 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TWINS: A Fine-Tuning Framework for Improved Transferability of Adversarial Robustness and Generalization
Mar 20, 2023
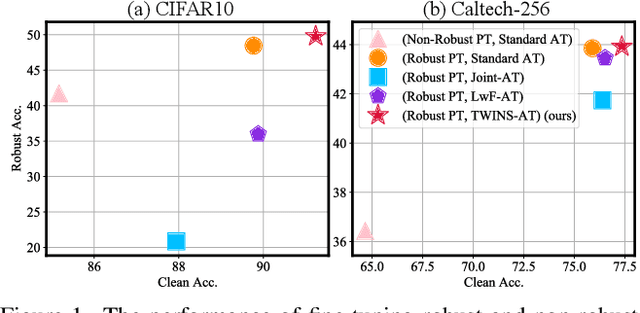
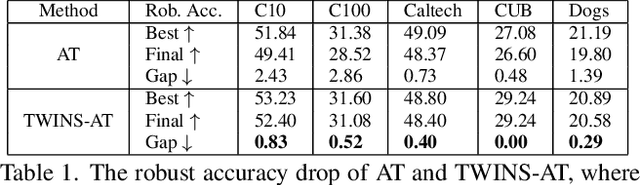
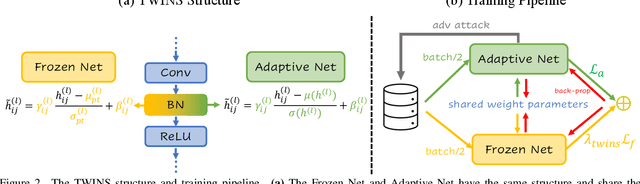
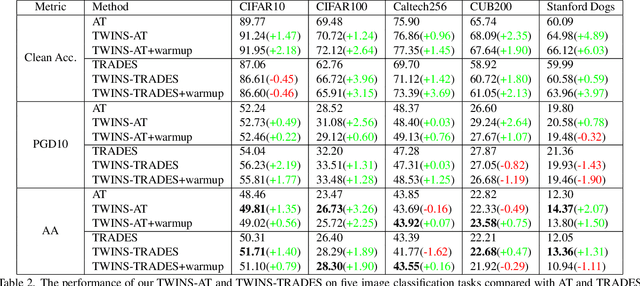
Recent years have seen the ever-increasing importance of pre-trained models and their downstream training in deep learning research and applications. At the same time, the defense for adversarial examples has been mainly investigated in the context of training from random initialization on simple classification tasks. To better exploit the potential of pre-trained models in adversarial robustness, this paper focuses on the fine-tuning of an adversarially pre-trained model in various classification tasks. Existing research has shown that since the robust pre-trained model has already learned a robust feature extractor, the crucial question is how to maintain the robustness in the pre-trained model when learning the downstream task. We study the model-based and data-based approaches for this goal and find that the two common approaches cannot achieve the objective of improving both generalization and adversarial robustness. Thus, we propose a novel statistics-based approach, Two-WIng NormliSation (TWINS) fine-tuning framework, which consists of two neural networks where one of them keeps the population means and variances of pre-training data in the batch normalization layers. Besides the robust information transfer, TWINS increases the effective learning rate without hurting the training stability since the relationship between a weight norm and its gradient norm in standard batch normalization layer is broken, resulting in a faster escape from the sub-optimal initialization and alleviating the robust overfitting. Finally, TWINS is shown to be effective on a wide range of image classification datasets in terms of both generalization and robustness. Our code is available at https://github.com/ziquanliu/CVPR2023-TWINS.
Automated Ensemble Search Framework for Semantic Segmentation Using Medical Imaging Labels
Mar 14, 2023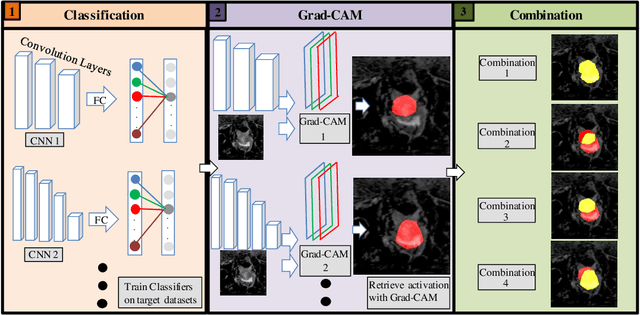
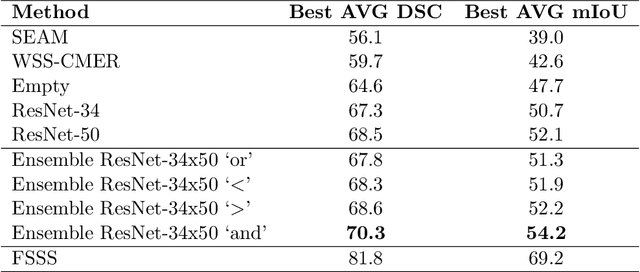
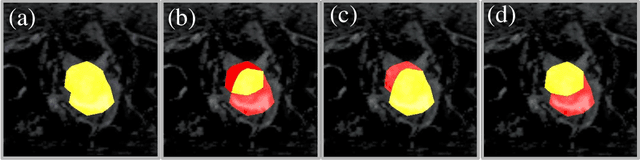
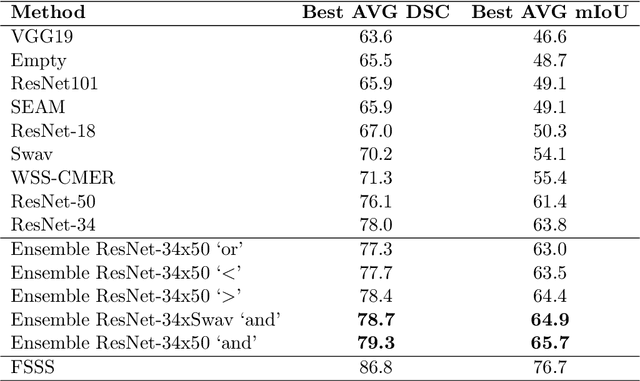
Reliable classification and detection of certain medical conditions, in images, with state-of-the-art semantic segmentation networks, require vast amounts of pixel-wise annotation. However, the public availability of such datasets is minimal. Therefore, semantic segmentation with image-level labels presents a promising alternative to this problem. Nevertheless, very few works have focused on evaluating this technique and its applicability to the medical sector. Due to their complexity and the small number of training examples in medical datasets, classifier-based weakly supervised networks like class activation maps (CAMs) struggle to extract useful information from them. However, most state-of-the-art approaches rely on them to achieve their improvements. Therefore, we propose a framework that can still utilize the low-quality CAM predictions of complicated datasets to improve the accuracy of our results. Our framework achieves that by first utilizing lower threshold CAMs to cover the target object with high certainty; second, by combining multiple low-threshold CAMs that even out their errors while highlighting the target object. We performed exhaustive experiments on the popular multi-modal BRATS and prostate DECATHLON segmentation challenge datasets. Using the proposed framework, we have demonstrated an improved dice score of up to 8% on BRATS and 6% on DECATHLON datasets compared to the previous state-of-the-art.
Precise Facial Landmark Detection by Reference Heatmap Transformer
Mar 14, 2023
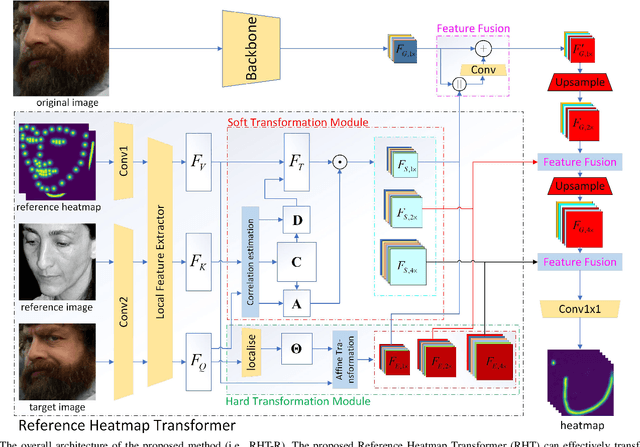
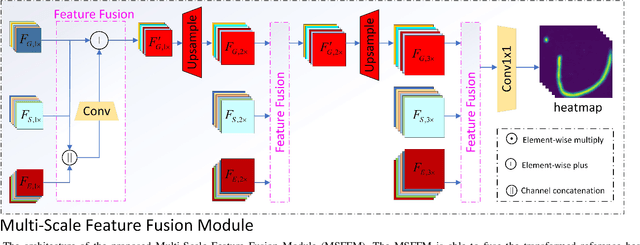

Most facial landmark detection methods predict landmarks by mapping the input facial appearance features to landmark heatmaps and have achieved promising results. However, when the face image is suffering from large poses, heavy occlusions and complicated illuminations, they cannot learn discriminative feature representations and effective facial shape constraints, nor can they accurately predict the value of each element in the landmark heatmap, limiting their detection accuracy. To address this problem, we propose a novel Reference Heatmap Transformer (RHT) by introducing reference heatmap information for more precise facial landmark detection. The proposed RHT consists of a Soft Transformation Module (STM) and a Hard Transformation Module (HTM), which can cooperate with each other to encourage the accurate transformation of the reference heatmap information and facial shape constraints. Then, a Multi-Scale Feature Fusion Module (MSFFM) is proposed to fuse the transformed heatmap features and the semantic features learned from the original face images to enhance feature representations for producing more accurate target heatmaps. To the best of our knowledge, this is the first study to explore how to enhance facial landmark detection by transforming the reference heatmap information. The experimental results from challenging benchmark datasets demonstrate that our proposed method outperforms the state-of-the-art methods in the literature.
Toward a Geometric Theory of Manifold Untangling
Mar 07, 2023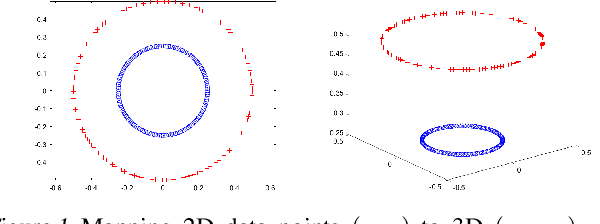


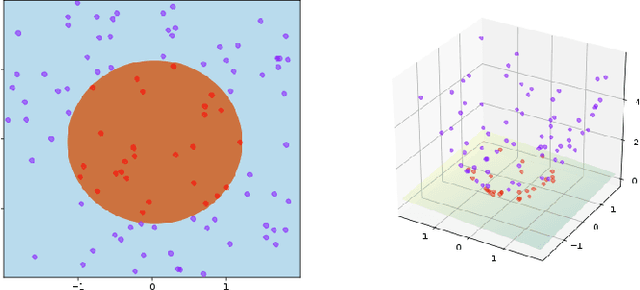
It has been hypothesized that the ventral stream processing for object recognition is based on a mechanism called cortically local subspace untangling. A mathematical abstraction of object recognition by the visual cortex is how to untangle the manifolds associated with different object category. Such a manifold untangling problem is closely related to the celebrated kernel trick in metric space. In this paper, we conjecture that there is a more general solution to manifold untangling in the topological space without artificially defining any distance metric. Geometrically, we can either $embed$ a manifold in a higher dimensional space to promote selectivity or $flatten$ a manifold to promote tolerance. General strategies of both global manifold embedding and local manifold flattening are presented and connected with existing work on the untangling of image, audio, and language data. We also discuss the implications of untangling the manifold into motor control and internal representations.
ShiftDDPMs: Exploring Conditional Diffusion Models by Shifting Diffusion Trajectories
Feb 18, 2023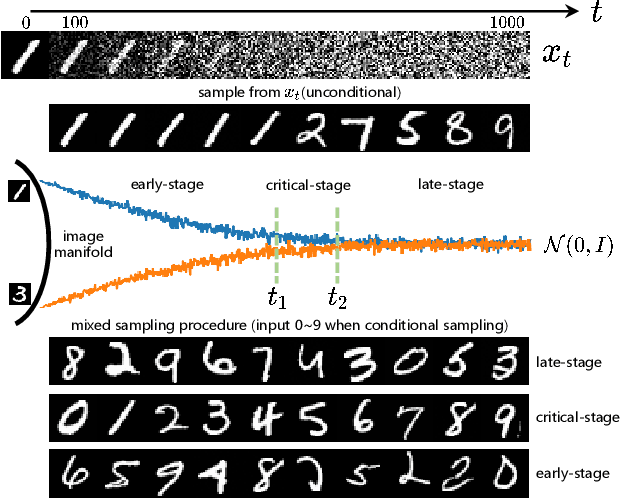
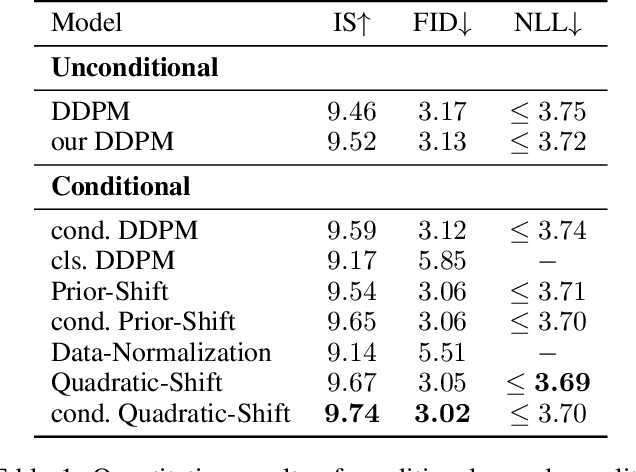
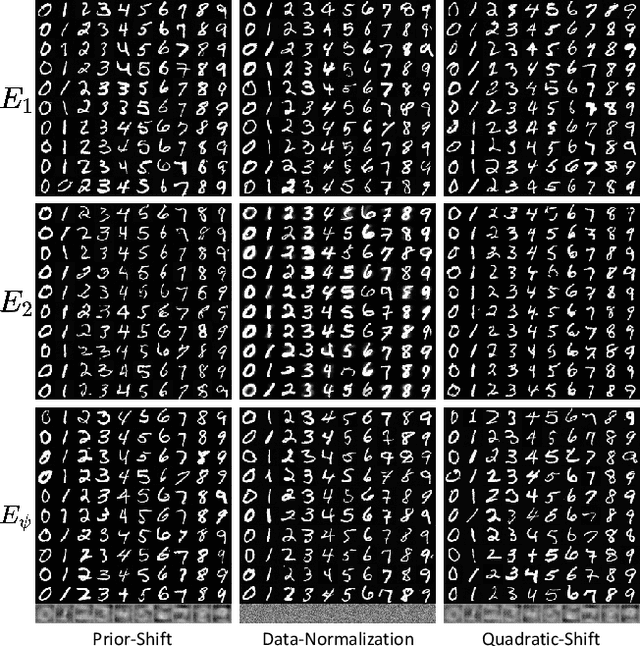
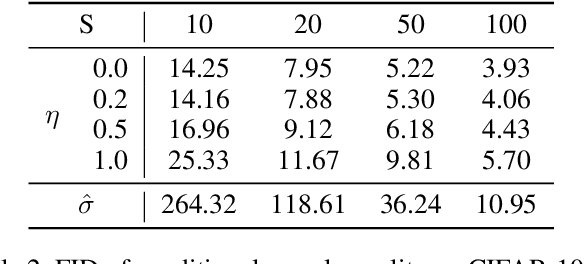
Diffusion models have recently exhibited remarkable abilities to synthesize striking image samples since the introduction of denoising diffusion probabilistic models (DDPMs). Their key idea is to disrupt images into noise through a fixed forward process and learn its reverse process to generate samples from noise in a denoising way. For conditional DDPMs, most existing practices relate conditions only to the reverse process and fit it to the reversal of unconditional forward process. We find this will limit the condition modeling and generation in a small time window. In this paper, we propose a novel and flexible conditional diffusion model by introducing conditions into the forward process. We utilize extra latent space to allocate an exclusive diffusion trajectory for each condition based on some shifting rules, which will disperse condition modeling to all timesteps and improve the learning capacity of model. We formulate our method, which we call \textbf{ShiftDDPMs}, and provide a unified point of view on existing related methods. Extensive qualitative and quantitative experiments on image synthesis demonstrate the feasibility and effectiveness of ShiftDDPMs.
Redes Generativas Adversarias (GAN) Fundamentos Teóricos y Aplicaciones
Feb 18, 2023Generative adversarial networks (GANs) are a method based on the training of two neural networks, one called generator and the other discriminator, competing with each other to generate new instances that resemble those of the probability distribution of the training data. GANs have a wide range of applications in fields such as computer vision, semantic segmentation, time series synthesis, image editing, natural language processing, and image generation from text, among others. Generative models model the probability distribution of a data set, but instead of providing a probability value, they generate new instances that are close to the original distribution. GANs use a learning scheme that allows the defining attributes of the probability distribution to be encoded in a neural network, allowing instances to be generated that resemble the original probability distribution. This article presents the theoretical foundations of this type of network as well as the basic architecture schemes and some of its applications. This article is in Spanish to facilitate the arrival of this scientific knowledge to the Spanish-speaking community.
Learning advisor networks for noisy image classification
Nov 08, 2022In this paper, we introduced the novel concept of advisor network to address the problem of noisy labels in image classification. Deep neural networks (DNN) are prone to performance reduction and overfitting problems on training data with noisy annotations. Weighting loss methods aim to mitigate the influence of noisy labels during the training, completely removing their contribution. This discarding process prevents DNNs from learning wrong associations between images and their correct labels but reduces the amount of data used, especially when most of the samples have noisy labels. Differently, our method weighs the feature extracted directly from the classifier without altering the loss value of each data. The advisor helps to focus only on some part of the information present in mislabeled examples, allowing the classifier to leverage that data as well. We trained it with a meta-learning strategy so that it can adapt throughout the training of the main model. We tested our method on CIFAR10 and CIFAR100 with synthetic noise, and on Clothing1M which contains real-world noise, reporting state-of-the-art results.
* Paper published as Poster at ICIAP21
TEXTure: Text-Guided Texturing of 3D Shapes
Feb 03, 2023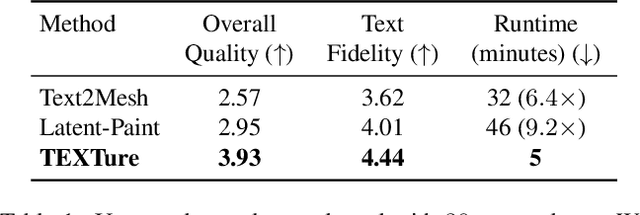


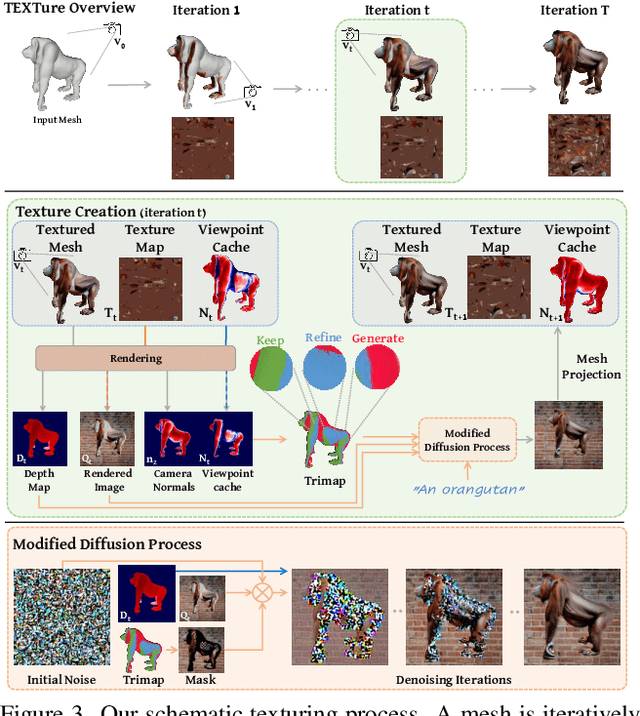
In this paper, we present TEXTure, a novel method for text-guided generation, editing, and transfer of textures for 3D shapes. Leveraging a pretrained depth-to-image diffusion model, TEXTure applies an iterative scheme that paints a 3D model from different viewpoints. Yet, while depth-to-image models can create plausible textures from a single viewpoint, the stochastic nature of the generation process can cause many inconsistencies when texturing an entire 3D object. To tackle these problems, we dynamically define a trimap partitioning of the rendered image into three progression states, and present a novel elaborated diffusion sampling process that uses this trimap representation to generate seamless textures from different views. We then show that one can transfer the generated texture maps to new 3D geometries without requiring explicit surface-to-surface mapping, as well as extract semantic textures from a set of images without requiring any explicit reconstruction. Finally, we show that TEXTure can be used to not only generate new textures but also edit and refine existing textures using either a text prompt or user-provided scribbles. We demonstrate that our TEXTuring method excels at generating, transferring, and editing textures through extensive evaluation, and further close the gap between 2D image generation and 3D texturing.
MorDIFF: Recognition Vulnerability and Attack Detectability of Face Morphing Attacks Created by Diffusion Autoencoders
Feb 03, 2023


Investigating new methods of creating face morphing attacks is essential to foresee novel attacks and help mitigate them. Creating morphing attacks is commonly either performed on the image-level or on the representation-level. The representation-level morphing has been performed so far based on generative adversarial networks (GAN) where the encoded images are interpolated in the latent space to produce a morphed image based on the interpolated vector. Such a process was constrained by the limited reconstruction fidelity of GAN architectures. Recent advances in the diffusion autoencoder models have overcome the GAN limitations, leading to high reconstruction fidelity. This theoretically makes them a perfect candidate to perform representation-level face morphing. This work investigates using diffusion autoencoders to create face morphing attacks by comparing them to a wide range of image-level and representation-level morphs. Our vulnerability analyses on four state-of-the-art face recognition models have shown that such models are highly vulnerable to the created attacks, the MorDIFF, especially when compared to existing representation-level morphs. Detailed detectability analyses are also performed on the MorDIFF, showing that they are as challenging to detect as other morphing attacks created on the image- or representation-level. Data and morphing script are made public.
Variational multichannel multiclass segmentation\endgraf using unsupervised lifting with CNNs
Feb 04, 2023


We propose an unsupervised image segmentation approach, that combines a variational energy functional and deep convolutional neural networks. The variational part is based on a recent multichannel multiphase Chan-Vese model, which is capable to extract useful information from multiple input images simultaneously. We implement a flexible multiclass segmentation method that divides a given image into $K$ different regions. We use convolutional neural networks (CNNs) targeting a pre-decomposition of the image. By subsequently minimising the segmentation functional, the final segmentation is obtained in a fully unsupervised manner. Special emphasis is given to the extraction of informative feature maps serving as a starting point for the segmentation. The initial results indicate that the proposed method is able to decompose and segment the different regions of various types of images, such as texture and medical images and compare its performance with another multiphase segmentation method.