 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Lightweight Estimation of Hand Mesh and Biomechanically Feasible Kinematic Parameters
Mar 26, 2023



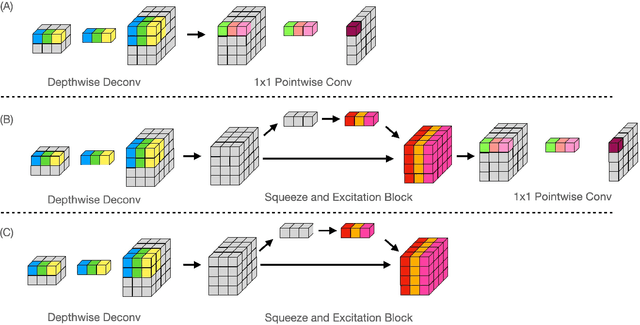
3D hand pose estimation is a long-standing challenge in both robotics and computer vision communities due to its implicit depth ambiguity and often strong self-occlusion. Recently, in addition to the hand skeleton, jointly estimating hand pose and shape has gained more attraction. State-of-the-art methods adopt a model-free approach, estimating the vertices of the hand mesh directly and providing superior accuracy compared to traditional model-based methods directly regressing the parameters of the parametric hand mesh. However, with the large number of mesh vertices to estimate, these methods are often slow in inference. We propose an efficient variation of the previously proposed image-to-lixel approach to efficiently estimate hand meshes from the images. Leveraging recent developments in efficient neural architectures, we significantly reduce the computation complexity without sacrificing the estimation accuracy. Furthermore, we introduce an inverted kinematic(IK) network to translate the estimated hand mesh to a biomechanically feasible set of joint rotation parameters, which is necessary for applications that leverage pose estimation for controlling robotic hands. Finally, an optional post-processing module is proposed to refine the rotation and shape parameters to compensate for the error introduced by the IK net. Our Lite I2L Mesh Net achieves state-of-the-art joint and mesh estimation accuracy with less than $13\%$ of the total computational complexity of the original I2L hand mesh estimator. Adding the IK net and post-optimization modules can improve the accuracy slightly at a small computation cost, but more importantly, provide the kinematic parameters required for robotic applications.
gpcgc: a green point cloud geometry coding method
Feb 13, 2023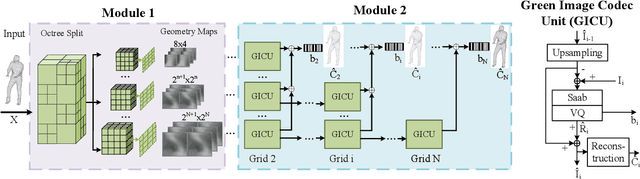
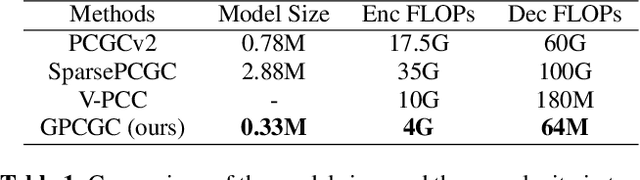
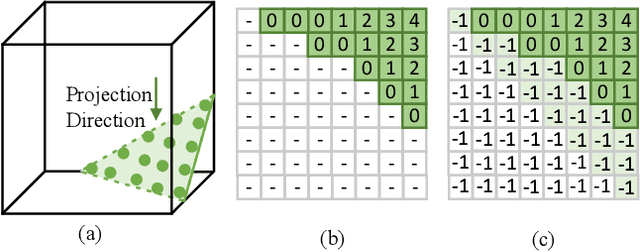
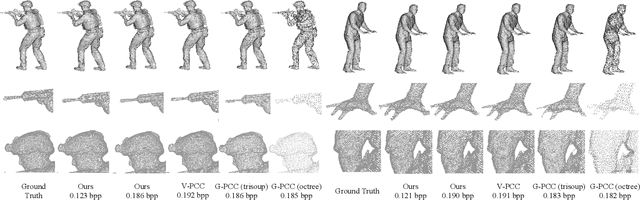
A low-complexity point cloud compression method called the Green Point Cloud Geometry Codec (GPCGC), is proposed to encode the 3D spatial coordinates of static point clouds efficiently. GPCGC consists of two modules. In the first module, point coordinates of input point clouds are hierarchically organized into an octree structure. Points at each leaf node are projected along one of three axes to yield image maps. In the second module, the occupancy map is clustered into 9 modes while the depth map is coded by a low-complexity high-efficiency image codec, called the green image codec (GIC). GIC is a multi-resolution codec based on vector quantization (VQ). Its complexity is significantly lower than HEVC-Intra. Furthermore, the rate-distortion optimization (RDO) technique is used to select the optimal coding parameters. GPCGC is a progressive codec, and it offers a coding performance competitive with MPEG's V-PCC and G-PCC standards at significantly lower complexity.
LiT Tuned Models for Efficient Species Detection
Feb 12, 2023
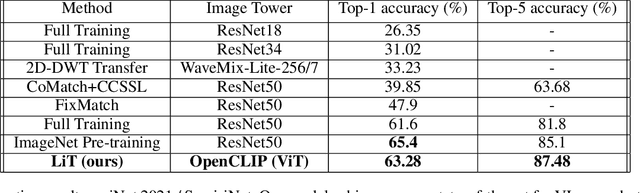
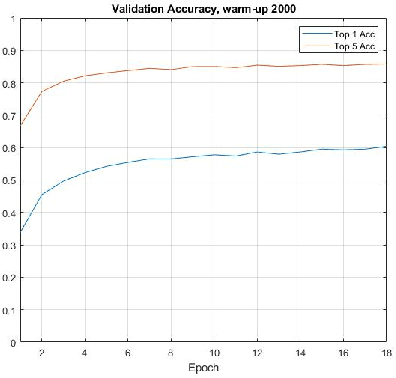
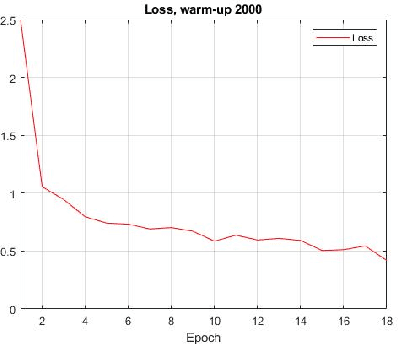
Recent advances in training vision-language models have demonstrated unprecedented robustness and transfer learning effectiveness; however, standard computer vision datasets are image-only, and therefore not well adapted to such training methods. Our paper introduces a simple methodology for adapting any fine-grained image classification dataset for distributed vision-language pretraining. We implement this methodology on the challenging iNaturalist-2021 dataset, comprised of approximately 2.7 million images of macro-organisms across 10,000 classes, and achieve a new state-of-the art model in terms of zero-shot classification accuracy. Somewhat surprisingly, our model (trained using a new method called locked-image text tuning) uses a pre-trained, frozen vision representation, proving that language alignment alone can attain strong transfer learning performance, even on fractious, long-tailed datasets. Our approach opens the door for utilizing high quality vision-language pretrained models in agriculturally relevant applications involving species detection.
Hypernetworks build Implicit Neural Representations of Sounds
Feb 09, 2023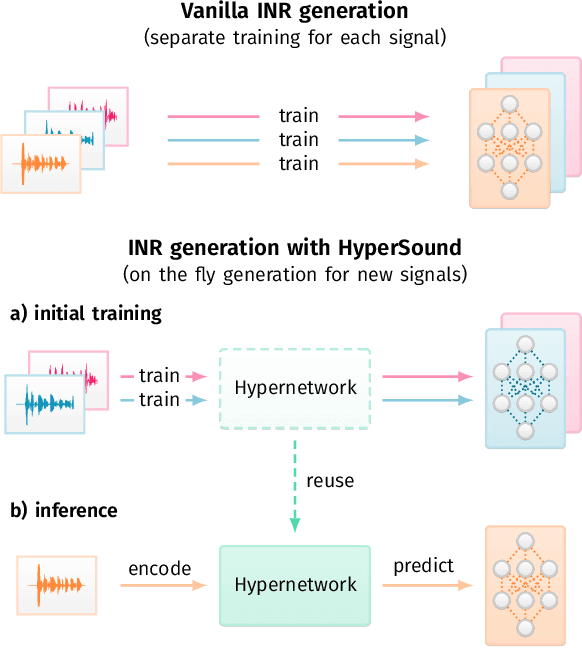

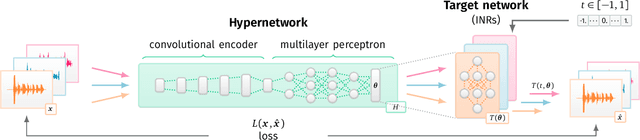
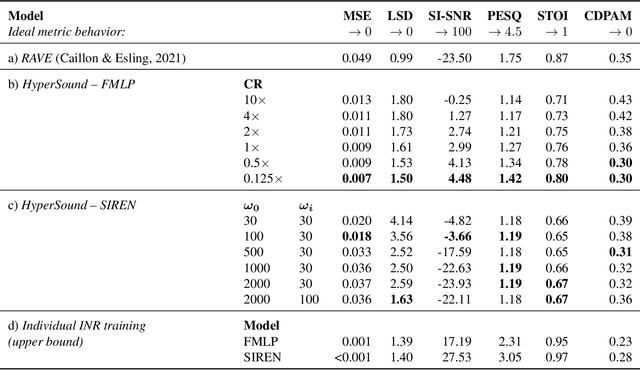
Implicit Neural Representations (INRs) are nowadays used to represent multimedia signals across various real-life applications, including image super-resolution, image compression, or 3D rendering. Existing methods that leverage INRs are predominantly focused on visual data, as their application to other modalities, such as audio, is nontrivial due to the inductive biases present in architectural attributes of image-based INR models. To address this limitation, we introduce HyperSound, the first meta-learning approach to produce INRs for audio samples that leverages hypernetworks to generalize beyond samples observed in training. Our approach reconstructs audio samples with quality comparable to other state-of-the-art models and provides a viable alternative to contemporary sound representations used in deep neural networks for audio processing, such as spectrograms.
CP$^3$: Channel Pruning Plug-in for Point-based Networks
Mar 23, 2023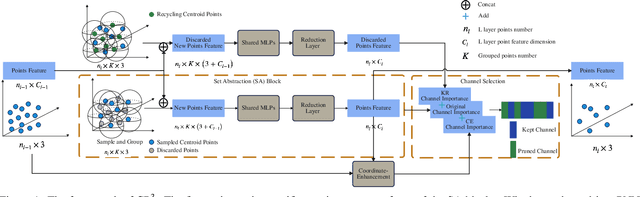
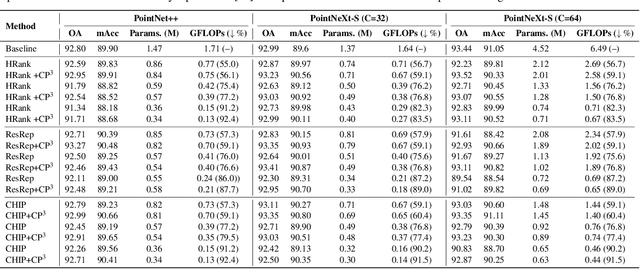
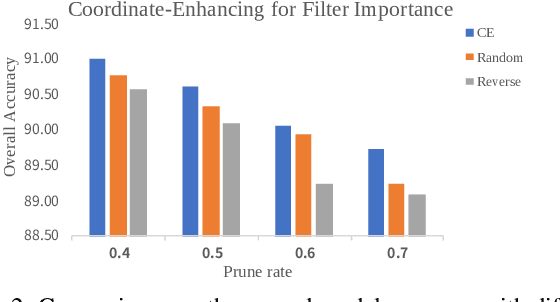
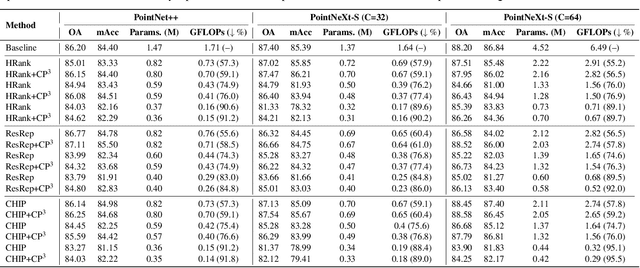
Channel pruning can effectively reduce both computational cost and memory footprint of the original network while keeping a comparable accuracy performance. Though great success has been achieved in channel pruning for 2D image-based convolutional networks (CNNs), existing works seldom extend the channel pruning methods to 3D point-based neural networks (PNNs). Directly implementing the 2D CNN channel pruning methods to PNNs undermine the performance of PNNs because of the different representations of 2D images and 3D point clouds as well as the network architecture disparity. In this paper, we proposed CP$^3$, which is a Channel Pruning Plug-in for Point-based network. CP$^3$ is elaborately designed to leverage the characteristics of point clouds and PNNs in order to enable 2D channel pruning methods for PNNs. Specifically, it presents a coordinate-enhanced channel importance metric to reflect the correlation between dimensional information and individual channel features, and it recycles the discarded points in PNN's sampling process and reconsiders their potentially-exclusive information to enhance the robustness of channel pruning. Experiments on various PNN architectures show that CP$^3$ constantly improves state-of-the-art 2D CNN pruning approaches on different point cloud tasks. For instance, our compressed PointNeXt-S on ScanObjectNN achieves an accuracy of 88.52% with a pruning rate of 57.8%, outperforming the baseline pruning methods with an accuracy gain of 1.94%.
Set-the-Scene: Global-Local Training for Generating Controllable NeRF Scenes
Mar 23, 2023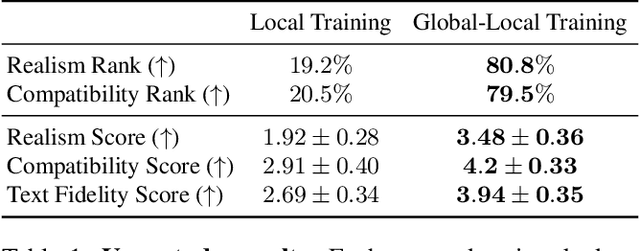

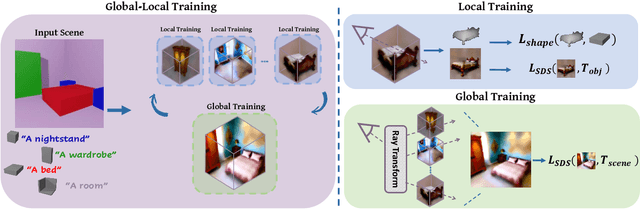

Recent breakthroughs in text-guided image generation have led to remarkable progress in the field of 3D synthesis from text. By optimizing neural radiance fields (NeRF) directly from text, recent methods are able to produce remarkable results. Yet, these methods are limited in their control of each object's placement or appearance, as they represent the scene as a whole. This can be a major issue in scenarios that require refining or manipulating objects in the scene. To remedy this deficit, we propose a novel GlobalLocal training framework for synthesizing a 3D scene using object proxies. A proxy represents the object's placement in the generated scene and optionally defines its coarse geometry. The key to our approach is to represent each object as an independent NeRF. We alternate between optimizing each NeRF on its own and as part of the full scene. Thus, a complete representation of each object can be learned, while also creating a harmonious scene with style and lighting match. We show that using proxies allows a wide variety of editing options, such as adjusting the placement of each independent object, removing objects from a scene, or refining an object. Our results show that Set-the-Scene offers a powerful solution for scene synthesis and manipulation, filling a crucial gap in controllable text-to-3D synthesis.
MonoATT: Online Monocular 3D Object Detection with Adaptive Token Transformer
Mar 23, 2023
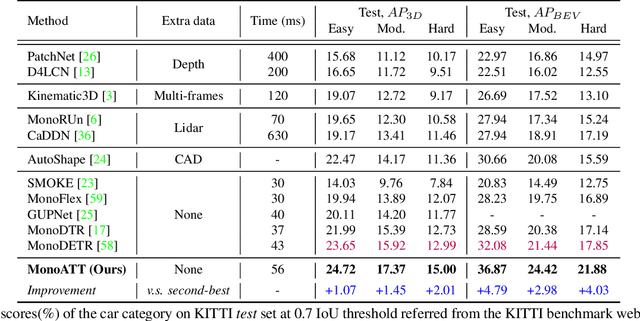
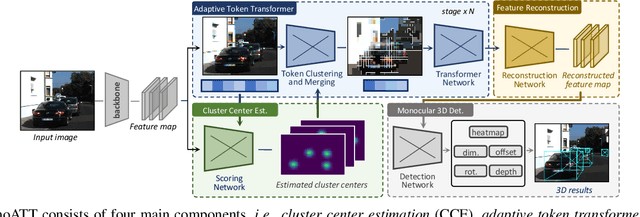
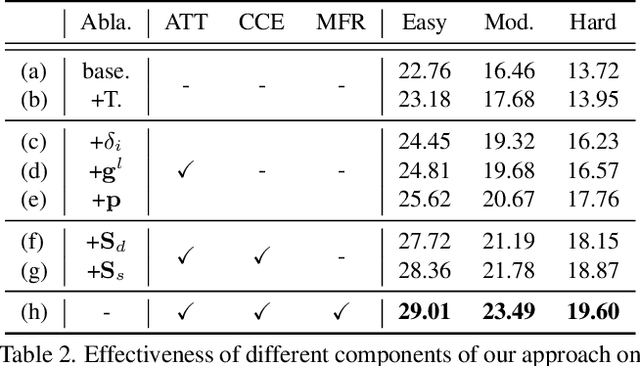
Mobile monocular 3D object detection (Mono3D) (e.g., on a vehicle, a drone, or a robot) is an important yet challenging task. Existing transformer-based offline Mono3D models adopt grid-based vision tokens, which is suboptimal when using coarse tokens due to the limited available computational power. In this paper, we propose an online Mono3D framework, called MonoATT, which leverages a novel vision transformer with heterogeneous tokens of varying shapes and sizes to facilitate mobile Mono3D. The core idea of MonoATT is to adaptively assign finer tokens to areas of more significance before utilizing a transformer to enhance Mono3D. To this end, we first use prior knowledge to design a scoring network for selecting the most important areas of the image, and then propose a token clustering and merging network with an attention mechanism to gradually merge tokens around the selected areas in multiple stages. Finally, a pixel-level feature map is reconstructed from heterogeneous tokens before employing a SOTA Mono3D detector as the underlying detection core. Experiment results on the real-world KITTI dataset demonstrate that MonoATT can effectively improve the Mono3D accuracy for both near and far objects and guarantee low latency. MonoATT yields the best performance compared with the state-of-the-art methods by a large margin and is ranked number one on the KITTI 3D benchmark.
Semantic 3D-aware Portrait Synthesis and Manipulation Based on Compositional Neural Radiance Field
Feb 03, 2023
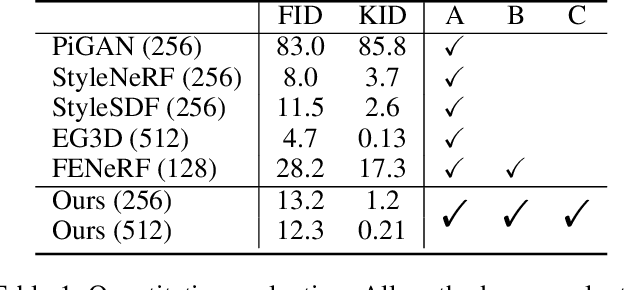
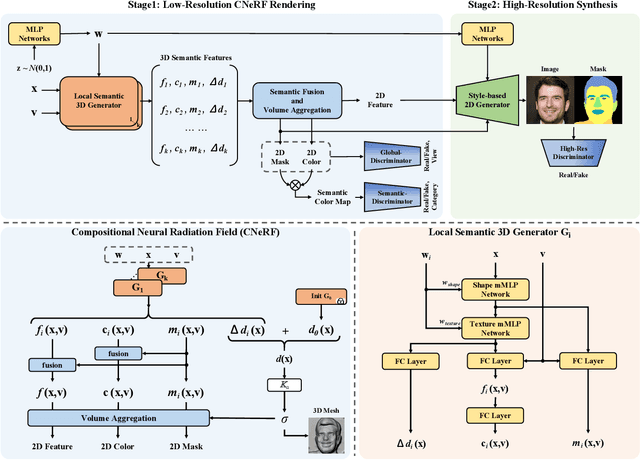

Recently 3D-aware GAN methods with neural radiance field have developed rapidly. However, current methods model the whole image as an overall neural radiance field, which limits the partial semantic editability of synthetic results. Since NeRF renders an image pixel by pixel, it is possible to split NeRF in the spatial dimension. We propose a Compositional Neural Radiance Field (CNeRF) for semantic 3D-aware portrait synthesis and manipulation. CNeRF divides the image by semantic regions and learns an independent neural radiance field for each region, and finally fuses them and renders the complete image. Thus we can manipulate the synthesized semantic regions independently, while fixing the other parts unchanged. Furthermore, CNeRF is also designed to decouple shape and texture within each semantic region. Compared to state-of-the-art 3D-aware GAN methods, our approach enables fine-grained semantic region manipulation, while maintaining high-quality 3D-consistent synthesis. The ablation studies show the effectiveness of the structure and loss function used by our method. In addition real image inversion and cartoon portrait 3D editing experiments demonstrate the application potential of our method.
Layered-Garment Net: Generating Multiple Implicit Garment Layers from a Single Image
Nov 22, 2022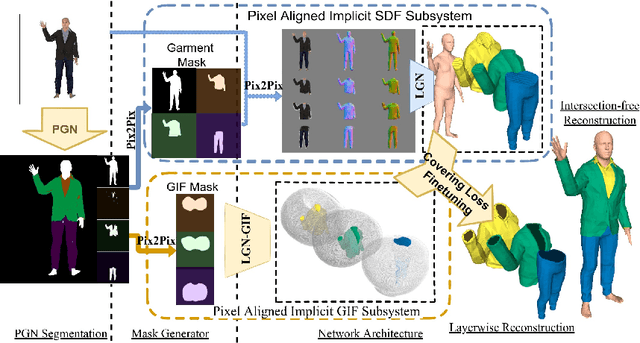

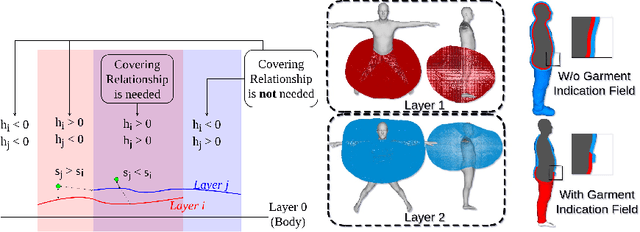
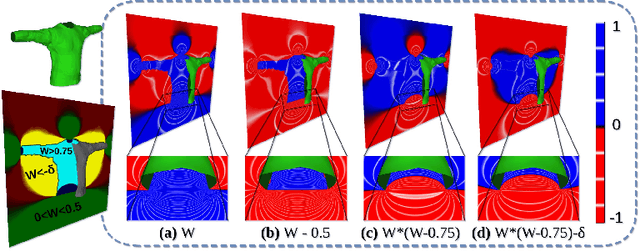
Recent research works have focused on generating human models and garments from their 2D images. However, state-of-the-art researches focus either on only a single layer of the garment on a human model or on generating multiple garment layers without any guarantee of the intersection-free geometric relationship between them. In reality, people wear multiple layers of garments in their daily life, where an inner layer of garment could be partially covered by an outer one. In this paper, we try to address this multi-layer modeling problem and propose the Layered-Garment Net (LGN) that is capable of generating intersection-free multiple layers of garments defined by implicit function fields over the body surface, given the person's near front-view image. With a special design of garment indication fields (GIF), we can enforce an implicit covering relationship between the signed distance fields (SDF) of different layers to avoid self-intersections among different garment surfaces and the human body. Experiments demonstrate the strength of our proposed LGN framework in generating multi-layer garments as compared to state-of-the-art methods. To the best of our knowledge, LGN is the first research work to generate intersection-free multiple layers of garments on the human body from a single image.
Bayesian Metric Learning for Uncertainty Quantification in Image Retrieval
Feb 04, 2023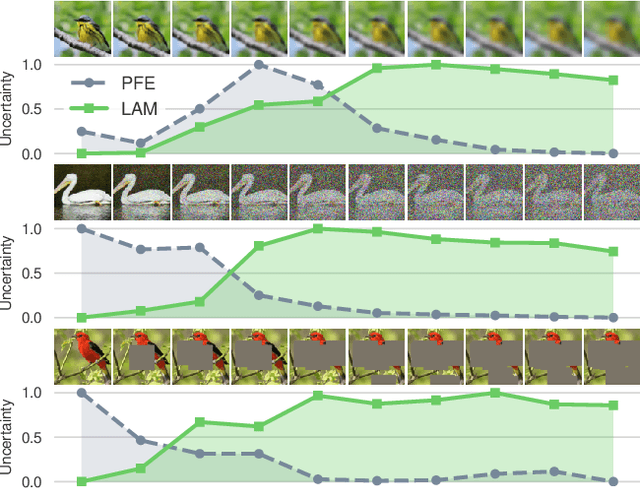
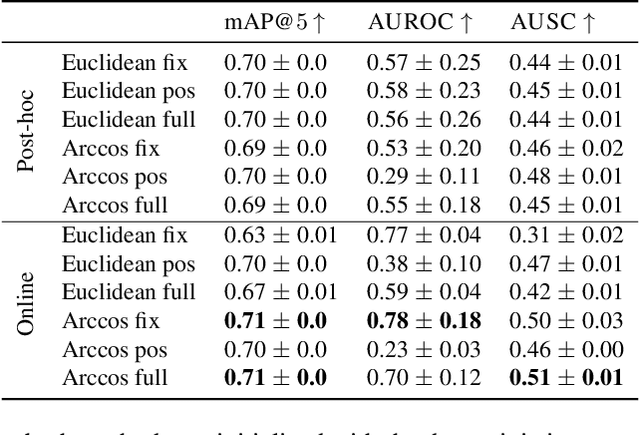

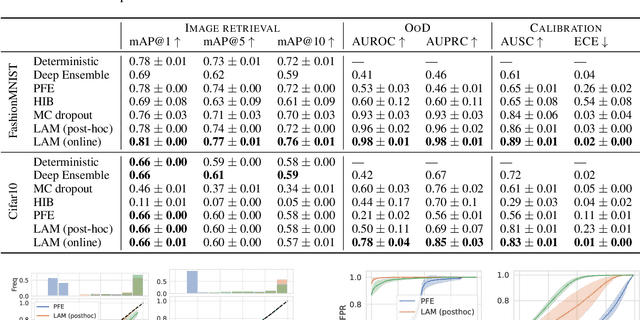
We propose the first Bayesian encoder for metric learning. Rather than relying on neural amortization as done in prior works, we learn a distribution over the network weights with the Laplace Approximation. We actualize this by first proving that the contrastive loss is a valid log-posterior. We then propose three methods that ensure a positive definite Hessian. Lastly, we present a novel decomposition of the Generalized Gauss-Newton approximation. Empirically, we show that our Laplacian Metric Learner (LAM) estimates well-calibrated uncertainties, reliably detects out-of-distribution examples, and yields state-of-the-art predictive performance.