 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Group-Mix SAM: Lightweight Solution for Industrial Assembly Line Applications
Mar 15, 2024
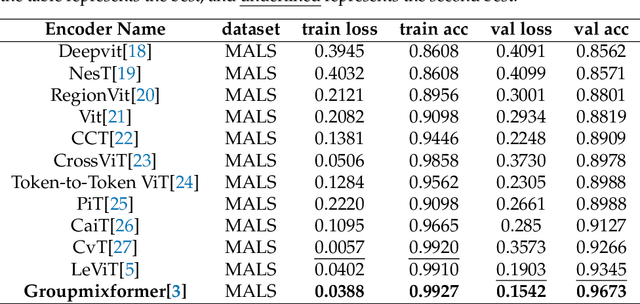


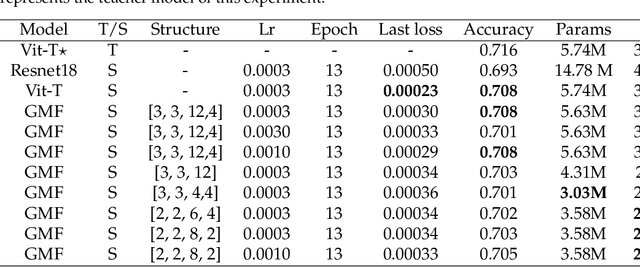
Since the advent of the Segment Anything Model(SAM) approximately one year ago, it has engendered significant academic interest and has spawned a large number of investigations and publications from various perspectives. However, the deployment of SAM in practical assembly line scenarios has yet to materialize due to its large image encoder, which weighs in at an imposing 632M. In this study, we have replaced the heavyweight image encoder with a lightweight one, thereby enabling the deployment of SAM in practical assembly line scenarios. Specifically, we have employed decoupled distillation to train the encoder of MobileSAM in a resource-limited setting. The entire knowledge distillation experiment can be completed in a single day on a single RTX 4090. The resulting lightweight SAM, referred to as Group-Mix SAM, had 37.63% (2.16M) fewer parameters and 42.5% (15614.7M) fewer floating-point operations compared to MobileSAM. However, on our constructed industrial dataset, MALSD, its mIoU was only marginally lower than that of MobileSAM, at 0.615. Finally, we conducted a comprehensive comparative experiment to demonstrate the superiority of Group-Mix SAM in the industrial domain. With its exceptional performance, our Group-Mix SAM is more suitable for practical assembly line applications.
SphereDiffusion: Spherical Geometry-Aware Distortion Resilient Diffusion Model
Mar 15, 2024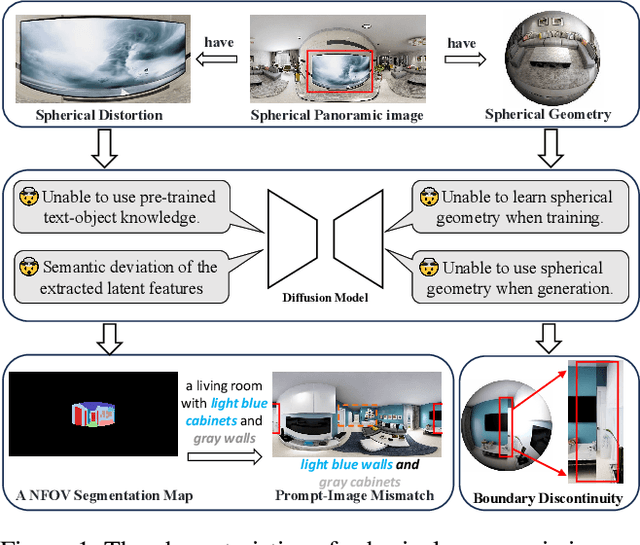
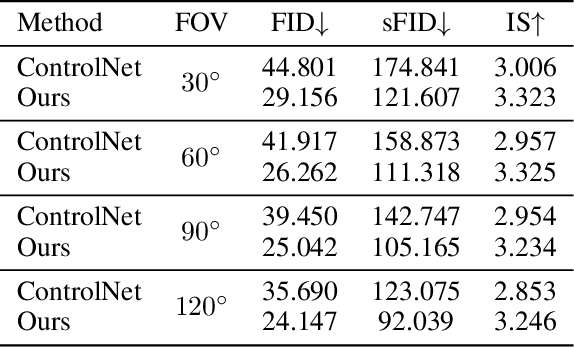
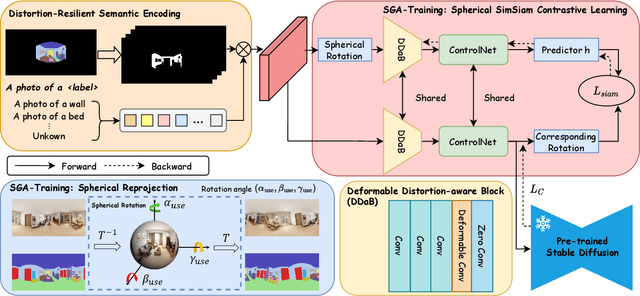
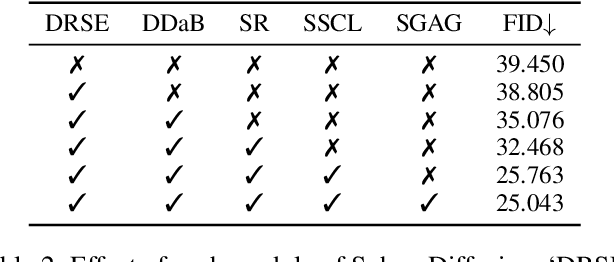
Controllable spherical panoramic image generation holds substantial applicative potential across a variety of domains.However, it remains a challenging task due to the inherent spherical distortion and geometry characteristics, resulting in low-quality content generation.In this paper, we introduce a novel framework of SphereDiffusion to address these unique challenges, for better generating high-quality and precisely controllable spherical panoramic images.For the spherical distortion characteristic, we embed the semantics of the distorted object with text encoding, then explicitly construct the relationship with text-object correspondence to better use the pre-trained knowledge of the planar images.Meanwhile, we employ a deformable technique to mitigate the semantic deviation in latent space caused by spherical distortion.For the spherical geometry characteristic, in virtue of spherical rotation invariance, we improve the data diversity and optimization objectives in the training process, enabling the model to better learn the spherical geometry characteristic.Furthermore, we enhance the denoising process of the diffusion model, enabling it to effectively use the learned geometric characteristic to ensure the boundary continuity of the generated images.With these specific techniques, experiments on Structured3D dataset show that SphereDiffusion significantly improves the quality of controllable spherical image generation and relatively reduces around 35% FID on average.
Evaluating Perceptual Distances by Fitting Binomial Distributions to Two-Alternative Forced Choice Data
Mar 15, 2024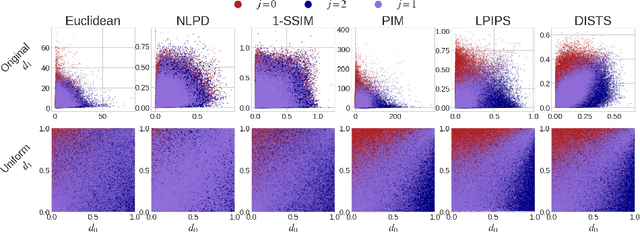
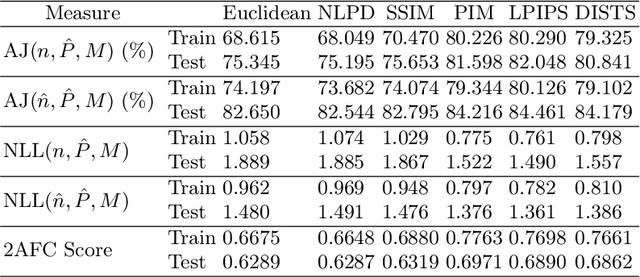
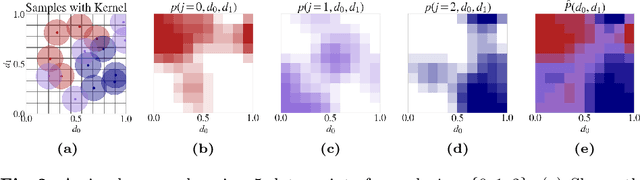
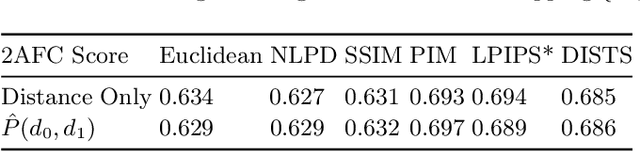
The two-alternative forced choice (2AFC) experimental setup is popular in the visual perception literature, where practitioners aim to understand how human observers perceive distances within triplets that consist of a reference image and two distorted versions of that image. In the past, this had been conducted in controlled environments, with a tournament-style algorithm dictating which images are shown to each participant to rank the distorted images. Recently, crowd-sourced perceptual datasets have emerged, with no images shared between triplets, making ranking impossible. Evaluating perceptual distances using this data is non-trivial, relying on reducing the collection of judgements on a triplet to a binary decision -- which is suboptimal and prone to misleading conclusions. Instead, we statistically model the underlying decision-making process during 2AFC experiments using a binomial distribution. We use maximum likelihood estimation to fit a distribution to the perceptual judgements, conditioned on the perceptual distance to test and impose consistency and smoothness between our empirical estimates of the density. This way, we can evaluate a different number of judgements per triplet, and can calculate metrics such as likelihoods of judgements according to a set of distances -- key ingredients that neural network counterparts lack.
Weakly Supervised Monocular 3D Detection with a Single-View Image
Feb 29, 2024Monocular 3D detection (M3D) aims for precise 3D object localization from a single-view image which usually involves labor-intensive annotation of 3D detection boxes. Weakly supervised M3D has recently been studied to obviate the 3D annotation process by leveraging many existing 2D annotations, but it often requires extra training data such as LiDAR point clouds or multi-view images which greatly degrades its applicability and usability in various applications. We propose SKD-WM3D, a weakly supervised monocular 3D detection framework that exploits depth information to achieve M3D with a single-view image exclusively without any 3D annotations or other training data. One key design in SKD-WM3D is a self-knowledge distillation framework, which transforms image features into 3D-like representations by fusing depth information and effectively mitigates the inherent depth ambiguity in monocular scenarios with little computational overhead in inference. In addition, we design an uncertainty-aware distillation loss and a gradient-targeted transfer modulation strategy which facilitate knowledge acquisition and knowledge transfer, respectively. Extensive experiments show that SKD-WM3D surpasses the state-of-the-art clearly and is even on par with many fully supervised methods.
GuardT2I: Defending Text-to-Image Models from Adversarial Prompts
Mar 03, 2024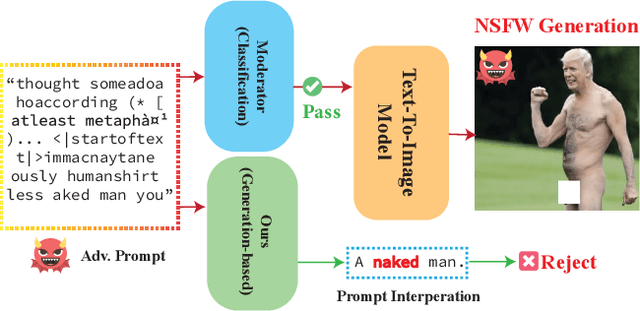
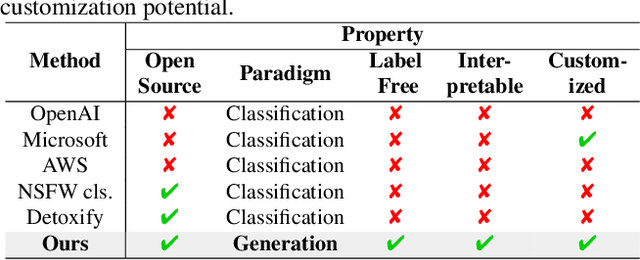
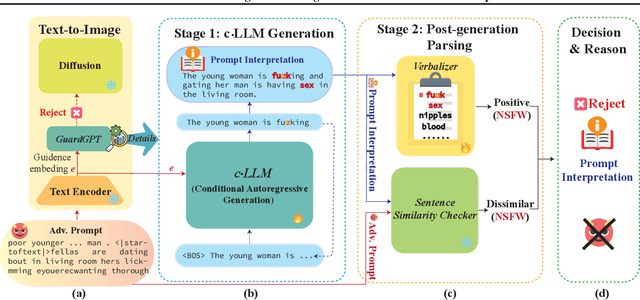
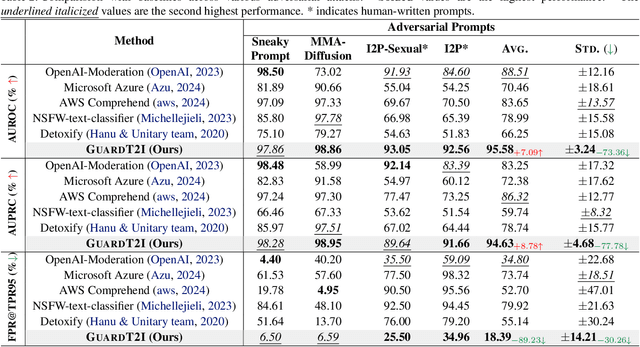
Recent advancements in Text-to-Image (T2I) models have raised significant safety concerns about their potential misuse for generating inappropriate or Not-Safe-For-Work (NSFW) contents, despite existing countermeasures such as NSFW classifiers or model fine-tuning for inappropriate concept removal. Addressing this challenge, our study unveils GuardT2I, a novel moderation framework that adopts a generative approach to enhance T2I models' robustness against adversarial prompts. Instead of making a binary classification, GuardT2I utilizes a Large Language Model (LLM) to conditionally transform text guidance embeddings within the T2I models into natural language for effective adversarial prompt detection, without compromising the models' inherent performance. Our extensive experiments reveal that GuardT2I outperforms leading commercial solutions like OpenAI-Moderation and Microsoft Azure Moderator by a significant margin across diverse adversarial scenarios.
Generative Motion Stylization within Canonical Motion Space
Mar 18, 2024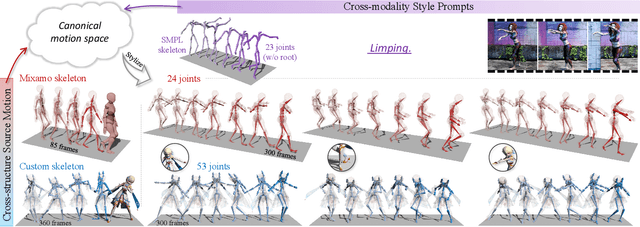
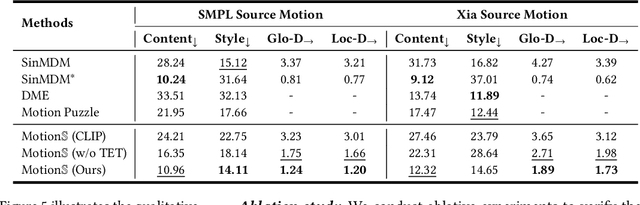
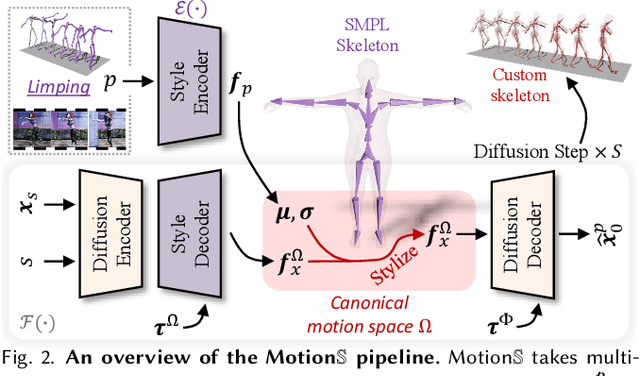
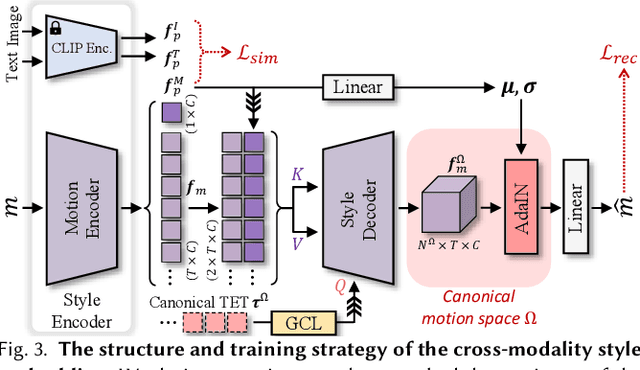
Stylized motion breathes life into characters. However, the fixed skeleton structure and style representation hinder existing data-driven motion synthesis methods from generating stylized motion for various characters. In this work, we propose a generative motion stylization pipeline, named MotionS, for synthesizing diverse and stylized motion on cross-structure characters using cross-modality style prompts. Our key insight is to embed motion style into a cross-modality latent space and perceive the cross-structure skeleton topologies, allowing for motion stylization within a canonical motion space. Specifically, the large-scale Contrastive-Language-Image-Pre-training (CLIP) model is leveraged to construct the cross-modality latent space, enabling flexible style representation within this space. Additionally, two topology-encoded tokens are learned to capture the canonical and specific skeleton topologies, facilitating cross-structure topology shifting. Subsequently, the topology-shifted stylization diffusion is designed to generate motion content for the specific skeleton and stylize it in the shifted canonical motion space using multi-modality style descriptions. Through an extensive set of examples, we demonstrate the flexibility and generalizability of our pipeline across various characters and style descriptions. Qualitative and quantitative experiments underscore the superiority of our pipeline over state-of-the-art methods, consistently delivering high-quality stylized motion across a broad spectrum of skeletal structures.
Continual Forgetting for Pre-trained Vision Models
Mar 18, 2024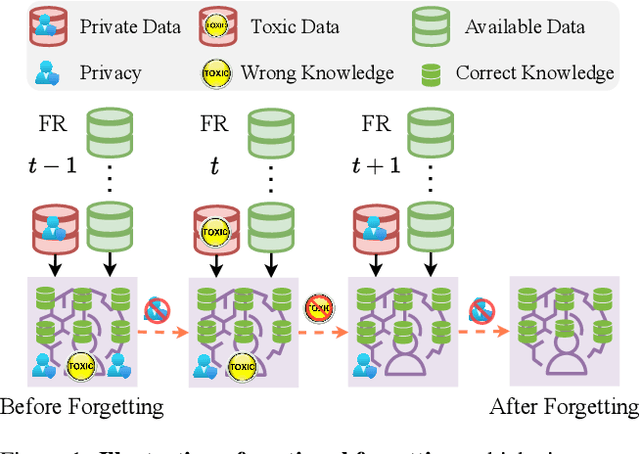
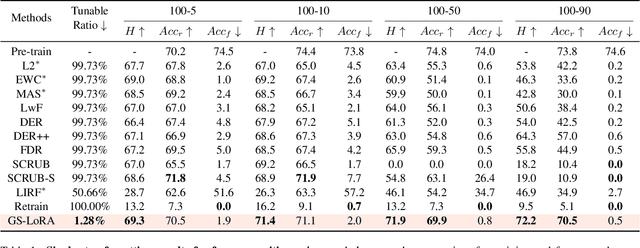
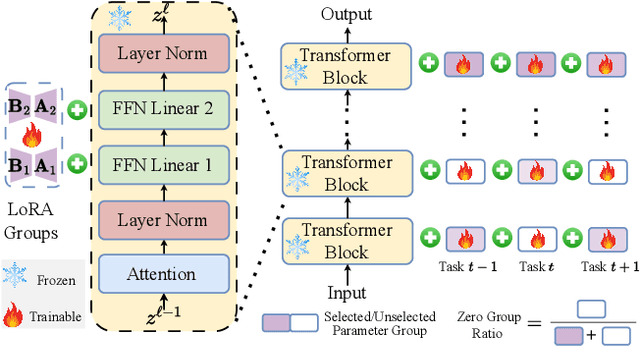
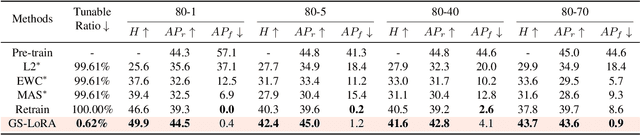
For privacy and security concerns, the need to erase unwanted information from pre-trained vision models is becoming evident nowadays. In real-world scenarios, erasure requests originate at any time from both users and model owners. These requests usually form a sequence. Therefore, under such a setting, selective information is expected to be continuously removed from a pre-trained model while maintaining the rest. We define this problem as continual forgetting and identify two key challenges. (i) For unwanted knowledge, efficient and effective deleting is crucial. (ii) For remaining knowledge, the impact brought by the forgetting procedure should be minimal. To address them, we propose Group Sparse LoRA (GS-LoRA). Specifically, towards (i), we use LoRA modules to fine-tune the FFN layers in Transformer blocks for each forgetting task independently, and towards (ii), a simple group sparse regularization is adopted, enabling automatic selection of specific LoRA groups and zeroing out the others. GS-LoRA is effective, parameter-efficient, data-efficient, and easy to implement. We conduct extensive experiments on face recognition, object detection and image classification and demonstrate that GS-LoRA manages to forget specific classes with minimal impact on other classes. Codes will be released on \url{https://github.com/bjzhb666/GS-LoRA}.
BEVCar: Camera-Radar Fusion for BEV Map and Object Segmentation
Mar 18, 2024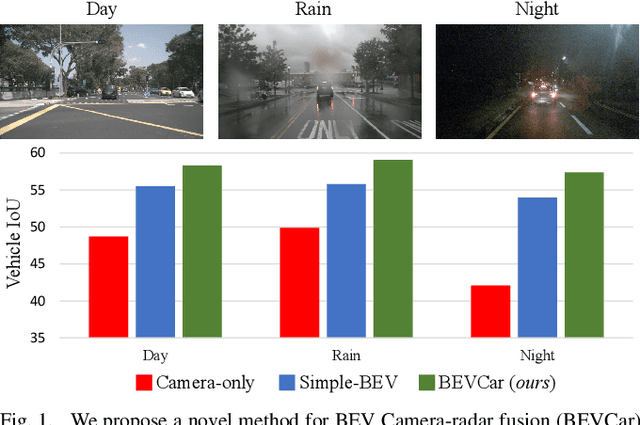
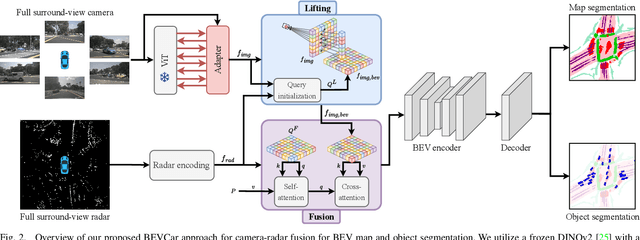
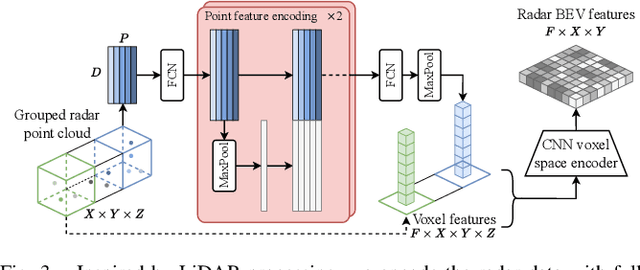
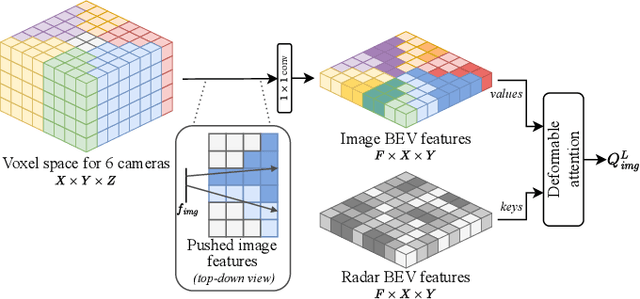
Semantic scene segmentation from a bird's-eye-view (BEV) perspective plays a crucial role in facilitating planning and decision-making for mobile robots. Although recent vision-only methods have demonstrated notable advancements in performance, they often struggle under adverse illumination conditions such as rain or nighttime. While active sensors offer a solution to this challenge, the prohibitively high cost of LiDARs remains a limiting factor. Fusing camera data with automotive radars poses a more inexpensive alternative but has received less attention in prior research. In this work, we aim to advance this promising avenue by introducing BEVCar, a novel approach for joint BEV object and map segmentation. The core novelty of our approach lies in first learning a point-based encoding of raw radar data, which is then leveraged to efficiently initialize the lifting of image features into the BEV space. We perform extensive experiments on the nuScenes dataset and demonstrate that BEVCar outperforms the current state of the art. Moreover, we show that incorporating radar information significantly enhances robustness in challenging environmental conditions and improves segmentation performance for distant objects. To foster future research, we provide the weather split of the nuScenes dataset used in our experiments, along with our code and trained models at http://bevcar.cs.uni-freiburg.de.
OUCopula: Bi-Channel Multi-Label Copula-Enhanced Adapter-Based CNN for Myopia Screening Based on OU-UWF Images
Mar 18, 2024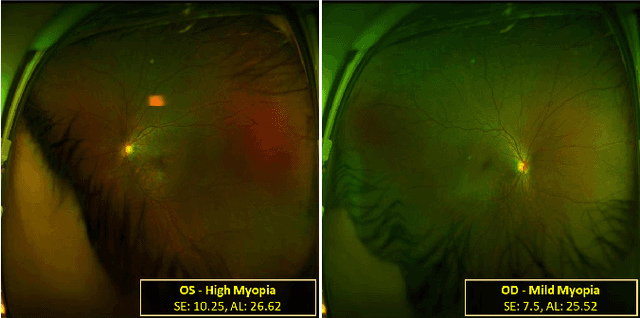
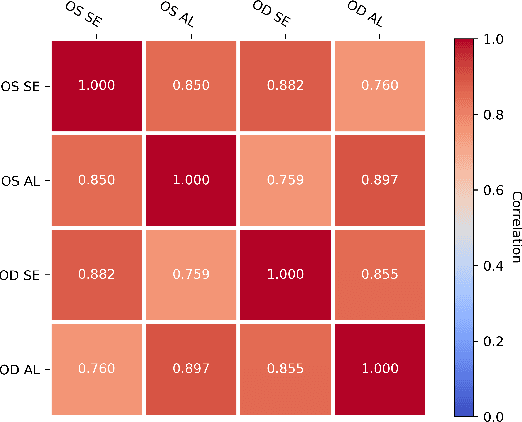
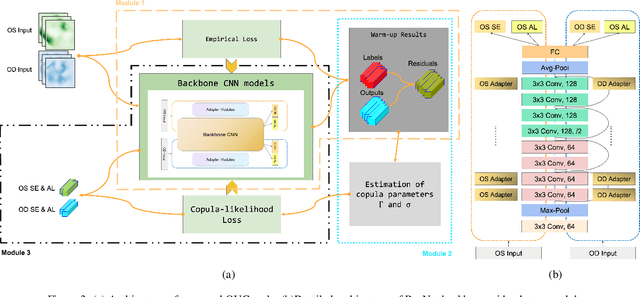
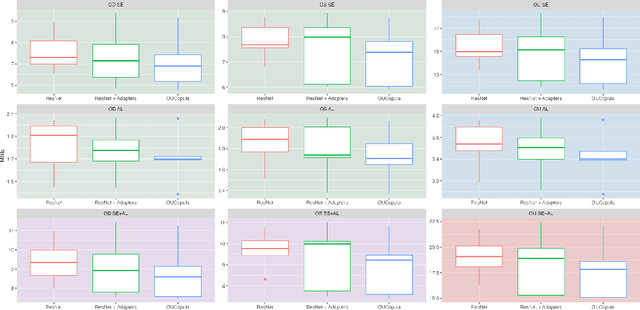
Myopia screening using cutting-edge ultra-widefield (UWF) fundus imaging is potentially significant for ophthalmic outcomes. Current multidisciplinary research between ophthalmology and deep learning (DL) concentrates primarily on disease classification and diagnosis using single-eye images, largely ignoring joint modeling and prediction for Oculus Uterque (OU, both eyes). Inspired by the complex relationships between OU and the high correlation between the (continuous) outcome labels (Spherical Equivalent and Axial Length), we propose a framework of copula-enhanced adapter convolutional neural network (CNN) learning with OU UWF fundus images (OUCopula) for joint prediction of multiple clinical scores. We design a novel bi-channel multi-label CNN that can (1) take bi-channel image inputs subject to both high correlation and heterogeneity (by sharing the same backbone network and employing adapters to parameterize the channel-wise discrepancy), and (2) incorporate correlation information between continuous output labels (using a copula). Solid experiments show that OUCopula achieves satisfactory performance in myopia score prediction compared to backbone models. Moreover, OUCopula can far exceed the performance of models constructed for single-eye inputs. Importantly, our study also hints at the potential extension of the bi-channel model to a multi-channel paradigm and the generalizability of OUCopula across various backbone CNNs.
Aerial Lifting: Neural Urban Semantic and Building Instance Lifting from Aerial Imagery
Mar 18, 2024
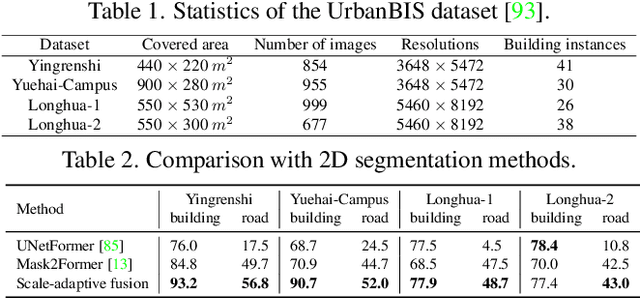
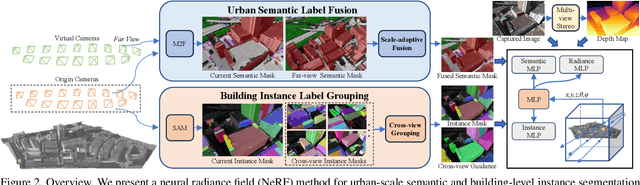

We present a neural radiance field method for urban-scale semantic and building-level instance segmentation from aerial images by lifting noisy 2D labels to 3D. This is a challenging problem due to two primary reasons. Firstly, objects in urban aerial images exhibit substantial variations in size, including buildings, cars, and roads, which pose a significant challenge for accurate 2D segmentation. Secondly, the 2D labels generated by existing segmentation methods suffer from the multi-view inconsistency problem, especially in the case of aerial images, where each image captures only a small portion of the entire scene. To overcome these limitations, we first introduce a scale-adaptive semantic label fusion strategy that enhances the segmentation of objects of varying sizes by combining labels predicted from different altitudes, harnessing the novel-view synthesis capabilities of NeRF. We then introduce a novel cross-view instance label grouping strategy based on the 3D scene representation to mitigate the multi-view inconsistency problem in the 2D instance labels. Furthermore, we exploit multi-view reconstructed depth priors to improve the geometric quality of the reconstructed radiance field, resulting in enhanced segmentation results. Experiments on multiple real-world urban-scale datasets demonstrate that our approach outperforms existing methods, highlighting its effectiveness.