 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ParaFormer: Parallel Attention Transformer for Efficient Feature Matching
Mar 02, 2023
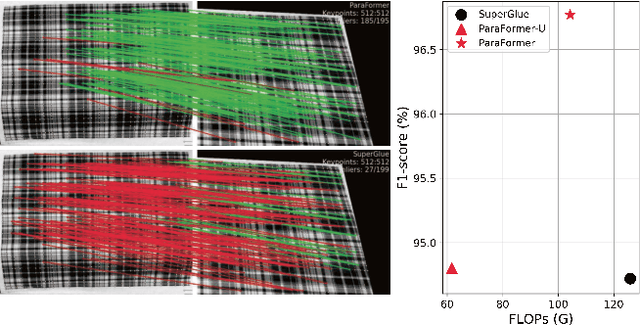
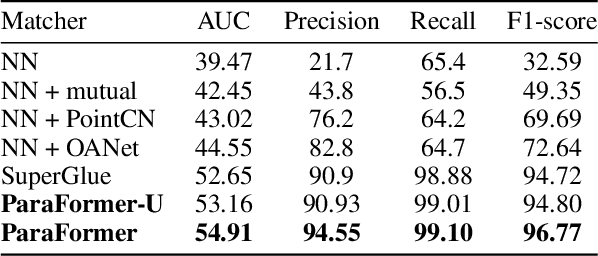
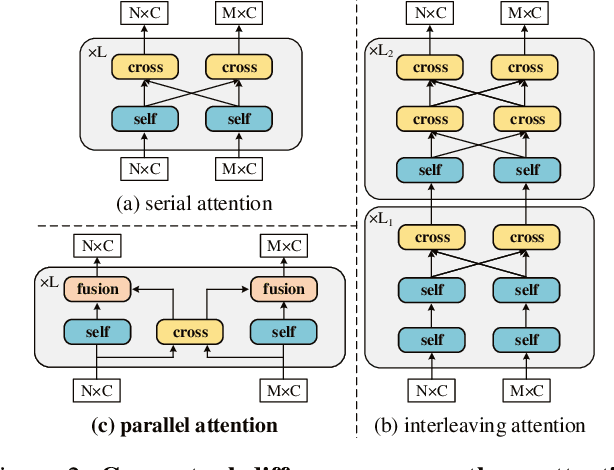
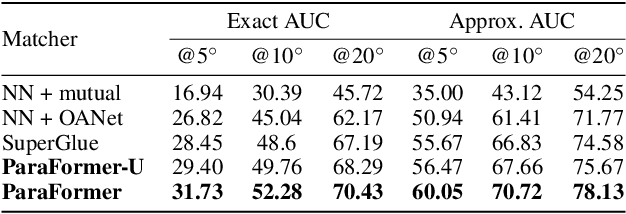
Heavy computation is a bottleneck limiting deep-learningbased feature matching algorithms to be applied in many realtime applications. However, existing lightweight networks optimized for Euclidean data cannot address classical feature matching tasks, since sparse keypoint based descriptors are expected to be matched. This paper tackles this problem and proposes two concepts: 1) a novel parallel attention model entitled ParaFormer and 2) a graph based U-Net architecture with attentional pooling. First, ParaFormer fuses features and keypoint positions through the concept of amplitude and phase, and integrates self- and cross-attention in a parallel manner which achieves a win-win performance in terms of accuracy and efficiency. Second, with U-Net architecture and proposed attentional pooling, the ParaFormer-U variant significantly reduces computational complexity, and minimize performance loss caused by downsampling. Sufficient experiments on various applications, including homography estimation, pose estimation, and image matching, demonstrate that ParaFormer achieves state-of-the-art performance while maintaining high efficiency. The efficient ParaFormer-U variant achieves comparable performance with less than 50% FLOPs of the existing attention-based models.
Curvature-Sensitive Predictive Coding with Approximate Laplace Monte Carlo
Mar 09, 2023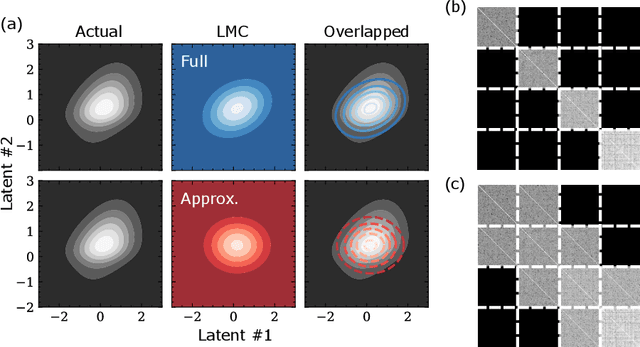
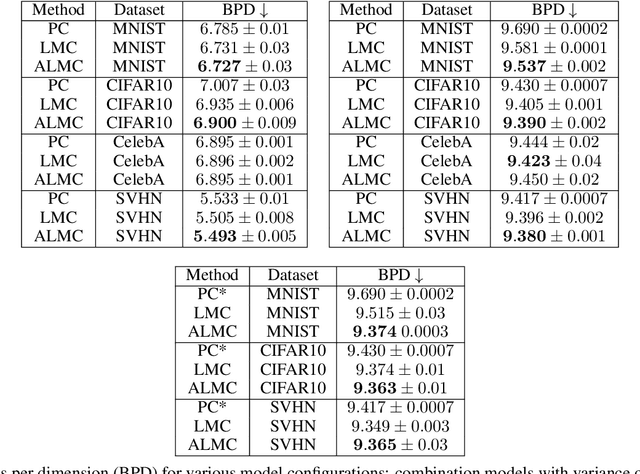
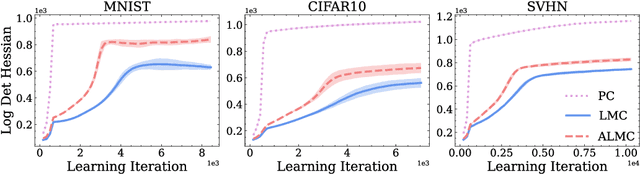

Predictive coding (PC) accounts of perception now form one of the dominant computational theories of the brain, where they prescribe a general algorithm for inference and learning over hierarchical latent probabilistic models. Despite this, they have enjoyed little export to the broader field of machine learning, where comparative generative modelling techniques have flourished. In part, this has been due to the poor performance of models trained with PC when evaluated by both sample quality and marginal likelihood. By adopting the perspective of PC as a variational Bayes algorithm under the Laplace approximation, we identify the source of these deficits to lie in the exclusion of an associated Hessian term in the PC objective function, which would otherwise regularise the sharpness of the probability landscape and prevent over-certainty in the approximate posterior. To remedy this, we make three primary contributions: we begin by suggesting a simple Monte Carlo estimated evidence lower bound which relies on sampling from the Hessian-parameterised variational posterior. We then derive a novel block diagonal approximation to the full Hessian matrix that has lower memory requirements and favourable mathematical properties. Lastly, we present an algorithm that combines our method with standard PC to reduce memory complexity further. We evaluate models trained with our approach against the standard PC framework on image benchmark datasets. Our approach produces higher log-likelihoods and qualitatively better samples that more closely capture the diversity of the data-generating distribution.
TQ-Net: Mixed Contrastive Representation Learning For Heterogeneous Test Questions
Mar 09, 2023

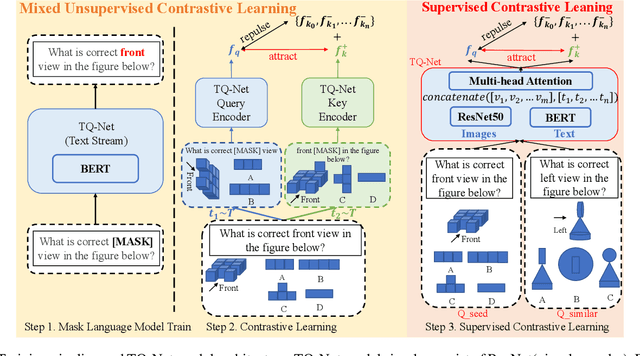
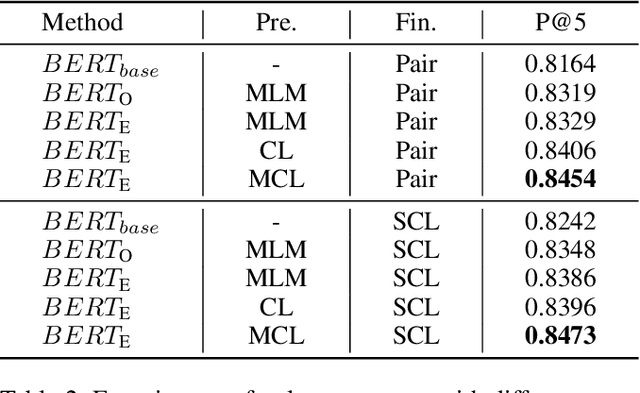
Recently, more and more people study online for the convenience of access to massive learning materials (e.g. test questions/notes), thus accurately understanding learning materials became a crucial issue, which is essential for many educational applications. Previous studies focus on using language models to represent the question data. However, test questions (TQ) are usually heterogeneous and multi-modal, e.g., some of them may only contain text, while others half contain images with information beyond their literal description. In this context, both supervised and unsupervised methods are difficult to learn a fused representation of questions. Meanwhile, this problem cannot be solved by conventional methods such as image caption, as the images may contain information complementary rather than duplicate to the text. In this paper, we first improve previous text-only representation with a two-stage unsupervised instance level contrastive based pre-training method (MCL: Mixture Unsupervised Contrastive Learning). Then, TQ-Net was proposed to fuse the content of images to the representation of heterogeneous data. Finally, supervised contrastive learning was conducted on relevance prediction-related downstream tasks, which helped the model to learn the representation of questions effectively. We conducted extensive experiments on question-based tasks on large-scale, real-world datasets, which demonstrated the effectiveness of TQ-Net and improve the precision of downstream applications (e.g. similar questions +2.02% and knowledge point prediction +7.20%). Our code will be available, and we will open-source a subset of our data to promote the development of relative studies.
Penalized Deep Partially Linear Cox Models with Application to CT Scans of Lung Cancer Patients
Mar 09, 2023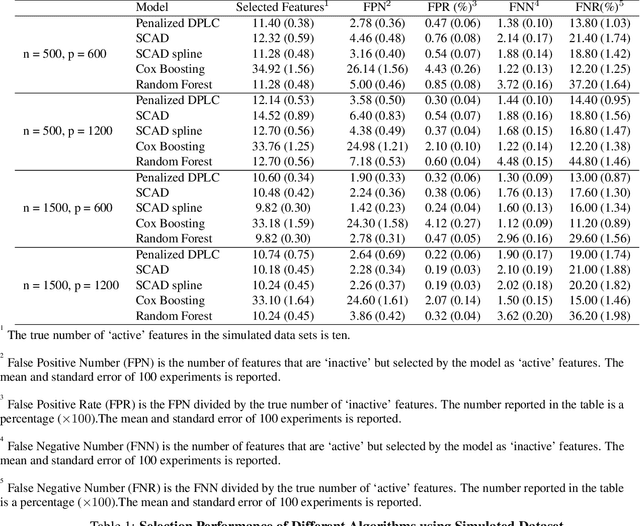
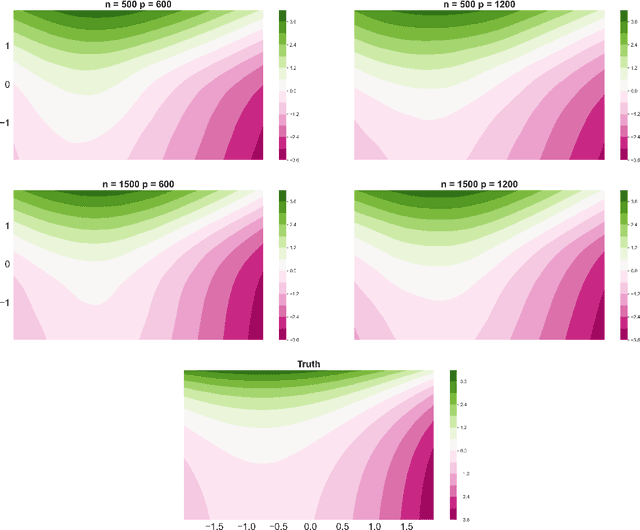
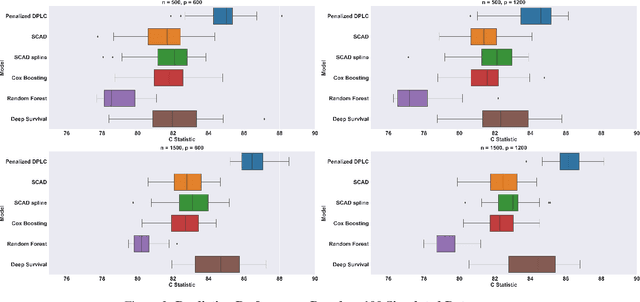
Lung cancer is a leading cause of cancer mortality globally, highlighting the importance of understanding its mortality risks to design effective patient-centered therapies. The National Lung Screening Trial (NLST) was a nationwide study aimed at investigating risk factors for lung cancer. The study employed computed tomography texture analysis (CTTA), which provides objective measurements of texture patterns on CT scans, to quantify the mortality risks of lung cancer patients. Partially linear Cox models are becoming a popular tool for modeling survival outcomes, as they effectively handle both established risk factors (such as age and other clinical factors) and new risk factors (such as image features) in a single framework. The challenge in identifying the texture features that impact cancer survival is due to their sensitivity to factors such as scanner type, segmentation, and organ motion. To overcome this challenge, we propose a novel Penalized Deep Partially Linear Cox Model (Penalized DPLC), which incorporates the SCAD penalty to select significant texture features and employs a deep neural network to estimate the nonparametric component of the model accurately. We prove the convergence and asymptotic properties of the estimator and compare it to other methods through extensive simulation studies, evaluating its performance in risk prediction and feature selection. The proposed method is applied to the NLST study dataset to uncover the effects of key clinical and imaging risk factors on patients' survival. Our findings provide valuable insights into the relationship between these factors and survival outcomes.
The Influences of Color and Shape Features in Visual Contrastive Learning
Jan 29, 2023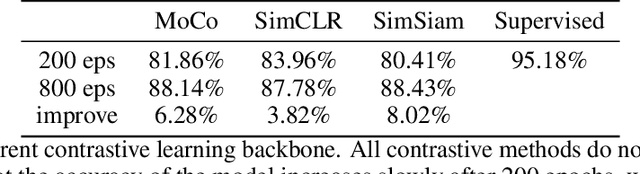



In the field of visual representation learning, performance of contrastive learning has been catching up with the supervised method which is commonly a classification convolutional neural network. However, most of the research work focuses on improving the accuracy of downstream tasks such as image classification and object detection. For visual contrastive learning, the influences of individual image features (e.g., color and shape) to model performance remain ambiguous. This paper investigates such influences by designing various ablation experiments, the results of which are evaluated by specifically designed metrics. While these metrics are not invented by us, we first use them in the field of representation evaluation. Specifically, we assess the contribution of two primary image features (i.e., color and shape) in a quantitative way. Experimental results show that compared with supervised representations, contrastive representations tend to cluster with objects of similar color in the representation space, and contain less shape information than supervised representations. Finally, we discuss that the current data augmentation is responsible for these results. We believe that exploring an unsupervised augmentation method that
Language Does More Than Describe: On The Lack Of Figurative Speech in Text-To-Image Models
Oct 19, 2022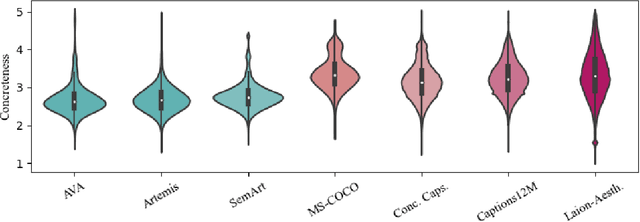
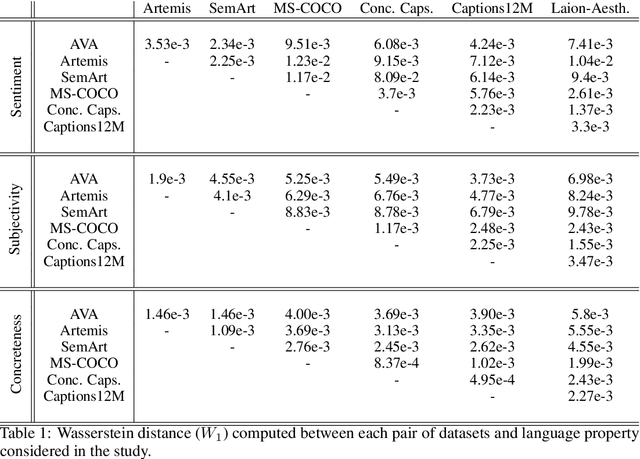


The impressive capacity shown by recent text-to-image diffusion models to generate high-quality pictures from textual input prompts has leveraged the debate about the very definition of art. Nonetheless, these models have been trained using text data collected from content-based labelling protocols that focus on describing the items and actions in an image but neglect any subjective appraisal. Consequently, these automatic systems need rigorous descriptions of the elements and the pictorial style of the image to be generated, otherwise failing to deliver. As potential indicators of the actual artistic capabilities of current generative models, we characterise the sentimentality, objectiveness and degree of abstraction of publicly available text data used to train current text-to-image diffusion models. Considering the sharp difference observed between their language style and that typically employed in artistic contexts, we suggest generative models should incorporate additional sources of subjective information in their training in order to overcome (or at least to alleviate) some of their current limitations, thus effectively unleashing a truly artistic and creative generation.
On the Importance of Noise Scheduling for Diffusion Models
Jan 26, 2023
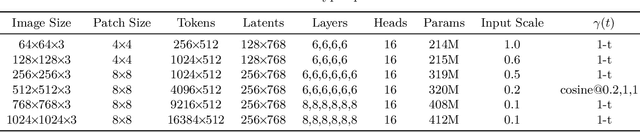

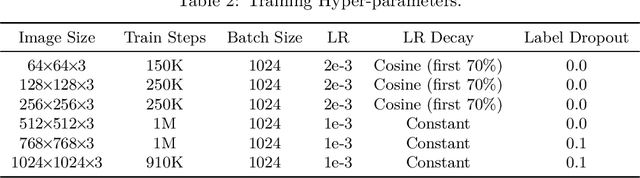
We empirically study the effect of noise scheduling strategies for denoising diffusion generative models. There are three findings: (1) the noise scheduling is crucial for the performance, and the optimal one depends on the task (e.g., image sizes), (2) when increasing the image size, the optimal noise scheduling shifts towards a noisier one (due to increased redundancy in pixels), and (3) simply scaling the input data by a factor of $b$ while keeping the noise schedule function fixed (equivalent to shifting the logSNR by $\log b$) is a good strategy across image sizes. This simple recipe, when combined with recently proposed Recurrent Interface Network (RIN), yields state-of-the-art pixel-based diffusion models for high-resolution images on ImageNet, enabling single-stage, end-to-end generation of diverse and high-fidelity images at 1024$\times$1024 resolution for the first time (without upsampling/cascades).
Disease Severity Regression with Continuous Data Augmentation
Feb 24, 2023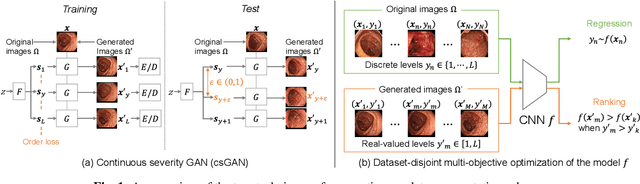
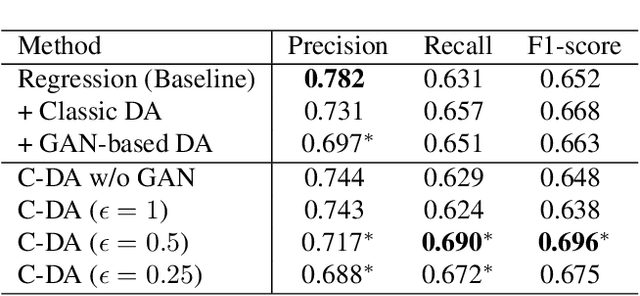
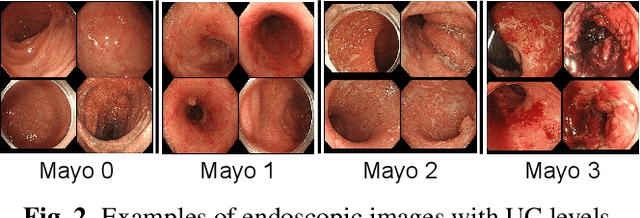
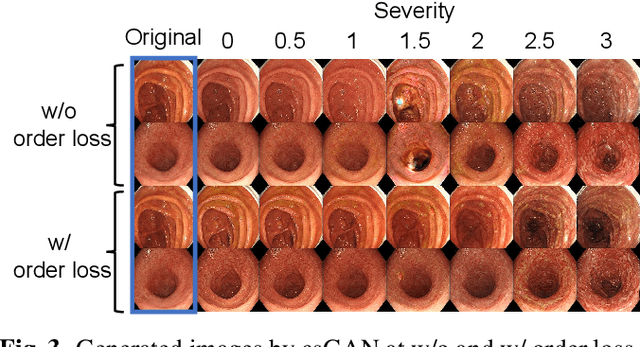
Disease severity regression by a convolutional neural network (CNN) for medical images requires a sufficient number of image samples labeled with severity levels. Conditional generative adversarial network (cGAN)-based data augmentation (DA) is a possible solution, but it encounters two issues. The first issue is that existing cGANs cannot deal with real-valued severity levels as their conditions, and the second is that the severity of the generated images is not fully reliable. We propose continuous DA as a solution to the two issues. Our method uses continuous severity GAN to generate images at real-valued severity levels and dataset-disjoint multi-objective optimization to deal with the second issue. Our method was evaluated for estimating ulcerative colitis (UC) severity of endoscopic images and achieved higher classification performance than conventional DA methods.
Heterogeneous Feature Distillation Network for SAR Image Semantic Segmentation
Oct 17, 2022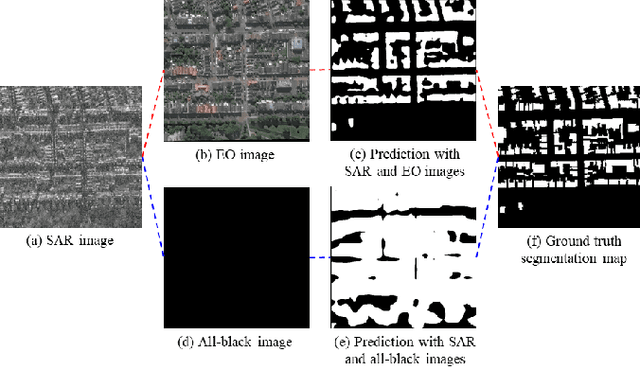
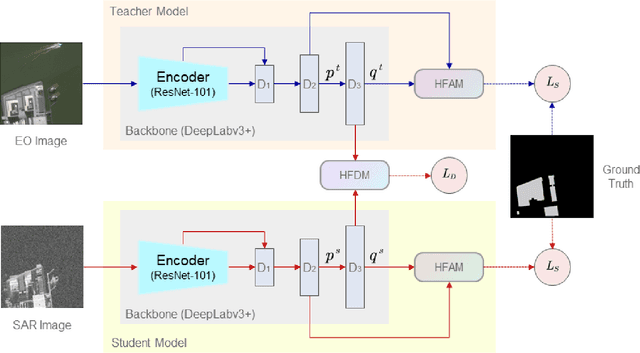
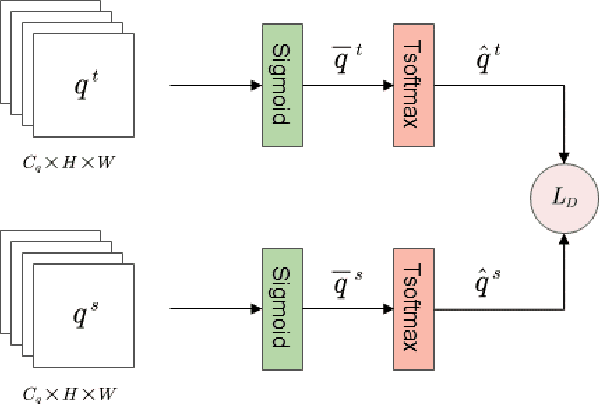
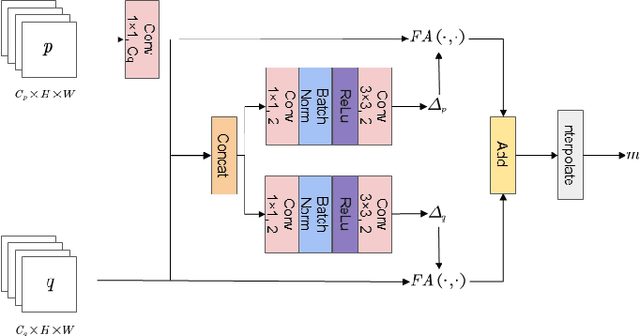
Semantic segmentation for SAR (Synthetic Aperture Radar) images has attracted increasing attention in the remote sensing community recently, due to SAR's all-time and all-weather imaging capability. However, SAR images are generally more difficult to be segmented than their EO (Electro-Optical) counterparts, since speckle noises and layovers are inevitably involved in SAR images. To address this problem, we investigate how to introduce EO features to assist the training of a SAR-segmentation model, and propose a heterogeneous feature distillation network for segmenting SAR images, called HFD-Net, where a SAR-segmentation student model gains knowledge from a pre-trained EO-segmentation teacher model. In the proposed HFD-Net, both the student and teacher models employ an identical architecture but different parameter configurations, and a heterogeneous feature distillation model is explored for transferring latent EO features from the teacher model to the student model and then enhancing the ability of the student model for SAR image segmentation. In addition, a heterogeneous feature alignment module is explored to aggregate multi-scale features for segmentation in each of the student model and teacher model. Extensive experimental results on two public datasets demonstrate that the proposed HFD-Net outperforms seven state-of-the-art SAR image semantic segmentation methods.
Diagnostic Quality Assessment of Fundus Photographs: Hierarchical Deep Learning with Clinically Significant Explanations
Feb 18, 2023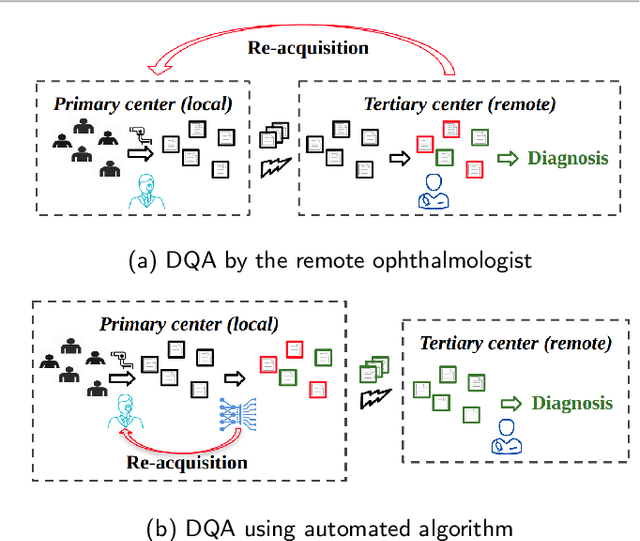
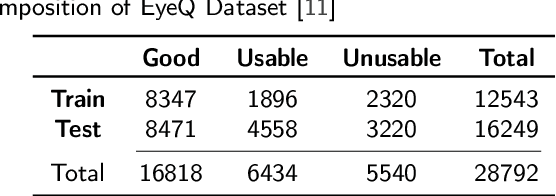
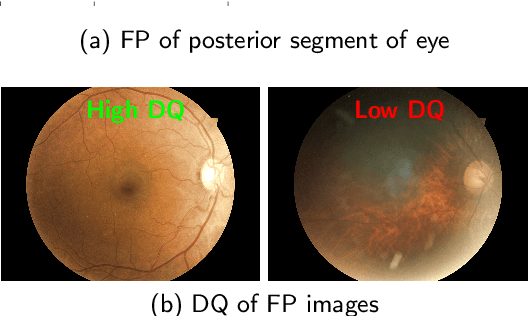
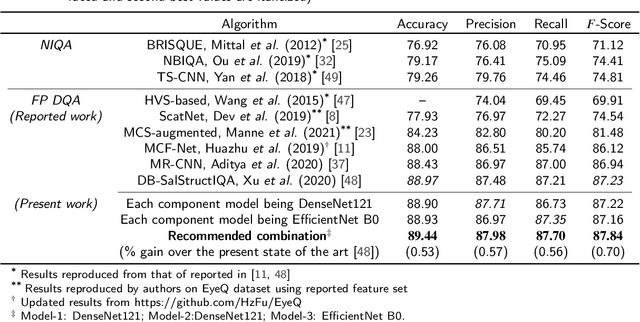
Fundus photography (FP) remains the primary imaging modality in screening various retinal diseases including age-related macular degeneration, diabetic retinopathy and glaucoma. FP allows the clinician to examine the ocular fundus structures such as the macula, the optic disc (OD) and retinal vessels, whose visibility and clarity in an FP image remain central to ensuring diagnostic accuracy, and hence determine the diagnostic quality (DQ). Images with low DQ, resulting from eye movement, improper illumination and other possible causes, should obviously be recaptured. However, the technician, often unfamiliar with DQ criteria, initiates recapture only based on expert feedback. The process potentially engages the imaging device multiple times for single subject, and wastes the time and effort of the ophthalmologist, the technician and the subject. The burden could be prohibitive in case of teleophthalmology, where obtaining feedback from the remote expert entails additional communication cost and delay. Accordingly, a strong need for automated diagnostic quality assessment (DQA) has been felt, where an image is immediately assigned a DQ category. In response, motivated by the notional continuum of DQ, we propose a hierarchical deep learning (DL) architecture to distinguish between good, usable and unusable categories. On the public EyeQ dataset, we achieve an accuracy of 89.44%, improving upon existing methods. In addition, using gradient based class activation map (Grad-CAM), we generate a visual explanation which agrees with the expert intuition. Future FP cameras equipped with the proposed DQA algorithm will potentially improve the efficacy of the teleophthalmology as well as the traditional system.