 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion in the Dark: A Diffusion Model for Low-Light Text Recognition
Mar 07, 2023
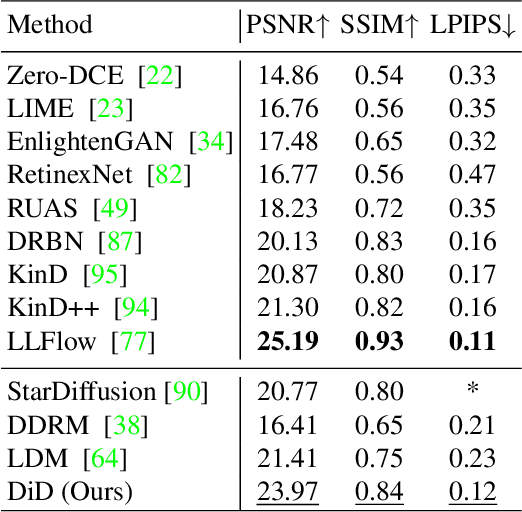
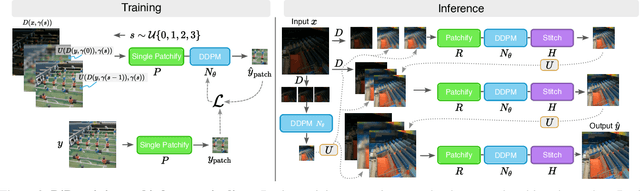
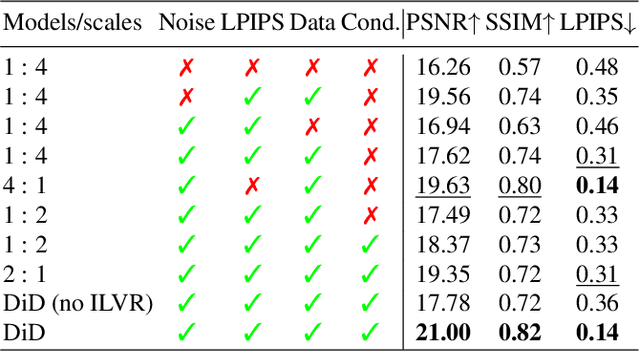
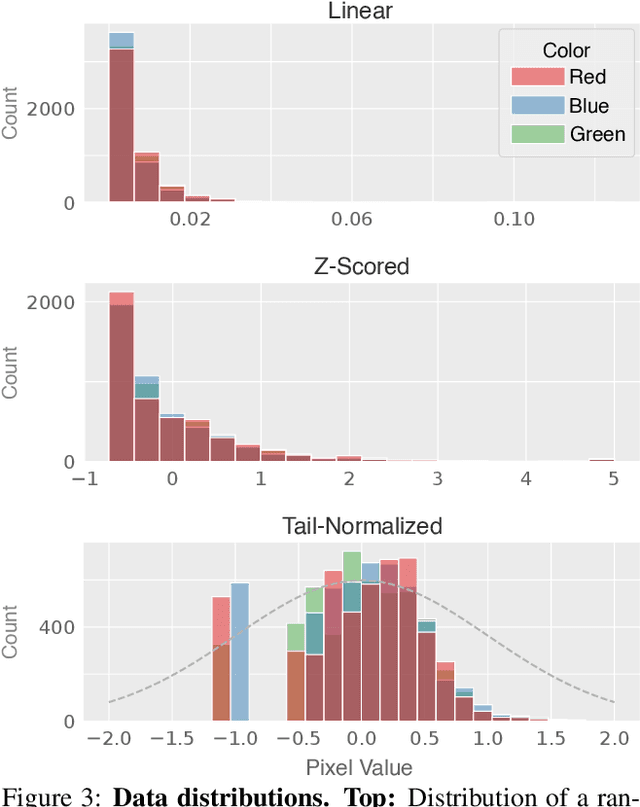
Images are indispensable for the automation of high-level tasks, such as text recognition. Low-light conditions pose a challenge for these high-level perception stacks, which are often optimized on well-lit, artifact-free images. Reconstruction methods for low-light images can produce well-lit counterparts, but typically at the cost of high-frequency details critical for downstream tasks. We propose Diffusion in the Dark (DiD), a diffusion model for low-light image reconstruction that provides qualitatively competitive reconstructions with that of SOTA, while preserving high-frequency details even in extremely noisy, dark conditions. We demonstrate that DiD, without any task-specific optimization, can outperform SOTA low-light methods in low-light text recognition on real images, bolstering the potential of diffusion models for ill-posed inverse problems.
Adaptive Weighted Multiview Kernel Matrix Factorization with its application in Alzheimer's Disease Analysis -- A clustering Perspective
Mar 07, 2023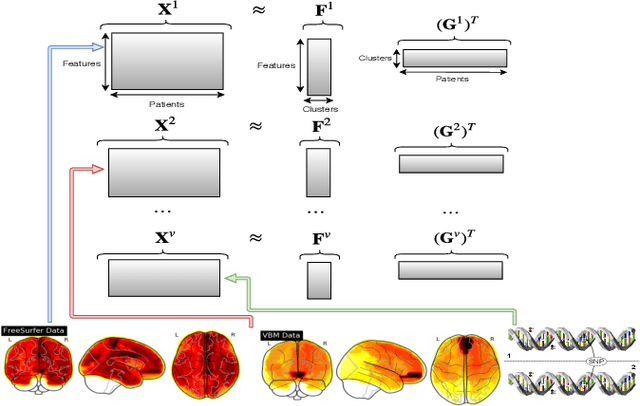
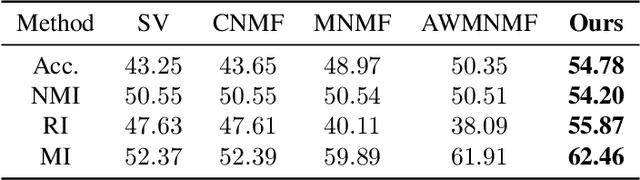
Recent technology and equipment advancements provide with us opportunities to better analyze Alzheimer's disease (AD), where we could collect and employ the data from different image and genetic modalities that may potentially enhance the predictive performance. To perform better clustering in AD analysis, in this paper we propose a novel model to leverage data from all different modalities/views, which can learn the weights of each view adaptively. Different from previous vanilla Non-negative Matrix Factorization which assumes data is linearly separable, we propose a simple yet efficient method based on kernel matrix factorization, which is not only able to deal with non-linear data structure but also can achieve better prediction accuracy. Experimental results on ADNI dataset demonstrate the effectiveness of our proposed method, which indicate promising prospects of kernel application in AD analysis.
How Image Generation Helps Visible-to-Infrared Person Re-Identification?
Oct 04, 2022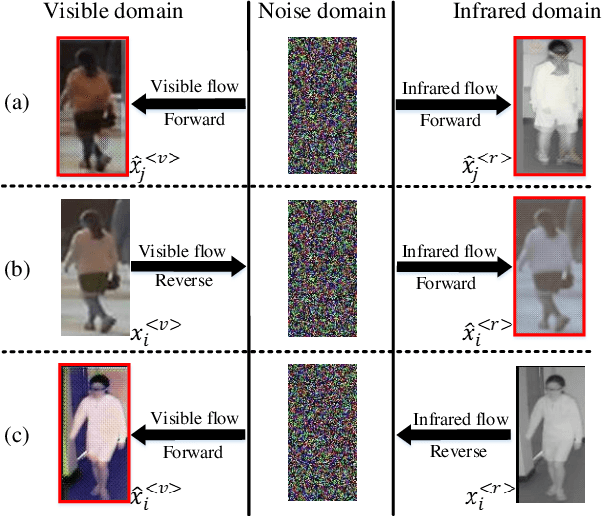
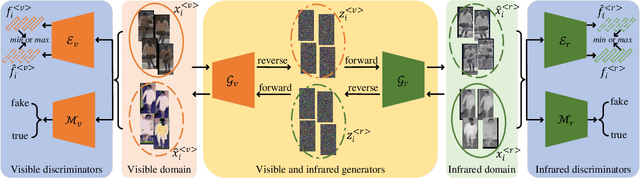


Compared to visible-to-visible (V2V) person re-identification (ReID), the visible-to-infrared (V2I) person ReID task is more challenging due to the lack of sufficient training samples and the large cross-modality discrepancy. To this end, we propose Flow2Flow, a unified framework that could jointly achieve training sample expansion and cross-modality image generation for V2I person ReID. Specifically, Flow2Flow learns bijective transformations from both the visible image domain and the infrared domain to a shared isotropic Gaussian domain with an invertible visible flow-based generator and an infrared one, respectively. With Flow2Flow, we are able to generate pseudo training samples by the transformation from latent Gaussian noises to visible or infrared images, and generate cross-modality images by transformations from existing-modality images to latent Gaussian noises to missing-modality images. For the purpose of identity alignment and modality alignment of generated images, we develop adversarial training strategies to train Flow2Flow. Specifically, we design an image encoder and a modality discriminator for each modality. The image encoder encourages the generated images to be similar to real images of the same identity via identity adversarial training, and the modality discriminator makes the generated images modal-indistinguishable from real images via modality adversarial training. Experimental results on SYSU-MM01 and RegDB demonstrate that both training sample expansion and cross-modality image generation can significantly improve V2I ReID accuracy.
Robust Table Structure Recognition with Dynamic Queries Enhanced Detection Transformer
Mar 21, 2023
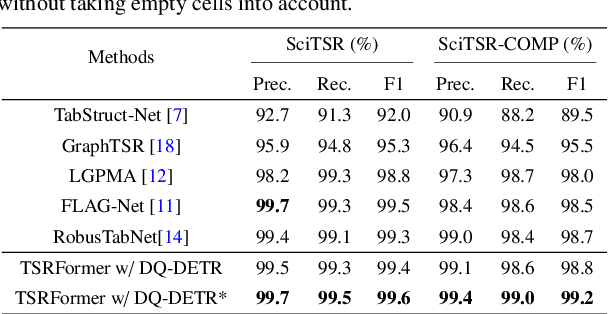
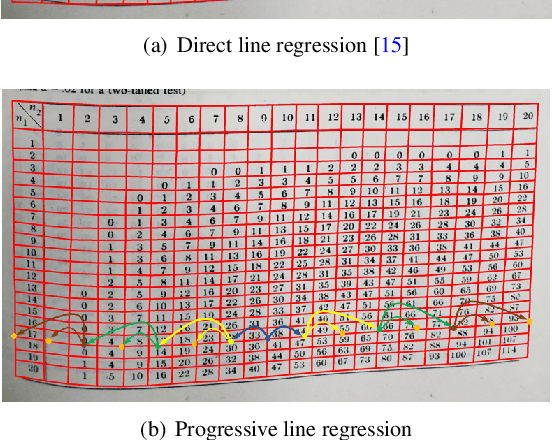
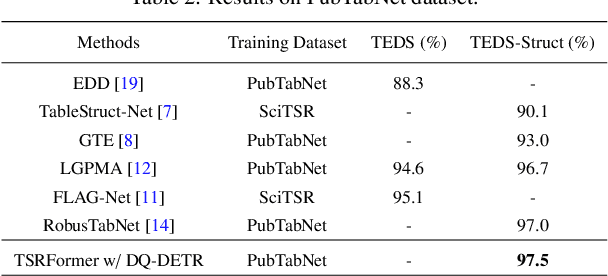
We present a new table structure recognition (TSR) approach, called TSRFormer, to robustly recognizing the structures of complex tables with geometrical distortions from various table images. Unlike previous methods, we formulate table separation line prediction as a line regression problem instead of an image segmentation problem and propose a new two-stage dynamic queries enhanced DETR based separation line regression approach, named DQ-DETR, to predict separation lines from table images directly. Compared to Vallina DETR, we propose three improvements in DQ-DETR to make the two-stage DETR framework work efficiently and effectively for the separation line prediction task: 1) A new query design, named Dynamic Query, to decouple single line query into separable point queries which could intuitively improve the localization accuracy for regression tasks; 2) A dynamic queries based progressive line regression approach to progressively regressing points on the line which further enhances localization accuracy for distorted tables; 3) A prior-enhanced matching strategy to solve the slow convergence issue of DETR. After separation line prediction, a simple relation network based cell merging module is used to recover spanning cells. With these new techniques, our TSRFormer achieves state-of-the-art performance on several benchmark datasets, including SciTSR, PubTabNet, WTW and FinTabNet. Furthermore, we have validated the robustness and high localization accuracy of our approach to tables with complex structures, borderless cells, large blank spaces, empty or spanning cells as well as distorted or even curved shapes on a more challenging real-world in-house dataset.
Machine Learning Techniques for Estimating Soil Moisture from Mobile Captured Images
Mar 21, 2023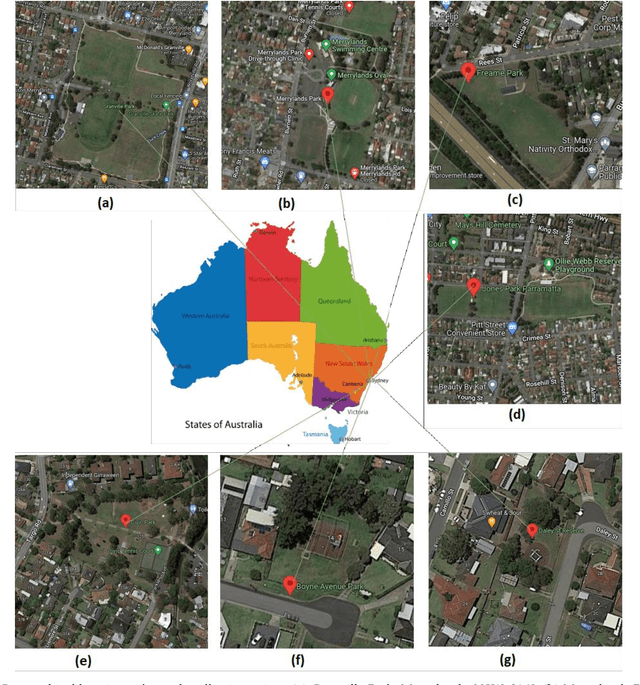
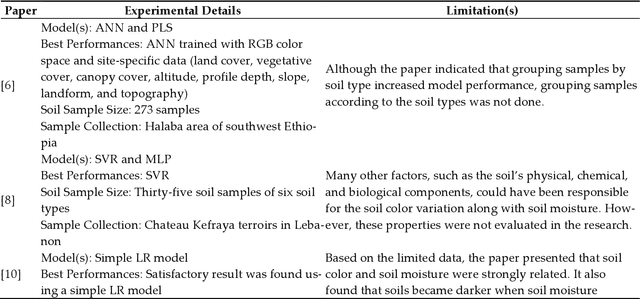

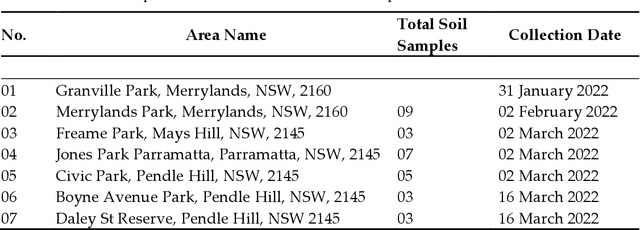
Precise Soil Moisture (SM) assessment is essential in agriculture. By understanding the level of SM, we can improve yield irrigation scheduling which significantly impacts food production and other needs of the global population. The advancements in smartphone technologies and computer vision have demonstrated a non-destructive nature of soil properties, including SM. The study aims to analyze the existing Machine Learning (ML) techniques for estimating SM from soil images and understand the moisture accuracy using different smartphones and various sunlight conditions. Therefore, 629 images of 38 soil samples were taken from seven areas in Sydney, Australia, and split into four datasets based on the image-capturing devices used (iPhone 6s and iPhone 11 Pro) and the lighting circumstances (direct and indirect sunlight). A comparison between Multiple Linear Regression (MLR), Support Vector Regression (SVR), and Convolutional Neural Network (CNN) was presented. MLR was performed with higher accuracy using holdout cross-validation, where the images were captured in indirect sunlight with the Mean Absolute Error (MAE) value of 0.35, Root Mean Square Error (RMSE) value of 0.15, and R^2 value of 0.60. Nevertheless, SVR was better with MAE, RMSE, and R^2 values of 0.05, 0.06, and 0.96 for 10-fold cross-validation and 0.22, 0.06, and 0.95 for leave-one-out cross-validation when images were captured in indirect sunlight. It demonstrates a smartphone camera's potential for predicting SM by utilizing ML. In the future, software developers can develop mobile applications based on the research findings for accurate, easy, and rapid SM estimation.
Paint it Black: Generating paintings from text descriptions
Feb 17, 2023
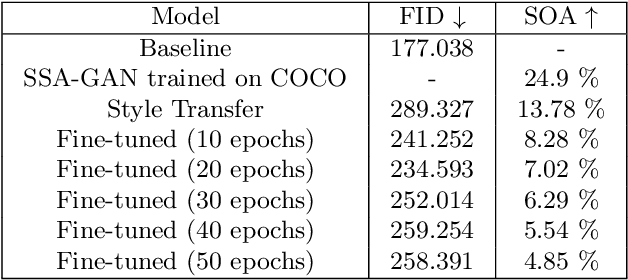

Two distinct tasks - generating photorealistic pictures from given text prompts and transferring the style of a painting to a real image to make it appear as though it were done by an artist, have been addressed many times, and several approaches have been proposed to accomplish them. However, the intersection of these two, i.e., generating paintings from a given caption, is a relatively unexplored area with little data available. In this paper, we have explored two distinct strategies and have integrated them together. First strategy is to generate photorealistic images and then apply style transfer and the second strategy is to train an image generation model on real images with captions and then fine-tune it on captioned paintings later. These two models are evaluated using different metrics as well as a user study is conducted to get human feedback on the produced results.
Is This Loss Informative? Speeding Up Textual Inversion with Deterministic Objective Evaluation
Feb 09, 2023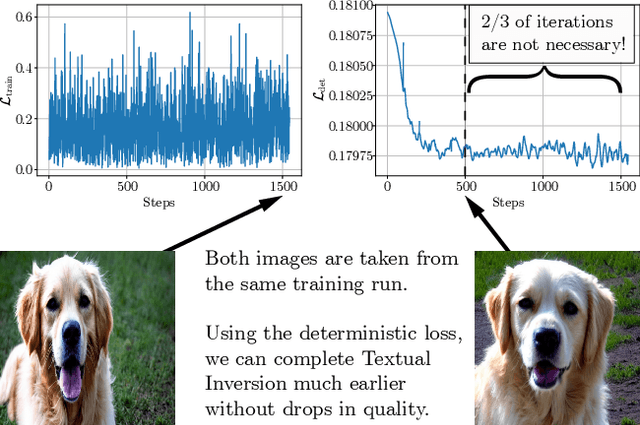
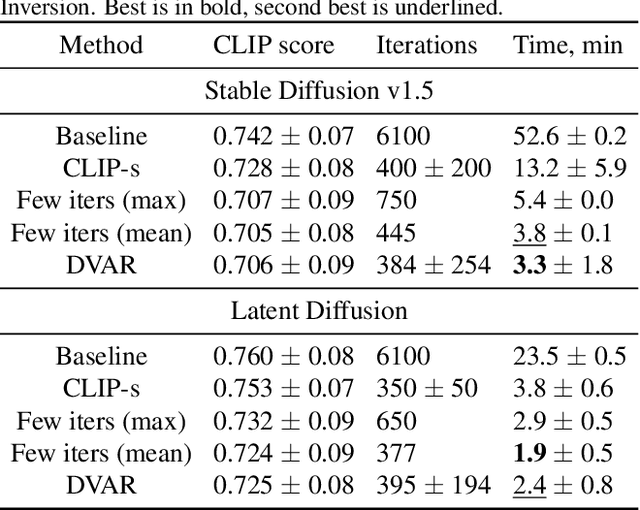
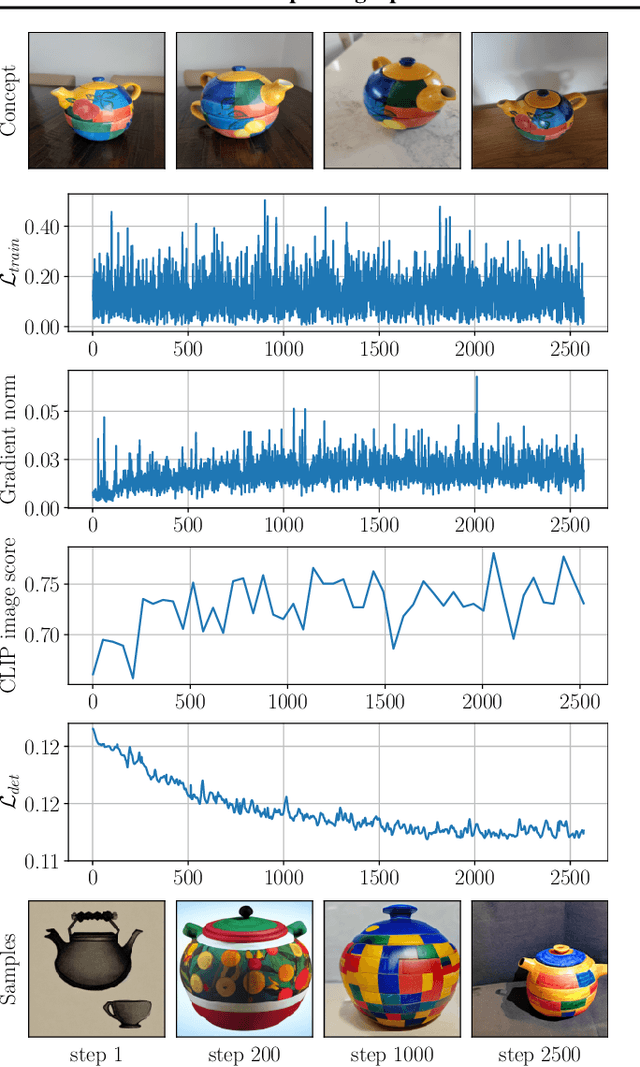
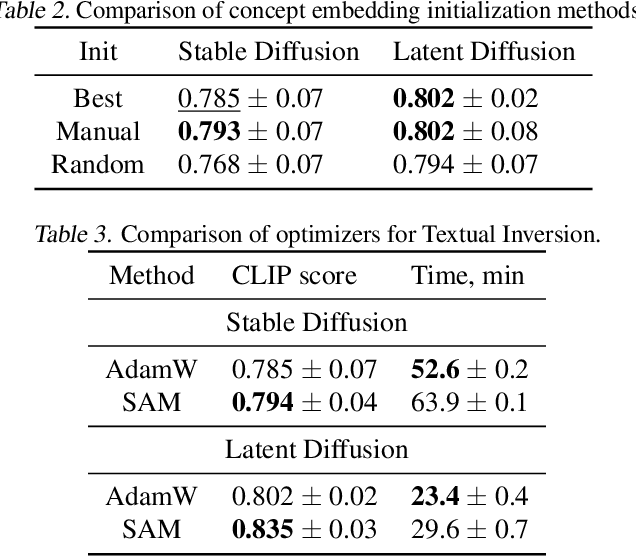
Text-to-image generation models represent the next step of evolution in image synthesis, offering natural means of flexible yet fine-grained control over the result. One emerging area of research is the rapid adaptation of large text-to-image models to smaller datasets or new visual concepts. However, the most efficient method of adaptation, called textual inversion, has a known limitation of long training time, which both restricts practical applications and increases the experiment time for research. In this work, we study the training dynamics of textual inversion, aiming to speed it up. We observe that most concepts are learned at early stages and do not improve in quality later, but standard model convergence metrics fail to indicate that. Instead, we propose a simple early stopping criterion that only requires computing the textual inversion loss on the same inputs for all training iterations. Our experiments on both Latent Diffusion and Stable Diffusion models for 93 concepts demonstrate the competitive performance of our method, speeding adaptation up to 15 times with no significant drops in quality.
Open-domain Visual Entity Recognition: Towards Recognizing Millions of Wikipedia Entities
Feb 24, 2023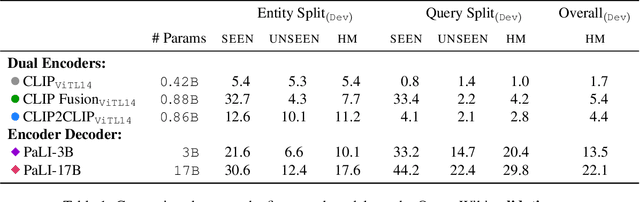
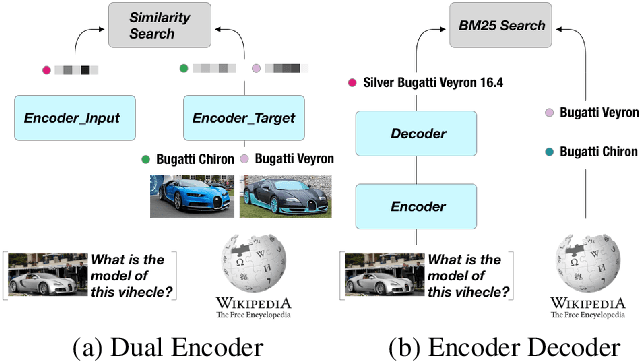
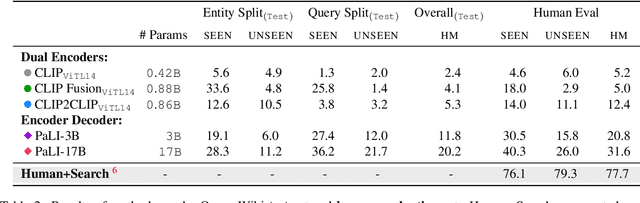

Large-scale multi-modal pre-training models such as CLIP and PaLI exhibit strong generalization on various visual domains and tasks. However, existing image classification benchmarks often evaluate recognition on a specific domain (e.g., outdoor images) or a specific task (e.g., classifying plant species), which falls short of evaluating whether pre-trained foundational models are universal visual recognizers. To address this, we formally present the task of Open-domain Visual Entity recognitioN (OVEN), where a model need to link an image onto a Wikipedia entity with respect to a text query. We construct OVEN-Wiki by re-purposing 14 existing datasets with all labels grounded onto one single label space: Wikipedia entities. OVEN challenges models to select among six million possible Wikipedia entities, making it a general visual recognition benchmark with the largest number of labels. Our study on state-of-the-art pre-trained models reveals large headroom in generalizing to the massive-scale label space. We show that a PaLI-based auto-regressive visual recognition model performs surprisingly well, even on Wikipedia entities that have never been seen during fine-tuning. We also find existing pretrained models yield different strengths: while PaLI-based models obtain higher overall performance, CLIP-based models are better at recognizing tail entities.
ConvTransSeg: A Multi-resolution Convolution-Transformer Network for Medical Image Segmentation
Oct 13, 2022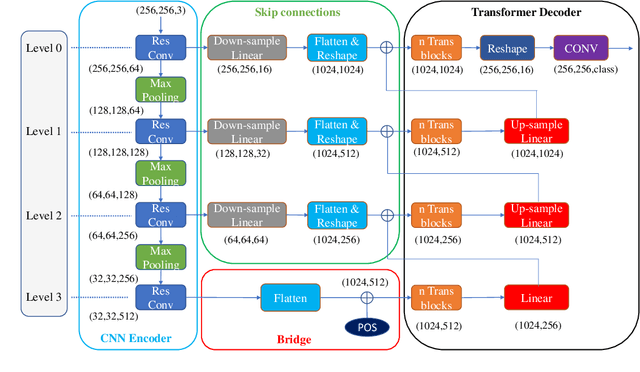
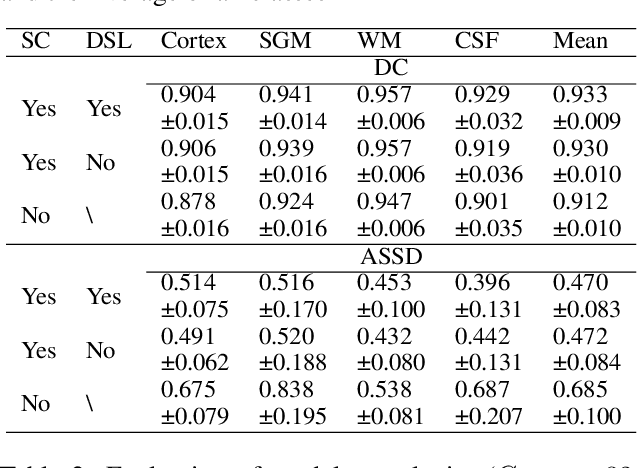
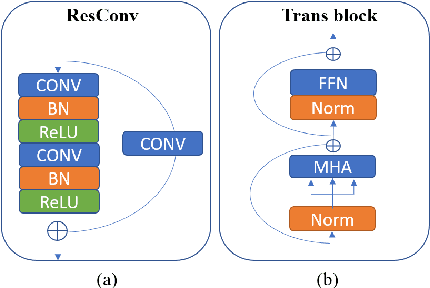
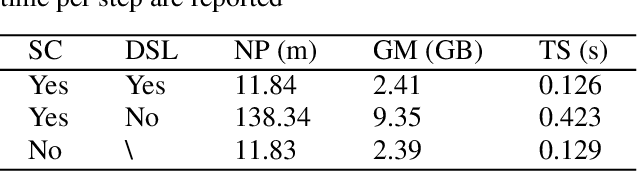
Convolutional neural networks (CNNs) achieved the state-of-the-art performance in medical image segmentation due to their ability to extract highly complex feature representations. However, it is argued in recent studies that traditional CNNs lack the intelligence to capture long-term dependencies of different image regions. Following the success of applying Transformer models on natural language processing tasks, the medical image segmentation field has also witnessed growing interest in utilizing Transformers, due to their ability to capture long-range contextual information. However, unlike CNNs, Transformers lack the ability to learn local feature representations. Thus, to fully utilize the advantages of both CNNs and Transformers, we propose a hybrid encoder-decoder segmentation model (ConvTransSeg). It consists of a multi-layer CNN as the encoder for feature learning and the corresponding multi-level Transformer as the decoder for segmentation prediction. The encoder and decoder are interconnected in a multi-resolution manner. We compared our method with many other state-of-the-art hybrid CNN and Transformer segmentation models on binary and multiple class image segmentation tasks using several public medical image datasets, including skin lesion, polyp, cell and brain tissue. The experimental results show that our method achieves overall the best performance in terms of Dice coefficient and average symmetric surface distance measures with low model complexity and memory consumption. In contrast to most Transformer-based methods that we compared, our method does not require the use of pre-trained models to achieve similar or better performance. The code is freely available for research purposes on Github: (the link will be added upon acceptance).
Bridging the Gap between Local Semantic Concepts and Bag of Visual Words for Natural Scene Image Retrieval
Oct 17, 2022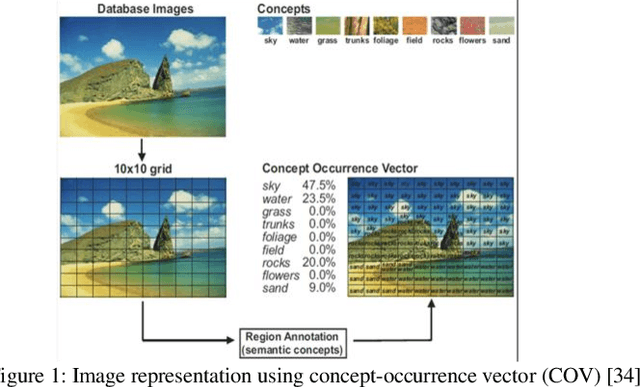



This paper addresses the problem of semantic-based image retrieval of natural scenes. A typical content-based image retrieval system deals with the query image and images in the dataset as a collection of low-level features and retrieves a ranked list of images based on the similarities between features of the query image and features of images in the image dataset. However, top ranked images in the retrieved list, which have high similarities to the query image, may be different from the query image in terms of the semantic interpretation of the user which is known as the semantic gap. In order to reduce the semantic gap, this paper investigates how natural scene retrieval can be performed using the bag of visual word model and the distribution of local semantic concepts. The paper studies the efficiency of using different approaches for representing the semantic information, depicted in natural scene images, for image retrieval. An extensive experimental work has been conducted to study the efficiency of using semantic information as well as the bag of visual words model for natural and urban scene image retrieval.