 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Text-Only Training for Image Captioning using Noise-Injected CLIP
Nov 01, 2022
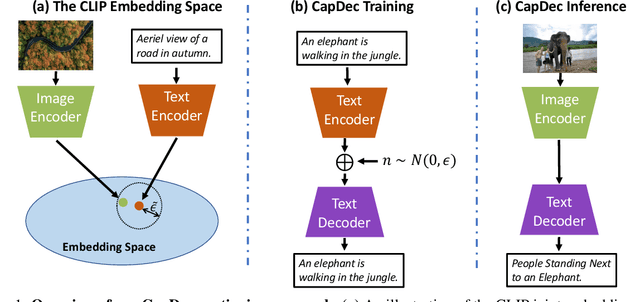
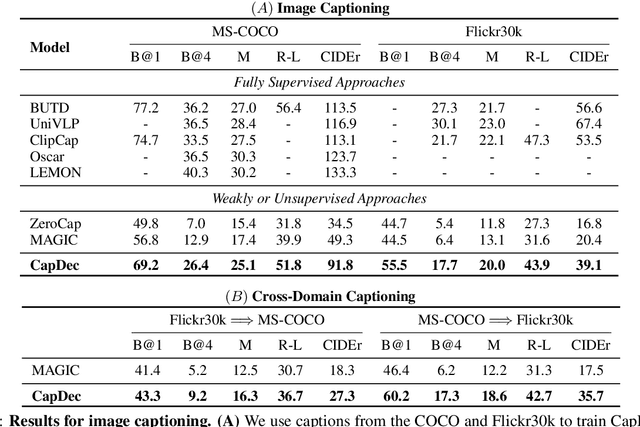
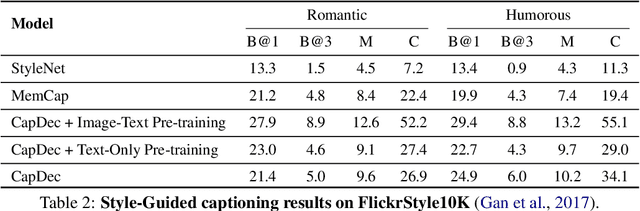

We consider the task of image-captioning using only the CLIP model and additional text data at training time, and no additional captioned images. Our approach relies on the fact that CLIP is trained to make visual and textual embeddings similar. Therefore, we only need to learn how to translate CLIP textual embeddings back into text, and we can learn how to do this by learning a decoder for the frozen CLIP text encoder using only text. We argue that this intuition is "almost correct" because of a gap between the embedding spaces, and propose to rectify this via noise injection during training. We demonstrate the effectiveness of our approach by showing SOTA zero-shot image captioning across four benchmarks, including style transfer. Code, data, and models are available on GitHub.
RRSR:Reciprocal Reference-based Image Super-Resolution with Progressive Feature Alignment and Selection
Nov 08, 2022
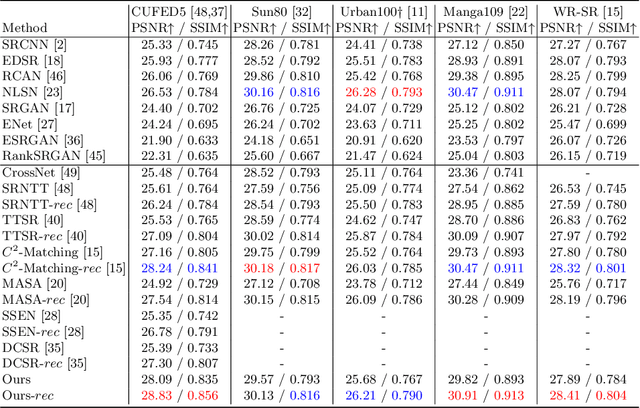
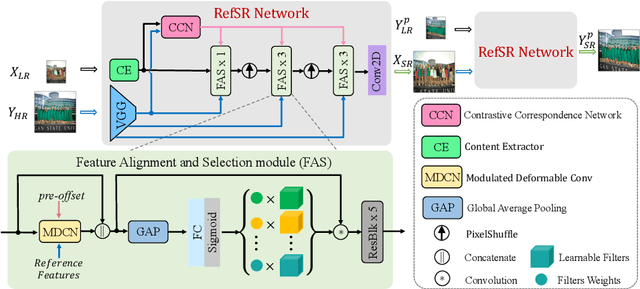

Reference-based image super-resolution (RefSR) is a promising SR branch and has shown great potential in overcoming the limitations of single image super-resolution. While previous state-of-the-art RefSR methods mainly focus on improving the efficacy and robustness of reference feature transfer, it is generally overlooked that a well reconstructed SR image should enable better SR reconstruction for its similar LR images when it is referred to as. Therefore, in this work, we propose a reciprocal learning framework that can appropriately leverage such a fact to reinforce the learning of a RefSR network. Besides, we deliberately design a progressive feature alignment and selection module for further improving the RefSR task. The newly proposed module aligns reference-input images at multi-scale feature spaces and performs reference-aware feature selection in a progressive manner, thus more precise reference features can be transferred into the input features and the network capability is enhanced. Our reciprocal learning paradigm is model-agnostic and it can be applied to arbitrary RefSR models. We empirically show that multiple recent state-of-the-art RefSR models can be consistently improved with our reciprocal learning paradigm. Furthermore, our proposed model together with the reciprocal learning strategy sets new state-of-the-art performances on multiple benchmarks.
Development of A Real-time POCUS Image Quality Assessment and Acquisition Guidance System
Dec 19, 2022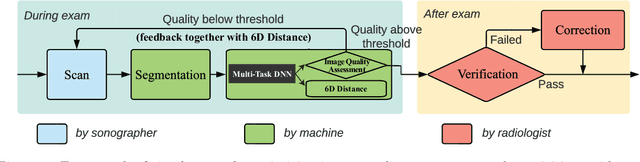
Point-of-care ultrasound (POCUS) is one of the most commonly applied tools for cardiac function imaging in the clinical routine of the emergency department and pediatric intensive care unit. The prior studies demonstrate that AI-assisted software can guide nurses or novices without prior sonography experience to acquire POCUS by recognizing the interest region, assessing image quality, and providing instructions. However, these AI algorithms cannot simply replace the role of skilled sonographers in acquiring diagnostic-quality POCUS. Unlike chest X-ray, CT, and MRI, which have standardized imaging protocols, POCUS can be acquired with high inter-observer variability. Though being with variability, they are usually all clinically acceptable and interpretable. In challenging clinical environments, sonographers employ novel heuristics to acquire POCUS in complex scenarios. To help novice learners to expedite the training process while reducing the dependency on experienced sonographers in the curriculum implementation, We will develop a framework to perform real-time AI-assisted quality assessment and probe position guidance to provide training process for novice learners with less manual intervention.
Learning Distinct and Representative Modes for Image Captioning
Sep 17, 2022



Over the years, state-of-the-art (SoTA) image captioning methods have achieved promising results on some evaluation metrics (e.g., CIDEr). However, recent findings show that the captions generated by these methods tend to be biased toward the "average" caption that only captures the most general mode (a.k.a, language pattern) in the training corpus, i.e., the so-called mode collapse problem. Affected by it, the generated captions are limited in diversity and usually less informative than natural image descriptions made by humans. In this paper, we seek to avoid this problem by proposing a Discrete Mode Learning (DML) paradigm for image captioning. Our innovative idea is to explore the rich modes in the training caption corpus to learn a set of "mode embeddings", and further use them to control the mode of the generated captions for existing image captioning models. Specifically, the proposed DML optimizes a dual architecture that consists of an image-conditioned discrete variational autoencoder (CdVAE) branch and a mode-conditioned image captioning (MIC) branch. The CdVAE branch maps each image caption to one of the mode embeddings stored in a learned codebook, and is trained with a pure non-autoregressive generation objective to make the modes distinct and representative. The MIC branch can be simply modified from an existing image captioning model, where the mode embedding is added to the original word embeddings as the control signal. In the experiments, we apply the proposed DML to two widely used image captioning models, Transformer and AoANet. The results show that the learned mode embedding successfully facilitates these models to generate high-quality image captions with different modes, further leading to better performance for both diversity and quality on the MSCOCO dataset.
Evaluating the Effectiveness of 2D and 3D Features for Predicting Tumor Response to Chemotherapy
Mar 28, 2023
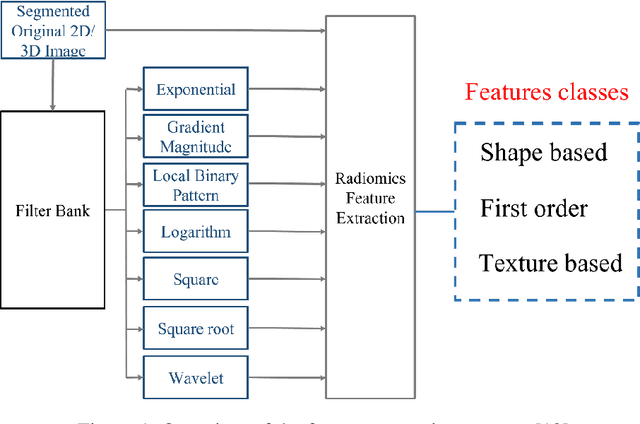

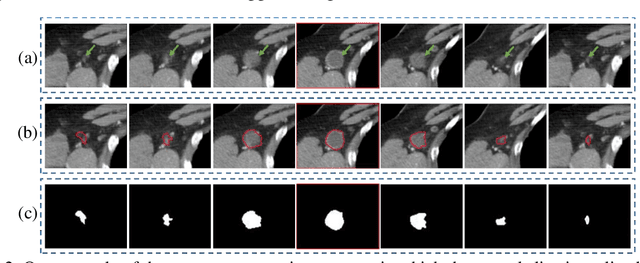
2D and 3D tumor features are widely used in a variety of medical image analysis tasks. However, for chemotherapy response prediction, the effectiveness between different kinds of 2D and 3D features are not comprehensively assessed, especially in ovarian cancer-related applications. This investigation aims to accomplish such a comprehensive evaluation. For this purpose, CT images were collected retrospectively from 188 advanced-stage ovarian cancer patients. All the metastatic tumors that occurred in each patient were segmented and then processed by a set of six filters. Next, three categories of features, namely geometric, density, and texture features, were calculated from both the filtered results and the original segmented tumors, generating a total of 1595 and 1403 features for the 3D and 2D tumors, respectively. In addition to the conventional single-slice 2D and full-volume 3D tumor features, we also computed the incomplete-3D tumor features, which were achieved by sequentially adding one individual CT slice and calculating the corresponding features. Support vector machine (SVM) based prediction models were developed and optimized for each feature set. 5-fold cross-validation was used to assess the performance of each individual model. The results show that the 2D feature-based model achieved an AUC (area under the ROC curve [receiver operating characteristic]) of 0.84+-0.02. When adding more slices, the AUC first increased to reach the maximum and then gradually decreased to 0.86+-0.02. The maximum AUC was yielded when adding two adjacent slices, with a value of 0.91+-0.01. This initial result provides meaningful information for optimizing machine learning-based decision-making support tools in the future.
Virtual Sparse Convolution for Multimodal 3D Object Detection
Mar 04, 2023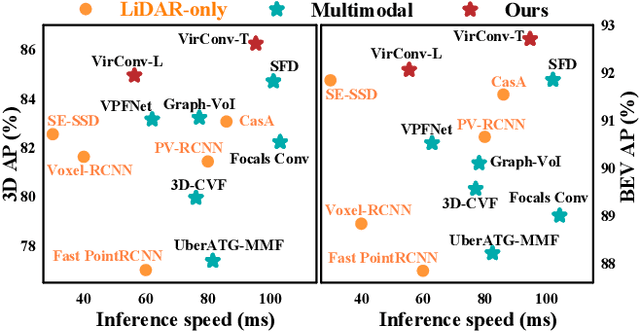
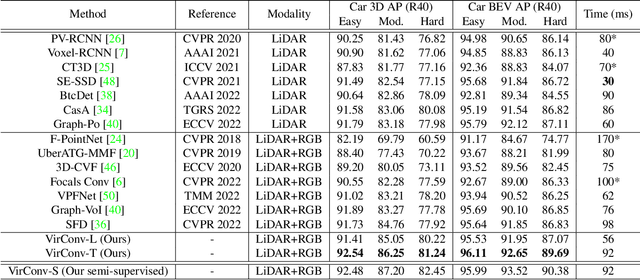
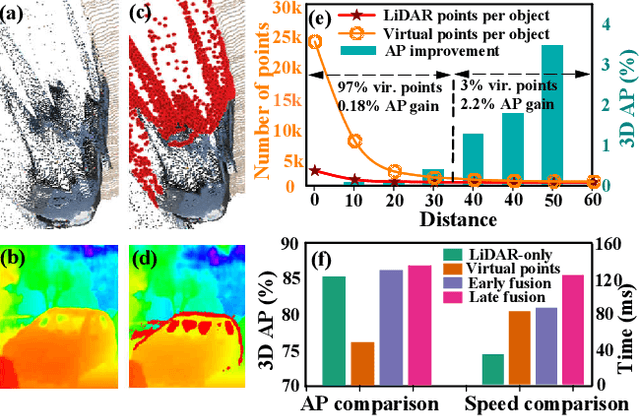
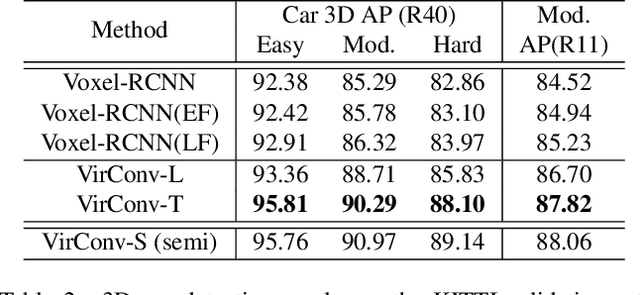
Recently, virtual/pseudo-point-based 3D object detection that seamlessly fuses RGB images and LiDAR data by depth completion has gained great attention. However, virtual points generated from an image are very dense, introducing a huge amount of redundant computation during detection. Meanwhile, noises brought by inaccurate depth completion significantly degrade detection precision. This paper proposes a fast yet effective backbone, termed VirConvNet, based on a new operator VirConv (Virtual Sparse Convolution), for virtual-point-based 3D object detection. VirConv consists of two key designs: (1) StVD (Stochastic Voxel Discard) and (2) NRConv (Noise-Resistant Submanifold Convolution). StVD alleviates the computation problem by discarding large amounts of nearby redundant voxels. NRConv tackles the noise problem by encoding voxel features in both 2D image and 3D LiDAR space. By integrating VirConv, we first develop an efficient pipeline VirConv-L based on an early fusion design. Then, we build a high-precision pipeline VirConv-T based on a transformed refinement scheme. Finally, we develop a semi-supervised pipeline VirConv-S based on a pseudo-label framework. On the KITTI car 3D detection test leaderboard, our VirConv-L achieves 85% AP with a fast running speed of 56ms. Our VirConv-T and VirConv-S attains a high-precision of 86.3% and 87.2% AP, and currently rank 2nd and 1st, respectively. The code is available at https://github.com/hailanyi/VirConv.
Visualizing Transferred Knowledge: An Interpretive Model of Unsupervised Domain Adaptation
Mar 04, 2023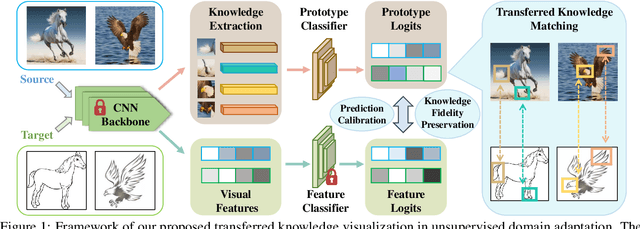
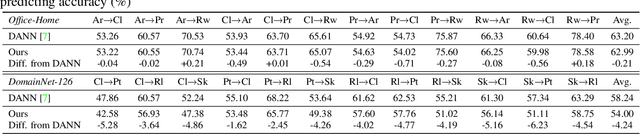
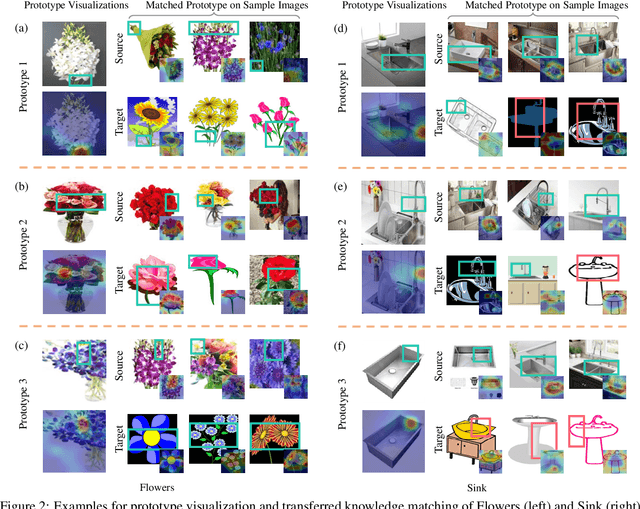
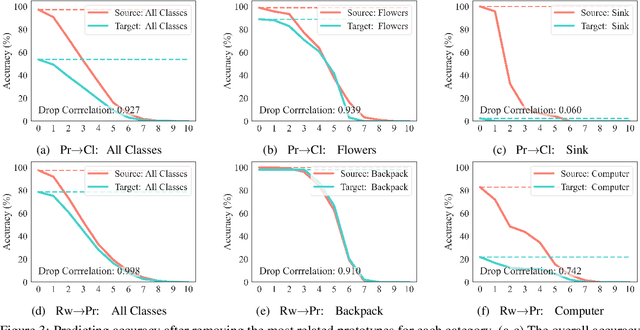
Many research efforts have been committed to unsupervised domain adaptation (DA) problems that transfer knowledge learned from a labeled source domain to an unlabeled target domain. Various DA methods have achieved remarkable results recently in terms of predicting ability, which implies the effectiveness of the aforementioned knowledge transferring. However, state-of-the-art methods rarely probe deeper into the transferred mechanism, leaving the true essence of such knowledge obscure. Recognizing its importance in the adaptation process, we propose an interpretive model of unsupervised domain adaptation, as the first attempt to visually unveil the mystery of transferred knowledge. Adapting the existing concept of the prototype from visual image interpretation to the DA task, our model similarly extracts shared information from the domain-invariant representations as prototype vectors. Furthermore, we extend the current prototype method with our novel prediction calibration and knowledge fidelity preservation modules, to orientate the learned prototypes to the actual transferred knowledge. By visualizing these prototypes, our method not only provides an intuitive explanation for the base model's predictions but also unveils transfer knowledge by matching the image patches with the same semantics across both source and target domains. Comprehensive experiments and in-depth explorations demonstrate the efficacy of our method in understanding the transferred mechanism and its potential in downstream tasks including model diagnosis.
Effective Data Augmentation With Diffusion Models
Feb 07, 2023
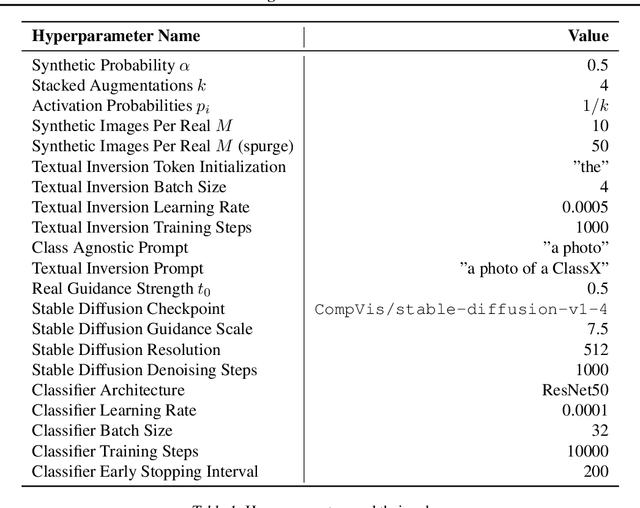


Data augmentation is one of the most prevalent tools in deep learning, underpinning many recent advances, including those from classification, generative models, and representation learning. The standard approach to data augmentation combines simple transformations like rotations and flips to generate new images from existing ones. However, these new images lack diversity along key semantic axes present in the data. Consider the task of recognizing different animals. Current augmentations fail to produce diversity in task-relevant high-level semantic attributes like the species of the animal. We address the lack of diversity in data augmentation with image-to-image transformations parameterized by pre-trained text-to-image diffusion models. Our method edits images to change their semantics using an off-the-shelf diffusion model, and generalizes to novel visual concepts from a few labelled examples. We evaluate our approach on image classification tasks in a few-shot setting, and on a real-world weed recognition task, and observe an improvement in accuracy in tested domains.
MI-SegNet: Mutual Information-Based US Segmentation for Unseen Domain Generalization
Mar 22, 2023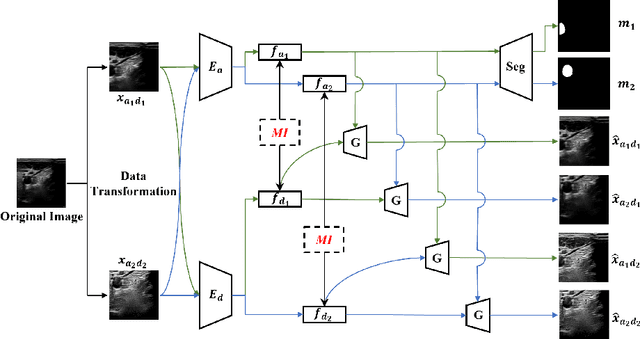
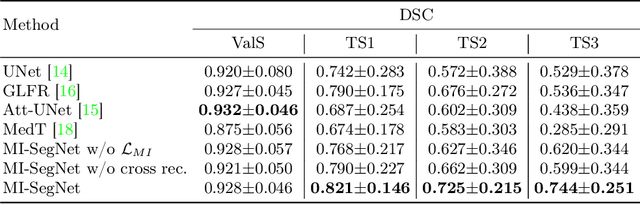

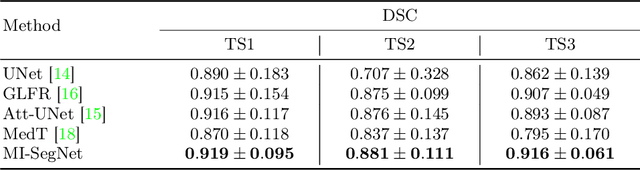
Generalization capabilities of learning-based medical image segmentation across domains are currently limited by the performance degradation caused by the domain shift, particularly for ultrasound (US) imaging. The quality of US images heavily relies on carefully tuned acoustic parameters, which vary across sonographers, machines, and settings. To improve the generalizability on US images across domains, we propose MI-SegNet, a novel mutual information (MI) based framework to explicitly disentangle the anatomical and domain feature representations; therefore, robust domain-independent segmentation can be expected. Two encoders are employed to extract the relevant features for the disentanglement. The segmentation only uses the anatomical feature map for its prediction. In order to force the encoders to learn meaningful feature representations a cross-reconstruction method is used during training. Transformations, specific to either domain or anatomy are applied to guide the encoders in their respective feature extraction task. Additionally, any MI present in both feature maps is punished to further promote separate feature spaces. We validate the generalizability of the proposed domain-independent segmentation approach on several datasets with varying parameters and machines. Furthermore, we demonstrate the effectiveness of the proposed MI-SegNet serving as a pre-trained model by comparing it with state-of-the-art networks.
StyO: Stylize Your Face in Only One-Shot
Mar 07, 2023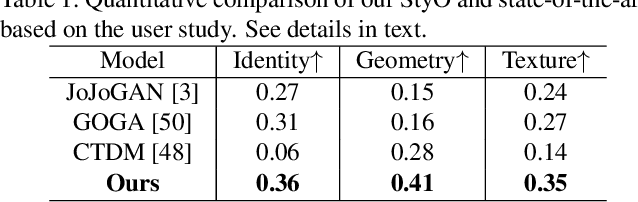
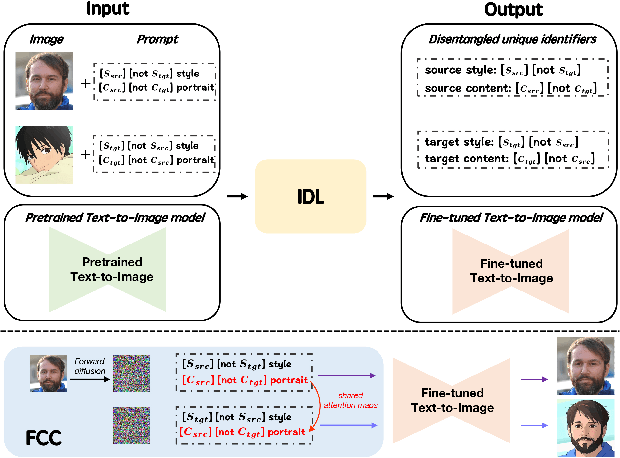
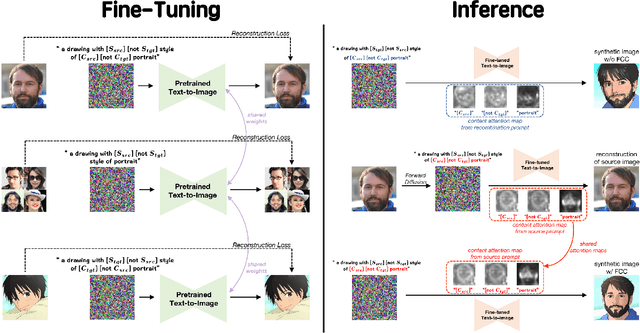

This paper focuses on face stylization with a single artistic target. Existing works for this task often fail to retain the source content while achieving geometry variation. Here, we present a novel StyO model, ie. Stylize the face in only One-shot, to solve the above problem. In particular, StyO exploits a disentanglement and recombination strategy. It first disentangles the content and style of source and target images into identifiers, which are then recombined in a cross manner to derive the stylized face image. In this way, StyO decomposes complex images into independent and specific attributes, and simplifies one-shot face stylization as the combination of different attributes from input images, thus producing results better matching face geometry of target image and content of source one. StyO is implemented with latent diffusion models (LDM) and composed of two key modules: 1) Identifier Disentanglement Learner (IDL) for disentanglement phase. It represents identifiers as contrastive text prompts, ie. positive and negative descriptions. And it introduces a novel triple reconstruction loss to fine-tune the pre-trained LDM for encoding style and content into corresponding identifiers; 2) Fine-grained Content Controller (FCC) for the recombination phase. It recombines disentangled identifiers from IDL to form an augmented text prompt for generating stylized faces. In addition, FCC also constrains the cross-attention maps of latent and text features to preserve source face details in results. The extensive evaluation shows that StyO produces high-quality images on numerous paintings of various styles and outperforms the current state-of-the-art. Code will be released upon acceptance.