 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Continuous U-Net: Faster, Greater and Noiseless
Feb 01, 2023
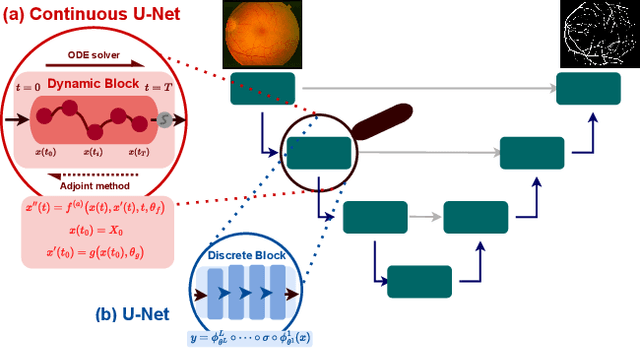

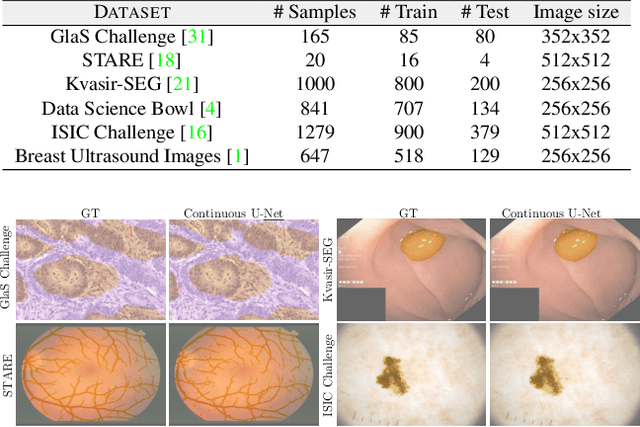
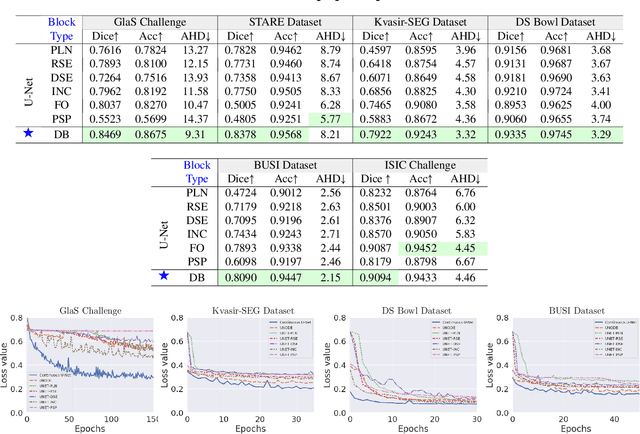
Image segmentation is a fundamental task in image analysis and clinical practice. The current state-of-the-art techniques are based on U-shape type encoder-decoder networks with skip connections, called U-Net. Despite the powerful performance reported by existing U-Net type networks, they suffer from several major limitations. Issues include the hard coding of the receptive field size, compromising the performance and computational cost, as well as the fact that they do not account for inherent noise in the data. They have problems associated with discrete layers, and do not offer any theoretical underpinning. In this work we introduce continuous U-Net, a novel family of networks for image segmentation. Firstly, continuous U-Net is a continuous deep neural network that introduces new dynamic blocks modelled by second order ordinary differential equations. Secondly, we provide theoretical guarantees for our network demonstrating faster convergence, higher robustness and less sensitivity to noise. Thirdly, we derive qualitative measures to tailor-made segmentation tasks. We demonstrate, through extensive numerical and visual results, that our model outperforms existing U-Net blocks for several medical image segmentation benchmarking datasets.
Counterfactual Explanation and Instance-Generation using Cycle-Consistent Generative Adversarial Networks
Jan 21, 2023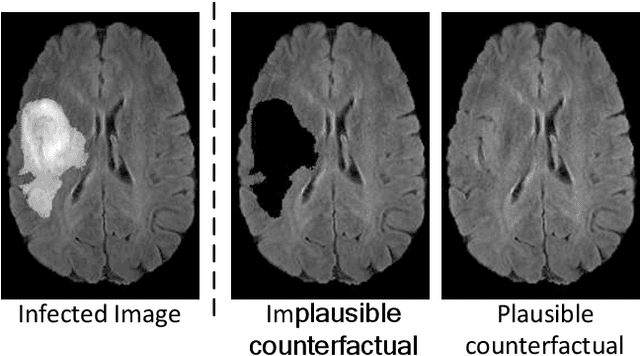
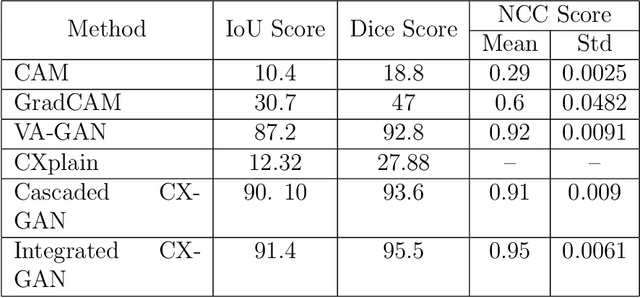
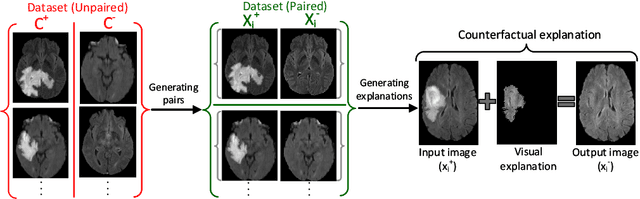
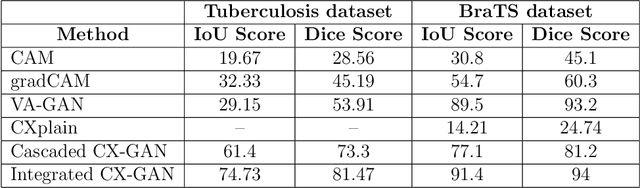
The image-based diagnosis is now a vital aspect of modern automation assisted diagnosis. To enable models to produce pixel-level diagnosis, pixel-level ground-truth labels are essentially required. However, since it is often not straight forward to obtain the labels in many application domains such as in medical image, classification-based approaches have become the de facto standard to perform the diagnosis. Though they can identify class-salient regions, they may not be useful for diagnosis where capturing all of the evidences is important requirement. Alternatively, a counterfactual explanation (CX) aims at providing explanations using a casual reasoning process of form "If X has not happend, Y would not heppend". Existing CX approaches, however, use classifier to explain features that can change its predictions. Thus, they can only explain class-salient features, rather than entire object of interest. This hence motivates us to propose a novel CX strategy that is not reliant on image classification. This work is inspired from the recent developments in generative adversarial networks (GANs) based image-to-image domain translation, and leverages to translate an abnormal image to counterpart normal image (i.e. counterfactual instance CI) to find discrepancy maps between the two. Since it is generally not possible to obtain abnormal and normal image pairs, we leverage Cycle-Consistency principle (a.k.a CycleGAN) to perform the translation in unsupervised way. We formulate CX in terms of a discrepancy map that, when added from the abnormal image, will make it indistinguishable from the CI. We evaluate our method on three datasets including a synthetic, tuberculosis and BraTS dataset. All these experiments confirm the supremacy of propose method in generating accurate CX and CI.
Sequential Spatial Network for Collision Avoidance in Autonomous Driving
Mar 12, 2023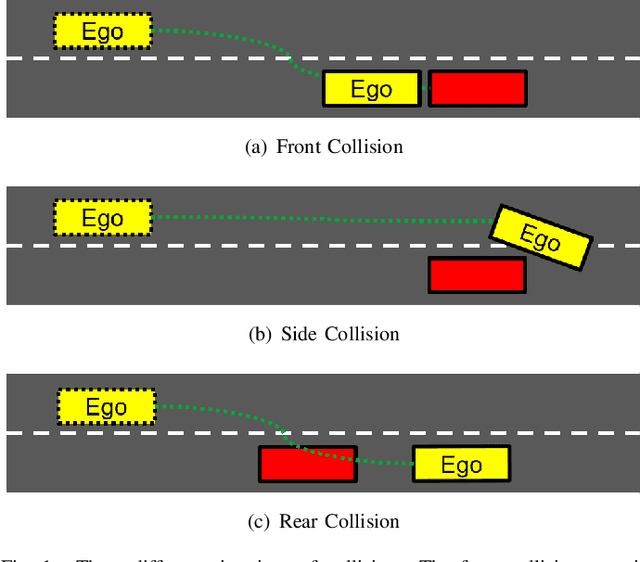
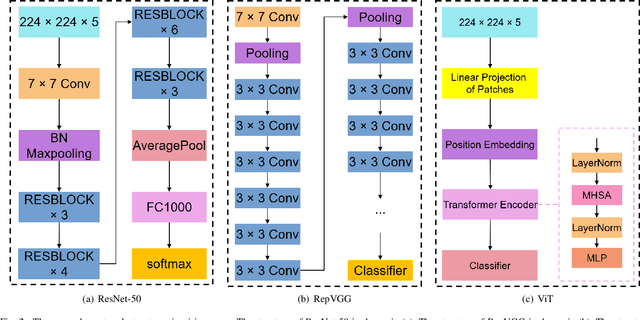
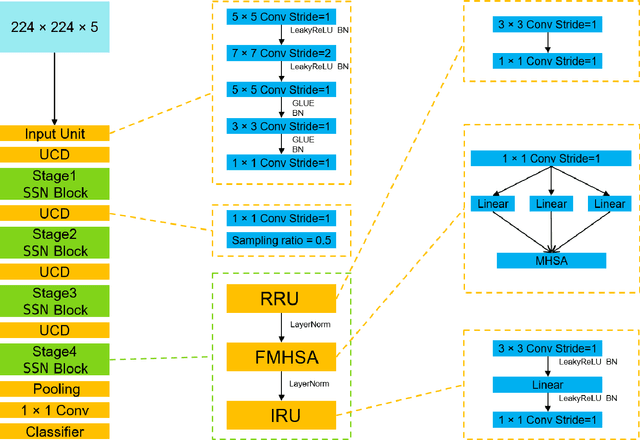
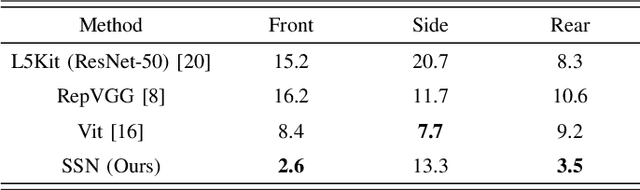
Several autonomous driving strategies have been applied to autonomous vehicles, especially in the collision avoidance area. The purpose of collision avoidance is achieved by adjusting the trajectory of autonomous vehicles (AV) to avoid intersection or overlap with the trajectory of surrounding vehicles. A large number of sophisticated vision algorithms have been designed for target inspection, classification, and other tasks, such as ResNet, YOLO, etc., which have achieved excellent performance in vision tasks because of their ability to accurately and quickly capture regional features. However, due to the variability of different tasks, the above models achieve good performance in capturing small regions but are still insufficient in correlating the regional features of the input image with each other. In this paper, we aim to solve this problem and develop an algorithm that takes into account the advantages of CNN in capturing regional features while establishing feature correlation between regions using variants of attention. Finally, our model achieves better performance in the test set of L5Kit compared to the other vision models. The average number of collisions is 19.4 per 10000 frames of driving distance, which greatly improves the success rate of collision avoidance.
Improved Segmentation of Deep Sulci in Cortical Gray Matter Using a Deep Learning Framework Incorporating Laplace's Equation
Mar 03, 2023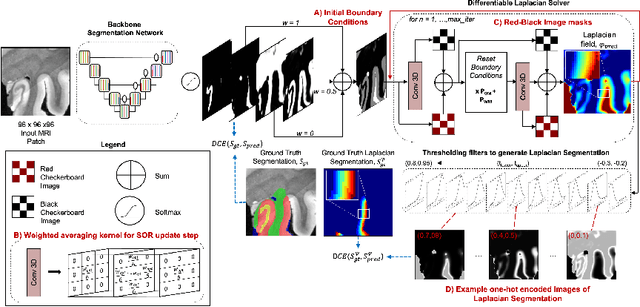
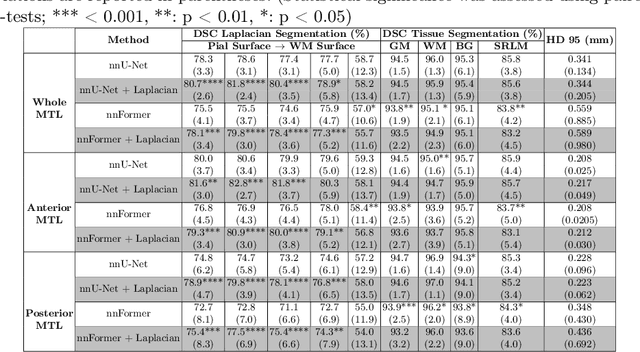
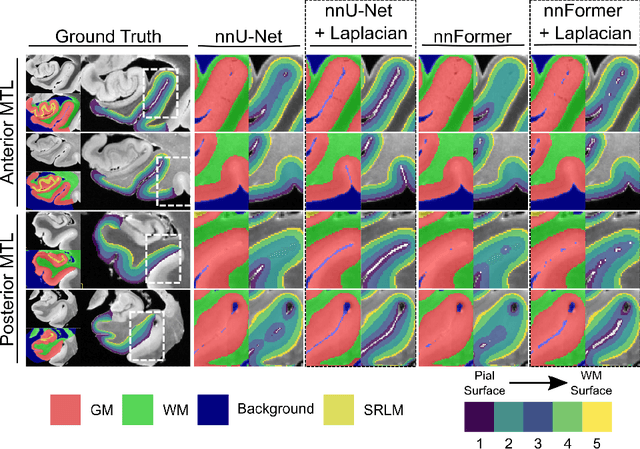
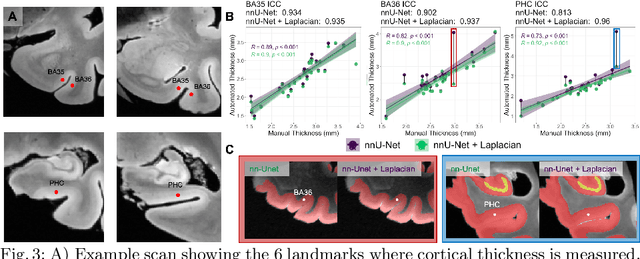
When developing tools for automated cortical segmentation, the ability to produce topologically correct segmentations is important in order to compute geometrically valid morphometry measures. In practice, accurate cortical segmentation is challenged by image artifacts and the highly convoluted anatomy of the cortex itself. To address this, we propose a novel deep learning-based cortical segmentation method in which prior knowledge about the geometry of the cortex is incorporated into the network during the training process. We design a loss function which uses the theory of Laplace's equation applied to the cortex to locally penalize unresolved boundaries between tightly folded sulci. Using an ex vivo MRI dataset of human medial temporal lobe specimens, we demonstrate that our approach outperforms baseline segmentation networks, both quantitatively and qualitatively.
ParaFormer: Parallel Attention Transformer for Efficient Feature Matching
Mar 10, 2023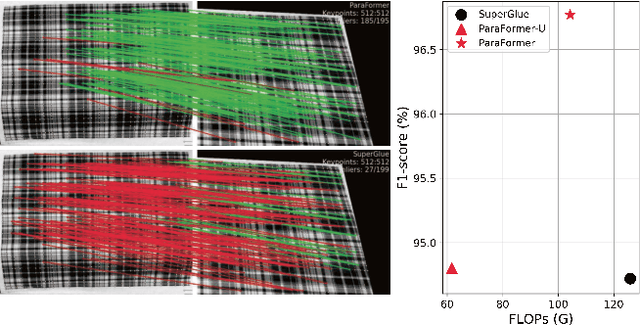
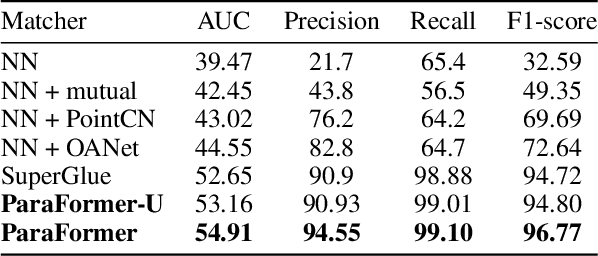
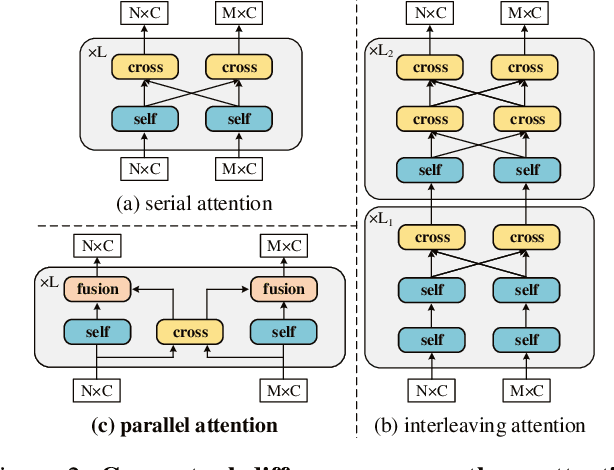
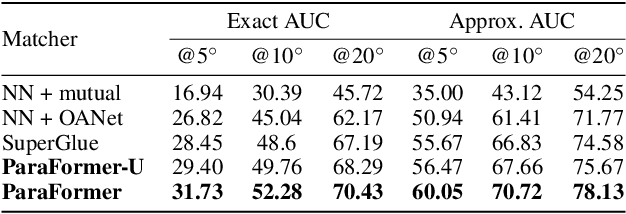
Heavy computation is a bottleneck limiting deep-learningbased feature matching algorithms to be applied in many realtime applications. However, existing lightweight networks optimized for Euclidean data cannot address classical feature matching tasks, since sparse keypoint based descriptors are expected to be matched. This paper tackles this problem and proposes two concepts: 1) a novel parallel attention model entitled ParaFormer and 2) a graph based U-Net architecture with attentional pooling. First, ParaFormer fuses features and keypoint positions through the concept of amplitude and phase, and integrates self- and cross-attention in a parallel manner which achieves a win-win performance in terms of accuracy and efficiency. Second, with U-Net architecture and proposed attentional pooling, the ParaFormer-U variant significantly reduces computational complexity, and minimize performance loss caused by downsampling. Sufficient experiments on various applications, including homography estimation, pose estimation, and image matching, demonstrate that ParaFormer achieves state-of-the-art performance while maintaining high efficiency. The efficient ParaFormer-U variant achieves comparable performance with less than 50% FLOPs of the existing attention-based models.
Adaptive Weight Assignment Scheme For Multi-task Learning
Mar 10, 2023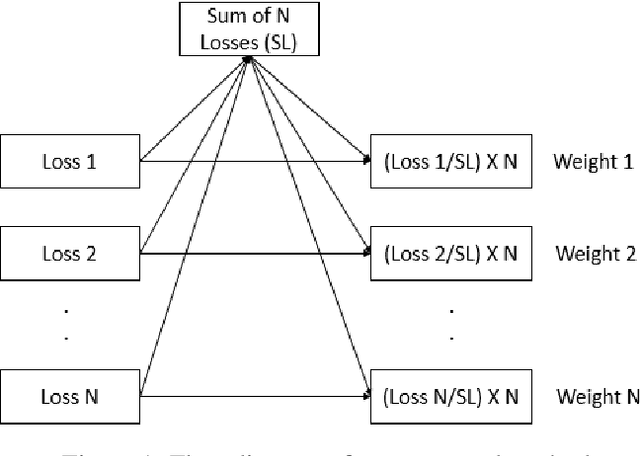
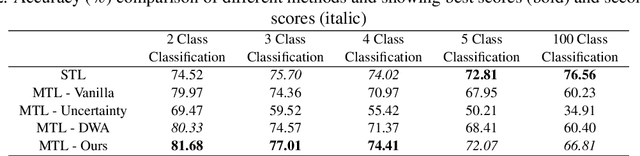
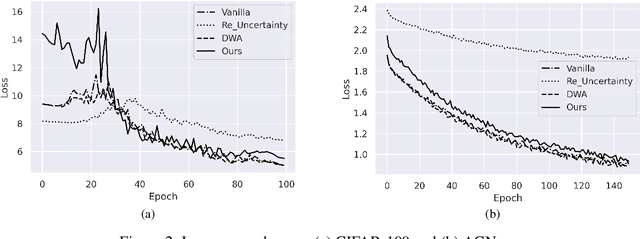
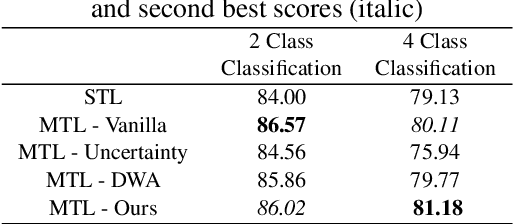
Deep learning based models are used regularly in every applications nowadays. Generally we train a single model on a single task. However, we can train multiple tasks on a single model under multi-task learning settings. This provides us many benefits like lesser training time, training a single model for multiple tasks, reducing overfitting, improving performances etc. To train a model in multi-task learning settings we need to sum the loss values from different tasks. In vanilla multi-task learning settings we assign equal weights but since not all tasks are of similar difficulty we need to allocate more weight to tasks which are more difficult. Also improper weight assignment reduces the performance of the model. We propose a simple weight assignment scheme in this paper which improves the performance of the model and puts more emphasis on difficult tasks. We tested our methods performance on both image and textual data and also compared performance against two popular weight assignment methods. Empirical results suggest that our proposed method achieves better results compared to other popular methods.
Monocular Simultaneous Localization and Mapping using Ground Textures
Mar 10, 2023
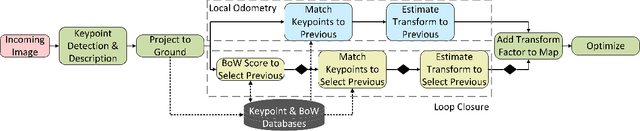

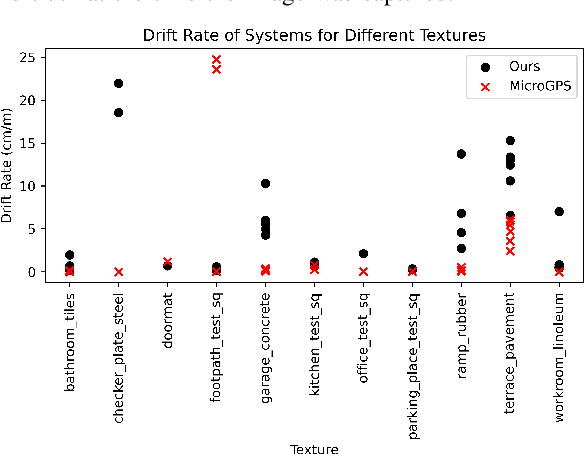
Recent work has shown impressive localization performance using only images of ground textures taken with a downward facing monocular camera. This provides a reliable navigation method that is robust to feature sparse environments and challenging lighting conditions. However, these localization methods require an existing map for comparison. Our work aims to relax the need for a map by introducing a full simultaneous localization and mapping (SLAM) system. By not requiring an existing map, setup times are minimized and the system is more robust to changing environments. This SLAM system uses a combination of several techniques to accomplish this. Image keypoints are identified and projected into the ground plane. These keypoints, visual bags of words, and several threshold parameters are then used to identify overlapping images and revisited areas. The system then uses robust M-estimators to estimate the transform between robot poses with overlapping images and revisited areas. These optimized estimates make up the map used for navigation. We show, through experimental data, that this system performs reliably on many ground textures, but not all.
Exploring Sparse Visual Prompt for Cross-domain Semantic Segmentation
Mar 17, 2023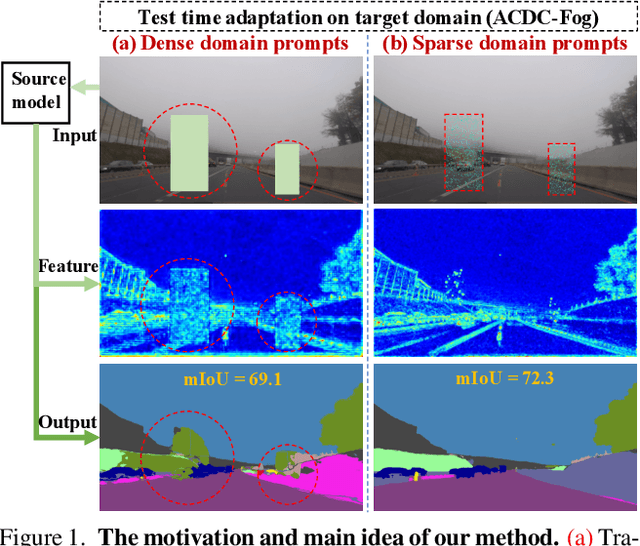
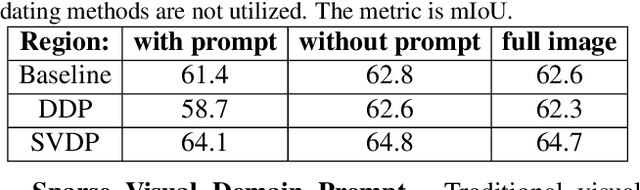
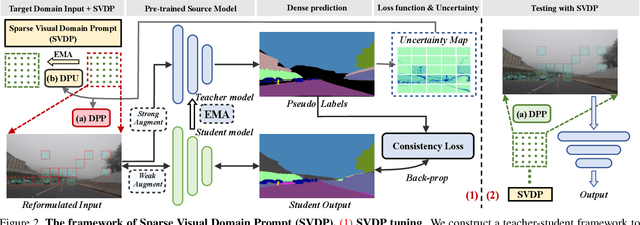

Visual Domain Prompts (VDP) have shown promising potential in addressing visual cross-domain problems. Existing methods adopt VDP in classification domain adaptation (DA), such as tuning image-level or feature-level prompts for target domains. Since the previous dense prompts are opaque and mask out continuous spatial details in the prompt regions, it will suffer from inaccurate contextual information extraction and insufficient domain-specific feature transferring when dealing with the dense prediction (i.e. semantic segmentation) DA problems. Therefore, we propose a novel Sparse Visual Domain Prompts (SVDP) approach tailored for addressing domain shift problems in semantic segmentation, which holds minimal discrete trainable parameters (e.g. 10\%) of the prompt and reserves more spatial information. To better apply SVDP, we propose Domain Prompt Placement (DPP) method to adaptively distribute several SVDP on regions with large data distribution distance based on uncertainty guidance. It aims to extract more local domain-specific knowledge and realizes efficient cross-domain learning. Furthermore, we design a Domain Prompt Updating (DPU) method to optimize prompt parameters differently for each target domain sample with different degrees of domain shift, which helps SVDP to better fit target domain knowledge. Experiments, which are conducted on the widely-used benchmarks (Cityscapes, Foggy-Cityscapes, and ACDC), show that our proposed method achieves state-of-the-art performances on the source-free adaptations, including six Test Time Adaptation and one Continual Test-Time Adaptation in semantic segmentation.
SwinVFTR: A Novel Volumetric Feature-learning Transformer for 3D OCT Fluid Segmentation
Mar 17, 2023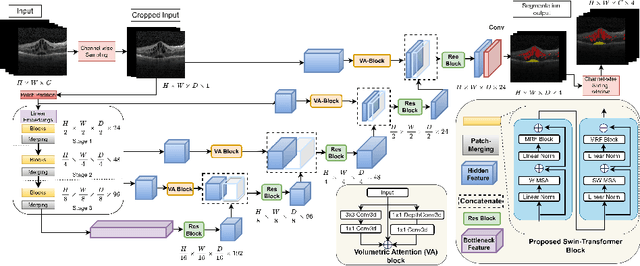
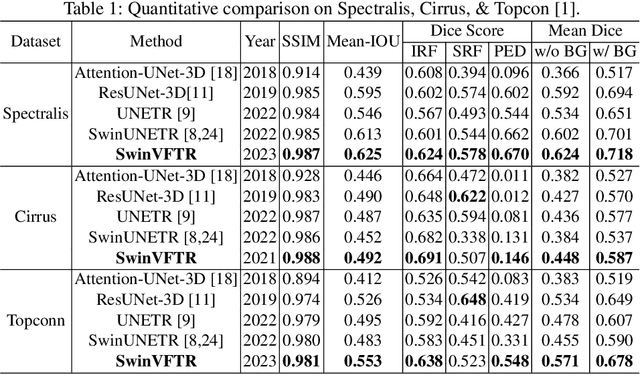
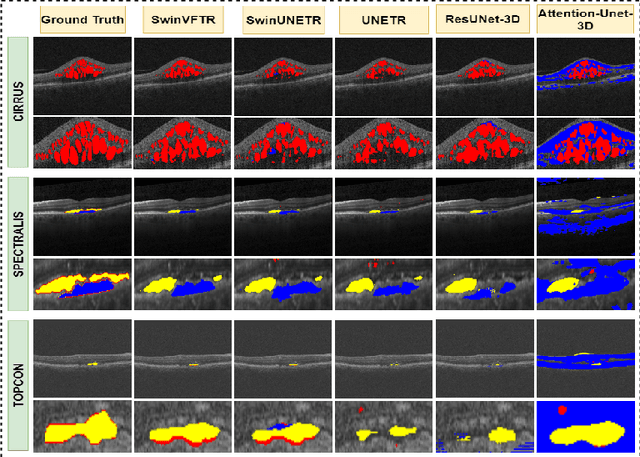
Accurately segmenting fluid in 3D volumetric optical coherence tomography (OCT) images is a crucial yet challenging task for detecting eye diseases. Traditional autoencoding-based segmentation approaches have limitations in extracting fluid regions due to successive resolution loss in the encoding phase and the inability to recover lost information in the decoding phase. Although current transformer-based models for medical image segmentation addresses this limitation, they are not designed to be applied out-of-the-box for 3D OCT volumes, which have a wide-ranging channel-axis size based on different vendor device and extraction technique. To address these issues, we propose SwinVFTR, a new transformer-based architecture designed for precise fluid segmentation in 3D volumetric OCT images. We first utilize a channel-wise volumetric sampling for training on OCT volumes with varying depths (B-scans). Next, the model uses a novel shifted window transformer block in the encoder to achieve better localization and segmentation of fluid regions. Additionally, we propose a new volumetric attention block for spatial and depth-wise attention, which improves upon traditional residual skip connections. Consequently, utilizing multi-class dice loss, the proposed architecture outperforms other existing architectures on the three publicly available vendor-specific OCT datasets, namely Spectralis, Cirrus, and Topcon, with mean dice scores of 0.72, 0.59, and 0.68, respectively. Additionally, SwinVFTR outperforms other architectures in two additional relevant metrics, mean intersection-over-union (Mean-IOU) and structural similarity measure (SSIM).
SF2Former: Amyotrophic Lateral Sclerosis Identification From Multi-center MRI Data Using Spatial and Frequency Fusion Transformer
Feb 28, 2023
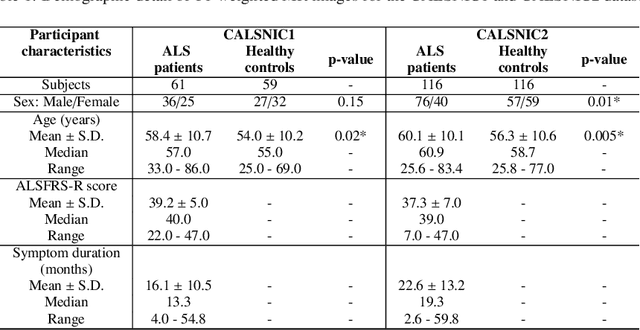
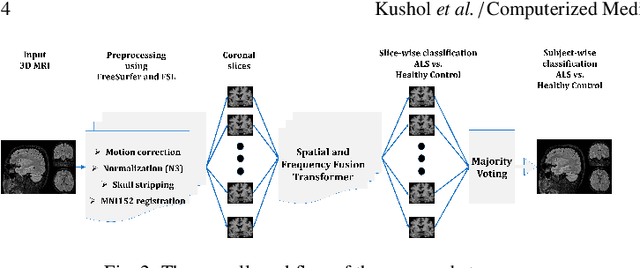
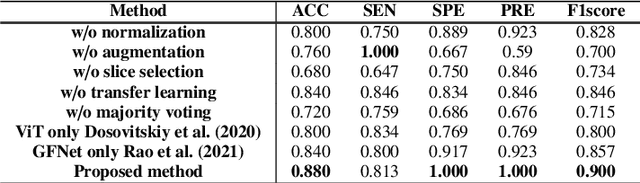
Amyotrophic Lateral Sclerosis (ALS) is a complex neurodegenerative disorder involving motor neuron degeneration. Significant research has begun to establish brain magnetic resonance imaging (MRI) as a potential biomarker to diagnose and monitor the state of the disease. Deep learning has turned into a prominent class of machine learning programs in computer vision and has been successfully employed to solve diverse medical image analysis tasks. However, deep learning-based methods applied to neuroimaging have not achieved superior performance in ALS patients classification from healthy controls due to having insignificant structural changes correlated with pathological features. Therefore, the critical challenge in deep models is to determine useful discriminative features with limited training data. By exploiting the long-range relationship of image features, this study introduces a framework named SF2Former that leverages vision transformer architecture's power to distinguish the ALS subjects from the control group. To further improve the network's performance, spatial and frequency domain information are combined because MRI scans are captured in the frequency domain before being converted to the spatial domain. The proposed framework is trained with a set of consecutive coronal 2D slices, which uses the pre-trained weights on ImageNet by leveraging transfer learning. Finally, a majority voting scheme has been employed to those coronal slices of a particular subject to produce the final classification decision. Our proposed architecture has been thoroughly assessed with multi-modal neuroimaging data using two well-organized versions of the Canadian ALS Neuroimaging Consortium (CALSNIC) multi-center datasets. The experimental results demonstrate the superiority of our proposed strategy in terms of classification accuracy compared with several popular deep learning-based techniques.