 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HyT-NAS: Hybrid Transformers Neural Architecture Search for Edge Devices
Mar 08, 2023
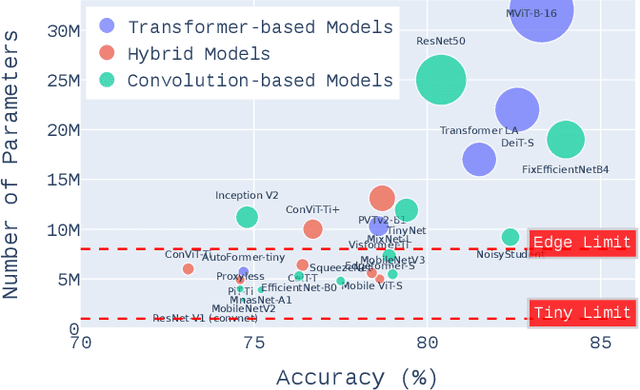

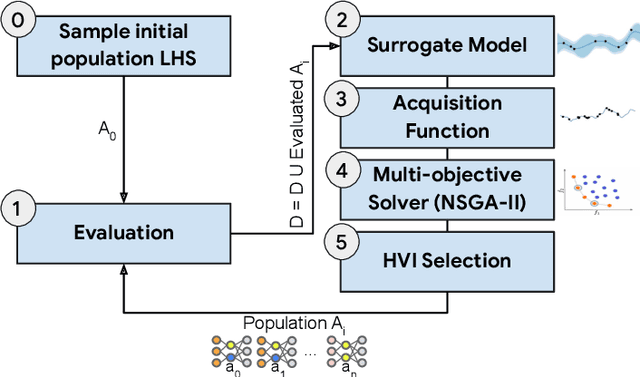
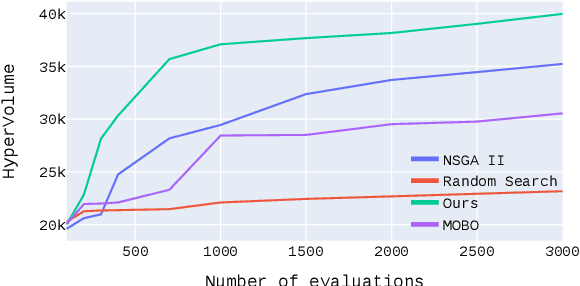
Vision Transformers have enabled recent attention-based Deep Learning (DL) architectures to achieve remarkable results in Computer Vision (CV) tasks. However, due to the extensive computational resources required, these architectures are rarely implemented on resource-constrained platforms. Current research investigates hybrid handcrafted convolution-based and attention-based models for CV tasks such as image classification and object detection. In this paper, we propose HyT-NAS, an efficient Hardware-aware Neural Architecture Search (HW-NAS) including hybrid architectures targeting vision tasks on tiny devices. HyT-NAS improves state-of-the-art HW-NAS by enriching the search space and enhancing the search strategy as well as the performance predictors. Our experiments show that HyT-NAS achieves a similar hypervolume with less than ~5x training evaluations. Our resulting architecture outperforms MLPerf MobileNetV1 by 6.3% accuracy improvement with 3.5x less number of parameters on Visual Wake Words.
Unpaired Image Translation via Vector Symbolic Architectures
Sep 06, 2022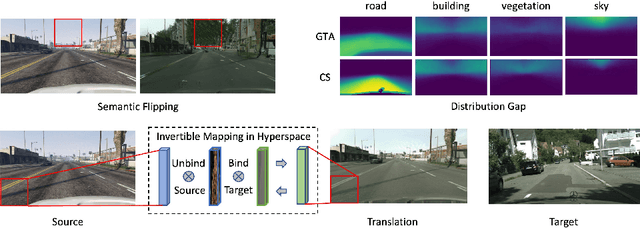
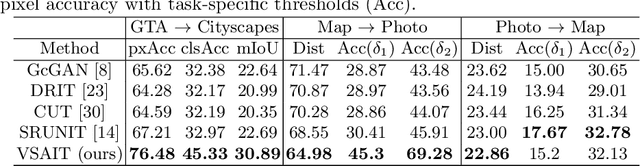


Image-to-image translation has played an important role in enabling synthetic data for computer vision. However, if the source and target domains have a large semantic mismatch, existing techniques often suffer from source content corruption aka semantic flipping. To address this problem, we propose a new paradigm for image-to-image translation using Vector Symbolic Architectures (VSA), a theoretical framework which defines algebraic operations in a high-dimensional vector (hypervector) space. We introduce VSA-based constraints on adversarial learning for source-to-target translations by learning a hypervector mapping that inverts the translation to ensure consistency with source content. We show both qualitatively and quantitatively that our method improves over other state-of-the-art techniques.
Cross-modal Semantic Enhanced Interaction for Image-Sentence Retrieval
Oct 17, 2022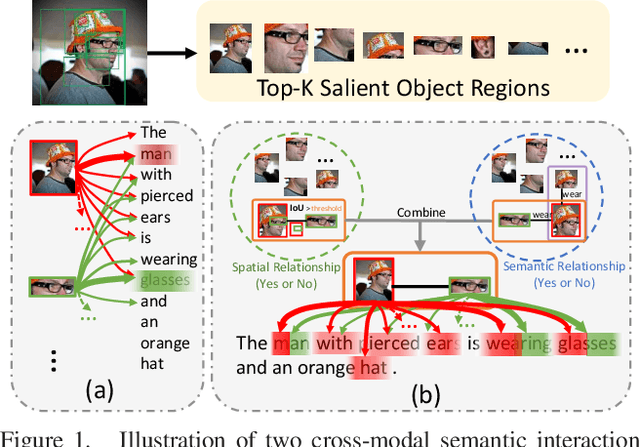
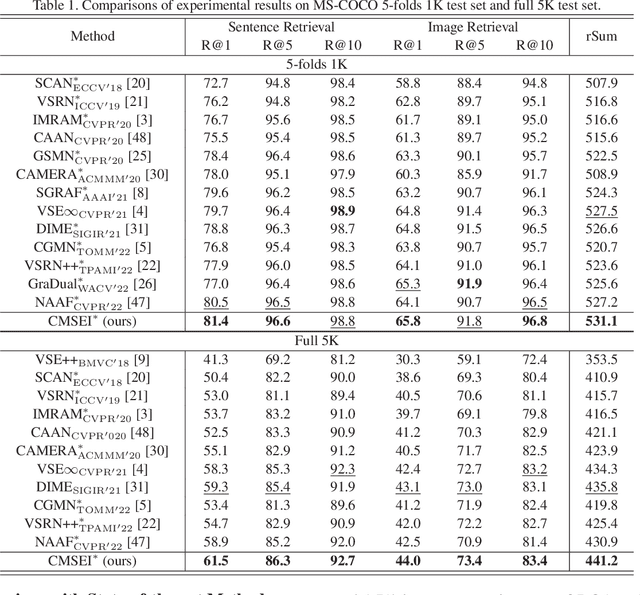
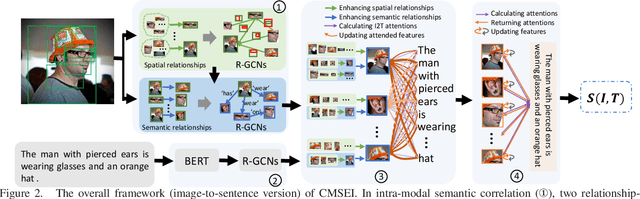
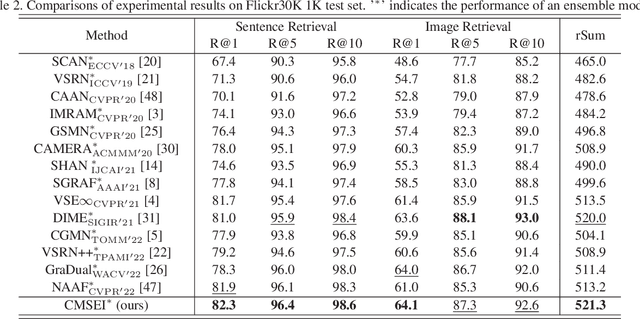
Image-sentence retrieval has attracted extensive research attention in multimedia and computer vision due to its promising application. The key issue lies in jointly learning the visual and textual representation to accurately estimate their similarity. To this end, the mainstream schema adopts an object-word based attention to calculate their relevance scores and refine their interactive representations with the attention features, which, however, neglects the context of the object representation on the inter-object relationship that matches the predicates in sentences. In this paper, we propose a Cross-modal Semantic Enhanced Interaction method, termed CMSEI for image-sentence retrieval, which correlates the intra- and inter-modal semantics between objects and words. In particular, we first design the intra-modal spatial and semantic graphs based reasoning to enhance the semantic representations of objects guided by the explicit relationships of the objects' spatial positions and their scene graph. Then the visual and textual semantic representations are refined jointly via the inter-modal interactive attention and the cross-modal alignment. To correlate the context of objects with the textual context, we further refine the visual semantic representation via the cross-level object-sentence and word-image based interactive attention. Experimental results on seven standard evaluation metrics show that the proposed CMSEI outperforms the state-of-the-art and the alternative approaches on MS-COCO and Flickr30K benchmarks.
Extracting Class Activation Maps from Non-Discriminative Features as well
Mar 18, 2023
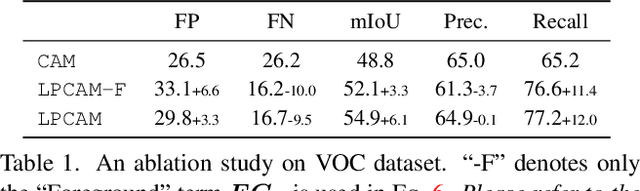
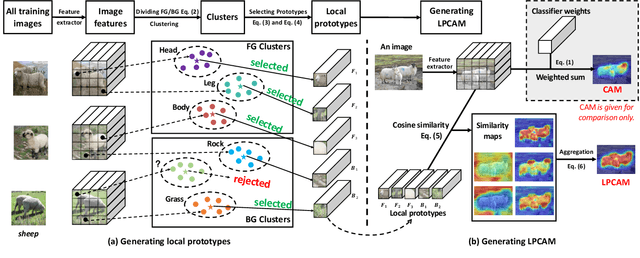
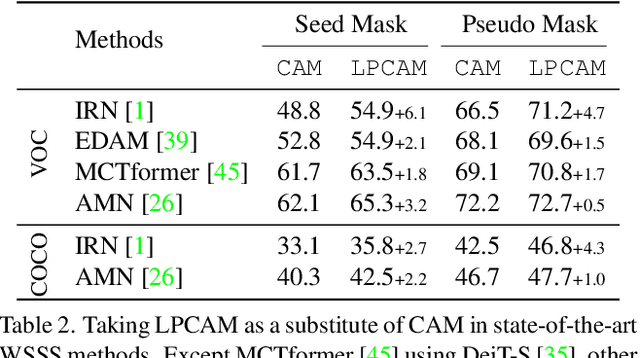
Extracting class activation maps (CAM) from a classification model often results in poor coverage on foreground objects, i.e., only the discriminative region (e.g., the "head" of "sheep") is recognized and the rest (e.g., the "leg" of "sheep") mistakenly as background. The crux behind is that the weight of the classifier (used to compute CAM) captures only the discriminative features of objects. We tackle this by introducing a new computation method for CAM that explicitly captures non-discriminative features as well, thereby expanding CAM to cover whole objects. Specifically, we omit the last pooling layer of the classification model, and perform clustering on all local features of an object class, where "local" means "at a spatial pixel position". We call the resultant K cluster centers local prototypes - represent local semantics like the "head", "leg", and "body" of "sheep". Given a new image of the class, we compare its unpooled features to every prototype, derive K similarity matrices, and then aggregate them into a heatmap (i.e., our CAM). Our CAM thus captures all local features of the class without discrimination. We evaluate it in the challenging tasks of weakly-supervised semantic segmentation (WSSS), and plug it in multiple state-of-the-art WSSS methods, such as MCTformer and AMN, by simply replacing their original CAM with ours. Our extensive experiments on standard WSSS benchmarks (PASCAL VOC and MS COCO) show the superiority of our method: consistent improvements with little computational overhead.
Autonomous Robotic Drilling System for Mice Cranial Window Creation: An Evaluation with an Egg Model
Mar 22, 2023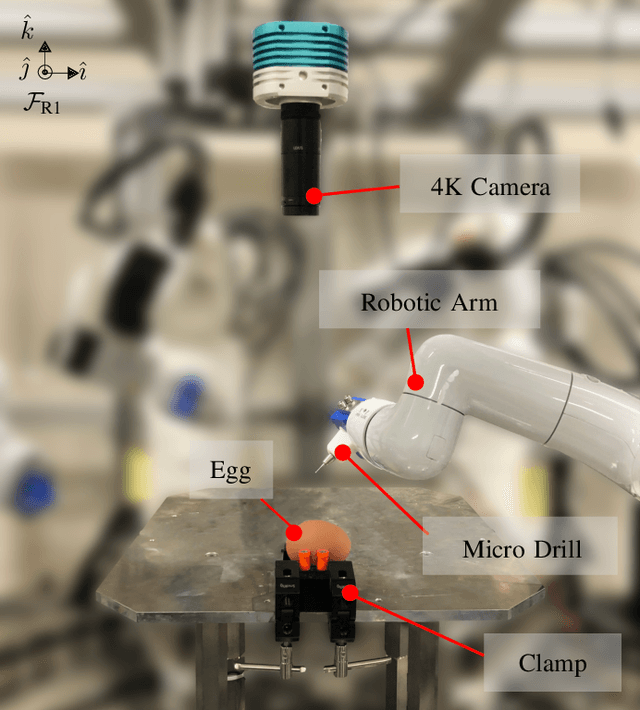
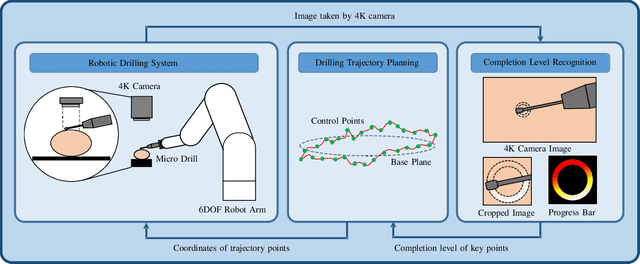
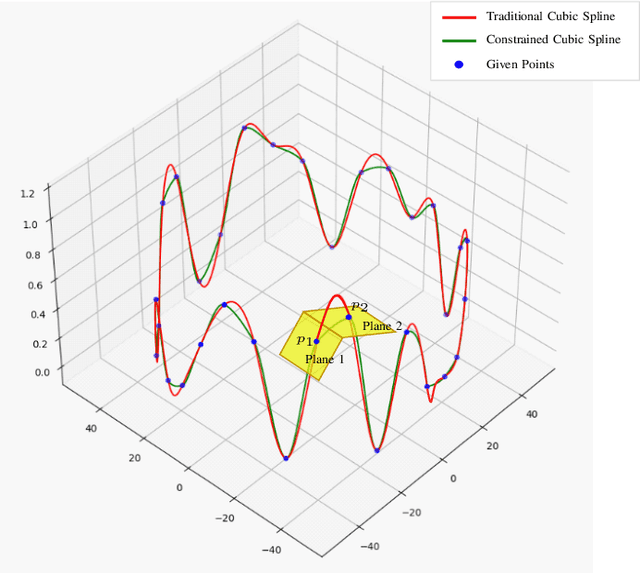
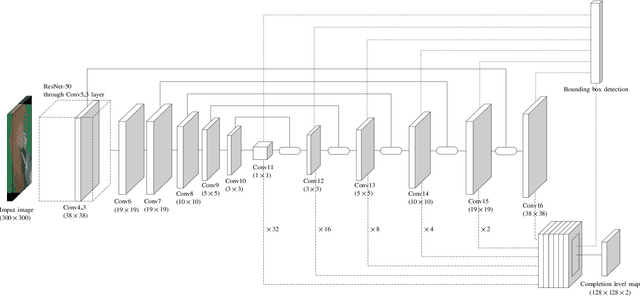
Robotic assistance for experimental manipulation in the life sciences is expected to enable precise manipulation of valuable samples, regardless of the skill of the scientist. Experimental specimens in the life sciences are subject to individual variability and deformation, and therefore require autonomous robotic control. As an example, we are studying the installation of a cranial window in a mouse. This operation requires the removal of the skull, which is approximately 300 um thick, to cut it into a circular shape 8 mm in diameter, but the shape of the mouse skull varies depending on the strain of mouse, sex and week of age. The thickness of the skull is not uniform, with some areas being thin and others thicker. It is also difficult to ensure that the skulls of the mice are kept in the same position for each operation. It is not realistically possible to measure all these features and pre-program a robotic trajectory for individual mice. The paper therefore proposes an autonomous robotic drilling method. The proposed method consists of drilling trajectory planning and image-based task completion level recognition. The trajectory planning adjusts the z-position of the drill according to the task completion level at each discrete point, and forms the 3D drilling path via constrained cubic spline interpolation while avoiding overshoot. The task completion level recognition uses a DSSD-inspired deep learning model to estimate the task completion level of each discrete point. Since an egg has similar characteristics to a mouse skull in terms of shape, thickness and mechanical properties, removing the egg shell without damaging the membrane underneath was chosen as the simulation task. The proposed method was evaluated using a 6-DOF robotic arm holding a drill and achieved a success rate of 80% out of 20 trials.
MobileBrick: Building LEGO for 3D Reconstruction on Mobile Devices
Mar 09, 2023
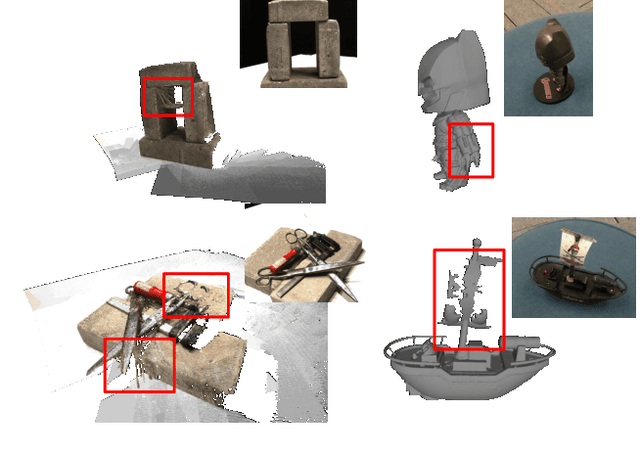
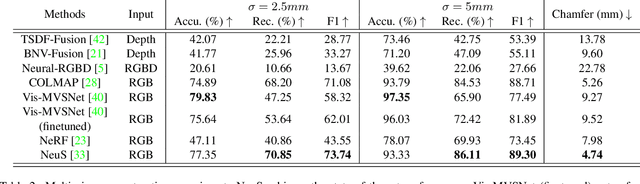
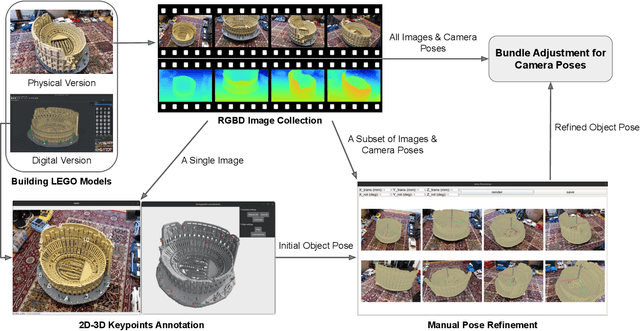
High-quality 3D ground-truth shapes are critical for 3D object reconstruction evaluation. However, it is difficult to create a replica of an object in reality, and even 3D reconstructions generated by 3D scanners have artefacts that cause biases in evaluation. To address this issue, we introduce a novel multi-view RGBD dataset captured using a mobile device, which includes highly precise 3D ground-truth annotations for 153 object models featuring a diverse set of 3D structures. We obtain precise 3D ground-truth shape without relying on high-end 3D scanners by utilising LEGO models with known geometry as the 3D structures for image capture. The distinct data modality offered by high-resolution RGB images and low-resolution depth maps captured on a mobile device, when combined with precise 3D geometry annotations, presents a unique opportunity for future research on high-fidelity 3D reconstruction. Furthermore, we evaluate a range of 3D reconstruction algorithms on the proposed dataset. Project page: http://code.active.vision/MobileBrick/
Replacement as a Self-supervision for Fine-grained Vision-language Pre-training
Mar 09, 2023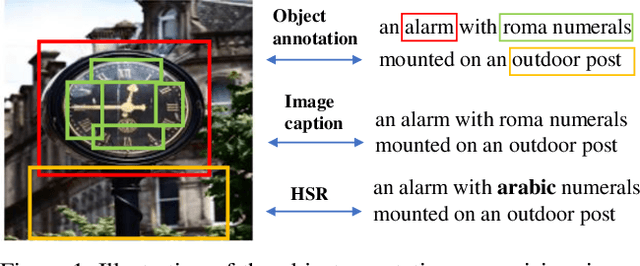
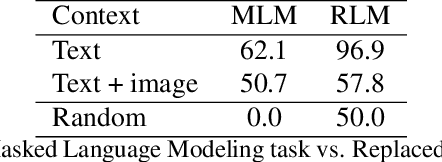
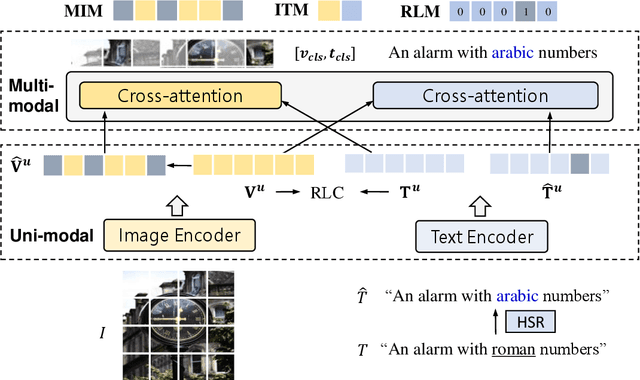

Fine-grained supervision based on object annotations has been widely used for vision and language pre-training (VLP). However, in real-world application scenarios, aligned multi-modal data is usually in the image-caption format, which only provides coarse-grained supervision. It is cost-expensive to collect object annotations and build object annotation pre-extractor for different scenarios. In this paper, we propose a fine-grained self-supervision signal without object annotations from a replacement perspective. First, we propose a homonym sentence rewriting (HSR) algorithm to provide token-level supervision. The algorithm replaces a verb/noun/adjective/quantifier word of the caption with its homonyms from WordNet. Correspondingly, we propose a replacement vision-language modeling (RVLM) framework to exploit the token-level supervision. Two replaced modeling tasks, i.e., replaced language contrastive (RLC) and replaced language modeling (RLM), are proposed to learn the fine-grained alignment. Extensive experiments on several downstream tasks demonstrate the superior performance of the proposed method.
StyleDiff: Attribute Comparison Between Unlabeled Datasets in Latent Disentangled Space
Mar 09, 2023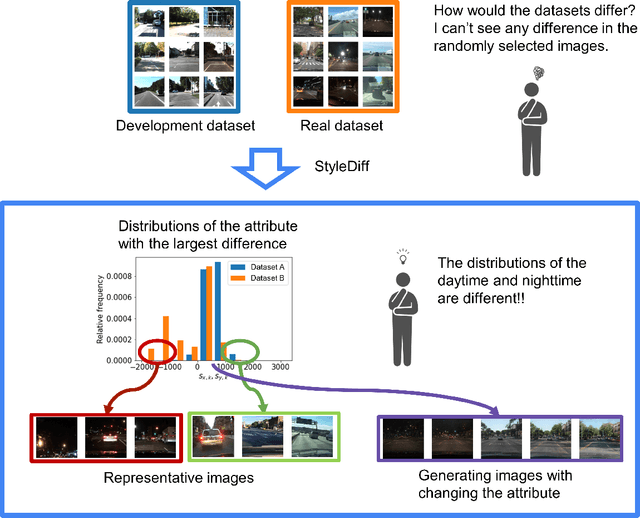
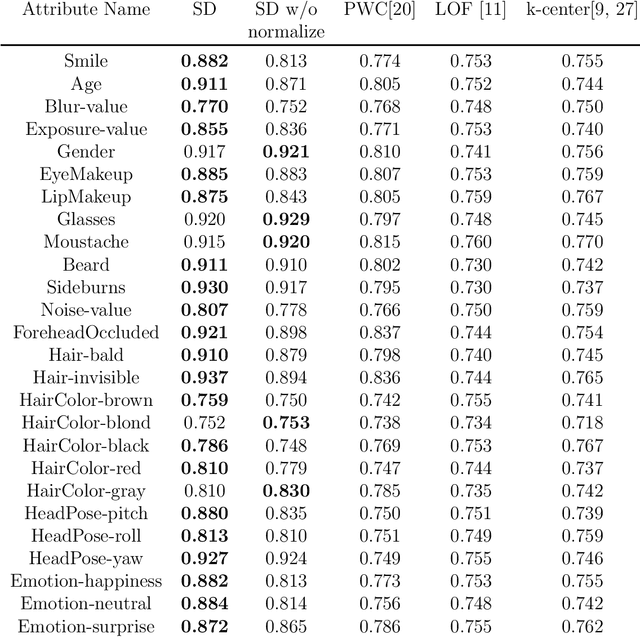
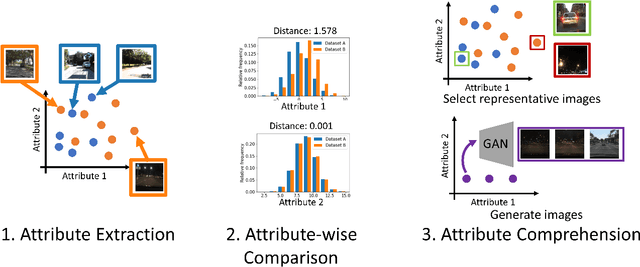

One major challenge in machine learning applications is coping with mismatches between the datasets used in the development and those obtained in real-world applications. These mismatches may lead to inaccurate predictions and errors, resulting in poor product quality and unreliable systems. In this study, we propose StyleDiff to inform developers of the differences between the two datasets for the steady development of machine learning systems. Using disentangled image spaces obtained from recently proposed generative models, StyleDiff compares the two datasets by focusing on attributes in the images and provides an easy-to-understand analysis of the differences between the datasets. The proposed StyleDiff performs in $O (d N\log N)$, where $N$ is the size of the datasets and $d$ is the number of attributes, enabling the application to large datasets. We demonstrate that StyleDiff accurately detects differences between datasets and presents them in an understandable format using, for example, driving scenes datasets.
Active Learning Based Domain Adaptation for Tissue Segmentation of Histopathological Images
Mar 09, 2023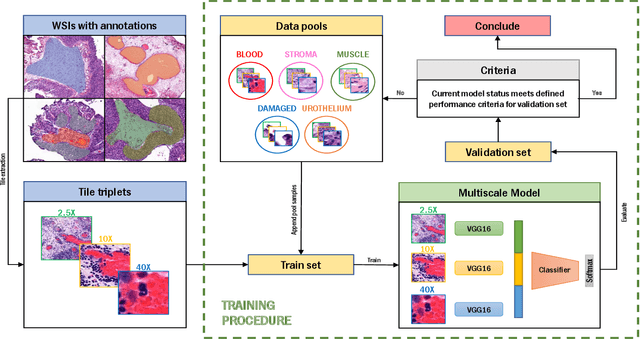
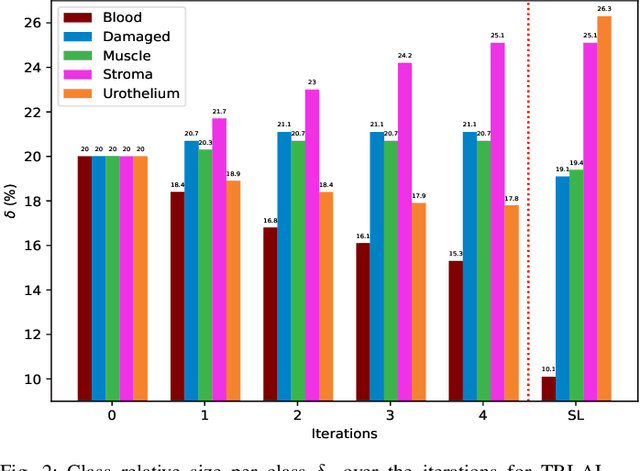
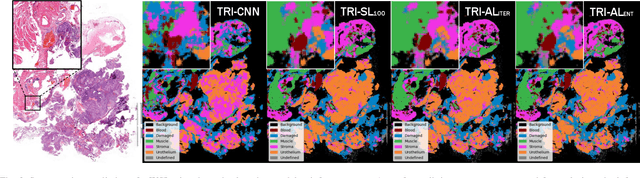
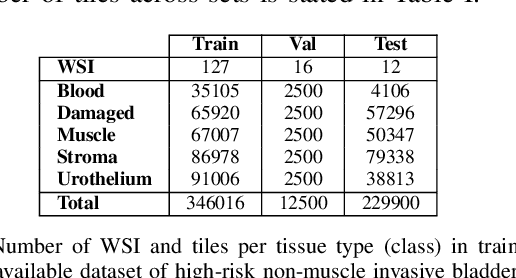
Accurate segmentation of tissue in histopathological images can be very beneficial for defining regions of interest (ROI) for streamline of diagnostic and prognostic tasks. Still, adapting to different domains is essential for histopathology image analysis, as the visual characteristics of tissues can vary significantly across datasets. Yet, acquiring sufficient annotated data in the medical domain is cumbersome and time-consuming. The labeling effort can be significantly reduced by leveraging active learning, which enables the selective annotation of the most informative samples. Our proposed method allows for fine-tuning a pre-trained deep neural network using a small set of labeled data from the target domain, while also actively selecting the most informative samples to label next. We demonstrate that our approach performs with significantly fewer labeled samples compared to traditional supervised learning approaches for similar F1-scores, using barely a 59\% of the training set. We also investigate the distribution of class balance to establish annotation guidelines.
Revisiting Self-Training with Regularized Pseudo-Labeling for Tabular Data
Mar 13, 2023
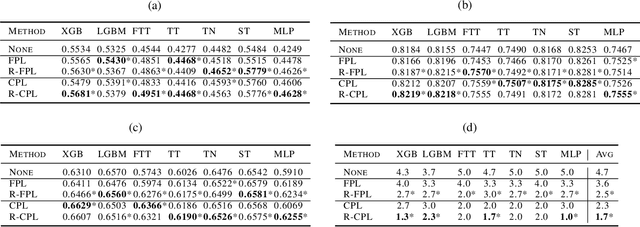
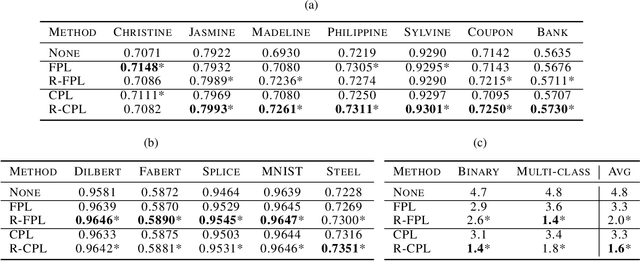
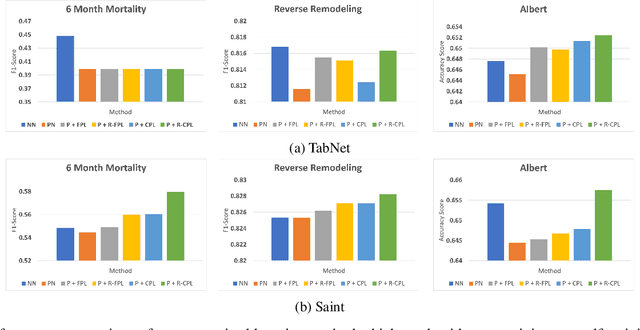
Recent progress in semi- and self-supervised learning has caused a rift in the long-held belief about the need for an enormous amount of labeled data for machine learning and the irrelevancy of unlabeled data. Although it has been successful in various data, there is no dominant semi- and self-supervised learning method that can be generalized for tabular data (i.e. most of the existing methods require appropriate tabular datasets and architectures). In this paper, we revisit self-training which can be applied to any kind of algorithm including the most widely used architecture, gradient boosting decision tree, and introduce curriculum pseudo-labeling (a state-of-the-art pseudo-labeling technique in image) for a tabular domain. Furthermore, existing pseudo-labeling techniques do not assure the cluster assumption when computing confidence scores of pseudo-labels generated from unlabeled data. To overcome this issue, we propose a novel pseudo-labeling approach that regularizes the confidence scores based on the likelihoods of the pseudo-labels so that more reliable pseudo-labels which lie in high density regions can be obtained. We exhaustively validate the superiority of our approaches using various models and tabular datasets.