 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Segmentation of Deep Sulci in Cortical Gray Matter Using a Deep Learning Framework Incorporating Laplace's Equation
Mar 01, 2023
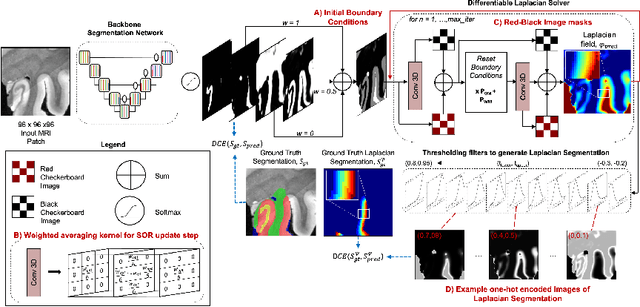
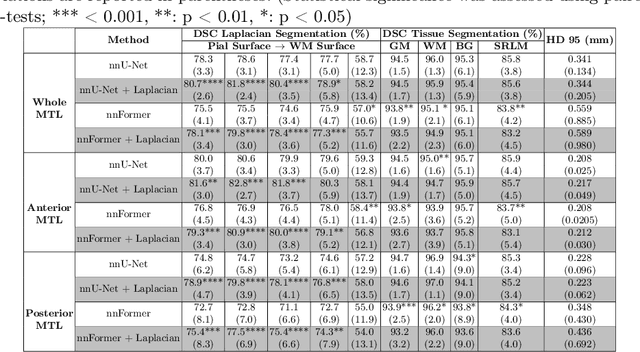
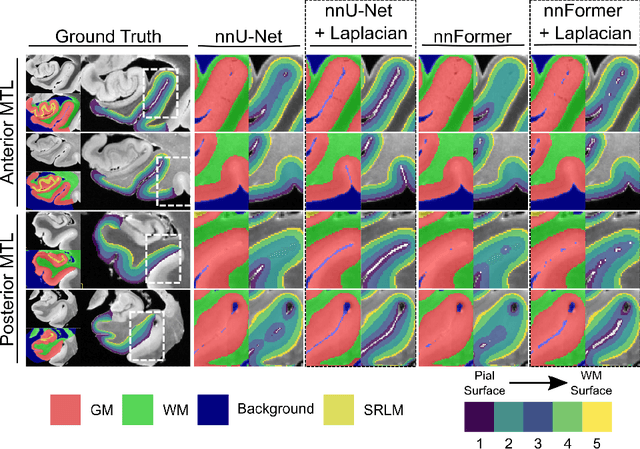
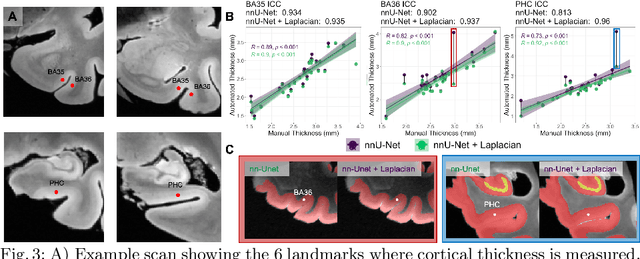
When developing tools for automated cortical segmentation, the ability to produce topologically correct segmentations is important in order to compute geometrically valid morphometry measures. In practice, accurate cortical segmentation is challenged by image artifacts and the highly convoluted anatomy of the cortex itself. To address this, we propose a novel deep learning-based cortical segmentation method in which prior knowledge about the geometry of the cortex is incorporated into the network during the training process. We design a loss function which uses the theory of Laplace's equation applied to the cortex to locally penalize unresolved boundaries between tightly folded sulci. Using an ex vivo MRI dataset of human medial temporal lobe specimens, we demonstrate that our approach outperforms baseline segmentation networks, both quantitatively and qualitatively.
Content-oriented learned image compression
Aug 01, 2022
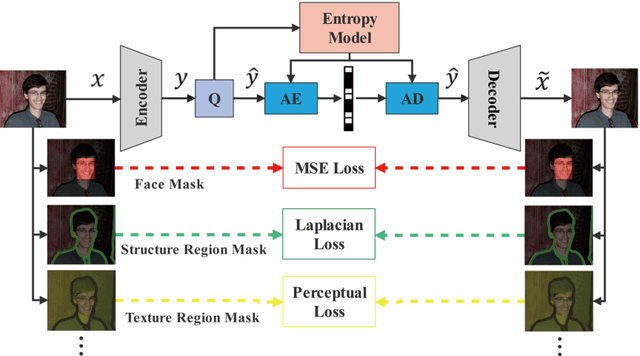
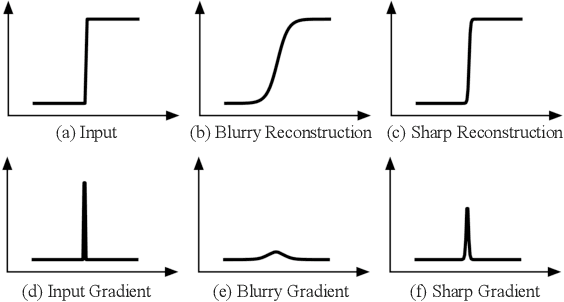
In recent years, with the development of deep neural networks, end-to-end optimized image compression has made significant progress and exceeded the classic methods in terms of rate-distortion performance. However, most learning-based image compression methods are unlabeled and do not consider image semantics or content when optimizing the model. In fact, human eyes have different sensitivities to different content, so the image content also needs to be considered. In this paper, we propose a content-oriented image compression method, which handles different kinds of image contents with different strategies. Extensive experiments show that the proposed method achieves competitive subjective results compared with state-of-the-art end-to-end learned image compression methods or classic methods.
Lossy Image Compression with Quantized Hierarchical VAEs
Aug 27, 2022
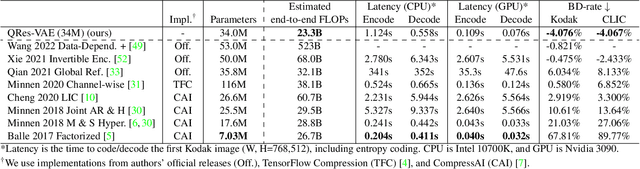
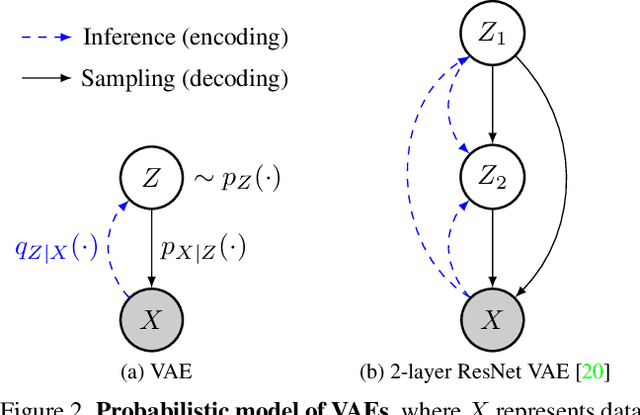
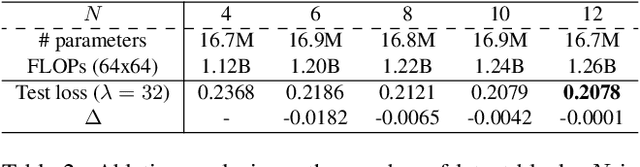
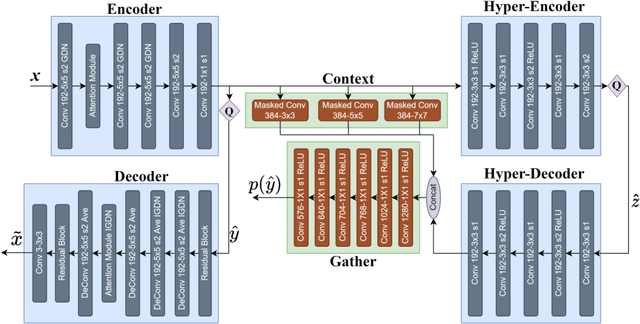
Recent work has shown a strong theoretical connection between variational autoencoders (VAEs) and the rate distortion theory. Motivated by this, we consider the problem of lossy image compression from the perspective of generative modeling. Starting from ResNet VAEs, which are originally designed for data (image) distribution modeling, we redesign their latent variable model using a quantization-aware posterior and prior, enabling easy quantization and entropy coding for image compression. Along with improved neural network blocks, we present a powerful and efficient class of lossy image coders, outperforming previous methods on natural image (lossy) compression. Our model compresses images in a coarse-to-fine fashion and supports parallel encoding and decoding, leading to fast execution on GPUs.
Diffusion Denoising for Low-Dose-CT Model
Jan 31, 2023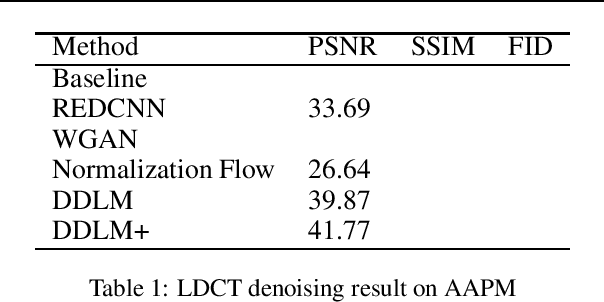

Low-dose Computed Tomography (LDCT) reconstruction is an important task in medical image analysis. Recent years have seen many deep learning based methods, proved to be effective in this area. However, these methods mostly follow a supervised architecture, which needs paired CT image of full dose and quarter dose, and the solution is highly dependent on specific measurements. In this work, we introduce Denoising Diffusion LDCT Model, dubbed as DDLM, generating noise-free CT image using conditioned sampling. DDLM uses pretrained model, and need no training nor tuning process, thus our proposal is in unsupervised manner. Experiments on LDCT images have shown comparable performance of DDLM using less inference time, surpassing other state-of-the-art methods, proving both accurate and efficient. Implementation code will be set to public soon.
Priors are Powerful: Improving a Transformer for Multi-camera 3D Detection with 2D Priors
Jan 31, 2023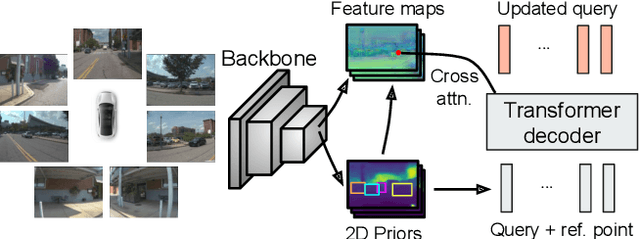
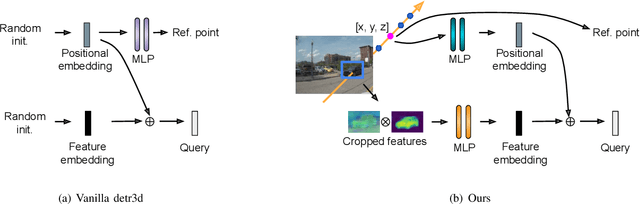
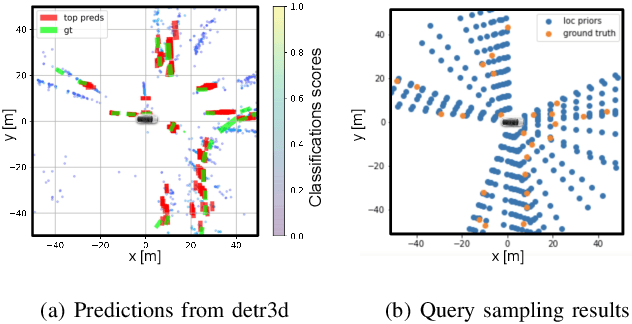
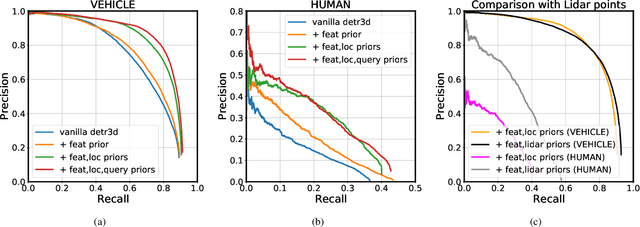
Transfomer-based approaches advance the recent development of multi-camera 3D detection both in academia and industry. In a vanilla transformer architecture, queries are randomly initialised and optimised for the whole dataset, without considering the differences among input frames. In this work, we propose to leverage the predictions from an image backbone, which is often highly optimised for 2D tasks, as priors to the transformer part of a 3D detection network. The method works by (1). augmenting image feature maps with 2D priors, (2). sampling query locations via ray-casting along 2D box centroids, as well as (3). initialising query features with object-level image features. Experimental results shows that 2D priors not only help the model converge faster, but also largely improve the baseline approach by up to 12% in terms of average precision.
EpipolarNVS: leveraging on Epipolar geometry for single-image Novel View Synthesis
Oct 24, 2022
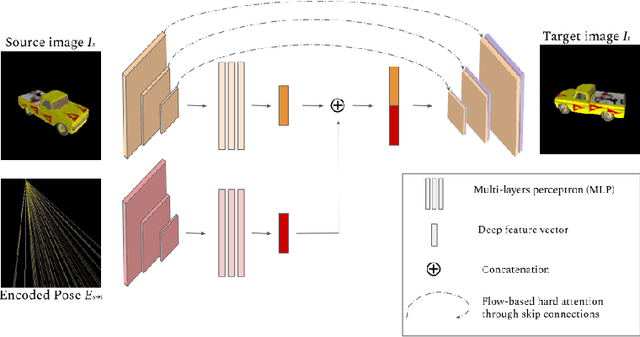

Novel-view synthesis (NVS) can be tackled through different approaches, depending on the general setting: a single source image to a short video sequence, exact or noisy camera pose information, 3D-based information such as point clouds etc. The most challenging scenario, the one where we stand in this work, only considers a unique source image to generate a novel one from another viewpoint. However, in such a tricky situation, the latest learning-based solutions often struggle to integrate the camera viewpoint transformation. Indeed, the extrinsic information is often passed as-is, through a low-dimensional vector. It might even occur that such a camera pose, when parametrized as Euler angles, is quantized through a one-hot representation. This vanilla encoding choice prevents the learnt architecture from inferring novel views on a continuous basis (from a camera pose perspective). We claim it exists an elegant way to better encode relative camera pose, by leveraging 3D-related concepts such as the epipolar constraint. We, therefore, introduce an innovative method that encodes the viewpoint transformation as a 2D feature image. Such a camera encoding strategy gives meaningful insights to the network regarding how the camera has moved in space between the two views. By encoding the camera pose information as a finite number of coloured epipolar lines, we demonstrate through our experiments that our strategy outperforms vanilla encoding.
FurryGAN: High Quality Foreground-aware Image Synthesis
Aug 22, 2022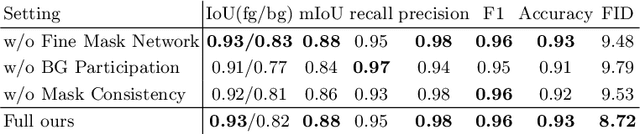
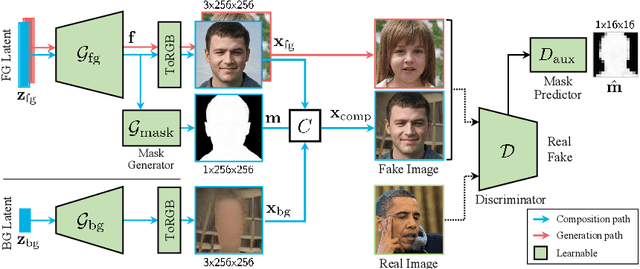
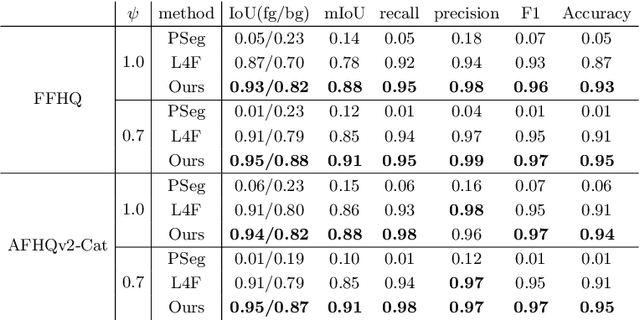
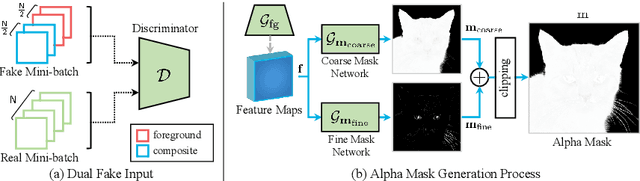
Foreground-aware image synthesis aims to generate images as well as their foreground masks. A common approach is to formulate an image as an masked blending of a foreground image and a background image. It is a challenging problem because it is prone to reach the trivial solution where either image overwhelms the other, i.e., the masks become completely full or empty, and the foreground and background are not meaningfully separated. We present FurryGAN with three key components: 1) imposing both the foreground image and the composite image to be realistic, 2) designing a mask as a combination of coarse and fine masks, and 3) guiding the generator by an auxiliary mask predictor in the discriminator. Our method produces realistic images with remarkably detailed alpha masks which cover hair, fur, and whiskers in a fully unsupervised manner.
Multi-Spectral Image Classification with Ultra-Lean Complex-Valued Models
Nov 21, 2022
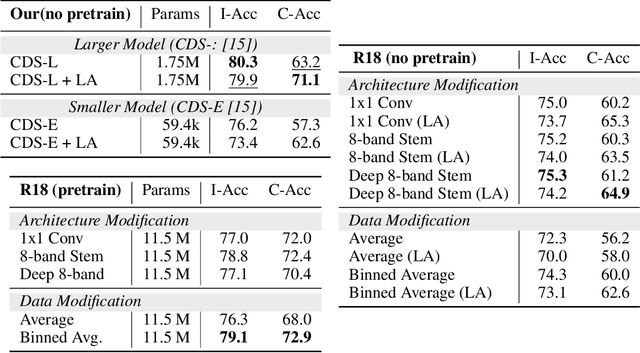
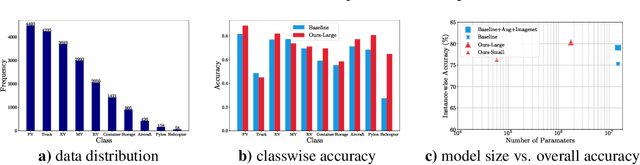
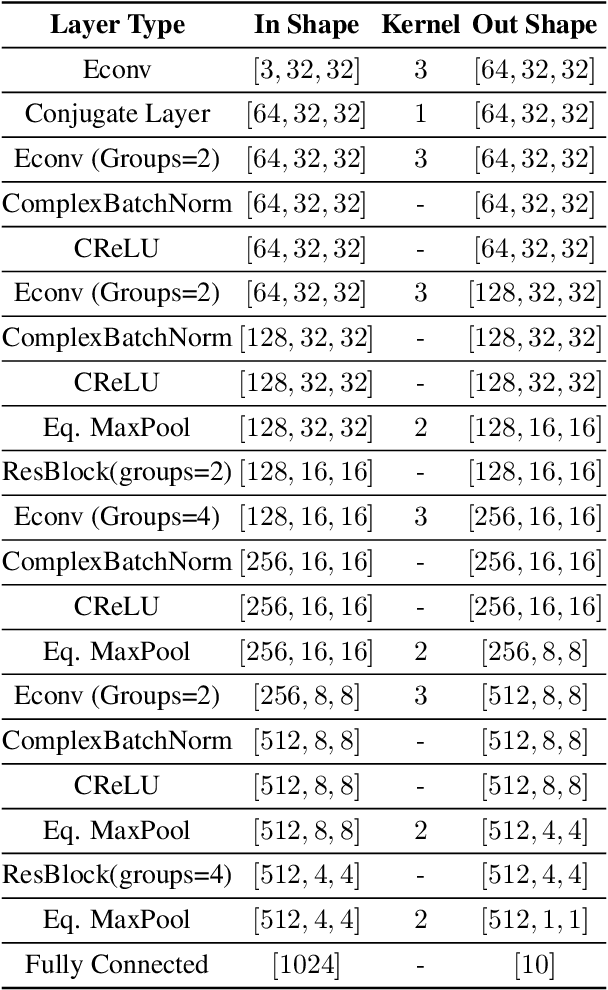
Multi-spectral imagery is invaluable for remote sensing due to different spectral signatures exhibited by materials that often appear identical in greyscale and RGB imagery. Paired with modern deep learning methods, this modality has great potential utility in a variety of remote sensing applications, such as humanitarian assistance and disaster recovery efforts. State-of-the-art deep learning methods have greatly benefited from large-scale annotations like in ImageNet, but existing MSI image datasets lack annotations at a similar scale. As an alternative to transfer learning on such data with few annotations, we apply complex-valued co-domain symmetric models to classify real-valued MSI images. Our experiments on 8-band xView data show that our ultra-lean model trained on xView from scratch without data augmentations can outperform ResNet with data augmentation and modified transfer learning on xView. Our work is the first to demonstrate the value of complex-valued deep learning on real-valued MSI data.
JPEG Steganalysis Based on Steganographic Feature Enhancement and Graph Attention Learning
Feb 05, 2023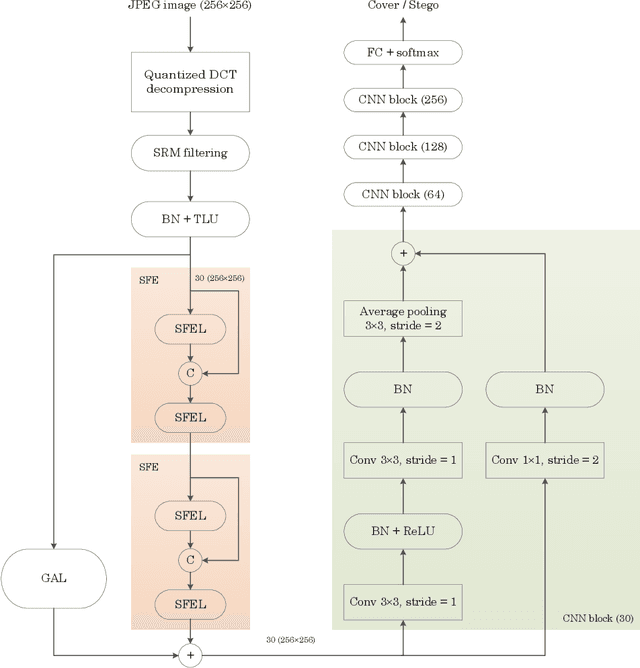

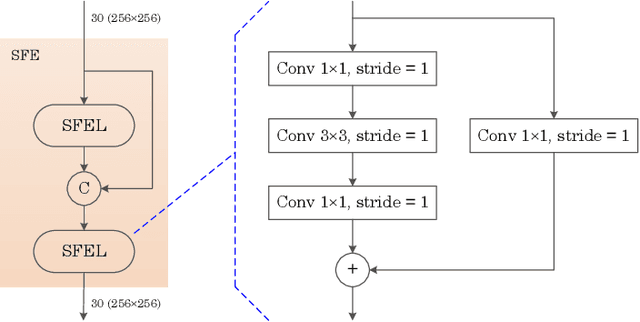
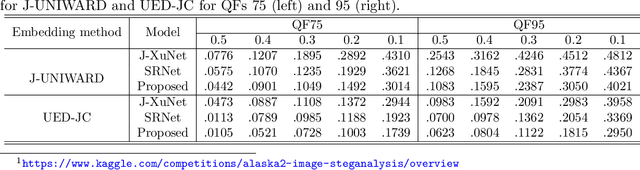
The purpose of image steganalysis is to determine whether the carrier image contains hidden information or not. Since JEPG is the most commonly used image format over social networks, steganalysis in JPEG images is also the most urgently needed to be explored. However, in order to detect whether secret information is hidden within JEPG images, the majority of existing algorithms are designed in conjunction with the popular computer vision related networks, without considering the key characteristics appeared in image steganalysis. It is crucial that the steganographic signal, as an extremely weak signal, can be enhanced during its representation learning process. Motivated by this insight, in this paper, we introduce a novel representation learning algorithm for JPEG steganalysis that is mainly consisting of a graph attention learning module and a feature enhancement module. The graph attention learning module is designed to avoid global feature loss caused by the local feature learning of convolutional neural network and reliance on depth stacking to extend the perceptual domain. The feature enhancement module is applied to prevent the stacking of convolutional layers from weakening the steganographic information. In addition, pretraining as a way to initialize the network weights with a large-scale dataset is utilized to enhance the ability of the network to extract discriminative features. We advocate pretraining with ALASKA2 for the model trained with BOSSBase+BOWS2. The experimental results indicate that the proposed algorithm outperforms previous arts in terms of detection accuracy, which has verified the superiority and applicability of the proposed work.
The NCI Imaging Data Commons as a platform for reproducible research in computational pathology
Mar 16, 2023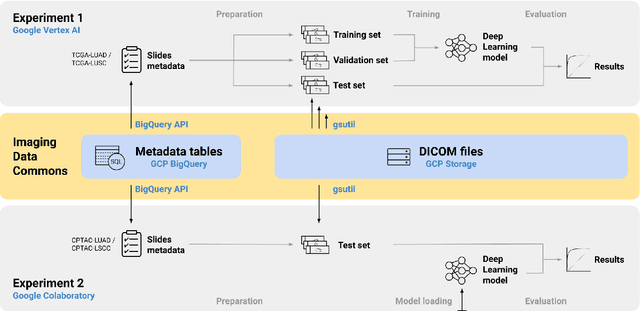
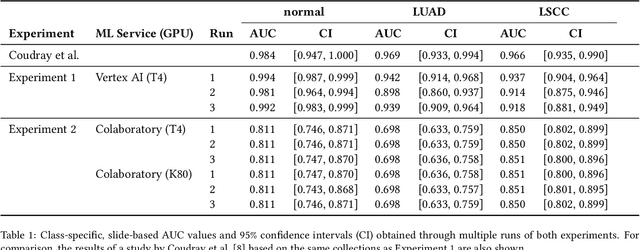
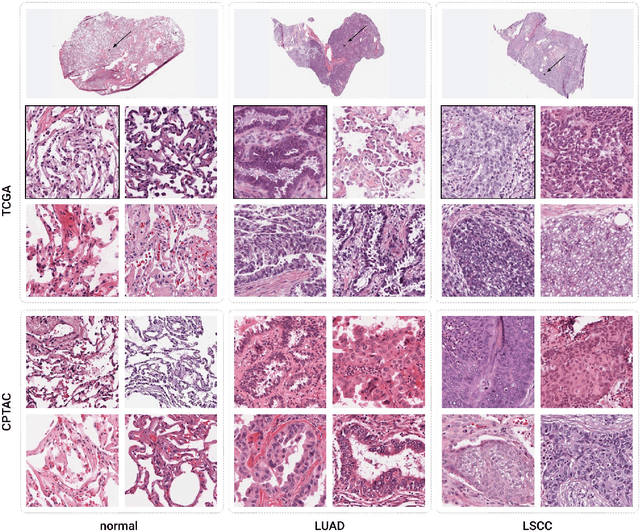

Objective: Reproducibility is critical for translating machine learning-based (ML) solutions in computational pathology (CompPath) into practice. However, an increasing number of studies report difficulties in reproducing ML results. The NCI Imaging Data Commons (IDC) is a public repository of >120 cancer image collections, including >38,000 whole-slide images (WSIs), that is designed to be used with cloud-based ML services. Here, we explore the potential of the IDC to facilitate reproducibility of CompPath research. Materials and Methods: The IDC realizes the FAIR principles: All images are encoded according to the DICOM standard, persistently identified, discoverable via rich metadata, and accessible via open tools. Taking advantage of this, we implemented two experiments in which a representative ML-based method for classifying lung tumor tissue was trained and/or evaluated on different datasets from the IDC. To assess reproducibility, the experiments were run multiple times with independent but identically configured sessions of common ML services. Results: The AUC values of different runs of the same experiment were generally consistent and in the same order of magnitude as a similar, previously published study. However, there were occasional small variations in AUC values of up to 0.044, indicating a practical limit to reproducibility. Discussion and conclusion: By realizing the FAIR principles, the IDC enables other researchers to reuse exactly the same datasets. Cloud-based ML services enable others to run CompPath experiments in an identically configured computing environment without having to own high-performance hardware. The combination of both makes it possible to approach the reproducibility limit.