 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HCGMNET: A Hierarchical Change Guiding Map Network For Change Detection
Feb 21, 2023
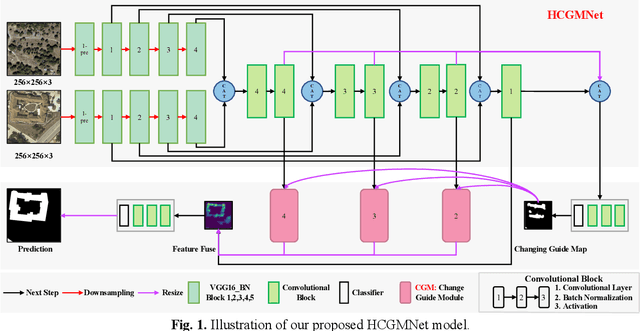
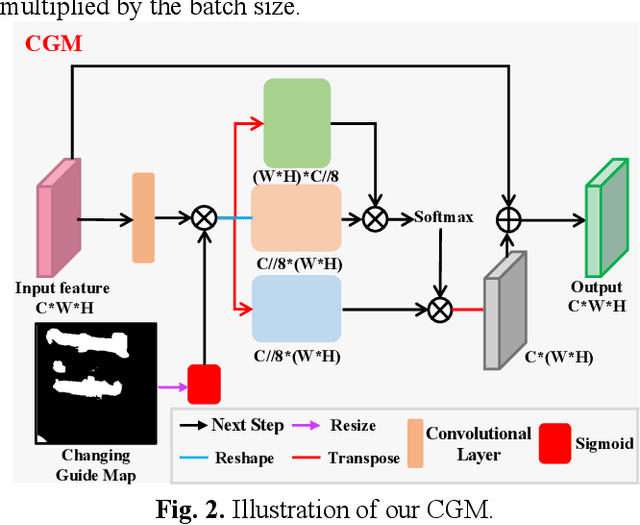

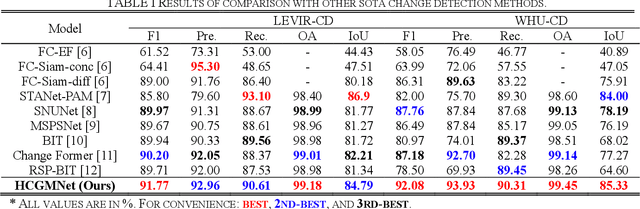
Very-high-resolution (VHR) remote sensing (RS) image change detection (CD) has been a challenging task for its very rich spatial information and sample imbalance problem. In this paper, we have proposed a hierarchical change guiding map network (HCGMNet) for change detection. The model uses hierarchical convolution operations to extract multiscale features, continuously merges multi-scale features layer by layer to improve the expression of global and local information, and guides the model to gradually refine edge features and comprehensive performance by a change guide module (CGM), which is a self-attention with changing guide map. Extensive experiments on two CD datasets show that the proposed HCGMNet architecture achieves better CD performance than existing state-of-the-art (SOTA) CD methods.
MVImgNet: A Large-scale Dataset of Multi-view Images
Mar 10, 2023
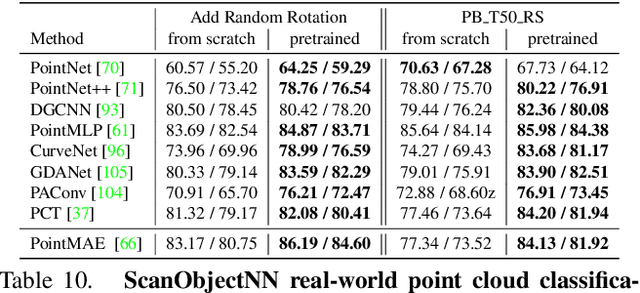
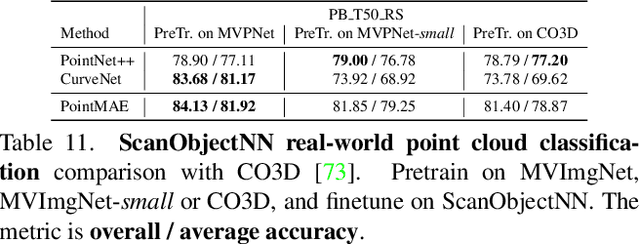

Being data-driven is one of the most iconic properties of deep learning algorithms. The birth of ImageNet drives a remarkable trend of "learning from large-scale data" in computer vision. Pretraining on ImageNet to obtain rich universal representations has been manifested to benefit various 2D visual tasks, and becomes a standard in 2D vision. However, due to the laborious collection of real-world 3D data, there is yet no generic dataset serving as a counterpart of ImageNet in 3D vision, thus how such a dataset can impact the 3D community is unraveled. To remedy this defect, we introduce MVImgNet, a large-scale dataset of multi-view images, which is highly convenient to gain by shooting videos of real-world objects in human daily life. It contains 6.5 million frames from 219,188 videos crossing objects from 238 classes, with rich annotations of object masks, camera parameters, and point clouds. The multi-view attribute endows our dataset with 3D-aware signals, making it a soft bridge between 2D and 3D vision. We conduct pilot studies for probing the potential of MVImgNet on a variety of 3D and 2D visual tasks, including radiance field reconstruction, multi-view stereo, and view-consistent image understanding, where MVImgNet demonstrates promising performance, remaining lots of possibilities for future explorations. Besides, via dense reconstruction on MVImgNet, a 3D object point cloud dataset is derived, called MVPNet, covering 87,200 samples from 150 categories, with the class label on each point cloud. Experiments show that MVPNet can benefit the real-world 3D object classification while posing new challenges to point cloud understanding. MVImgNet and MVPNet will be publicly available, hoping to inspire the broader vision community.
Quantification of cervical elasticity during pregnancy based on transvaginal ultrasound imaging and stress measurement
Mar 10, 2023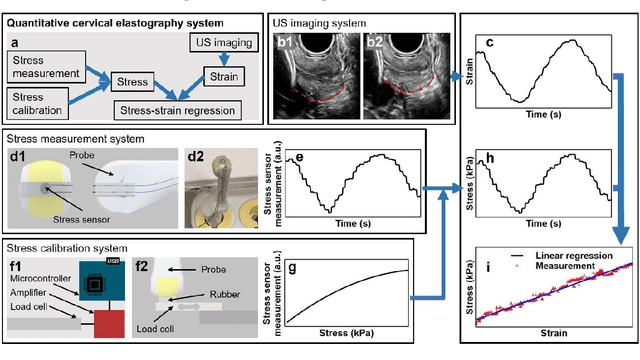

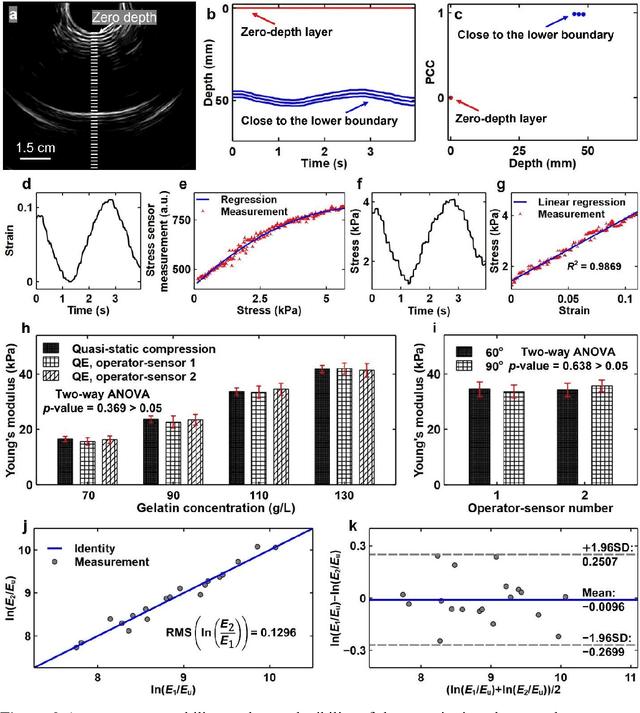
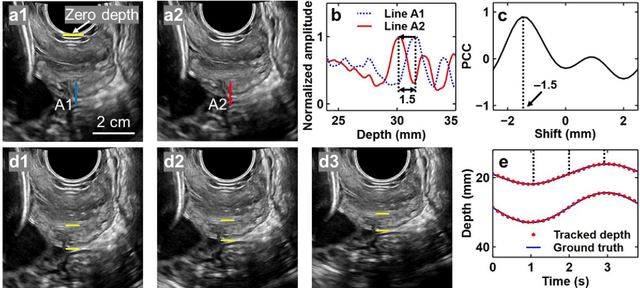
Objective: Strain elastography and shear wave elastography are two commonly used methods to quantify cervical elasticity; however, they have limitations. Strain elastography is effective in showing tissue elasticity distribution in a single image, but the absence of stress information causes difficulty in comparing the results acquired from different imaging sessions. Shear wave elastography is effective in measuring shear wave speed (an intrinsic tissue property correlated with elasticity) in relatively homogeneous tissue, such as in the liver. However, for inhomogeneous tissue in the cervix, the shear wave speed measurement is less robust. To overcome these limitations, we develop a quantitative cervical elastography system by adding a stress sensor to an ultrasound imaging system. Methods: In an imaging session for quantitative cervical elastography, we use the transvaginal ultrasound imaging system to record B-mode images of the cervix showing its deformation and use the stress sensor to record the probe-surface stress simultaneously. We develop a correlation-based automatic feature tracking algorithm to quantify the deformation, from which the strain is quantified. After each imaging session, we calibrate the stress sensor and transform its measurement to true stress. Applying a linear regression to the stress and strain, we obtain an approximation of the cervical Young's modulus. Results: We validate the accuracy and robustness of this elastography system using phantom experiments. Applying this system to pregnant participants, we observe significant softening of the cervix during pregnancy (p-value < 0.001) with the cervical Young's modulus decreasing 3.95% per week. We estimate that geometric mean values of cervical Young's moduli during the first (11 to 13 weeks), second, and third trimesters are 13.07 kPa, 7.59 kPa, and 4.40 kPa, respectively.
DAVIS-Ag: A Synthetic Plant Dataset for Developing Domain-Inspired Active Vision in Agricultural Robots
Mar 10, 2023
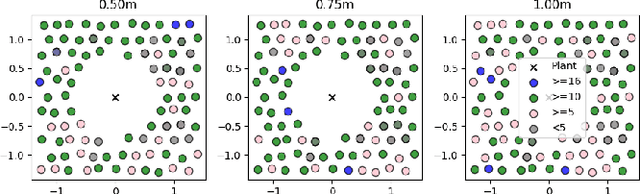

In agricultural environments, viewpoint planning can be a critical functionality for a robot with visual sensors to obtain informative observations of objects of interest (e.g., fruits) from complex structures of plant with random occlusions. Although recent studies on active vision have shown some potential for agricultural tasks, each model has been designed and validated on a unique environment that would not easily be replicated for benchmarking novel methods being developed later. In this paper, hence, we introduce a dataset for more extensive research on Domain-inspired Active VISion in Agriculture (DAVIS-Ag). To be specific, we utilized our open-source "AgML" framework and the 3D plant simulator of "Helios" to produce 502K RGB images from 30K dense spatial locations in 632 realistically synthesized orchards of strawberries, tomatoes, and grapes. In addition, useful labels are provided for each image, including (1) bounding boxes and (2) pixel-wise instance segmentations for all identifiable fruits, and also (3) pointers to other images that are reachable by an execution of action so as to simulate the active selection of viewpoint at each time step. Using DAVIS-Ag, we show the motivating examples in which performance of fruit detection for the same plant can significantly vary depending on the position and orientation of camera view primarily due to occlusions by other components such as leaves. Furthermore, we develop several baseline models to showcase the "usage" of data with one of agricultural active vision tasks--fruit search optimization--providing evaluation results against which future studies could benchmark their methodologies. For encouraging relevant research, our dataset is released online to be freely available at: https://github.com/ctyeong/DAVIS-Ag
Data-Efficient Training of CNNs and Transformers with Coresets: A Stability Perspective
Mar 10, 2023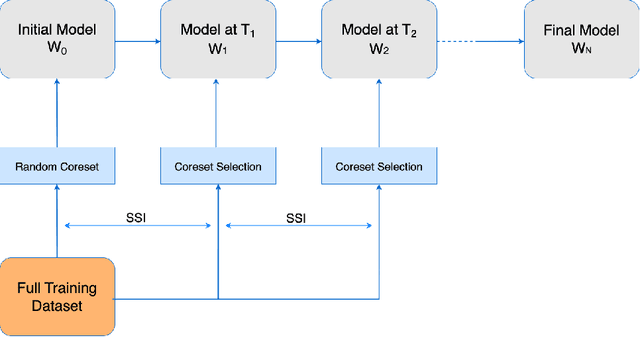

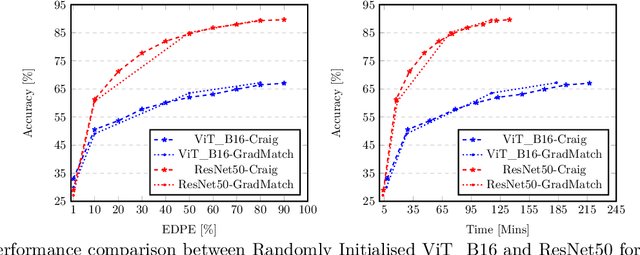
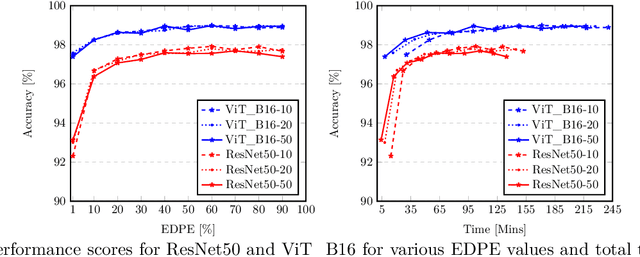
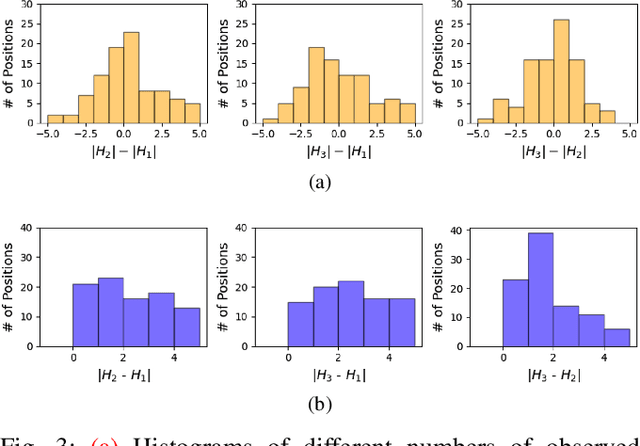
Coreset selection is among the most effective ways to reduce the training time of CNNs, however, only limited is known on how the resultant models will behave under variations of the coreset size, and choice of datasets and models. Moreover, given the recent paradigm shift towards transformer-based models, it is still an open question how coreset selection would impact their performance. There are several similar intriguing questions that need to be answered for a wide acceptance of coreset selection methods, and this paper attempts to answer some of these. We present a systematic benchmarking setup and perform a rigorous comparison of different coreset selection methods on CNNs and transformers. Our investigation reveals that under certain circumstances, random selection of subsets is more robust and stable when compared with the SOTA selection methods. We demonstrate that the conventional concept of uniform subset sampling across the various classes of the data is not the appropriate choice. Rather samples should be adaptively chosen based on the complexity of the data distribution for each class. Transformers are generally pretrained on large datasets, and we show that for certain target datasets, it helps to keep their performance stable at even very small coreset sizes. We further show that when no pretraining is done or when the pretrained transformer models are used with non-natural images (e.g. medical data), CNNs tend to generalize better than transformers at even very small coreset sizes. Lastly, we demonstrate that in the absence of the right pretraining, CNNs are better at learning the semantic coherence between spatially distant objects within an image, and these tend to outperform transformers at almost all choices of the coreset size.
DisPositioNet: Disentangled Pose and Identity in Semantic Image Manipulation
Nov 10, 2022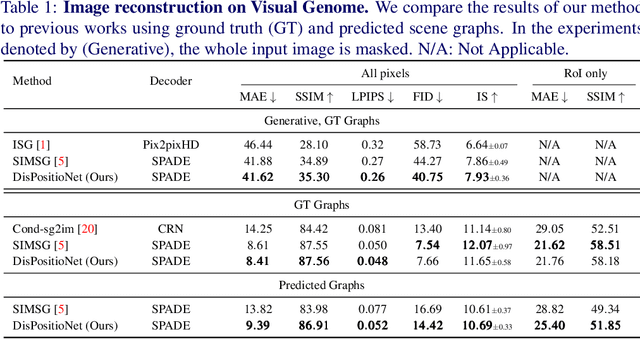
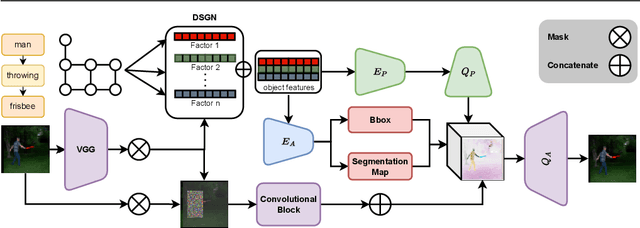
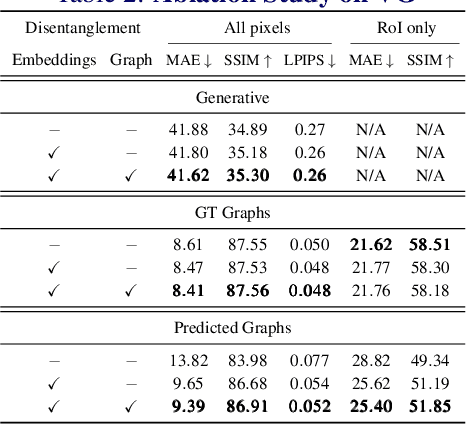
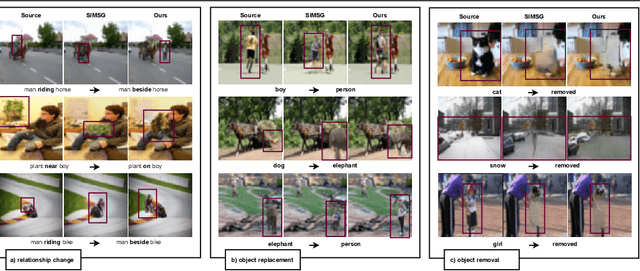
Graph representation of objects and their relations in a scene, known as a scene graph, provides a precise and discernible interface to manipulate a scene by modifying the nodes or the edges in the graph. Although existing works have shown promising results in modifying the placement and pose of objects, scene manipulation often leads to losing some visual characteristics like the appearance or identity of objects. In this work, we propose DisPositioNet, a model that learns a disentangled representation for each object for the task of image manipulation using scene graphs in a self-supervised manner. Our framework enables the disentanglement of the variational latent embeddings as well as the feature representation in the graph. In addition to producing more realistic images due to the decomposition of features like pose and identity, our method takes advantage of the probabilistic sampling in the intermediate features to generate more diverse images in object replacement or addition tasks. The results of our experiments show that disentangling the feature representations in the latent manifold of the model outperforms the previous works qualitatively and quantitatively on two public benchmarks. Project Page: https://scenegenie.github.io/DispositioNet/
Improving The Reconstruction Quality by Overfitted Decoder Bias in Neural Image Compression
Oct 10, 2022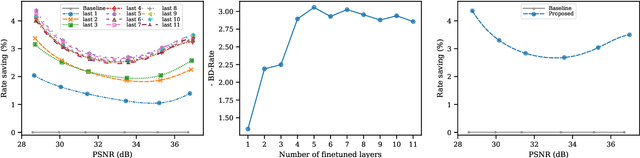
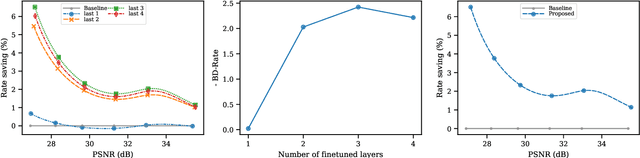
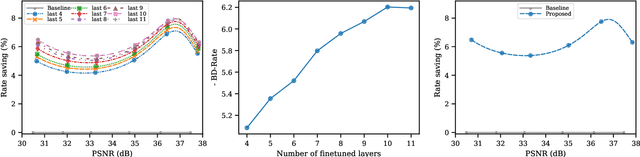
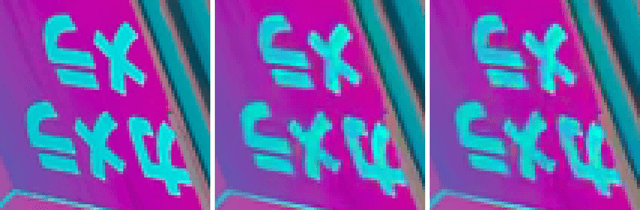
End-to-end trainable models have reached the performance of traditional handcrafted compression techniques on videos and images. Since the parameters of these models are learned over large training sets, they are not optimal for any given image to be compressed. In this paper, we propose an instance-based fine-tuning of a subset of decoder's bias to improve the reconstruction quality in exchange for extra encoding time and minor additional signaling cost. The proposed method is applicable to any end-to-end compression methods, improving the state-of-the-art neural image compression BD-rate by $3-5\%$.
High-Fidelity Image Inpainting with GAN Inversion
Aug 25, 2022
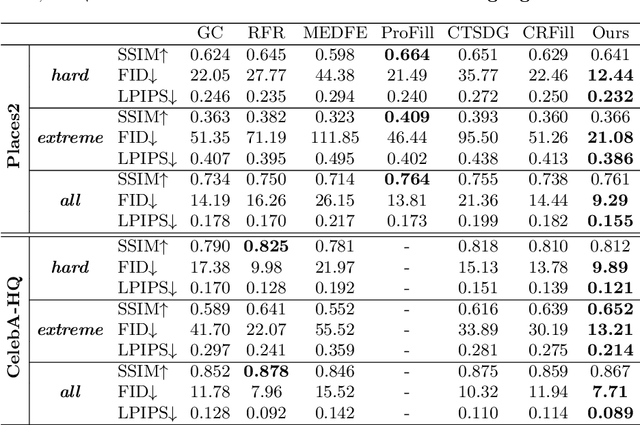
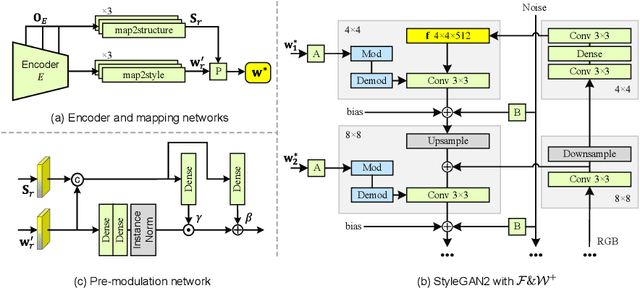
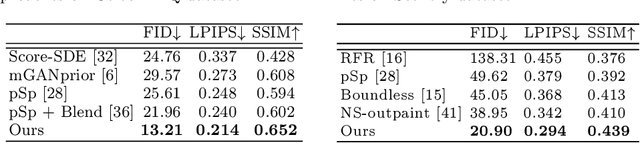
Image inpainting seeks a semantically consistent way to recover the corrupted image in the light of its unmasked content. Previous approaches usually reuse the well-trained GAN as effective prior to generate realistic patches for missing holes with GAN inversion. Nevertheless, the ignorance of a hard constraint in these algorithms may yield the gap between GAN inversion and image inpainting. Addressing this problem, in this paper, we devise a novel GAN inversion model for image inpainting, dubbed InvertFill, mainly consisting of an encoder with a pre-modulation module and a GAN generator with F&W+ latent space. Within the encoder, the pre-modulation network leverages multi-scale structures to encode more discriminative semantics into style vectors. In order to bridge the gap between GAN inversion and image inpainting, F&W+ latent space is proposed to eliminate glaring color discrepancy and semantic inconsistency. To reconstruct faithful and photorealistic images, a simple yet effective Soft-update Mean Latent module is designed to capture more diverse in-domain patterns that synthesize high-fidelity textures for large corruptions. Comprehensive experiments on four challenging datasets, including Places2, CelebA-HQ, MetFaces, and Scenery, demonstrate that our InvertFill outperforms the advanced approaches qualitatively and quantitatively and supports the completion of out-of-domain images well.
An end-to-end SE(3)-equivariant segmentation network
Mar 02, 2023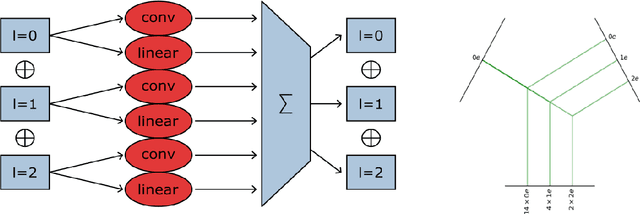


Convolutional neural networks (CNNs) allow for parameter sharing and translational equivariance by using convolutional kernels in their linear layers. By restricting these kernels to be SO(3)-steerable, CNNs can further improve parameter sharing and equivariance. These equivariant convolutional layers have several advantages over standard convolutional layers, including increased robustness to unseen poses, smaller network size, and improved sample efficiency. Despite this, most segmentation networks used in medical image analysis continue to rely on standard convolutional kernels. In this paper, we present a new family of segmentation networks that use equivariant voxel convolutions based on spherical harmonics, as well as equivariant pooling and normalization operations. These SE(3)-equivariant volumetric segmentation networks, which are robust to data poses not seen during training, do not require rotation-based data augmentation during training. In addition, we demonstrate improved segmentation performance in MRI brain tumor and healthy brain structure segmentation tasks, with enhanced robustness to reduced amounts of training data and improved parameter efficiency. Code to reproduce our results, and to implement the equivariant segmentation networks for other tasks is available at http://github.com/SCAN-NRAD/e3nn_Unet
MoSS: Monocular Shape Sensing for Continuum Robots
Mar 02, 2023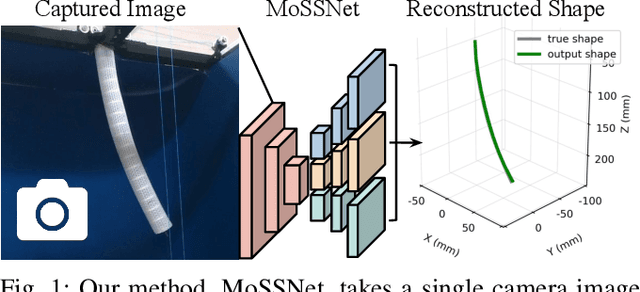
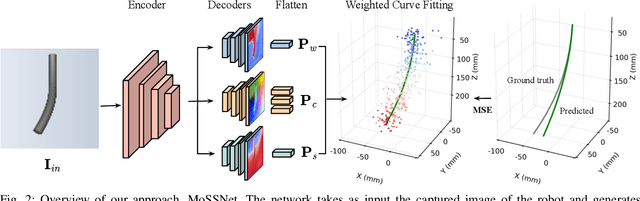

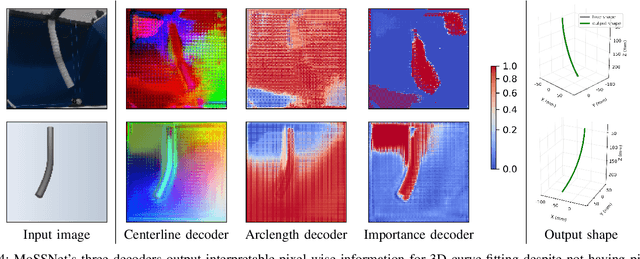
Continuum robots are promising candidates for interactive tasks in various applications due to their unique shape, compliance, and miniaturization capability. Accurate and real-time shape sensing is essential for such tasks yet remains a challenge. Embedded shape sensing has high hardware complexity and cost, while vision-based methods require stereo setup and struggle to achieve real-time performance. This paper proposes the first eye-to-hand monocular approach to continuum robot shape sensing. Utilizing a deep encoder-decoder network, our method, MoSSNet, eliminates the computation cost of stereo matching and reduces requirements on sensing hardware. In particular, MoSSNet comprises an encoder and three parallel decoders to uncover spatial, length, and contour information from a single RGB image, and then obtains the 3D shape through curve fitting. A two-segment tendon-driven continuum robot is used for data collection and testing, demonstrating accurate (mean shape error of 0.91 mm, or 0.36% of robot length) and real-time (70 fps) shape sensing on real-world data. Additionally, the method is optimized end-to-end and does not require fiducial markers, manual segmentation, or camera calibration. Code and datasets will be made available at https://github.com/ContinuumRoboticsLab/MoSSNet.