 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Calibrated Teacher for Sparsely Annotated Object Detection
Mar 14, 2023

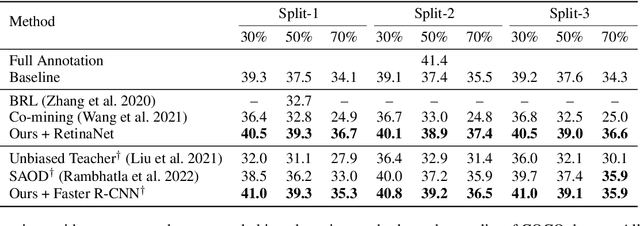
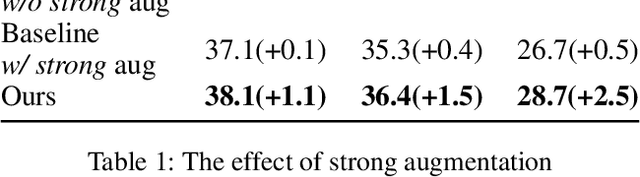
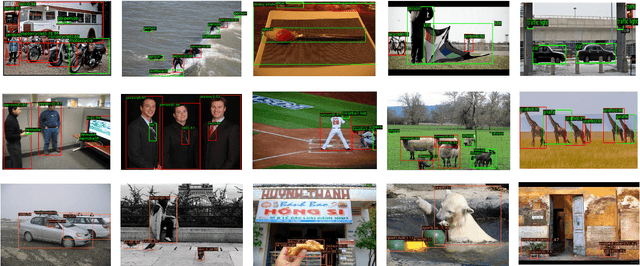
Fully supervised object detection requires training images in which all instances are annotated. This is actually impractical due to the high labor and time costs and the unavoidable missing annotations. As a result, the incomplete annotation in each image could provide misleading supervision and harm the training. Recent works on sparsely annotated object detection alleviate this problem by generating pseudo labels for the missing annotations. Such a mechanism is sensitive to the threshold of the pseudo label score. However, the effective threshold is different in different training stages and among different object detectors. Therefore, the current methods with fixed thresholds have sub-optimal performance, and are difficult to be applied to other detectors. In order to resolve this obstacle, we propose a Calibrated Teacher, of which the confidence estimation of the prediction is well calibrated to match its real precision. In this way, different detectors in different training stages would share a similar distribution of the output confidence, so that multiple detectors could share the same fixed threshold and achieve better performance. Furthermore, we present a simple but effective Focal IoU Weight (FIoU) for the classification loss. FIoU aims at reducing the loss weight of false negative samples caused by the missing annotation, and thus works as the complement of the teacher-student paradigm. Extensive experiments show that our methods set new state-of-the-art under all different sparse settings in COCO. Code will be available at https://github.com/Whileherham/CalibratedTeacher.
Edit-A-Video: Single Video Editing with Object-Aware Consistency
Mar 14, 2023
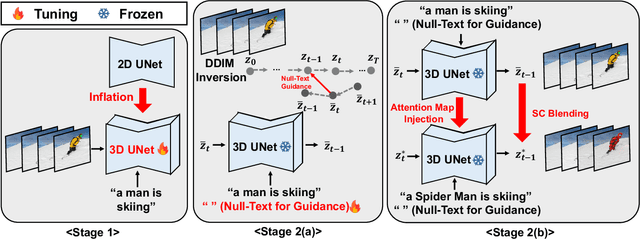
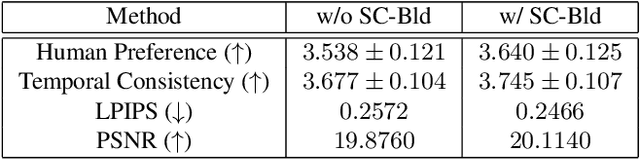

Despite the fact that text-to-video (TTV) model has recently achieved remarkable success, there have been few approaches on TTV for its extension to video editing. Motivated by approaches on TTV models adapting from diffusion-based text-to-image (TTI) models, we suggest the video editing framework given only a pretrained TTI model and a single <text, video> pair, which we term Edit-A-Video. The framework consists of two stages: (1) inflating the 2D model into the 3D model by appending temporal modules and tuning on the source video (2) inverting the source video into the noise and editing with target text prompt and attention map injection. Each stage enables the temporal modeling and preservation of semantic attributes of the source video. One of the key challenges for video editing include a background inconsistency problem, where the regions not included for the edit suffer from undesirable and inconsistent temporal alterations. To mitigate this issue, we also introduce a novel mask blending method, termed as sparse-causal blending (SC Blending). We improve previous mask blending methods to reflect the temporal consistency so that the area where the editing is applied exhibits smooth transition while also achieving spatio-temporal consistency of the unedited regions. We present extensive experimental results over various types of text and videos, and demonstrate the superiority of the proposed method compared to baselines in terms of background consistency, text alignment, and video editing quality.
Scaling Robot Learning with Semantically Imagined Experience
Feb 22, 2023
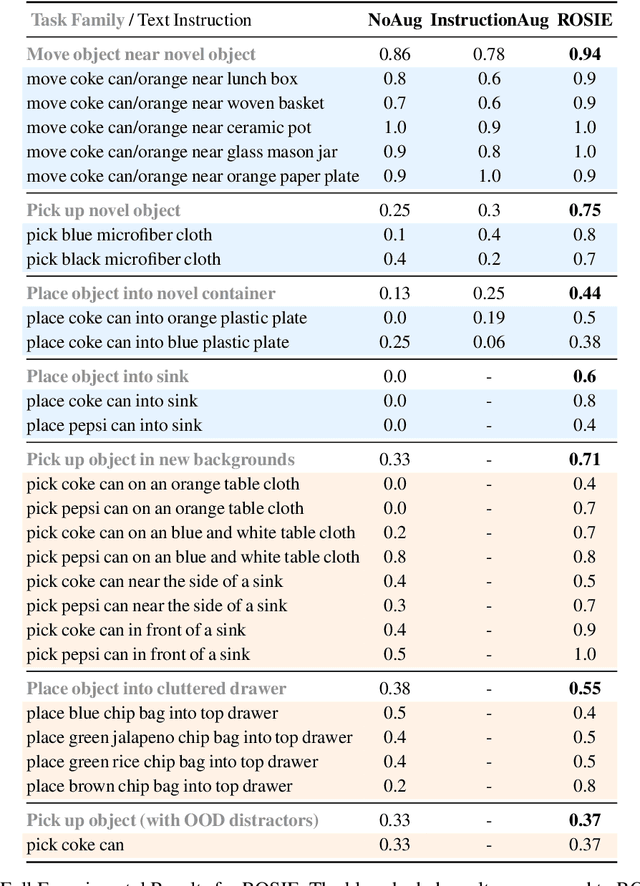
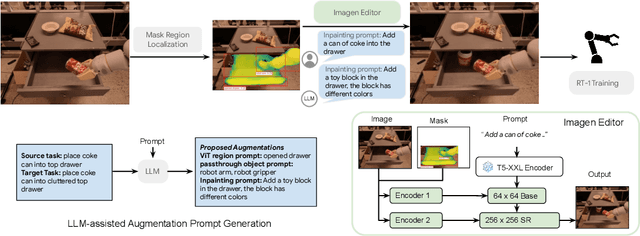

Recent advances in robot learning have shown promise in enabling robots to perform a variety of manipulation tasks and generalize to novel scenarios. One of the key contributing factors to this progress is the scale of robot data used to train the models. To obtain large-scale datasets, prior approaches have relied on either demonstrations requiring high human involvement or engineering-heavy autonomous data collection schemes, both of which are challenging to scale. To mitigate this issue, we propose an alternative route and leverage text-to-image foundation models widely used in computer vision and natural language processing to obtain meaningful data for robot learning without requiring additional robot data. We term our method Robot Learning with Semantically Imagened Experience (ROSIE). Specifically, we make use of the state of the art text-to-image diffusion models and perform aggressive data augmentation on top of our existing robotic manipulation datasets via inpainting various unseen objects for manipulation, backgrounds, and distractors with text guidance. Through extensive real-world experiments, we show that manipulation policies trained on data augmented this way are able to solve completely unseen tasks with new objects and can behave more robustly w.r.t. novel distractors. In addition, we find that we can improve the robustness and generalization of high-level robot learning tasks such as success detection through training with the diffusion-based data augmentation. The project's website and videos can be found at diffusion-rosie.github.io
Graph Decision Transformer
Mar 07, 2023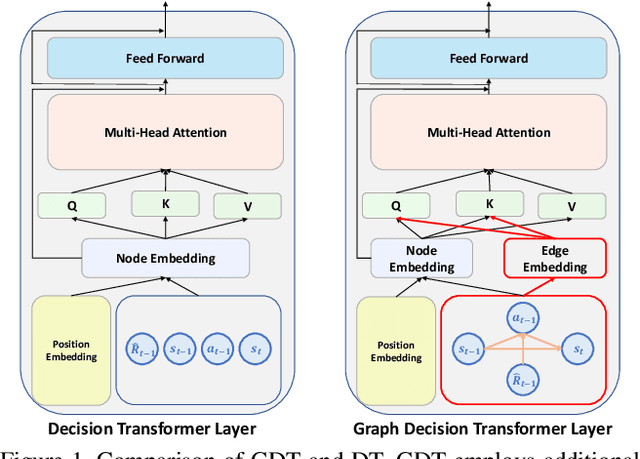

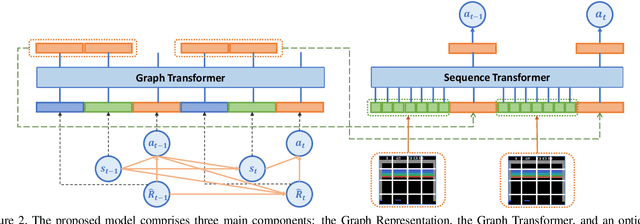
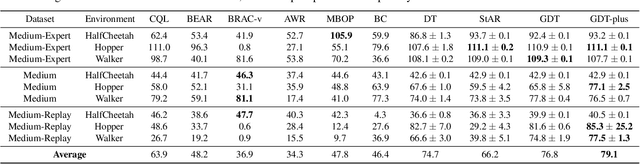
Offline reinforcement learning (RL) is a challenging task, whose objective is to learn policies from static trajectory data without interacting with the environment. Recently, offline RL has been viewed as a sequence modeling problem, where an agent generates a sequence of subsequent actions based on a set of static transition experiences. However, existing approaches that use transformers to attend to all tokens naively can overlook the dependencies between different tokens and limit long-term dependency learning. In this paper, we propose the Graph Decision Transformer (GDT), a novel offline RL approach that models the input sequence into a causal graph to capture potential dependencies between fundamentally different concepts and facilitate temporal and causal relationship learning. GDT uses a graph transformer to process the graph inputs with relation-enhanced mechanisms, and an optional sequence transformer to handle fine-grained spatial information in visual tasks. Our experiments show that GDT matches or surpasses the performance of state-of-the-art offline RL methods on image-based Atari and OpenAI Gym.
Multi-stage image denoising with the wavelet transform
Sep 27, 2022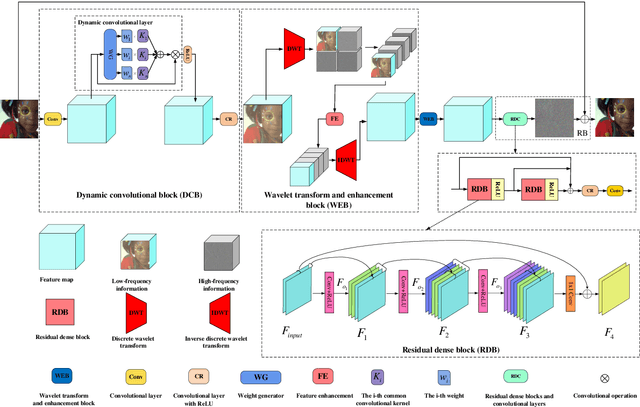
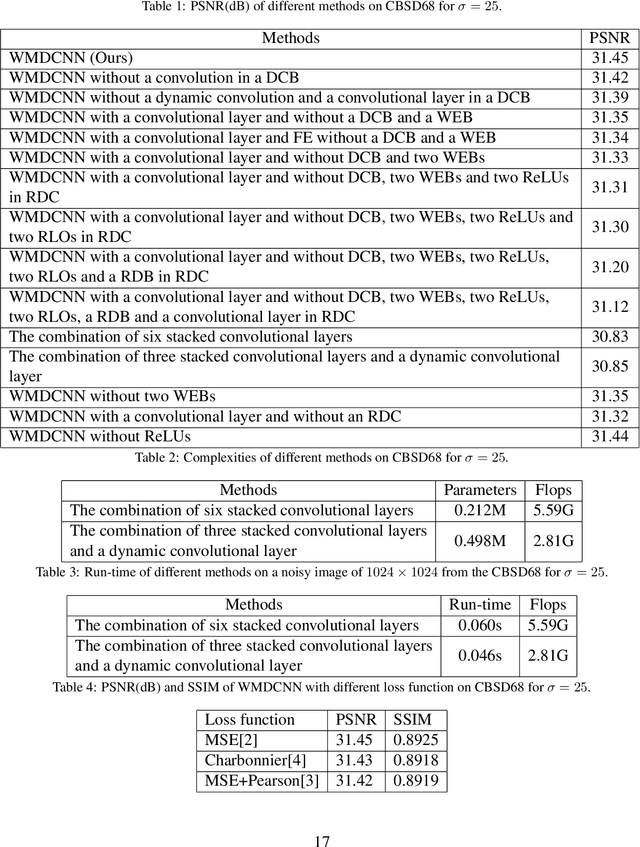
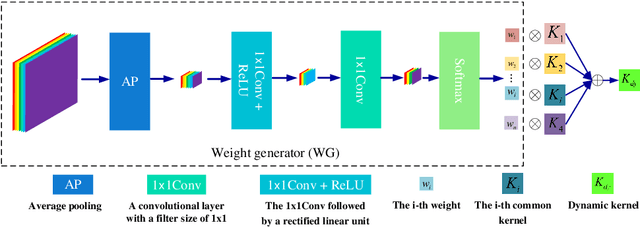
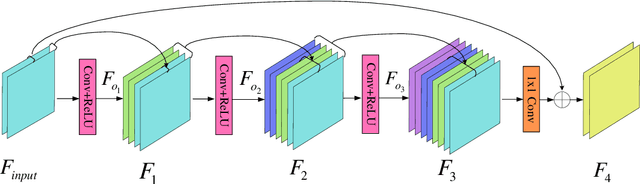
Deep convolutional neural networks (CNNs) are used for image denoising via automatically mining accurate structure information. However, most of existing CNNs depend on enlarging depth of designed networks to obtain better denoising performance, which may cause training difficulty. In this paper, we propose a multi-stage image denoising CNN with the wavelet transform (MWDCNN) via three stages, i.e., a dynamic convolutional block (DCB), two cascaded wavelet transform and enhancement blocks (WEBs) and residual block (RB). DCB uses a dynamic convolution to dynamically adjust parameters of several convolutions for making a tradeoff between denoising performance and computational costs. WEB uses a combination of signal processing technique (i.e., wavelet transformation) and discriminative learning to suppress noise for recovering more detailed information in image denoising. To further remove redundant features, RB is used to refine obtained features for improving denoising effects and reconstruct clean images via improved residual dense architectures. Experimental results show that the proposed MWDCNN outperforms some popular denoising methods in terms of quantitative and qualitative analysis. Codes are available at https://github.com/hellloxiaotian/MWDCNN.
Extremal Domain Translation with Neural Optimal Transport
Jan 30, 2023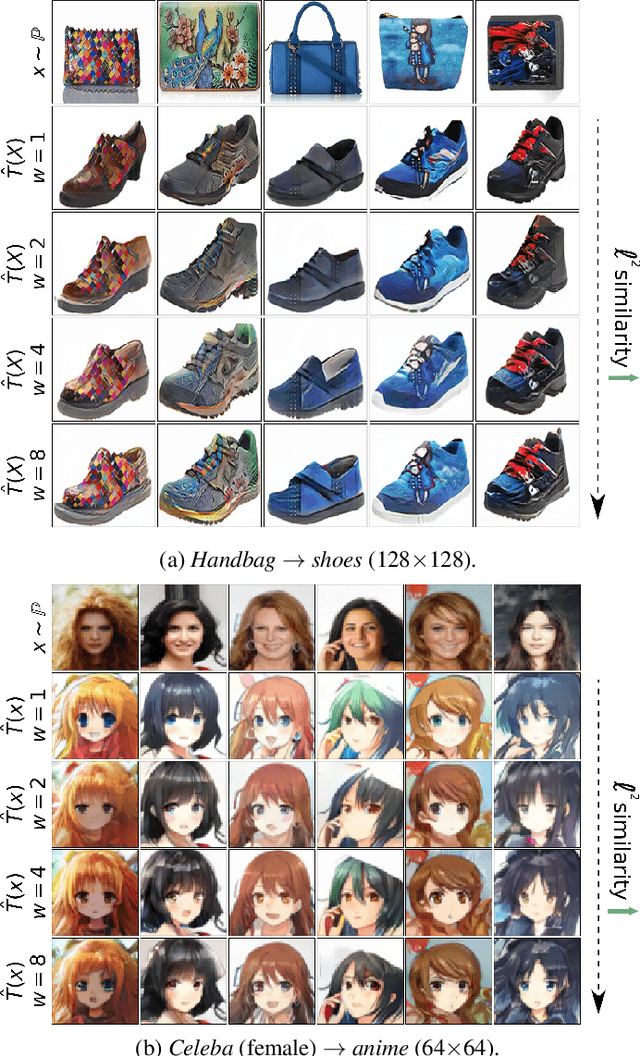
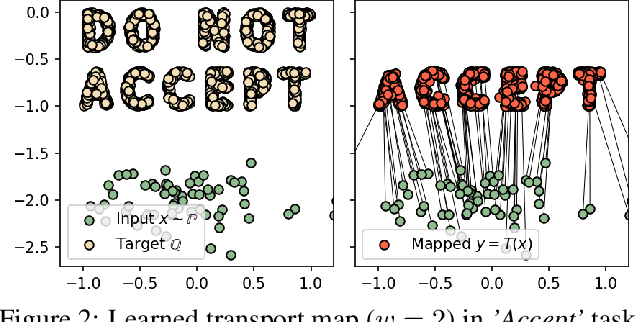
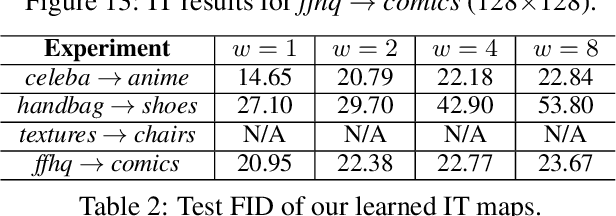
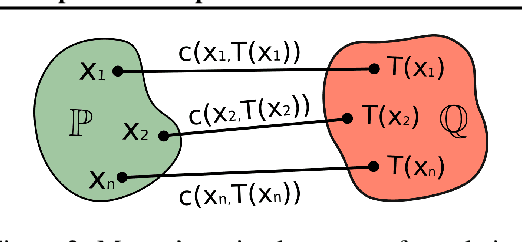
We propose the extremal transport (ET) which is a mathematical formalization of the theoretically best possible unpaired translation between a pair of domains w.r.t. the given similarity function. Inspired by the recent advances in neural optimal transport (OT), we propose a scalable algorithm to approximate ET maps as a limit of partial OT maps. We test our algorithm on toy examples and on the unpaired image-to-image translation task.
Novel Fundus Image Preprocessing for Retcam Images to Improve Deep Learning Classification of Retinopathy of Prematurity
Feb 16, 2023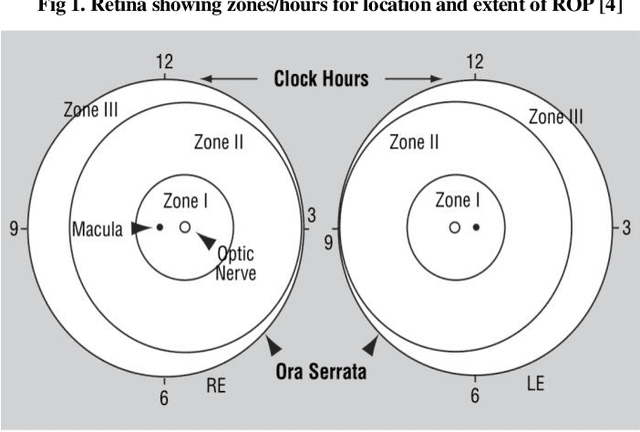
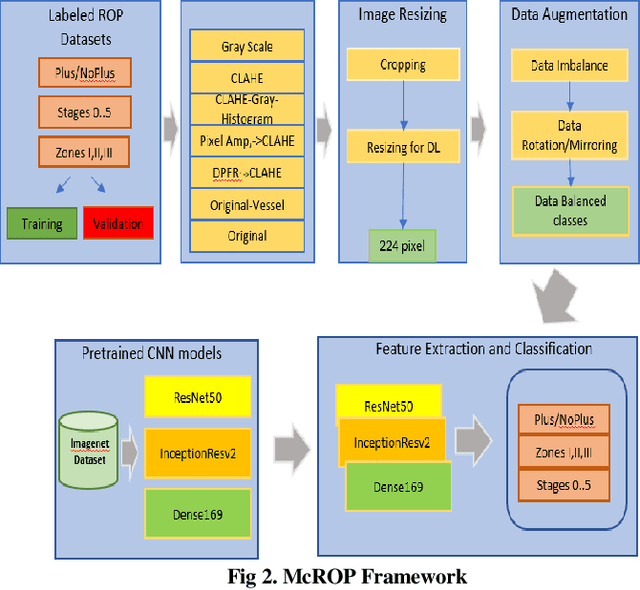
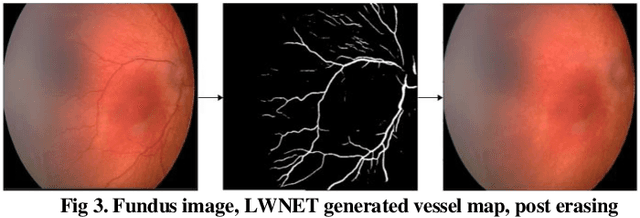
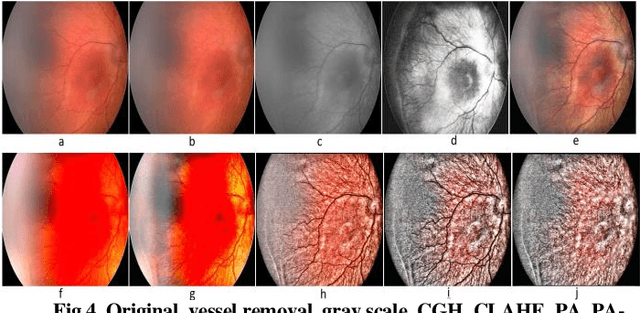
Retinopathy of Prematurity (ROP) is a potentially blinding eye disorder because of damage to the eye's retina which can affect babies born prematurely. Screening of ROP is essential for early detection and treatment. This is a laborious and manual process which requires trained physician performing dilated ophthalmological examination which can be subjective resulting in lower diagnosis success for clinically significant disease. Automated diagnostic methods can assist ophthalmologists increase diagnosis accuracy using deep learning. Several research groups have highlighted various approaches. This paper proposes the use of new novel fundus preprocessing methods using pretrained transfer learning frameworks to create hybrid models to give higher diagnosis accuracy. The evaluations show that these novel methods in comparison to traditional imaging processing contribute to higher accuracy in classifying Plus disease, Stages of ROP and Zones. We achieve accuracy of 97.65% for Plus disease, 89.44% for Stage, 90.24% for Zones with limited training dataset.
Empowering Networks With Scale and Rotation Equivariance Using A Similarity Convolution
Mar 01, 2023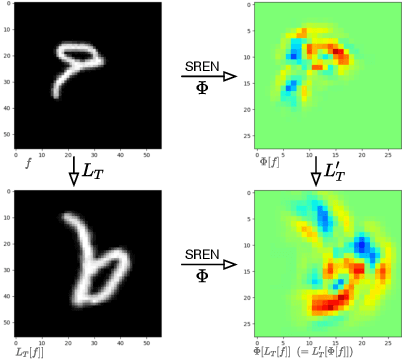
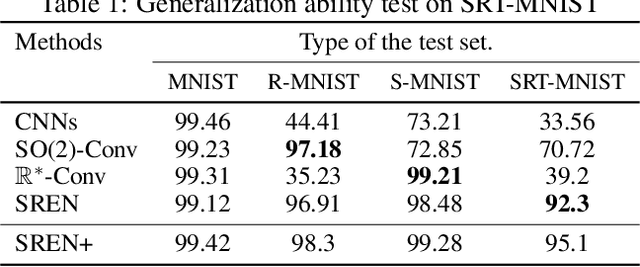
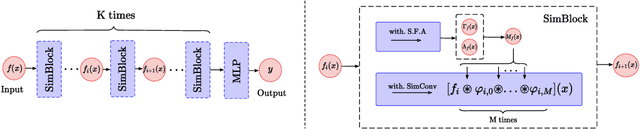
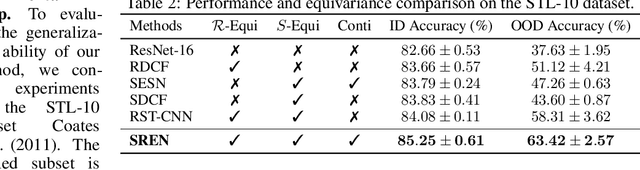
The translational equivariant nature of Convolutional Neural Networks (CNNs) is a reason for its great success in computer vision. However, networks do not enjoy more general equivariance properties such as rotation or scaling, ultimately limiting their generalization performance. To address this limitation, we devise a method that endows CNNs with simultaneous equivariance with respect to translation, rotation, and scaling. Our approach defines a convolution-like operation and ensures equivariance based on our proposed scalable Fourier-Argand representation. The method maintains similar efficiency as a traditional network and hardly introduces any additional learnable parameters, since it does not face the computational issue that often occurs in group-convolution operators. We validate the efficacy of our approach in the image classification task, demonstrating its robustness and the generalization ability to both scaled and rotated inputs.
BiFormer: Vision Transformer with Bi-Level Routing Attention
Mar 15, 2023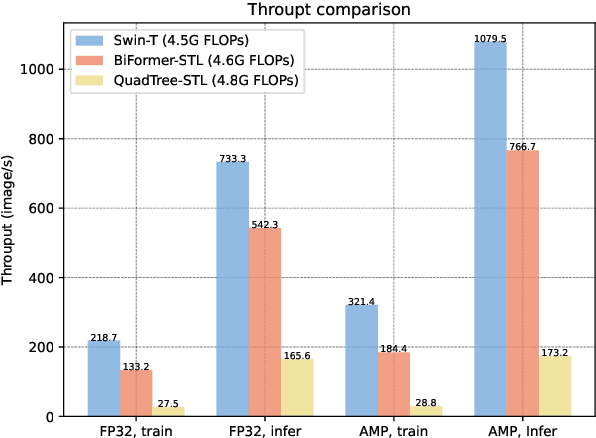
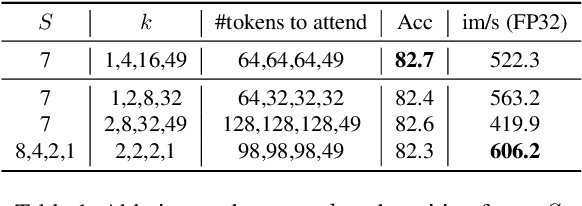


As the core building block of vision transformers, attention is a powerful tool to capture long-range dependency. However, such power comes at a cost: it incurs a huge computation burden and heavy memory footprint as pairwise token interaction across all spatial locations is computed. A series of works attempt to alleviate this problem by introducing handcrafted and content-agnostic sparsity into attention, such as restricting the attention operation to be inside local windows, axial stripes, or dilated windows. In contrast to these approaches, we propose a novel dynamic sparse attention via bi-level routing to enable a more flexible allocation of computations with content awareness. Specifically, for a query, irrelevant key-value pairs are first filtered out at a coarse region level, and then fine-grained token-to-token attention is applied in the union of remaining candidate regions (\ie, routed regions). We provide a simple yet effective implementation of the proposed bi-level routing attention, which utilizes the sparsity to save both computation and memory while involving only GPU-friendly dense matrix multiplications. Built with the proposed bi-level routing attention, a new general vision transformer, named BiFormer, is then presented. As BiFormer attends to a small subset of relevant tokens in a \textbf{query adaptive} manner without distraction from other irrelevant ones, it enjoys both good performance and high computational efficiency, especially in dense prediction tasks. Empirical results across several computer vision tasks such as image classification, object detection, and semantic segmentation verify the effectiveness of our design. Code is available at \url{https://github.com/rayleizhu/BiFormer}.
DeDA: Deep Directed Accumulator
Mar 15, 2023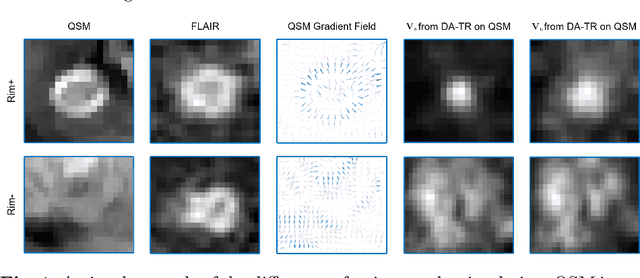

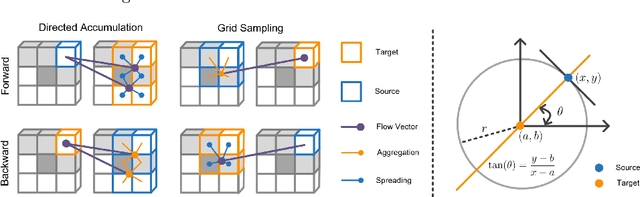

Chronic active multiple sclerosis lesions, also termed as rim+ lesions, can be characterized by a hyperintense rim at the edge of the lesion on quantitative susceptibility maps. These rim+ lesions exhibit a geometrically simple structure, where gradients at the lesion edge are radially oriented and a greater magnitude of gradients is observed in contrast to rim- (non rim+) lesions. However, recent studies have shown that the identification performance of such lesions remains unsatisfied due to the limited amount of data and high class imbalance. In this paper, we propose a simple yet effective image processing operation, deep directed accumulator (DeDA), that provides a new perspective for injecting domain-specific inductive biases (priors) into neural networks for rim+ lesion identification. Given a feature map and a set of sampling grids, DeDA creates and quantizes an accumulator space into finite intervals, and accumulates feature values accordingly. This DeDA operation is a generalized discrete Radon transform and can also be regarded as a symmetric operation to the grid sampling within the forward-backward neural network framework, the process of which is order-agnostic, and can be efficiently implemented with the native CUDA programming. Experimental results on a dataset with 177 rim+ and 3986 rim- lesions show that 10.1% of improvement in a partial (false positive rate<0.1) area under the receiver operating characteristic curve (pROC AUC) and 10.2% of improvement in an area under the precision recall curve (PR AUC) can be achieved respectively comparing to other state-of-the-art methods. The source code is available online at https://github.com/tinymilky/DeDA