 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Morpho-logic from a Topos Perspective: Application to symbolic AI
Mar 08, 2023
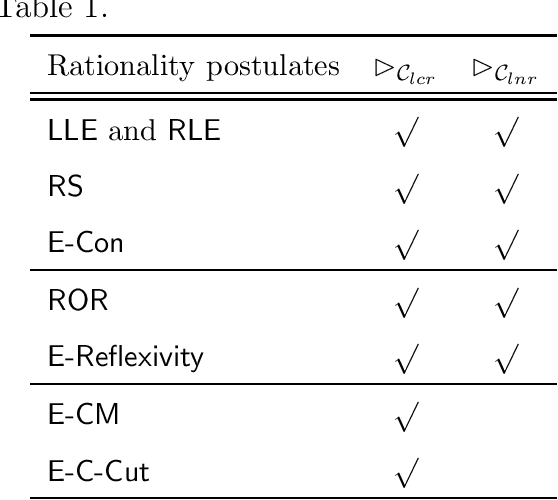
Modal logics have proved useful for many reasoning tasks in symbolic artificial intelligence (AI), such as belief revision, spatial reasoning, among others. On the other hand, mathematical morphology (MM) is a theory for non-linear analysis of structures, that was widely developed and applied in image analysis. Its mathematical bases rely on algebra, complete lattices, topology. Strong links have been established between MM and mathematical logics, mostly modal logics. In this paper, we propose to further develop and generalize this link between mathematical morphology and modal logic from a topos perspective, i.e. categorial structures generalizing space, and connecting logics, sets and topology. Furthermore, we rely on the internal language and logic of topos. We define structuring elements, dilations and erosions as morphisms. Then we introduce the notion of structuring neighborhoods, and show that the dilations and erosions based on them lead to a constructive modal logic, for which a sound and complete proof system is proposed. We then show that the modal logic thus defined (called morpho-logic here), is well adapted to define concrete and efficient operators for revision, merging, and abduction of new knowledge, or even spatial reasoning.
RADAM: Texture Recognition through Randomized Aggregated Encoding of Deep Activation Maps
Mar 08, 2023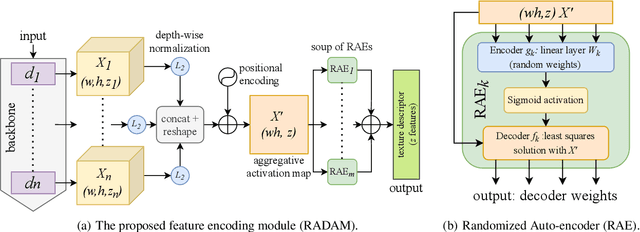
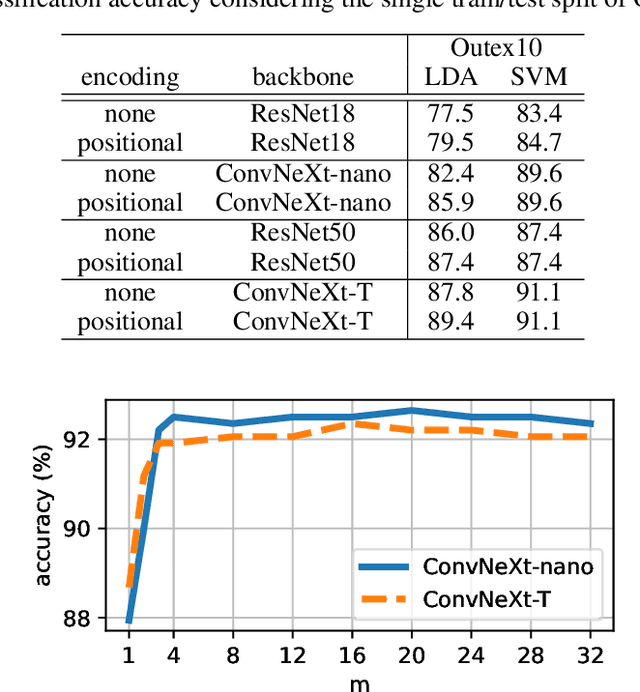
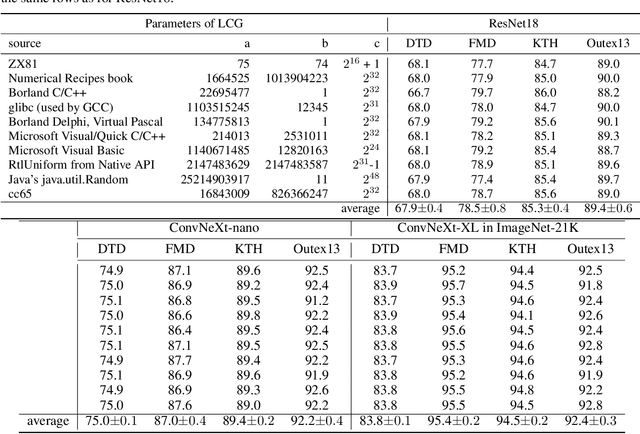
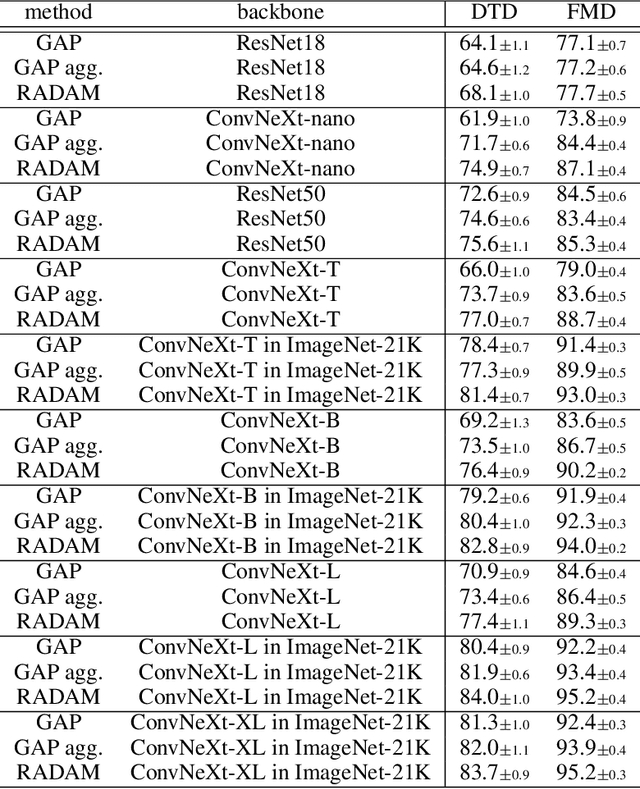
Texture analysis is a classical yet challenging task in computer vision for which deep neural networks are actively being applied. Most approaches are based on building feature aggregation modules around a pre-trained backbone and then fine-tuning the new architecture on specific texture recognition tasks. Here we propose a new method named \textbf{R}andom encoding of \textbf{A}ggregated \textbf{D}eep \textbf{A}ctivation \textbf{M}aps (RADAM) which extracts rich texture representations without ever changing the backbone. The technique consists of encoding the output at different depths of a pre-trained deep convolutional network using a Randomized Autoencoder (RAE). The RAE is trained locally to each image using a closed-form solution, and its decoder weights are used to compose a 1-dimensional texture representation that is fed into a linear SVM. This means that no fine-tuning or backpropagation is needed. We explore RADAM on several texture benchmarks and achieve state-of-the-art results with different computational budgets. Our results suggest that pre-trained backbones may not require additional fine-tuning for texture recognition if their learned representations are better encoded.
Traffic Scene Parsing through the TSP6K Dataset
Mar 06, 2023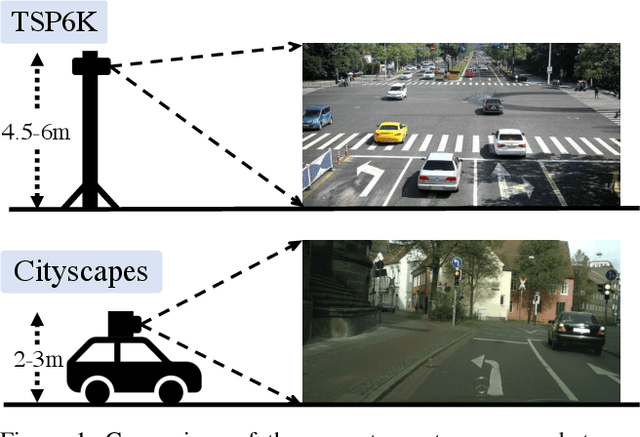


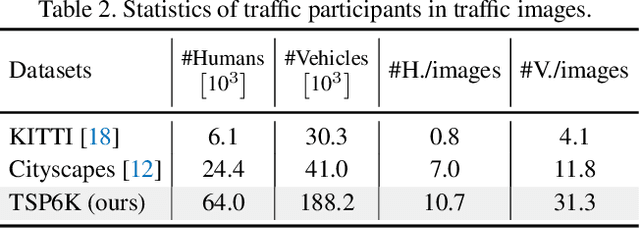
Traffic scene parsing is one of the most important tasks to achieve intelligent cities. So far, little effort has been spent on constructing datasets specifically for the task of traffic scene parsing. To fill this gap, here we introduce the TSP6K dataset, containing 6,000 urban traffic images and spanning hundreds of street scenes under various weather conditions. In contrast to most previous traffic scene datasets collected from a driving platform, the images in our dataset are from the shooting platform high-hanging on the street. Such traffic images can capture more crowded street scenes with several times more traffic participants than the driving scenes. Each image in the TSP6K dataset is provided with high-quality pixel-level and instance-level annotations. We perform a detailed analysis for the dataset and comprehensively evaluate the state-of-the-art scene parsing methods. Considering the vast difference in instance sizes, we propose a detail refining decoder, which recovers the details of different semantic regions in traffic scenes. Experiments have shown its effectiveness in parsing high-hanging traffic scenes. Code and dataset will be made publicly available.
From RGB images to Dynamic Movement Primitives for planar tasks
Mar 06, 2023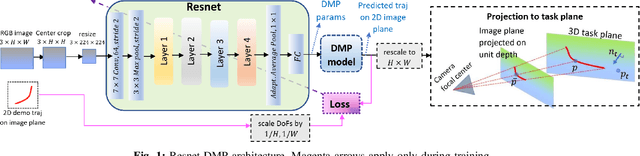
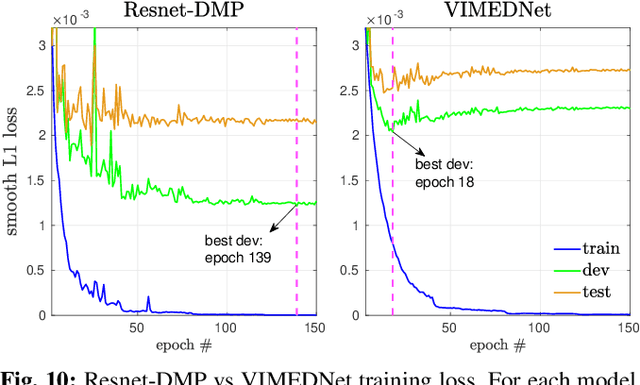
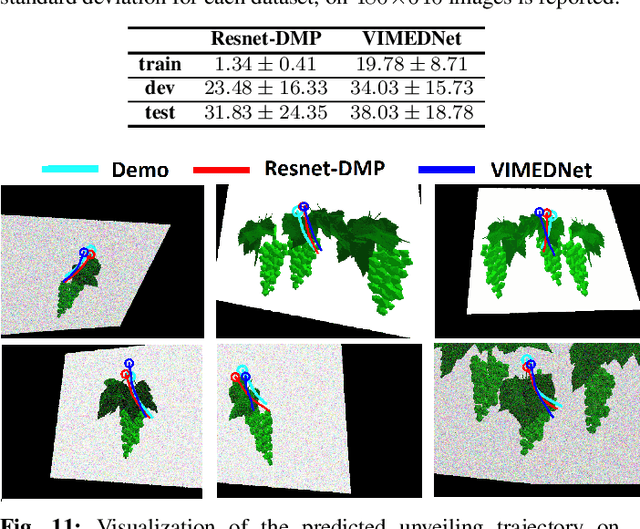
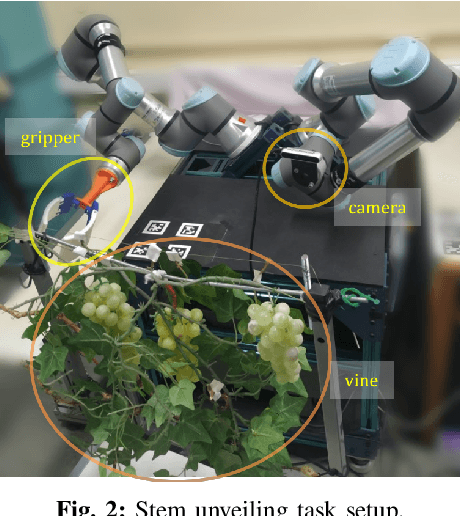
DMP have been extensively applied in various robotic tasks thanks to their generalization and robustness properties. However, the successful execution of a given task may necessitate the use of different motion patterns that take into account not only the initial and target position but also features relating to the overall structure and layout of the scene. To make DMP applicable in wider range of tasks and further automate their use, we design in this work a framework combining deep residual networks with DMP, that can encapsulate different motion patterns of a planar task, provided through human demonstrations on the RGB image plane. We can then automatically infer from new raw RGB visual input the appropriate DMP parameters, i.e. the weights that determine the motion pattern and the initial/target positions. We experimentally validate our method in the task of unveiling the stem of a grape-bunch from occluding leaves using on a mock-up vine setup and compare it to another SoA method for inferring DMP from images.
Self-supervised learning of object pose estimation using keypoint prediction
Feb 19, 2023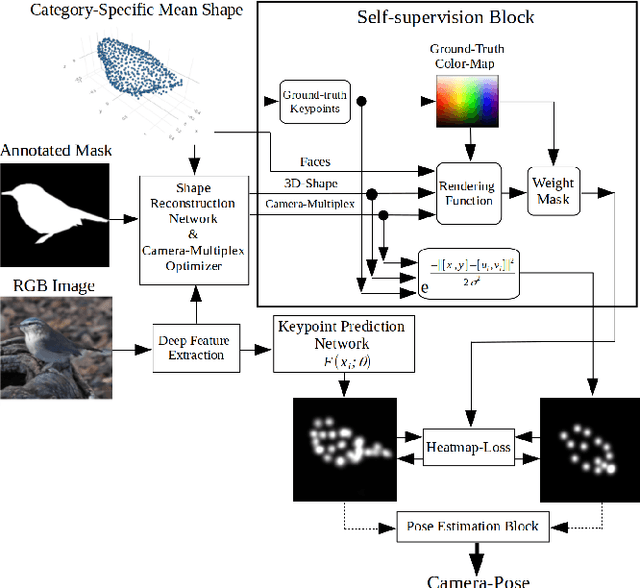
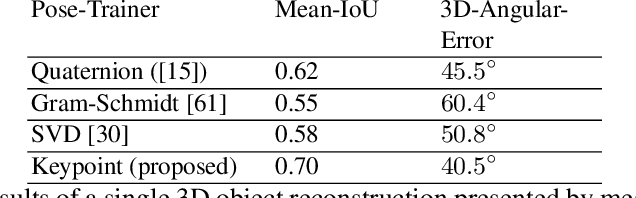

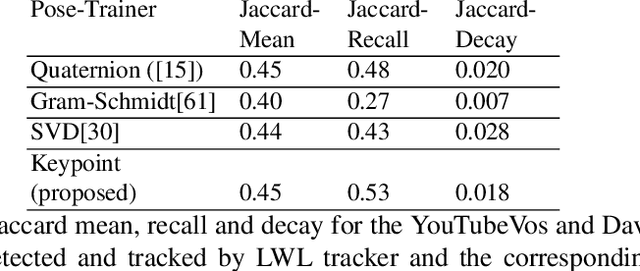
This paper describes recent developments in object specific pose and shape prediction from single images. The main contribution is a new approach to camera pose prediction by self-supervised learning of keypoints corresponding to locations on a category specific deformable shape. We designed a network to generate a proxy ground-truth heatmap from a set of keypoints distributed all over the category-specific mean shape, where each is represented by a unique color on a labeled texture. The proxy ground-truth heatmap is used to train a deep keypoint prediction network, which can be used in online inference. The proposed approach to camera pose prediction show significant improvements when compared with state-of-the-art methods. Our approach to camera pose prediction is used to infer 3D objects from 2D image frames of video sequences online. To train the reconstruction model, it receives only a silhouette mask from a single frame of a video sequence in every training step and a category-specific mean object shape. We conducted experiments using three different datasets representing the bird category: the CUB [51] image dataset, YouTubeVos and the Davis video datasets. The network is trained on the CUB dataset and tested on all three datasets. The online experiments are demonstrated on YouTubeVos and Davis [56] video sequences using a network trained on the CUB training set.
MetaDIP: Accelerating Deep Image Prior with Meta Learning
Sep 18, 2022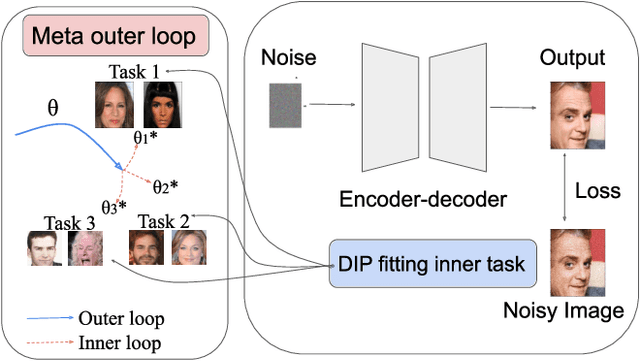
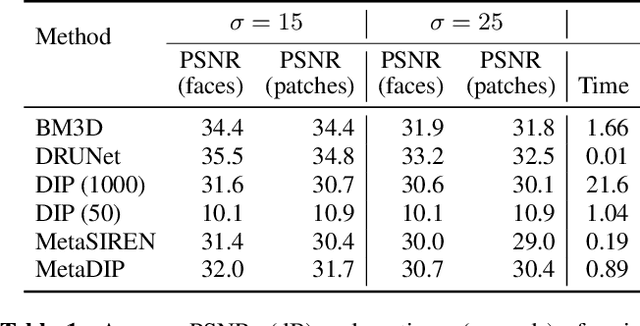
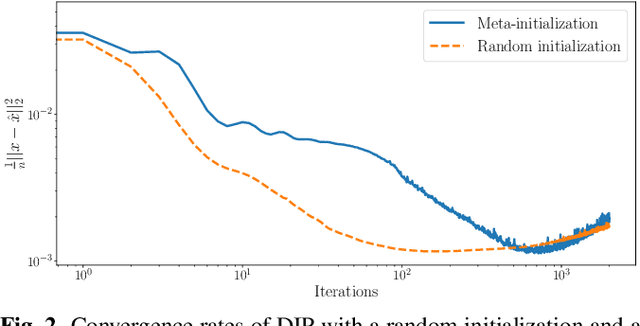
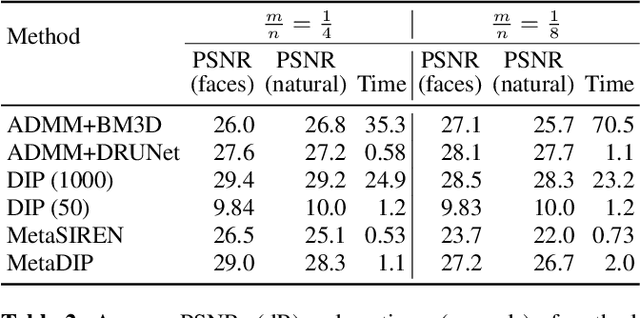
Deep image prior (DIP) is a recently proposed technique for solving imaging inverse problems by fitting the reconstructed images to the output of an untrained convolutional neural network. Unlike pretrained feedforward neural networks, the same DIP can generalize to arbitrary inverse problems, from denoising to phase retrieval, while offering competitive performance at each task. The central disadvantage of DIP is that, while feedforward neural networks can reconstruct an image in a single pass, DIP must gradually update its weights over hundreds to thousands of iterations, at a significant computational cost. In this work we use meta-learning to massively accelerate DIP-based reconstructions. By learning a proper initialization for the DIP weights, we demonstrate a 10x improvement in runtimes across a range of inverse imaging tasks. Moreover, we demonstrate that a network trained to quickly reconstruct faces also generalizes to reconstructing natural image patches.
Geometry Aligned Variational Transformer for Image-conditioned Layout Generation
Sep 02, 2022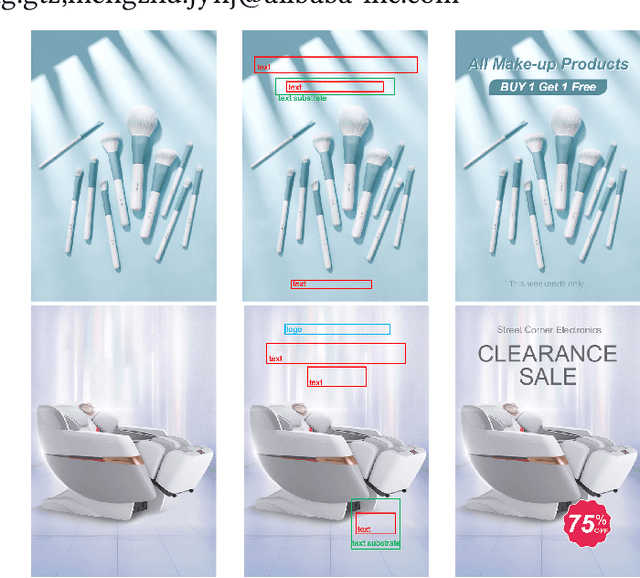
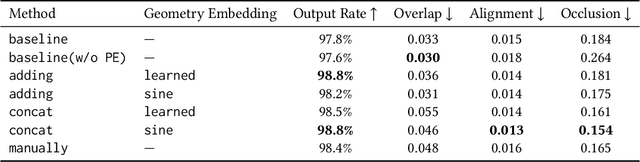
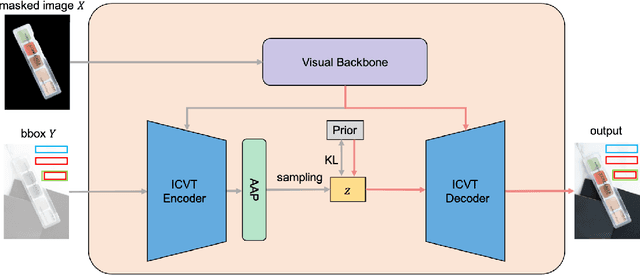

Layout generation is a novel task in computer vision, which combines the challenges in both object localization and aesthetic appraisal, widely used in advertisements, posters, and slides design. An accurate and pleasant layout should consider both the intra-domain relationship within layout elements and the inter-domain relationship between layout elements and the image. However, most previous methods simply focus on image-content-agnostic layout generation, without leveraging the complex visual information from the image. To this end, we explore a novel paradigm entitled image-conditioned layout generation, which aims to add text overlays to an image in a semantically coherent manner. Specifically, we propose an Image-Conditioned Variational Transformer (ICVT) that autoregressively generates various layouts in an image. First, self-attention mechanism is adopted to model the contextual relationship within layout elements, while cross-attention mechanism is used to fuse the visual information of conditional images. Subsequently, we take them as building blocks of conditional variational autoencoder (CVAE), which demonstrates appealing diversity. Second, in order to alleviate the gap between layout elements domain and visual domain, we design a Geometry Alignment module, in which the geometric information of the image is aligned with the layout representation. In addition, we construct a large-scale advertisement poster layout designing dataset with delicate layout and saliency map annotations. Experimental results show that our model can adaptively generate layouts in the non-intrusive area of the image, resulting in a harmonious layout design.
PromptFusion: Decoupling Stability and Plasticity for Continual Learning
Mar 13, 2023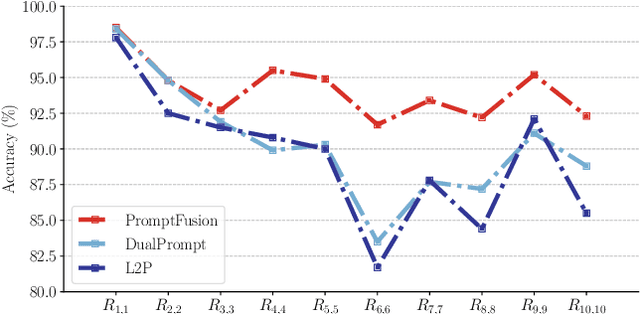
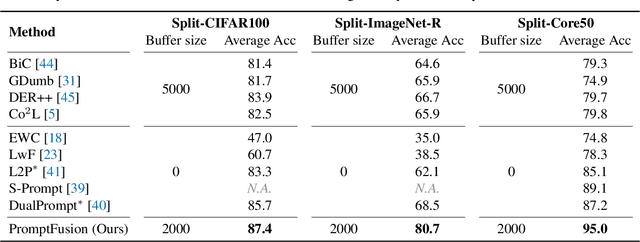
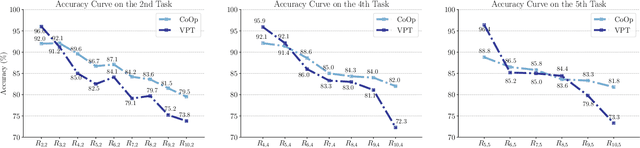
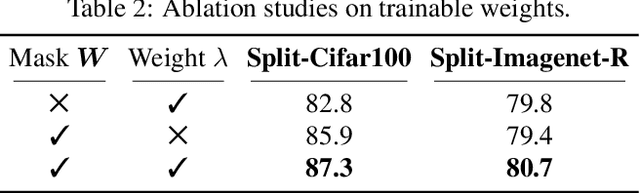
Continual learning refers to the capability of continuously learning from a stream of data. Current research mainly focuses on relieving catastrophic forgetting, and most of their success is at the cost of limiting the performance of newly incoming tasks. Such a trade-off is referred to as the stabilityplasticity dilemma and is a more general and challenging problem for continual learning. However, the inherent conflict between these two concepts makes it seemingly impossible to devise a satisfactory solution to both of them simultaneously. Therefore, we ask, "is it possible to divide them into two problems to conquer independently?" To this end, we propose a prompt-tuning-based method termed PromptFusion to enable the decoupling of stability and plasticity. Specifically, PromptFusion consists of a carefully designed Stabilizer module that deals with catastrophic forgetting and a Booster module to learn new knowledge concurrently. During training, PromptFusion first passes an input image to the two modules separately. Then the resulting logits are further fused with a learnable weight parameter. Finally, a weight mask is applied to the derived logits to balance between old and new classes. Extensive experiments show that our method achieves promising results on popular continual learning datasets for both class-incremental and domain incremental settings. Especially on Split-Imagenet-R, one of the most challenging datasets for class-incremental learning, our method exceeds state-of-the-art prompt-based methods L2P and DualPrompt by more than 10%.
Is the Elephant Flying? Resolving Ambiguities in Text-to-Image Generative Models
Nov 17, 2022
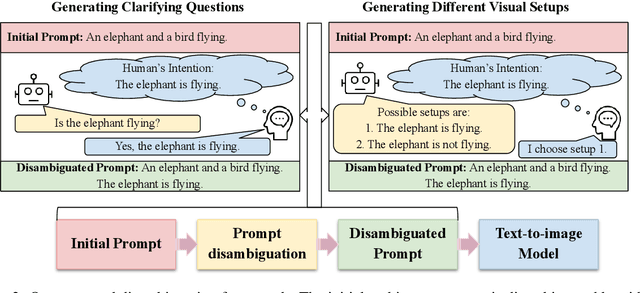
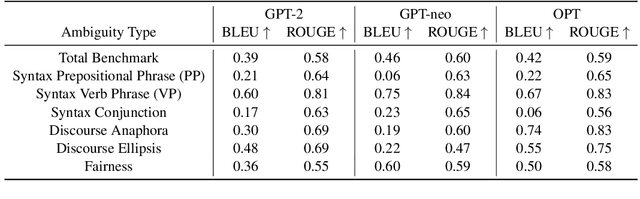
Natural language often contains ambiguities that can lead to misinterpretation and miscommunication. While humans can handle ambiguities effectively by asking clarifying questions and/or relying on contextual cues and common-sense knowledge, resolving ambiguities can be notoriously hard for machines. In this work, we study ambiguities that arise in text-to-image generative models. We curate a benchmark dataset covering different types of ambiguities that occur in these systems. We then propose a framework to mitigate ambiguities in the prompts given to the systems by soliciting clarifications from the user. Through automatic and human evaluations, we show the effectiveness of our framework in generating more faithful images aligned with human intention in the presence of ambiguities.
Wider and Higher: Intensive Integration and Global Foreground Perception for Image Matting
Oct 13, 2022
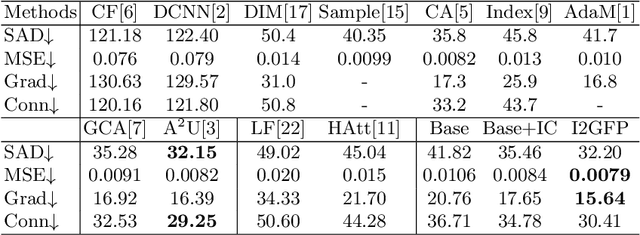
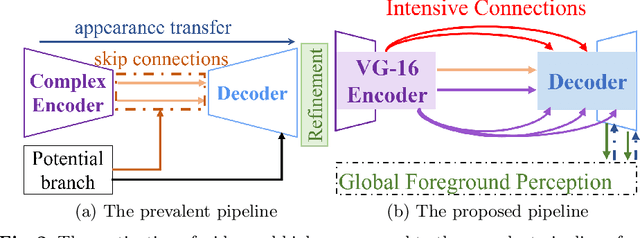
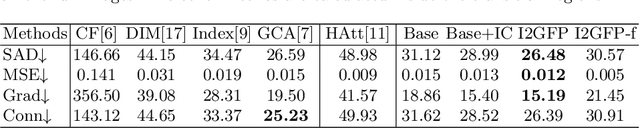
This paper reviews recent deep-learning-based matting research and conceives our wider and higher motivation for image matting. Many approaches achieve alpha mattes with complex encoders to extract robust semantics, then resort to the U-net-like decoder to concatenate or fuse encoder features. However, image matting is essentially a pixel-wise regression, and the ideal situation is to perceive the maximum opacity correspondence from the input image. In this paper, we argue that the high-resolution feature representation, perception and communication are more crucial for matting accuracy. Therefore, we propose an Intensive Integration and Global Foreground Perception network (I2GFP) to integrate wider and higher feature streams. Wider means we combine intensive features in each decoder stage, while higher suggests we retain high-resolution intermediate features and perceive large-scale foreground appearance. Our motivation sacrifices model depth for a significant performance promotion. We perform extensive experiments to prove the proposed I2GFP model, and state-of-the-art results can be achieved on different public datasets.