 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient Informed Proposals for Discrete Distributions via Newton's Series Approximation
Feb 27, 2023
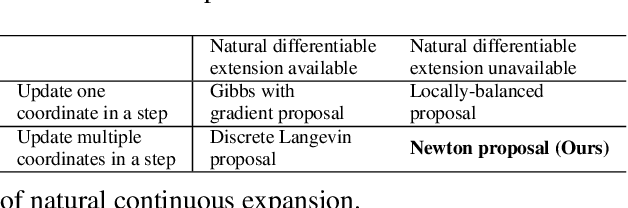
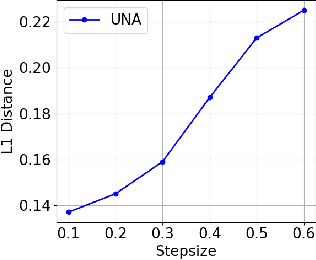
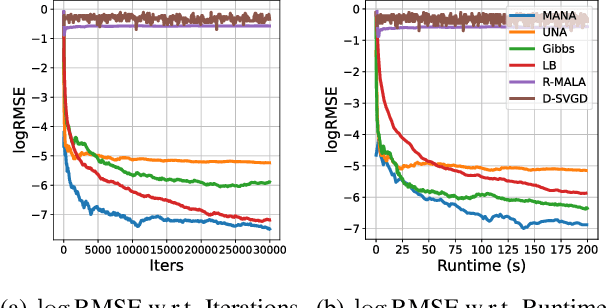

Gradients have been exploited in proposal distributions to accelerate the convergence of Markov chain Monte Carlo algorithms on discrete distributions. However, these methods require a natural differentiable extension of the target discrete distribution, which often does not exist or does not provide effective gradient guidance. In this paper, we develop a gradient-like proposal for any discrete distribution without this strong requirement. Built upon a locally-balanced proposal, our method efficiently approximates the discrete likelihood ratio via Newton's series expansion to enable a large and efficient exploration in discrete spaces. We show that our method can also be viewed as a multilinear extension, thus inheriting its desired properties. We prove that our method has a guaranteed convergence rate with or without the Metropolis-Hastings step. Furthermore, our method outperforms a number of popular alternatives in several different experiments, including the facility location problem, extractive text summarization, and image retrieval.
6th Place Solution to Google Universal Image Embedding
Oct 17, 2022This paper presents the 6th place solution to the Google Universal Image Embedding competition on Kaggle. Our approach is based on the CLIP architecture, a powerful pre-trained model used to learn visual representation from natural language supervision. We also utilized the SubCenter ArcFace loss with dynamic margins to improve the distinctive power of class separability and embeddings. Finally, a diverse dataset has been created based on the test's set categories and the leaderboard's feedback. By carefully crafting a training scheme to enhance transfer learning, our submission scored 0.685 on the private leaderboard.
Disentanglement of Latent Representations via Sparse Causal Interventions
Feb 02, 2023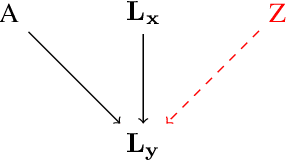
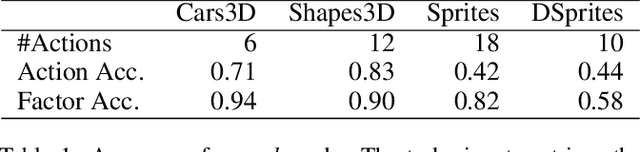
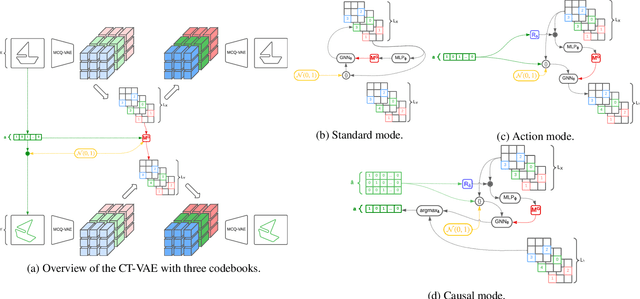

The process of generating data such as images is controlled by independent and unknown factors of variation. The retrieval of these variables has been studied extensively in the disentanglement, causal representation learning, and independent component analysis fields. Recently, approaches merging these domains together have shown great success. Instead of directly representing the factors of variation, the problem of disentanglement can be seen as finding the interventions on one image that yield a change to a single factor. Following this assumption, we introduce a new method for disentanglement inspired by causal dynamics that combines causality theory with vector-quantized variational autoencoders. Our model considers the quantized vectors as causal variables and links them in a causal graph. It performs causal interventions on the graph and generates atomic transitions affecting a unique factor of variation in the image. We also introduce a new task of action retrieval that consists of finding the action responsible for the transition between two images. We test our method on standard synthetic and real-world disentanglement datasets. We show that it can effectively disentangle the factors of variation and perform precise interventions on high-level semantic attributes of an image without affecting its quality, even with imbalanced data distributions.
PartSLIP: Low-Shot Part Segmentation for 3D Point Clouds via Pretrained Image-Language Models
Dec 03, 2022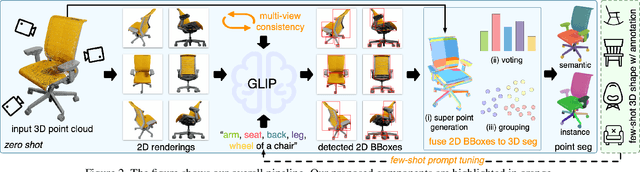
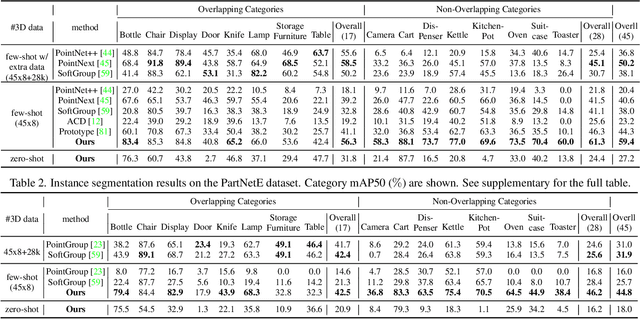
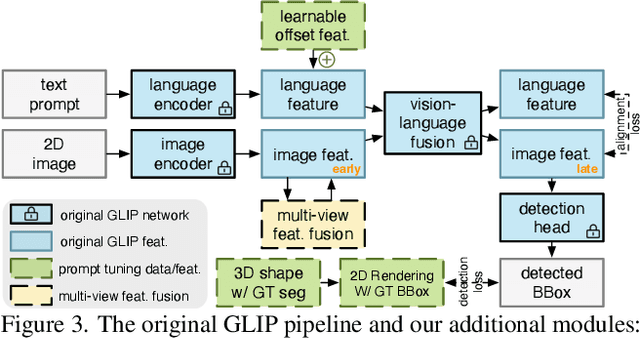
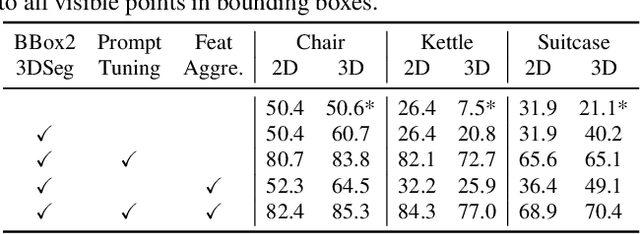
Generalizable 3D part segmentation is important but challenging in vision and robotics. Training deep models via conventional supervised methods requires large-scale 3D datasets with fine-grained part annotations, which are costly to collect. This paper explores an alternative way for low-shot part segmentation of 3D point clouds by leveraging a pretrained image-language model, GLIP, which achieves superior performance on open-vocabulary 2D detection. We transfer the rich knowledge from 2D to 3D through GLIP-based part detection on point cloud rendering and a novel 2D-to-3D label lifting algorithm. We also utilize multi-view 3D priors and few-shot prompt tuning to boost performance significantly. Extensive evaluation on PartNet and PartNet-Mobility datasets shows that our method enables excellent zero-shot 3D part segmentation. Our few-shot version not only outperforms existing few-shot approaches by a large margin but also achieves highly competitive results compared to the fully supervised counterpart. Furthermore, we demonstrate that our method can be directly applied to iPhone-scanned point clouds without significant domain gaps.
EvHandPose: Event-based 3D Hand Pose Estimation with Sparse Supervision
Mar 06, 2023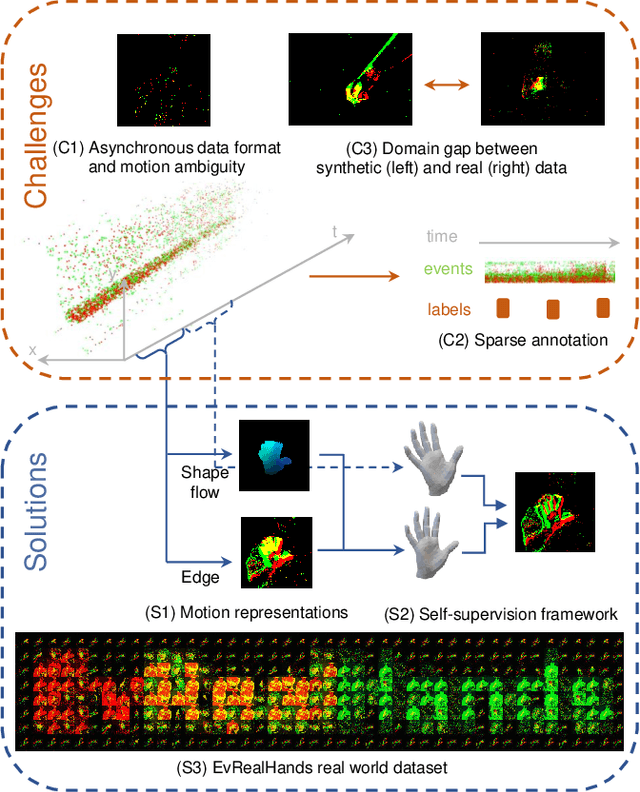

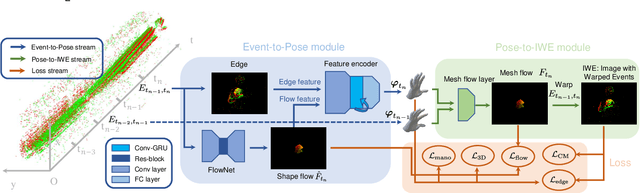

Event camera shows great potential in 3D hand pose estimation, especially addressing the challenges of fast motion and high dynamic range in a low-power way. However, due to the asynchronous differential imaging mechanism, it is challenging to design event representation to encode hand motion information especially when the hands are not moving (causing motion ambiguity), and it is infeasible to fully annotate the temporally dense event stream. In this paper, we propose EvHandPose with novel hand flow representations in Event-to-Pose module for accurate hand pose estimation and alleviating the motion ambiguity issue. To solve the problem under sparse annotation, we design contrast maximization and edge constraints in Pose-to-IWE (Image with Warped Events) module and formulate EvHandPose in a self-supervision framework. We further build EvRealHands, the first large-scale real-world event-based hand pose dataset on several challenging scenes to bridge the domain gap due to relying on synthetic data and facilitate future research. Experiments on EvRealHands demonstrate that EvHandPose outperforms previous event-based method under all evaluation scenes with 15 $\sim$ 20 mm lower MPJPE and achieves accurate and stable hand pose estimation in fast motion and strong light scenes compared with RGB-based methods. Furthermore, EvHandPose demonstrates 3D hand pose estimation at 120 fps or higher.
CLIP-guided Prototype Modulating for Few-shot Action Recognition
Mar 06, 2023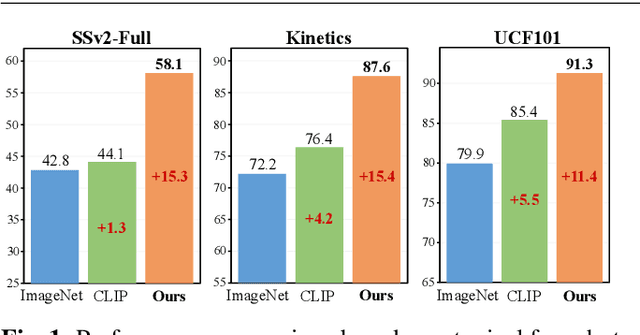
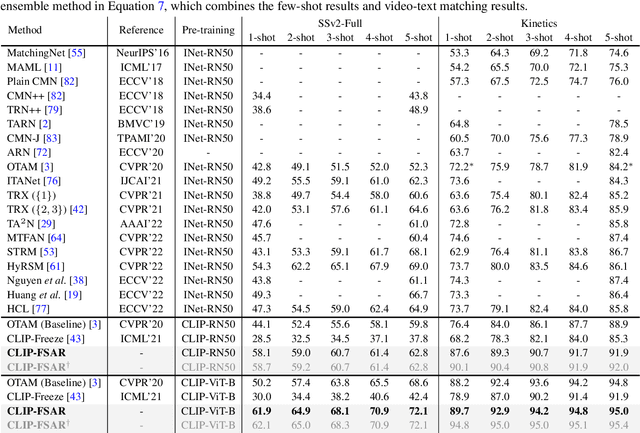
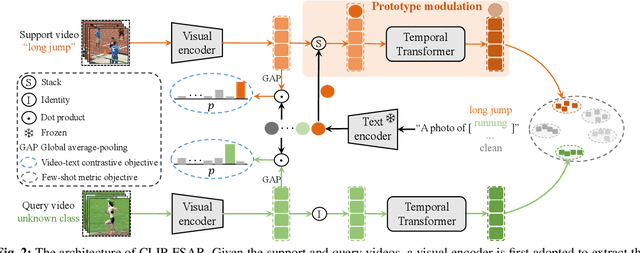
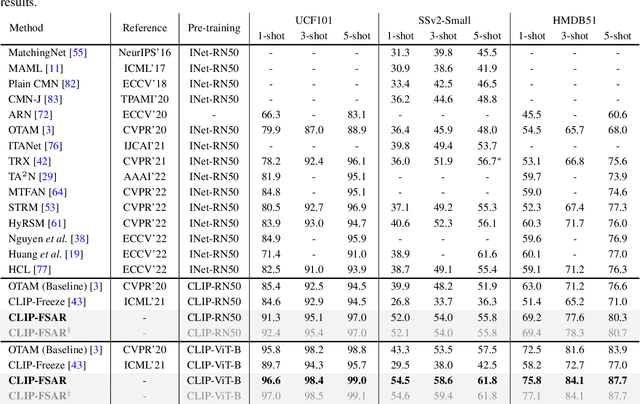
Learning from large-scale contrastive language-image pre-training like CLIP has shown remarkable success in a wide range of downstream tasks recently, but it is still under-explored on the challenging few-shot action recognition (FSAR) task. In this work, we aim to transfer the powerful multimodal knowledge of CLIP to alleviate the inaccurate prototype estimation issue due to data scarcity, which is a critical problem in low-shot regimes. To this end, we present a CLIP-guided prototype modulating framework called CLIP-FSAR, which consists of two key components: a video-text contrastive objective and a prototype modulation. Specifically, the former bridges the task discrepancy between CLIP and the few-shot video task by contrasting videos and corresponding class text descriptions. The latter leverages the transferable textual concepts from CLIP to adaptively refine visual prototypes with a temporal Transformer. By this means, CLIP-FSAR can take full advantage of the rich semantic priors in CLIP to obtain reliable prototypes and achieve accurate few-shot classification. Extensive experiments on five commonly used benchmarks demonstrate the effectiveness of our proposed method, and CLIP-FSAR significantly outperforms existing state-of-the-art methods under various settings. The source code and models will be publicly available at https://github.com/alibaba-mmai-research/CLIP-FSAR.
ST-KeyS: Self-Supervised Transformer for Keyword Spotting in Historical Handwritten Documents
Mar 06, 2023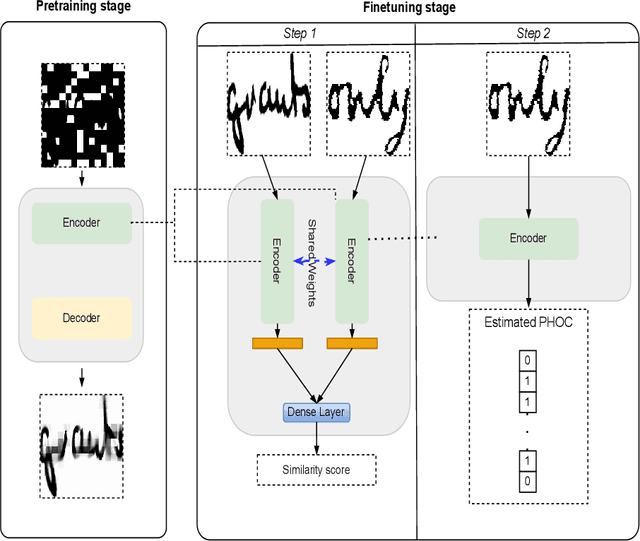

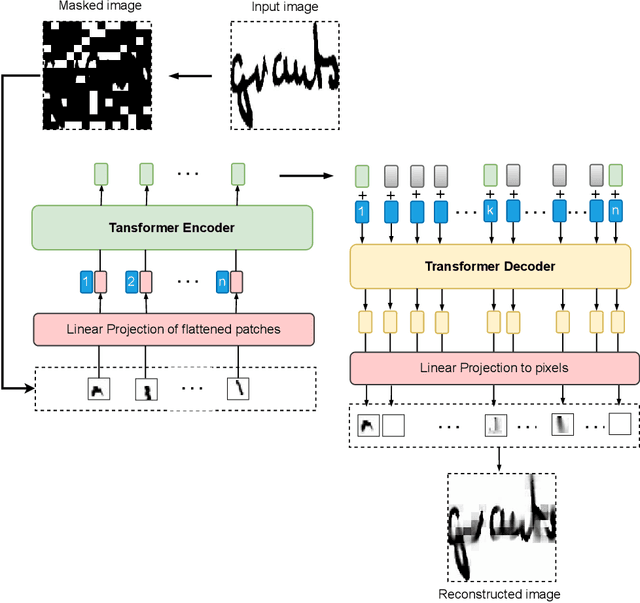
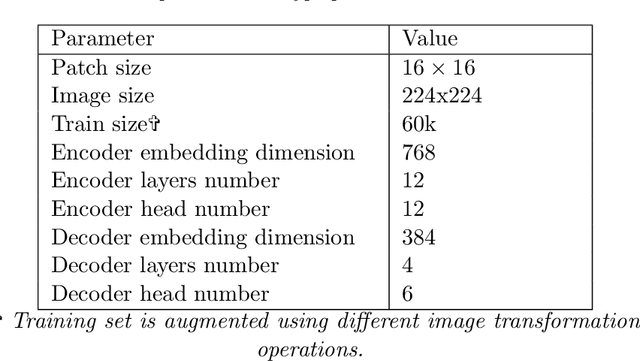
Keyword spotting (KWS) in historical documents is an important tool for the initial exploration of digitized collections. Nowadays, the most efficient KWS methods are relying on machine learning techniques that require a large amount of annotated training data. However, in the case of historical manuscripts, there is a lack of annotated corpus for training. To handle the data scarcity issue, we investigate the merits of the self-supervised learning to extract useful representations of the input data without relying on human annotations and then using these representations in the downstream task. We propose ST-KeyS, a masked auto-encoder model based on vision transformers where the pretraining stage is based on the mask-and-predict paradigm, without the need of labeled data. In the fine-tuning stage, the pre-trained encoder is integrated into a siamese neural network model that is fine-tuned to improve feature embedding from the input images. We further improve the image representation using pyramidal histogram of characters (PHOC) embedding to create and exploit an intermediate representation of images based on text attributes. In an exhaustive experimental evaluation on three widely used benchmark datasets (Botany, Alvermann Konzilsprotokolle and George Washington), the proposed approach outperforms state-of-the-art methods trained on the same datasets.
sMRI-PatchNet: A novel explainable patch-based deep learning network for Alzheimer's disease diagnosis and discriminative atrophy localisation with Structural MRI
Feb 17, 2023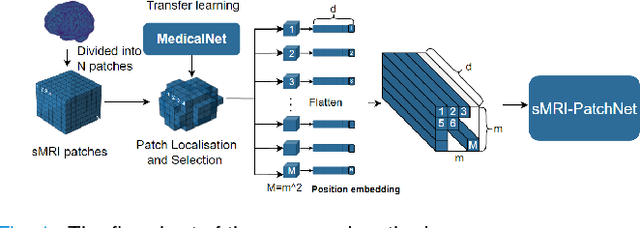
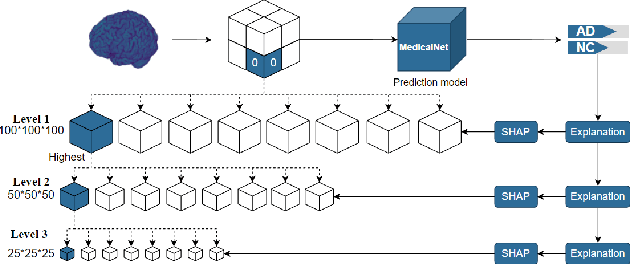

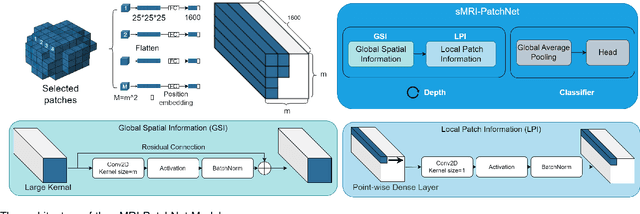
Structural magnetic resonance imaging (sMRI) can identify subtle brain changes due to its high contrast for soft tissues and high spatial resolution. It has been widely used in diagnosing neurological brain diseases, such as Alzheimer disease (AD). However, the size of 3D high-resolution data poses a significant challenge for data analysis and processing. Since only a few areas of the brain show structural changes highly associated with AD, the patch-based methods dividing the whole image data into several small regular patches have shown promising for more efficient sMRI-based image analysis. The major challenges of the patch-based methods on sMRI include identifying the discriminative patches, combining features from the discrete discriminative patches, and designing appropriate classifiers. This work proposes a novel patch-based deep learning network (sMRI-PatchNet) with explainable patch localisation and selection for AD diagnosis using sMRI. Specifically, it consists of two primary components: 1) A fast and efficient explainable patch selection mechanism for determining the most discriminative patches based on computing the SHapley Additive exPlanations (SHAP) contribution to a transfer learning model for AD diagnosis on massive medical data; and 2) A novel patch-based network for extracting deep features and AD classfication from the selected patches with position embeddings to retain position information, capable of capturing the global and local information of inter- and intra-patches. This method has been applied for the AD classification and the prediction of the transitional state moderate cognitive impairment (MCI) conversion with real datasets.
Learnt Deep Hyperparameter selection in Adversarial Training for compressed video enhancement with perceptual critic
Feb 28, 2023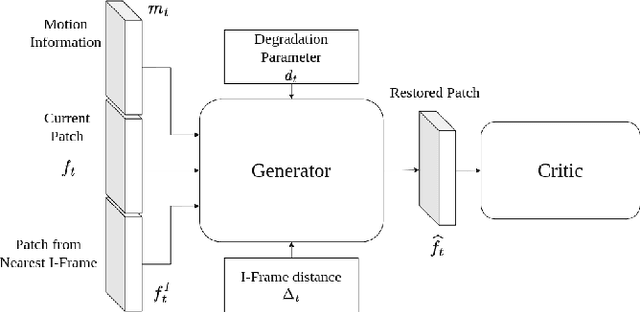
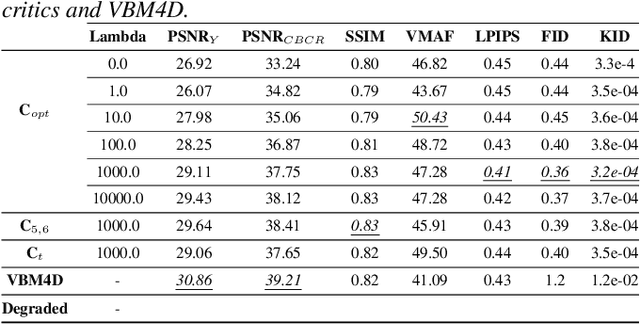
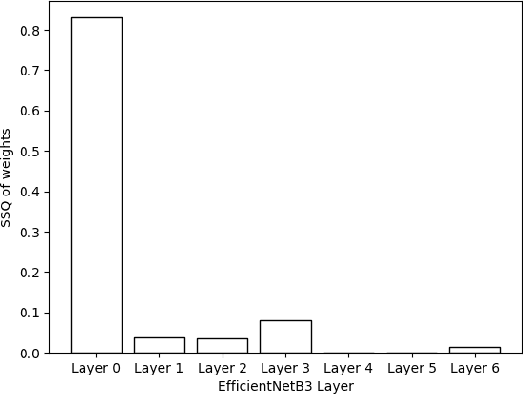
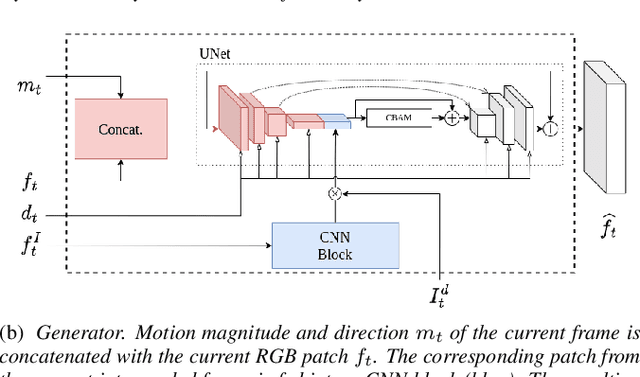
Image based Deep Feature Quality Metrics (DFQMs) have been shown to better correlate with subjective perceptual scores over traditional metrics. The fundamental focus of these DFQMs is to exploit internal representations from a large scale classification network as the metric feature space. Previously, no attention has been given to the problem of identifying which layers are most perceptually relevant. In this paper we present a new method for selecting perceptually relevant layers from such a network, based on a neuroscience interpretation of layer behaviour. The selected layers are treated as a hyperparameter to the critic network in a W-GAN. The critic uses the output from these layers in the preliminary stages to extract perceptual information. A video enhancement network is trained adversarially with this critic. Our results show that the introduction of these selected features into the critic yields up to 10% (FID) and 15% (KID) performance increase against other critic networks that do not exploit the idea of optimised feature selection.
Learning Sparse Control Tasks from Pixels by Latent Nearest-Neighbor-Guided Explorations
Feb 28, 2023
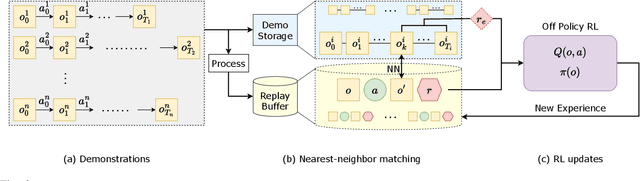


Recent progress in deep reinforcement learning (RL) and computer vision enables artificial agents to solve complex tasks, including locomotion, manipulation and video games from high-dimensional pixel observations. However, domain specific reward functions are often engineered to provide sufficient learning signals, requiring expert knowledge. While it is possible to train vision-based RL agents using only sparse rewards, additional challenges in exploration arise. We present a novel and efficient method to solve sparse-reward robot manipulation tasks from only image observations by utilizing a few demonstrations. First, we learn an embedded neural dynamics model from demonstration transitions and further fine-tune it with the replay buffer. Next, we reward the agents for staying close to the demonstrated trajectories using a distance metric defined in the embedding space. Finally, we use an off-policy, model-free vision RL algorithm to update the control policies. Our method achieves state-of-the-art sample efficiency in simulation and enables efficient training of a real Franka Emika Panda manipulator.