 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models
Mar 19, 2023
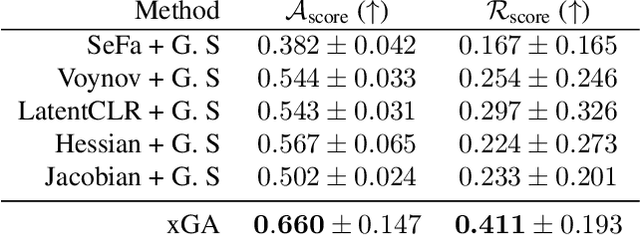
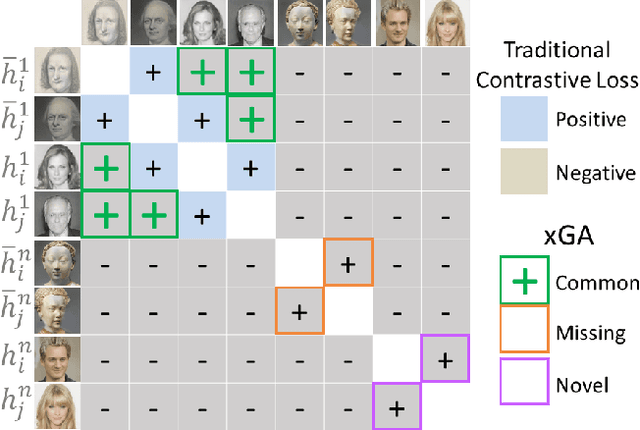
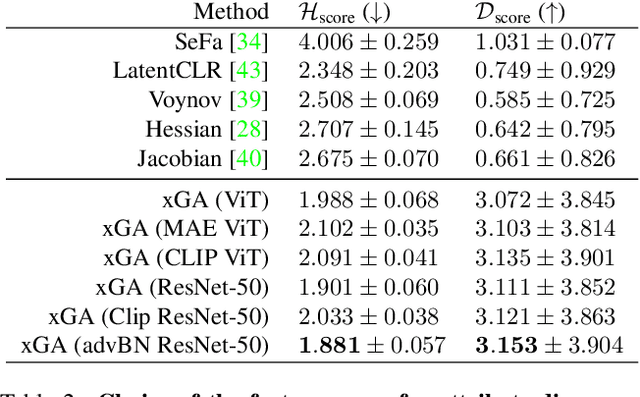
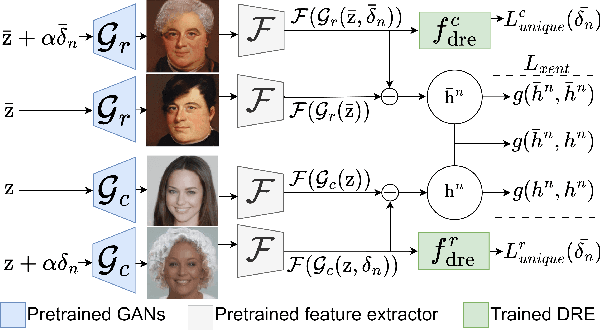
Generative Adversarial Networks (GANs) are notoriously difficult to train especially for complex distributions and with limited data. This has driven the need for tools to audit trained networks in human intelligible format, for example, to identify biases or ensure fairness. Existing GAN audit tools are restricted to coarse-grained, model-data comparisons based on summary statistics such as FID or recall. In this paper, we propose an alternative approach that compares a newly developed GAN against a prior baseline. To this end, we introduce Cross-GAN Auditing (xGA) that, given an established "reference" GAN and a newly proposed "client" GAN, jointly identifies intelligible attributes that are either common across both GANs, novel to the client GAN, or missing from the client GAN. This provides both users and model developers an intuitive assessment of similarity and differences between GANs. We introduce novel metrics to evaluate attribute-based GAN auditing approaches and use these metrics to demonstrate quantitatively that xGA outperforms baseline approaches. We also include qualitative results that illustrate the common, novel and missing attributes identified by xGA from GANs trained on a variety of image datasets.
Learning to Super-Resolve Blurry Images with Events
Feb 27, 2023
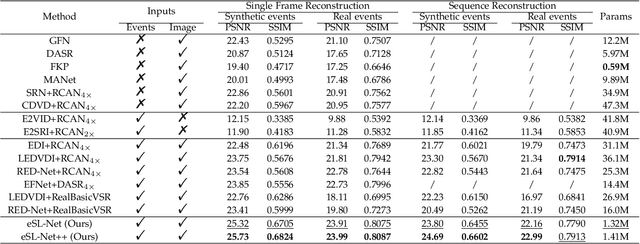
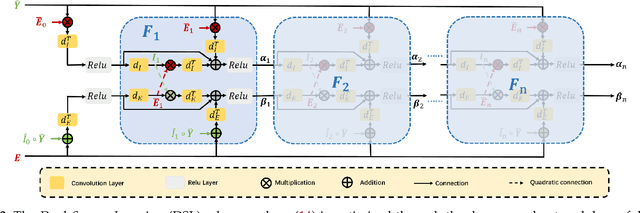
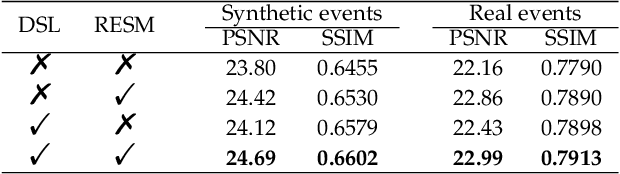
Super-Resolution from a single motion Blurred image (SRB) is a severely ill-posed problem due to the joint degradation of motion blurs and low spatial resolution. In this paper, we employ events to alleviate the burden of SRB and propose an Event-enhanced SRB (E-SRB) algorithm, which can generate a sequence of sharp and clear images with High Resolution (HR) from a single blurry image with Low Resolution (LR). To achieve this end, we formulate an event-enhanced degeneration model to consider the low spatial resolution, motion blurs, and event noises simultaneously. We then build an event-enhanced Sparse Learning Network (eSL-Net++) upon a dual sparse learning scheme where both events and intensity frames are modeled with sparse representations. Furthermore, we propose an event shuffle-and-merge scheme to extend the single-frame SRB to the sequence-frame SRB without any additional training process. Experimental results on synthetic and real-world datasets show that the proposed eSL-Net++ outperforms state-of-the-art methods by a large margin. Datasets, codes, and more results are available at https://github.com/ShinyWang33/eSL-Net-Plusplus.
DiffusionSeg: Adapting Diffusion Towards Unsupervised Object Discovery
Mar 17, 2023
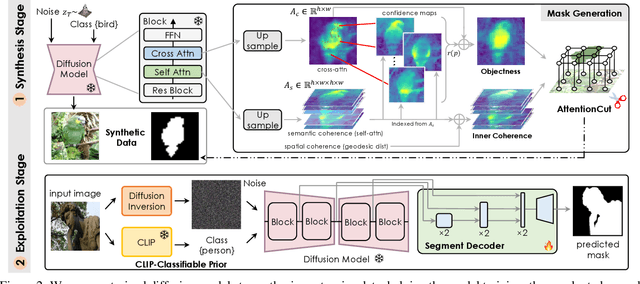

Learning from a large corpus of data, pre-trained models have achieved impressive progress nowadays. As popular generative pre-training, diffusion models capture both low-level visual knowledge and high-level semantic relations. In this paper, we propose to exploit such knowledgeable diffusion models for mainstream discriminative tasks, i.e., unsupervised object discovery: saliency segmentation and object localization. However, the challenges exist as there is one structural difference between generative and discriminative models, which limits the direct use. Besides, the lack of explicitly labeled data significantly limits performance in unsupervised settings. To tackle these issues, we introduce DiffusionSeg, one novel synthesis-exploitation framework containing two-stage strategies. To alleviate data insufficiency, we synthesize abundant images, and propose a novel training-free AttentionCut to obtain masks in the first synthesis stage. In the second exploitation stage, to bridge the structural gap, we use the inversion technique, to map the given image back to diffusion features. These features can be directly used by downstream architectures. Extensive experiments and ablation studies demonstrate the superiority of adapting diffusion for unsupervised object discovery.
CoDEPS: Online Continual Learning for Depth Estimation and Panoptic Segmentation
Mar 17, 2023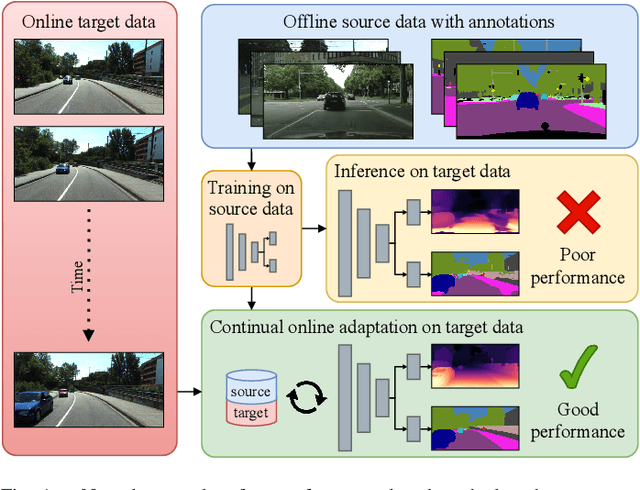
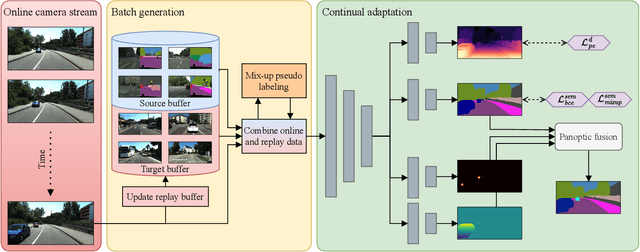
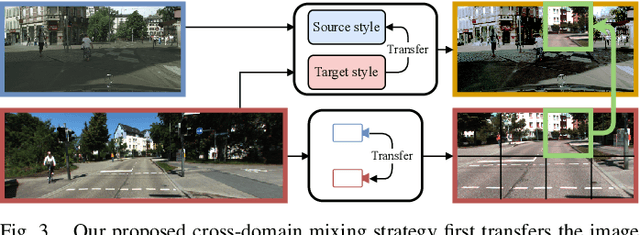
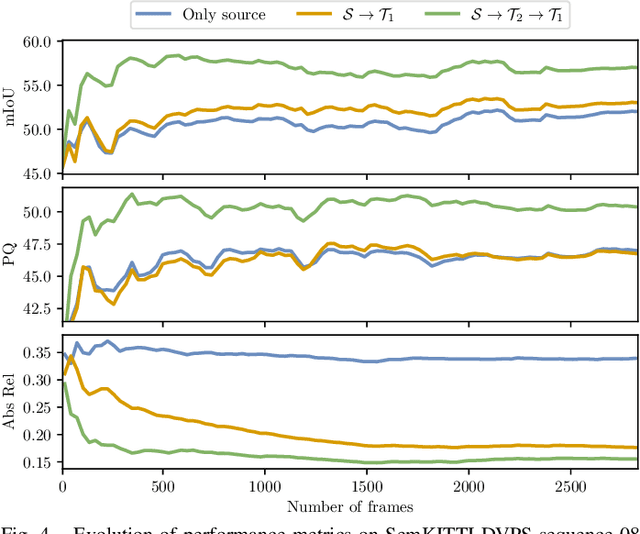
Operating a robot in the open world requires a high level of robustness with respect to previously unseen environments. Optimally, the robot is able to adapt by itself to new conditions without human supervision, e.g., automatically adjusting its perception system to changing lighting conditions. In this work, we address the task of continual learning for deep learning-based monocular depth estimation and panoptic segmentation in new environments in an online manner. We introduce CoDEPS to perform continual learning involving multiple real-world domains while mitigating catastrophic forgetting by leveraging experience replay. In particular, we propose a novel domain-mixing strategy to generate pseudo-labels to adapt panoptic segmentation. Furthermore, we explicitly address the limited storage capacity of robotic systems by proposing sampling strategies for constructing a fixed-size replay buffer based on rare semantic class sampling and image diversity. We perform extensive evaluations of CoDEPS on various real-world datasets demonstrating that it successfully adapts to unseen environments without sacrificing performance on previous domains while achieving state-of-the-art results. The code of our work is publicly available at http://codeps.cs.uni-freiburg.de.
GNNFormer: A Graph-based Framework for Cytopathology Report Generation
Mar 17, 2023
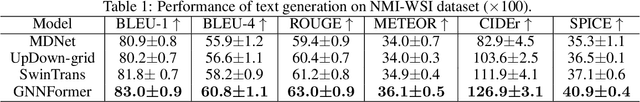
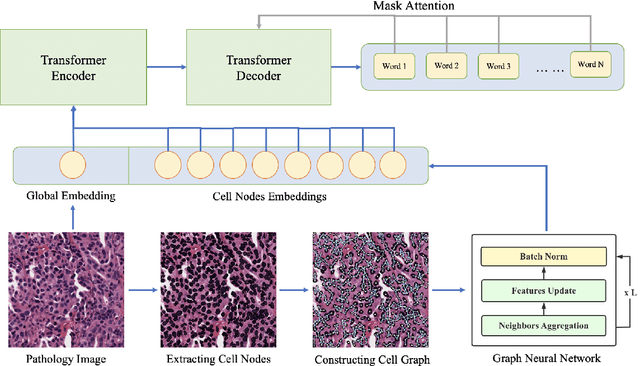
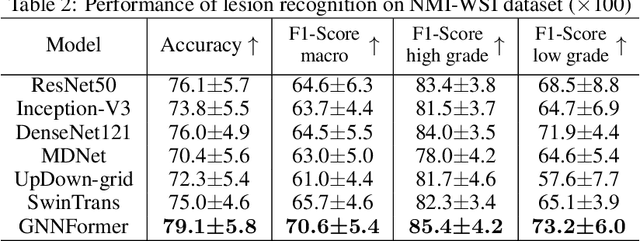
Cytopathology report generation is a necessary step for the standardized examination of pathology images. However, manually writing detailed reports brings heavy workloads for pathologists. To improve efficiency, some existing works have studied automatic generation of cytopathology reports, mainly by applying image caption generation frameworks with visual encoders originally proposed for natural images. A common weakness of these works is that they do not explicitly model the structural information among cells, which is a key feature of pathology images and provides significant information for making diagnoses. In this paper, we propose a novel graph-based framework called GNNFormer, which seamlessly integrates graph neural network (GNN) and Transformer into the same framework, for cytopathology report generation. To the best of our knowledge, GNNFormer is the first report generation method that explicitly models the structural information among cells in pathology images. It also effectively fuses structural information among cells, fine-grained morphology features of cells and background features to generate high-quality reports. Experimental results on the NMI-WSI dataset show that GNNFormer can outperform other state-of-the-art baselines.
CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
Mar 17, 2023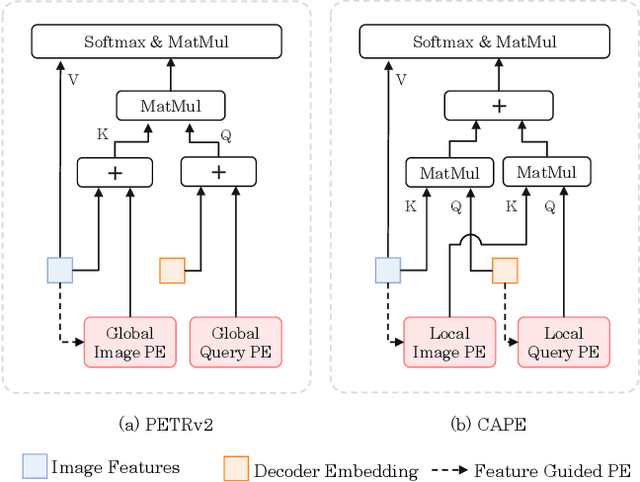
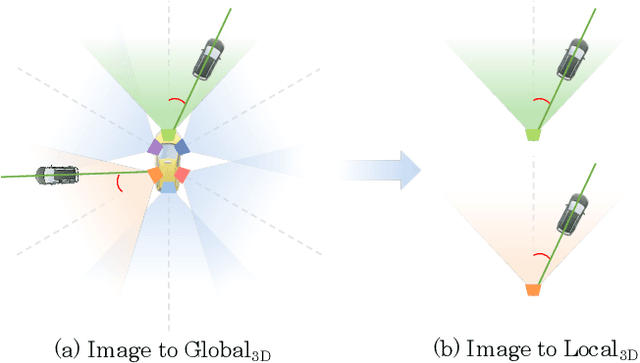
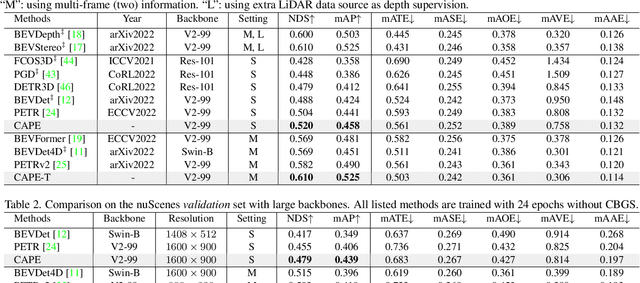
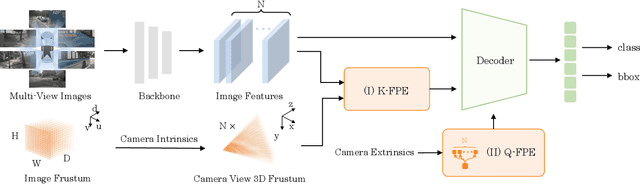
In this paper, we address the problem of detecting 3D objects from multi-view images. Current query-based methods rely on global 3D position embeddings (PE) to learn the geometric correspondence between images and 3D space. We claim that directly interacting 2D image features with global 3D PE could increase the difficulty of learning view transformation due to the variation of camera extrinsics. Thus we propose a novel method based on CAmera view Position Embedding, called CAPE. We form the 3D position embeddings under the local camera-view coordinate system instead of the global coordinate system, such that 3D position embedding is free of encoding camera extrinsic parameters. Furthermore, we extend our CAPE to temporal modeling by exploiting the object queries of previous frames and encoding the ego-motion for boosting 3D object detection. CAPE achieves state-of-the-art performance (61.0% NDS and 52.5% mAP) among all LiDAR-free methods on nuScenes dataset. Codes and models are available on \href{https://github.com/PaddlePaddle/Paddle3D}{Paddle3D} and \href{https://github.com/kaixinbear/CAPE}{PyTorch Implementation}.
A deep learning approach for patchless estimation of ultrasound quantitative parametric image with uncertainty measurement
Feb 24, 2023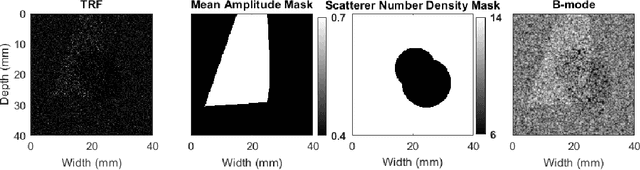

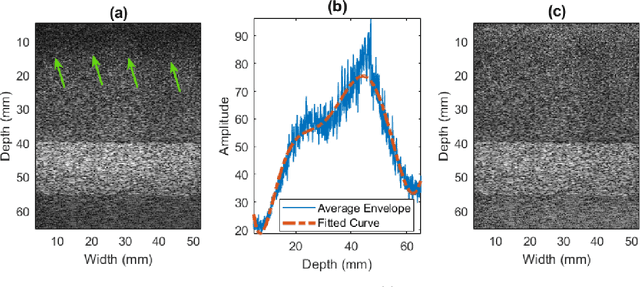
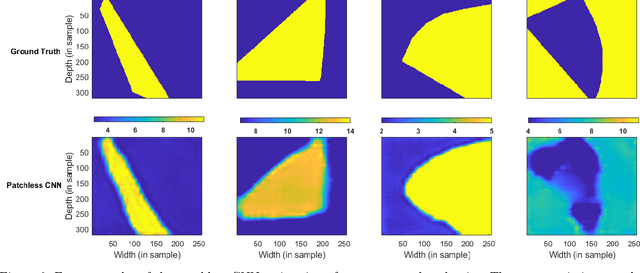
Quantitative ultrasound (QUS) aims to find properties of scatterers which are related to the tissue microstructure. Among different QUS parameters, scatterer number density has been found to be a reliable biomarker for detecting different abnormalities. The homodyned K-distribution (HK-distribution) is a model for the probability density function of the ultrasound echo amplitude that can model different scattering scenarios but requires a large number of samples to be estimated reliably. Parametric images of HK-distribution parameters can be formed by dividing the envelope data into small overlapping patches and estimating parameters within the patches independently. This approach imposes two limiting constraints, the HK-distribution parameters are assumed to be constant within each patch, and each patch requires enough independent samples. In order to mitigate those problems, we employ a deep learning approach to estimate parametric images of scatterer number density (related to HK-distribution shape parameter) without patching. Furthermore, an uncertainty map of the network's prediction is quantified to provide insight about the confidence of the network about the estimated HK parameter values.
UKnow: A Unified Knowledge Protocol for Common-Sense Reasoning and Vision-Language Pre-training
Feb 14, 2023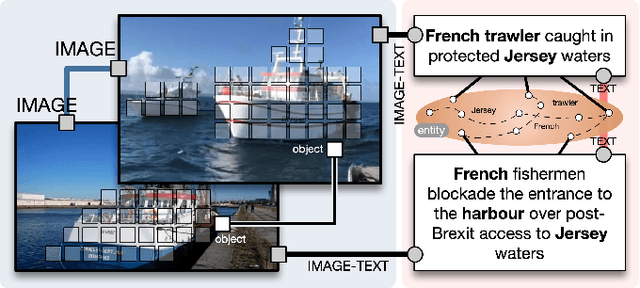
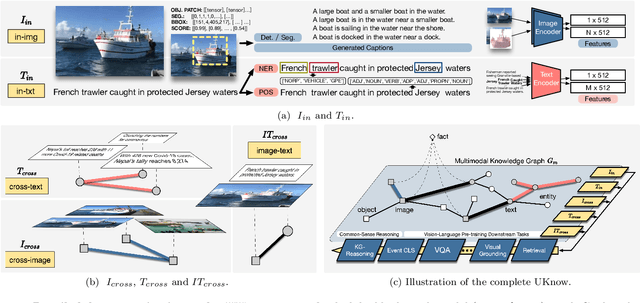
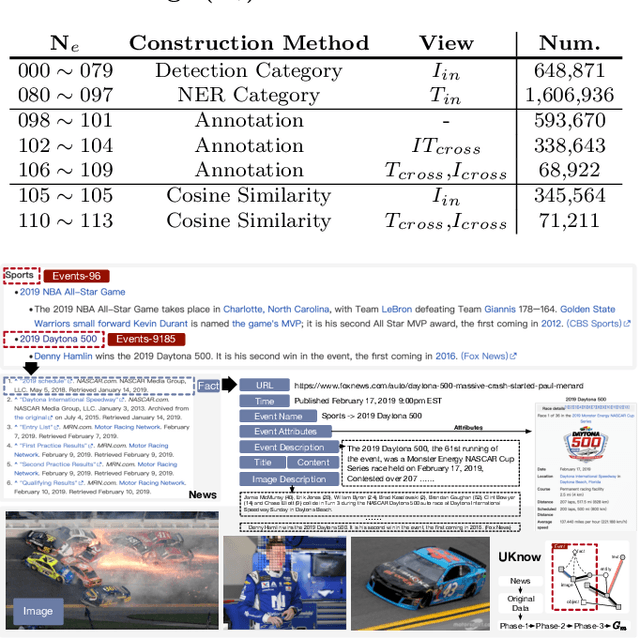
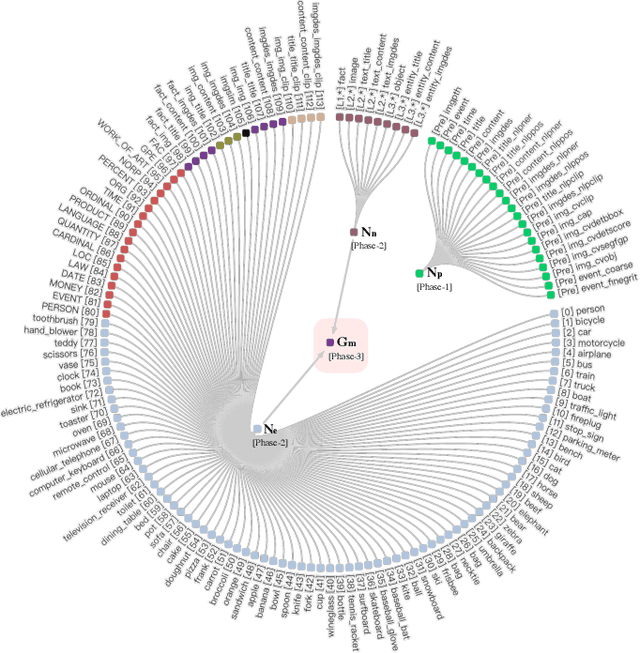
This work presents a unified knowledge protocol, called UKnow, which facilitates knowledge-based studies from the perspective of data. Particularly focusing on visual and linguistic modalities, we categorize data knowledge into five unit types, namely, in-image, in-text, cross-image, cross-text, and image-text. Following this protocol, we collect, from public international news, a large-scale multimodal knowledge graph dataset that consists of 1,388,568 nodes (with 571,791 vision-related ones) and 3,673,817 triplets. The dataset is also annotated with rich event tags, including 96 coarse labels and 9,185 fine labels, expanding its potential usage. To further verify that UKnow can serve as a standard protocol, we set up an efficient pipeline to help reorganize existing datasets under UKnow format. Finally, we benchmark the performance of some widely-used baselines on the tasks of common-sense reasoning and vision-language pre-training. Results on both our new dataset and the reformatted public datasets demonstrate the effectiveness of UKnow in knowledge organization and method evaluation. Code, dataset, conversion tool, and baseline models will be made public.
Guided Depth Map Super-resolution: A Survey
Feb 19, 2023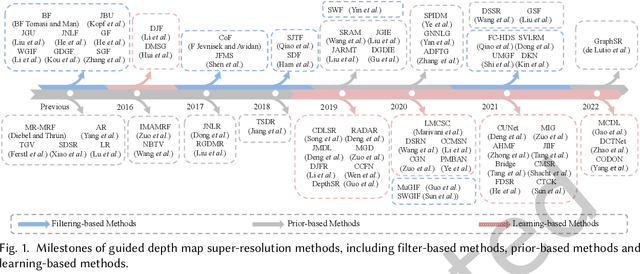

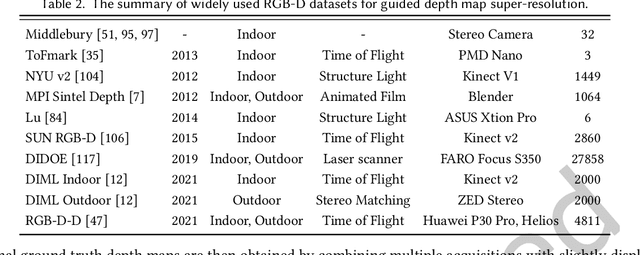
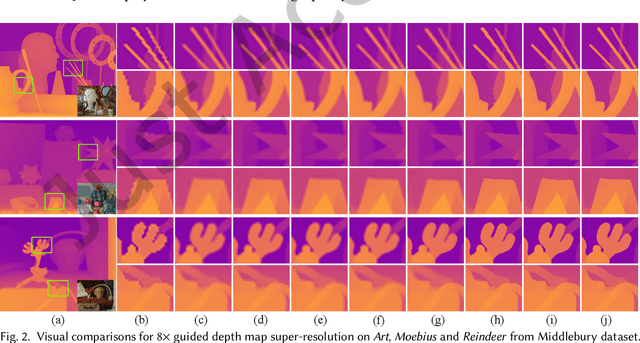
Guided depth map super-resolution (GDSR), which aims to reconstruct a high-resolution (HR) depth map from a low-resolution (LR) observation with the help of a paired HR color image, is a longstanding and fundamental problem, it has attracted considerable attention from computer vision and image processing communities. A myriad of novel and effective approaches have been proposed recently, especially with powerful deep learning techniques. This survey is an effort to present a comprehensive survey of recent progress in GDSR. We start by summarizing the problem of GDSR and explaining why it is challenging. Next, we introduce some commonly used datasets and image quality assessment methods. In addition, we roughly classify existing GDSR methods into three categories, i.e., filtering-based methods, prior-based methods, and learning-based methods. In each category, we introduce the general description of the published algorithms and design principles, summarize the representative methods, and discuss their highlights and limitations. Moreover, the depth related applications are introduced. Furthermore, we conduct experiments to evaluate the performance of some representative methods based on unified experimental configurations, so as to offer a systematic and fair performance evaluation to readers. Finally, we conclude this survey with possible directions and open problems for further research. All the related materials can be found at \url{https://github.com/zhwzhong/Guided-Depth-Map-Super-resolution-A-Survey}.
Visual Watermark Removal Based on Deep Learning
Feb 07, 2023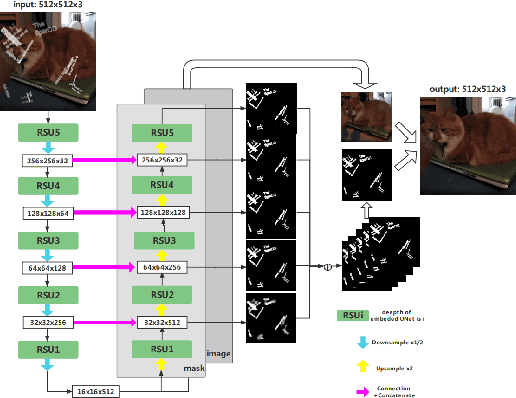
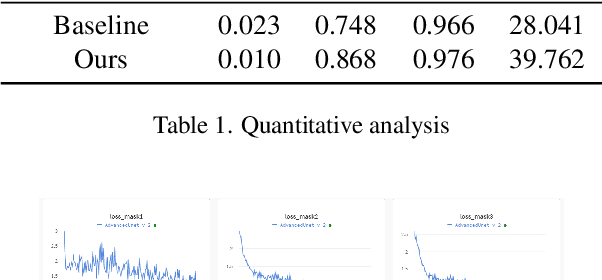
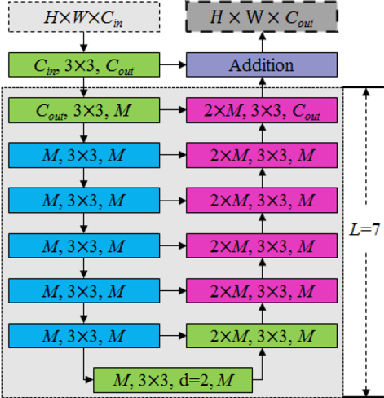
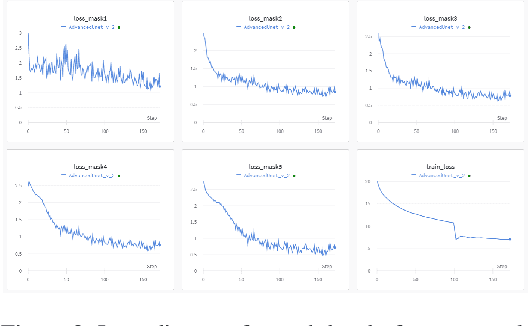
In recent years as the internet age continues to grow, sharing images on social media has become a common occurrence. In certain cases, watermarks are used as protection for the ownership of the image, however, in more cases, one may wish to remove these watermark images to get the original image without obscuring. In this work, we proposed a deep learning method based technique for visual watermark removal. Inspired by the strong image translation performance of the U-structure, an end-to-end deep neural network model named AdvancedUnet is proposed to extract and remove the visual watermark simultaneously. On the other hand, we embed some effective RSU module instead of the common residual block used in UNet, which increases the depth of the whole architecture without significantly increasing the computational cost. The deep-supervised hybrid loss guides the network to learn the transformation between the input image and the ground truth in a multi-scale and three-level hierarchy. Comparison experiments demonstrate the effectiveness of our method.