 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pseudo 3D Perception Transformer with Multi-level Confidence Optimization for Visual Commonsense Reasoning
Jan 30, 2023
A framework performing Visual Commonsense Reasoning(VCR) needs to choose an answer and further provide a rationale justifying based on the given image and question, where the image contains all the facts for reasoning and requires to be sufficiently understood. Previous methods use a detector applied on the image to obtain a set of visual objects without considering the exact positions of them in the scene, which is inadequate for properly understanding spatial and semantic relationships between objects. In addition, VCR samples are quite diverse, and parameters of the framework tend to be trained suboptimally based on mini-batches. To address above challenges, pseudo 3D perception Transformer with multi-level confidence optimization named PPTMCO is proposed for VCR in this paper. Specifically, image depth is introduced to represent pseudo 3-dimension(3D) positions of objects along with 2-dimension(2D) coordinates in the image and further enhance visual features. Then, considering that relationships between objects are influenced by depth, depth-aware Transformer is proposed to do attention mechanism guided by depth differences from answer words and objects to objects, where each word is tagged with pseudo depth value according to related objects. To better optimize parameters of the framework, a model parameter estimation method is further proposed to weightedly integrate parameters optimized by mini-batches based on multi-level reasoning confidence. Experiments on the benchmark VCR dataset demonstrate the proposed framework performs better against the state-of-the-art approaches.
LIDA: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Infographics using Large Language Models
Mar 06, 2023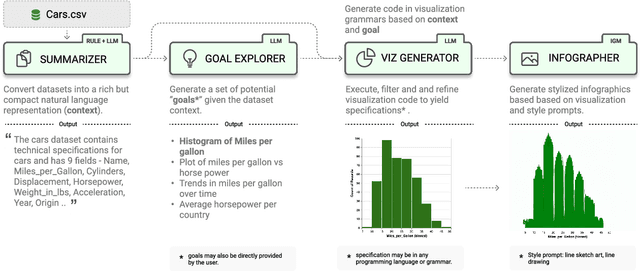
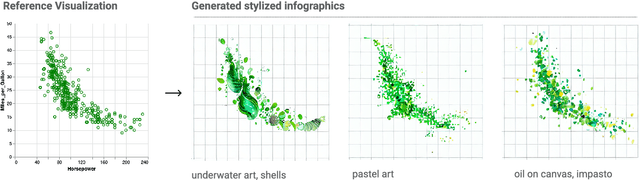
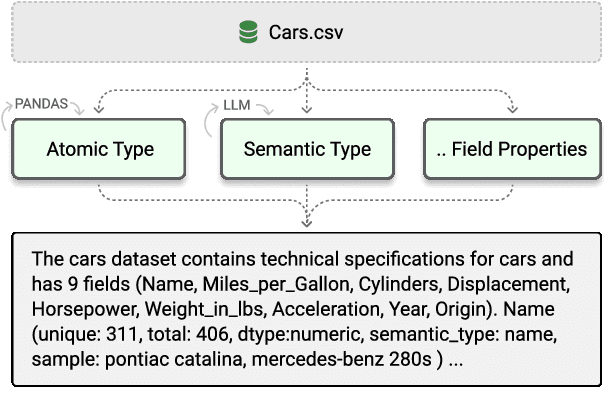
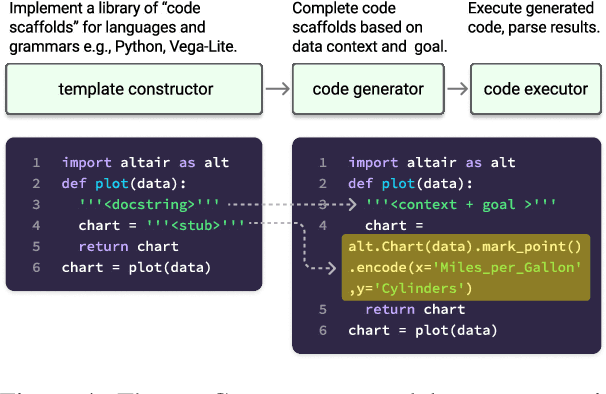
Systems that support users in the automatic creation of visualizations must address several subtasks - understand the semantics of data, enumerate relevant visualization goals and generate visualization specifications. In this work, we pose visualization generation as a multi-stage generation problem and argue that well-orchestrated pipelines based on large language models (LLMs) and image generation models (IGMs) are suitable to addressing these tasks. We present LIDA, a novel tool for generating grammar-agnostic visualizations and infographics. LIDA comprises of 4 modules - A SUMMARIZER that converts data into a rich but compact natural language summary, a GOAL EXPLORER that enumerates visualization goals given the data, a VISGENERATOR that generates, refines, executes and filters visualization code and an INFOGRAPHER module that yields data-faithful stylized graphics using IGMs. LIDA provides a python api, and a hybrid user interface (direct manipulation and natural language) for interactive chart, infographics and data story generation.
Multi-stage image denoising with the wavelet transform
Sep 27, 2022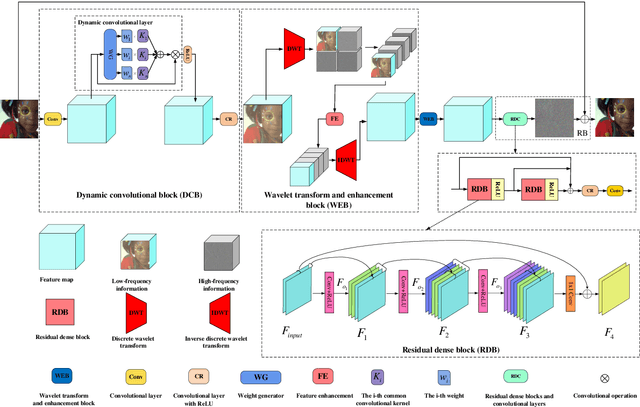
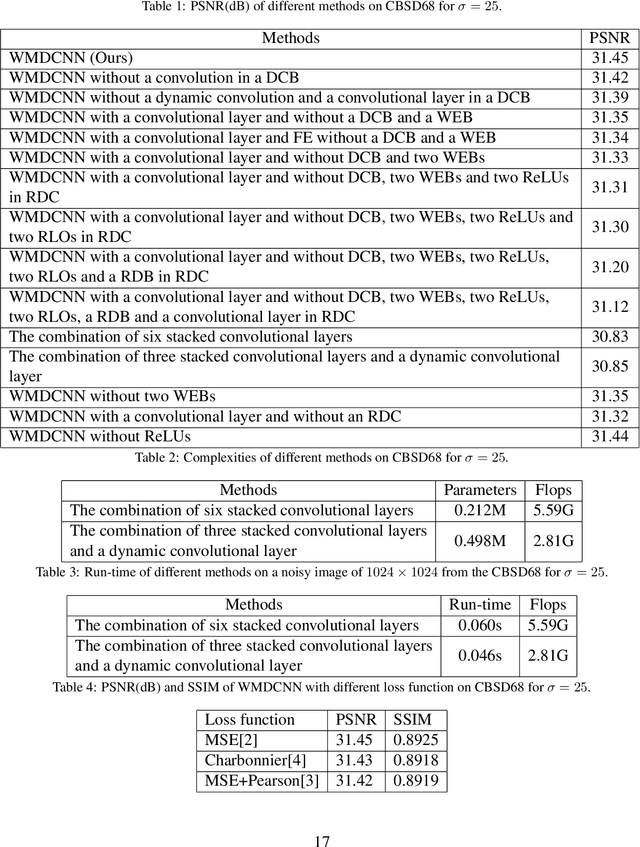
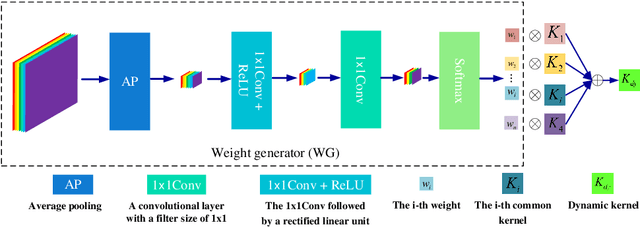
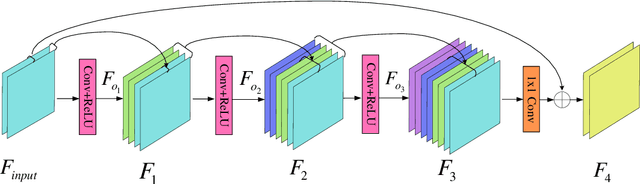
Deep convolutional neural networks (CNNs) are used for image denoising via automatically mining accurate structure information. However, most of existing CNNs depend on enlarging depth of designed networks to obtain better denoising performance, which may cause training difficulty. In this paper, we propose a multi-stage image denoising CNN with the wavelet transform (MWDCNN) via three stages, i.e., a dynamic convolutional block (DCB), two cascaded wavelet transform and enhancement blocks (WEBs) and residual block (RB). DCB uses a dynamic convolution to dynamically adjust parameters of several convolutions for making a tradeoff between denoising performance and computational costs. WEB uses a combination of signal processing technique (i.e., wavelet transformation) and discriminative learning to suppress noise for recovering more detailed information in image denoising. To further remove redundant features, RB is used to refine obtained features for improving denoising effects and reconstruct clean images via improved residual dense architectures. Experimental results show that the proposed MWDCNN outperforms some popular denoising methods in terms of quantitative and qualitative analysis. Codes are available at https://github.com/hellloxiaotian/MWDCNN.
Modality-Agnostic Debiasing for Single Domain Generalization
Mar 13, 2023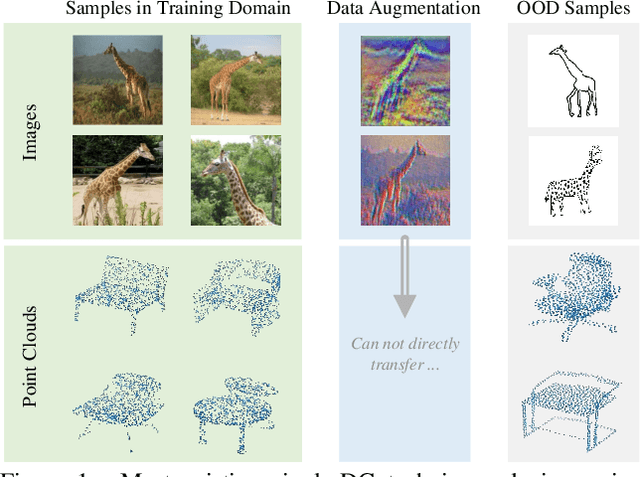


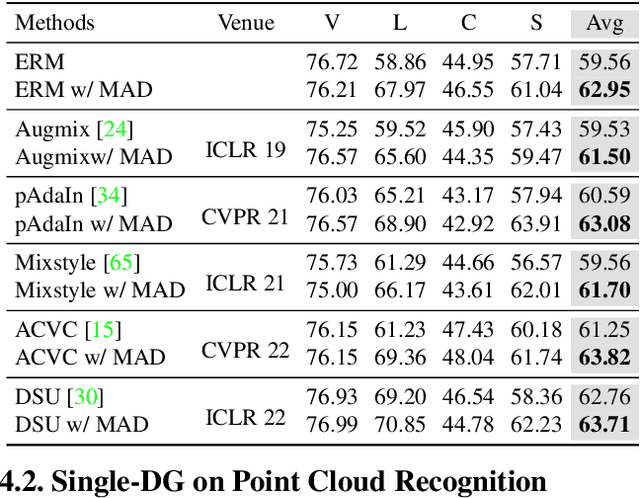
Deep neural networks (DNNs) usually fail to generalize well to outside of distribution (OOD) data, especially in the extreme case of single domain generalization (single-DG) that transfers DNNs from single domain to multiple unseen domains. Existing single-DG techniques commonly devise various data-augmentation algorithms, and remould the multi-source domain generalization methodology to learn domain-generalized (semantic) features. Nevertheless, these methods are typically modality-specific, thereby being only applicable to one single modality (e.g., image). In contrast, we target a versatile Modality-Agnostic Debiasing (MAD) framework for single-DG, that enables generalization for different modalities. Technically, MAD introduces a novel two-branch classifier: a biased-branch encourages the classifier to identify the domain-specific (superficial) features, and a general-branch captures domain-generalized features based on the knowledge from biased-branch. Our MAD is appealing in view that it is pluggable to most single-DG models. We validate the superiority of our MAD in a variety of single-DG scenarios with different modalities, including recognition on 1D texts, 2D images, 3D point clouds, and semantic segmentation on 2D images. More remarkably, for recognition on 3D point clouds and semantic segmentation on 2D images, MAD improves DSU by 2.82\% and 1.5\% in accuracy and mIOU.
View Adaptive Light Field Deblurring Networks with Depth Perception
Mar 13, 2023
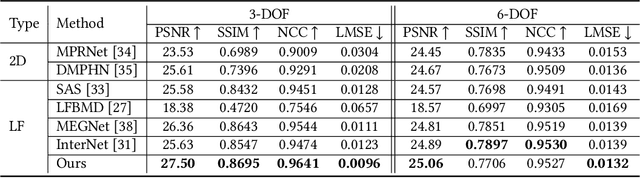
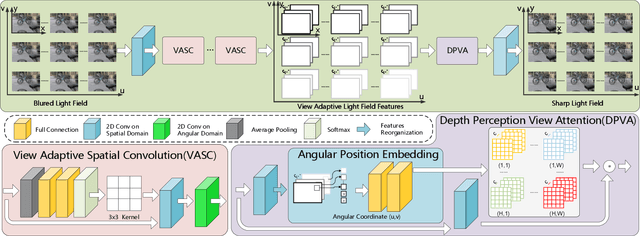
The Light Field (LF) deblurring task is a challenging problem as the blur images are caused by different reasons like the camera shake and the object motion. The single image deblurring method is a possible way to solve this problem. However, since it deals with each view independently and cannot effectively utilize and maintain the LF structure, the restoration effect is usually not ideal. Besides, the LF blur is more complex because the degree is affected by the views and depth. Therefore, we carefully designed a novel LF deblurring network based on the LF blur characteristics. On one hand, since the blur degree varies a lot in different views, we design a novel view adaptive spatial convolution to deblur blurred LFs, which calculates the exclusive convolution kernel for each view. On the other hand, because the blur degree also varies with the depth of the object, a depth perception view attention is designed to deblur different depth areas by selectively integrating information from different views. Besides, we introduce an angular position embedding to maintain the LF structure better, which ensures the model correctly restores the view information. Quantitative and qualitative experimental results on synthetic and real images show that the deblurring effect of our method is better than other state-of-the-art methods.
Guiding the Guidance: A Comparative Analysis of User Guidance Signals for Interactive Segmentation of Volumetric Images
Mar 13, 2023
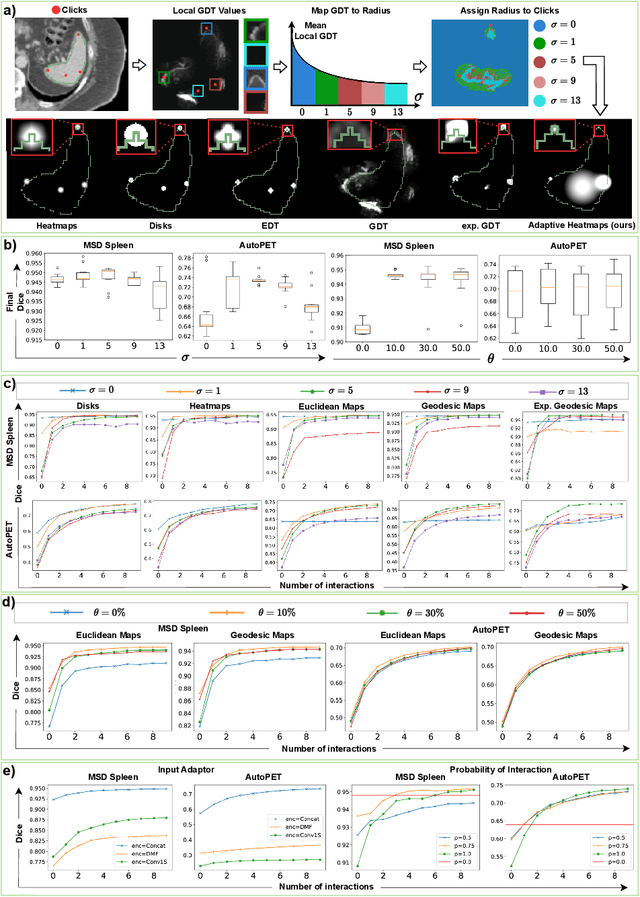

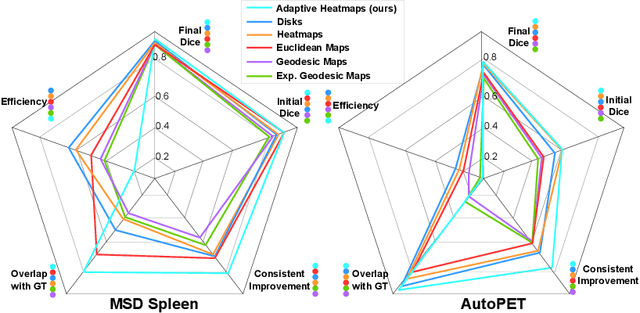
Interactive segmentation reduces the annotation time of medical images and allows annotators to iteratively refine labels with corrective interactions, such as clicks. While existing interactive models transform clicks into user guidance signals, which are combined with images to form (image, guidance) pairs, the question of how to best represent the guidance has not been fully explored. To address this, we conduct a comparative study of existing guidance signals by training interactive models with different signals and parameter settings to identify crucial parameters for the model's design. Based on our findings, we design a guidance signal that retains the benefits of other signals while addressing their limitations. We propose an adaptive Gaussian heatmaps guidance signal that utilizes the geodesic distance transform to dynamically adapt the radius of each heatmap when encoding clicks. We conduct our study on the MSD Spleen and the AutoPET datasets to explore the segmentation of both anatomy (spleen) and pathology (tumor lesions). Our results show that choosing the guidance signal is crucial for interactive segmentation as we improve the performance by 14% Dice with our adaptive heatmaps on the challenging AutoPET dataset when compared to non-interactive models. This brings interactive models one step closer to deployment on clinical workflows. We will make our code publically available.
CrossFormer++: A Versatile Vision Transformer Hinging on Cross-scale Attention
Mar 13, 2023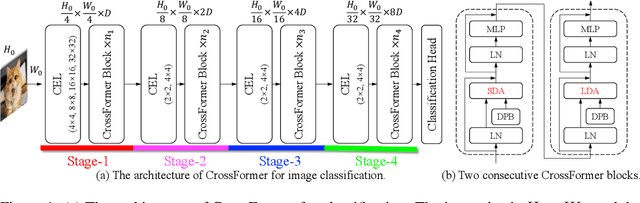
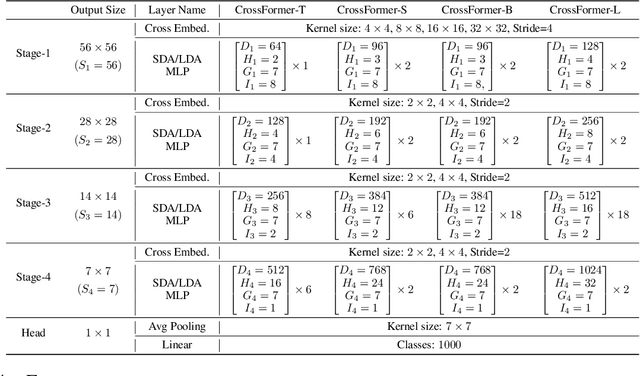
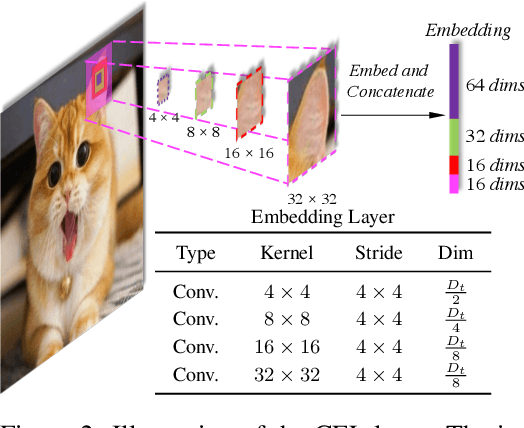
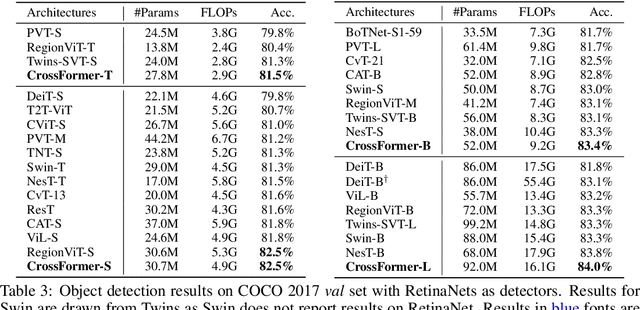
While features of different scales are perceptually important to visual inputs, existing vision transformers do not yet take advantage of them explicitly. To this end, we first propose a cross-scale vision transformer, CrossFormer. It introduces a cross-scale embedding layer (CEL) and a long-short distance attention (LSDA). On the one hand, CEL blends each token with multiple patches of different scales, providing the self-attention module itself with cross-scale features. On the other hand, LSDA splits the self-attention module into a short-distance one and a long-distance counterpart, which not only reduces the computational burden but also keeps both small-scale and large-scale features in the tokens. Moreover, through experiments on CrossFormer, we observe another two issues that affect vision transformers' performance, i.e. the enlarging self-attention maps and amplitude explosion. Thus, we further propose a progressive group size (PGS) paradigm and an amplitude cooling layer (ACL) to alleviate the two issues, respectively. The CrossFormer incorporating with PGS and ACL is called CrossFormer++. Extensive experiments show that CrossFormer++ outperforms the other vision transformers on image classification, object detection, instance segmentation, and semantic segmentation tasks. The code will be available at: https://github.com/cheerss/CrossFormer.
EcoTTA: Memory-Efficient Continual Test-time Adaptation via Self-distilled Regularization
Mar 13, 2023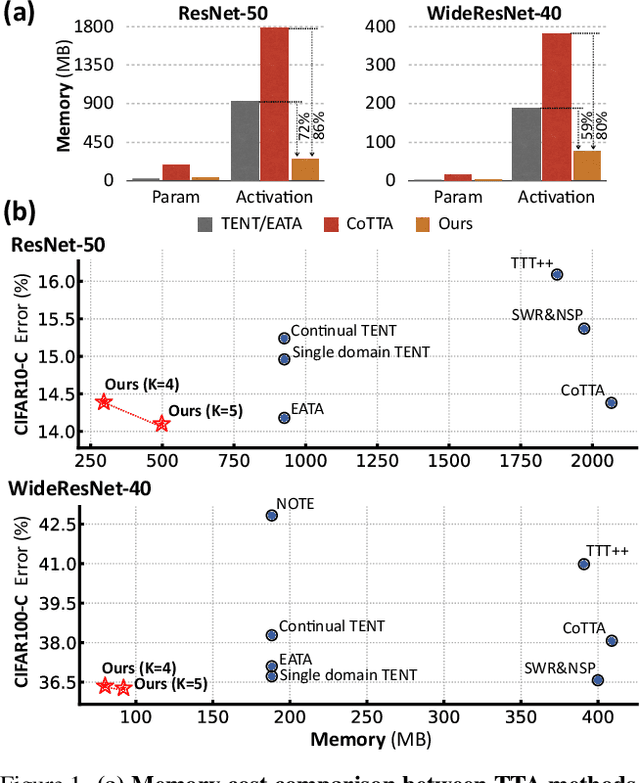
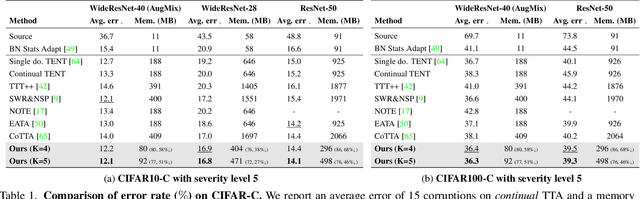
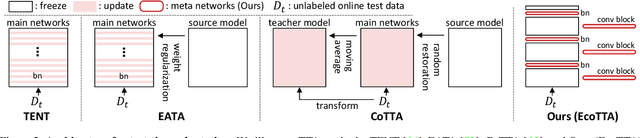
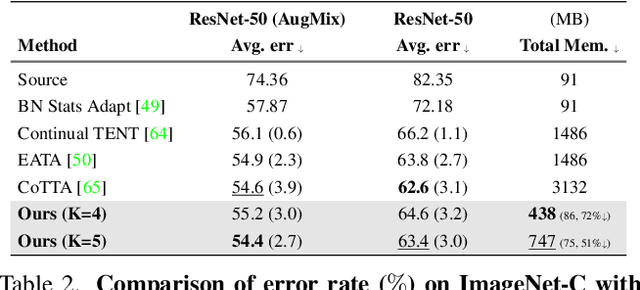
This paper presents a simple yet effective approach that improves continual test-time adaptation (TTA) in a memory-efficient manner. TTA may primarily be conducted on edge devices with limited memory, so reducing memory is crucial but has been overlooked in previous TTA studies. In addition, long-term adaptation often leads to catastrophic forgetting and error accumulation, which hinders applying TTA in real-world deployments. Our approach consists of two components to address these issues. First, we present lightweight meta networks that can adapt the frozen original networks to the target domain. This novel architecture minimizes memory consumption by decreasing the size of intermediate activations required for backpropagation. Second, our novel self-distilled regularization controls the output of the meta networks not to deviate significantly from the output of the frozen original networks, thereby preserving well-trained knowledge from the source domain. Without additional memory, this regularization prevents error accumulation and catastrophic forgetting, resulting in stable performance even in long-term test-time adaptation. We demonstrate that our simple yet effective strategy outperforms other state-of-the-art methods on various benchmarks for image classification and semantic segmentation tasks. Notably, our proposed method with ResNet-50 and WideResNet-40 takes 86% and 80% less memory than the recent state-of-the-art method, CoTTA.
F2BEV: Bird's Eye View Generation from Surround-View Fisheye Camera Images for Automated Driving
Mar 07, 2023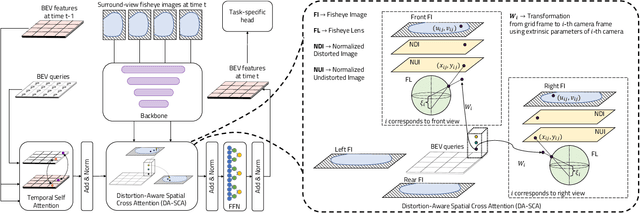



Bird's Eye View (BEV) representations are tremendously useful for perception-related automated driving tasks. However, generating BEVs from surround-view fisheye camera images is challenging due to the strong distortions introduced by such wide-angle lenses. We take the first step in addressing this challenge and introduce a baseline, F2BEV, to generate BEV height maps and semantic segmentation maps from fisheye images. F2BEV consists of a distortion-aware spatial cross attention module for querying and consolidating spatial information from fisheye image features in a transformer-style architecture followed by a task-specific head. We evaluate single-task and multi-task variants of F2BEV on our synthetic FB-SSEM dataset, all of which generate better BEV height and segmentation maps (in terms of the IoU) than a state-of-the-art BEV generation method operating on undistorted fisheye images. We also demonstrate height map generation from real-world fisheye images using F2BEV. An initial sample of our dataset is publicly available at https://tinyurl.com/58jvnscy
Stereo Event-based Visual-Inertial Odometry
Mar 09, 2023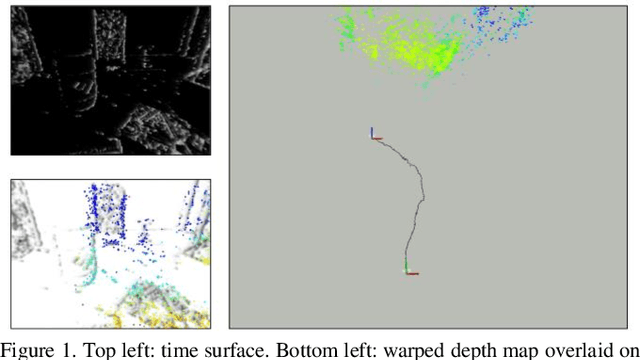
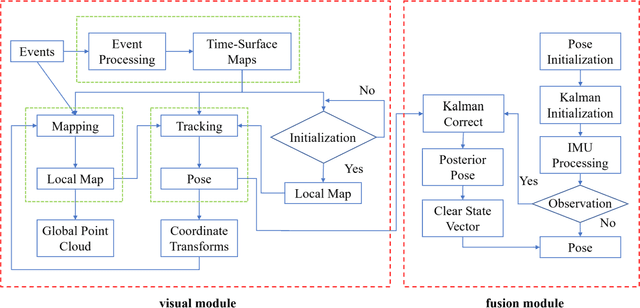
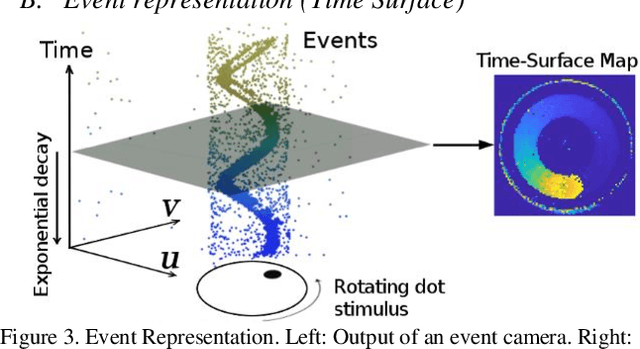
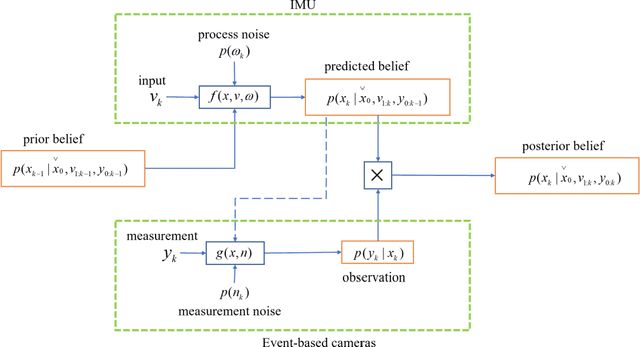
Event-based cameras are new type vision sensors whose pixels work independently and respond asynchronously to brightness change with microsecond resolution, instead of provide stand-ard intensity frames. Compared with traditional cameras, event-based cameras have low latency, no motion blur, and high dynamic range (HDR), which provide possibilities for robots to deal with some challenging scenes. We propose a visual-inertial odometry method for stereo event-cameras based on Kalman filtering. The visual module updates the camera pose relies on the edge alignment of a semi-dense 3D map to a 2D image, and the IMU module updates pose by midpoint method. We evaluate our method on public datasets in natural scenes with general 6-DoF motion and compare the results against ground truth. We show that the proposed pipeline provides improved accuracy over the result of a state-of-the-art visual odometry method for stereo event-cameras, while running in real-time on a standard CPU. To the best of our knowledge, this is the first published visual-inertial odometry algorithm for stereo event-cameras.