 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DISCO: Distributed Inference with Sparse Communications
Feb 22, 2023
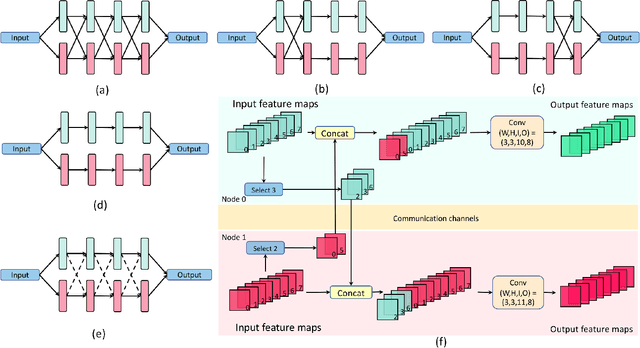
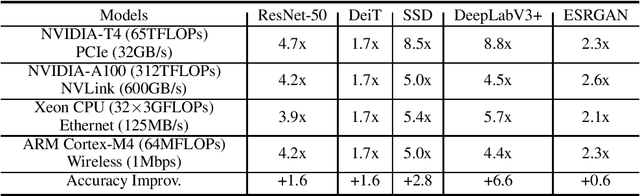
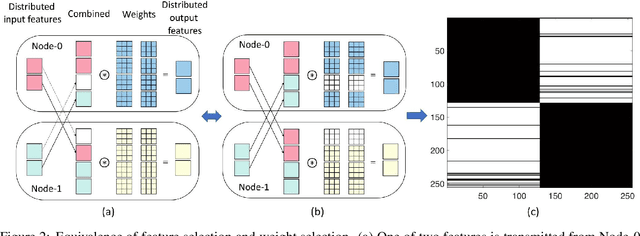
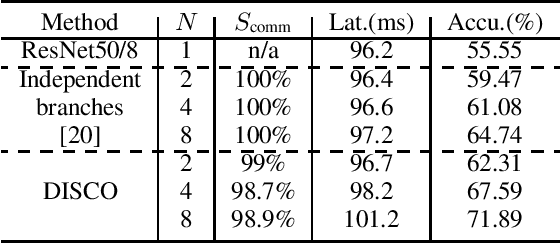
Deep neural networks (DNNs) have great potential to solve many real-world problems, but they usually require an extensive amount of computation and memory. It is of great difficulty to deploy a large DNN model to a single resource-limited device with small memory capacity. Distributed computing is a common approach to reduce single-node memory consumption and to accelerate the inference of DNN models. In this paper, we explore the "within-layer model parallelism", which distributes the inference of each layer into multiple nodes. In this way, the memory requirement can be distributed to many nodes, making it possible to use several edge devices to infer a large DNN model. Due to the dependency within each layer, data communications between nodes during this parallel inference can be a bottleneck when the communication bandwidth is limited. We propose a framework to train DNN models for Distributed Inference with Sparse Communications (DISCO). We convert the problem of selecting which subset of data to transmit between nodes into a model optimization problem, and derive models with both computation and communication reduction when each layer is inferred on multiple nodes. We show the benefit of the DISCO framework on a variety of CV tasks such as image classification, object detection, semantic segmentation, and image super resolution. The corresponding models include important DNN building blocks such as convolutions and transformers. For example, each layer of a ResNet-50 model can be distributively inferred across two nodes with five times less data communications, almost half overall computations and half memory requirement for a single node, and achieve comparable accuracy to the original ResNet-50 model. This also results in 4.7 times overall inference speedup.
Investigating Group Distributionally Robust Optimization for Deep Imbalanced Learning: A Case Study of Binary Tabular Data Classification
Mar 04, 2023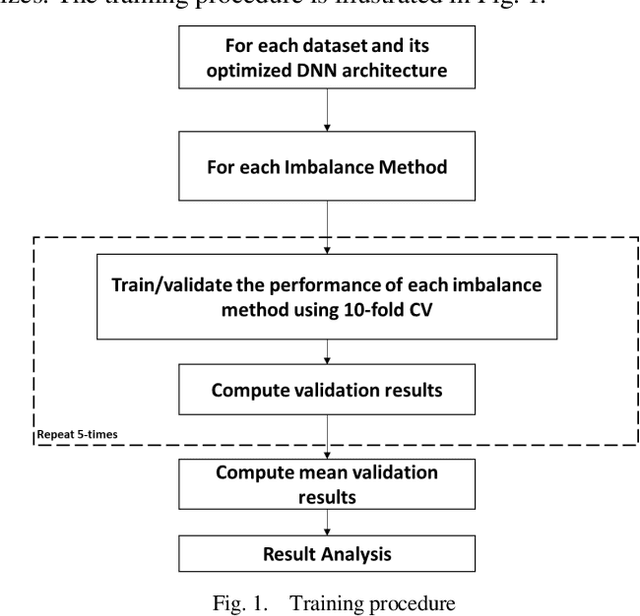
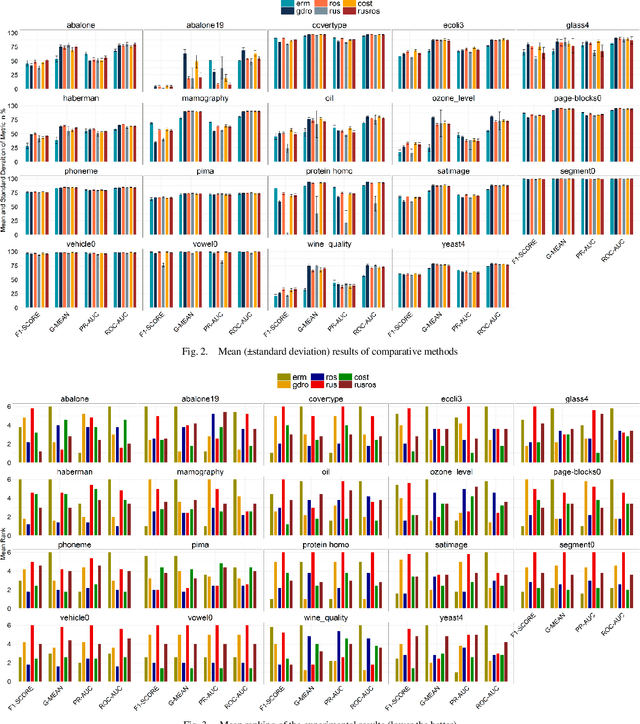
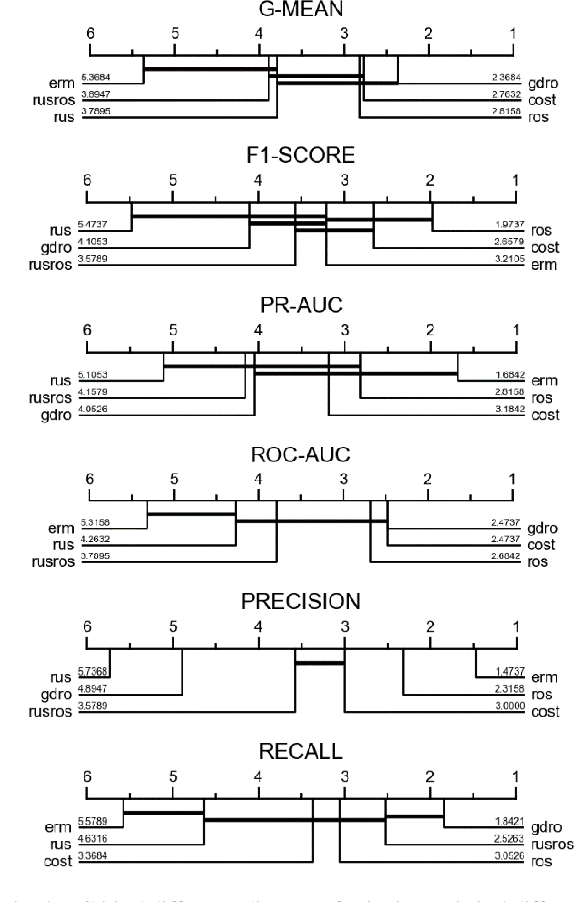
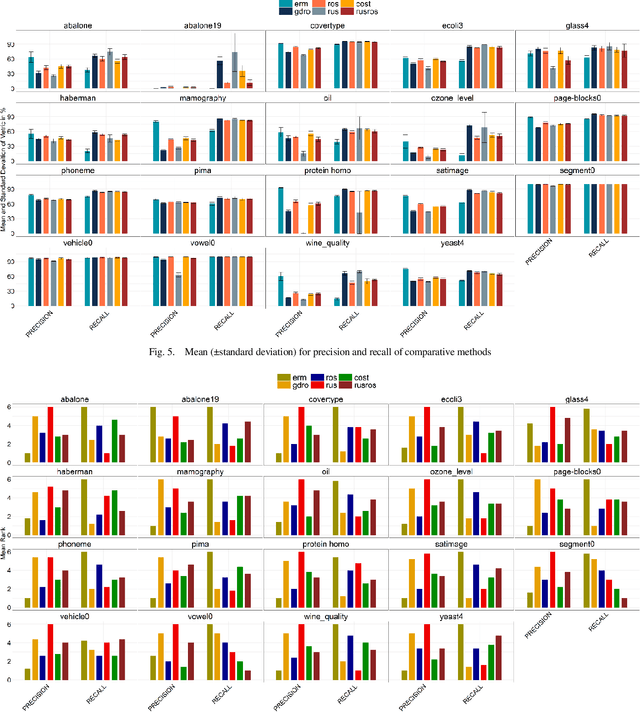
One of the most studied machine learning challenges that recent studies have shown the susceptibility of deep neural networks to is the class imbalance problem. While concerted research efforts in this direction have been notable in recent years, findings have shown that the canonical learning objective, empirical risk minimization (ERM), is unable to achieve optimal imbalance learning in deep neural networks given its bias to the majority class. An alternative learning objective, group distributionally robust optimization (gDRO), is investigated in this study for imbalance learning, focusing on tabular imbalanced data as against image data that has dominated deep imbalance learning research. Contrary to minimizing average per instance loss as in ERM, gDRO seeks to minimize the worst group loss over the training data. Experimental findings in comparison with ERM and classical imbalance methods using four popularly used evaluation metrics in imbalance learning across several benchmark imbalance binary tabular data of varying imbalance ratios reveal impressive performance of gDRO, outperforming other compared methods in terms of g-mean and roc-auc.
* 10 pages
Augmented smartphone bilirubinometer enabled by a mobile app that turns smartphone into multispectral imager
Mar 04, 2023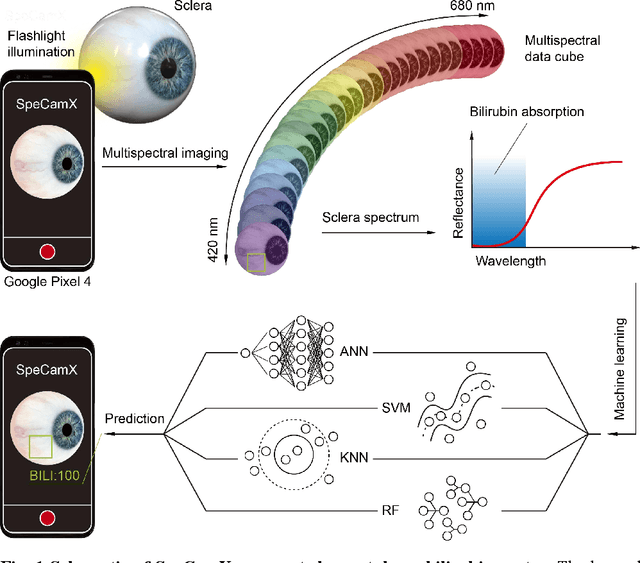
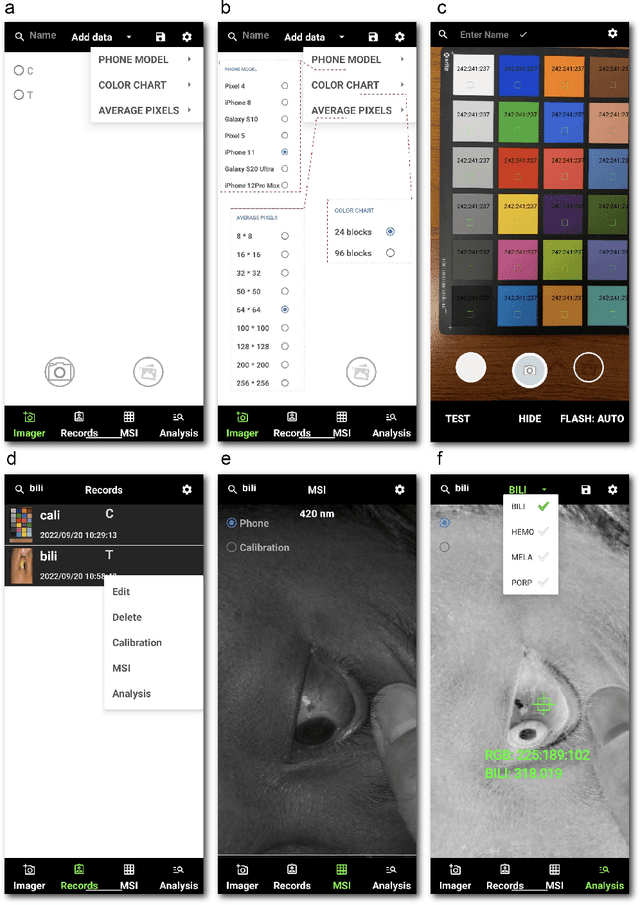
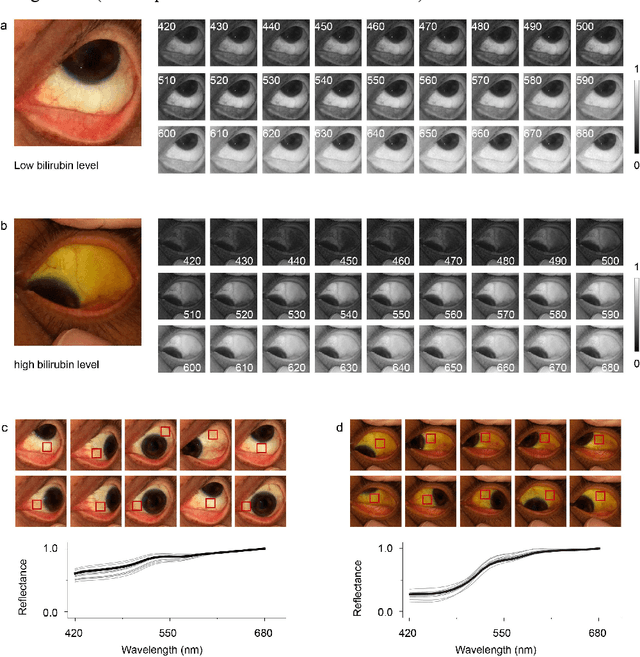
We present the development of SpeCamX, a mobile application that transforms any unmodified smartphone into a powerful multispectral imager capable of capturing multispectral information. Our application includes an augmented bilirubinometer, enabling accurate prediction of blood bilirubin levels (BBL). In a clinical study involving 320 patients with liver diseases, we used SpeCamX to image the bulbar conjunctiva region, and we employed a hybrid machine learning prediction model to predict BBL. We observed a high correlation with blood test results, demonstrating the efficacy of our approach. Furthermore, we compared our method, which uses spectrally augmented learning (SAL), with traditional learning based on RGB photographs (RGBL), and our results clearly indicate that SpeCamX outperforms RGBL in terms of prediction accuracy, efficiency, and stability. This study highlights the potential of SpeCamX to improve the prediction of bio-chromophores, and its ability to transform an ordinary smartphone into a powerful medical tool without the need for additional investments or expertise. This makes it suitable for widespread use, particularly in areas where medical resources are scarce.
PRSNet: A Masked Self-Supervised Learning Pedestrian Re-Identification Method
Mar 11, 2023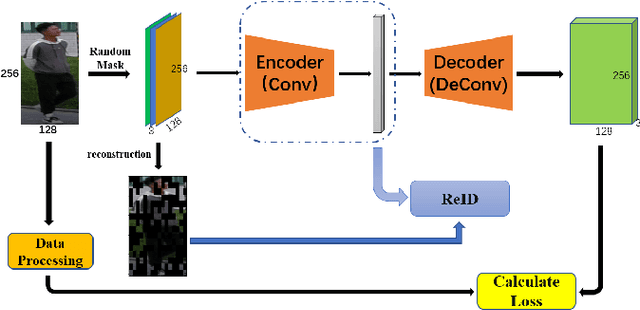
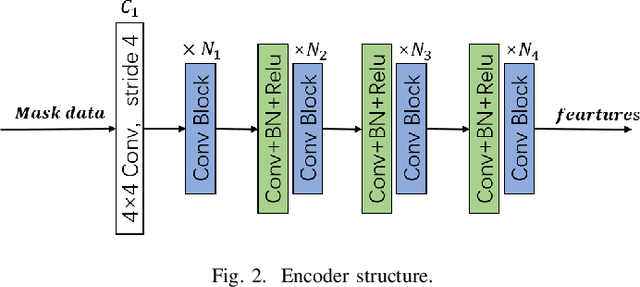
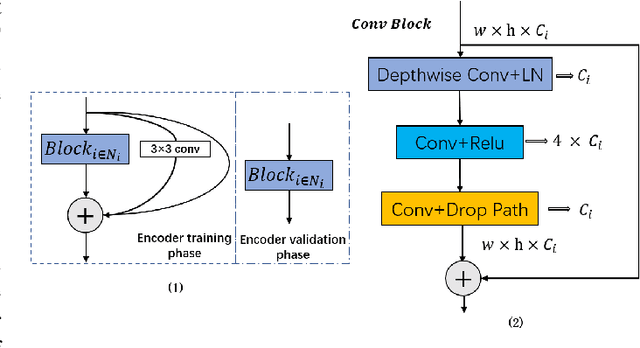
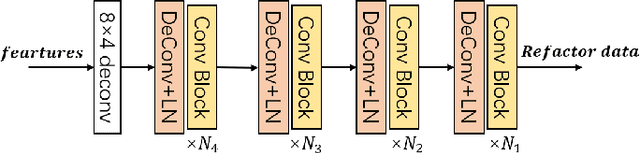
In recent years, self-supervised learning has attracted widespread academic debate and addressed many of the key issues of computer vision. The present research focus is on how to construct a good agent task that allows for improved network learning of advanced semantic information on images so that model reasoning is accelerated during pre-training of the current task. In order to solve the problem that existing feature extraction networks are pre-trained on the ImageNet dataset and cannot extract the fine-grained information in pedestrian images well, and the existing pre-task of contrast self-supervised learning may destroy the original properties of pedestrian images, this paper designs a pre-task of mask reconstruction to obtain a pre-training model with strong robustness and uses it for the pedestrian re-identification task. The training optimization of the network is performed by improving the triplet loss based on the centroid, and the mask image is added as an additional sample to the loss calculation, so that the network can better cope with the pedestrian matching in practical applications after the training is completed. This method achieves about 5% higher mAP on Marker1501 and CUHK03 data than existing self-supervised learning pedestrian re-identification methods, and about 1% higher for Rank1, and ablation experiments are conducted to demonstrate the feasibility of this method. Our model code is located at https://github.com/ZJieX/prsnet.
Benchmarking performance of object detection under image distortions in an uncontrolled environment
Oct 28, 2022
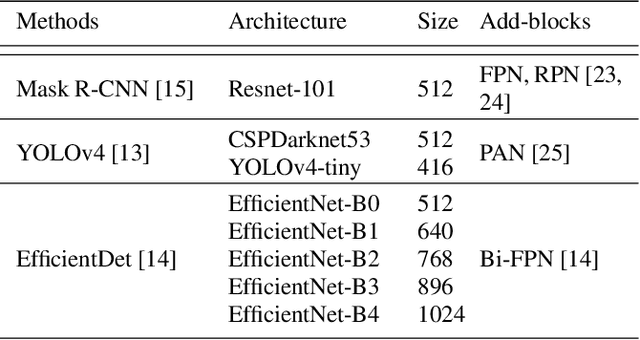


The robustness of object detection algorithms plays a prominent role in real-world applications, especially in uncontrolled environments due to distortions during image acquisition. It has been proven that the performance of object detection methods suffers from in-capture distortions. In this study, we present a performance evaluation framework for the state-of-the-art object detection methods using a dedicated dataset containing images with various distortions at different levels of severity. Furthermore, we propose an original strategy of image distortion generation applied to the MS-COCO dataset that combines some local and global distortions to reach much better performances. We have shown that training using the proposed dataset improves the robustness of object detection by 31.5\%. Finally, we provide a custom dataset including natural images distorted from MS-COCO to perform a more reliable evaluation of the robustness against common distortions. The database and the generation source codes of the different distortions are made publicly available
Factor Fields: A Unified Framework for Neural Fields and Beyond
Feb 02, 2023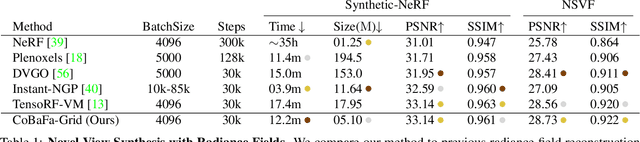
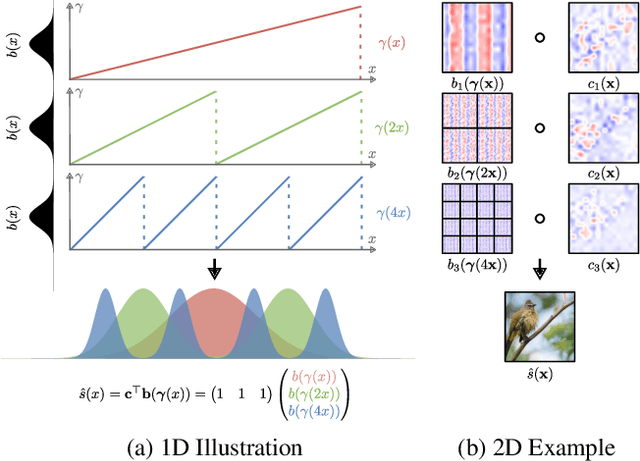
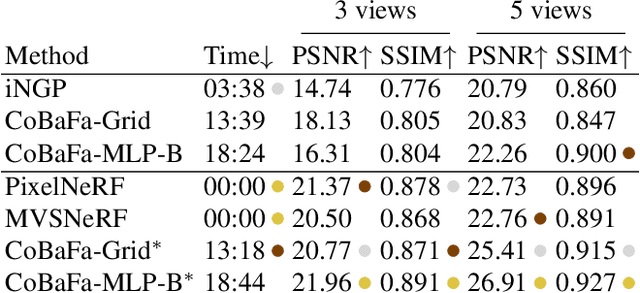
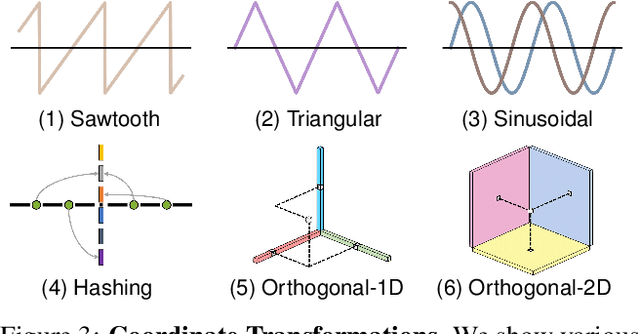
We present Factor Fields, a novel framework for modeling and representing signals. Factor Fields decomposes a signal into a product of factors, each of which is represented by a neural or regular field representation operating on a coordinate transformed input signal. We show that this decomposition yields a unified framework that generalizes several recent signal representations including NeRF, PlenOxels, EG3D, Instant-NGP, and TensoRF. Moreover, the framework allows for the creation of powerful new signal representations, such as the Coefficient-Basis Factorization (CoBaFa) which we propose in this paper. As evidenced by our experiments, CoBaFa leads to improvements over previous fast reconstruction methods in terms of the three critical goals in neural signal representation: approximation quality, compactness and efficiency. Experimentally, we demonstrate that our representation achieves better image approximation quality on 2D image regression tasks, higher geometric quality when reconstructing 3D signed distance fields and higher compactness for radiance field reconstruction tasks compared to previous fast reconstruction methods. Besides, our CoBaFa representation enables generalization by sharing the basis across signals during training, enabling generalization tasks such as image regression with sparse observations and few-shot radiance field reconstruction.
MetaDIP: Accelerating Deep Image Prior with Meta Learning
Sep 18, 2022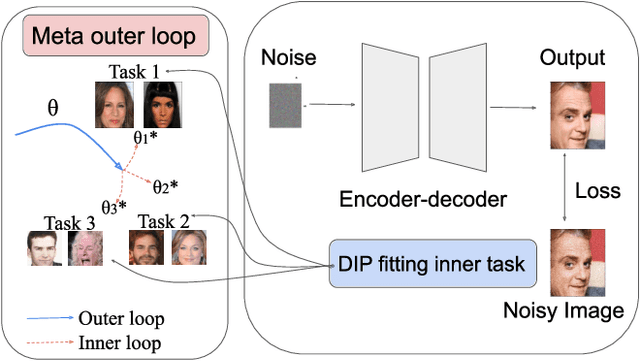
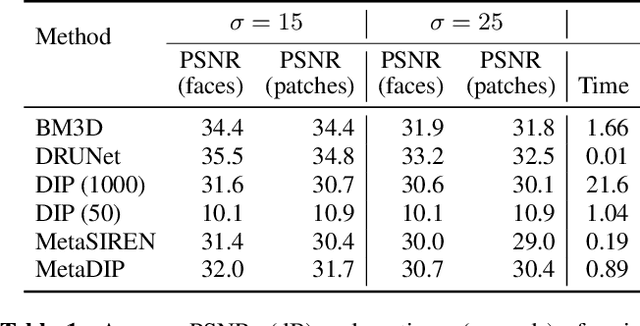
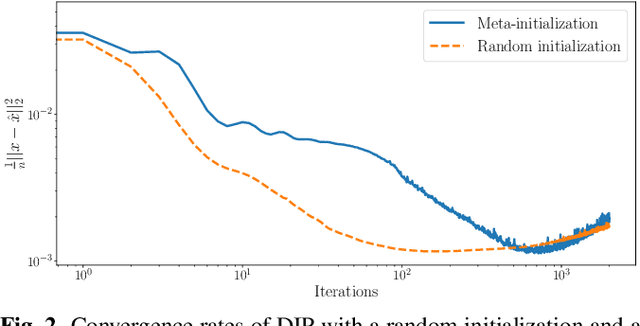
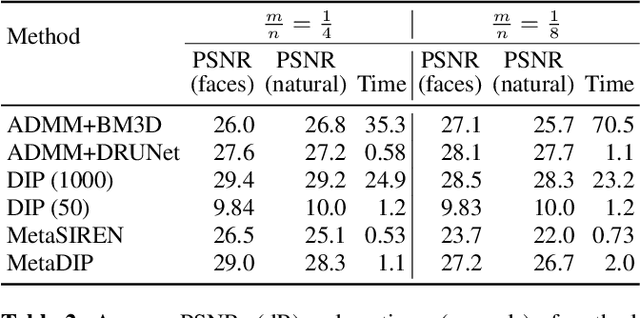
Deep image prior (DIP) is a recently proposed technique for solving imaging inverse problems by fitting the reconstructed images to the output of an untrained convolutional neural network. Unlike pretrained feedforward neural networks, the same DIP can generalize to arbitrary inverse problems, from denoising to phase retrieval, while offering competitive performance at each task. The central disadvantage of DIP is that, while feedforward neural networks can reconstruct an image in a single pass, DIP must gradually update its weights over hundreds to thousands of iterations, at a significant computational cost. In this work we use meta-learning to massively accelerate DIP-based reconstructions. By learning a proper initialization for the DIP weights, we demonstrate a 10x improvement in runtimes across a range of inverse imaging tasks. Moreover, we demonstrate that a network trained to quickly reconstruct faces also generalizes to reconstructing natural image patches.
Application of probabilistic modeling and automated machine learning framework for high-dimensional stress field
Mar 15, 2023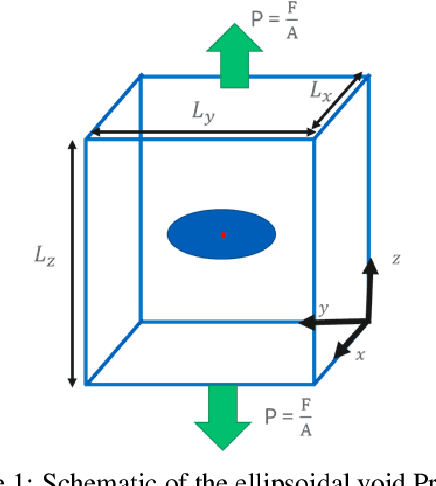
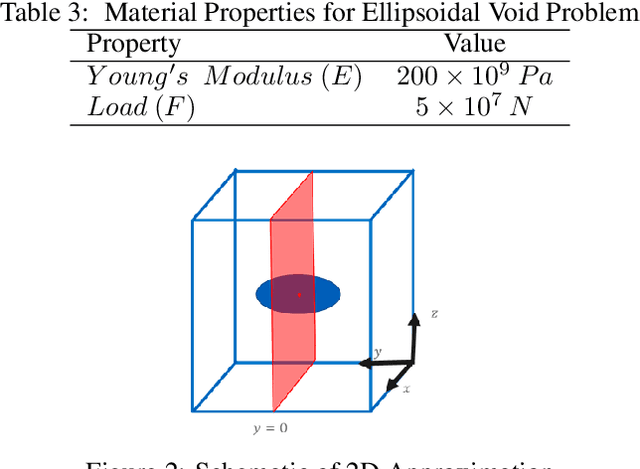
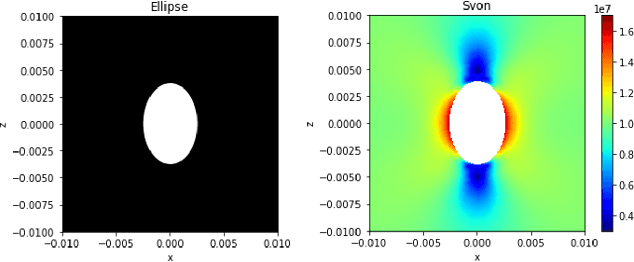
Modern computational methods, involving highly sophisticated mathematical formulations, enable several tasks like modeling complex physical phenomenon, predicting key properties and design optimization. The higher fidelity in these computer models makes it computationally intensive to query them hundreds of times for optimization and one usually relies on a simplified model albeit at the cost of losing predictive accuracy and precision. Towards this, data-driven surrogate modeling methods have shown a lot of promise in emulating the behavior of the expensive computer models. However, a major bottleneck in such methods is the inability to deal with high input dimensionality and the need for relatively large datasets. With such problems, the input and output quantity of interest are tensors of high dimensionality. Commonly used surrogate modeling methods for such problems, suffer from requirements like high number of computational evaluations that precludes one from performing other numerical tasks like uncertainty quantification and statistical analysis. In this work, we propose an end-to-end approach that maps a high-dimensional image like input to an output of high dimensionality or its key statistics. Our approach uses two main framework that perform three steps: a) reduce the input and output from a high-dimensional space to a reduced or low-dimensional space, b) model the input-output relationship in the low-dimensional space, and c) enable the incorporation of domain-specific physical constraints as masks. In order to accomplish the task of reducing input dimensionality we leverage principal component analysis, that is coupled with two surrogate modeling methods namely: a) Bayesian hybrid modeling, and b) DeepHyper's deep neural networks. We demonstrate the applicability of the approach on a problem of a linear elastic stress field data.
URCDC-Depth: Uncertainty Rectified Cross-Distillation with CutFlip for Monocular Depth Estimation
Feb 17, 2023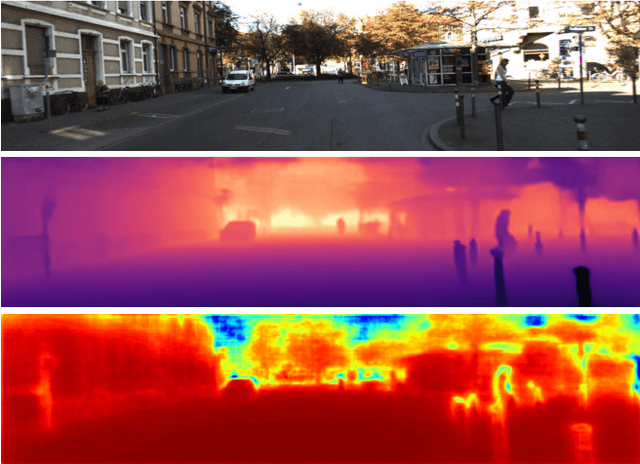
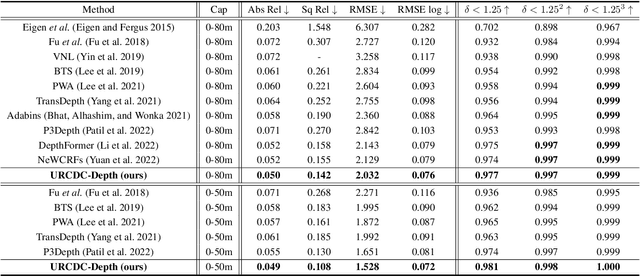
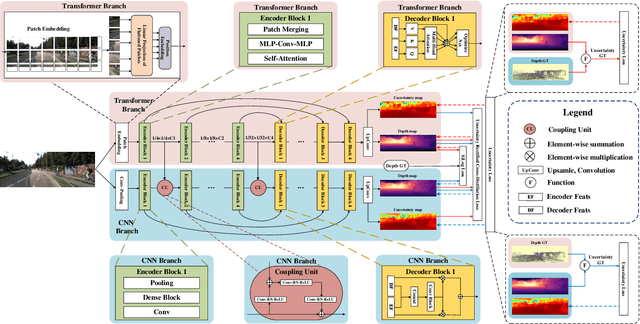
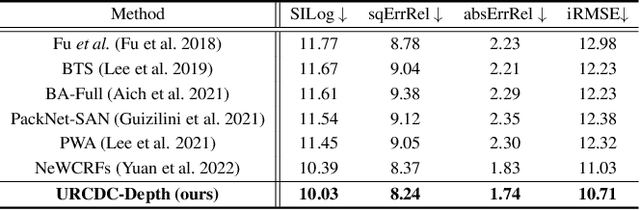
This work aims to estimate a high-quality depth map from a single RGB image. Due to the lack of depth clues, making full use of the long-range correlation and the local information is critical for accurate depth estimation. Towards this end, we introduce an uncertainty rectified cross-distillation between Transformer and convolutional neural network (CNN) to learn a unified depth estimator. Specifically, we use the depth estimates from the Transformer branch and the CNN branch as pseudo labels to teach each other. Meanwhile, we model the pixel-wise depth uncertainty to rectify the loss weights of noisy pseudo labels. To avoid the large capacity gap induced by the strong Transformer branch deteriorating the cross-distillation, we transfer the feature maps from Transformer to CNN and design coupling units to assist the weak CNN branch to leverage the transferred features. Furthermore, we propose a surprisingly simple yet highly effective data augmentation technique CutFlip, which enforces the model to exploit more valuable clues apart from the vertical image position for depth inference. Extensive experiments demonstrate that our model, termed~\textbf{URCDC-Depth}, exceeds previous state-of-the-art methods on the KITTI, NYU-Depth-v2 and SUN RGB-D datasets, even with no additional computational burden at inference time. The source code is publicly available at \url{https://github.com/ShuweiShao/URCDC-Depth}.
Hybrid Traffic Control and Coordination from Pixels
Feb 17, 2023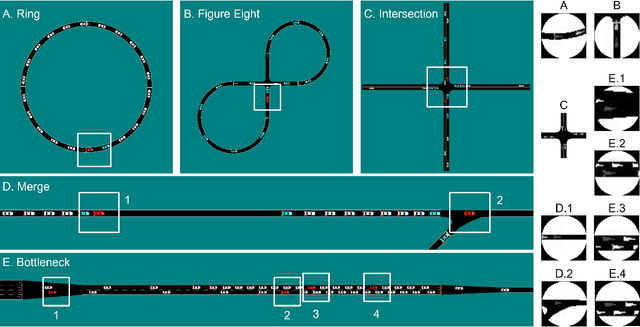

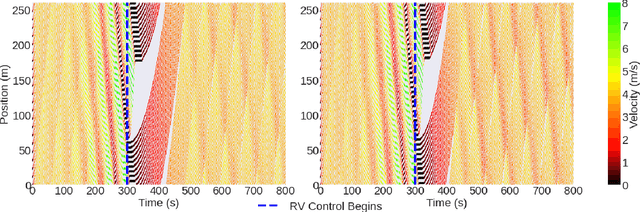

Traffic congestion is a persistent problem in our society. Existing methods for traffic control have proven futile in alleviating current congestion levels leading researchers to explore ideas with robot vehicles given the increased emergence of vehicles with different levels of autonomy on our roads. This gives rise to hybrid traffic control, where robot vehicles regulate human-driven vehicles, through reinforcement learning (RL). However, most existing studies use precise observations that involve global information, such as network throughput, as well as local information, such as vehicle positions and velocities. Obtaining this information requires updating existing road infrastructure with vast sensor networks and communication to potentially unwilling human drivers. We consider image observations as the alternative for hybrid traffic control via RL: 1) images are readily available through satellite imagery, in-car camera systems, and traffic monitoring systems; 2) Images do not require a complete re-imagination of the observation space from network to network; and 3) images only require communication to equipment. In this work, we show that robot vehicles using image observations can achieve similar performance to using precise information on networks, including ring, figure eight, merge, bottleneck, and intersections. We also demonstrate increased performance (up to 26%) in certain cases on tested networks, despite only using local traffic information as opposed to global traffic information.