 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Stochastic Conditional Diffusion Models for Semantic Image Synthesis
Feb 27, 2024
Semantic image synthesis (SIS) is a task to generate realistic images corresponding to semantic maps (labels). It can be applied to diverse real-world practices such as photo editing or content creation. However, in real-world applications, SIS often encounters noisy user inputs. To address this, we propose Stochastic Conditional Diffusion Model (SCDM), which is a robust conditional diffusion model that features novel forward and generation processes tailored for SIS with noisy labels. It enhances robustness by stochastically perturbing the semantic label maps through Label Diffusion, which diffuses the labels with discrete diffusion. Through the diffusion of labels, the noisy and clean semantic maps become similar as the timestep increases, eventually becoming identical at $t=T$. This facilitates the generation of an image close to a clean image, enabling robust generation. Furthermore, we propose a class-wise noise schedule to differentially diffuse the labels depending on the class. We demonstrate that the proposed method generates high-quality samples through extensive experiments and analyses on benchmark datasets, including a novel experimental setup simulating human errors during real-world applications.
FineDiffusion: Scaling up Diffusion Models for Fine-grained Image Generation with 10,000 Classes
Feb 28, 2024The class-conditional image generation based on diffusion models is renowned for generating high-quality and diverse images. However, most prior efforts focus on generating images for general categories, e.g., 1000 classes in ImageNet-1k. A more challenging task, large-scale fine-grained image generation, remains the boundary to explore. In this work, we present a parameter-efficient strategy, called FineDiffusion, to fine-tune large pre-trained diffusion models scaling to large-scale fine-grained image generation with 10,000 categories. FineDiffusion significantly accelerates training and reduces storage overhead by only fine-tuning tiered class embedder, bias terms, and normalization layers' parameters. To further improve the image generation quality of fine-grained categories, we propose a novel sampling method for fine-grained image generation, which utilizes superclass-conditioned guidance, specifically tailored for fine-grained categories, to replace the conventional classifier-free guidance sampling. Compared to full fine-tuning, FineDiffusion achieves a remarkable 1.56x training speed-up and requires storing merely 1.77% of the total model parameters, while achieving state-of-the-art FID of 9.776 on image generation of 10,000 classes. Extensive qualitative and quantitative experiments demonstrate the superiority of our method compared to other parameter-efficient fine-tuning methods. The code and more generated results are available at our project website: https://finediffusion.github.io/.
GLFNET: Global-Local (frequency) Filter Networks for efficient medical image segmentation
Mar 01, 2024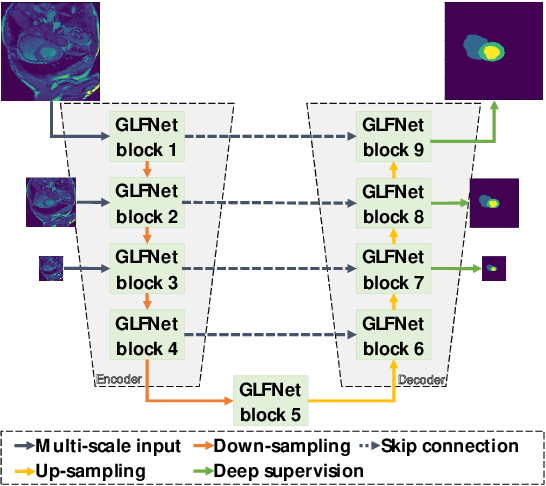
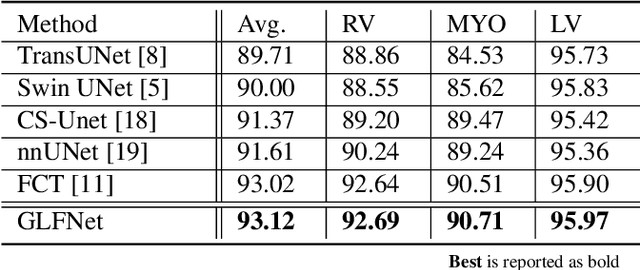
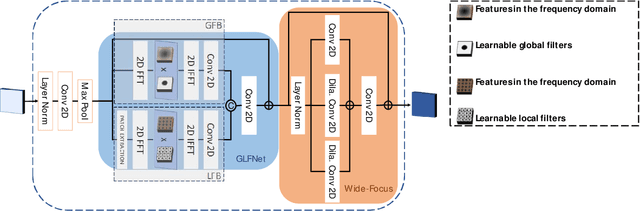
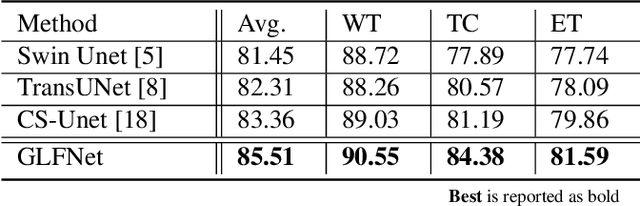
We propose a novel transformer-style architecture called Global-Local Filter Network (GLFNet) for medical image segmentation and demonstrate its state-of-the-art performance. We replace the self-attention mechanism with a combination of global-local filter blocks to optimize model efficiency. The global filters extract features from the whole feature map whereas the local filters are being adaptively created as 4x4 patches of the same feature map and add restricted scale information. In particular, the feature extraction takes place in the frequency domain rather than the commonly used spatial (image) domain to facilitate faster computations. The fusion of information from both spatial and frequency spaces creates an efficient model with regards to complexity, required data and performance. We test GLFNet on three benchmark datasets achieving state-of-the-art performance on all of them while being almost twice as efficient in terms of GFLOP operations.
Perspective-Equivariant Imaging: an Unsupervised Framework for Multispectral Pansharpening
Mar 14, 2024

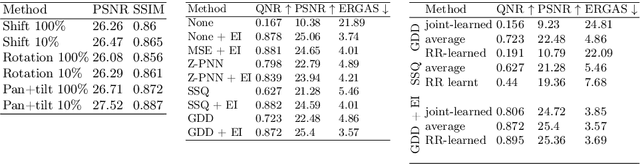
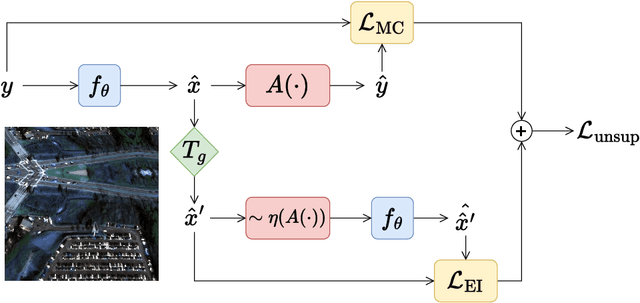
Ill-posed image reconstruction problems appear in many scenarios such as remote sensing, where obtaining high quality images is crucial for environmental monitoring, disaster management and urban planning. Deep learning has seen great success in overcoming the limitations of traditional methods. However, these inverse problems rarely come with ground truth data, highlighting the importance of unsupervised learning from partial and noisy measurements alone. We propose perspective-equivariant imaging (EI), a framework that leverages perspective variability in optical camera-based imaging systems, such as satellites or handheld cameras, to recover information lost in ill-posed optical camera imaging problems. This extends previous EI work to include a much richer non-linear class of group transforms and is shown to be an excellent prior for satellite and urban image data, where perspective-EI achieves state-of-the-art results in multispectral pansharpening, outperforming other unsupervised methods in the literature. Code at https://andrewwango.github.io/perspective-equivariant-imaging
D-YOLO a robust framework for object detection in adverse weather conditions
Mar 14, 2024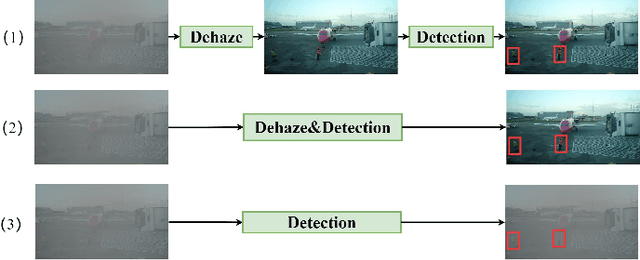
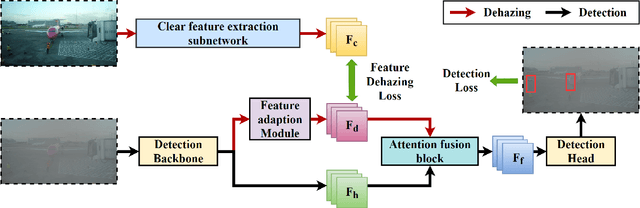
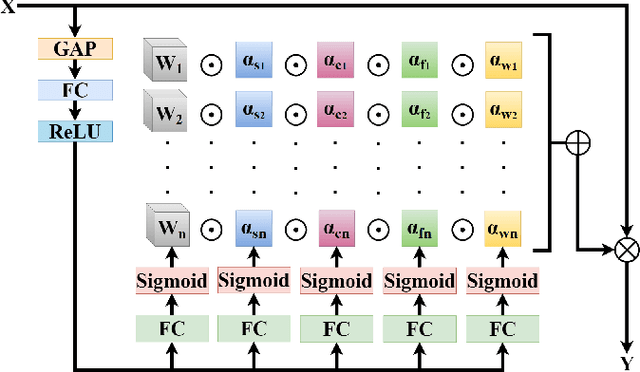
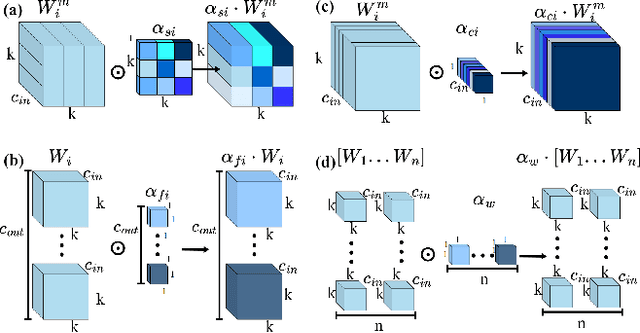
Adverse weather conditions including haze, snow and rain lead to decline in image qualities, which often causes a decline in performance for deep-learning based detection networks. Most existing approaches attempts to rectify hazy images before performing object detection, which increases the complexity of the network and may result in the loss in latent information. To better integrate image restoration and object detection tasks, we designed a double-route network with an attention feature fusion module, taking both hazy and dehazed features into consideration. We also proposed a subnetwork to provide haze-free features to the detection network. Specifically, our D-YOLO improves the performance of the detection network by minimizing the distance between the clear feature extraction subnetwork and detection network. Experiments on RTTS and FoggyCityscapes datasets show that D-YOLO demonstrates better performance compared to the state-of-the-art methods. It is a robust detection framework for bridging the gap between low-level dehazing and high-level detection.
Transformers Get Stable: An End-to-End Signal Propagation Theory for Language Models
Mar 14, 2024

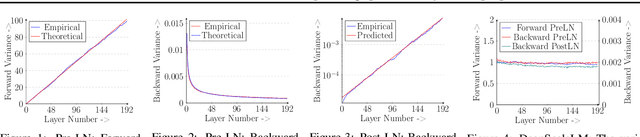
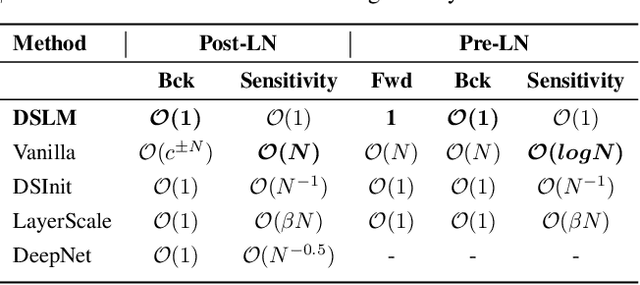
In spite of their huge success, transformer models remain difficult to scale in depth. In this work, we develop a unified signal propagation theory and provide formulae that govern the moments of the forward and backward signal through the transformer model. Our framework can be used to understand and mitigate vanishing/exploding gradients, rank collapse, and instability associated with high attention scores. We also propose DeepScaleLM, an initialization and scaling scheme that conserves unit output/gradient moments throughout the model, enabling the training of very deep models with 100s of layers. We find that transformer models could be much deeper - our deep models with fewer parameters outperform shallow models in Language Modeling, Speech Translation, and Image Classification, across Encoder-only, Decoder-only and Encoder-Decoder variants, for both Pre-LN and Post-LN transformers, for multiple datasets and model sizes. These improvements also translate into improved performance on downstream Question Answering tasks and improved robustness for image classification.
QEAN: Quaternion-Enhanced Attention Network for Visual Dance Generation
Mar 18, 2024The study of music-generated dance is a novel and challenging Image generation task. It aims to input a piece of music and seed motions, then generate natural dance movements for the subsequent music. Transformer-based methods face challenges in time series prediction tasks related to human movements and music due to their struggle in capturing the nonlinear relationship and temporal aspects. This can lead to issues like joint deformation, role deviation, floating, and inconsistencies in dance movements generated in response to the music. In this paper, we propose a Quaternion-Enhanced Attention Network (QEAN) for visual dance synthesis from a quaternion perspective, which consists of a Spin Position Embedding (SPE) module and a Quaternion Rotary Attention (QRA) module. First, SPE embeds position information into self-attention in a rotational manner, leading to better learning of features of movement sequences and audio sequences, and improved understanding of the connection between music and dance. Second, QRA represents and fuses 3D motion features and audio features in the form of a series of quaternions, enabling the model to better learn the temporal coordination of music and dance under the complex temporal cycle conditions of dance generation. Finally, we conducted experiments on the dataset AIST++, and the results show that our approach achieves better and more robust performance in generating accurate, high-quality dance movements. Our source code and dataset can be available from https://github.com/MarasyZZ/QEAN and https://google.github.io/aistplusplus_dataset respectively.
Bridging 3D Gaussian and Mesh for Freeview Video Rendering
Mar 18, 2024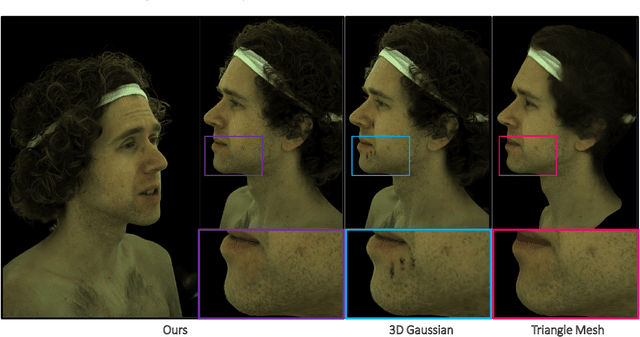
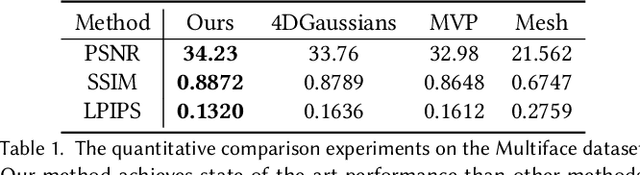


This is only a preview version of GauMesh. Recently, primitive-based rendering has been proven to achieve convincing results in solving the problem of modeling and rendering the 3D dynamic scene from 2D images. Despite this, in the context of novel view synthesis, each type of primitive has its inherent defects in terms of representation ability. It is difficult to exploit the mesh to depict the fuzzy geometry. Meanwhile, the point-based splatting (e.g. the 3D Gaussian Splatting) method usually produces artifacts or blurry pixels in the area with smooth geometry and sharp textures. As a result, it is difficult, even not impossible, to represent the complex and dynamic scene with a single type of primitive. To this end, we propose a novel approach, GauMesh, to bridge the 3D Gaussian and Mesh for modeling and rendering the dynamic scenes. Given a sequence of tracked mesh as initialization, our goal is to simultaneously optimize the mesh geometry, color texture, opacity maps, a set of 3D Gaussians, and the deformation field. At a specific time, we perform $\alpha$-blending on the RGB and opacity values based on the merged and re-ordered z-buffers from mesh and 3D Gaussian rasterizations. This produces the final rendering, which is supervised by the ground-truth image. Experiments demonstrate that our approach adapts the appropriate type of primitives to represent the different parts of the dynamic scene and outperforms all the baseline methods in both quantitative and qualitative comparisons without losing render speed.
N-Modal Contrastive Losses with Applications to Social Media Data in Trimodal Space
Mar 18, 2024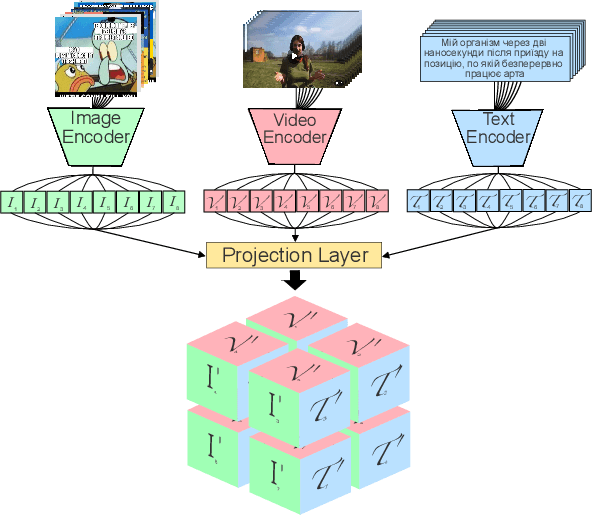
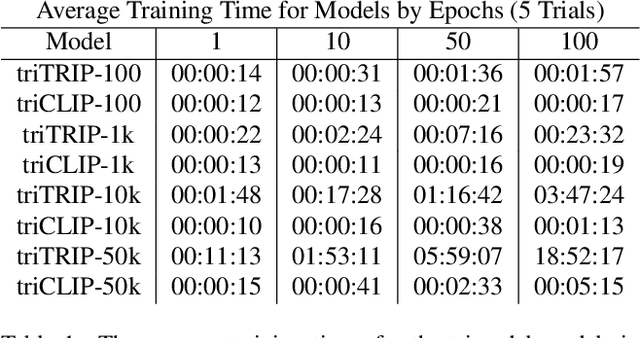

The social media landscape of conflict dynamics has grown increasingly multi-modal. Recent advancements in model architectures such as CLIP have enabled researchers to begin studying the interplay between the modalities of text and images in a shared latent space. However, CLIP models fail to handle situations on social media when modalities present in a post expand above two. Social media dynamics often require understanding the interplay between not only text and images, but video as well. In this paper we explore an extension of the contrastive loss function to allow for any number of modalities, and demonstrate its usefulness in trimodal spaces on social media. By extending CLIP into three dimensions we can further aide understanding social media landscapes where all three modalities are present (an increasingly common situation). We use a newly collected public data set of Telegram posts containing all three modalities to train, and then demonstrate the usefulness of, a trimodal model in two OSINT scenarios: classifying a social media artifact post as either pro-Russian or pro-Ukrainian and identifying which account a given artifact originated from. While trimodal CLIP models have been explored before (though not on social media data), we also display a novel quadmodal CLIP model. This model can learn the interplay between text, image, video, and audio. We demonstrate new state-of-the-art baseline results on retrieval for quadmodel models moving forward.
CDMAD: Class-Distribution-Mismatch-Aware Debiasing for Class-Imbalanced Semi-Supervised Learning
Mar 15, 2024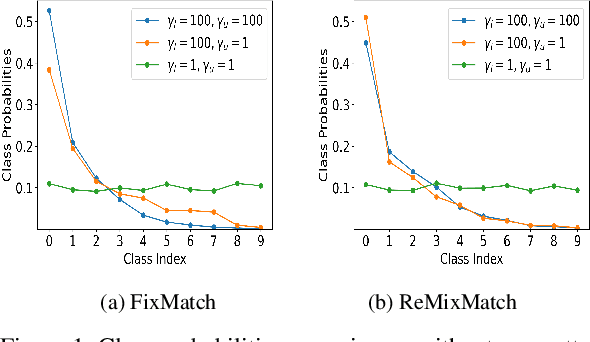
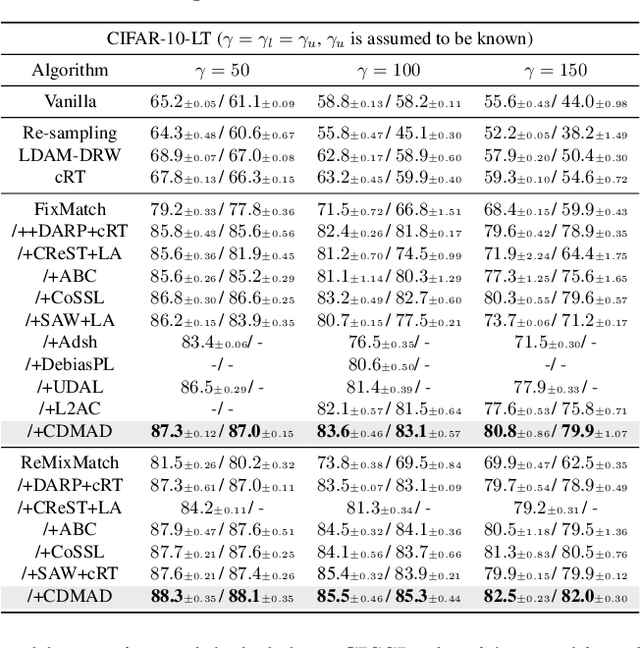
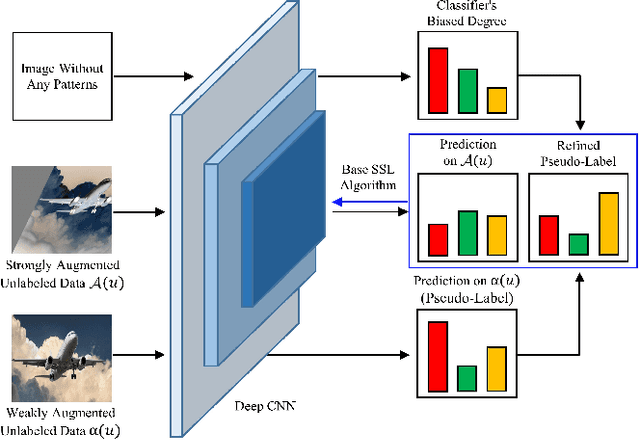
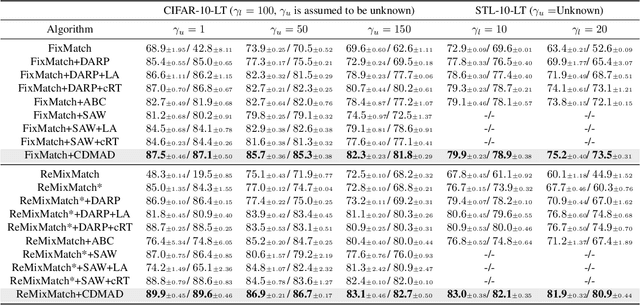
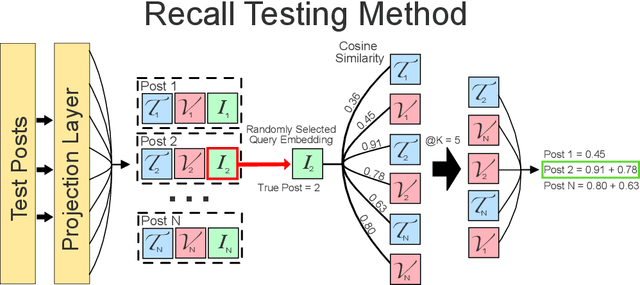
Pseudo-label-based semi-supervised learning (SSL) algorithms trained on a class-imbalanced set face two cascading challenges: 1) Classifiers tend to be biased towards majority classes, and 2) Biased pseudo-labels are used for training. It is difficult to appropriately re-balance the classifiers in SSL because the class distribution of an unlabeled set is often unknown and could be mismatched with that of a labeled set. We propose a novel class-imbalanced SSL algorithm called class-distribution-mismatch-aware debiasing (CDMAD). For each iteration of training, CDMAD first assesses the classifier's biased degree towards each class by calculating the logits on an image without any patterns (e.g., solid color image), which can be considered irrelevant to the training set. CDMAD then refines biased pseudo-labels of the base SSL algorithm by ensuring the classifier's neutrality. CDMAD uses these refined pseudo-labels during the training of the base SSL algorithm to improve the quality of the representations. In the test phase, CDMAD similarly refines biased class predictions on test samples. CDMAD can be seen as an extension of post-hoc logit adjustment to address a challenge of incorporating the unknown class distribution of the unlabeled set for re-balancing the biased classifier under class distribution mismatch. CDMAD ensures Fisher consistency for the balanced error. Extensive experiments verify the effectiveness of CDMAD.