 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A lightweight method for detecting dynamic target occlusions by the robot body
Feb 14, 2023
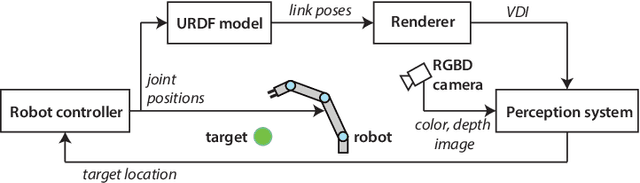

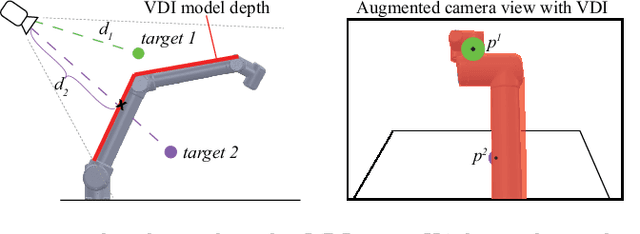

Robot vision is greatly affected by occlusions, which poses challenges to autonomous systems. The robot itself may hide targets of interest from the camera, while it moves within the field of view, leading to failures in task execution. For example, if a target of interest is partially occluded by the robot, detecting and grasping it correctly, becomes very challenging. To solve this problem, we propose a computationally lightweight method to determine the areas that the robot occludes. For this purpose, we use the Unified Robot Description Format (URDF) to generate a virtual depth image of the 3D robot model. Using the virtual depth image, we can effectively determine the partially occluded areas to improve the robustness of the information given by the perception system. Due to the real-time capabilities of the method, it can successfully detect occlusions of moving targets by the moving robot. We validate the effectiveness of the method in an experimental setup using a 6-DoF robot arm and an RGB-D camera by detecting and handling occlusions for two tasks: Pose estimation of a moving object for pickup and human tracking for robot handover. The code is available in \url{https://github.com/auth-arl/virtual\_depth\_image}.
Uncovering Bias in Face Generation Models
Feb 22, 2023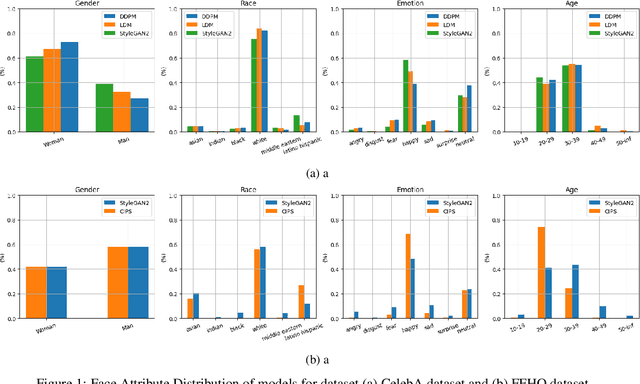
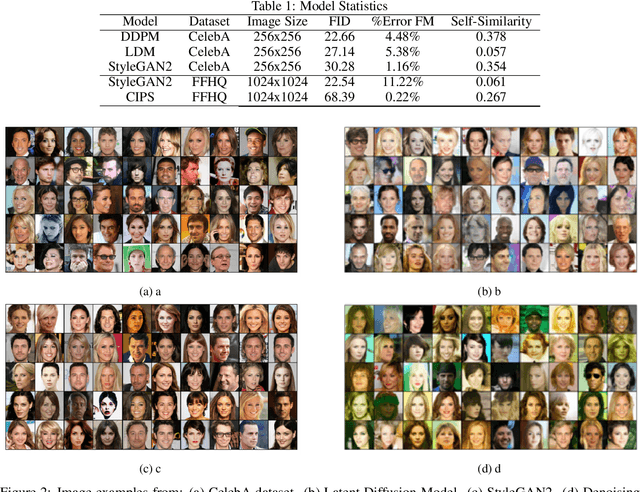

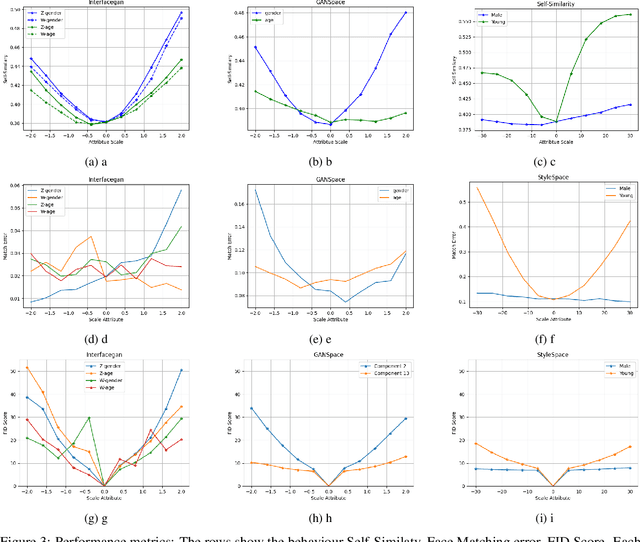
Recent advancements in GANs and diffusion models have enabled the creation of high-resolution, hyper-realistic images. However, these models may misrepresent certain social groups and present bias. Understanding bias in these models remains an important research question, especially for tasks that support critical decision-making and could affect minorities. The contribution of this work is a novel analysis covering architectures and embedding spaces for fine-grained understanding of bias over three approaches: generators, attribute modifier, and post-processing bias mitigators. This work shows that generators suffer from bias across all social groups with attribute preferences such as between 75%-85% for whiteness and 60%-80% for the female gender (for all trained CelebA models) and low probabilities of generating children and older men. Modifier and mitigators work as post-processor and change the generator performance. For instance, attribute channel perturbation strategies modify the embedding spaces. We quantify the influence of this change on group fairness by measuring the impact on image quality and group features. Specifically, we use the Fr\'echet Inception Distance (FID), the Face Matching Error and the Self-Similarity score. For Interfacegan, we analyze one and two attribute channel perturbations and examine the effect on the fairness distribution and the quality of the image. Finally, we analyzed the post-processing bias mitigators, which are the fastest and most computationally efficient way to mitigate bias. We find that these mitigation techniques show similar results on KL divergence and FID score, however, self-similarity scores show a different feature concentration on the new groups of the data distribution. The weaknesses and ongoing challenges described in this work must be considered in the pursuit of creating fair and unbiased face generation models.
Bidirectional Propagation for Cross-Modal 3D Object Detection
Jan 22, 2023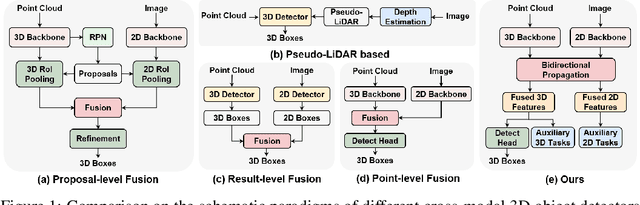
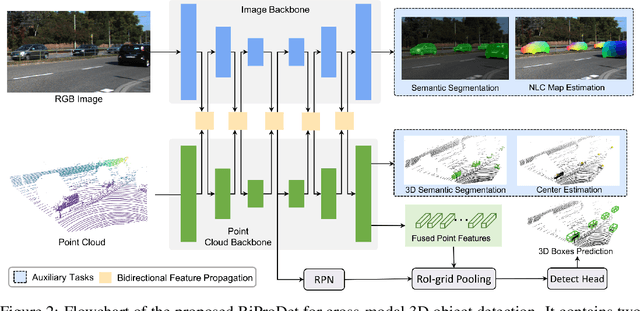
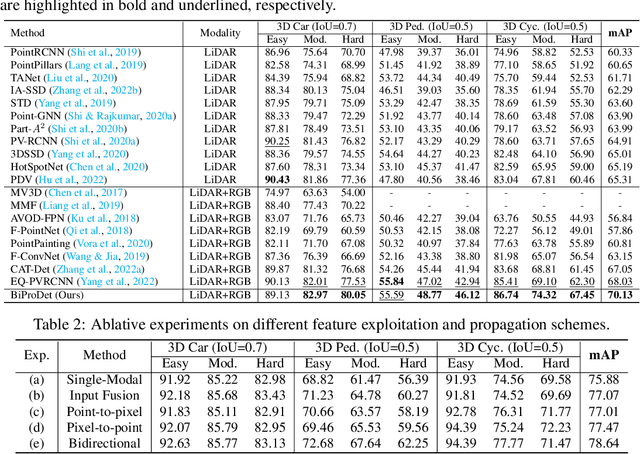
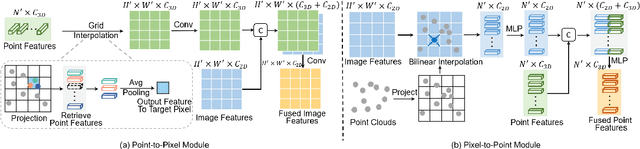
Recent works have revealed the superiority of feature-level fusion for cross-modal 3D object detection, where fine-grained feature propagation from 2D image pixels to 3D LiDAR points has been widely adopted for performance improvement. Still, the potential of heterogeneous feature propagation between 2D and 3D domains has not been fully explored. In this paper, in contrast to existing pixel-to-point feature propagation, we investigate an opposite point-to-pixel direction, allowing point-wise features to flow inversely into the 2D image branch. Thus, when jointly optimizing the 2D and 3D streams, the gradients back-propagated from the 2D image branch can boost the representation ability of the 3D backbone network working on LiDAR point clouds. Then, combining pixel-to-point and point-to-pixel information flow mechanisms, we construct an bidirectional feature propagation framework, dubbed BiProDet. In addition to the architectural design, we also propose normalized local coordinates map estimation, a new 2D auxiliary task for the training of the 2D image branch, which facilitates learning local spatial-aware features from the image modality and implicitly enhances the overall 3D detection performance. Extensive experiments and ablation studies validate the effectiveness of our method. Notably, we rank $\mathbf{1^{\mathrm{st}}}$ on the highly competitive KITTI benchmark on the cyclist class by the time of submission. The source code is available at https://github.com/Eaphan/BiProDet.
Perception-Oriented Single Image Super-Resolution using Optimal Objective Estimation
Nov 28, 2022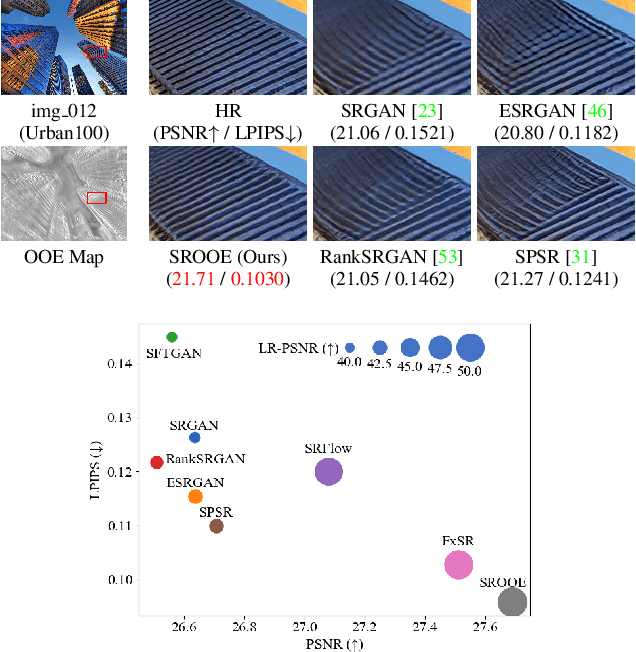
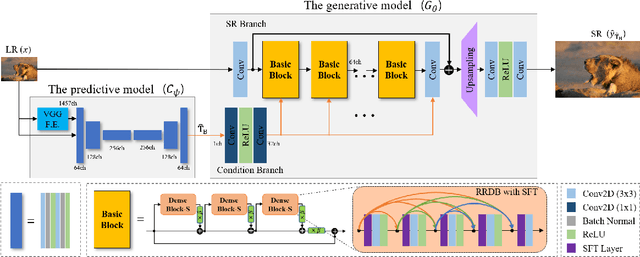
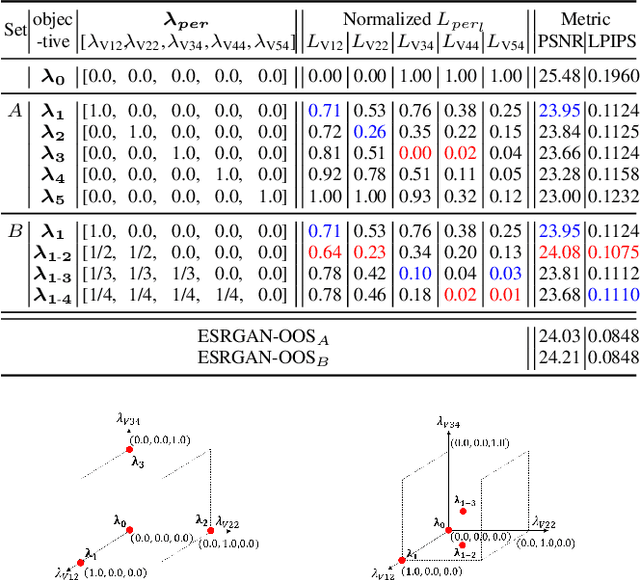
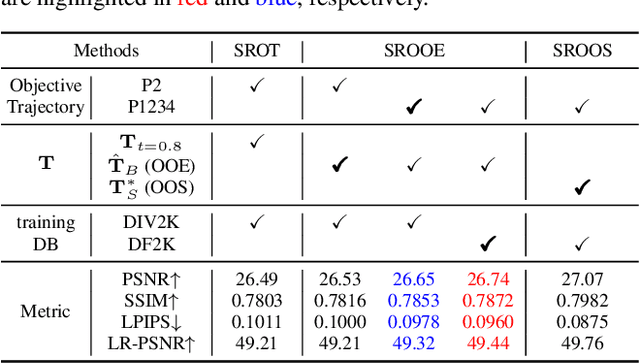
Single-image super-resolution (SISR) networks trained with perceptual and adversarial losses provide high-contrast outputs compared to those of networks trained with distortion-oriented losses, such as L1 or L2. However, it has been shown that using a single perceptual loss is insufficient for accurately restoring locally varying diverse shapes in images, often generating undesirable artifacts or unnatural details. For this reason, combinations of various losses, such as perceptual, adversarial, and distortion losses, have been attempted, yet it remains challenging to find optimal combinations. Hence, in this paper, we propose a new SISR framework that applies optimal objectives for each region to generate plausible results in overall areas of high-resolution outputs. Specifically, the framework comprises two models: a predictive model that infers an optimal objective map for a given low-resolution (LR) input and a generative model that applies a target objective map to produce the corresponding SR output. The generative model is trained over our proposed objective trajectory representing a set of essential objectives, which enables the single network to learn various SR results corresponding to combined losses on the trajectory. The predictive model is trained using pairs of LR images and corresponding optimal objective maps searched from the objective trajectory. Experimental results on five benchmarks show that the proposed method outperforms state-of-the-art perception-driven SR methods in LPIPS, DISTS, PSNR, and SSIM metrics. The visual results also demonstrate the superiority of our method in perception-oriented reconstruction. The code and models are available at https://github.com/seungho-snu/SROOE.
CUTS: A Fully Unsupervised Framework for Medical Image Segmentation
Sep 23, 2022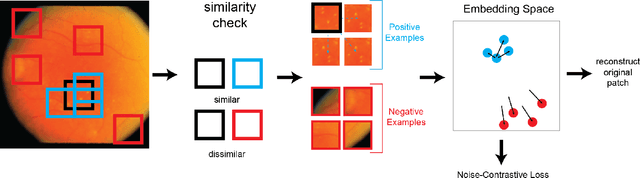

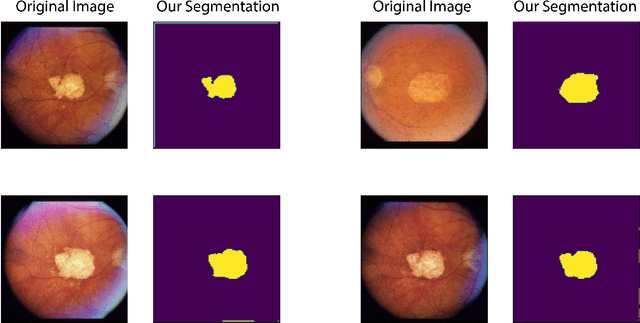
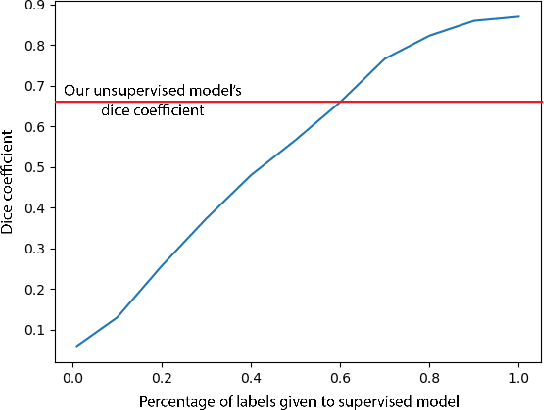
In this work we introduce CUTS (Contrastive and Unsupervised Training for Segmentation) the first fully unsupervised deep learning framework for medical image segmentation, facilitating the use of the vast majority of imaging data that is not labeled or annotated. Segmenting medical images into regions of interest is a critical task for facilitating both patient diagnoses and quantitative research. A major limiting factor in this segmentation is the lack of labeled data, as getting expert annotations for each new set of imaging data or task can be expensive, labor intensive, and inconsistent across annotators: thus, we utilize self-supervision based on pixel-centered patches from the images themselves. Our unsupervised approach is based on a training objective with both contrastive learning and autoencoding aspects. Previous contrastive learning approaches for medical image segmentation have focused on image-level contrastive training, rather than our intra-image patch-level approach or have used this as a pre-training task where the network needed further supervised training afterwards. By contrast, we build the first entirely unsupervised framework that operates at the pixel-centered-patch level. Specifically, we add novel augmentations, a patch reconstruction loss, and introduce a new pixel clustering and identification framework. Our model achieves improved results on several key medical imaging tasks, as verified by held-out expert annotations on the task of segmenting geographic atrophy (GA) regions of images of the retina.
Revising Image-Text Retrieval via Multi-Modal Entailment
Aug 22, 2022

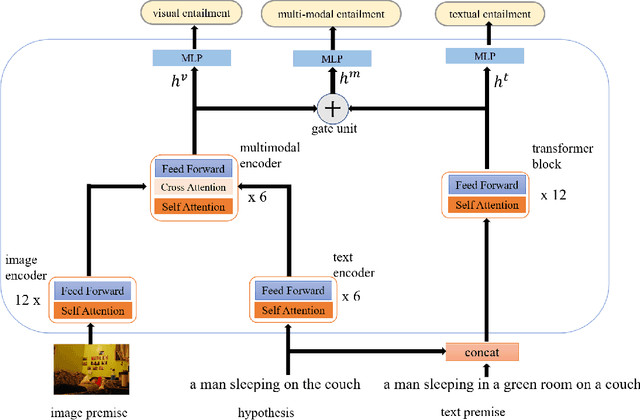
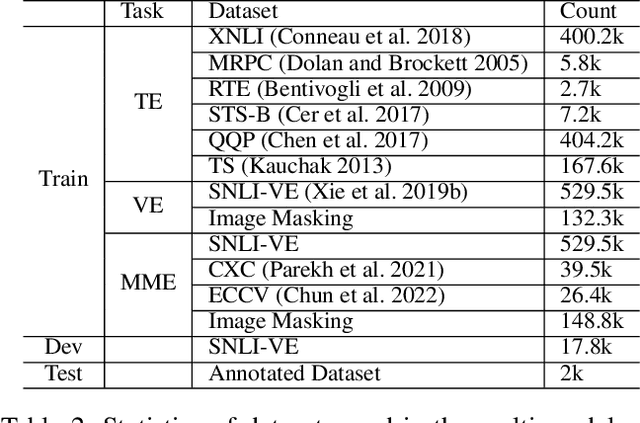
An outstanding image-text retrieval model depends on high-quality labeled data. While the builders of existing image-text retrieval datasets strive to ensure that the caption matches the linked image, they cannot prevent a caption from fitting other images. We observe that such a many-to-many matching phenomenon is quite common in the widely-used retrieval datasets, where one caption can describe up to 178 images. These large matching-lost data not only confuse the model in training but also weaken the evaluation accuracy. Inspired by visual and textual entailment tasks, we propose a multi-modal entailment classifier to determine whether a sentence is entailed by an image plus its linked captions. Subsequently, we revise the image-text retrieval datasets by adding these entailed captions as additional weak labels of an image and develop a universal variable learning rate strategy to teach a retrieval model to distinguish the entailed captions from other negative samples. In experiments, we manually annotate an entailment-corrected image-text retrieval dataset for evaluation. The results demonstrate that the proposed entailment classifier achieves about 78% accuracy and consistently improves the performance of image-text retrieval baselines.
Self-supervised Pseudo-colorizing of Masked Cells
Feb 12, 2023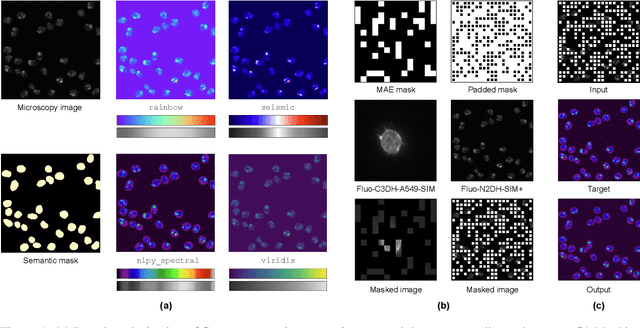
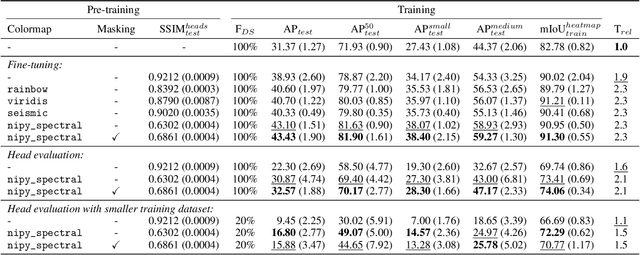
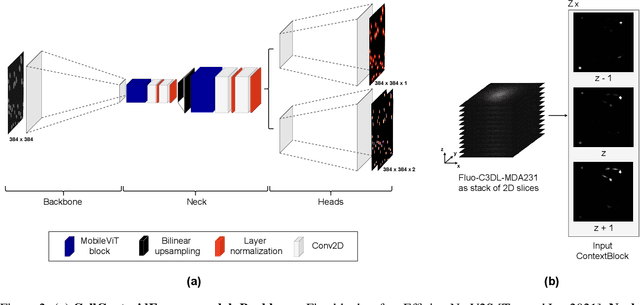
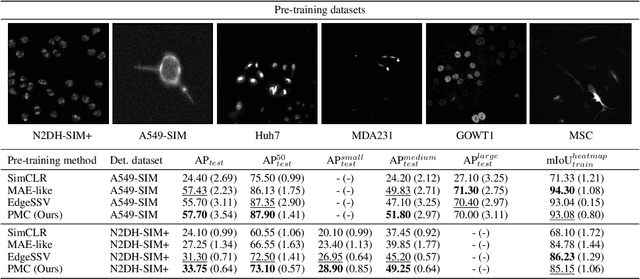
Self-supervised learning, which is strikingly referred to as the dark matter of intelligence, is gaining more attention in biomedical applications of deep learning. In this work, we introduce a novel self-supervision objective for the analysis of cells in biomedical microscopy images. We propose training deep learning models to pseudo-colorize masked cells. We use a physics-informed pseudo-spectral colormap that is well suited for colorizing cell topology. Our experiments reveal that approximating semantic segmentation by pseudo-colorization is beneficial for subsequent fine-tuning on cell detection. Inspired by the recent success of masked image modeling, we additionally mask out cell parts and train to reconstruct these parts to further enrich the learned representations. We compare our pre-training method with self-supervised frameworks including contrastive learning (SimCLR), masked autoencoders (MAEs), and edge-based self-supervision. We build upon our previous work and train hybrid models for cell detection, which contain both convolutional and vision transformer modules. Our pre-training method can outperform SimCLR, MAE-like masked image modeling, and edge-based self-supervision when pre-training on a diverse set of six fluorescence microscopy datasets. Code is available at: https://github.com/roydenwa/cell-centroid-former
POSTER++: A simpler and stronger facial expression recognition network
Feb 12, 2023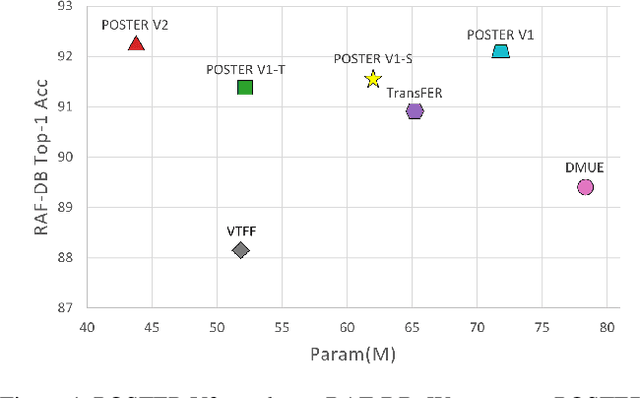

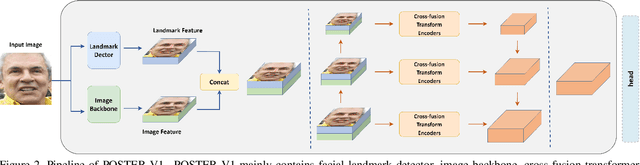
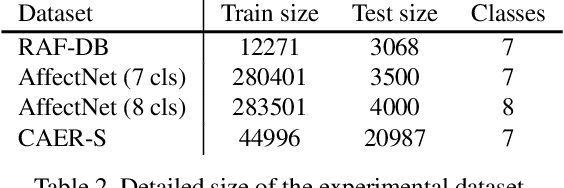
Facial expression recognition (FER) plays an important role in a variety of real-world applications such as human-computer interaction. POSTER achieves the state-of-the-art (SOTA) performance in FER by effectively combining facial landmark and image features through two-stream pyramid cross-fusion design. However, the architecture of POSTER is undoubtedly complex. It causes expensive computational costs. In order to relieve the computational pressure of POSTER, in this paper, we propose POSTER++. It improves POSTER in three directions: cross-fusion, two-stream, and multi-scale feature extraction. In cross-fusion, we use window-based cross-attention mechanism replacing vanilla cross-attention mechanism. We remove the image-to-landmark branch in the two-stream design. For multi-scale feature extraction, POSTER++ combines images with landmark's multi-scale features to replace POSTER's pyramid design. Extensive experiments on several standard datasets show that our POSTER++ achieves the SOTA FER performance with the minimum computational cost. For example, POSTER++ reached 92.21% on RAF-DB, 67.49% on AffectNet (7 cls) and 63.77% on AffectNet (8 cls), respectively, using only 8.4G floating point operations (FLOPs) and 43.7M parameters (Param). This demonstrates the effectiveness of our improvements.
DeepGD: A Multi-Objective Black-Box Test Selection Approach for Deep Neural Networks
Mar 08, 2023
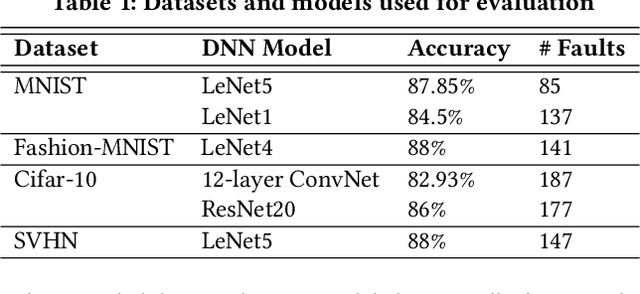
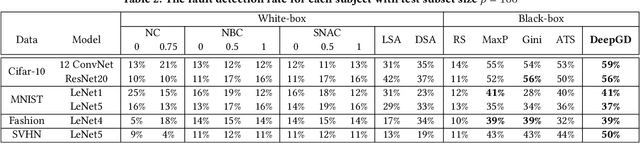
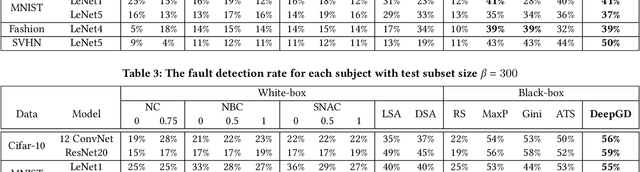
Deep neural networks (DNNs) are widely used in various application domains such as image processing, speech recognition, and natural language processing. However, testing DNN models may be challenging due to the complexity and size of their input domain. Particularly, testing DNN models often requires generating or exploring large unlabeled datasets. In practice, DNN test oracles, which identify the correct outputs for inputs, often require expensive manual effort to label test data, possibly involving multiple experts to ensure labeling correctness. In this paper, we propose DeepGD, a black-box multi-objective test selection approach for DNN models. It reduces the cost of labeling by prioritizing the selection of test inputs with high fault revealing power from large unlabeled datasets. DeepGD not only selects test inputs with high uncertainty scores to trigger as many mispredicted inputs as possible but also maximizes the probability of revealing distinct faults in the DNN model by selecting diverse mispredicted inputs. The experimental results conducted on four widely used datasets and five DNN models show that in terms of fault-revealing ability: (1) White-box, coverage-based approaches fare poorly, (2) DeepGD outperforms existing black-box test selection approaches in terms of fault detection, and (3) DeepGD also leads to better guidance for DNN model retraining when using selected inputs to augment the training set.
Understanding Social Media Cross-Modality Discourse in Linguistic Space
Feb 26, 2023
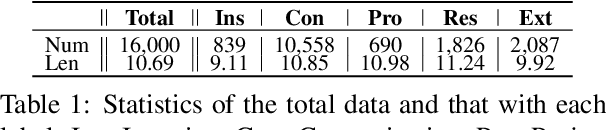

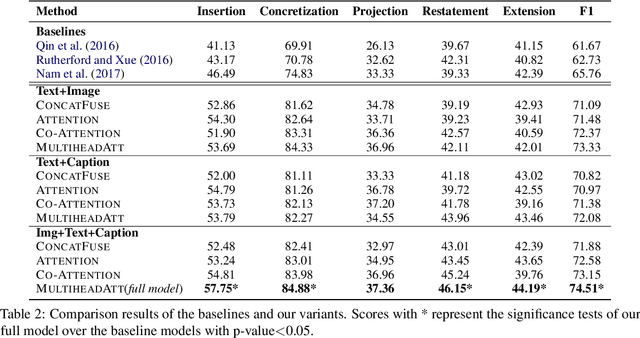
The multimedia communications with texts and images are popular on social media. However, limited studies concern how images are structured with texts to form coherent meanings in human cognition. To fill in the gap, we present a novel concept of cross-modality discourse, reflecting how human readers couple image and text understandings. Text descriptions are first derived from images (named as subtitles) in the multimedia contexts. Five labels -- entity-level insertion, projection and concretization and scene-level restatement and extension -- are further employed to shape the structure of subtitles and texts and present their joint meanings. As a pilot study, we also build the very first dataset containing 16K multimedia tweets with manually annotated discourse labels. The experimental results show that the multimedia encoder based on multi-head attention with captions is able to obtain the-state-of-the-art results.