 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Weakly-Supervised Text Instance Segmentation
Mar 20, 2023
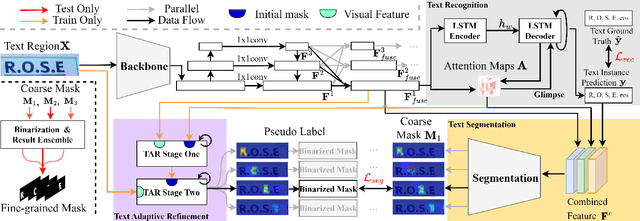
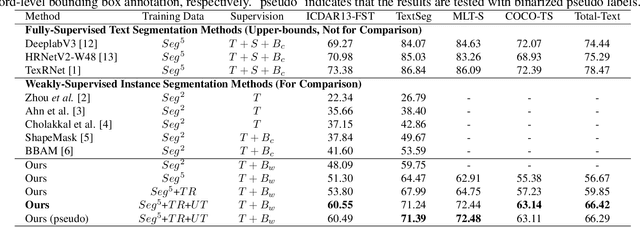


Text segmentation is a challenging vision task with many downstream applications. Current text segmentation methods require pixel-level annotations, which are expensive in the cost of human labor and limited in application scenarios. In this paper, we take the first attempt to perform weakly-supervised text instance segmentation by bridging text recognition and text segmentation. The insight is that text recognition methods provide precise attention position of each text instance, and the attention location can feed to both a text adaptive refinement head (TAR) and a text segmentation head. Specifically, the proposed TAR generates pseudo labels by performing two-stage iterative refinement operations on the attention location to fit the accurate boundaries of the corresponding text instance. Meanwhile, the text segmentation head takes the rough attention location to predict segmentation masks which are supervised by the aforementioned pseudo labels. In addition, we design a mask-augmented contrastive learning by treating our segmentation result as an augmented version of the input text image, thus improving the visual representation and further enhancing the performance of both recognition and segmentation. The experimental results demonstrate that the proposed method significantly outperforms weakly-supervised instance segmentation methods on ICDAR13-FST (18.95$\%$ improvement) and TextSeg (17.80$\%$ improvement) benchmarks.
Facial Affective Analysis based on MAE and Multi-modal Information for 5th ABAW Competition
Mar 20, 2023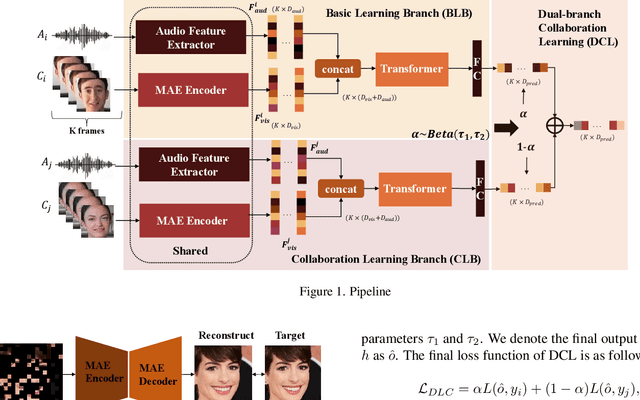
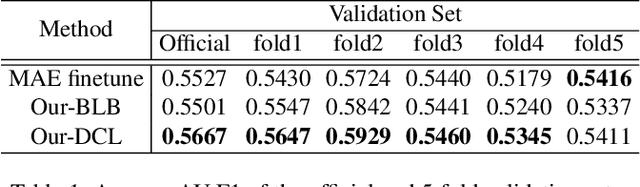
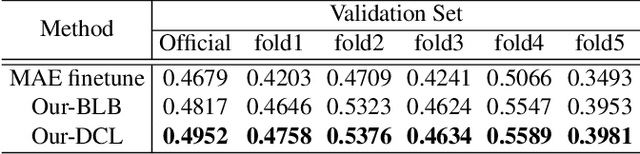
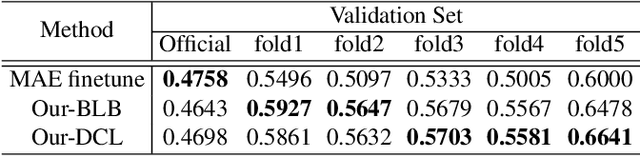
Human affective behavior analysis focuses on analyzing human expressions or other behaviors, which helps improve the understanding of human psychology. CVPR 2023 Competition on Affective Behavior Analysis in-the-wild (ABAW) makes great efforts to provide the diversity data for the recognition of the commonly used emotion representations, including Action Units~(AU), basic expression categories and Valence-Arousal~(VA). In this paper, we introduce our submission to the CVPR 2023: ABAW5 for AU detection, expression classification, VA estimation and emotional reaction intensity (ERI) estimation. First of all, we introduce the vision information from an MAE model, which has been pre-trained on a large-scale face image dataset in a self-supervised manner. Then the MAE encoder part is finetuned on the ABAW challenges on the single frame of Aff-wild2 dataset. We also exploit the multi-modal and temporal information from the videos and design a transformer-based framework to fusion the multi-modal features. Moreover, we construct a novel two-branch collaboration training strategy to further enhance the model generalization by randomly interpolating the logits space. The extensive quantitative experiments, as well as ablation studies on the Aff-Wild2 dataset and Hume-Reaction dataset prove the effectiveness of our proposed method.
Adaptive Dynamic Filtering Network for Image Denoising
Nov 26, 2022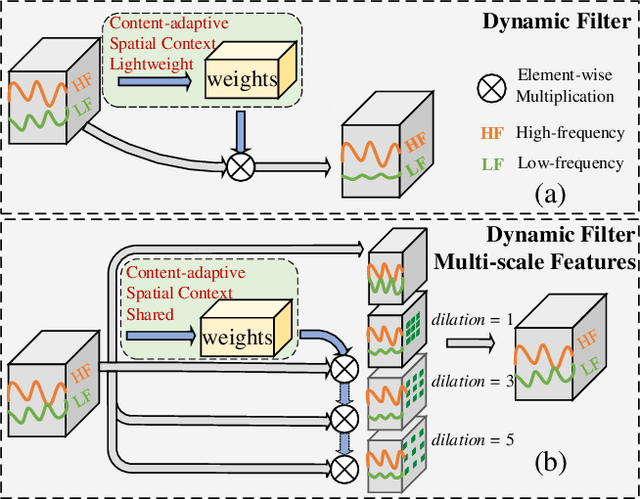
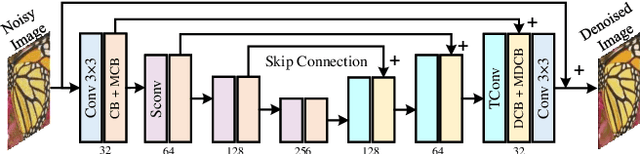

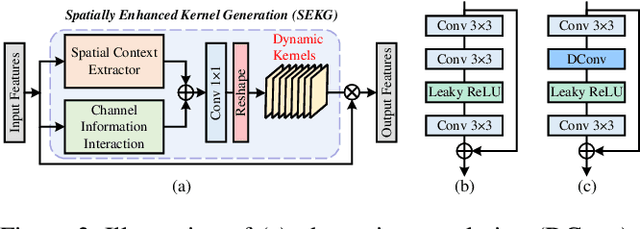
In image denoising networks, feature scaling is widely used to enlarge the receptive field size and reduce computational costs. This practice, however, also leads to the loss of high-frequency information and fails to consider within-scale characteristics. Recently, dynamic convolution has exhibited powerful capabilities in processing high-frequency information (e.g., edges, corners, textures), but previous works lack sufficient spatial contextual information in filter generation. To alleviate these issues, we propose to employ dynamic convolution to improve the learning of high-frequency and multi-scale features. Specifically, we design a spatially enhanced kernel generation (SEKG) module to improve dynamic convolution, enabling the learning of spatial context information with a very low computational complexity. Based on the SEKG module, we propose a dynamic convolution block (DCB) and a multi-scale dynamic convolution block (MDCB). The former enhances the high-frequency information via dynamic convolution and preserves low-frequency information via skip connections. The latter utilizes shared adaptive dynamic kernels and the idea of dilated convolution to achieve efficient multi-scale feature extraction. The proposed multi-dimension feature integration (MFI) mechanism further fuses the multi-scale features, providing precise and contextually enriched feature representations. Finally, we build an efficient denoising network with the proposed DCB and MDCB, named ADFNet. It achieves better performance with low computational complexity on real-world and synthetic Gaussian noisy datasets. The source code is available at https://github.com/it-hao/ADFNet.
Audio Retrieval for Multimodal Design Documents: A New Dataset and Algorithms
Feb 28, 2023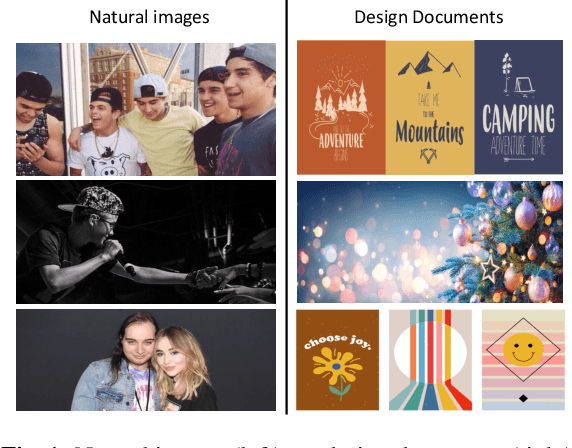
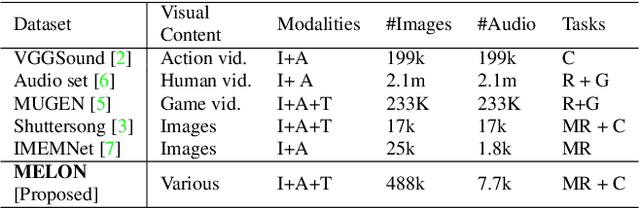

We consider and propose a new problem of retrieving audio files relevant to multimodal design document inputs comprising both textual elements and visual imagery, e.g., birthday/greeting cards. In addition to enhancing user experience, integrating audio that matches the theme/style of these inputs also helps improve the accessibility of these documents (e.g., visually impaired people can listen to the audio instead). While recent work in audio retrieval exists, these methods and datasets are targeted explicitly towards natural images. However, our problem considers multimodal design documents (created by users using creative software) substantially different from a naturally clicked photograph. To this end, our first contribution is collecting and curating a new large-scale dataset called Melodic-Design (or MELON), comprising design documents representing various styles, themes, templates, illustrations, etc., paired with music audio. Given our paired image-text-audio dataset, our next contribution is a novel multimodal cross-attention audio retrieval (MMCAR) algorithm that enables training neural networks to learn a common shared feature space across image, text, and audio dimensions. We use these learned features to demonstrate that our method outperforms existing state-of-the-art methods and produce a new reference benchmark for the research community on our new dataset.
Artificial Intelligence-Based Image Reconstruction in Cardiac Magnetic Resonance
Sep 21, 2022Artificial intelligence (AI) and Machine Learning (ML) have shown great potential in improving the medical imaging workflow, from image acquisition and reconstruction to disease diagnosis and treatment. Particularly, in recent years, there has been a significant growth in the use of AI and ML algorithms, especially Deep Learning (DL) based methods, for medical image reconstruction. DL techniques have shown to be competitive and often superior over conventional reconstruction methods in terms of both reconstruction quality and computational efficiency. The use of DL-based image reconstruction also provides promising opportunities to transform the way cardiac images are acquired and reconstructed. In this chapter, we will review recent advances in DL-based reconstruction techniques for cardiac imaging, with emphasis on cardiac magnetic resonance (CMR) image reconstruction. We mainly focus on supervised DL methods for the application, including image post-processing techniques, model-driven approaches and k-space based methods. Current limitations, challenges and future opportunities of DL for cardiac image reconstruction are also discussed.
Realistic 3D printed imaging tumor phantoms for validation of image processing algorithms
Nov 27, 2022
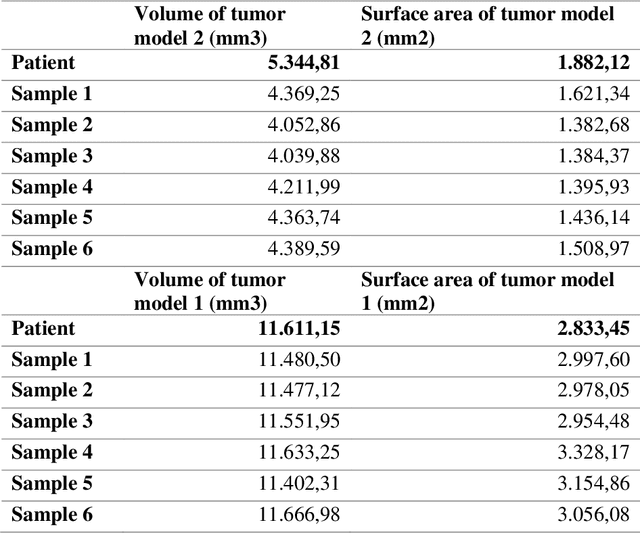
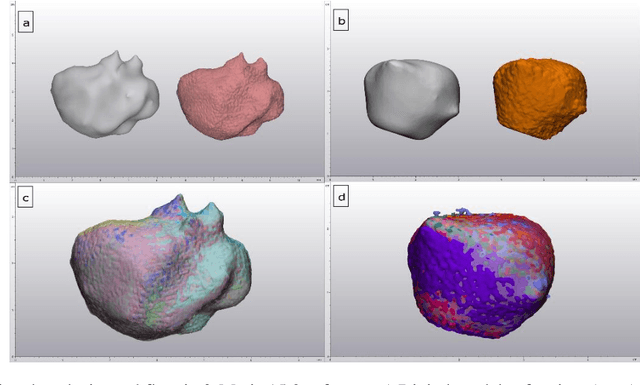
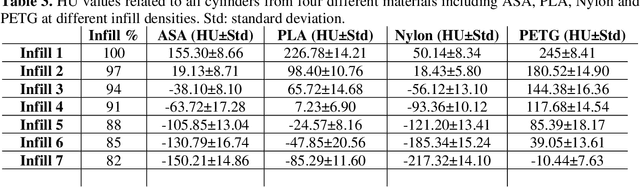
Medical imaging phantoms are widely used for validation and verification of imaging systems and algorithms in surgical guidance and radiation oncology procedures. Especially, for the performance evaluation of new algorithms in the field of medical imaging, manufactured phantoms need to replicate specific properties of the human body, e.g., tissue morphology and radiological properties. Additive manufacturing (AM) technology provides an inexpensive opportunity for accurate anatomical replication with customization capabilities. In this study, we proposed a simple and cheap protocol to manufacture realistic tumor phantoms based on the filament 3D printing technology. Tumor phantoms with both homogenous and heterogenous radiodensity were fabricated. The radiodensity similarity between the printed tumor models and real tumor data from CT images of lung cancer patients was evaluated. Additionally, it was investigated whether a heterogeneity in the 3D printed tumor phantoms as observed in the tumor patient data had an influence on the validation of image registration algorithms. A density range between -217 to 226 HUs was achieved for 3D printed phantoms; this range of radiation attenuation is also observed in the human lung tumor tissue. The resulted HU range could serve as a lookup-table for researchers and phantom manufactures to create realistic CT tumor phantoms with the desired range of radiodensities. The 3D printed tumor phantoms also precisely replicated real lung tumor patient data regarding morphology and could also include life-like heterogeneity of the radiodensity inside the tumor models. An influence of the heterogeneity on accuracy and robustness of the image registration algorithms was not found.
Rethinking Generalization: The Impact of Annotation Style on Medical Image Segmentation
Oct 31, 2022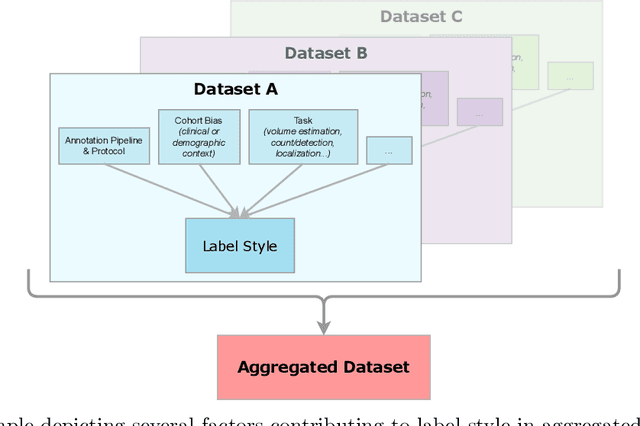
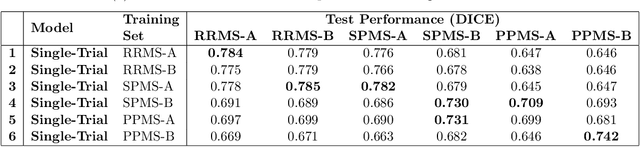
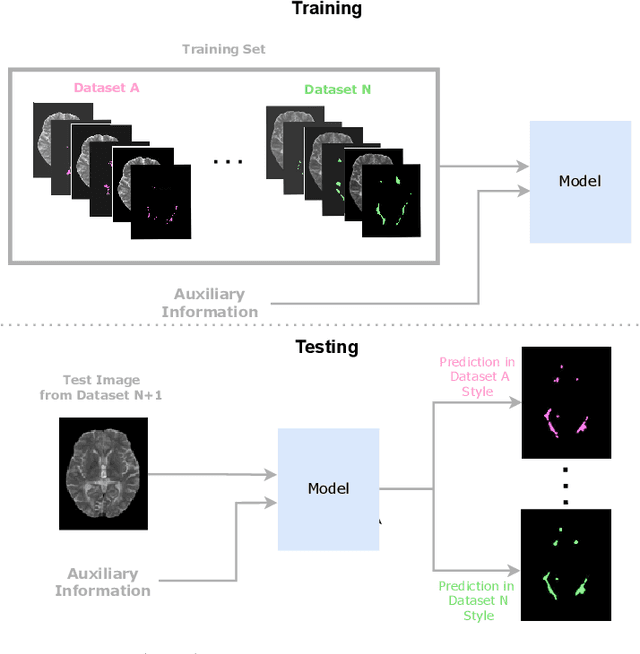
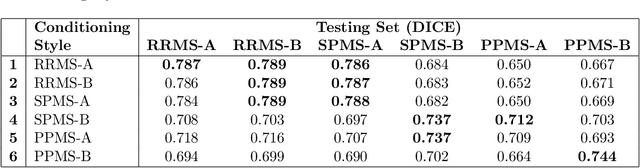
Generalization is an important attribute of machine learning models, particularly for those that are to be deployed in a medical context, where unreliable predictions can have real world consequences. While the failure of models to generalize across datasets is typically attributed to a mismatch in the data distributions, performance gaps are often a consequence of biases in the ``ground-truth" label annotations. This is particularly important in the context of medical image segmentation of pathological structures (e.g. lesions), where the annotation process is much more subjective, and affected by a number underlying factors, including the annotation protocol, rater education/experience, and clinical aims, among others. In this paper, we show that modeling annotation biases, rather than ignoring them, poses a promising way of accounting for differences in annotation style across datasets. To this end, we propose a generalized conditioning framework to (1) learn and account for different annotation styles across multiple datasets using a single model, (2) identify similar annotation styles across different datasets in order to permit their effective aggregation, and (3) fine-tune a fully trained model to a new annotation style with just a few samples. Next, we present an image-conditioning approach to model annotation styles that correlate with specific image features, potentially enabling detection biases to be more easily identified.
Knowing What to Label for Few Shot Microscopy Image Cell Segmentation
Nov 18, 2022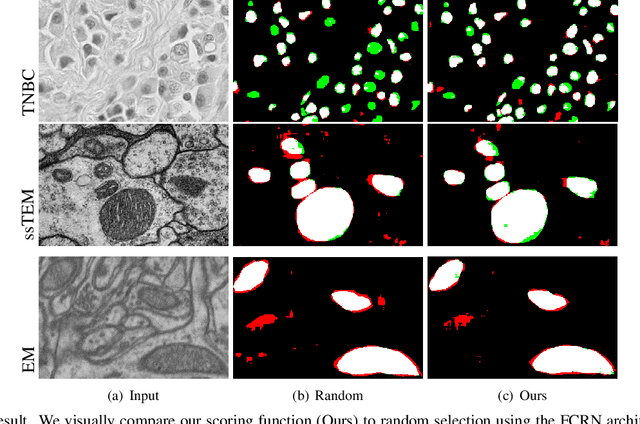


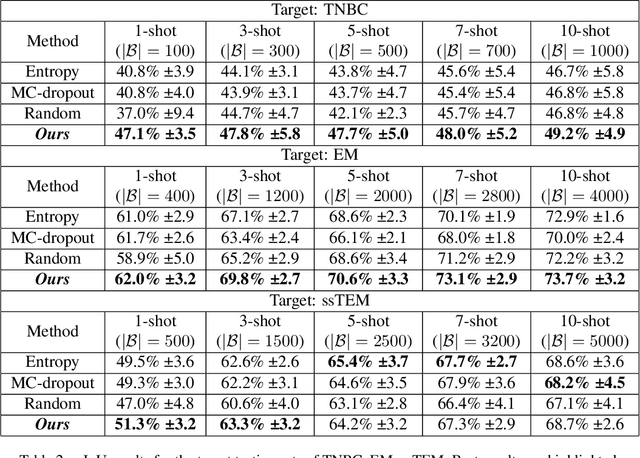
In microscopy image cell segmentation, it is common to train a deep neural network on source data, containing different types of microscopy images, and then fine-tune it using a support set comprising a few randomly selected and annotated training target images. In this paper, we argue that the random selection of unlabelled training target images to be annotated and included in the support set may not enable an effective fine-tuning process, so we propose a new approach to optimise this image selection process. Our approach involves a new scoring function to find informative unlabelled target images. In particular, we propose to measure the consistency in the model predictions on target images against specific data augmentations. However, we observe that the model trained with source datasets does not reliably evaluate consistency on target images. To alleviate this problem, we propose novel self-supervised pretext tasks to compute the scores of unlabelled target images. Finally, the top few images with the least consistency scores are added to the support set for oracle (i.e., expert) annotation and later used to fine-tune the model to the target images. In our evaluations that involve the segmentation of five different types of cell images, we demonstrate promising results on several target test sets compared to the random selection approach as well as other selection approaches, such as Shannon's entropy and Monte-Carlo dropout.
Edit-A-Video: Single Video Editing with Object-Aware Consistency
Mar 23, 2023
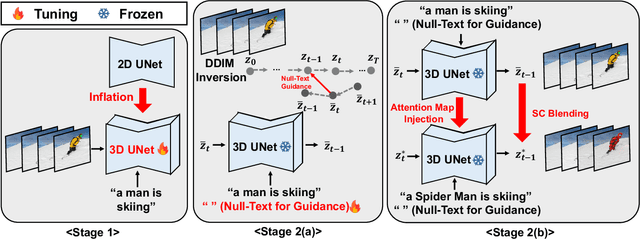
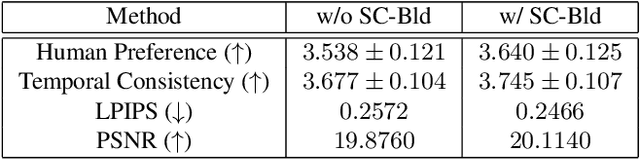

Despite the fact that text-to-video (TTV) model has recently achieved remarkable success, there have been few approaches on TTV for its extension to video editing. Motivated by approaches on TTV models adapting from diffusion-based text-to-image (TTI) models, we suggest the video editing framework given only a pretrained TTI model and a single <text, video> pair, which we term Edit-A-Video. The framework consists of two stages: (1) inflating the 2D model into the 3D model by appending temporal modules and tuning on the source video (2) inverting the source video into the noise and editing with target text prompt and attention map injection. Each stage enables the temporal modeling and preservation of semantic attributes of the source video. One of the key challenges for video editing include a background inconsistency problem, where the regions not included for the edit suffer from undesirable and inconsistent temporal alterations. To mitigate this issue, we also introduce a novel mask blending method, termed as sparse-causal blending (SC Blending). We improve previous mask blending methods to reflect the temporal consistency so that the area where the editing is applied exhibits smooth transition while also achieving spatio-temporal consistency of the unedited regions. We present extensive experimental results over various types of text and videos, and demonstrate the superiority of the proposed method compared to baselines in terms of background consistency, text alignment, and video editing quality.
ReVersion: Diffusion-Based Relation Inversion from Images
Mar 23, 2023
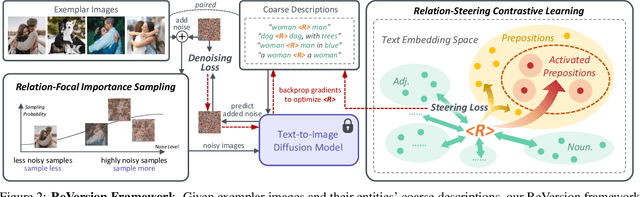
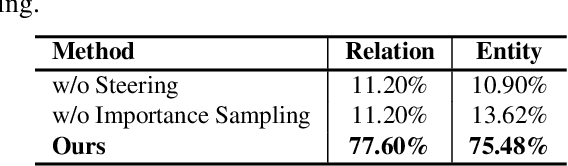
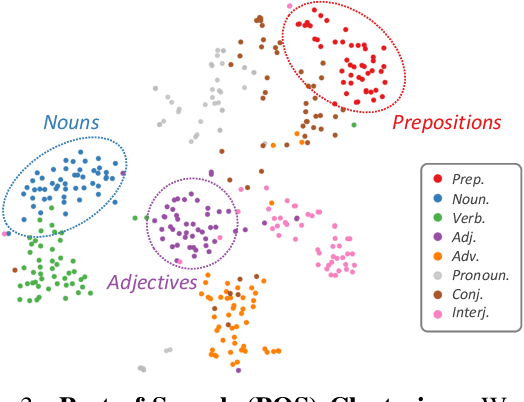
Diffusion models gain increasing popularity for their generative capabilities. Recently, there have been surging needs to generate customized images by inverting diffusion models from exemplar images. However, existing inversion methods mainly focus on capturing object appearances. How to invert object relations, another important pillar in the visual world, remains unexplored. In this work, we propose ReVersion for the Relation Inversion task, which aims to learn a specific relation (represented as "relation prompt") from exemplar images. Specifically, we learn a relation prompt from a frozen pre-trained text-to-image diffusion model. The learned relation prompt can then be applied to generate relation-specific images with new objects, backgrounds, and styles. Our key insight is the "preposition prior" - real-world relation prompts can be sparsely activated upon a set of basis prepositional words. Specifically, we propose a novel relation-steering contrastive learning scheme to impose two critical properties of the relation prompt: 1) The relation prompt should capture the interaction between objects, enforced by the preposition prior. 2) The relation prompt should be disentangled away from object appearances. We further devise relation-focal importance sampling to emphasize high-level interactions over low-level appearances (e.g., texture, color). To comprehensively evaluate this new task, we contribute ReVersion Benchmark, which provides various exemplar images with diverse relations. Extensive experiments validate the superiority of our approach over existing methods across a wide range of visual relations.