 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
F2BEV: Bird's Eye View Generation from Surround-View Fisheye Camera Images for Automated Driving
Mar 07, 2023
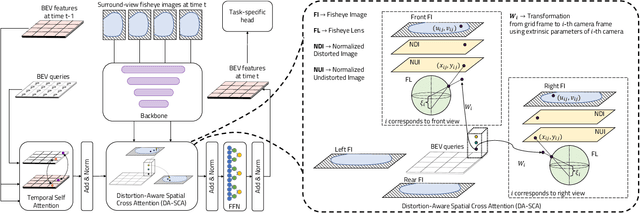



Bird's Eye View (BEV) representations are tremendously useful for perception-related automated driving tasks. However, generating BEVs from surround-view fisheye camera images is challenging due to the strong distortions introduced by such wide-angle lenses. We take the first step in addressing this challenge and introduce a baseline, F2BEV, to generate BEV height maps and semantic segmentation maps from fisheye images. F2BEV consists of a distortion-aware spatial cross attention module for querying and consolidating spatial information from fisheye image features in a transformer-style architecture followed by a task-specific head. We evaluate single-task and multi-task variants of F2BEV on our synthetic FB-SSEM dataset, all of which generate better BEV height and segmentation maps (in terms of the IoU) than a state-of-the-art BEV generation method operating on undistorted fisheye images. We also demonstrate height map generation from real-world fisheye images using F2BEV. An initial sample of our dataset is publicly available at https://tinyurl.com/58jvnscy
Content-oriented learned image compression
Aug 01, 2022
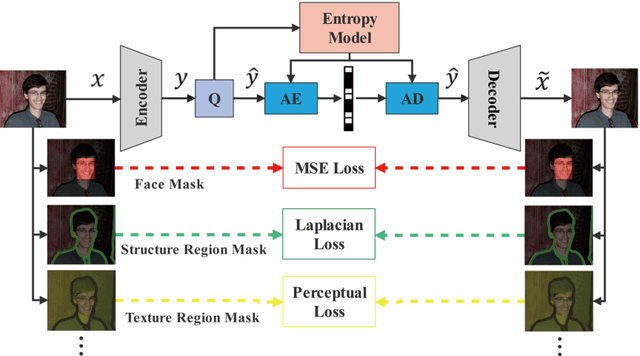
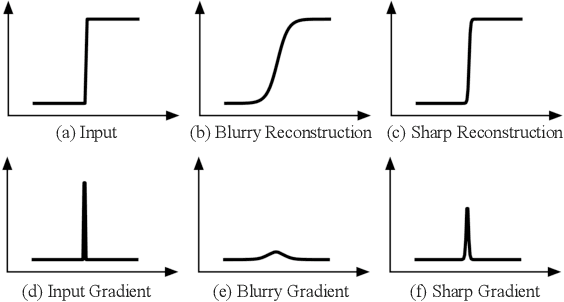
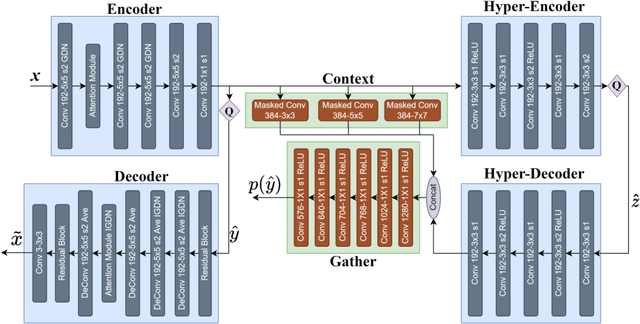
In recent years, with the development of deep neural networks, end-to-end optimized image compression has made significant progress and exceeded the classic methods in terms of rate-distortion performance. However, most learning-based image compression methods are unlabeled and do not consider image semantics or content when optimizing the model. In fact, human eyes have different sensitivities to different content, so the image content also needs to be considered. In this paper, we propose a content-oriented image compression method, which handles different kinds of image contents with different strategies. Extensive experiments show that the proposed method achieves competitive subjective results compared with state-of-the-art end-to-end learned image compression methods or classic methods.
Global Knowledge Calibration for Fast Open-Vocabulary Segmentation
Mar 16, 2023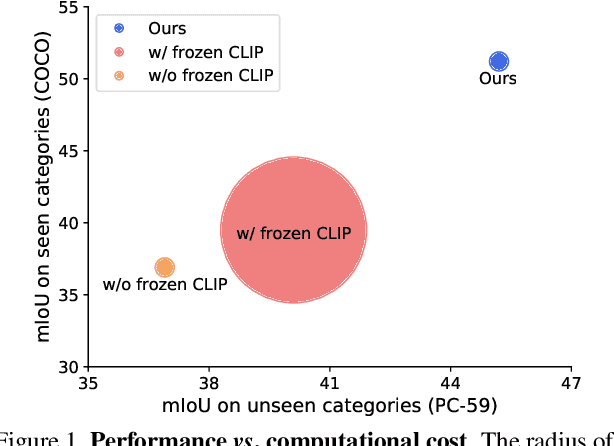
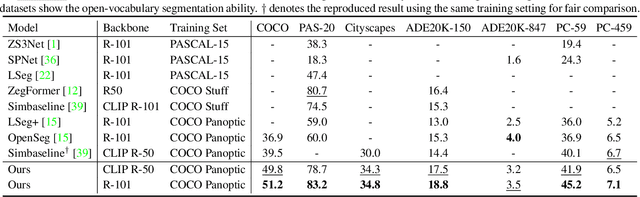
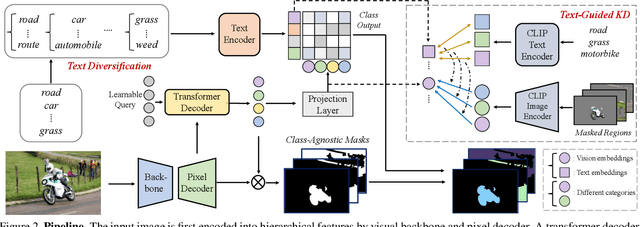

Recent advancements in pre-trained vision-language models, such as CLIP, have enabled the segmentation of arbitrary concepts solely from textual inputs, a process commonly referred to as open-vocabulary semantic segmentation (OVS). However, existing OVS techniques confront a fundamental challenge: the trained classifier tends to overfit on the base classes observed during training, resulting in suboptimal generalization performance to unseen classes. To mitigate this issue, recent studies have proposed the use of an additional frozen pre-trained CLIP for classification. Nonetheless, this approach incurs heavy computational overheads as the CLIP vision encoder must be repeatedly forward-passed for each mask, rendering it impractical for real-world applications. To address this challenge, our objective is to develop a fast OVS model that can perform comparably or better without the extra computational burden of the CLIP image encoder during inference. To this end, we propose a core idea of preserving the generalizable representation when fine-tuning on known classes. Specifically, we introduce a text diversification strategy that generates a set of synonyms for each training category, which prevents the learned representation from collapsing onto specific known category names. Additionally, we employ a text-guided knowledge distillation method to preserve the generalizable knowledge of CLIP. Extensive experiments demonstrate that our proposed model achieves robust generalization performance across various datasets. Furthermore, we perform a preliminary exploration of open-vocabulary video segmentation and present a benchmark that can facilitate future open-vocabulary research in the video domain.
CoLo-CAM: Class Activation Mapping for Object Co-Localization in Weakly-Labeled Unconstrained Videos
Mar 16, 2023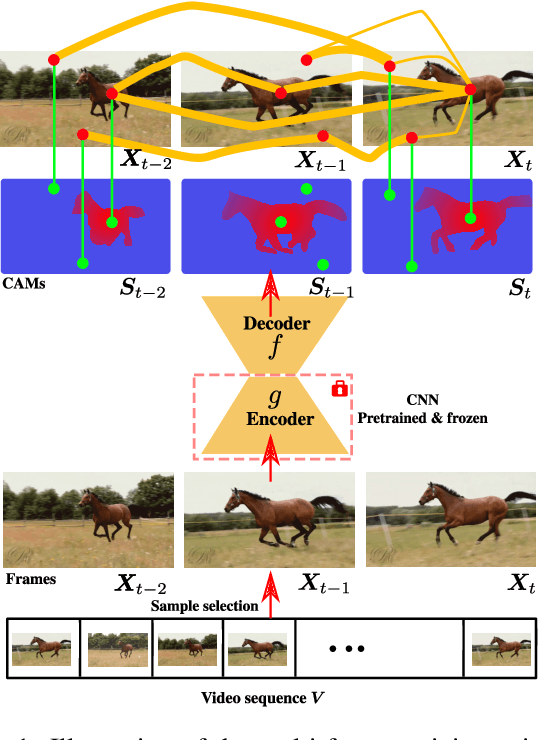
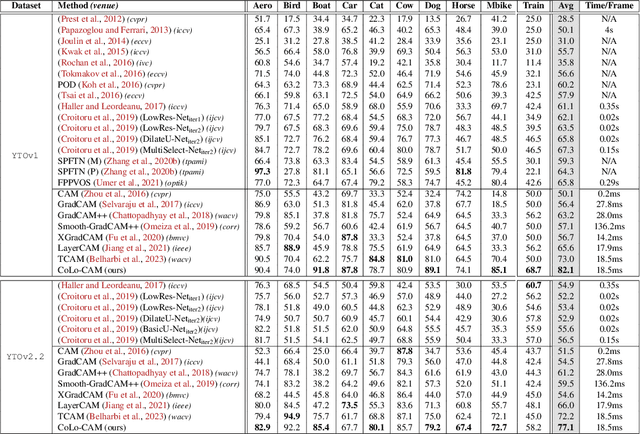
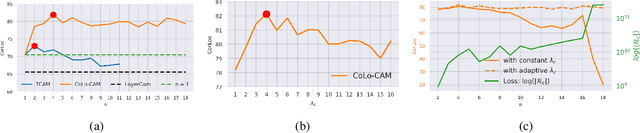

Weakly-supervised video object localization (WSVOL) methods often rely on visual and motion cues only, making them susceptible to inaccurate localization. Recently, discriminative models via a temporal class activation mapping (CAM) method have been explored. Although results are promising, objects are assumed to have minimal movement leading to degradation in performance for relatively long-term dependencies. In this paper, a novel CoLo-CAM method for object localization is proposed to leverage spatiotemporal information in activation maps without any assumptions about object movement. Over a given sequence of frames, explicit joint learning of localization is produced across these maps based on color cues, by assuming an object has similar color across frames. The CAMs' activations are constrained to activate similarly over pixels with similar colors, achieving co-localization. This joint learning creates direct communication among pixels across all image locations, and over all frames, allowing for transfer, aggregation, and correction of learned localization. This is achieved by minimizing a color term of a CRF loss over joint images/maps. In addition to our multi-frame constraint, we impose per-frame local constraints including pseudo-labels, and CRF loss in combination with a global size constraint to improve per-frame localization. Empirical experiments on two challenging datasets for unconstrained videos, YouTube-Objects, show the merits of our method, and its robustness to long-term dependencies, leading to new state-of-the-art localization performance. Public code: https://github.com/sbelharbi/colo-cam.
SSL-Cleanse: Trojan Detection and Mitigation in Self-Supervised Learning
Mar 16, 2023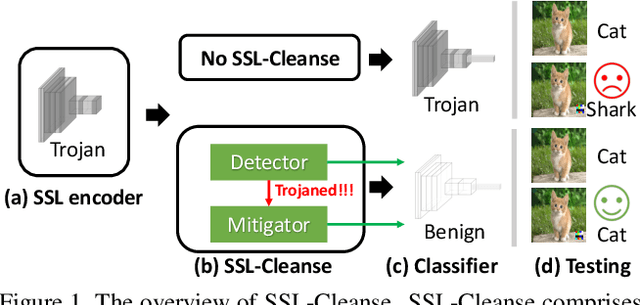
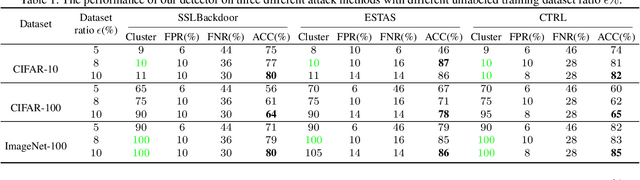


Self-supervised learning (SSL) is a commonly used approach to learning and encoding data representations. By using a pre-trained SSL image encoder and training a downstream classifier on top of it, impressive performance can be achieved on various tasks with very little labeled data. The increasing usage of SSL has led to an uptick in security research related to SSL encoders and the development of various Trojan attacks. The danger posed by Trojan attacks inserted in SSL encoders lies in their ability to operate covertly and spread widely among various users and devices. The presence of backdoor behavior in Trojaned encoders can inadvertently be inherited by downstream classifiers, making it even more difficult to detect and mitigate the threat. Although current Trojan detection methods in supervised learning can potentially safeguard SSL downstream classifiers, identifying and addressing triggers in the SSL encoder before its widespread dissemination is a challenging task. This is because downstream tasks are not always known, dataset labels are not available, and even the original training dataset is not accessible during the SSL encoder Trojan detection. This paper presents an innovative technique called SSL-Cleanse that is designed to detect and mitigate backdoor attacks in SSL encoders. We evaluated SSL-Cleanse on various datasets using 300 models, achieving an average detection success rate of 83.7% on ImageNet-100. After mitigating backdoors, on average, backdoored encoders achieve 0.24% attack success rate without great accuracy loss, proving the effectiveness of SSL-Cleanse.
JSRNN: Joint Sampling and Reconstruction Neural Networks for High Quality Image Compressed Sensing
Nov 11, 2022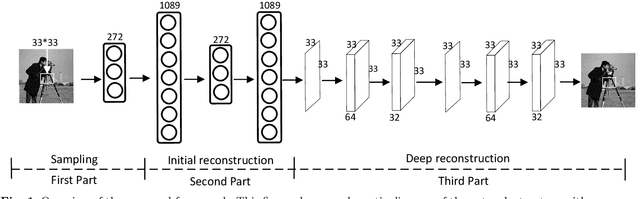
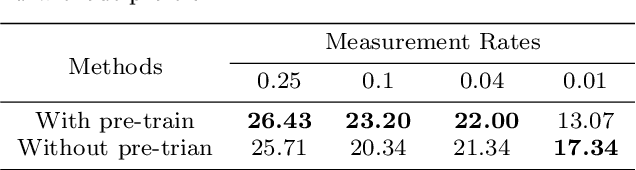
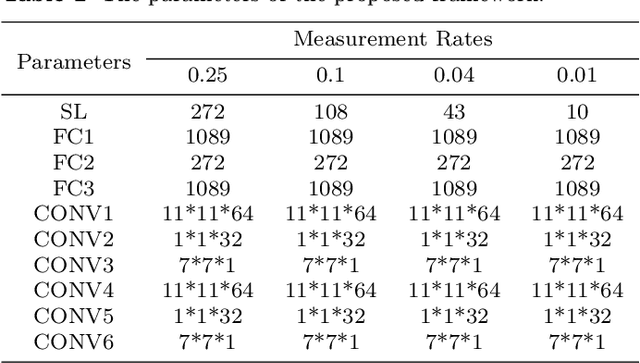
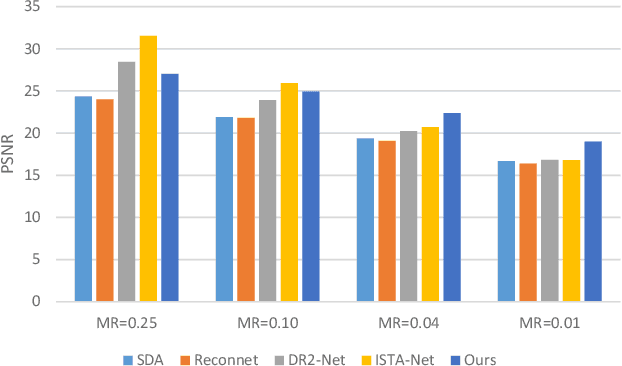
Most Deep Learning (DL) based Compressed Sensing (DCS) algorithms adopt a single neural network for signal reconstruction, and fail to jointly consider the influences of the sampling operation for reconstruction. In this paper, we propose unified framework, which jointly considers the sampling and reconstruction process for image compressive sensing based on well-designed cascade neural networks. Two sub-networks, which are the sampling sub-network and the reconstruction sub-network, are included in the proposed framework. In the sampling sub-network, an adaptive full connected layer instead of the traditional random matrix is used to mimic the sampling operator. In the reconstruction sub-network, a cascade network combining stacked denoising autoencoder (SDA) and convolutional neural network (CNN) is designed to reconstruct signals. The SDA is used to solve the signal mapping problem and the signals are initially reconstructed. Furthermore, CNN is used to fully recover the structure and texture features of the image to obtain better reconstruction performance. Extensive experiments show that this framework outperforms many other state-of-the-art methods, especially at low sampling rates.
Stereo Event-based Visual-Inertial Odometry
Mar 09, 2023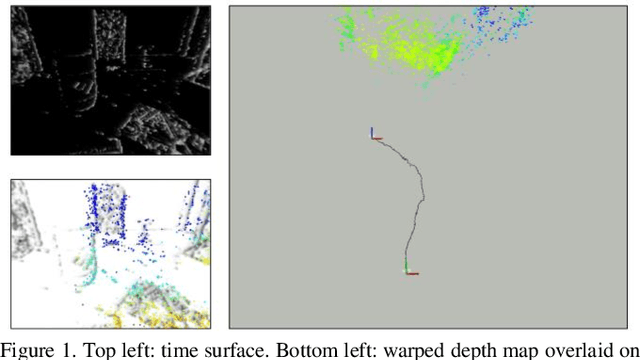
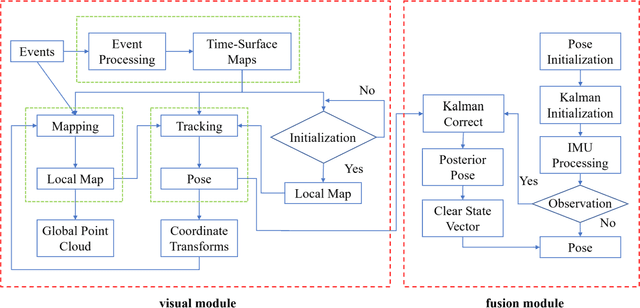
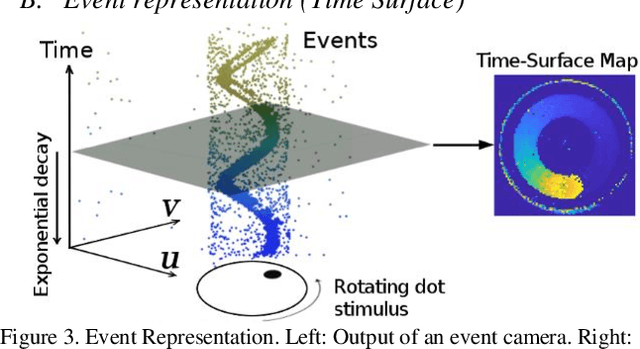
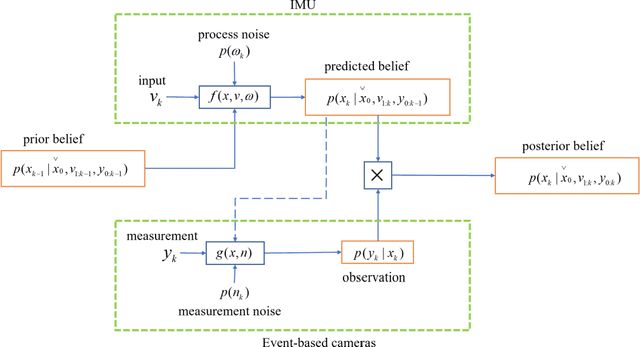
Event-based cameras are new type vision sensors whose pixels work independently and respond asynchronously to brightness change with microsecond resolution, instead of provide stand-ard intensity frames. Compared with traditional cameras, event-based cameras have low latency, no motion blur, and high dynamic range (HDR), which provide possibilities for robots to deal with some challenging scenes. We propose a visual-inertial odometry method for stereo event-cameras based on Kalman filtering. The visual module updates the camera pose relies on the edge alignment of a semi-dense 3D map to a 2D image, and the IMU module updates pose by midpoint method. We evaluate our method on public datasets in natural scenes with general 6-DoF motion and compare the results against ground truth. We show that the proposed pipeline provides improved accuracy over the result of a state-of-the-art visual odometry method for stereo event-cameras, while running in real-time on a standard CPU. To the best of our knowledge, this is the first published visual-inertial odometry algorithm for stereo event-cameras.
Toward Unsupervised Realistic Visual Question Answering
Mar 09, 2023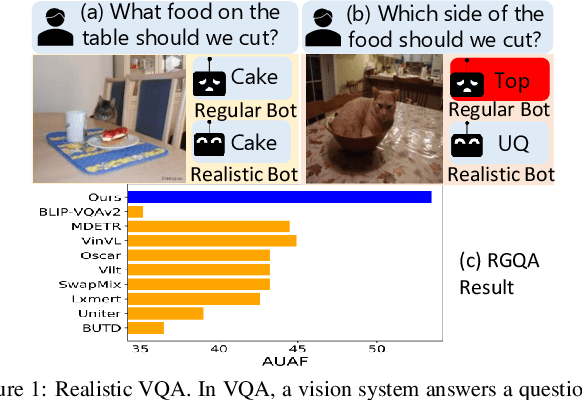


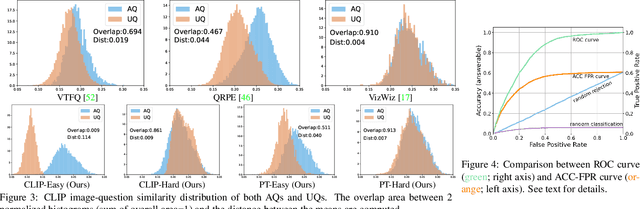
The problem of realistic VQA (RVQA), where a model has to reject unanswerable questions (UQs) and answer answerable ones (AQs), is studied. We first point out 2 drawbacks in current RVQA research, where (1) datasets contain too many unchallenging UQs and (2) a large number of annotated UQs are required for training. To resolve the first drawback, we propose a new testing dataset, RGQA, which combines AQs from an existing VQA dataset with around 29K human-annotated UQs. These UQs consist of both fine-grained and coarse-grained image-question pairs generated with 2 approaches: CLIP-based and Perturbation-based. To address the second drawback, we introduce an unsupervised training approach. This combines pseudo UQs obtained by randomly pairing images and questions, with an RoI Mixup procedure to generate more fine-grained pseudo UQs, and model ensembling to regularize model confidence. Experiments show that using pseudo UQs significantly outperforms RVQA baselines. RoI Mixup and model ensembling further increase the gain. Finally, human evaluation reveals a performance gap between humans and models, showing that more RVQA research is needed.
Knowledge-augmented Few-shot Visual Relation Detection
Mar 09, 2023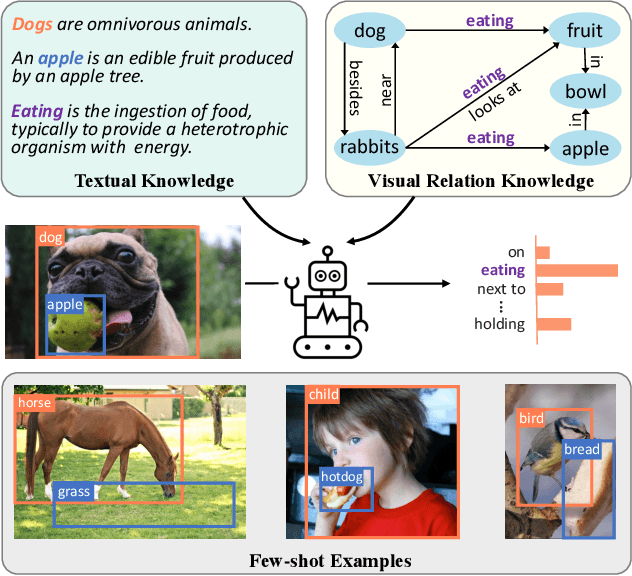

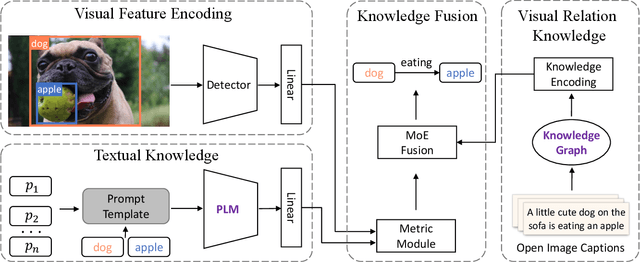
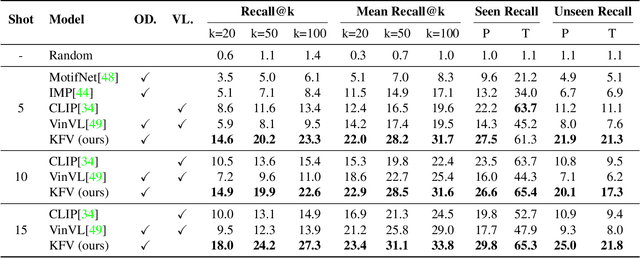
Visual Relation Detection (VRD) aims to detect relationships between objects for image understanding. Most existing VRD methods rely on thousands of training samples of each relationship to achieve satisfactory performance. Some recent papers tackle this problem by few-shot learning with elaborately designed pipelines and pre-trained word vectors. However, the performance of existing few-shot VRD models is severely hampered by the poor generalization capability, as they struggle to handle the vast semantic diversity of visual relationships. Nonetheless, humans have the ability to learn new relationships with just few examples based on their knowledge. Inspired by this, we devise a knowledge-augmented, few-shot VRD framework leveraging both textual knowledge and visual relation knowledge to improve the generalization ability of few-shot VRD. The textual knowledge and visual relation knowledge are acquired from a pre-trained language model and an automatically constructed visual relation knowledge graph, respectively. We extensively validate the effectiveness of our framework. Experiments conducted on three benchmarks from the commonly used Visual Genome dataset show that our performance surpasses existing state-of-the-art models with a large improvement.
Lifelong-MonoDepth: Lifelong Learning for Multi-Domain Monocular Metric Depth Estimation
Mar 09, 2023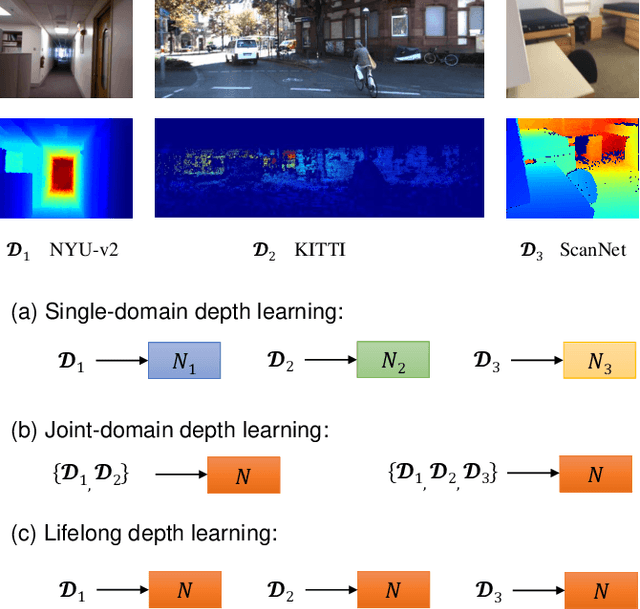
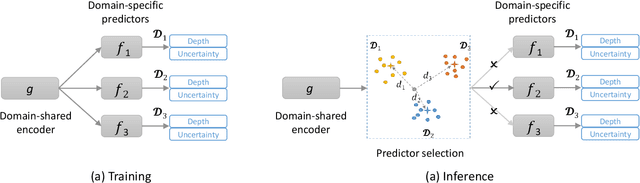
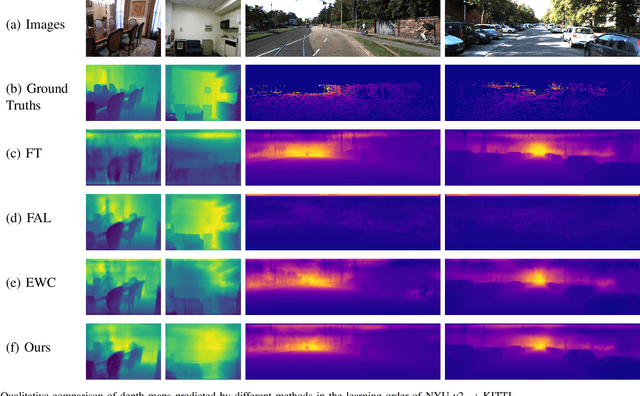
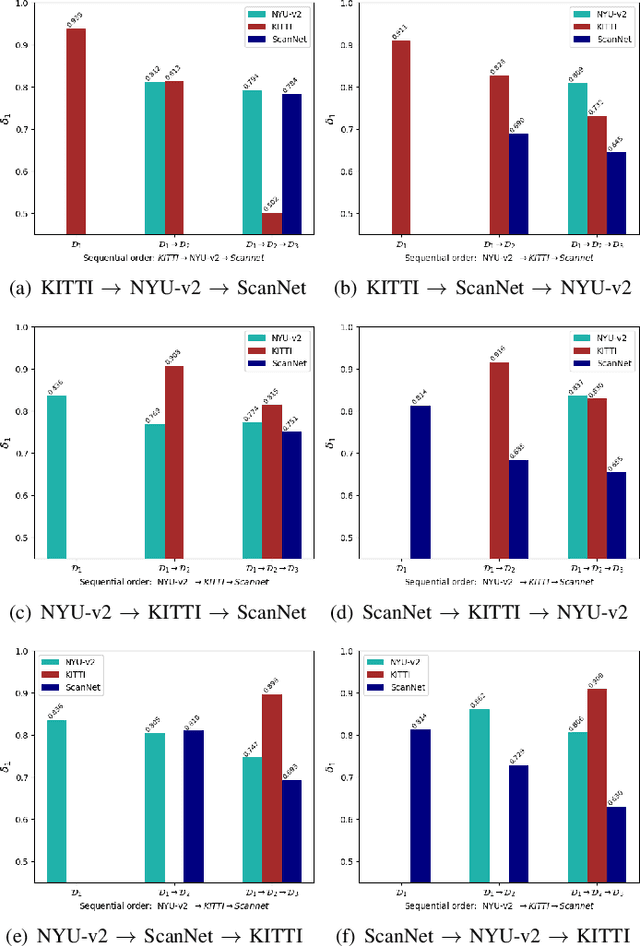
In recent years, monocular depth estimation (MDE) has gained significant progress in a data-driven learning fashion. Previous methods can infer depth maps for specific domains based on the paradigm of single-domain or joint-domain training with mixed data. However, they suffer from low scalability to new domains. In reality, target domains often dynamically change or increase, raising the requirement of incremental multi-domain/task learning. In this paper, we seek to enable lifelong learning for MDE, which performs cross-domain depth learning sequentially, to achieve high plasticity on a new domain and maintain good stability on original domains. To overcome significant domain gaps and enable scale-aware depth prediction, we design a lightweight multi-head framework that consists of a domain-shared encoder for feature extraction and domain-specific predictors for metric depth estimation. Moreover, given an input image, we propose an efficient predictor selection approach that automatically identifies the corresponding predictor for depth inference. Through extensive numerical studies, we show that the proposed method can achieve good efficiency, stability, and plasticity, leading the benchmarks by 8% to 15%.