 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-Spectral Remote Sensing Image Retrieval Using Geospatial Foundation Models
Mar 04, 2024
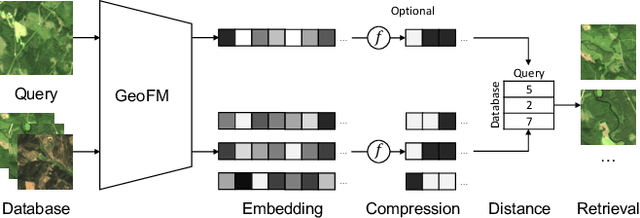
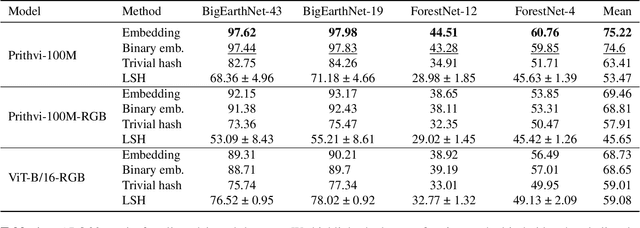
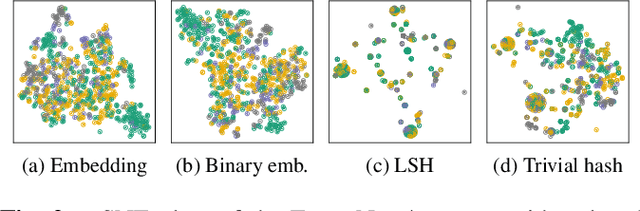

Image retrieval enables an efficient search through vast amounts of satellite imagery and returns similar images to a query. Deep learning models can identify images across various semantic concepts without the need for annotations. This work proposes to use Geospatial Foundation Models, like Prithvi, for remote sensing image retrieval with multiple benefits: i) the models encode multi-spectral satellite data and ii) generalize without further fine-tuning. We introduce two datasets to the retrieval task and observe a strong performance: Prithvi processes six bands and achieves a mean Average Precision of 97.62\% on BigEarthNet-43 and 44.51\% on ForestNet-12, outperforming other RGB-based models. Further, we evaluate three compression methods with binarized embeddings balancing retrieval speed and accuracy. They match the retrieval speed of much shorter hash codes while maintaining the same accuracy as floating-point embeddings but with a 32-fold compression. The code is available at https://github.com/IBM/remote-sensing-image-retrieval.
Zero-LED: Zero-Reference Lighting Estimation Diffusion Model for Low-Light Image Enhancement
Mar 05, 2024
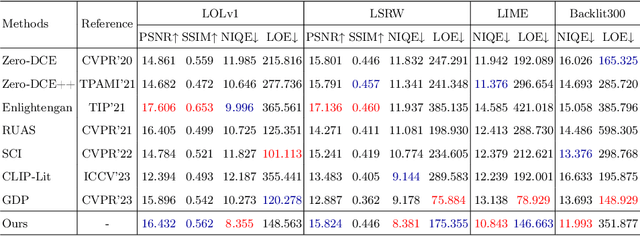
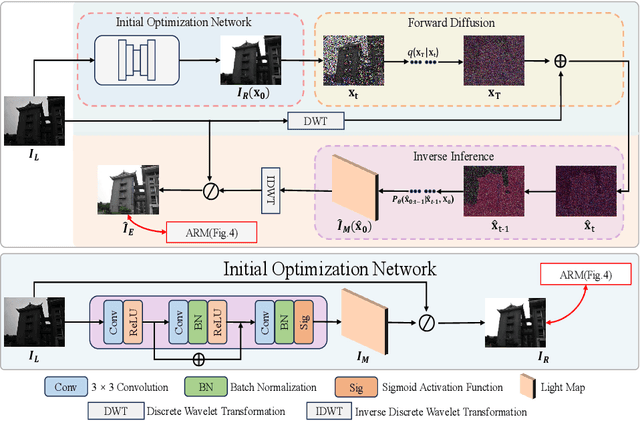
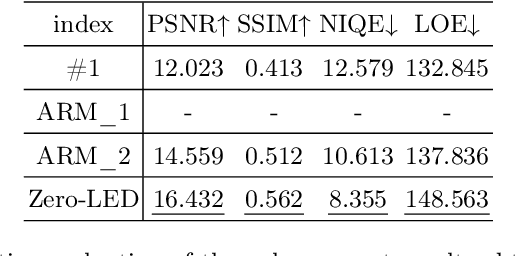
Diffusion model-based low-light image enhancement methods rely heavily on paired training data, leading to limited extensive application. Meanwhile, existing unsupervised methods lack effective bridging capabilities for unknown degradation. To address these limitations, we propose a novel zero-reference lighting estimation diffusion model for low-light image enhancement called Zero-LED. It utilizes the stable convergence ability of diffusion models to bridge the gap between low-light domains and real normal-light domains and successfully alleviates the dependence on pairwise training data via zero-reference learning. Specifically, we first design the initial optimization network to preprocess the input image and implement bidirectional constraints between the diffusion model and the initial optimization network through multiple objective functions. Subsequently, the degradation factors of the real-world scene are optimized iteratively to achieve effective light enhancement. In addition, we explore a frequency-domain based and semantically guided appearance reconstruction module that encourages feature alignment of the recovered image at a fine-grained level and satisfies subjective expectations. Finally, extensive experiments demonstrate the superiority of our approach to other state-of-the-art methods and more significant generalization capabilities. We will open the source code upon acceptance of the paper.
Visual Preference Inference: An Image Sequence-Based Preference Reasoning in Tabletop Object Manipulation
Mar 18, 2024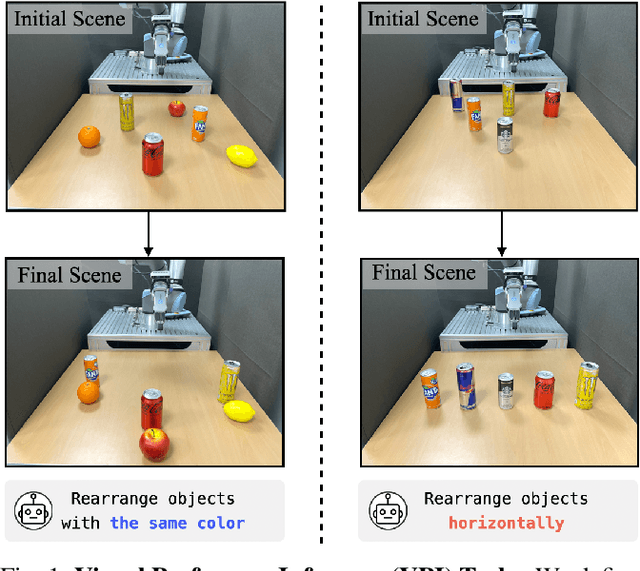
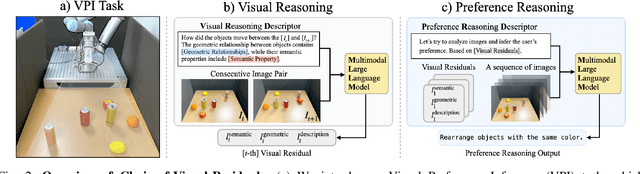

In robotic object manipulation, human preferences can often be influenced by the visual attributes of objects, such as color and shape. These properties play a crucial role in operating a robot to interact with objects and align with human intention. In this paper, we focus on the problem of inferring underlying human preferences from a sequence of raw visual observations in tabletop manipulation environments with a variety of object types, named Visual Preference Inference (VPI). To facilitate visual reasoning in the context of manipulation, we introduce the Chain-of-Visual-Residuals (CoVR) method. CoVR employs a prompting mechanism that describes the difference between the consecutive images (i.e., visual residuals) and incorporates such texts with a sequence of images to infer the user's preference. This approach significantly enhances the ability to understand and adapt to dynamic changes in its visual environment during manipulation tasks. Furthermore, we incorporate such texts along with a sequence of images to infer the user's preferences. Our method outperforms baseline methods in terms of extracting human preferences from visual sequences in both simulation and real-world environments. Code and videos are available at: \href{https://joonhyung-lee.github.io/vpi/}{https://joonhyung-lee.github.io/vpi/}
GeoWizard: Unleashing the Diffusion Priors for 3D Geometry Estimation from a Single Image
Mar 18, 2024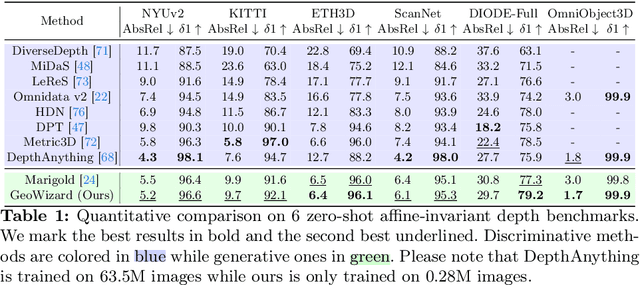
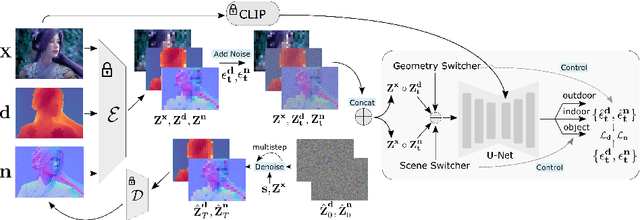

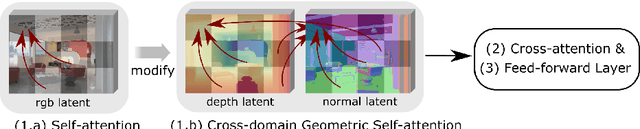
We introduce GeoWizard, a new generative foundation model designed for estimating geometric attributes, e.g., depth and normals, from single images. While significant research has already been conducted in this area, the progress has been substantially limited by the low diversity and poor quality of publicly available datasets. As a result, the prior works either are constrained to limited scenarios or suffer from the inability to capture geometric details. In this paper, we demonstrate that generative models, as opposed to traditional discriminative models (e.g., CNNs and Transformers), can effectively address the inherently ill-posed problem. We further show that leveraging diffusion priors can markedly improve generalization, detail preservation, and efficiency in resource usage. Specifically, we extend the original stable diffusion model to jointly predict depth and normal, allowing mutual information exchange and high consistency between the two representations. More importantly, we propose a simple yet effective strategy to segregate the complex data distribution of various scenes into distinct sub-distributions. This strategy enables our model to recognize different scene layouts, capturing 3D geometry with remarkable fidelity. GeoWizard sets new benchmarks for zero-shot depth and normal prediction, significantly enhancing many downstream applications such as 3D reconstruction, 2D content creation, and novel viewpoint synthesis.
Augmented Reality based Simulated Data (ARSim) with multi-view consistency for AV perception networks
Mar 22, 2024Detecting a diverse range of objects under various driving scenarios is essential for the effectiveness of autonomous driving systems. However, the real-world data collected often lacks the necessary diversity presenting a long-tail distribution. Although synthetic data has been utilized to overcome this issue by generating virtual scenes, it faces hurdles such as a significant domain gap and the substantial efforts required from 3D artists to create realistic environments. To overcome these challenges, we present ARSim, a fully automated, comprehensive, modular framework designed to enhance real multi-view image data with 3D synthetic objects of interest. The proposed method integrates domain adaptation and randomization strategies to address covariate shift between real and simulated data by inferring essential domain attributes from real data and employing simulation-based randomization for other attributes. We construct a simplified virtual scene using real data and strategically place 3D synthetic assets within it. Illumination is achieved by estimating light distribution from multiple images capturing the surroundings of the vehicle. Camera parameters from real data are employed to render synthetic assets in each frame. The resulting augmented multi-view consistent dataset is used to train a multi-camera perception network for autonomous vehicles. Experimental results on various AV perception tasks demonstrate the superior performance of networks trained on the augmented dataset.
LeGO: Leveraging a Surface Deformation Network for Animatable Stylized Face Generation with One Example
Mar 22, 2024Recent advances in 3D face stylization have made significant strides in few to zero-shot settings. However, the degree of stylization achieved by existing methods is often not sufficient for practical applications because they are mostly based on statistical 3D Morphable Models (3DMM) with limited variations. To this end, we propose a method that can produce a highly stylized 3D face model with desired topology. Our methods train a surface deformation network with 3DMM and translate its domain to the target style using a paired exemplar. The network achieves stylization of the 3D face mesh by mimicking the style of the target using a differentiable renderer and directional CLIP losses. Additionally, during the inference process, we utilize a Mesh Agnostic Encoder (MAGE) that takes deformation target, a mesh of diverse topologies as input to the stylization process and encodes its shape into our latent space. The resulting stylized face model can be animated by commonly used 3DMM blend shapes. A set of quantitative and qualitative evaluations demonstrate that our method can produce highly stylized face meshes according to a given style and output them in a desired topology. We also demonstrate example applications of our method including image-based stylized avatar generation, linear interpolation of geometric styles, and facial animation of stylized avatars.
Toward Tiny and High-quality Facial Makeup with Data Amplify Learning
Mar 22, 2024Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed "Data Amplify Learning (DAL)," alongside a compact makeup model named "TinyBeauty." The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to "amplify" limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.
ParFormer: Vision Transformer Baseline with Parallel Local Global Token Mixer and Convolution Attention Patch Embedding
Mar 22, 2024This work presents ParFormer as an enhanced transformer architecture that allows the incorporation of different token mixers into a single stage, hence improving feature extraction capabilities. Integrating both local and global data allows for precise representation of short- and long-range spatial relationships without the need for computationally intensive methods such as shifting windows. Along with the parallel token mixer encoder, We offer the Convolutional Attention Patch Embedding (CAPE) as an enhancement of standard patch embedding to improve token mixer extraction with a convolutional attention module. Our comprehensive evaluation demonstrates that our ParFormer outperforms CNN-based and state-of-the-art transformer-based architectures in image classification and several complex tasks such as object recognition. The proposed CAPE has been demonstrated to benefit the overall MetaFormer architecture, even while utilizing the Identity Mapping Token Mixer, resulting in a 0.5\% increase in accuracy. The ParFormer models outperformed ConvNeXt and Swin Transformer for the pure convolution and transformer model in accuracy. Furthermore, our model surpasses the current leading hybrid transformer by reaching competitive Top-1 scores in the ImageNet-1K classification test. Specifically, our model variants with 11M, 23M, and 34M parameters achieve scores of 80.4\%, 82.1\%, and 83.1\%, respectively. Code: https://github.com/novendrastywn/ParFormer-CAPE-2024
Semantics, Distortion, and Style Matter: Towards Source-free UDA for Panoramic Segmentation
Mar 22, 2024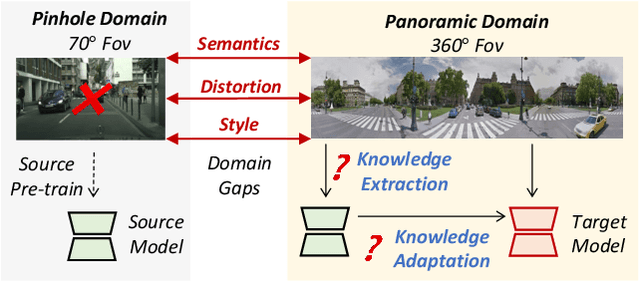
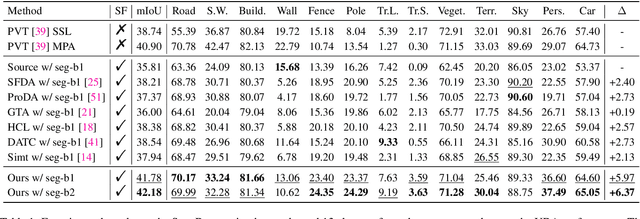
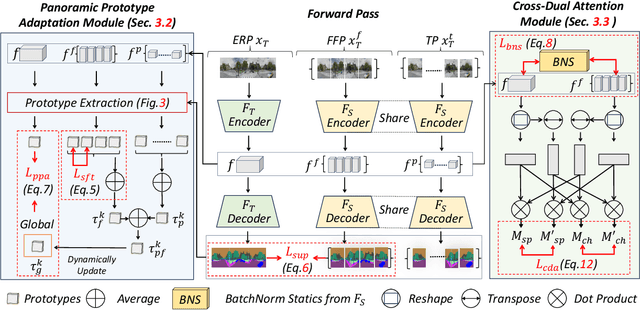
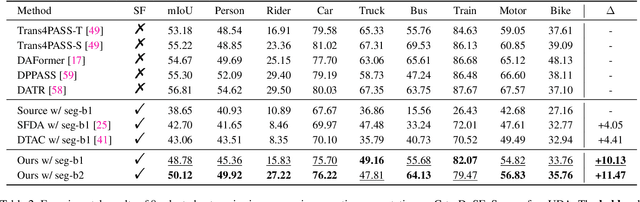
This paper addresses an interesting yet challenging problem -- source-free unsupervised domain adaptation (SFUDA) for pinhole-to-panoramic semantic segmentation -- given only a pinhole image-trained model (i.e., source) and unlabeled panoramic images (i.e., target). Tackling this problem is nontrivial due to the semantic mismatches, style discrepancies, and inevitable distortion of panoramic images. To this end, we propose a novel method that utilizes Tangent Projection (TP) as it has less distortion and meanwhile slits the equirectangular projection (ERP) with a fixed FoV to mimic the pinhole images. Both projections are shown effective in extracting knowledge from the source model. However, the distinct projection discrepancies between source and target domains impede the direct knowledge transfer; thus, we propose a panoramic prototype adaptation module (PPAM) to integrate panoramic prototypes from the extracted knowledge for adaptation. We then impose the loss constraints on both predictions and prototypes and propose a cross-dual attention module (CDAM) at the feature level to better align the spatial and channel characteristics across the domains and projections. Both knowledge extraction and transfer processes are synchronously updated to reach the best performance. Extensive experiments on the synthetic and real-world benchmarks, including outdoor and indoor scenarios, demonstrate that our method achieves significantly better performance than prior SFUDA methods for pinhole-to-panoramic adaptation.
HyperPredict: Estimating Hyperparameter Effects for Instance-Specific Regularization in Deformable Image Registration
Mar 04, 2024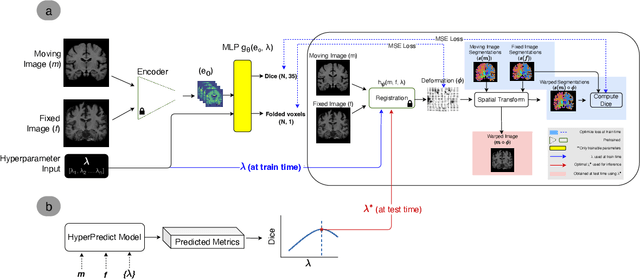

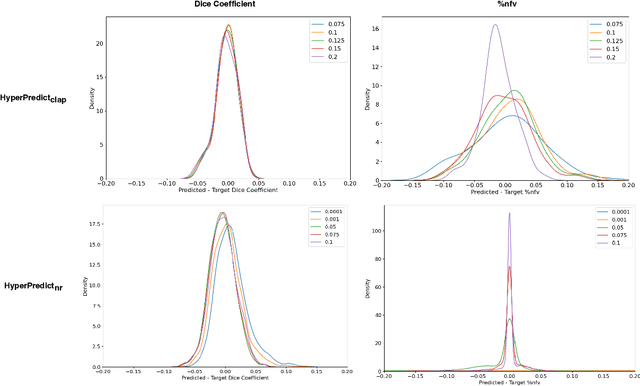
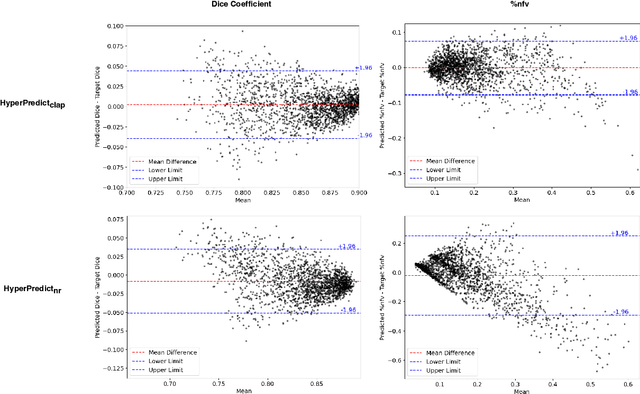
Methods for medical image registration infer geometric transformations that align pairs/groups of images by maximising an image similarity metric. This problem is ill-posed as several solutions may have equivalent likelihoods, also optimising purely for image similarity can yield implausible transformations. For these reasons regularization terms are essential to obtain meaningful registration results. However, this requires the introduction of at least one hyperparameter often termed {\lambda}, that serves as a tradeoff between loss terms. In some situations, the quality of the estimated transformation greatly depends on hyperparameter choice, and different choices may be required depending on the characteristics of the data. Analyzing the effect of these hyperparameters requires labelled data, which is not commonly available at test-time. In this paper, we propose a method for evaluating the influence of hyperparameters and subsequently selecting an optimal value for given image pairs. Our approach which we call HyperPredict, implements a Multi-Layer Perceptron that learns the effect of selecting particular hyperparameters for registering an image pair by predicting the resulting segmentation overlap and measure of deformation smoothness. This approach enables us to select optimal hyperparameters at test time without requiring labelled data, removing the need for a one-size-fits-all cross-validation approach. Furthermore, the criteria used to define optimal hyperparameter is flexible post-training, allowing us to efficiently choose specific properties. We evaluate our proposed method on the OASIS brain MR dataset using a recent deep learning approach(cLapIRN) and an algorithmic method(Niftyreg). Our results demonstrate good performance in predicting the effects of regularization hyperparameters and highlight the benefits of our image-pair specific approach to hyperparameter selection.