 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evaluating the Stability of Deep Image Quality Assessment With Respect to Image Scaling
Jul 20, 2022
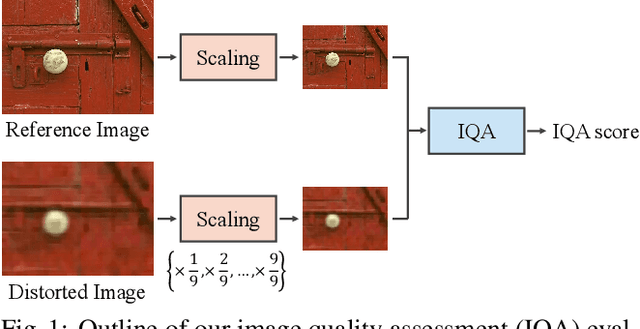

Image quality assessment (IQA) is a fundamental metric for image processing tasks (e.g., compression). With full-reference IQAs, traditional IQAs, such as PSNR and SSIM, have been used. Recently, IQAs based on deep neural networks (deep IQAs), such as LPIPS and DISTS, have also been used. It is known that image scaling is inconsistent among deep IQAs, as some perform down-scaling as pre-processing, whereas others instead use the original image size. In this paper, we show that the image scale is an influential factor that affects deep IQA performance. We comprehensively evaluate four deep IQAs on the same five datasets, and the experimental results show that image scale significantly influences IQA performance. We found that the most appropriate image scale is often neither the default nor the original size, and the choice differs depending on the methods and datasets used. We visualized the stability and found that PieAPP is the most stable among the four deep IQAs.
Disentanglement of Latent Representations via Sparse Causal Interventions
Feb 02, 2023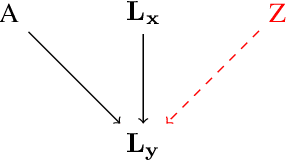
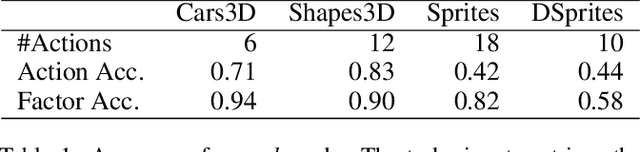
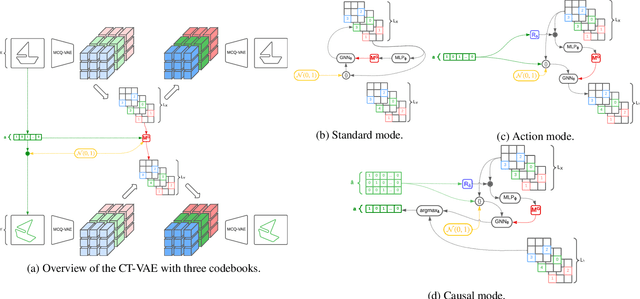

The process of generating data such as images is controlled by independent and unknown factors of variation. The retrieval of these variables has been studied extensively in the disentanglement, causal representation learning, and independent component analysis fields. Recently, approaches merging these domains together have shown great success. Instead of directly representing the factors of variation, the problem of disentanglement can be seen as finding the interventions on one image that yield a change to a single factor. Following this assumption, we introduce a new method for disentanglement inspired by causal dynamics that combines causality theory with vector-quantized variational autoencoders. Our model considers the quantized vectors as causal variables and links them in a causal graph. It performs causal interventions on the graph and generates atomic transitions affecting a unique factor of variation in the image. We also introduce a new task of action retrieval that consists of finding the action responsible for the transition between two images. We test our method on standard synthetic and real-world disentanglement datasets. We show that it can effectively disentangle the factors of variation and perform precise interventions on high-level semantic attributes of an image without affecting its quality, even with imbalanced data distributions.
Uncovering Bias in Face Generation Models
Feb 22, 2023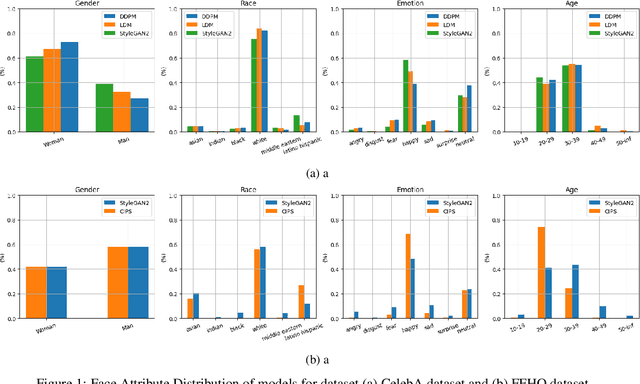
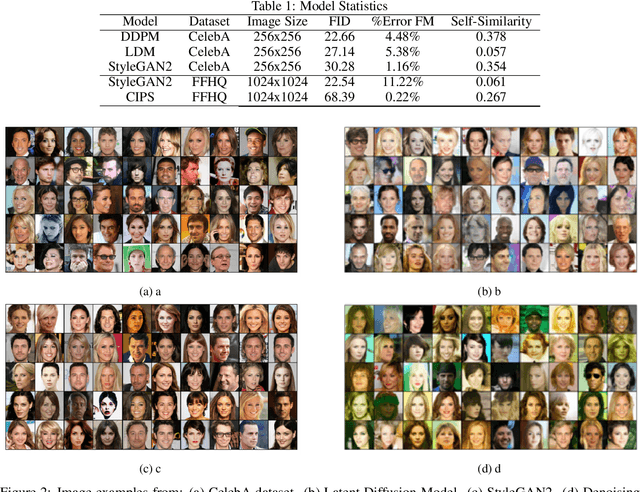

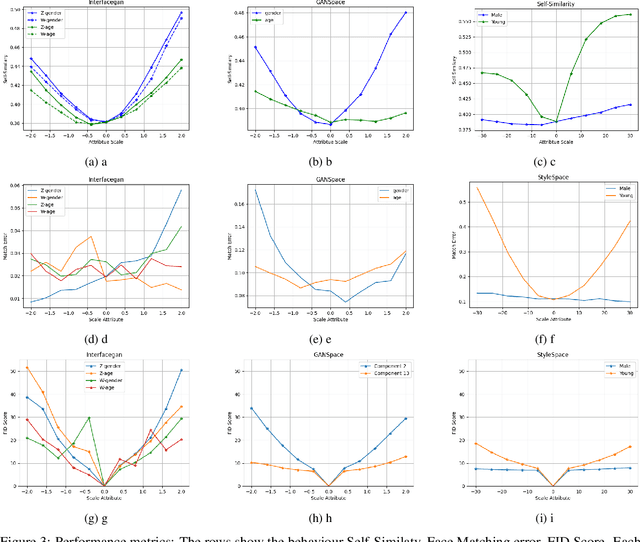
Recent advancements in GANs and diffusion models have enabled the creation of high-resolution, hyper-realistic images. However, these models may misrepresent certain social groups and present bias. Understanding bias in these models remains an important research question, especially for tasks that support critical decision-making and could affect minorities. The contribution of this work is a novel analysis covering architectures and embedding spaces for fine-grained understanding of bias over three approaches: generators, attribute modifier, and post-processing bias mitigators. This work shows that generators suffer from bias across all social groups with attribute preferences such as between 75%-85% for whiteness and 60%-80% for the female gender (for all trained CelebA models) and low probabilities of generating children and older men. Modifier and mitigators work as post-processor and change the generator performance. For instance, attribute channel perturbation strategies modify the embedding spaces. We quantify the influence of this change on group fairness by measuring the impact on image quality and group features. Specifically, we use the Fr\'echet Inception Distance (FID), the Face Matching Error and the Self-Similarity score. For Interfacegan, we analyze one and two attribute channel perturbations and examine the effect on the fairness distribution and the quality of the image. Finally, we analyzed the post-processing bias mitigators, which are the fastest and most computationally efficient way to mitigate bias. We find that these mitigation techniques show similar results on KL divergence and FID score, however, self-similarity scores show a different feature concentration on the new groups of the data distribution. The weaknesses and ongoing challenges described in this work must be considered in the pursuit of creating fair and unbiased face generation models.
Representation Learning of Image Schema
Jul 17, 2022
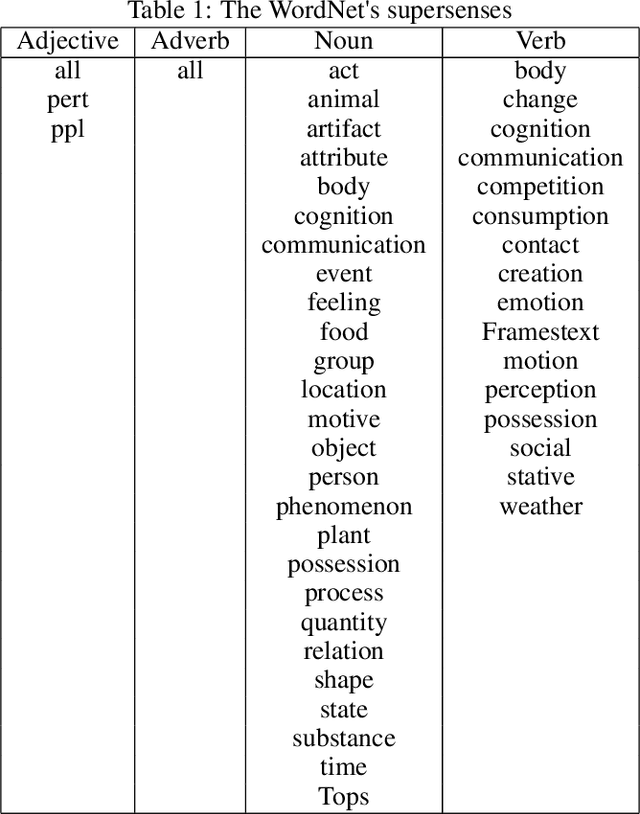
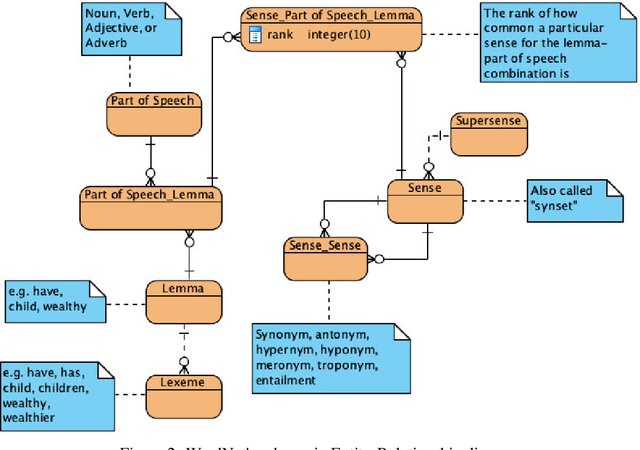
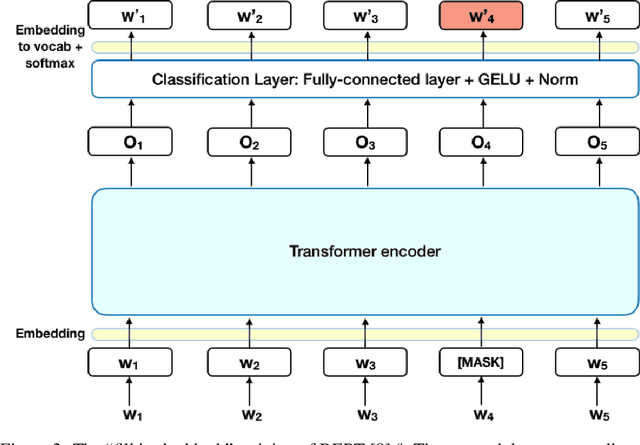
Image schema is a recurrent pattern of reasoning where one entity is mapped into another. Image schema is similar to conceptual metaphor and is also related to metaphoric gesture. Our main goal is to generate metaphoric gestures for an Embodied Conversational Agent. We propose a technique to learn the vector representation of image schemas. As far as we are aware of, this is the first work which addresses that problem. Our technique uses Ravenet et al's algorithm which we use to compute the image schemas from the text input and also BERT and SenseBERT which we use as the base word embedding technique to calculate the final vector representation of the image schema. Our representation learning technique works by clustering: word embedding vectors which belong to the same image schema should be relatively closer to each other, and thus form a cluster. With the image schemas representable as vectors, it also becomes possible to have a notion that some image schemas are closer or more similar to each other than to the others because the distance between the vectors is a proxy of the dissimilarity between the corresponding image schemas. Therefore, after obtaining the vector representation of the image schemas, we calculate the distances between those vectors. Based on these, we create visualizations to illustrate the relative distances between the different image schemas.
Cross-Modal Fusion Distillation for Fine-Grained Sketch-Based Image Retrieval
Oct 19, 2022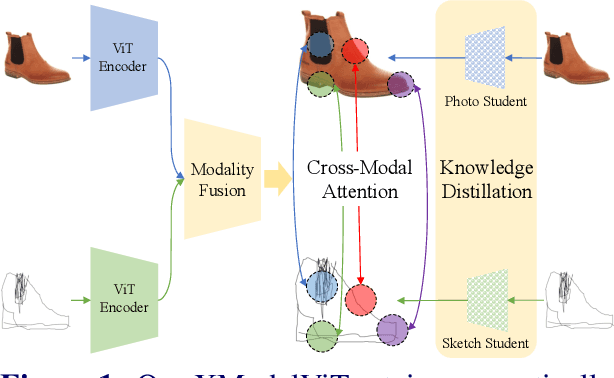
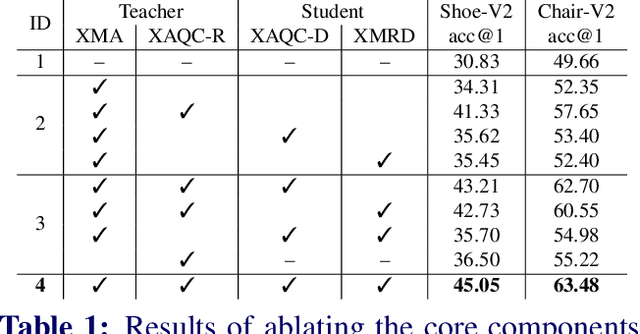

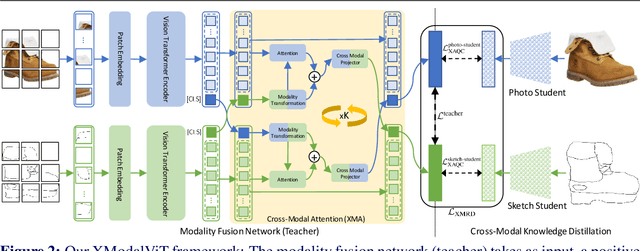
Representation learning for sketch-based image retrieval has mostly been tackled by learning embeddings that discard modality-specific information. As instances from different modalities can often provide complementary information describing the underlying concept, we propose a cross-attention framework for Vision Transformers (XModalViT) that fuses modality-specific information instead of discarding them. Our framework first maps paired datapoints from the individual photo and sketch modalities to fused representations that unify information from both modalities. We then decouple the input space of the aforementioned modality fusion network into independent encoders of the individual modalities via contrastive and relational cross-modal knowledge distillation. Such encoders can then be applied to downstream tasks like cross-modal retrieval. We demonstrate the expressive capacity of the learned representations by performing a wide range of experiments and achieving state-of-the-art results on three fine-grained sketch-based image retrieval benchmarks: Shoe-V2, Chair-V2 and Sketchy. Implementation is available at https://github.com/abhrac/xmodal-vit.
Understanding Social Media Cross-Modality Discourse in Linguistic Space
Feb 26, 2023

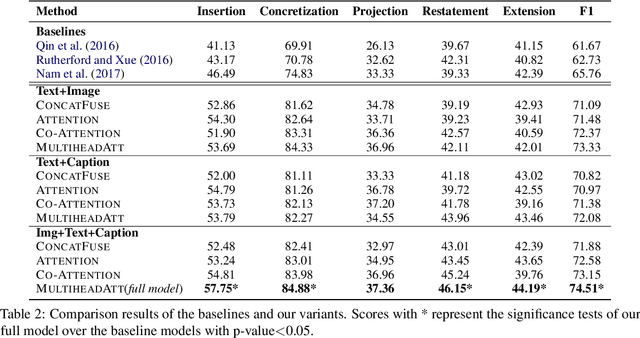
The multimedia communications with texts and images are popular on social media. However, limited studies concern how images are structured with texts to form coherent meanings in human cognition. To fill in the gap, we present a novel concept of cross-modality discourse, reflecting how human readers couple image and text understandings. Text descriptions are first derived from images (named as subtitles) in the multimedia contexts. Five labels -- entity-level insertion, projection and concretization and scene-level restatement and extension -- are further employed to shape the structure of subtitles and texts and present their joint meanings. As a pilot study, we also build the very first dataset containing 16K multimedia tweets with manually annotated discourse labels. The experimental results show that the multimedia encoder based on multi-head attention with captions is able to obtain the-state-of-the-art results.
Improving Long-tailed Object Detection with Image-Level Supervision by Multi-Task Collaborative Learning
Oct 11, 2022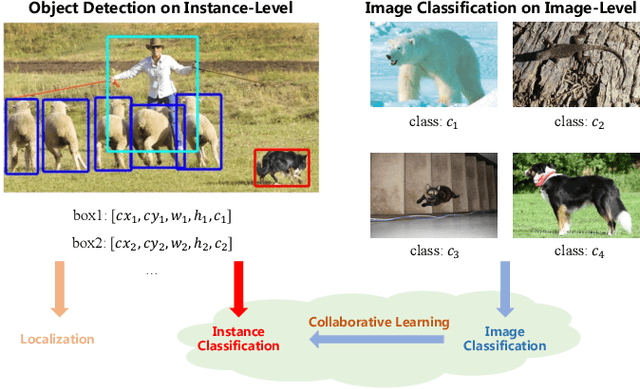
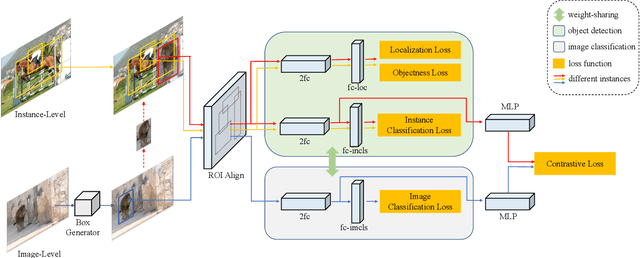
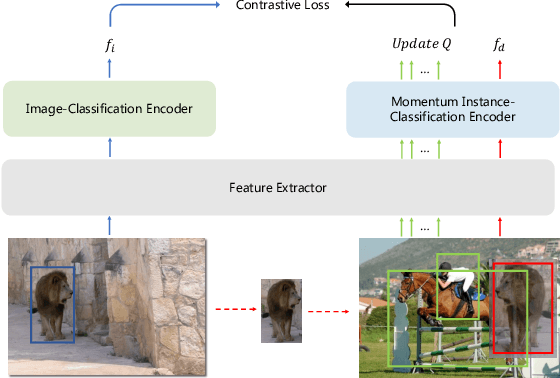

Data in real-world object detection often exhibits the long-tailed distribution. Existing solutions tackle this problem by mitigating the competition between the head and tail categories. However, due to the scarcity of training samples, tail categories are still unable to learn discriminative representations. Bringing more data into the training may alleviate the problem, but collecting instance-level annotations is an excruciating task. In contrast, image-level annotations are easily accessible but not fully exploited. In this paper, we propose a novel framework CLIS (multi-task Collaborative Learning with Image-level Supervision), which leverage image-level supervision to enhance the detection ability in a multi-task collaborative way. Specifically, there are an object detection task (consisting of an instance-classification task and a localization task) and an image-classification task in our framework, responsible for utilizing the two types of supervision. Different tasks are trained collaboratively by three key designs: (1) task-specialized sub-networks that learn specific representations of different tasks without feature entanglement. (2) a siamese sub-network for the image-classification task that shares its knowledge with the instance-classification task, resulting in feature enrichment of detectors. (3) a contrastive learning regularization that maintains representation consistency, bridging feature gaps of different supervision. Extensive experiments are conducted on the challenging LVIS dataset. Without sophisticated loss engineering, CLIS achieves an overall AP of 31.1 with 10.1 point improvement on tail categories, establishing a new state-of-the-art. Code will be at https://github.com/waveboo/CLIS.
Targeted Image Reconstruction by Sampling Pre-trained Diffusion Model
Jan 18, 2023
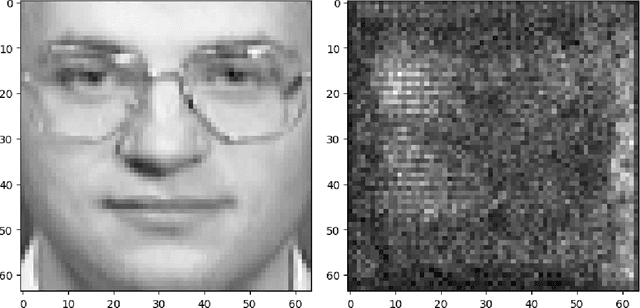
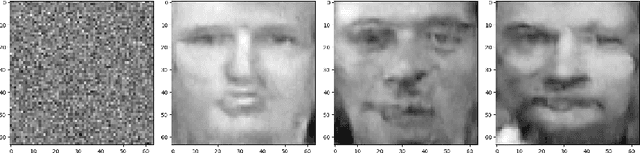

A trained neural network model contains information on the training data. Given such a model, malicious parties can leverage the "knowledge" in this model and design ways to print out any usable information (known as model inversion attack). Therefore, it is valuable to explore the ways to conduct a such attack and demonstrate its severity. In this work, we proposed ways to generate a data point of the target class without prior knowledge of the exact target distribution by using a pre-trained diffusion model.
DeepGD: A Multi-Objective Black-Box Test Selection Approach for Deep Neural Networks
Mar 08, 2023
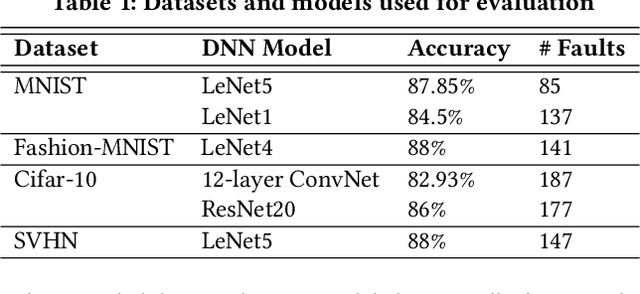
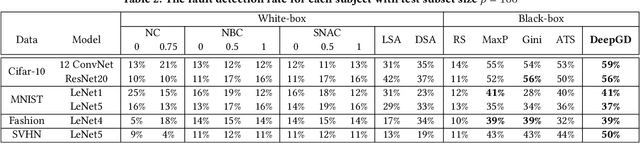
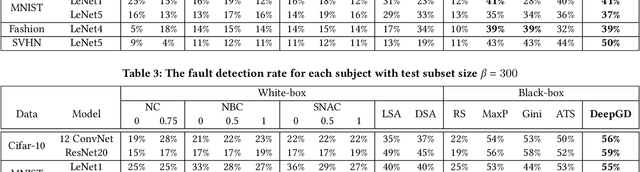
Deep neural networks (DNNs) are widely used in various application domains such as image processing, speech recognition, and natural language processing. However, testing DNN models may be challenging due to the complexity and size of their input domain. Particularly, testing DNN models often requires generating or exploring large unlabeled datasets. In practice, DNN test oracles, which identify the correct outputs for inputs, often require expensive manual effort to label test data, possibly involving multiple experts to ensure labeling correctness. In this paper, we propose DeepGD, a black-box multi-objective test selection approach for DNN models. It reduces the cost of labeling by prioritizing the selection of test inputs with high fault revealing power from large unlabeled datasets. DeepGD not only selects test inputs with high uncertainty scores to trigger as many mispredicted inputs as possible but also maximizes the probability of revealing distinct faults in the DNN model by selecting diverse mispredicted inputs. The experimental results conducted on four widely used datasets and five DNN models show that in terms of fault-revealing ability: (1) White-box, coverage-based approaches fare poorly, (2) DeepGD outperforms existing black-box test selection approaches in terms of fault detection, and (3) DeepGD also leads to better guidance for DNN model retraining when using selected inputs to augment the training set.
Spectral2Spectral: Image-spectral Similarity Assisted Spectral CT Deep Reconstruction without Reference
Oct 03, 2022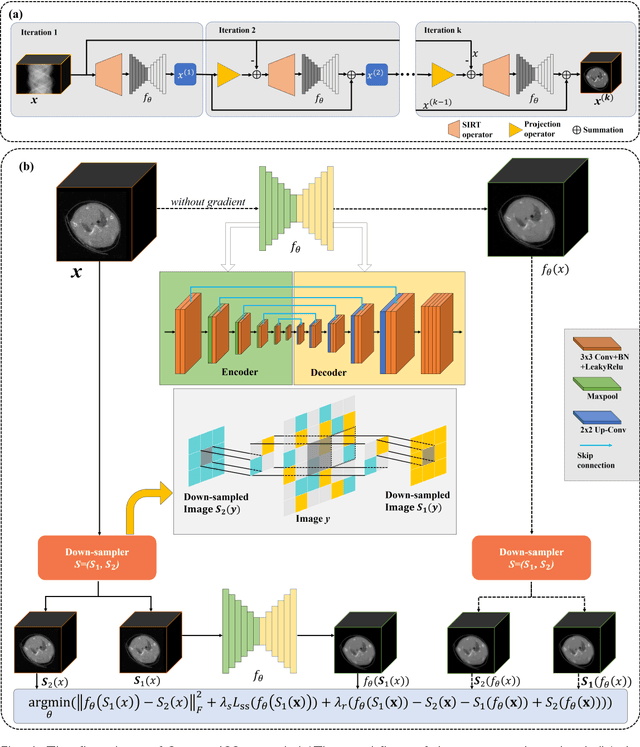
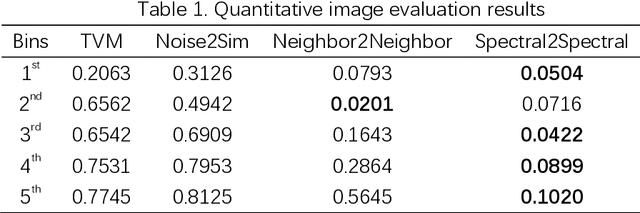

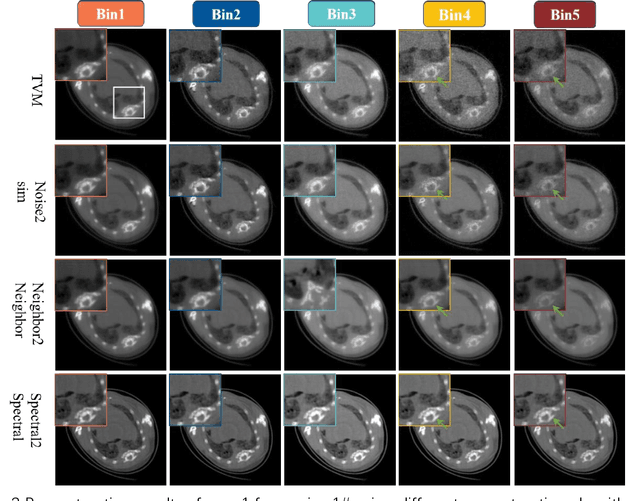
The photon-counting detector (PCD) based spectral computed tomography attracts much more attentions since it has the capability to provide more accurate identification and quantitative analysis for biomedical materials. The limited number of photons within narrow energy-bin leads to low signal-noise ratio data. The existing supervised deep reconstruction networks for CT reconstruction are difficult to address these challenges. In this paper, we propose an iterative deep reconstruction network to synergize model and data priors into a unified framework, named as Spectral2Spectral. Our Spectral2Spectral employs an unsupervised deep training strategy to obtain high-quality images from noisy data with an end-to-end fashion. The structural similarity prior within image-spectral domain is refined as a regularization term to further constrain the network training. The weights of neural network are automatically updated to capture image features and structures with iterative process. Three large-scale preclinical datasets experiments demonstrate that the Spectral2spectral reconstruct better image quality than other state-of-the-art methods.