 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
RFC-Net: Learning High Resolution Global Features for Medical Image Segmentation on a Computational Budget
Feb 13, 2023
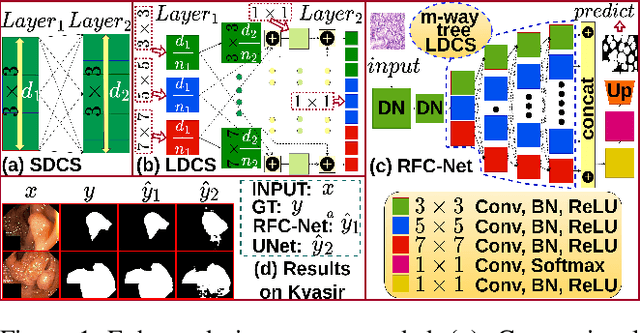
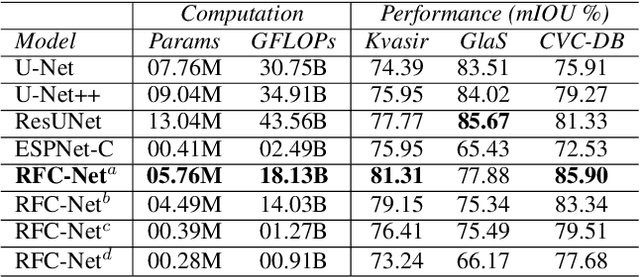
Learning High-Resolution representations is essential for semantic segmentation. Convolutional neural network (CNN)architectures with downstream and upstream propagation flow are popular for segmentation in medical diagnosis. However, due to performing spatial downsampling and upsampling in multiple stages, information loss is inexorable. On the contrary, connecting layers densely on high spatial resolution is computationally expensive. In this work, we devise a Loose Dense Connection Strategy to connect neurons in subsequent layers with reduced parameters. On top of that, using a m-way Tree structure for feature propagation we propose Receptive Field Chain Network (RFC-Net) that learns high resolution global features on a compressed computational space. Our experiments demonstrates that RFC-Net achieves state-of-the-art performance on Kvasir and CVC-ClinicDB benchmarks for Polyp segmentation.
Data-Efficient Sequence-Based Visual Place Recognition with Highly Compressed JPEG Images
Feb 26, 2023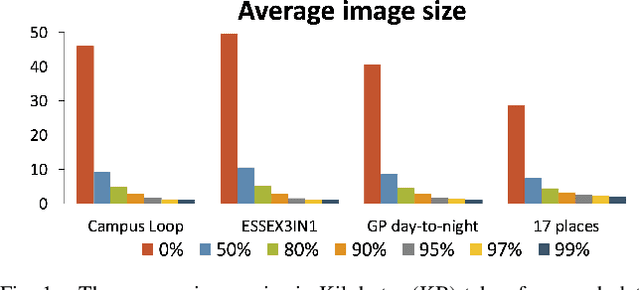
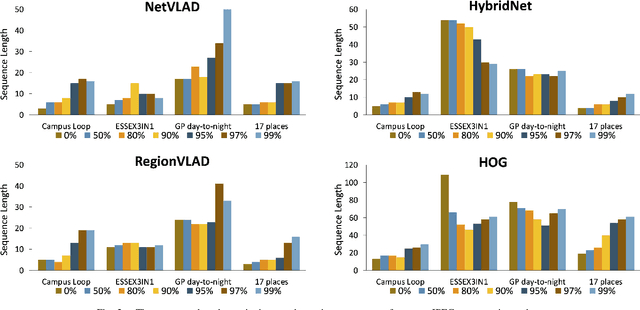

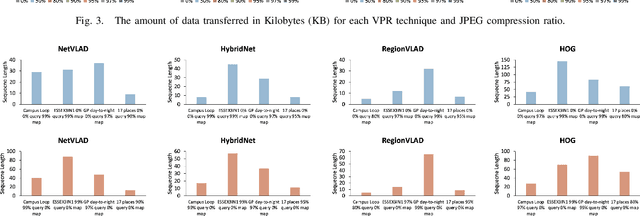
Visual Place Recognition (VPR) is a fundamental task that allows a robotic platform to successfully localise itself in the environment. For decentralised VPR applications where the visual data has to be transmitted between several agents, the communication channel may restrict the localisation process when limited bandwidth is available. JPEG is an image compression standard that can employ high compression ratios to facilitate lower data transmission for VPR applications. However, when applying high levels of JPEG compression, both the image clarity and size are drastically reduced. In this paper, we incorporate sequence-based filtering in a number of well-established, learnt and non-learnt VPR techniques to overcome the performance loss resulted from introducing high levels of JPEG compression. The sequence length that enables 100% place matching performance is reported and an analysis of the amount of data required for each VPR technique to perform the transfer on the entire spectrum of JPEG compression is provided. Moreover, the time required by each VPR technique to perform place matching is investigated, on both uniformly and non-uniformly JPEG compressed data. The results show that it is beneficial to use a highly compressed JPEG dataset with an increased sequence length, as similar levels of VPR performance are reported at a significantly reduced bandwidth. The results presented in this paper also emphasize that there is a trade-off between the amount of data transferred and the total time required to perform VPR. Our experiments also suggest that is often favourable to compress the query images to the same quality of the map, as more efficient place matching can be performed. The experiments are conducted on several VPR datasets, under mild to extreme JPEG compression.
Object-centric Learning with Cyclic Walks between Parts and Whole
Feb 16, 2023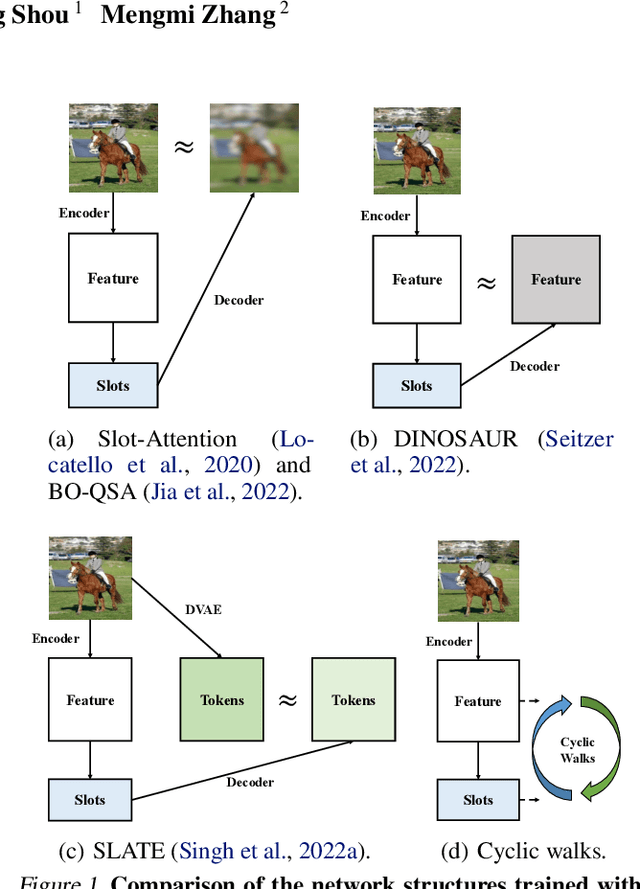
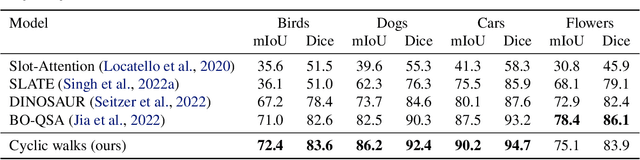
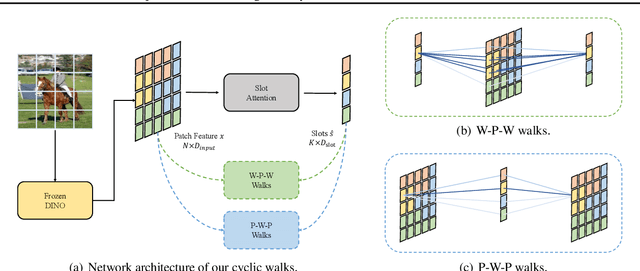
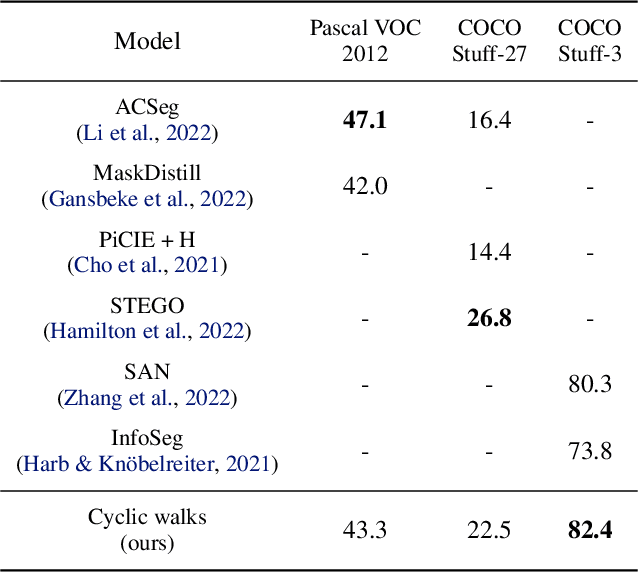
Learning object-centric representations from complex natural environments enables both humans and machines with reasoning abilities from low-level perceptual features. To capture compositional entities of the scene, we proposed cyclic walks between perceptual features extracted from CNN or transformers and object entities. First, a slot-attention module interfaces with these perceptual features and produces a finite set of slot representations. These slots can bind to any object entities in the scene via inter-slot competitions for attention. Next, we establish entity-feature correspondence with cyclic walks along high transition probability based on pairwise similarity between perceptual features (aka "parts") and slot-binded object representations (aka "whole"). The whole is greater than its parts and the parts constitute the whole. The part-whole interactions form cycle consistencies, as supervisory signals, to train the slot-attention module. We empirically demonstrate that the networks trained with our cyclic walks can extract object-centric representations on seven image datasets in three unsupervised learning tasks. In contrast to object-centric models attached with a decoder for image or feature reconstructions, our cyclic walks provide strong supervision signals, avoiding computation overheads and enhancing memory efficiency.
ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth
Feb 23, 2023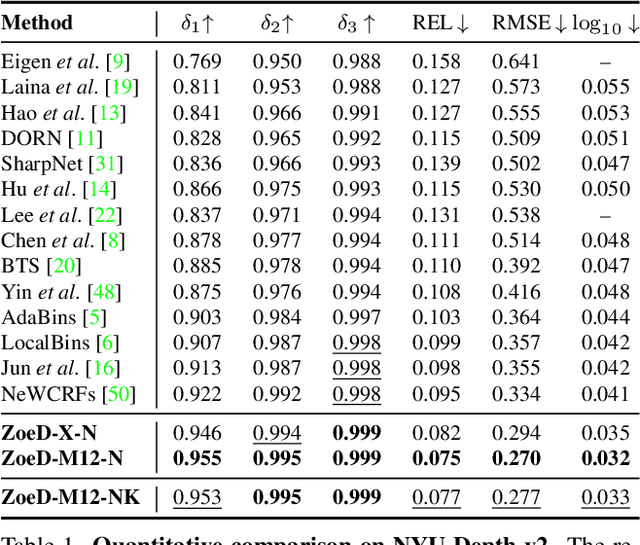

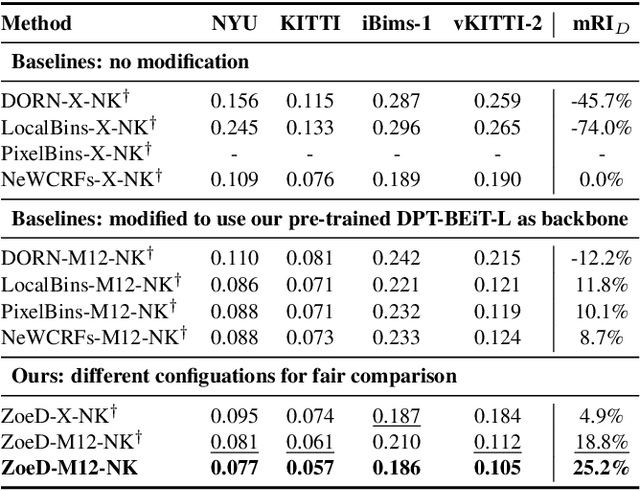
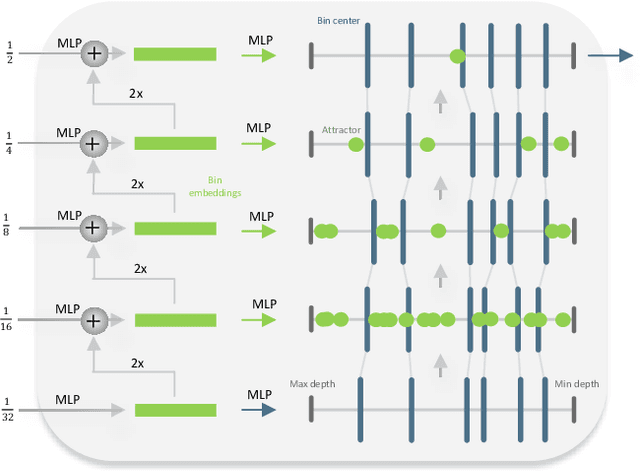
This paper tackles the problem of depth estimation from a single image. Existing work either focuses on generalization performance disregarding metric scale, i.e. relative depth estimation, or state-of-the-art results on specific datasets, i.e. metric depth estimation. We propose the first approach that combines both worlds, leading to a model with excellent generalization performance while maintaining metric scale. Our flagship model, ZoeD-M12-NK, is pre-trained on 12 datasets using relative depth and fine-tuned on two datasets using metric depth. We use a lightweight head with a novel bin adjustment design called metric bins module for each domain. During inference, each input image is automatically routed to the appropriate head using a latent classifier. Our framework admits multiple configurations depending on the datasets used for relative depth pre-training and metric fine-tuning. Without pre-training, we can already significantly improve the state of the art (SOTA) on the NYU Depth v2 indoor dataset. Pre-training on twelve datasets and fine-tuning on the NYU Depth v2 indoor dataset, we can further improve SOTA for a total of 21% in terms of relative absolute error (REL). Finally, ZoeD-M12-NK is the first model that can jointly train on multiple datasets (NYU Depth v2 and KITTI) without a significant drop in performance and achieve unprecedented zero-shot generalization performance to eight unseen datasets from both indoor and outdoor domains. The code and pre-trained models are publicly available at https://github.com/isl-org/ZoeDepth .
Federated Domain Generalization for Image Recognition via Cross-Client Style Transfer
Oct 03, 2022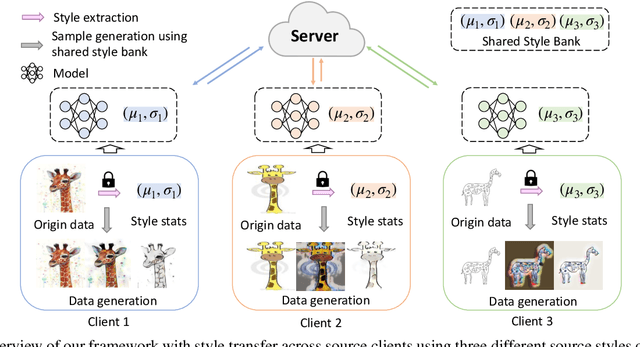
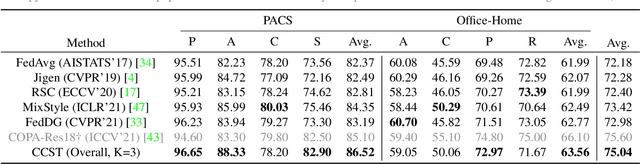
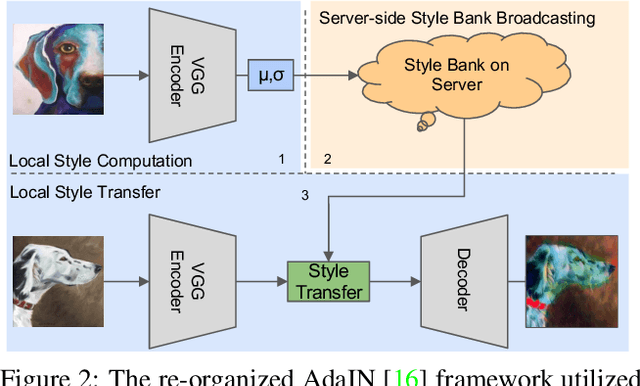
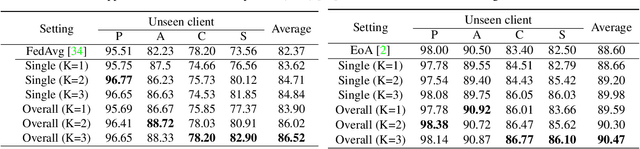
Domain generalization (DG) has been a hot topic in image recognition, with a goal to train a general model that can perform well on unseen domains. Recently, federated learning (FL), an emerging machine learning paradigm to train a global model from multiple decentralized clients without compromising data privacy, brings new challenges, also new possibilities, to DG. In the FL scenario, many existing state-of-the-art (SOTA) DG methods become ineffective, because they require the centralization of data from different domains during training. In this paper, we propose a novel domain generalization method for image recognition under federated learning through cross-client style transfer (CCST) without exchanging data samples. Our CCST method can lead to more uniform distributions of source clients, and thus make each local model learn to fit the image styles of all the clients to avoid the different model biases. Two types of style (single image style and overall domain style) with corresponding mechanisms are proposed to be chosen according to different scenarios. Our style representation is exceptionally lightweight and can hardly be used for the reconstruction of the dataset. The level of diversity is also flexible to be controlled with a hyper-parameter. Our method outperforms recent SOTA DG methods on two DG benchmarks (PACS, OfficeHome) and a large-scale medical image dataset (Camelyon17) in the FL setting. Last but not least, our method is orthogonal to many classic DG methods, achieving additive performance by combined utilization.
A Pathway Towards Responsible AI Generated Content
Mar 02, 2023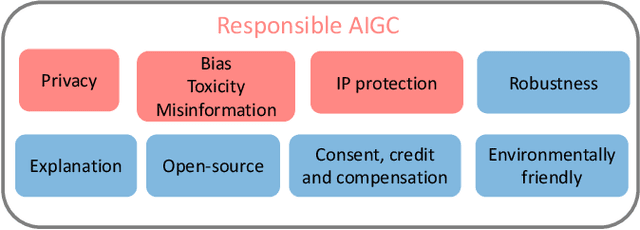
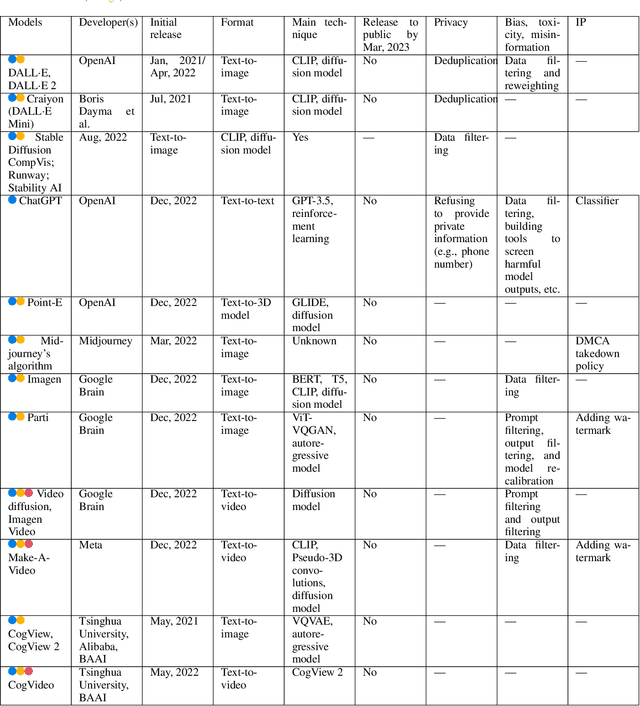
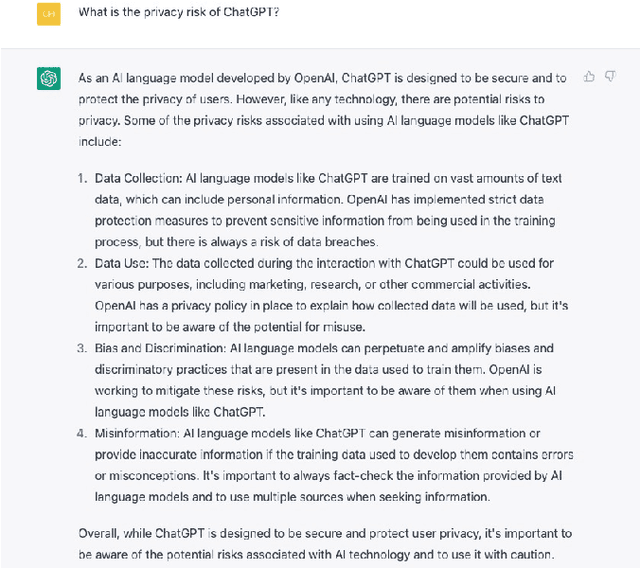

AI Generated Content (AIGC) has received tremendous attention within the past few years, with content ranging from image, text, to audio, video, etc. Meanwhile, AIGC has become a double-edged sword and recently received much criticism regarding its responsible usage. In this vision paper, we focus on three main concerns that may hinder the healthy development and deployment of AIGC in practice, including risks from privacy, bias, toxicity, misinformation, and intellectual property (IP). By documenting known and potential risks, as well as any possible misuse scenarios of AIGC, the aim is to draw attention to potential risks and misuse, help society to eliminate obstacles, and promote the more ethical and secure deployment of AIGC. Additionally, we provide insights into the promising directions for tackling these risks while constructing generative models, enabling AIGC to be used responsibly to benefit society.
Learning Deep Intensity Field for Extremely Sparse-View CBCT Reconstruction
Mar 12, 2023
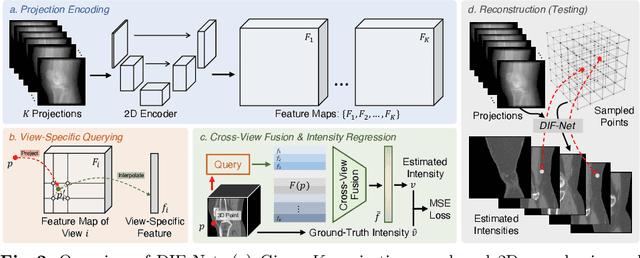
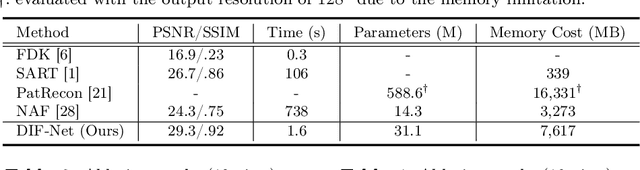
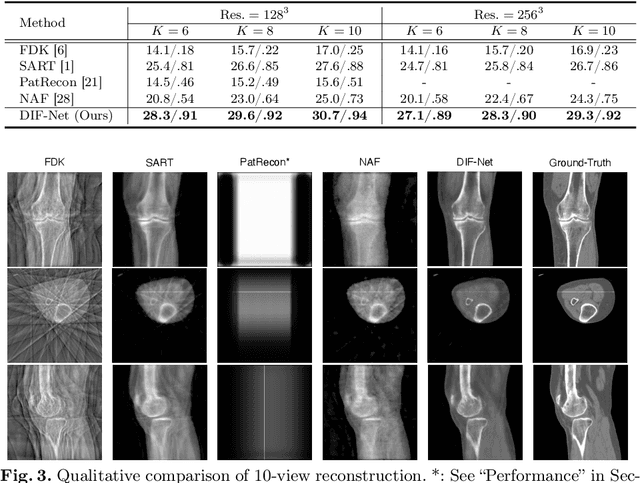
Sparse-view cone-beam CT (CBCT) reconstruction is an important direction to reduce radiation dose and benefit clinical applications. Previous voxel-based generation methods represent the CT as discrete voxels, resulting in high memory requirements and limited spatial resolution due to the use of 3D decoders. In this paper, we formulate the CT volume as a continuous intensity field and develop a novel DIF-Net to perform high-quality CBCT reconstruction from extremely sparse (fewer than 10) projection views at an ultrafast speed. The intensity field of a CT can be regarded as a continuous function of 3D spatial points. Therefore, the reconstruction can be reformulated as regressing the intensity value of an arbitrary 3D point from given sparse projections. Specifically, for a point, DIF-Net extracts its view-specific features from different 2D projection views. These features are subsequently aggregated by a fusion module for intensity estimation. Notably, thousands of points can be processed in parallel to improve efficiency during training and testing. In practice, we collect a knee CBCT dataset to train and evaluate DIF-Net. Extensive experiments show that our approach can reconstruct CBCT with high image quality and high spatial resolution from extremely sparse views within 1.6 seconds, significantly outperforming state-of-the-art methods. Our code will be available at https://github.com/lyqun/DIF-Net.
Retinex Image Enhancement Based on Sequential Decomposition With a Plug-and-Play Framework
Oct 11, 2022
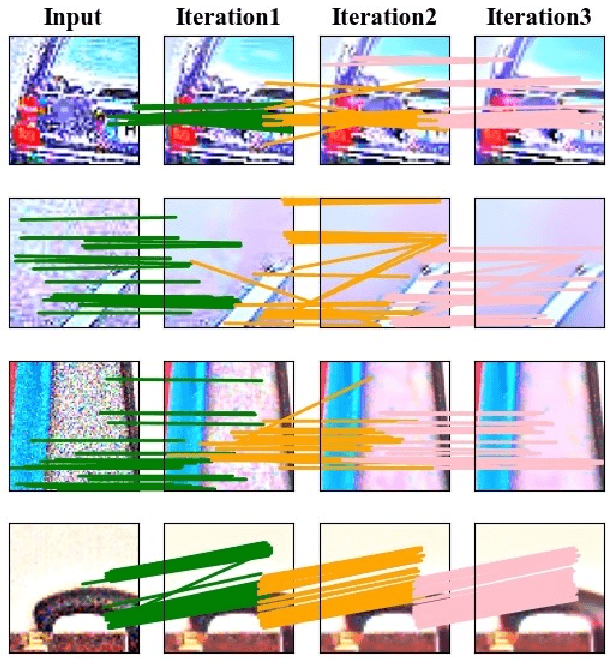


The Retinex model is one of the most representative and effective methods for low-light image enhancement. However, the Retinex model does not explicitly tackle the noise problem, and shows unsatisfactory enhancing results. In recent years, due to the excellent performance, deep learning models have been widely used in low-light image enhancement. However, these methods have two limitations: i) The desirable performance can only be achieved by deep learning when a large number of labeled data are available. However, it is not easy to curate massive low/normal-light paired data; ii) Deep learning is notoriously a black-box model [1]. It is difficult to explain their inner-working mechanism and understand their behaviors. In this paper, using a sequential Retinex decomposition strategy, we design a plug-and-play framework based on the Retinex theory for simultaneously image enhancement and noise removal. Meanwhile, we develop a convolutional neural network-based (CNN-based) denoiser into our proposed plug-and-play framework to generate a reflectance component. The final enhanced image is produced by integrating the illumination and reflectance with gamma correction. The proposed plug-and-play framework can facilitate both post hoc and ad hoc interpretability. Extensive experiments on different datasets demonstrate that our framework outcompetes the state-of-the-art methods in both image enhancement and denoising.
Adjacent-level Feature Cross-Fusion with 3D CNN for Remote Sensing Image Change Detection
Feb 10, 2023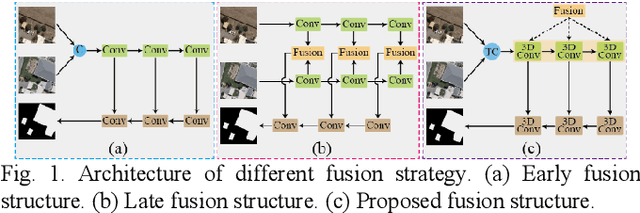

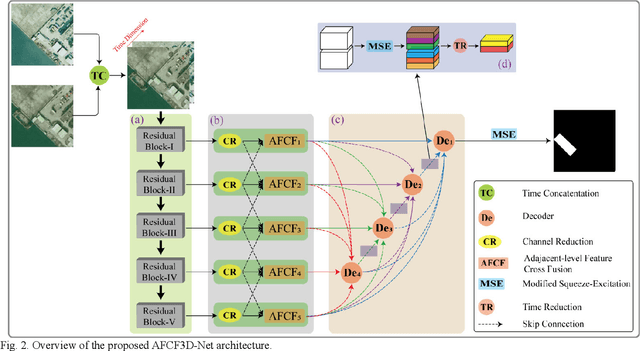
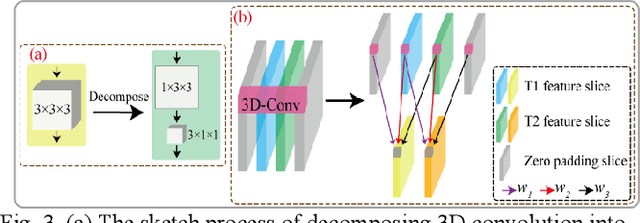
Deep learning-based change detection using remote sensing images has received increasing attention in recent years. However, how to effectively extract and fuse the deep features of bi-temporal images to improve the accuracy of change detection is still a challenge. To address that, a novel adjacent-level feature fusion network with 3D convolution (named AFCF3D-Net) is proposed in this article. First, through the inner fusion property of 3D convolution, we design a new feature fusion way that can simultaneously extract and fuse the feature information from bi-temporal images. Then, in order to bridge the semantic gap between low-level features and high-level features, we propose an adjacent-level feature cross-fusion (AFCF) module to aggregate complementary feature information between the adjacent-levels. Furthermore, the densely skip connection strategy is introduced to improve the capability of pixel-wise prediction and compactness of changed objects in the results. Finally, the proposed AFCF3D-Net has been validated on the three challenging remote sensing change detection datasets: Wuhan building dataset (WHU-CD), LEVIR building dataset (LEVIR-CD), and Sun Yat-Sen University (SYSU-CD). The results of quantitative analysis and qualitative comparison demonstrate that the proposed AFCF3D-Net achieves better performance compared to the other state-of-the-art change detection methods.
OAIR: Object-Aware Image Retargeting Using PSO and Aesthetic Quality Assessment
Sep 11, 2022
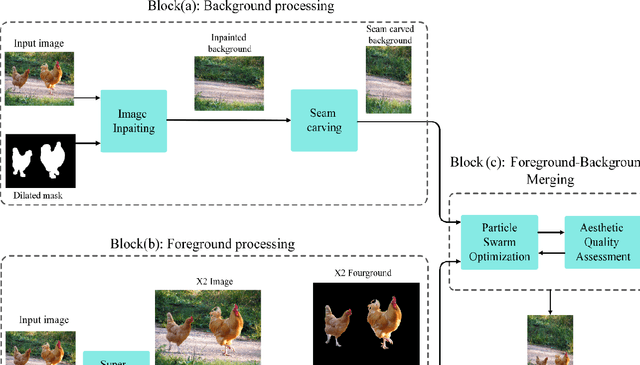

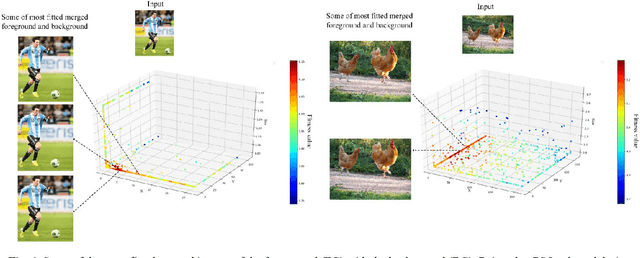
Image retargeting aims at altering an image size while preserving important content and minimizing noticeable distortions. However, previous image retargeting methods create outputs that suffer from artifacts and distortions. Besides, most previous works attempt to retarget the background and foreground of the input image simultaneously. Simultaneous resizing of the foreground and background causes changes in the aspect ratios of the objects. The change in the aspect ratio is specifically not desirable for human objects. We propose a retargeting method that overcomes these problems. The proposed approach consists of the following steps. Firstly, an inpainting method uses the input image and the binary mask of foreground objects to produce a background image without any foreground objects. Secondly, the seam carving method resizes the background image to the target size. Then, a super-resolution method increases the input image quality, and we then extract the foreground objects. Finally, the retargeted background and the extracted super-resolued objects are fed into a particle swarm optimization algorithm (PSO). The PSO algorithm uses aesthetic quality assessment as its objective function to identify the best location and size for the objects to be placed in the background. We used image quality assessment and aesthetic quality assessment measures to show our superior results compared to popular image retargeting techniques.