 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Map-free Visual Relocalization: Metric Pose Relative to a Single Image
Oct 11, 2022
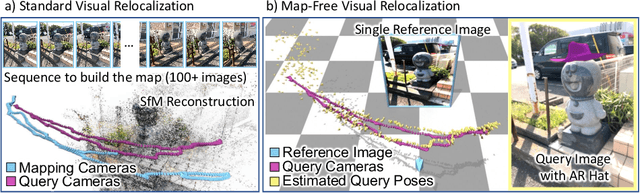

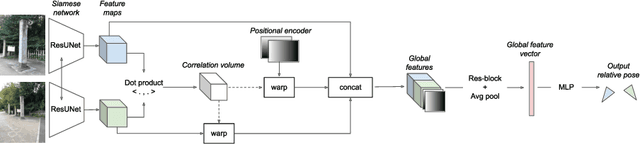

Can we relocalize in a scene represented by a single reference image? Standard visual relocalization requires hundreds of images and scale calibration to build a scene-specific 3D map. In contrast, we propose Map-free Relocalization, i.e., using only one photo of a scene to enable instant, metric scaled relocalization. Existing datasets are not suitable to benchmark map-free relocalization, due to their focus on large scenes or their limited variability. Thus, we have constructed a new dataset of 655 small places of interest, such as sculptures, murals and fountains, collected worldwide. Each place comes with a reference image to serve as a relocalization anchor, and dozens of query images with known, metric camera poses. The dataset features changing conditions, stark viewpoint changes, high variability across places, and queries with low to no visual overlap with the reference image. We identify two viable families of existing methods to provide baseline results: relative pose regression, and feature matching combined with single-image depth prediction. While these methods show reasonable performance on some favorable scenes in our dataset, map-free relocalization proves to be a challenge that requires new, innovative solutions.
Global Knowledge Calibration for Fast Open-Vocabulary Segmentation
Mar 16, 2023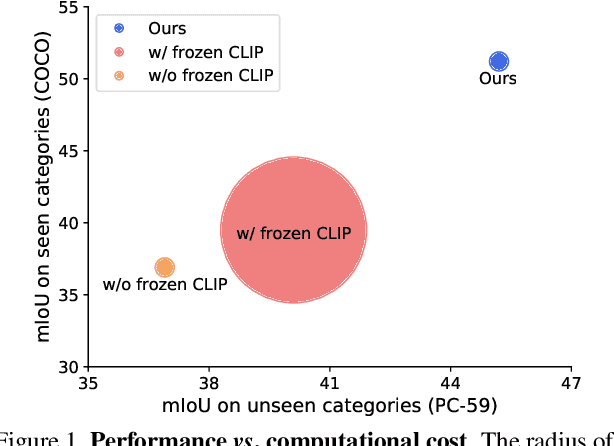
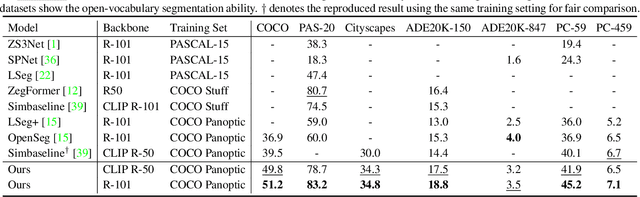
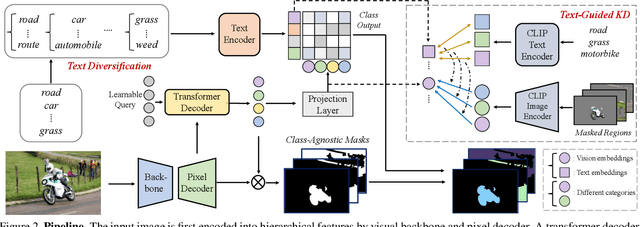

Recent advancements in pre-trained vision-language models, such as CLIP, have enabled the segmentation of arbitrary concepts solely from textual inputs, a process commonly referred to as open-vocabulary semantic segmentation (OVS). However, existing OVS techniques confront a fundamental challenge: the trained classifier tends to overfit on the base classes observed during training, resulting in suboptimal generalization performance to unseen classes. To mitigate this issue, recent studies have proposed the use of an additional frozen pre-trained CLIP for classification. Nonetheless, this approach incurs heavy computational overheads as the CLIP vision encoder must be repeatedly forward-passed for each mask, rendering it impractical for real-world applications. To address this challenge, our objective is to develop a fast OVS model that can perform comparably or better without the extra computational burden of the CLIP image encoder during inference. To this end, we propose a core idea of preserving the generalizable representation when fine-tuning on known classes. Specifically, we introduce a text diversification strategy that generates a set of synonyms for each training category, which prevents the learned representation from collapsing onto specific known category names. Additionally, we employ a text-guided knowledge distillation method to preserve the generalizable knowledge of CLIP. Extensive experiments demonstrate that our proposed model achieves robust generalization performance across various datasets. Furthermore, we perform a preliminary exploration of open-vocabulary video segmentation and present a benchmark that can facilitate future open-vocabulary research in the video domain.
CoLo-CAM: Class Activation Mapping for Object Co-Localization in Weakly-Labeled Unconstrained Videos
Mar 16, 2023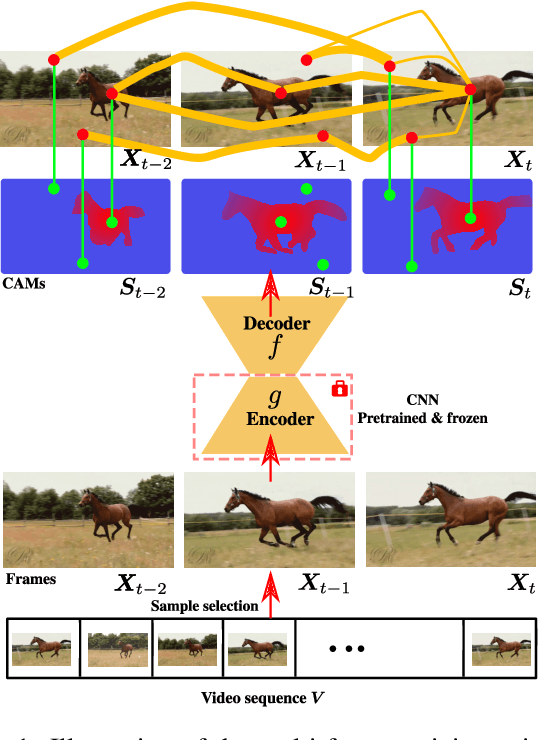
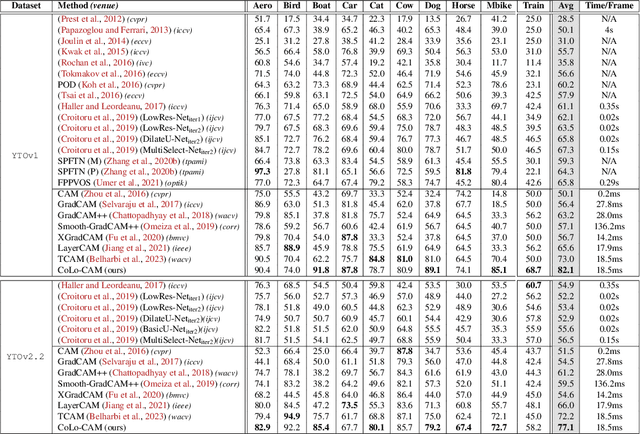
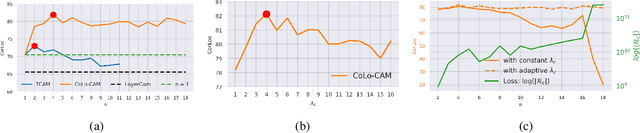

Weakly-supervised video object localization (WSVOL) methods often rely on visual and motion cues only, making them susceptible to inaccurate localization. Recently, discriminative models via a temporal class activation mapping (CAM) method have been explored. Although results are promising, objects are assumed to have minimal movement leading to degradation in performance for relatively long-term dependencies. In this paper, a novel CoLo-CAM method for object localization is proposed to leverage spatiotemporal information in activation maps without any assumptions about object movement. Over a given sequence of frames, explicit joint learning of localization is produced across these maps based on color cues, by assuming an object has similar color across frames. The CAMs' activations are constrained to activate similarly over pixels with similar colors, achieving co-localization. This joint learning creates direct communication among pixels across all image locations, and over all frames, allowing for transfer, aggregation, and correction of learned localization. This is achieved by minimizing a color term of a CRF loss over joint images/maps. In addition to our multi-frame constraint, we impose per-frame local constraints including pseudo-labels, and CRF loss in combination with a global size constraint to improve per-frame localization. Empirical experiments on two challenging datasets for unconstrained videos, YouTube-Objects, show the merits of our method, and its robustness to long-term dependencies, leading to new state-of-the-art localization performance. Public code: https://github.com/sbelharbi/colo-cam.
SSL-Cleanse: Trojan Detection and Mitigation in Self-Supervised Learning
Mar 16, 2023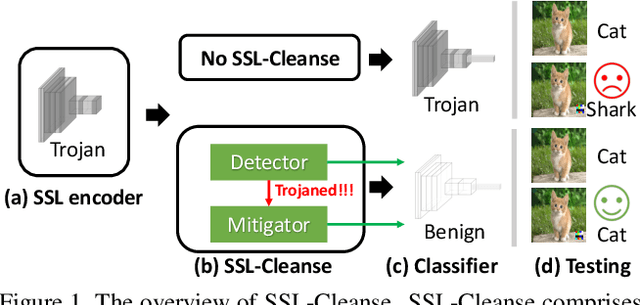
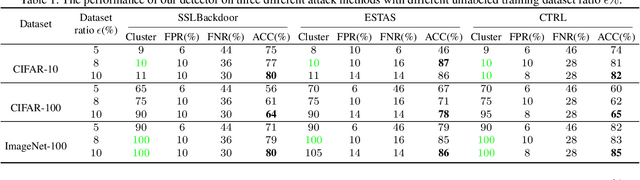


Self-supervised learning (SSL) is a commonly used approach to learning and encoding data representations. By using a pre-trained SSL image encoder and training a downstream classifier on top of it, impressive performance can be achieved on various tasks with very little labeled data. The increasing usage of SSL has led to an uptick in security research related to SSL encoders and the development of various Trojan attacks. The danger posed by Trojan attacks inserted in SSL encoders lies in their ability to operate covertly and spread widely among various users and devices. The presence of backdoor behavior in Trojaned encoders can inadvertently be inherited by downstream classifiers, making it even more difficult to detect and mitigate the threat. Although current Trojan detection methods in supervised learning can potentially safeguard SSL downstream classifiers, identifying and addressing triggers in the SSL encoder before its widespread dissemination is a challenging task. This is because downstream tasks are not always known, dataset labels are not available, and even the original training dataset is not accessible during the SSL encoder Trojan detection. This paper presents an innovative technique called SSL-Cleanse that is designed to detect and mitigate backdoor attacks in SSL encoders. We evaluated SSL-Cleanse on various datasets using 300 models, achieving an average detection success rate of 83.7% on ImageNet-100. After mitigating backdoors, on average, backdoored encoders achieve 0.24% attack success rate without great accuracy loss, proving the effectiveness of SSL-Cleanse.
Learning advisor networks for noisy image classification
Nov 08, 2022In this paper, we introduced the novel concept of advisor network to address the problem of noisy labels in image classification. Deep neural networks (DNN) are prone to performance reduction and overfitting problems on training data with noisy annotations. Weighting loss methods aim to mitigate the influence of noisy labels during the training, completely removing their contribution. This discarding process prevents DNNs from learning wrong associations between images and their correct labels but reduces the amount of data used, especially when most of the samples have noisy labels. Differently, our method weighs the feature extracted directly from the classifier without altering the loss value of each data. The advisor helps to focus only on some part of the information present in mislabeled examples, allowing the classifier to leverage that data as well. We trained it with a meta-learning strategy so that it can adapt throughout the training of the main model. We tested our method on CIFAR10 and CIFAR100 with synthetic noise, and on Clothing1M which contains real-world noise, reporting state-of-the-art results.
* Paper published as Poster at ICIAP21
F2BEV: Bird's Eye View Generation from Surround-View Fisheye Camera Images for Automated Driving
Mar 07, 2023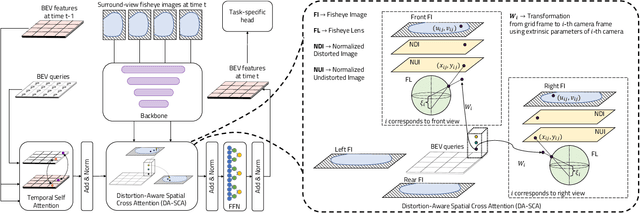



Bird's Eye View (BEV) representations are tremendously useful for perception-related automated driving tasks. However, generating BEVs from surround-view fisheye camera images is challenging due to the strong distortions introduced by such wide-angle lenses. We take the first step in addressing this challenge and introduce a baseline, F2BEV, to generate BEV height maps and semantic segmentation maps from fisheye images. F2BEV consists of a distortion-aware spatial cross attention module for querying and consolidating spatial information from fisheye image features in a transformer-style architecture followed by a task-specific head. We evaluate single-task and multi-task variants of F2BEV on our synthetic FB-SSEM dataset, all of which generate better BEV height and segmentation maps (in terms of the IoU) than a state-of-the-art BEV generation method operating on undistorted fisheye images. We also demonstrate height map generation from real-world fisheye images using F2BEV. An initial sample of our dataset is publicly available at https://tinyurl.com/58jvnscy
Clustering-Induced Generative Incomplete Image-Text Clustering (CIGIT-C)
Sep 28, 2022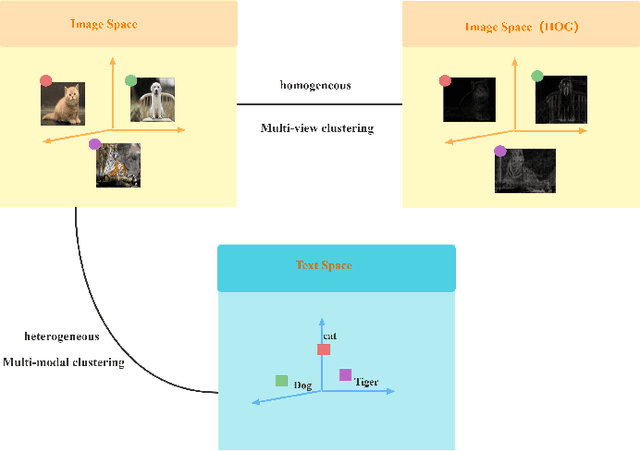
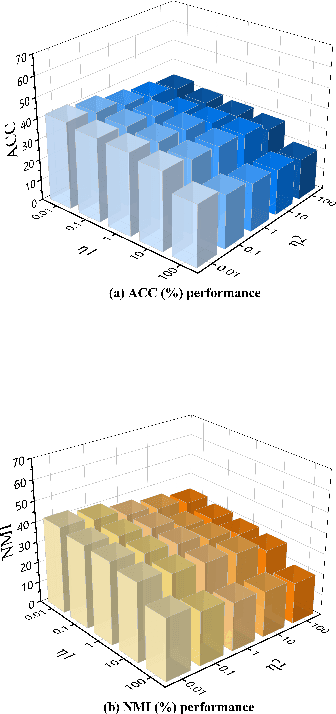
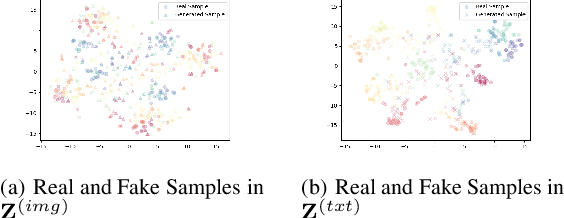

The target of image-text clustering (ITC) is to find correct clusters by integrating complementary and consistent information of multi-modalities for these heterogeneous samples. However, the majority of current studies analyse ITC on the ideal premise that the samples in every modality are complete. This presumption, however, is not always valid in real-world situations. The missing data issue degenerates the image-text feature learning performance and will finally affect the generalization abilities in ITC tasks. Although a series of methods have been proposed to address this incomplete image text clustering issue (IITC), the following problems still exist: 1) most existing methods hardly consider the distinct gap between heterogeneous feature domains. 2) For missing data, the representations generated by existing methods are rarely guaranteed to suit clustering tasks. 3) Existing methods do not tap into the latent connections both inter and intra modalities. In this paper, we propose a Clustering-Induced Generative Incomplete Image-Text Clustering(CIGIT-C) network to address the challenges above. More specifically, we first use modality-specific encoders to map original features to more distinctive subspaces. The latent connections between intra and inter-modalities are thoroughly explored by using the adversarial generating network to produce one modality conditional on the other modality. Finally, we update the corresponding modalityspecific encoders using two KL divergence losses. Experiment results on public image-text datasets demonstrated that the suggested method outperforms and is more effective in the IITC job.
Video Action Recognition Collaborative Learning with Dynamics via PSO-ConvNet Transformer
Feb 17, 2023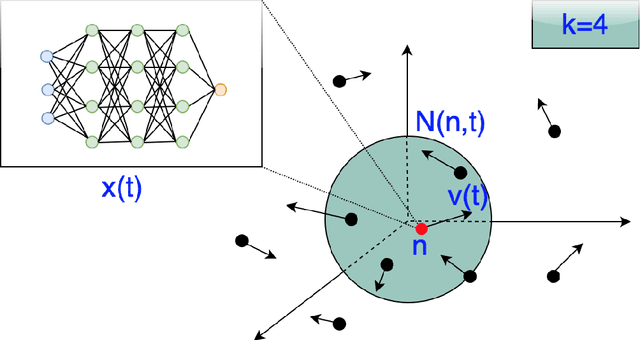
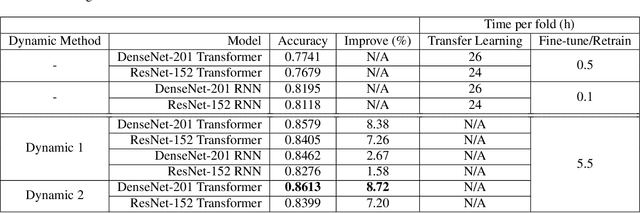
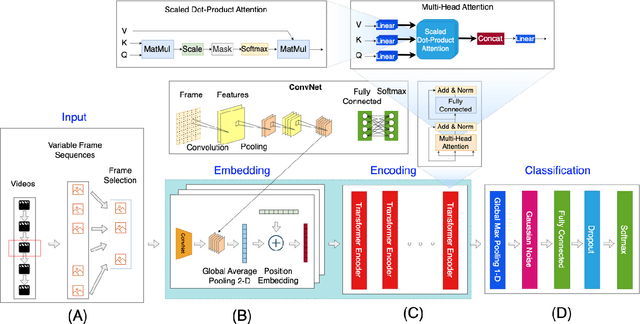

Human Action Recognition (HAR) involves the task of categorizing actions present in video sequences. Although it presents interesting problems, it remains one of the most challenging domains in pattern recognition. Convolutional Neural Networks (ConvNets) have demonstrated exceptional success in image recognition and related areas. However, these advanced techniques are not always directly applicable to HAR, as the consideration of temporal features is crucial. In this paper, we present a dynamic PSO-ConvNet model for learning actions in video, drawing on our recent research in image recognition. Our methods are based on a framework where the weight vector of each neural network serves as the position of a particle in phase space, and particles exchange their current weight vectors and gradient estimates of the Loss function. We extend the approach to video by integrating a ConvNet with state-of-the-art temporal methods such as Transformer and Recurrent Neural Networks. The results reveal substantial advancements, with improvements of up to 9% on UCF-101 dataset. The code is available at https://github.com/leonlha/Video-Action-Recognition-via-PSO-ConvNet-Transformer-Collaborative-Learning-with-Dynamics.
Stereo Event-based Visual-Inertial Odometry
Mar 09, 2023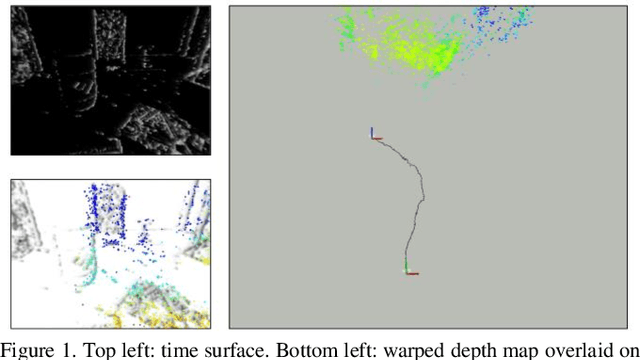
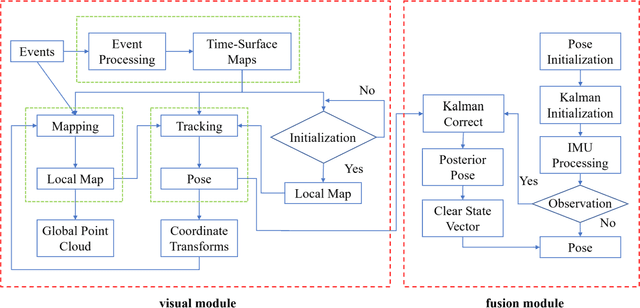
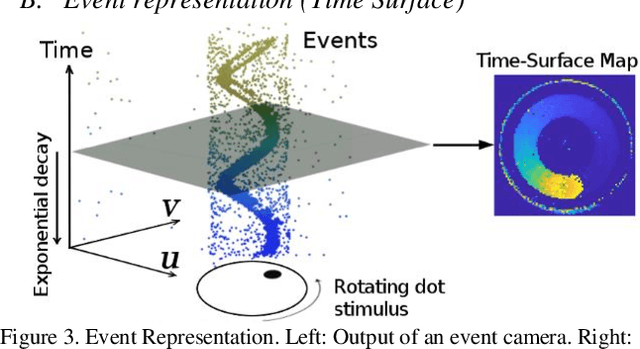
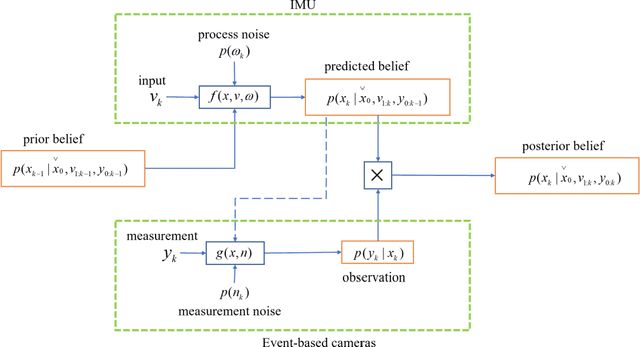
Event-based cameras are new type vision sensors whose pixels work independently and respond asynchronously to brightness change with microsecond resolution, instead of provide stand-ard intensity frames. Compared with traditional cameras, event-based cameras have low latency, no motion blur, and high dynamic range (HDR), which provide possibilities for robots to deal with some challenging scenes. We propose a visual-inertial odometry method for stereo event-cameras based on Kalman filtering. The visual module updates the camera pose relies on the edge alignment of a semi-dense 3D map to a 2D image, and the IMU module updates pose by midpoint method. We evaluate our method on public datasets in natural scenes with general 6-DoF motion and compare the results against ground truth. We show that the proposed pipeline provides improved accuracy over the result of a state-of-the-art visual odometry method for stereo event-cameras, while running in real-time on a standard CPU. To the best of our knowledge, this is the first published visual-inertial odometry algorithm for stereo event-cameras.
3D wind field profiles from hyperspectral sounders: revisiting optic-flow from a meteorological perspective
Mar 09, 2023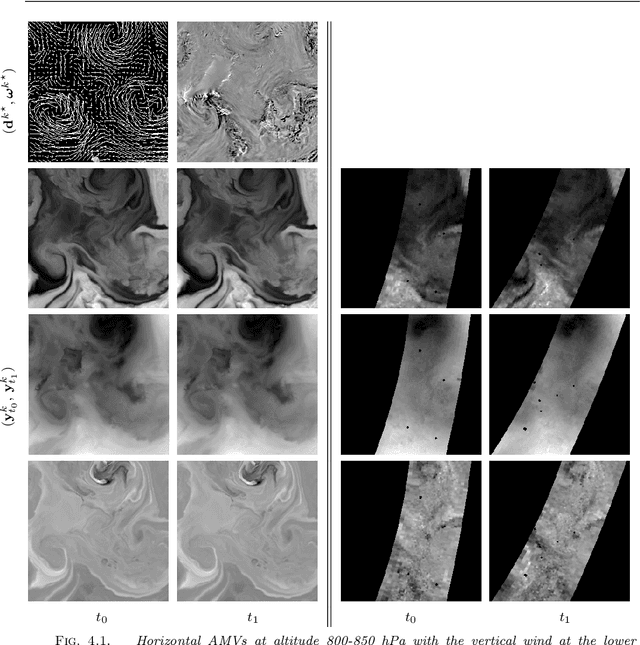
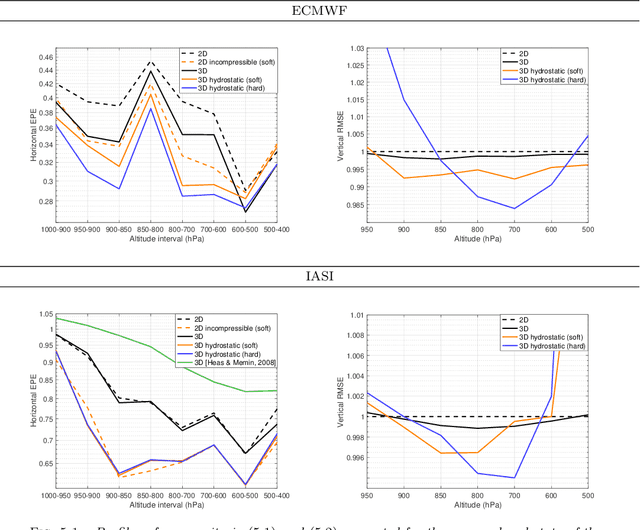


In this work, we present an efficient optic flow algorithm for the extraction of vertically resolved 3D atmospheric motion vector (AMV) fields from incomplete hyperspectral image data measures by infrared sounders. The model at the heart of the energy to be minimized is consistent with atmospheric dynamics, incorporating ingredients of thermodynamics, hydrostatic equilibrium and statistical turbulence. Modern optimization techniques are deployed to design a low-complexity solver for the energy minimization problem, which is non-convex, non-differentiable, high-dimensional and subject to physical constraints. In particular, taking advantage of the alternate direction of multipliers methods (ADMM), we show how to split the original high-dimensional problem into a recursion involving a set of standard and tractable optic-flow sub-problems. By comparing with the ground truth provided by the operational numerical simulation of the European Centre for Medium-Range Weather Forecasts (ECMWF), we show that the performance of the proposed method is superior to state-of-the-art optical flow algorithms in the context of real infrared atmospheric sounding interferometer (IASI) observations.