 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GDIP: Gated Differentiable Image Processing for Object-Detection in Adverse Conditions
Sep 29, 2022
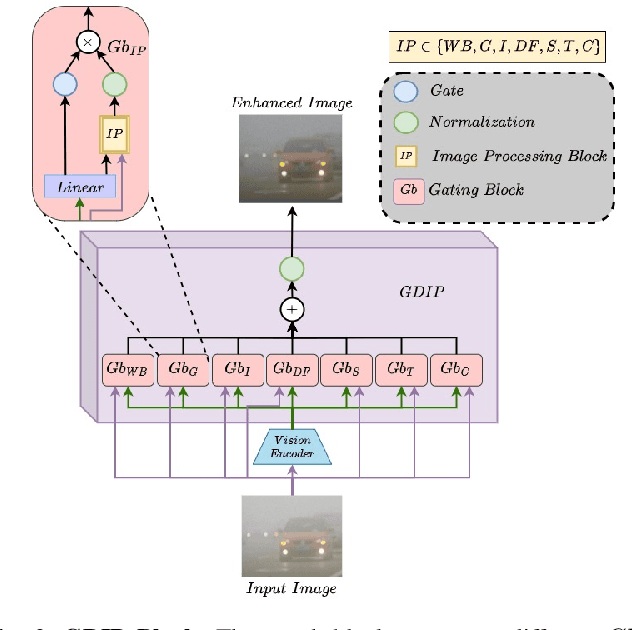
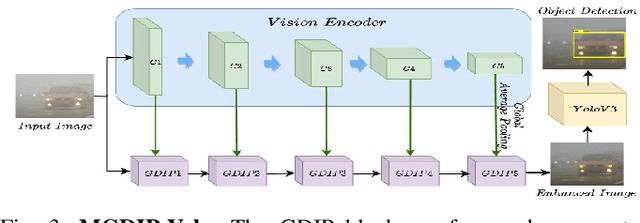
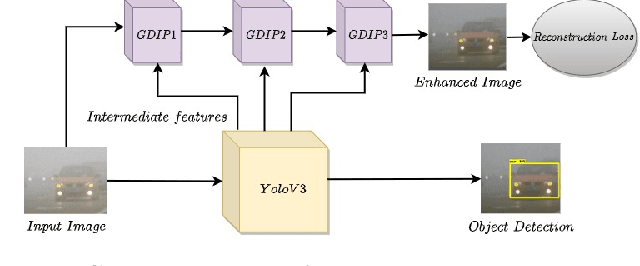
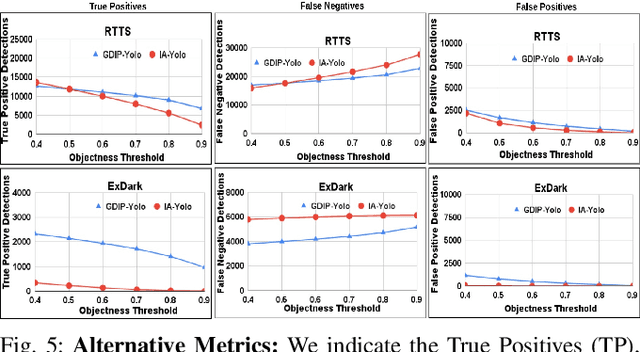
Detecting objects under adverse weather and lighting conditions is crucial for the safe and continuous operation of an autonomous vehicle, and remains an unsolved problem. We present a Gated Differentiable Image Processing (GDIP) block, a domain-agnostic network architecture, which can be plugged into existing object detection networks (e.g., Yolo) and trained end-to-end with adverse condition images such as those captured under fog and low lighting. Our proposed GDIP block learns to enhance images directly through the downstream object detection loss. This is achieved by learning parameters of multiple image pre-processing (IP) techniques that operate concurrently, with their outputs combined using weights learned through a novel gating mechanism. We further improve GDIP through a multi-stage guidance procedure for progressive image enhancement. Finally, trading off accuracy for speed, we propose a variant of GDIP that can be used as a regularizer for training Yolo, which eliminates the need for GDIP-based image enhancement during inference, resulting in higher throughput and plausible real-world deployment. We demonstrate significant improvement in detection performance over several state-of-the-art methods through quantitative and qualitative studies on synthetic datasets such as PascalVOC, and real-world foggy (RTTS) and low-lighting (ExDark) datasets.
A Capsule Network for Hierarchical Multi-Label Image Classification
Sep 13, 2022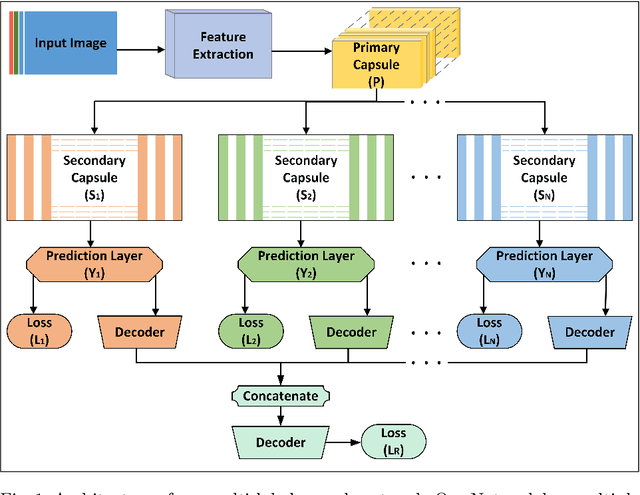
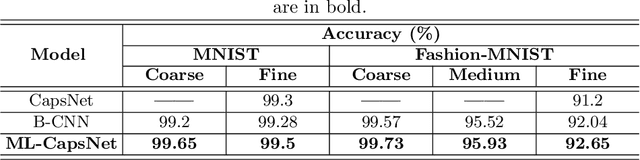
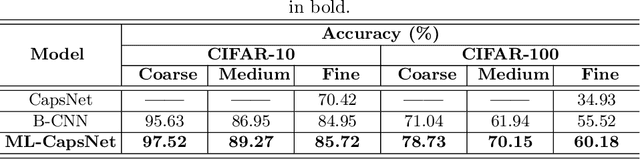
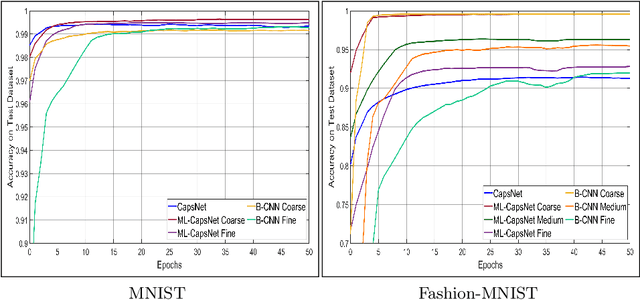
Image classification is one of the most important areas in computer vision. Hierarchical multi-label classification applies when a multi-class image classification problem is arranged into smaller ones based upon a hierarchy or taxonomy. Thus, hierarchical classification modes generally provide multiple class predictions on each instance, whereby these are expected to reflect the structure of image classes as related to one another. In this paper, we propose a multi-label capsule network (ML-CapsNet) for hierarchical classification. Our ML-CapsNet predicts multiple image classes based on a hierarchical class-label tree structure. To this end, we present a loss function that takes into account the multi-label predictions of the network. As a result, the training approach for our ML-CapsNet uses a coarse to fine paradigm while maintaining consistency with the structure in the classification levels in the label-hierarchy. We also perform experiments using widely available datasets and compare the model with alternatives elsewhere in the literature. In our experiments, our ML-CapsNet yields a margin of improvement with respect to these alternative methods.
Representation Learning of Image Schema
Jul 17, 2022
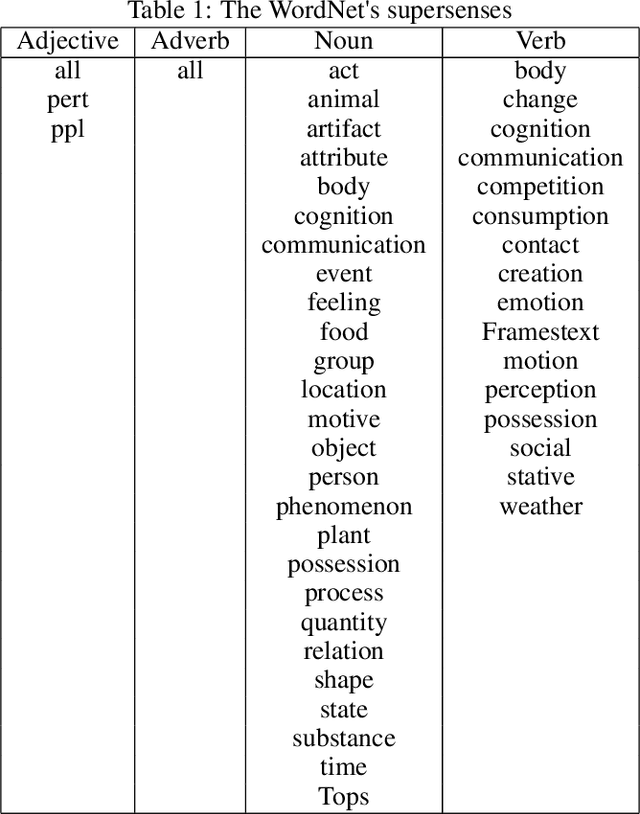
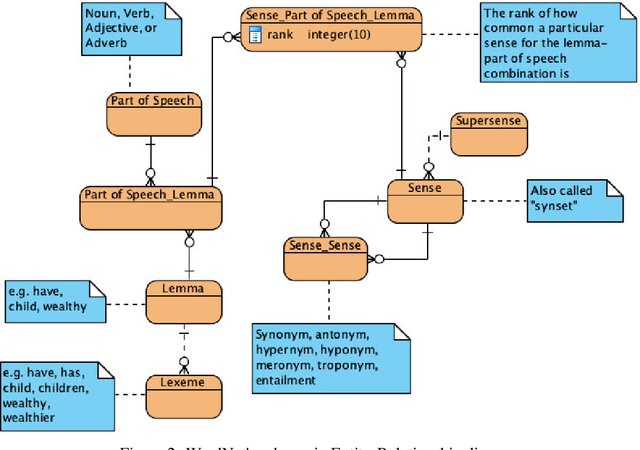
Image schema is a recurrent pattern of reasoning where one entity is mapped into another. Image schema is similar to conceptual metaphor and is also related to metaphoric gesture. Our main goal is to generate metaphoric gestures for an Embodied Conversational Agent. We propose a technique to learn the vector representation of image schemas. As far as we are aware of, this is the first work which addresses that problem. Our technique uses Ravenet et al's algorithm which we use to compute the image schemas from the text input and also BERT and SenseBERT which we use as the base word embedding technique to calculate the final vector representation of the image schema. Our representation learning technique works by clustering: word embedding vectors which belong to the same image schema should be relatively closer to each other, and thus form a cluster. With the image schemas representable as vectors, it also becomes possible to have a notion that some image schemas are closer or more similar to each other than to the others because the distance between the vectors is a proxy of the dissimilarity between the corresponding image schemas. Therefore, after obtaining the vector representation of the image schemas, we calculate the distances between those vectors. Based on these, we create visualizations to illustrate the relative distances between the different image schemas.
Satlas: A Large-Scale, Multi-Task Dataset for Remote Sensing Image Understanding
Nov 28, 2022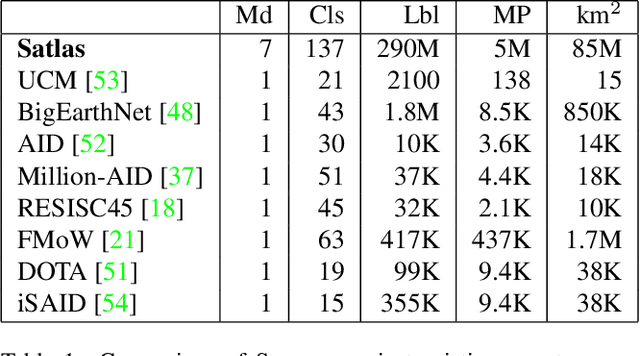

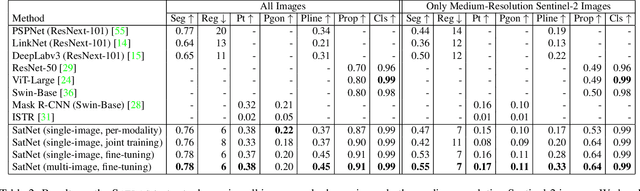
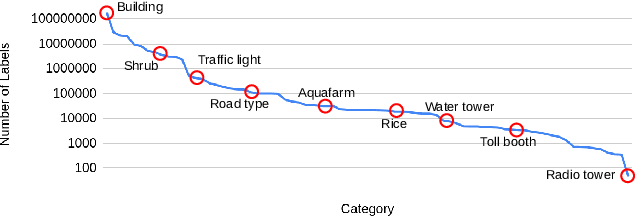
Remote sensing images are useful for a wide variety of environmental and earth monitoring tasks, including tracking deforestation, illegal fishing, urban expansion, and natural disasters. The earth is extremely diverse -- the amount of potential tasks in remote sensing images is massive, and the sizes of features range from several kilometers to just tens of centimeters. However, creating generalizable computer vision methods is a challenge in part due to the lack of a large-scale dataset that captures these diverse features for many tasks. In this paper, we present Satlas, a remote sensing dataset and benchmark that is large in both breadth, featuring all of the aforementioned applications and more, as well as scale, comprising 290M labels under 137 categories and seven label modalities. We evaluate eight baselines and a proposed method on Satlas, and find that there is substantial room for improvement in addressing research challenges specific to remote sensing, including processing image time series that consist of images from very different types of sensors, and taking advantage of long-range spatial context. We also find that pre-training on Satlas substantially improves performance on downstream tasks with few labeled examples, increasing average accuracy by 16% over ImageNet and 5% over the next best baseline.
Dynamic MLP for MRI Reconstruction
Jan 21, 2023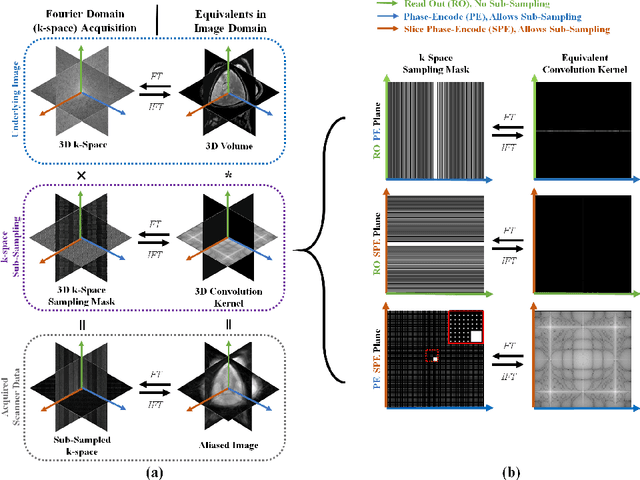
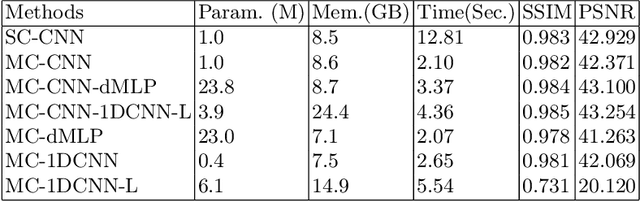
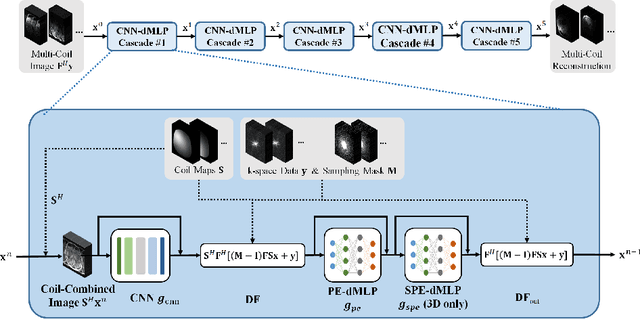
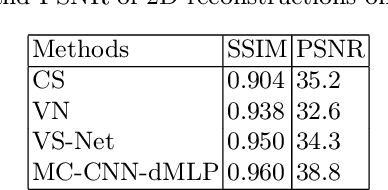
As convolutional neural networks (CNN) become the most successful reconstruction technique for accelerated Magnetic Resonance Imaging (MRI), CNN reaches its limit on image quality especially in sharpness. Further improvement on image quality often comes at massive computational costs, hindering their practicability in the clinic setting. MRI reconstruction is essentially a deconvolution problem, which demands long-distance information that is difficult to be captured by CNNs with small convolution kernels. The multi-layer perceptron (MLP) is able to model such long-distance information, but it restricts a fixed input size while the reconstruction of images in flexible resolutions is required in the clinic setting. In this paper, we proposed a hybrid CNN and MLP reconstruction strategy, featured by dynamic MLP (dMLP) that accepts arbitrary image sizes. Experiments were conducted using 3D multi-coil MRI. Our results suggested the proposed dMLP can improve image sharpness compared to its pure CNN counterpart, while costing minor additional GPU memory and computation time. We further compared the proposed dMLP with CNNs using large kernels and studied pure MLP-based reconstruction using a stack of 1D dMLPs, as well as its CNN counterpart using only 1D convolutions. We observed the enlarged receptive field has noticeably improved image quality, while simply using CNN with a large kernel leads to difficulties in training. Noticeably, the pure MLP-based method has been outperformed by CNN-involved methods, which matches the observations in other computer vision tasks for natural images.
Energy-Aware JPEG Image Compression: A Multi-Objective Approach
Sep 09, 2022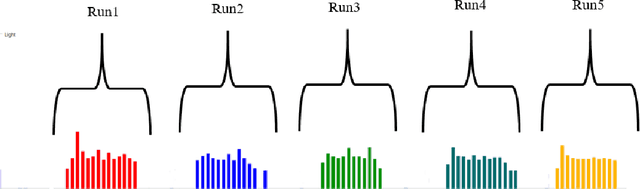
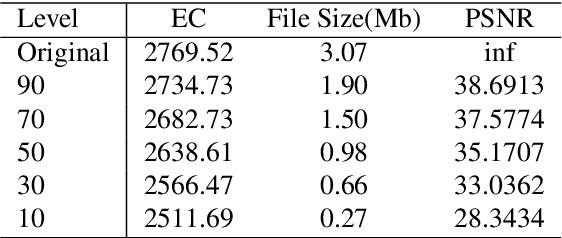
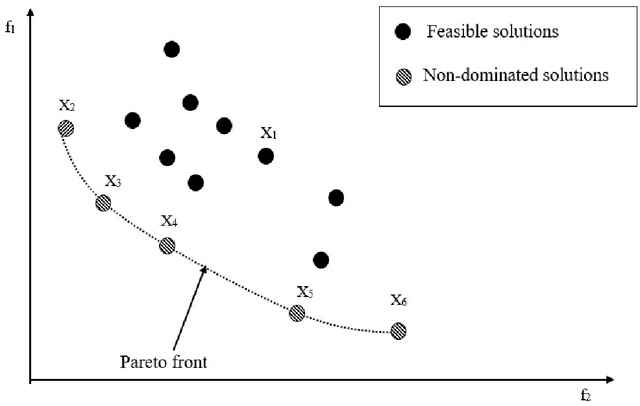
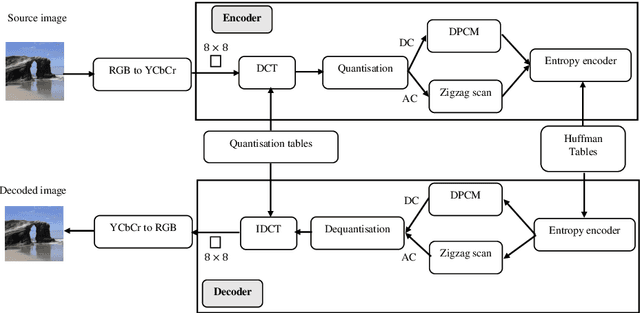
Customer satisfaction is crucially affected by energy consumption in mobile devices. One of the most energy-consuming parts of an application is images. While different images with different quality consume different amounts of energy, there are no straightforward methods to calculate the energy consumption of an operation in a typical image. This paper, first, investigates that there is a correlation between energy consumption and image quality as well as image file size. Therefore, these two can be considered as a proxy for energy consumption. Then, we propose a multi-objective strategy to enhance image quality and reduce image file size based on the quantisation tables in JPEG image compression. To this end, we have used two general multi-objective metaheuristic approaches: scalarisation and Pareto-based. Scalarisation methods find a single optimal solution based on combining different objectives, while Pareto-based techniques aim to achieve a set of solutions. In this paper, we embed our strategy into five scalarisation algorithms, including energy-aware multi-objective genetic algorithm (EnMOGA), energy-aware multi-objective particle swarm optimisation (EnMOPSO), energy-aware multi-objective differential evolution (EnMODE), energy-aware multi-objective evolutionary strategy (EnMOES), and energy-aware multi-objective pattern search (EnMOPS). Also, two Pareto-based methods, including a non-dominated sorting genetic algorithm (NSGA-II) and a reference-point-based NSGA-II (NSGA-III) are used for the embedding scheme, and two Pareto-based algorithms, EnNSGAII and EnNSGAIII, are presented. Experimental studies show that the performance of the baseline algorithm is improved by embedding the proposed strategy into metaheuristic algorithms.
TransAdapt: A Transformative Framework for Online Test Time Adaptive Semantic Segmentation
Feb 24, 2023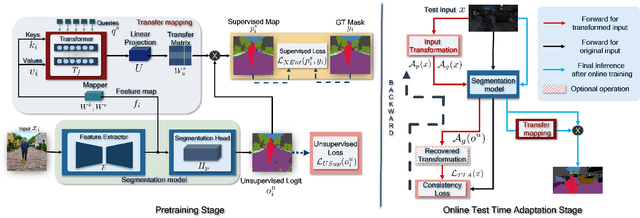

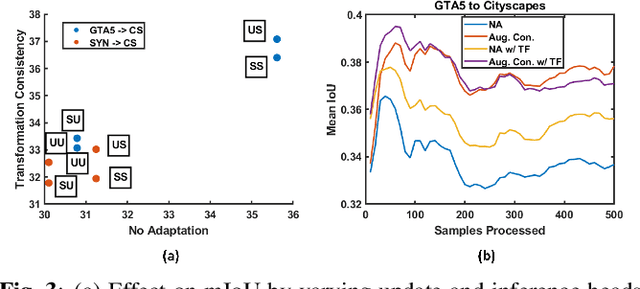
Test-time adaptive (TTA) semantic segmentation adapts a source pre-trained image semantic segmentation model to unlabeled batches of target domain test images, different from real-world, where samples arrive one-by-one in an online fashion. To tackle online settings, we propose TransAdapt, a framework that uses transformer and input transformations to improve segmentation performance. Specifically, we pre-train a transformer-based module on a segmentation network that transforms unsupervised segmentation output to a more reliable supervised output, without requiring test-time online training. To also facilitate test-time adaptation, we propose an unsupervised loss based on the transformed input that enforces the model to be invariant and equivariant to photometric and geometric perturbations, respectively. Overall, our framework produces higher quality segmentation masks with up to 17.6% and 2.8% mIOU improvement over no-adaptation and competitive baselines, respectively.
Progressive Knowledge Distillation: Building Ensembles for Efficient Inference
Feb 20, 2023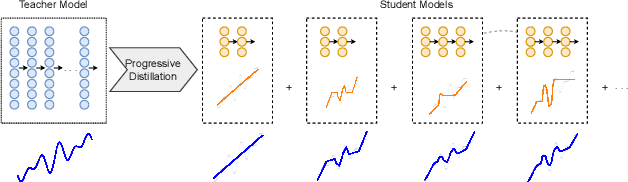
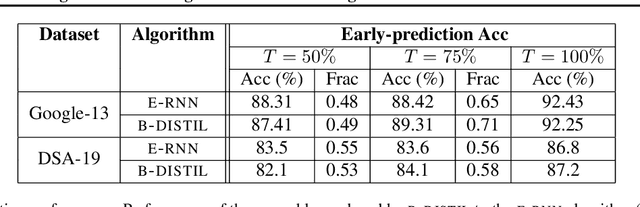
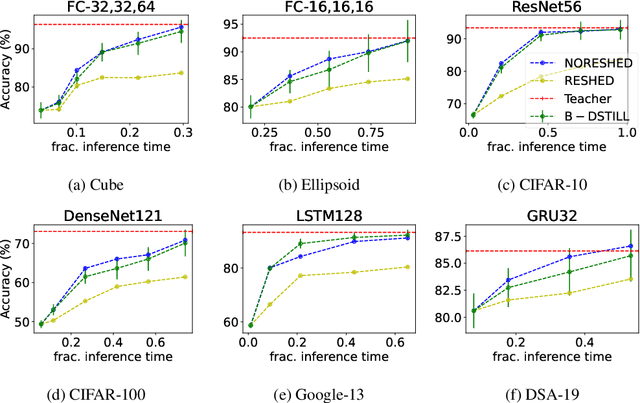
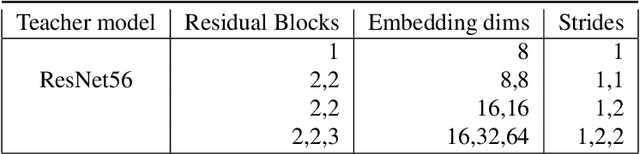
We study the problem of progressive distillation: Given a large, pre-trained teacher model $g$, we seek to decompose the model into an ensemble of smaller, low-inference cost student models $f_i$. The resulting ensemble allows for flexibly tuning accuracy vs. inference cost, which is useful for a number of applications in on-device inference. The method we propose, B-DISTIL, relies on an algorithmic procedure that uses function composition over intermediate activations to construct expressive ensembles with similar performance as $g$, but with much smaller student models. We demonstrate the effectiveness of \algA by decomposing pretrained models across standard image, speech, and sensor datasets. We also provide theoretical guarantees for our method in terms of convergence and generalization.
Memory-Driven Text-to-Image Generation
Aug 15, 2022
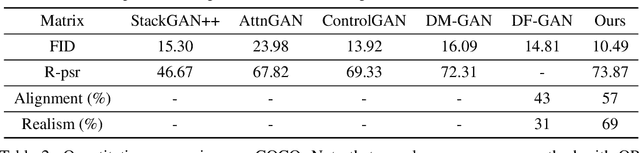

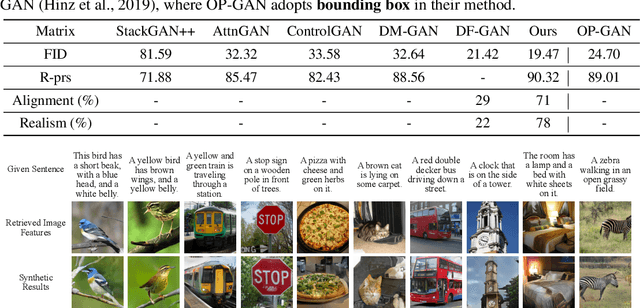
We introduce a memory-driven semi-parametric approach to text-to-image generation, which is based on both parametric and non-parametric techniques. The non-parametric component is a memory bank of image features constructed from a training set of images. The parametric component is a generative adversarial network. Given a new text description at inference time, the memory bank is used to selectively retrieve image features that are provided as basic information of target images, which enables the generator to produce realistic synthetic results. We also incorporate the content information into the discriminator, together with semantic features, allowing the discriminator to make a more reliable prediction. Experimental results demonstrate that the proposed memory-driven semi-parametric approach produces more realistic images than purely parametric approaches, in terms of both visual fidelity and text-image semantic consistency.
CGAN-ECT: Tomography Image Reconstruction from Electrical Capacitance Measurements Using CGANs
Sep 12, 2022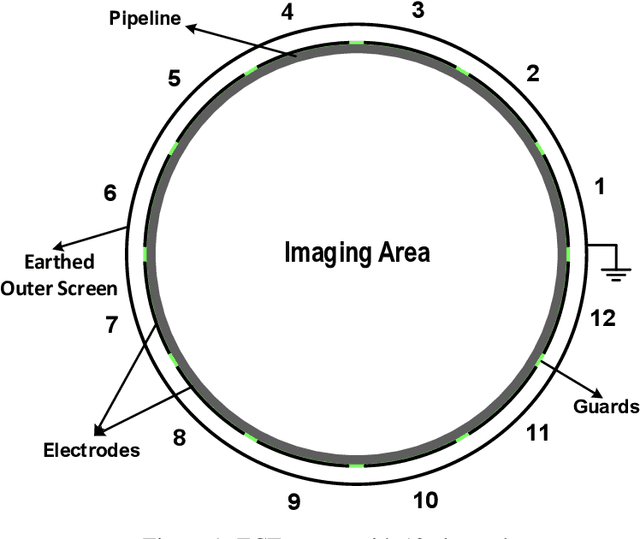
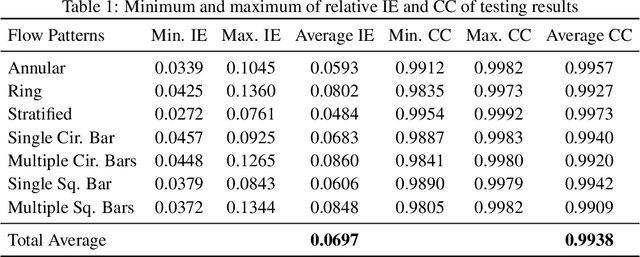
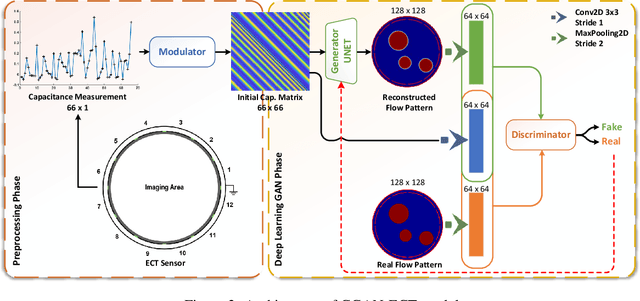
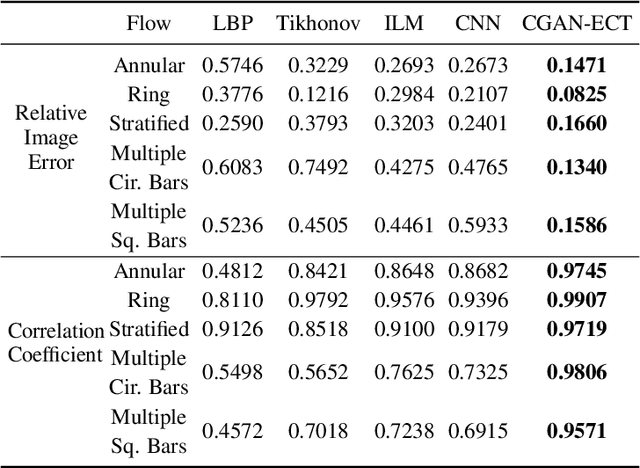
Due to the rapid growth of Electrical Capacitance Tomography (ECT) applications in several industrial fields, there is a crucial need for developing high quality, yet fast, methodologies of image reconstruction from raw capacitance measurements. Deep learning, as an effective non-linear mapping tool for complicated functions, has been going viral in many fields including electrical tomography. In this paper, we propose a Conditional Generative Adversarial Network (CGAN) model for reconstructing ECT images from capacitance measurements. The initial image of the CGAN model is constructed from the capacitance measurement. To our knowledge, this is the first time to represent the capacitance measurements in an image form. We have created a new massive ECT dataset of 320K synthetic image measurements pairs for training, and testing the proposed model. The feasibility and generalization ability of the proposed CGAN-ECT model are evaluated using testing dataset, contaminated data and flow patterns that are not exposed to the model during the training phase. The evaluation results prove that the proposed CGAN-ECT model can efficiently create more accurate ECT images than traditional and other deep learning-based image reconstruction algorithms. CGAN-ECT achieved an average image correlation coefficient of more than 99.3% and an average relative image error about 0.07.