 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Masked Image Generation with Token-Critic
Sep 09, 2022
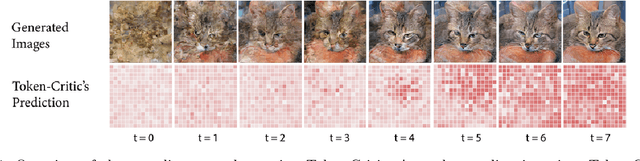
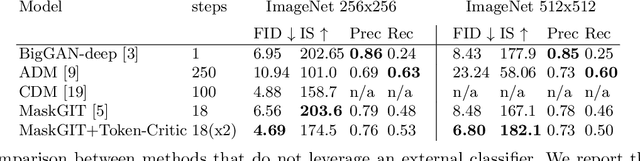
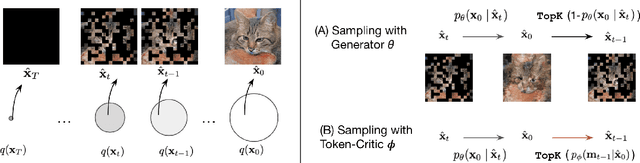
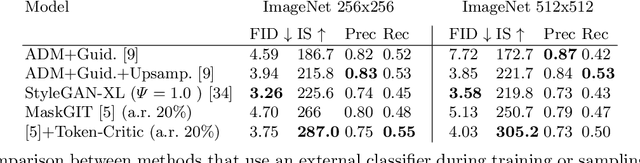
Non-autoregressive generative transformers recently demonstrated impressive image generation performance, and orders of magnitude faster sampling than their autoregressive counterparts. However, optimal parallel sampling from the true joint distribution of visual tokens remains an open challenge. In this paper we introduce Token-Critic, an auxiliary model to guide the sampling of a non-autoregressive generative transformer. Given a masked-and-reconstructed real image, the Token-Critic model is trained to distinguish which visual tokens belong to the original image and which were sampled by the generative transformer. During non-autoregressive iterative sampling, Token-Critic is used to select which tokens to accept and which to reject and resample. Coupled with Token-Critic, a state-of-the-art generative transformer significantly improves its performance, and outperforms recent diffusion models and GANs in terms of the trade-off between generated image quality and diversity, in the challenging class-conditional ImageNet generation.
Cross-View Image Sequence Geo-localization
Nov 02, 2022

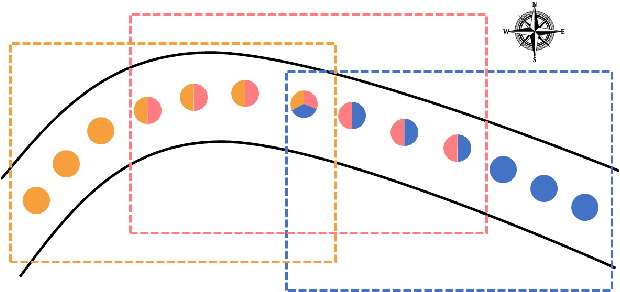
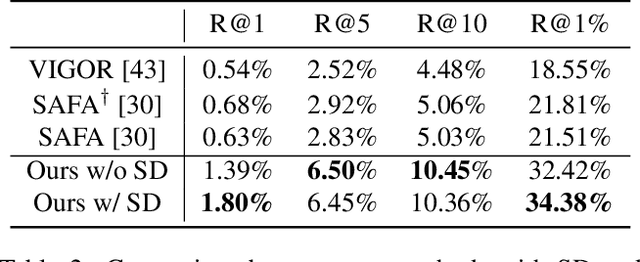
Cross-view geo-localization aims to estimate the GPS location of a query ground-view image by matching it to images from a reference database of geo-tagged aerial images. To address this challenging problem, recent approaches use panoramic ground-view images to increase the range of visibility. Although appealing, panoramic images are not readily available compared to the videos of limited Field-Of-View (FOV) images. In this paper, we present the first cross-view geo-localization method that works on a sequence of limited FOV images. Our model is trained end-to-end to capture the temporal structure that lies within the frames using the attention-based temporal feature aggregation module. To robustly tackle different sequences length and GPS noises during inference, we propose to use a sequential dropout scheme to simulate variant length sequences. To evaluate the proposed approach in realistic settings, we present a new large-scale dataset containing ground-view sequences along with the corresponding aerial-view images. Extensive experiments and comparisons demonstrate the superiority of the proposed approach compared to several competitive baselines.
PSDNet: Determination of Particle Size Distributions Using Synthetic Soil Images and Convolutional Neural Networks
Mar 07, 2023
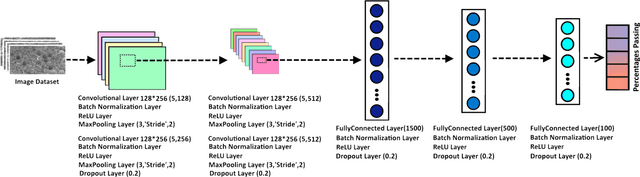
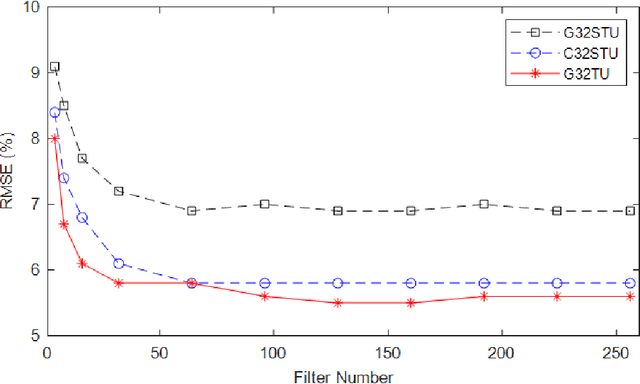
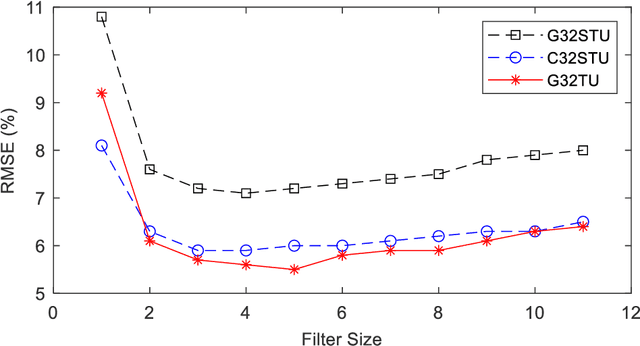
This project aimed to determine the grain size distribution of granular materials from images using convolutional neural networks. The application of ConvNet and pretrained ConvNet models, including AlexNet, SqueezeNet, GoogLeNet, InceptionV3, DenseNet201, MobileNetV2, ResNet18, ResNet50, ResNet101, Xception, InceptionResNetV2, ShuffleNet, and NASNetMobile was studied. Synthetic images of granular materials created with the discrete element code YADE were used. All the models were trained and verified with grayscale and color band datasets with image sizes ranging from 32 to 160 pixels. The proposed ConvNet model predicts the percentages of mass retained on the finest sieve, coarsest sieve, and all sieves with root-mean-square errors of 1.8 %, 3.3 %, and 2.8 %, respectively, and a coefficient of determination of 0.99. For pretrained networks, root-mean-square errors of 2.4 % and 2.8 % were obtained for the finest sieve with feature extraction and transfer learning models, respectively.
Probabilistic Contrastive Learning Recovers the Correct Aleatoric Uncertainty of Ambiguous Inputs
Feb 06, 2023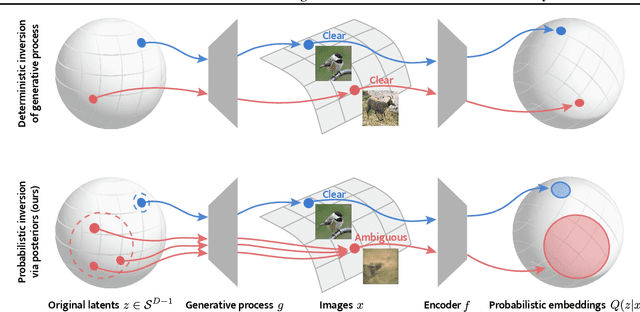
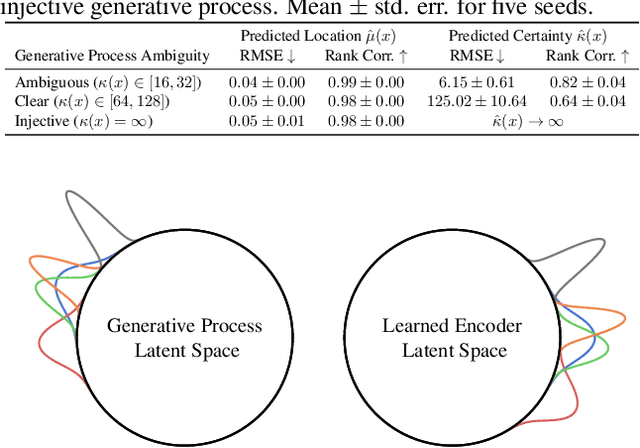
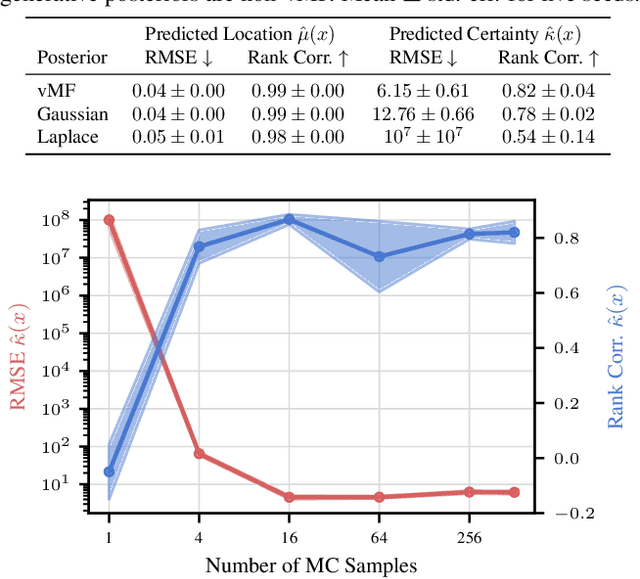
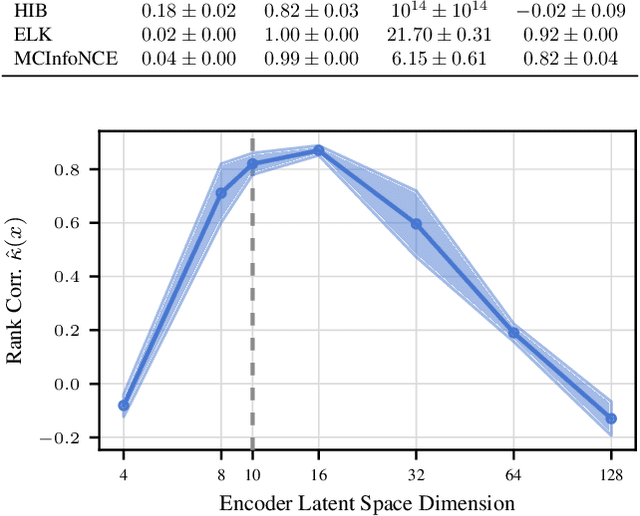
Contrastively trained encoders have recently been proven to invert the data-generating process: they encode each input, e.g., an image, into the true latent vector that generated the image (Zimmermann et al., 2021). However, real-world observations often have inherent ambiguities. For instance, images may be blurred or only show a 2D view of a 3D object, so multiple latents could have generated them. This makes the true posterior for the latent vector probabilistic with heteroscedastic uncertainty. In this setup, we extend the common InfoNCE objective and encoders to predict latent distributions instead of points. We prove that these distributions recover the correct posteriors of the data-generating process, including its level of aleatoric uncertainty, up to a rotation of the latent space. In addition to providing calibrated uncertainty estimates, these posteriors allow the computation of credible intervals in image retrieval. They comprise images with the same latent as a given query, subject to its uncertainty.
FastCLIPStyler: Towards fast text-based image style transfer using style representation
Oct 07, 2022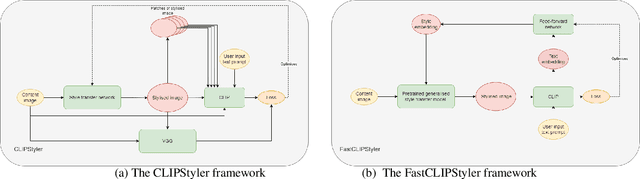

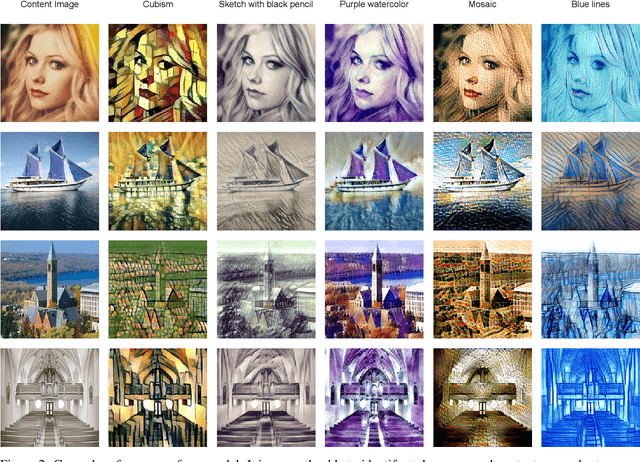

Artistic style transfer is usually performed between two images, a style image and a content image. Recently, a model named CLIPStyler demonstrated that a natural language description of style could replace the necessity of a reference style image. They achieved this by taking advantage of the CLIP model, which can compute the similarity between a text phrase and an image. In this work, we demonstrate how combining CLIPStyler with a pre-trained, purely vision-based style transfer model can significantly reduce the inference time of CLIPStyler. We call this model FastCLIPStyler. We do a qualitative exploration of the stylised images from both models and argue that our model also has merits in terms of the visual aesthetics of the generated images. Finally, we also point out how FastCLIPStyler can be used to further extend this line of research to create a generalised text-to-style model that does not require optimisation at inference time, which both CLIPStyler and FastCLIPStyler do currently.
Sneaky Spikes: Uncovering Stealthy Backdoor Attacks in Spiking Neural Networks with Neuromorphic Data
Feb 13, 2023


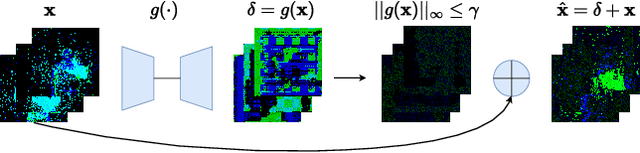
Deep neural networks (DNNs) have achieved excellent results in various tasks, including image and speech recognition. However, optimizing the performance of DNNs requires careful tuning of multiple hyperparameters and network parameters via training. High-performance DNNs utilize a large number of parameters, corresponding to high energy consumption during training. To address these limitations, researchers have developed spiking neural networks (SNNs), which are more energy-efficient and can process data in a biologically plausible manner, making them well-suited for tasks involving sensory data processing, i.e., neuromorphic data. Like DNNs, SNNs are vulnerable to various threats, such as adversarial examples and backdoor attacks. Yet, the attacks and countermeasures for SNNs have been almost fully unexplored. This paper investigates the application of backdoor attacks in SNNs using neuromorphic datasets and different triggers. More precisely, backdoor triggers in neuromorphic data can change their position and color, allowing a larger range of possibilities than common triggers in, e.g., the image domain. We propose different attacks achieving up to 100\% attack success rate without noticeable clean accuracy degradation. We also evaluate the stealthiness of the attacks via the structural similarity metric, showing our most powerful attacks being also stealthy. Finally, we adapt the state-of-the-art defenses from the image domain, demonstrating they are not necessarily effective for neuromorphic data resulting in inaccurate performance.
UniCLIP: Unified Framework for Contrastive Language-Image Pre-training
Sep 27, 2022
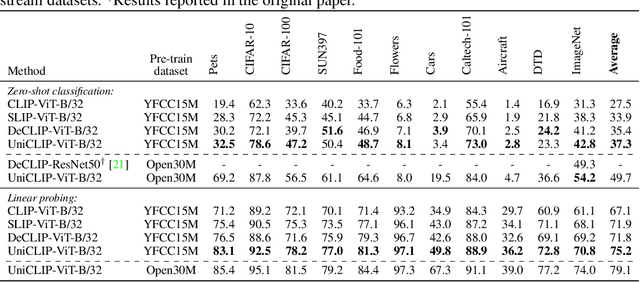
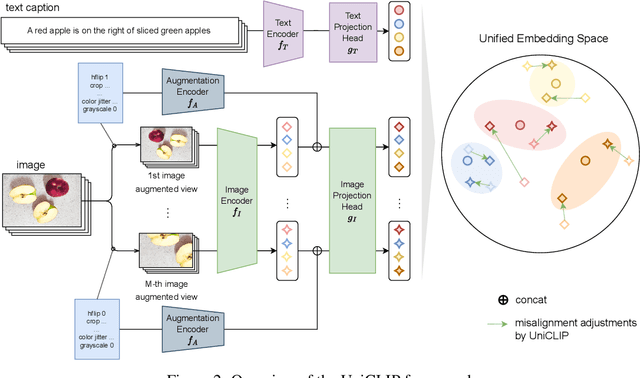
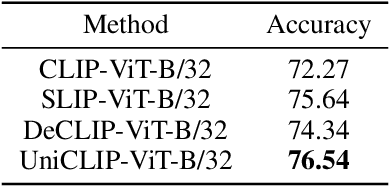
Pre-training vision-language models with contrastive objectives has shown promising results that are both scalable to large uncurated datasets and transferable to many downstream applications. Some following works have targeted to improve data efficiency by adding self-supervision terms, but inter-domain (image-text) contrastive loss and intra-domain (image-image) contrastive loss are defined on individual spaces in those works, so many feasible combinations of supervision are overlooked. To overcome this issue, we propose UniCLIP, a Unified framework for Contrastive Language-Image Pre-training. UniCLIP integrates the contrastive loss of both inter-domain pairs and intra-domain pairs into a single universal space. The discrepancies that occur when integrating contrastive loss between different domains are resolved by the three key components of UniCLIP: (1) augmentation-aware feature embedding, (2) MP-NCE loss, and (3) domain dependent similarity measure. UniCLIP outperforms previous vision-language pre-training methods on various single- and multi-modality downstream tasks. In our experiments, we show that each component that comprises UniCLIP contributes well to the final performance.
Meme Sentiment Analysis Enhanced with Multimodal Spatial Encoding and Facial Embedding
Mar 03, 2023Internet memes are characterised by the interspersing of text amongst visual elements. State-of-the-art multimodal meme classifiers do not account for the relative positions of these elements across the two modalities, despite the latent meaning associated with where text and visual elements are placed. Against two meme sentiment classification datasets, we systematically show performance gains from incorporating the spatial position of visual objects, faces, and text clusters extracted from memes. In addition, we also present facial embedding as an impactful enhancement to image representation in a multimodal meme classifier. Finally, we show that incorporating this spatial information allows our fully automated approaches to outperform their corresponding baselines that rely on additional human validation of OCR-extracted text.
* Published as chapter in ISBN:978-3-031-26438-2
A Multi-scale Video Denoising Algorithm for Raw Image
Sep 05, 2022
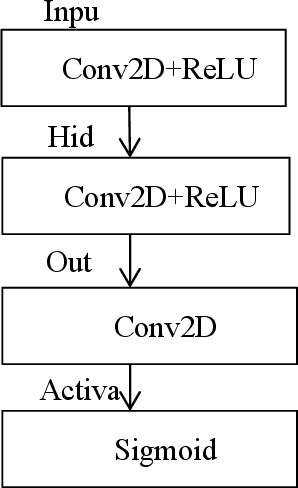
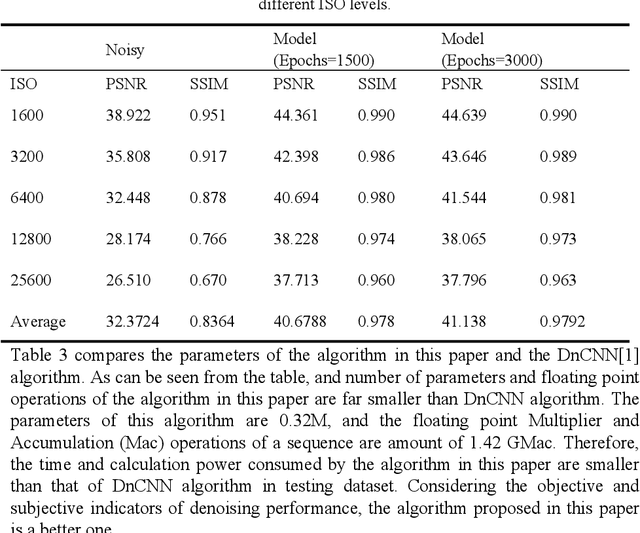
Video denoising for raw image has always been the difficulty of camera image processing. On the one hand, image denoising performance largely determines the image quality, moreover denoising effect in raw image will affect the accuracy of the following operations of ISP processing flow. On the other hand, compared with image, video have motion information in time sequence, thus motion estimation which is complex and computationally expensive is needed in video denoising. In view of the above problems, this paper proposes a video denoising algorithm for raw image, performing multiple cascading processing stages on raw-RGB image based on convolutional neural network, and carries out implicit motion estimation in the network. The denoising performance is far superior to that of traditional algorithms with minimal computation and bandwidth, and has computational advantages compared with most deep learning algorithms.
Euler Characteristic Transform Based Topological Loss for Reconstructing 3D Images from Single 2D Slices
Mar 08, 2023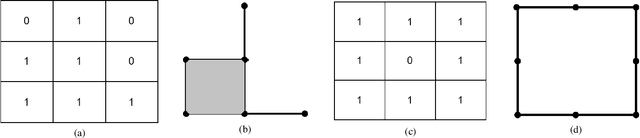

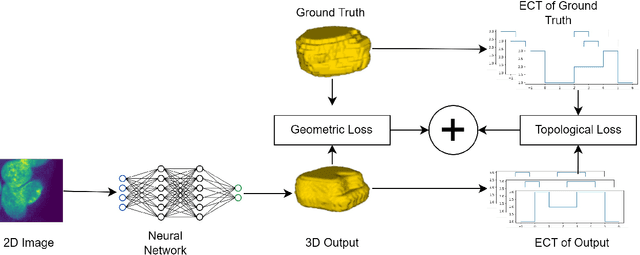
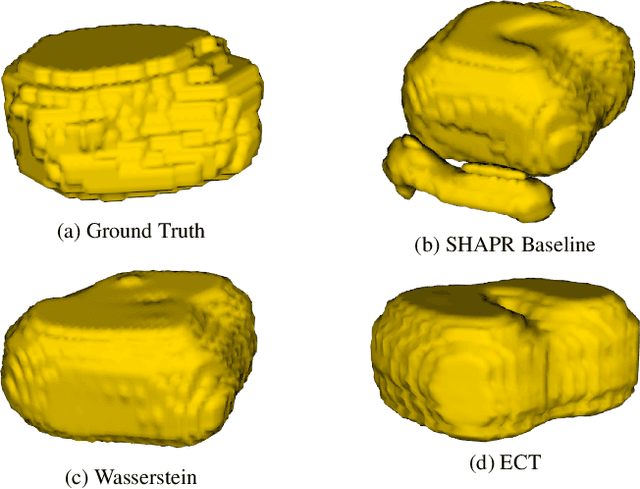
The computer vision task of reconstructing 3D images, i.e., shapes, from their single 2D image slices is extremely challenging, more so in the regime of limited data. Deep learning models typically optimize geometric loss functions, which may lead to poor reconstructions as they ignore the structural properties of the shape. To tackle this, we propose a novel topological loss function based on the Euler Characteristic Transform. This loss can be used as an inductive bias to aid the optimization of any neural network toward better reconstructions in the regime of limited data. We show the effectiveness of the proposed loss function by incorporating it into SHAPR, a state-of-the-art shape reconstruction model, and test it on two benchmark datasets, viz., Red Blood Cells and Nuclei datasets. We also show a favourable property, namely injectivity and discuss the stability of the topological loss function based on the Euler Characteristic Transform.