 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SF2Former: Amyotrophic Lateral Sclerosis Identification From Multi-center MRI Data Using Spatial and Frequency Fusion Transformer
Feb 21, 2023

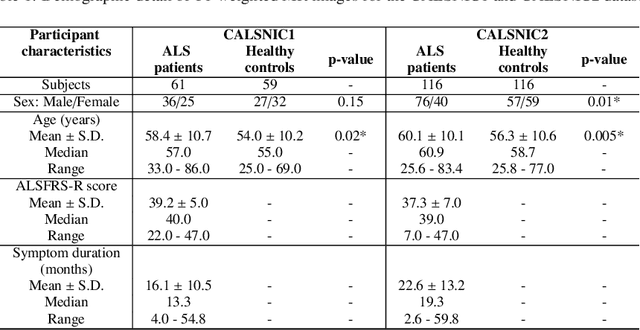
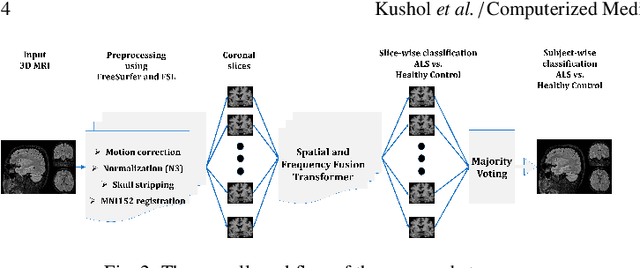
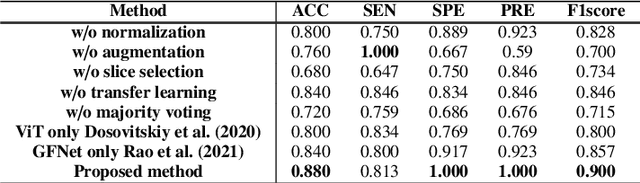
Amyotrophic Lateral Sclerosis (ALS) is a complex neurodegenerative disorder involving motor neuron degeneration. Significant research has begun to establish brain magnetic resonance imaging (MRI) as a potential biomarker to diagnose and monitor the state of the disease. Deep learning has turned into a prominent class of machine learning programs in computer vision and has been successfully employed to solve diverse medical image analysis tasks. However, deep learning-based methods applied to neuroimaging have not achieved superior performance in ALS patients classification from healthy controls due to having insignificant structural changes correlated with pathological features. Therefore, the critical challenge in deep models is to determine useful discriminative features with limited training data. By exploiting the long-range relationship of image features, this study introduces a framework named SF2Former that leverages vision transformer architecture's power to distinguish the ALS subjects from the control group. To further improve the network's performance, spatial and frequency domain information are combined because MRI scans are captured in the frequency domain before being converted to the spatial domain. The proposed framework is trained with a set of consecutive coronal 2D slices, which uses the pre-trained weights on ImageNet by leveraging transfer learning. Finally, a majority voting scheme has been employed to those coronal slices of a particular subject to produce the final classification decision. Our proposed architecture has been thoroughly assessed with multi-modal neuroimaging data using two well-organized versions of the Canadian ALS Neuroimaging Consortium (CALSNIC) multi-center datasets. The experimental results demonstrate the superiority of our proposed strategy in terms of classification accuracy compared with several popular deep learning-based techniques.
Criminal Investigation Tracker with Suspect Prediction using Machine Learning
Feb 21, 2023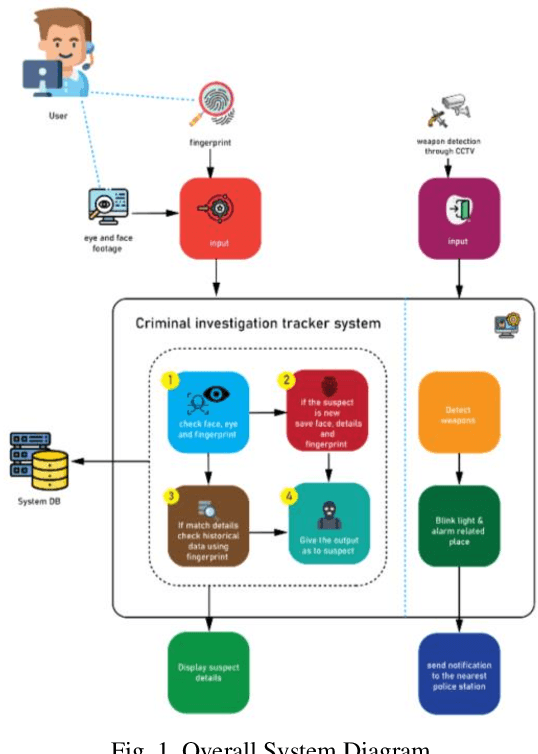

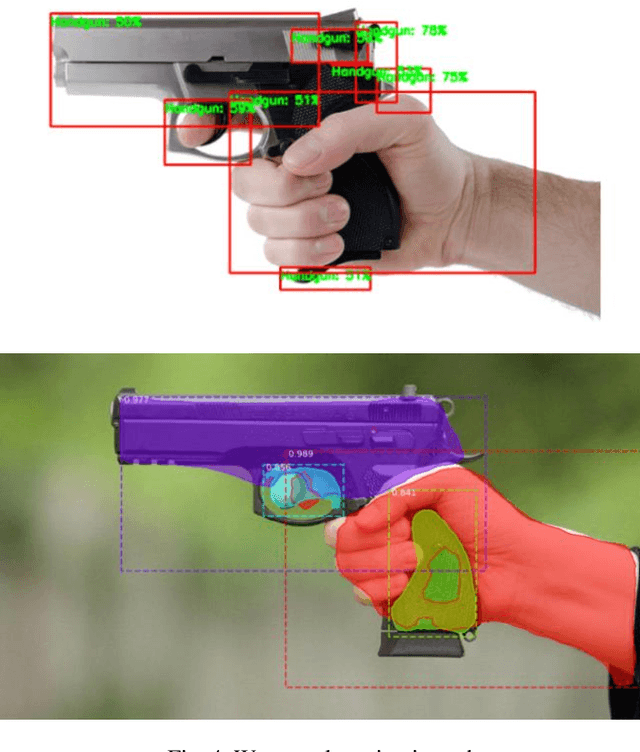
An automated approach to identifying offenders in Sri Lanka would be better than the current system. Obtaining information from eyewitnesses is one of the less reliable approaches and procedures still in use today. Automated criminal identification has the ability to save lives, notwithstanding Sri Lankan culture's lack of awareness of the issue. Using cutting-edge technology like biometrics to finish this task would be the most accurate strategy. The most notable outcomes will be obtained by applying fingerprint and face recognition as biometric techniques. The main responsibilities will be image optimization and criminality. CCTV footage may be used to identify a person's fingerprint, identify a person's face, and identify crimes involving weapons. Additionally, we unveil a notification system and condense the police report to Additionally, to make it simpler for police officers to understand the essential points of the crime, we develop a notification system and condense the police report. Additionally, if an incident involving a weapon is detected, an automated notice of the crime with all the relevant facts is sent to the closest police station. The summarization of the police report is what makes this the most original. In order to improve the efficacy of the overall image, the system will quickly and precisely identify the full crime scene, identify, and recognize the suspects using their faces and fingerprints, and detect firearms. This study provides a novel approach for crime prediction based on real-world data, and criminality incorporation. A crime or occurrence should be reported to the appropriate agencies, and the suggested web application should be improved further to offer a workable channel of communication.
ReDi: Efficient Learning-Free Diffusion Inference via Trajectory Retrieval
Feb 05, 2023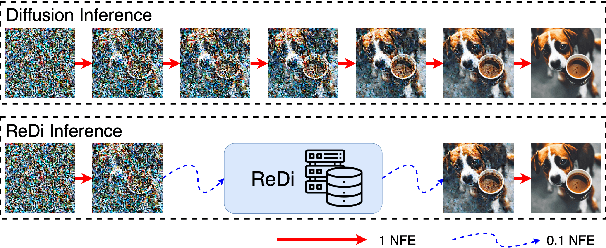

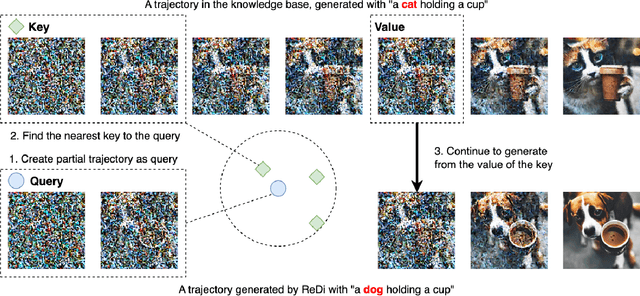
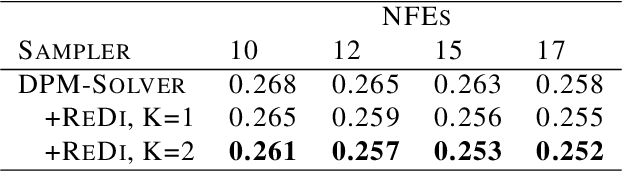
Diffusion models show promising generation capability for a variety of data. Despite their high generation quality, the inference for diffusion models is still time-consuming due to the numerous sampling iterations required. To accelerate the inference, we propose ReDi, a simple yet learning-free Retrieval-based Diffusion sampling framework. From a precomputed knowledge base, ReDi retrieves a trajectory similar to the partially generated trajectory at an early stage of generation, skips a large portion of intermediate steps, and continues sampling from a later step in the retrieved trajectory. We theoretically prove that the generation performance of ReDi is guaranteed. Our experiments demonstrate that ReDi improves the model inference efficiency by 2x speedup. Furthermore, ReDi is able to generalize well in zero-shot cross-domain image generation such as image stylization.
Dual Pyramid Generative Adversarial Networks for Semantic Image Synthesis
Oct 08, 2022



The goal of semantic image synthesis is to generate photo-realistic images from semantic label maps. It is highly relevant for tasks like content generation and image editing. Current state-of-the-art approaches, however, still struggle to generate realistic objects in images at various scales. In particular, small objects tend to fade away and large objects are often generated as collages of patches. In order to address this issue, we propose a Dual Pyramid Generative Adversarial Network (DP-GAN) that learns the conditioning of spatially-adaptive normalization blocks at all scales jointly, such that scale information is bi-directionally used, and it unifies supervision at different scales. Our qualitative and quantitative results show that the proposed approach generates images where small and large objects look more realistic compared to images generated by state-of-the-art methods.
Novel 3D Scene Understanding Applications From Recurrence in a Single Image
Oct 14, 2022


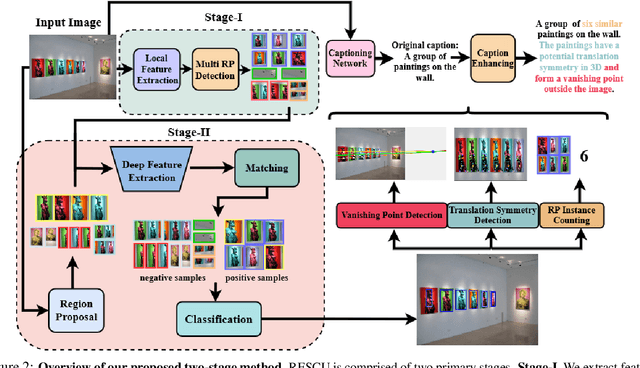
We demonstrate the utility of recurring pattern discovery from a single image for spatial understanding of a 3D scene in terms of (1) vanishing point detection, (2) hypothesizing 3D translation symmetry and (3) counting the number of RP instances in the image. Furthermore, we illustrate the feasibility of leveraging RP discovery output to form a more precise, quantitative text description of the scene. Our quantitative evaluations on a new 1K+ Recurring Pattern (RP) benchmark with diverse variations show that visual perception of recurrence from one single view leads to scene understanding outcomes that are as good as or better than existing supervised methods and/or unsupervised methods that use millions of images.
Analysing the effectiveness of a generative model for semi-supervised medical image segmentation
Nov 03, 2022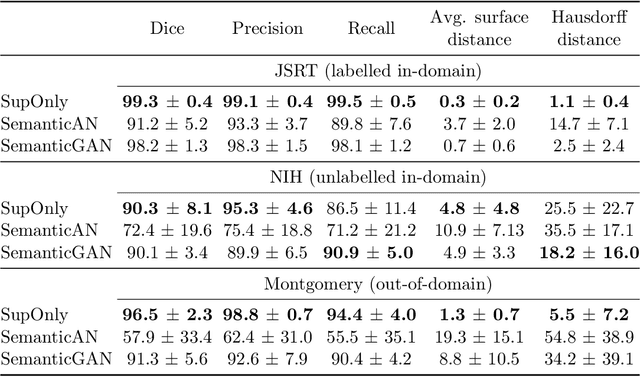
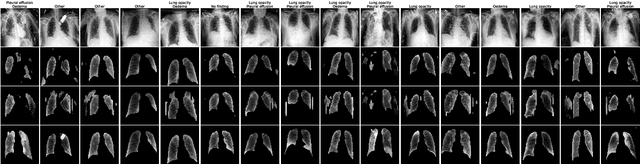
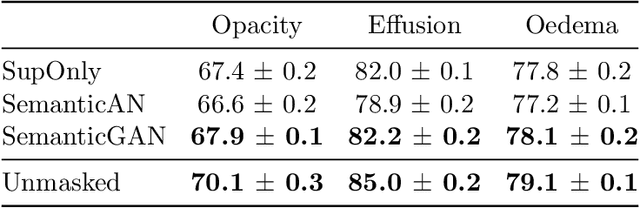

Image segmentation is important in medical imaging, providing valuable, quantitative information for clinical decision-making in diagnosis, therapy, and intervention. The state-of-the-art in automated segmentation remains supervised learning, employing discriminative models such as U-Net. However, training these models requires access to large amounts of manually labelled data which is often difficult to obtain in real medical applications. In such settings, semi-supervised learning (SSL) attempts to leverage the abundance of unlabelled data to obtain more robust and reliable models. Recently, generative models have been proposed for semantic segmentation, as they make an attractive choice for SSL. Their ability to capture the joint distribution over input images and output label maps provides a natural way to incorporate information from unlabelled images. This paper analyses whether deep generative models such as the SemanticGAN are truly viable alternatives to tackle challenging medical image segmentation problems. To that end, we thoroughly evaluate the segmentation performance, robustness, and potential subgroup disparities of discriminative and generative segmentation methods when applied to large-scale, publicly available chest X-ray datasets.
Efficient Single-Image Depth Estimation on Mobile Devices, Mobile AI & AIM 2022 Challenge: Report
Nov 07, 2022

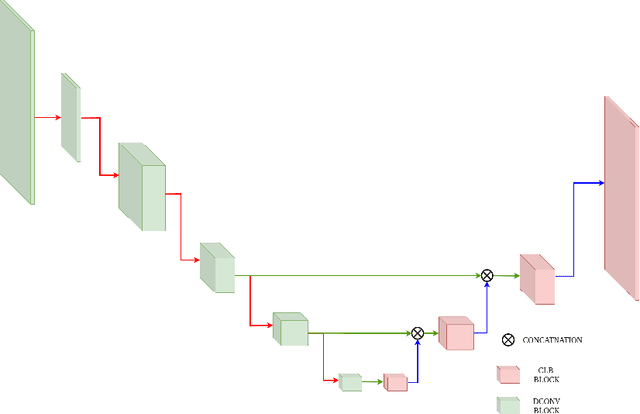
Various depth estimation models are now widely used on many mobile and IoT devices for image segmentation, bokeh effect rendering, object tracking and many other mobile tasks. Thus, it is very crucial to have efficient and accurate depth estimation models that can run fast on low-power mobile chipsets. In this Mobile AI challenge, the target was to develop deep learning-based single image depth estimation solutions that can show a real-time performance on IoT platforms and smartphones. For this, the participants used a large-scale RGB-to-depth dataset that was collected with the ZED stereo camera capable to generated depth maps for objects located at up to 50 meters. The runtime of all models was evaluated on the Raspberry Pi 4 platform, where the developed solutions were able to generate VGA resolution depth maps at up to 27 FPS while achieving high fidelity results. All models developed in the challenge are also compatible with any Android or Linux-based mobile devices, their detailed description is provided in this paper.
On the Feasibility of Machine Learning Augmented Magnetic Resonance for Point-of-Care Identification of Disease
Feb 02, 2023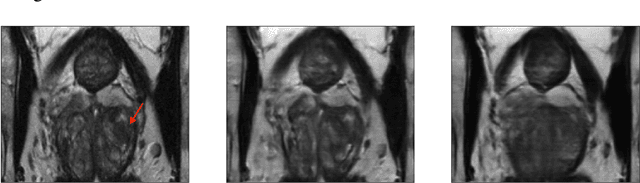

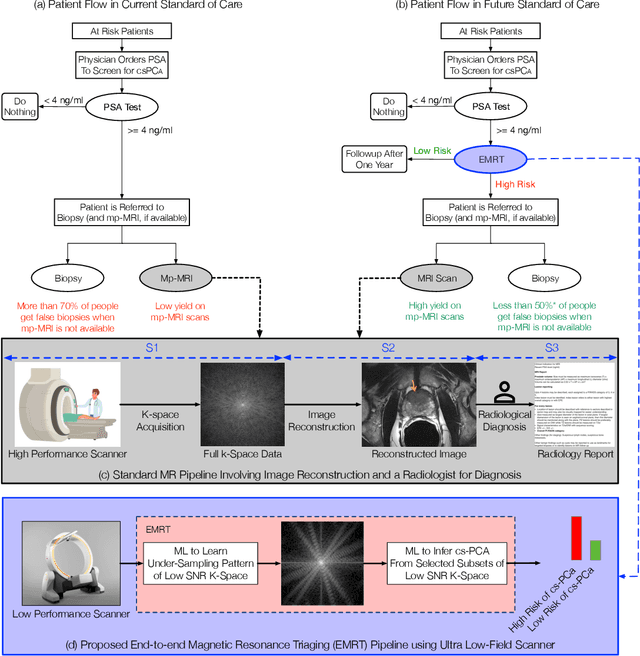

Early detection of many life-threatening diseases (e.g., prostate and breast cancer) within at-risk population can improve clinical outcomes and reduce cost of care. While numerous disease-specific "screening" tests that are closer to Point-of-Care (POC) are in use for this task, their low specificity results in unnecessary biopsies, leading to avoidable patient trauma and wasteful healthcare spending. On the other hand, despite the high accuracy of Magnetic Resonance (MR) imaging in disease diagnosis, it is not used as a POC disease identification tool because of poor accessibility. The root cause of poor accessibility of MR stems from the requirement to reconstruct high-fidelity images, as it necessitates a lengthy and complex process of acquiring large quantities of high-quality k-space measurements. In this study we explore the feasibility of an ML-augmented MR pipeline that directly infers the disease sidestepping the image reconstruction process. We hypothesise that the disease classification task can be solved using a very small tailored subset of k-space data, compared to image reconstruction. Towards that end, we propose a method that performs two tasks: 1) identifies a subset of the k-space that maximizes disease identification accuracy, and 2) infers the disease directly using the identified k-space subset, bypassing the image reconstruction step. We validate our hypothesis by measuring the performance of the proposed system across multiple diseases and anatomies. We show that comparable performance to image-based classifiers, trained on images reconstructed with full k-space data, can be achieved using small quantities of data: 8% of the data for detecting multiple abnormalities in prostate and brain scans, and 5% of the data for knee abnormalities. To better understand the proposed approach and instigate future research, we provide an extensive analysis and release code.
DeepGD: A Multi-Objective Black-Box Test Selection Approach for Deep Neural Networks
Mar 08, 2023
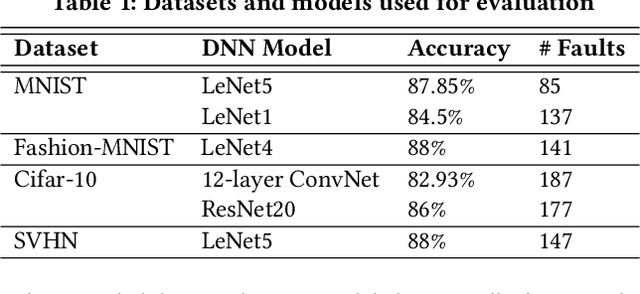
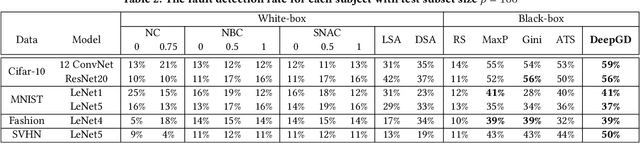
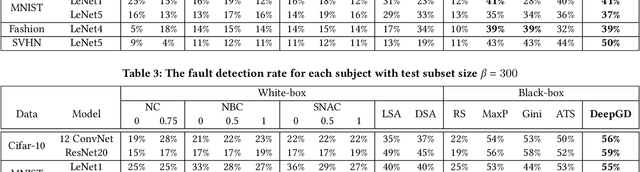
Deep neural networks (DNNs) are widely used in various application domains such as image processing, speech recognition, and natural language processing. However, testing DNN models may be challenging due to the complexity and size of their input domain. Particularly, testing DNN models often requires generating or exploring large unlabeled datasets. In practice, DNN test oracles, which identify the correct outputs for inputs, often require expensive manual effort to label test data, possibly involving multiple experts to ensure labeling correctness. In this paper, we propose DeepGD, a black-box multi-objective test selection approach for DNN models. It reduces the cost of labeling by prioritizing the selection of test inputs with high fault revealing power from large unlabeled datasets. DeepGD not only selects test inputs with high uncertainty scores to trigger as many mispredicted inputs as possible but also maximizes the probability of revealing distinct faults in the DNN model by selecting diverse mispredicted inputs. The experimental results conducted on four widely used datasets and five DNN models show that in terms of fault-revealing ability: (1) White-box, coverage-based approaches fare poorly, (2) DeepGD outperforms existing black-box test selection approaches in terms of fault detection, and (3) DeepGD also leads to better guidance for DNN model retraining when using selected inputs to augment the training set.
A lightweight method for detecting dynamic target occlusions by the robot body
Feb 14, 2023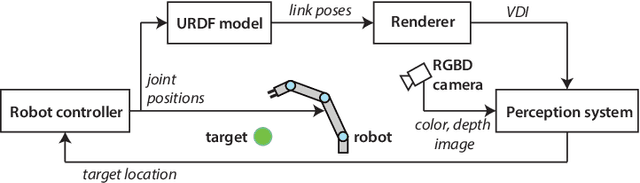

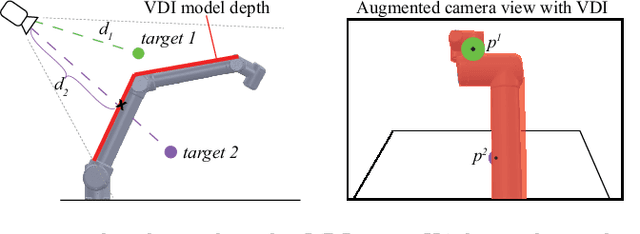

Robot vision is greatly affected by occlusions, which poses challenges to autonomous systems. The robot itself may hide targets of interest from the camera, while it moves within the field of view, leading to failures in task execution. For example, if a target of interest is partially occluded by the robot, detecting and grasping it correctly, becomes very challenging. To solve this problem, we propose a computationally lightweight method to determine the areas that the robot occludes. For this purpose, we use the Unified Robot Description Format (URDF) to generate a virtual depth image of the 3D robot model. Using the virtual depth image, we can effectively determine the partially occluded areas to improve the robustness of the information given by the perception system. Due to the real-time capabilities of the method, it can successfully detect occlusions of moving targets by the moving robot. We validate the effectiveness of the method in an experimental setup using a 6-DoF robot arm and an RGB-D camera by detecting and handling occlusions for two tasks: Pose estimation of a moving object for pickup and human tracking for robot handover. The code is available in \url{https://github.com/auth-arl/virtual\_depth\_image}.