 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Reinforcement Learning from Multiple Sensors via Joint Representations
Feb 10, 2023
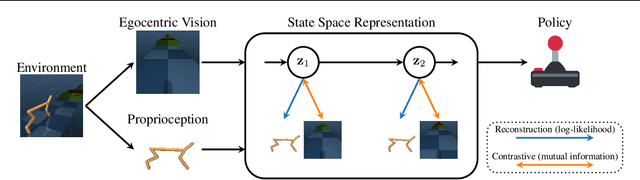


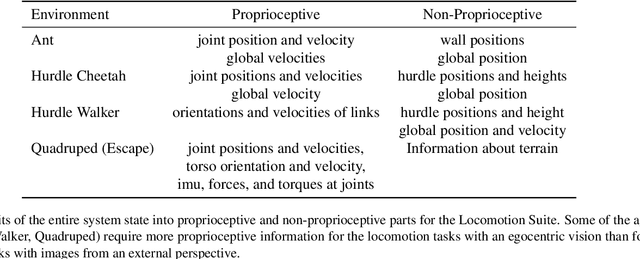
In many scenarios, observations from more than one sensor modality are available for reinforcement learning (RL). For example, many agents can perceive their internal state via proprioceptive sensors but must infer the environment's state from high-dimensional observations such as images. For image-based RL, a variety of self-supervised representation learning approaches exist to improve performance and sample complexity. These approaches learn the image representation in isolation. However, including proprioception can help representation learning algorithms to focus on relevant aspects and guide them toward finding better representations. Hence, in this work, we propose using Recurrent State Space Models to fuse all available sensory information into a single consistent representation. We combine reconstruction-based and contrastive approaches for training, which allows using the most appropriate method for each sensor modality. For example, we can use reconstruction for proprioception and a contrastive loss for images. We demonstrate the benefits of utilizing proprioception in learning representations for RL on a large set of experiments. Furthermore, we show that our joint representations significantly improve performance compared to a post hoc combination of image representations and proprioception.
Spiking sampling network for image sparse representation and dynamic vision sensor data compression
Nov 08, 2022
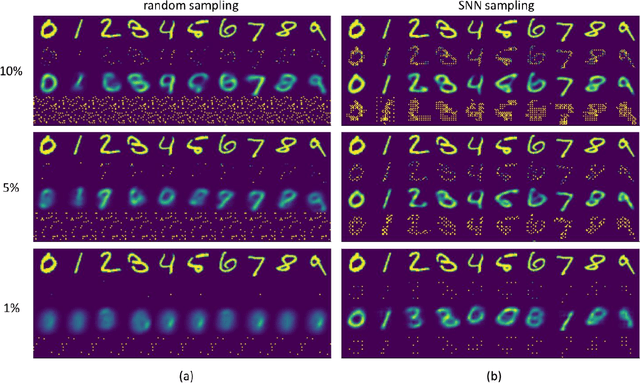
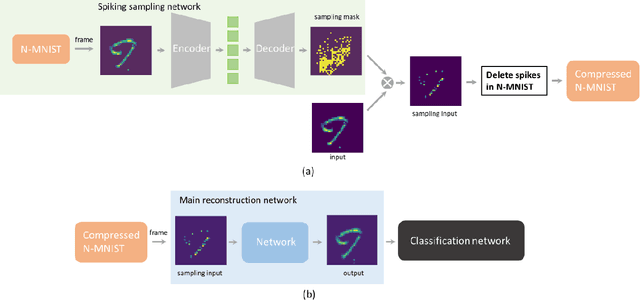
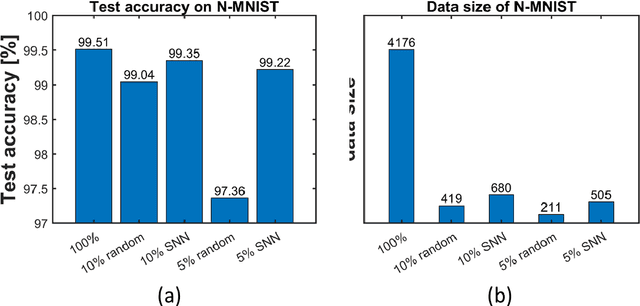
Sparse representation has attracted great attention because it can greatly save storage resources and find representative features of data in a low-dimensional space. As a result, it may be widely applied in engineering domains including feature extraction, compressed sensing, signal denoising, picture clustering, and dictionary learning, just to name a few. In this paper, we propose a spiking sampling network. This network is composed of spiking neurons, and it can dynamically decide which pixel points should be retained and which ones need to be masked according to the input. Our experiments demonstrate that this approach enables better sparse representation of the original image and facilitates image reconstruction compared to random sampling. We thus use this approach for compressing massive data from the dynamic vision sensor, which greatly reduces the storage requirements for event data.
Considerations on the Evaluation of Biometric Quality Assessment Algorithms
Mar 23, 2023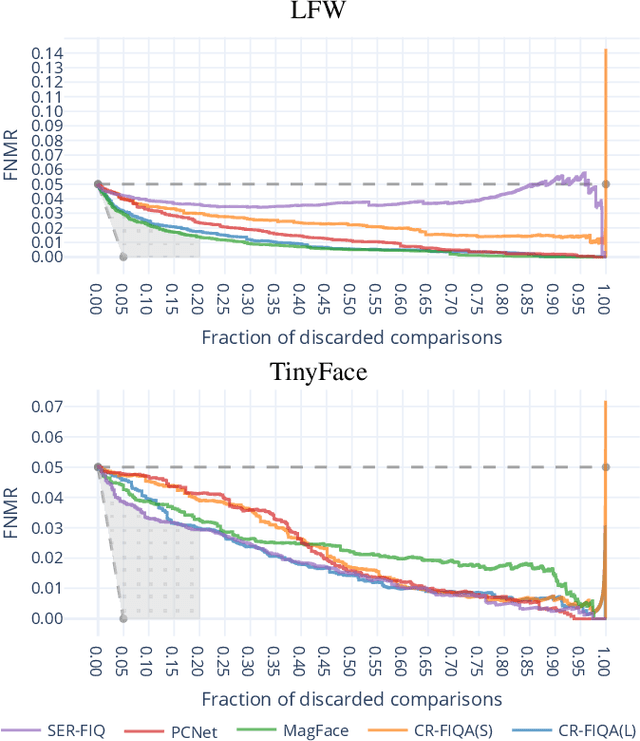
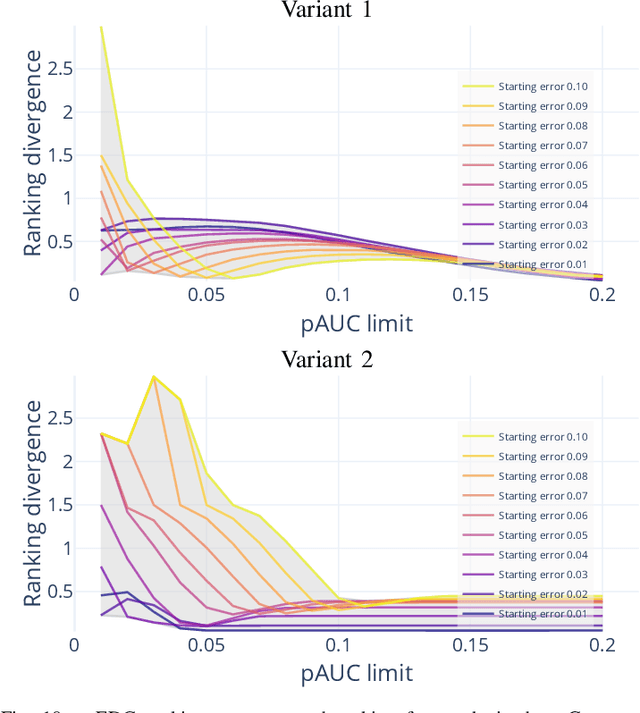
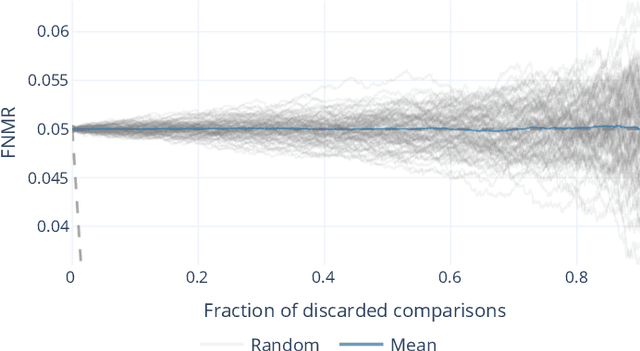
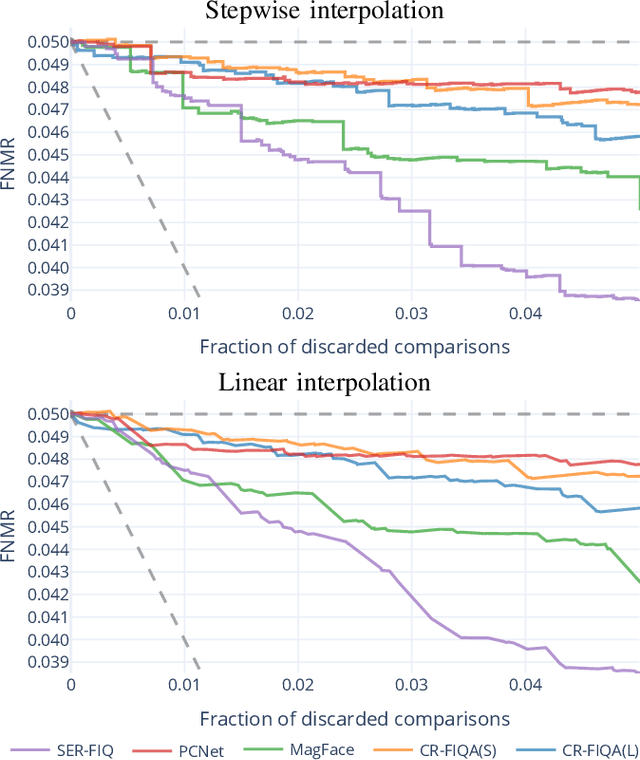
Quality assessment algorithms can be used to estimate the utility of a biometric sample for the purpose of biometric recognition. "Error versus Discard Characteristic" (EDC) plots, and "partial Area Under Curve" (pAUC) values of curves therein, are generally used by researchers to evaluate the predictive performance of such quality assessment algorithms. An EDC curve depends on an error type such as the "False Non Match Rate" (FNMR), a quality assessment algorithm, a biometric recognition system, a set of comparisons each corresponding to a biometric sample pair, and a comparison score threshold corresponding to a starting error. To compute an EDC curve, comparisons are progressively discarded based on the associated samples' lowest quality scores, and the error is computed for the remaining comparisons. Additionally, a discard fraction limit or range must be selected to compute pAUC values, which can then be used to quantitatively rank quality assessment algorithms. This paper discusses and analyses various details for this kind of quality assessment algorithm evaluation, including general EDC properties, interpretability improvements for pAUC values based on a hard lower error limit and a soft upper error limit, the use of relative instead of discrete rankings, stepwise vs. linear curve interpolation, and normalisation of quality scores to a [0, 100] integer range. We also analyse the stability of quantitative quality assessment algorithm rankings based on pAUC values across varying pAUC discard fraction limits and starting errors, concluding that higher pAUC discard fraction limits should be preferred. The analyses are conducted both with synthetic data and with real data for a face image quality assessment scenario, with a focus on general modality-independent conclusions for EDC evaluations.
Self-Supervised One-Shot Learning for Automatic Segmentation of StyleGAN Images
Mar 17, 2023
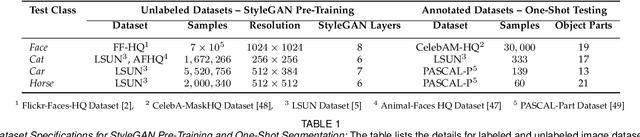

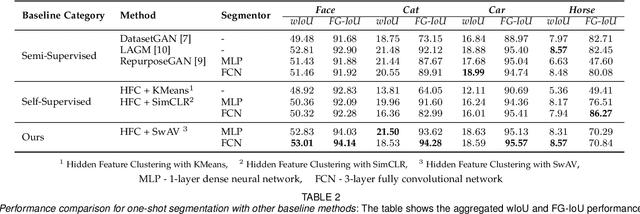
We propose a framework for the automatic one-shot segmentation of synthetic images generated by a StyleGAN. Our framework is based on the observation that the multi-scale hidden features in the GAN generator hold useful semantic information that can be utilized for automatic on-the-fly segmentation of the generated images. Using these features, our framework learns to segment synthetic images using a self-supervised contrastive clustering algorithm that projects the hidden features into a compact space for per-pixel classification. This novel contrastive learner is based on using a pixel-wise swapped prediction loss for image segmentation that leads to faster learning of the feature vectors for one-shot segmentation. We have tested our implementation on a number of standard benchmarks to yield a segmentation performance that not only outperforms the semi-supervised baseline methods by an average wIoU margin of 1.02% but also improves the inference speeds by a factor of 4.5. Finally, we also show the results of using the proposed one-shot learner in implementing BagGAN, a framework for producing annotated synthetic baggage X-ray scans for threat detection. This framework was trained and tested on the PIDRay baggage benchmark to yield a performance comparable to its baseline segmenter based on manual annotations.
Distributionally Robust Optimization with Probabilistic Group
Mar 10, 2023
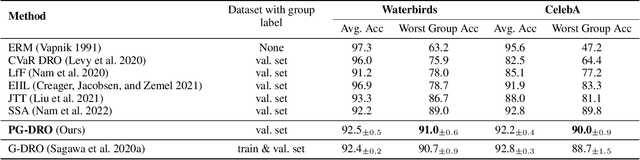

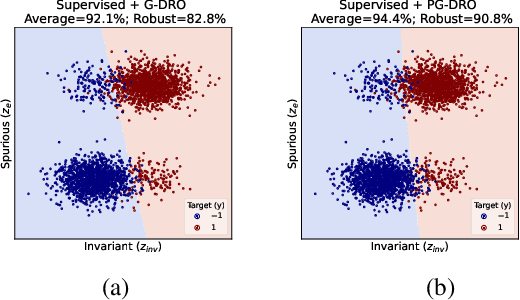
Modern machine learning models may be susceptible to learning spurious correlations that hold on average but not for the atypical group of samples. To address the problem, previous approaches minimize the empirical worst-group risk. Despite the promise, they often assume that each sample belongs to one and only one group, which does not allow expressing the uncertainty in group labeling. In this paper, we propose a novel framework PG-DRO, which explores the idea of probabilistic group membership for distributionally robust optimization. Key to our framework, we consider soft group membership instead of hard group annotations. The group probabilities can be flexibly generated using either supervised learning or zero-shot approaches. Our framework accommodates samples with group membership ambiguity, offering stronger flexibility and generality than the prior art. We comprehensively evaluate PG-DRO on both image classification and natural language processing benchmarks, establishing superior performance
Marginalia and machine learning: Handwritten text recognition for Marginalia Collections
Mar 10, 2023

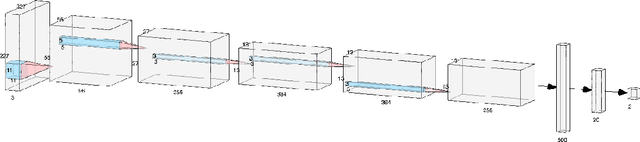
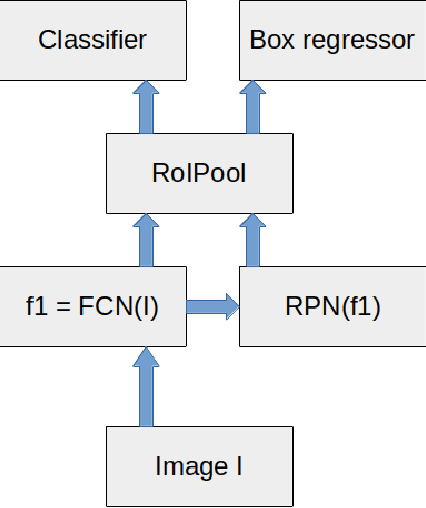
The pressing need for digitization of historical document collections has led to a strong interest in designing computerised image processing methods for automatic handwritten text recognition (HTR). Handwritten text possesses high variability due to different writing styles, languages and scripts. Training an accurate and robust HTR system calls for data-efficient approaches due to the unavailability of sufficient amounts of annotated multi-writer text. A case study on an ongoing project ``Marginalia and Machine Learning" is presented here that focuses on automatic detection and recognition of handwritten marginalia texts i.e., text written in margins or handwritten notes. Faster R-CNN network is used for detection of marginalia and AttentionHTR is used for word recognition. The data comes from early book collections (printed) found in the Uppsala University Library, with handwritten marginalia texts. Source code and pretrained models are available at https://github.com/ektavats/Project-Marginalia.
Uncertainty quantification in neural network classifiers -- a local linear approach
Mar 10, 2023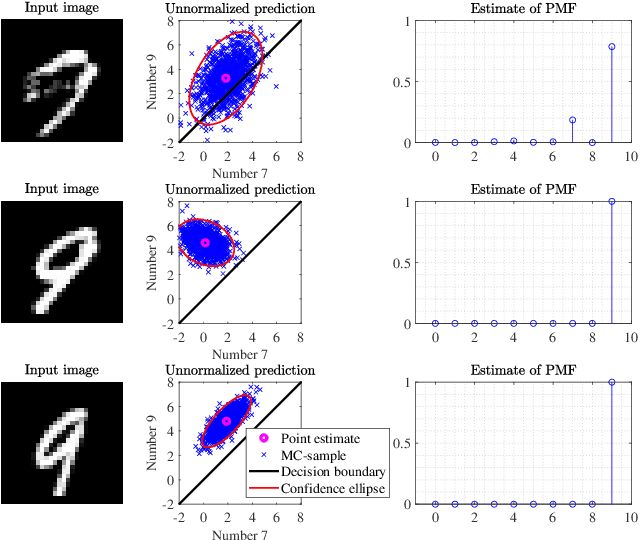
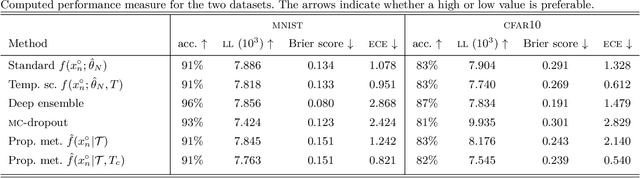
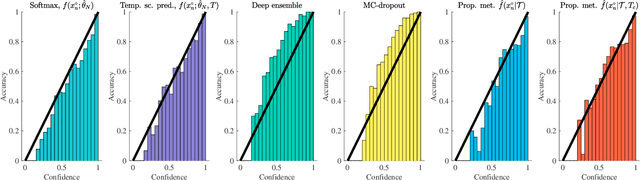
Classifiers based on neural networks (NN) often lack a measure of uncertainty in the predicted class. We propose a method to estimate the probability mass function (PMF) of the different classes, as well as the covariance of the estimated PMF. First, a local linear approach is used during the training phase to recursively compute the covariance of the parameters in the NN. Secondly, in the classification phase another local linear approach is used to propagate the covariance of the learned NN parameters to the uncertainty in the output of the last layer of the NN. This allows for an efficient Monte Carlo (MC) approach for: (i) estimating the PMF; (ii) calculating the covariance of the estimated PMF; and (iii) proper risk assessment and fusion of multiple classifiers. Two classical image classification tasks, i.e., MNIST, and CFAR10, are used to demonstrate the efficiency the proposed method.
Entropy Coding Improvement for Low-complexity Compressive Auto-encoders
Mar 10, 2023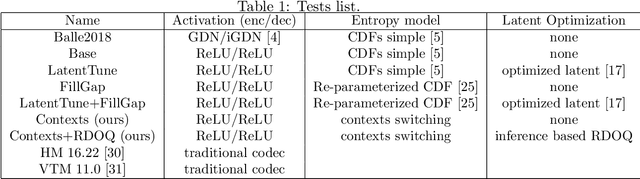
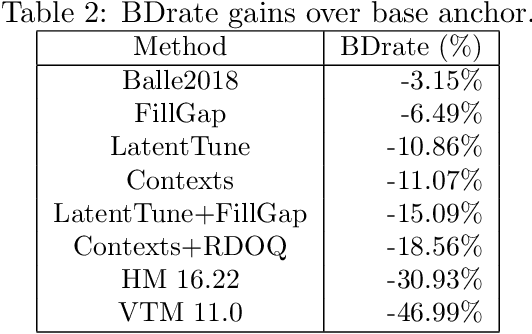
End-to-end image and video compression using auto-encoders (AE) offers new appealing perspectives in terms of rate-distortion gains and applications. While most complex models are on par with the latest compression standard like VVC/H.266 on objective metrics, practical implementation and complexity remain strong issues for real-world applications. In this paper, we propose a practical implementation suitable for realistic applications, leading to a low-complexity model. We demonstrate that some gains can be achieved on top of a state-of-the-art low-complexity AE, even when using simpler implementation. Improvements include off-training entropy coding improvement and encoder side Rate Distortion Optimized Quantization. Results show a 19% improvement in BDrate on basic implementation of fully-factorized model, and 15.3% improvement compared to the original implementation. The proposed implementation also allows a direct integration of such approaches on a variety of platforms.
MVFusion: Multi-View 3D Object Detection with Semantic-aligned Radar and Camera Fusion
Feb 21, 2023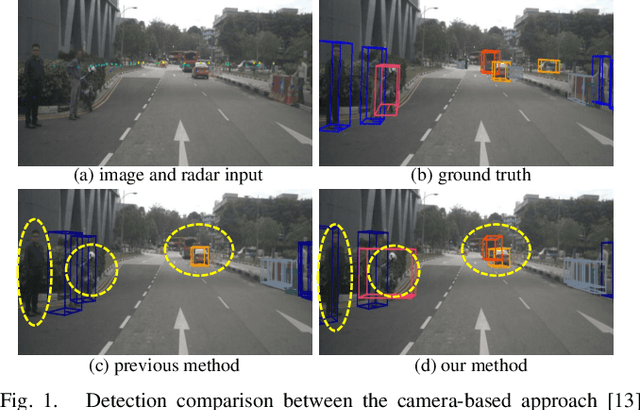
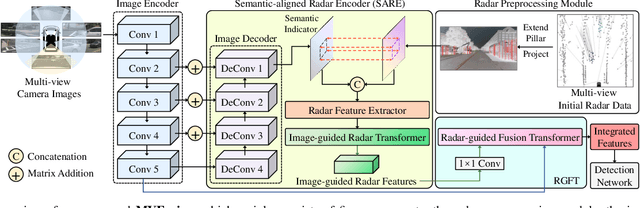

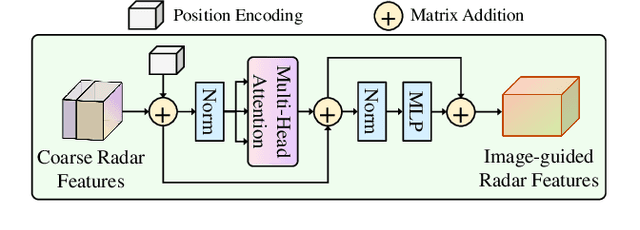
Multi-view radar-camera fused 3D object detection provides a farther detection range and more helpful features for autonomous driving, especially under adverse weather. The current radar-camera fusion methods deliver kinds of designs to fuse radar information with camera data. However, these fusion approaches usually adopt the straightforward concatenation operation between multi-modal features, which ignores the semantic alignment with radar features and sufficient correlations across modals. In this paper, we present MVFusion, a novel Multi-View radar-camera Fusion method to achieve semantic-aligned radar features and enhance the cross-modal information interaction. To achieve so, we inject the semantic alignment into the radar features via the semantic-aligned radar encoder (SARE) to produce image-guided radar features. Then, we propose the radar-guided fusion transformer (RGFT) to fuse our radar and image features to strengthen the two modals' correlation from the global scope via the cross-attention mechanism. Extensive experiments show that MVFusion achieves state-of-the-art performance (51.7% NDS and 45.3% mAP) on the nuScenes dataset. We shall release our code and trained networks upon publication.
RF-Annotate: Automatic RF-Supervised Image Annotation of Common Objects in Context
Nov 16, 2022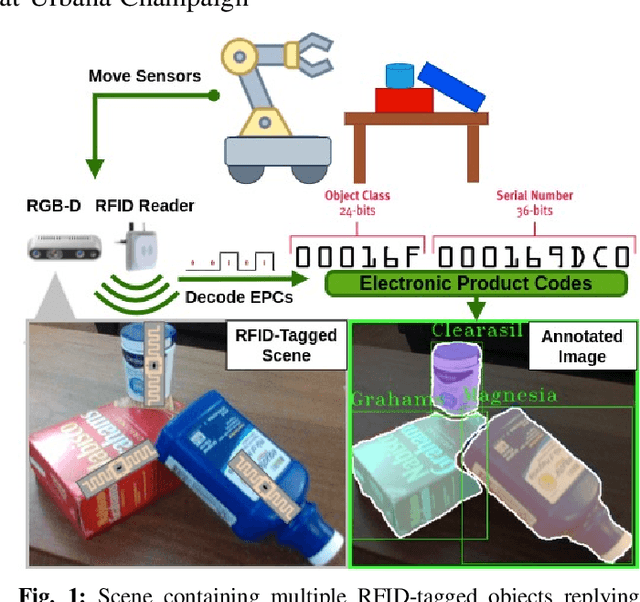
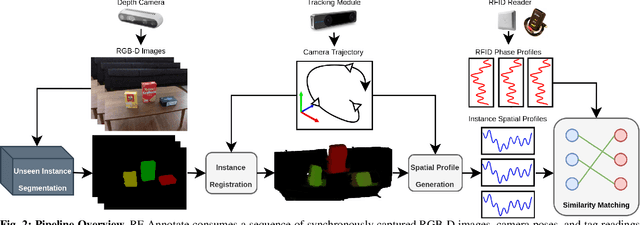


Wireless tags are increasingly used to track and identify common items of interest such as retail goods, food, medicine, clothing, books, documents, keys, equipment, and more. At the same time, there is a need for labelled visual data featuring such items for the purpose of training object detection and recognition models for robots operating in homes, warehouses, stores, libraries, pharmacies, and so on. In this paper, we ask: can we leverage the tracking and identification capabilities of such tags as a basis for a large-scale automatic image annotation system for robotic perception tasks? We present RF-Annotate, a pipeline for autonomous pixel-wise image annotation which enables robots to collect labelled visual data of objects of interest as they encounter them within their environment. Our pipeline uses unmodified commodity RFID readers and RGB-D cameras, and exploits arbitrary small-scale motions afforded by mobile robotic platforms to spatially map RFIDs to corresponding objects in the scene. Our only assumption is that the objects of interest within the environment are pre-tagged with inexpensive battery-free RFIDs costing 3-15 cents each. We demonstrate the efficacy of our pipeline on several RGB-D sequences of tabletop scenes featuring common objects in a variety of indoor environments.