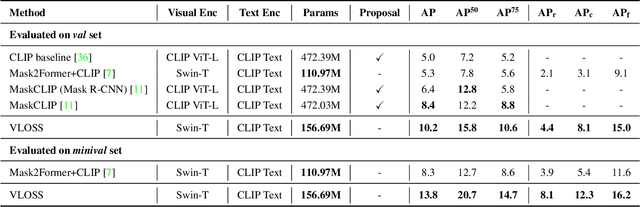
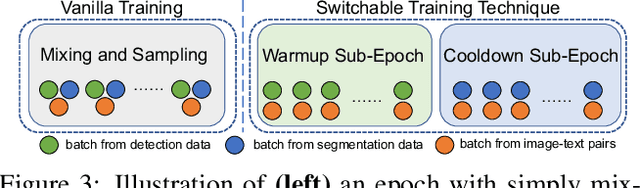
Existing open-world universal segmentation approaches usually leverage CLIP and pre-computed proposal masks to treat open-world segmentation tasks as proposal classification. However, 1) these works cannot handle universal segmentation in an end-to-end manner, and 2) the limited scale of panoptic datasets restricts the open-world segmentation ability on things classes. In this paper, we present Vision-Language Omni-Supervised Segmentation (VLOSS). VLOSS starts from a Mask2Former universal segmentation framework with CLIP text encoder. To improve the open-world segmentation ability, we leverage omni-supervised data (i.e., panoptic segmentation data, object detection data, and image-text pairs data) into training, thus enriching the open-world segmentation ability and achieving better segmentation accuracy. To better improve the training efficiency and fully release the power of omni-supervised data, we propose several advanced techniques, i.e., FPN-style encoder, switchable training technique, and positive classification loss. Benefiting from the end-to-end training manner with proposed techniques, VLOSS can be applied to various open-world segmentation tasks without further adaptation. Experimental results on different open-world panoptic and instance segmentation benchmarks demonstrate the effectiveness of VLOSS. Notably, with fewer parameters, our VLOSS with Swin-Tiny backbone surpasses MaskCLIP by ~2% in terms of mask AP on LVIS v1 dataset.
RotoGBML: Towards Out-of-Distribution Generalization for Gradient-Based Meta-Learning
Mar 12, 2023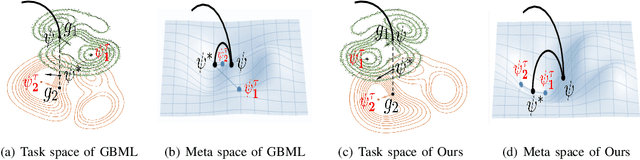
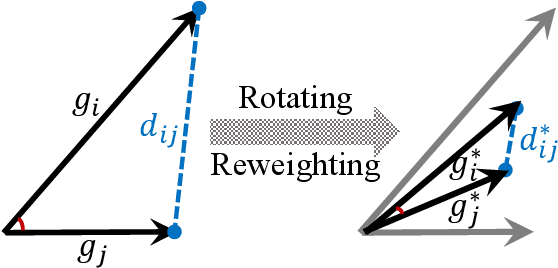
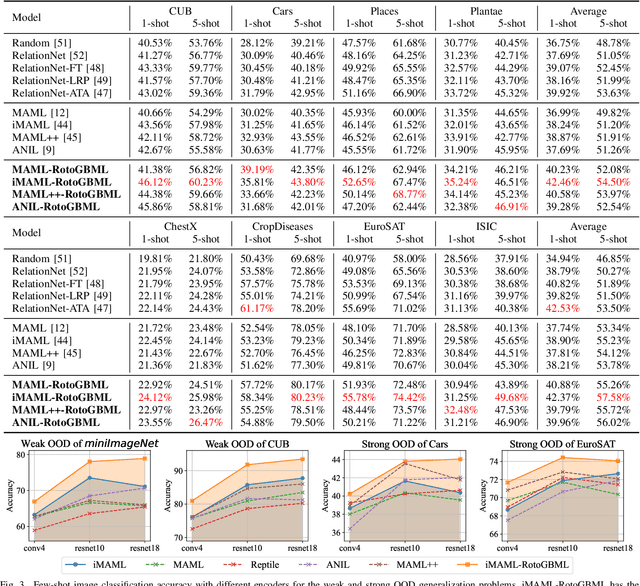
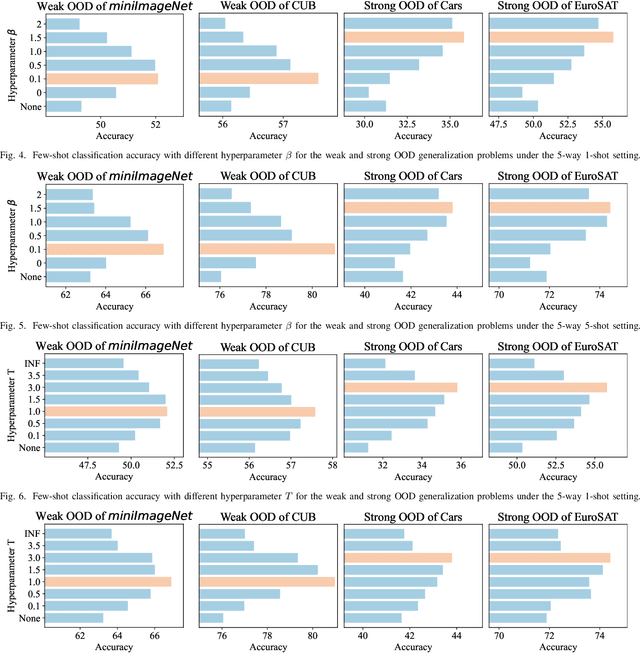
Gradient-based meta-learning (GBML) algorithms are able to fast adapt to new tasks by transferring the learned meta-knowledge, while assuming that all tasks come from the same distribution (in-distribution, ID). However, in the real world, they often suffer from an out-of-distribution (OOD) generalization problem, where tasks come from different distributions. OOD exacerbates inconsistencies in magnitudes and directions of task gradients, which brings challenges for GBML to optimize the meta-knowledge by minimizing the sum of task gradients in each minibatch. To address this problem, we propose RotoGBML, a novel approach to homogenize OOD task gradients. RotoGBML uses reweighted vectors to dynamically balance diverse magnitudes to a common scale and uses rotation matrixes to rotate conflicting directions close to each other. To reduce overhead, we homogenize gradients with the features rather than the network parameters. On this basis, to avoid the intervention of non-causal features (e.g., backgrounds), we also propose an invariant self-information (ISI) module to extract invariant causal features (e.g., the outlines of objects). Finally, task gradients are homogenized based on these invariant causal features. Experiments show that RotoGBML outperforms other state-of-the-art methods on various few-shot image classification benchmarks.
SAR-UNet: Small Attention Residual UNet for Explainable Nowcasting Tasks
Mar 12, 2023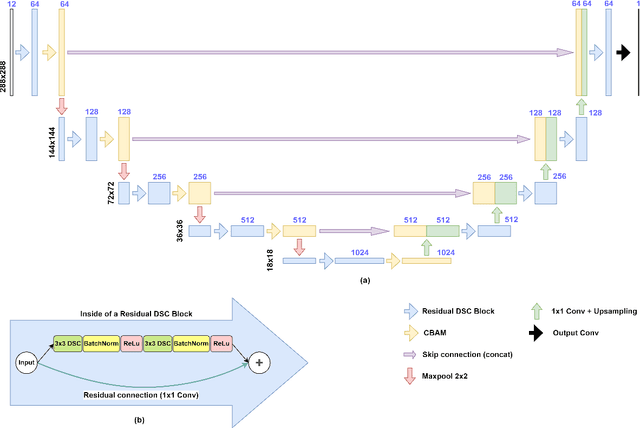
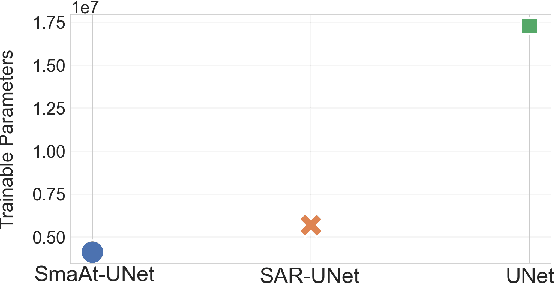
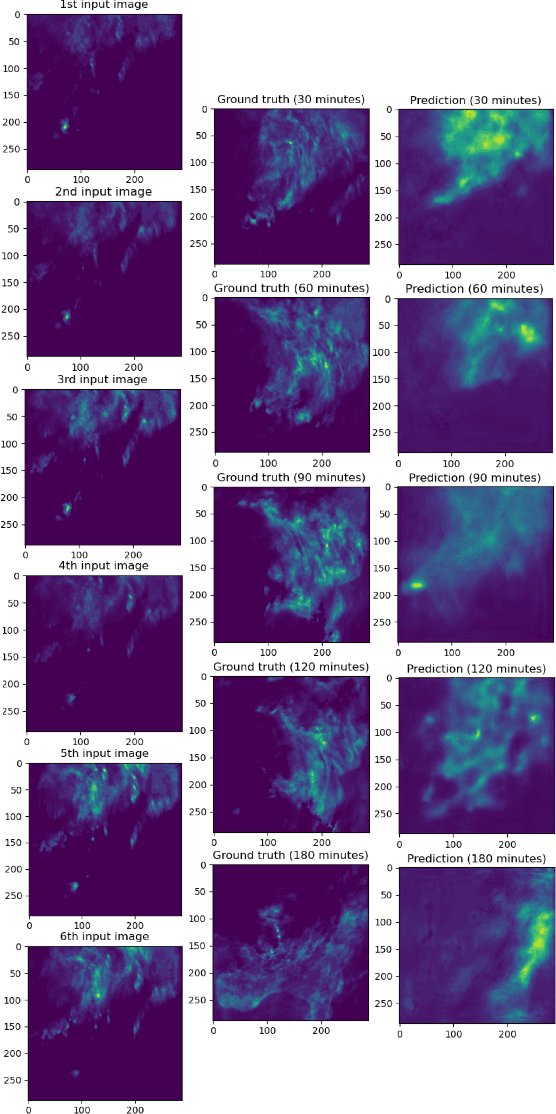
The accuracy and explainability of data-driven nowcasting models are of great importance in many socio-economic sectors reliant on weather-dependent decision making. This paper proposes a novel architecture called Small Attention Residual UNet (SAR-UNet) for precipitation and cloud cover nowcasting. Here, SmaAt-UNet is used as a core model and is further equipped with residual connections, parallel to the depthwise separable convolutions. The proposed SAR-UNet model is evaluated on two datasets, i.e., Dutch precipitation maps ranging from 2016 to 2019 and French cloud cover binary images from 2017 to 2018. The obtained results show that SAR-UNet outperforms other examined models in precipitation nowcasting from 30 to 180 minutes in the future as well as cloud cover nowcasting in the next 90 minutes. Furthermore, we provide additional insights on the nowcasts made by our proposed model using Grad-CAM, a visual explanation technique, which is employed on different levels of the encoder and decoder paths of the SAR-UNet model and produces heatmaps highlighting the critical regions in the input image as well as intermediate representations to the precipitation. The heatmaps generated by Grad-CAM reveal the interactions between the residual connections and the depthwise separable convolutions inside of the multiple depthwise separable blocks placed throughout the network architecture.
Automated Ventricle Parcellation and Evan's Ratio Computation in Pre- and Post-Surgical Ventriculomegaly
Mar 06, 2023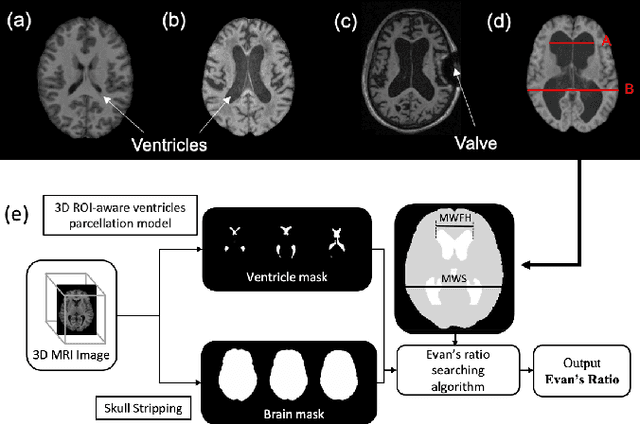
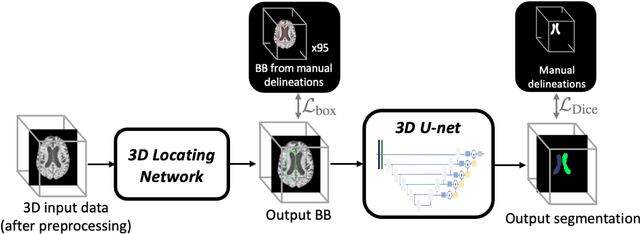
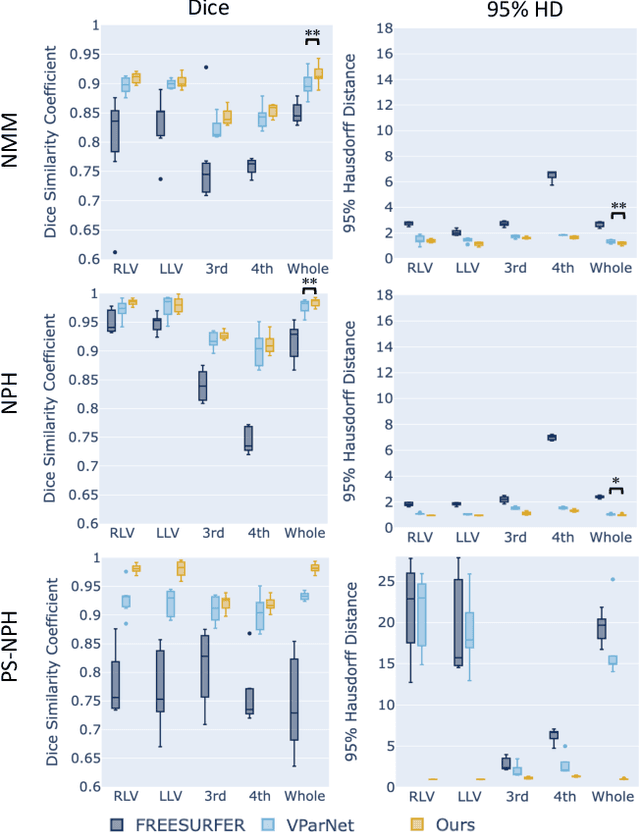
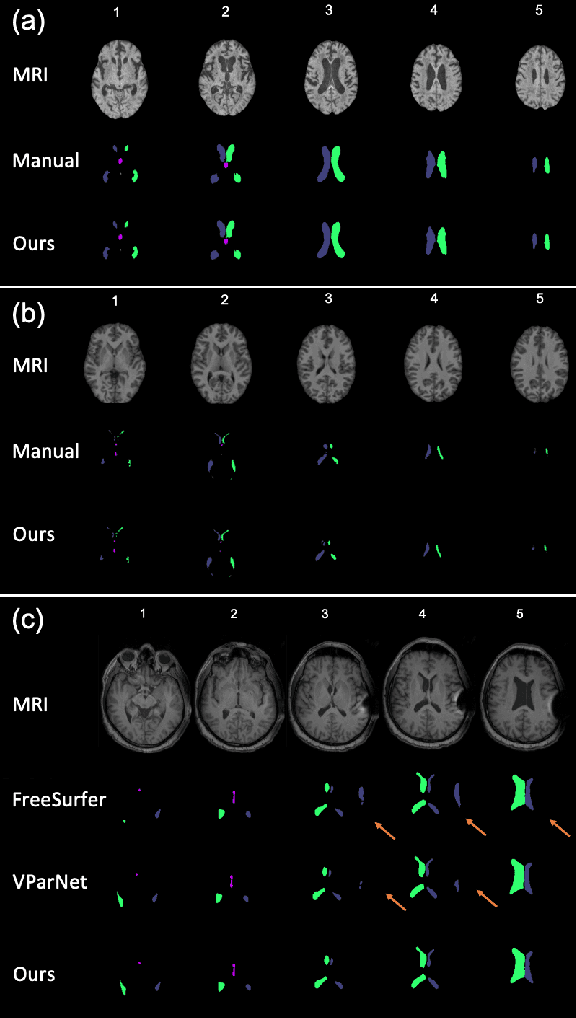
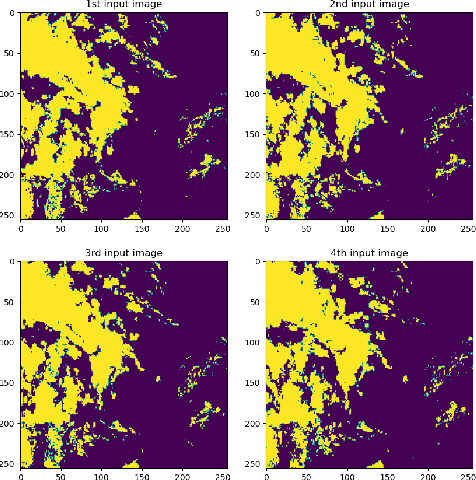
Normal pressure hydrocephalus~(NPH) is a brain disorder associated with enlarged ventricles and multiple cognitive and motor symptoms. The degree of ventricular enlargement can be measured using magnetic resonance images~(MRIs) and characterized quantitatively using the Evan's ratio (ER). Automatic computation of ER is desired to avoid the extra time and variations associated with manual measurements on MRI. Because shunt surgery is often used to treat NPH, it is necessary that this process be robust to image artifacts caused by the shunt and related implants. In this paper, we propose a 3D regions-of-interest aware (ROI-aware) network for segmenting the ventricles. The method achieves state-of-the-art performance on both pre-surgery MRIs and post-surgery MRIs with artifacts. Based on our segmentation results, we also describe an automated approach to compute ER from these results. Experimental results on multiple datasets demonstrate the potential of the proposed method to assist clinicians in the diagnosis and management of NPH.
Structured Kernel Estimation for Photon-Limited Deconvolution
Mar 06, 2023
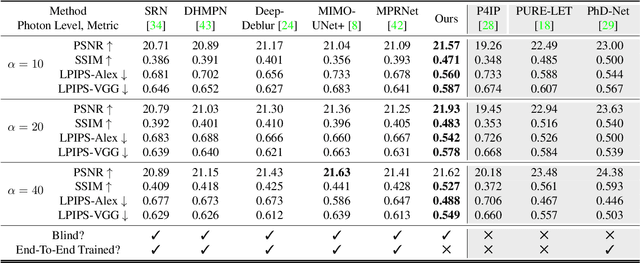
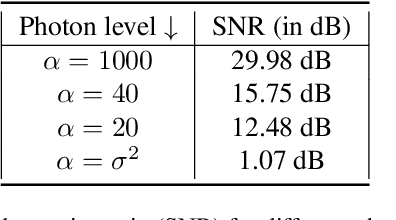

Images taken in a low light condition with the presence of camera shake suffer from motion blur and photon shot noise. While state-of-the-art image restoration networks show promising results, they are largely limited to well-illuminated scenes and their performance drops significantly when photon shot noise is strong. In this paper, we propose a new blur estimation technique customized for photon-limited conditions. The proposed method employs a gradient-based backpropagation method to estimate the blur kernel. By modeling the blur kernel using a low-dimensional representation with the key points on the motion trajectory, we significantly reduce the search space and improve the regularity of the kernel estimation problem. When plugged into an iterative framework, our novel low-dimensional representation provides improved kernel estimates and hence significantly better deconvolution performance when compared to end-to-end trained neural networks. The source code and pretrained models are available at \url{https://github.com/sanghviyashiitb/structured-kernel-cvpr23}
Advance quantum image representation and compression using DCTEFRQI approach
Aug 30, 2022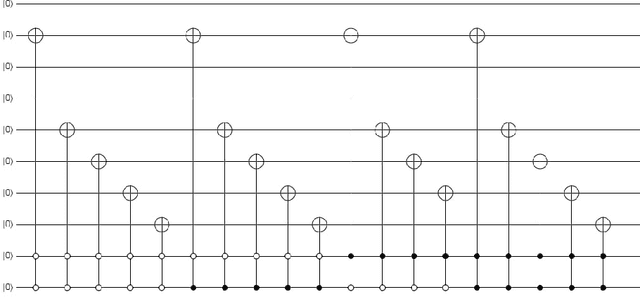
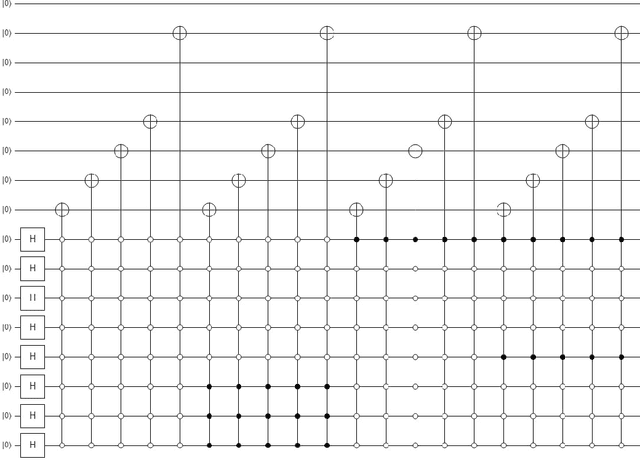
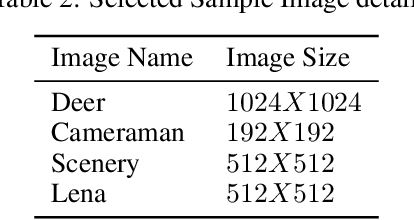
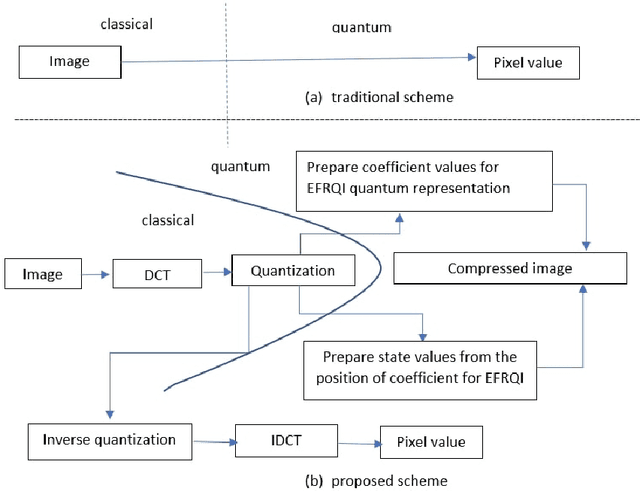
In recent year, quantum image processing got a lot of attention in the field of image processing due to opportunity to place huge image data in quantum Hilbert space. Hilbert space or Euclidean space has infinite dimension to locate and process the image data faster. Moreover, several researches show that, the computational time of quantum process is faster than classical computer. By encoding and compressing the image in quantum domain is still challenging issue. From literature survey, we have proposed a DCTEFRQI (Direct Cosine Transform Efficient Flexible Representation of Quantum Image) algorithm to represent and compress gray image efficiently which save computational time and minimize the complexity of preparation. The objective of this work is to represent and compress various gray image size in quantum computer using DCT(Discrete Cosine Transform) and EFRQI (Efficient Flexible Representation of Quantum Image) approach together. Quirk simulation tool is used to design corresponding quantum image circuit. Due to limitation of qubit, total 16 numbers of qubit are used to represent the gray scale image among those 8 are used to map the coefficient values and the rest 8 are used to generate the corresponding coefficient position. Theoretical analysis and experimental result show that, proposed DCTEFRQI scheme provides better representation and compression compare to DCT-GQIR, DWT-GQIR and DWT-EFRQI in terms of PSNR(Peak Signal to Noise Ratio) and bit rate..