 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Decision-BADGE: Decision-based Adversarial Batch Attack with Directional Gradient Estimation
Mar 09, 2023
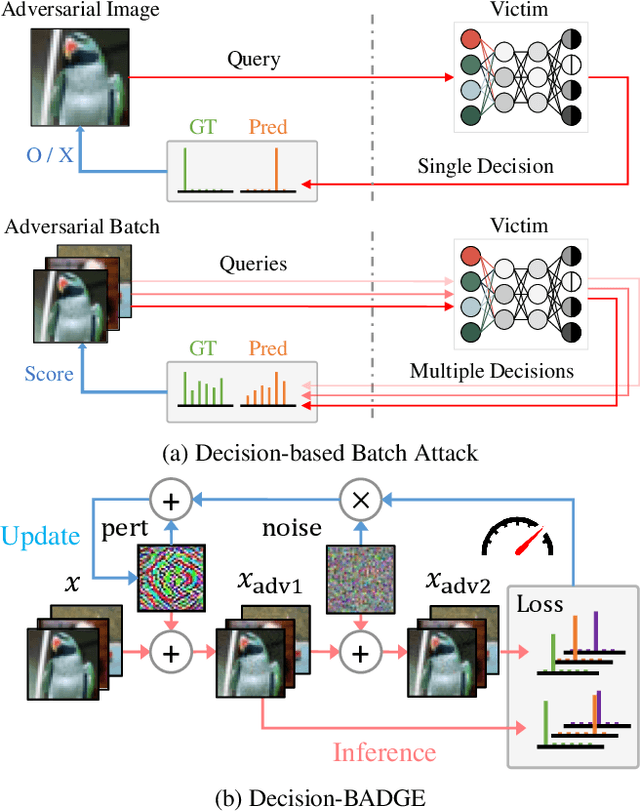

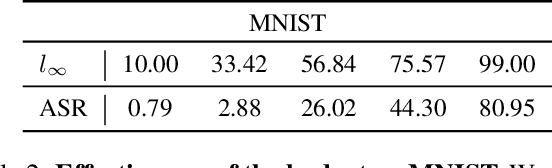
The vulnerability of deep neural networks to adversarial examples has led to the rise in the use of adversarial attacks. While various decision-based and universal attack methods have been proposed, none have attempted to create a decision-based universal adversarial attack. This research proposes Decision-BADGE, which uses random gradient-free optimization and batch attack to generate universal adversarial perturbations for decision-based attacks. Multiple adversarial examples are combined to optimize a single universal perturbation, and the accuracy metric is reformulated into a continuous Hamming distance form. The effectiveness of accuracy metric as a loss function is demonstrated and mathematically proven. The combination of Decision-BADGE and the accuracy loss function performs better than both score-based image-dependent attack and white-box universal attack methods in terms of attack time efficiency. The research also shows that Decision-BADGE can successfully deceive unseen victims and accurately target specific classes.
Image Compression With Learned Lifting-Based DWT and Learned Tree-Based Entropy Models
Dec 07, 2022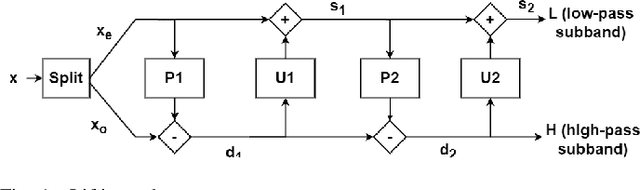
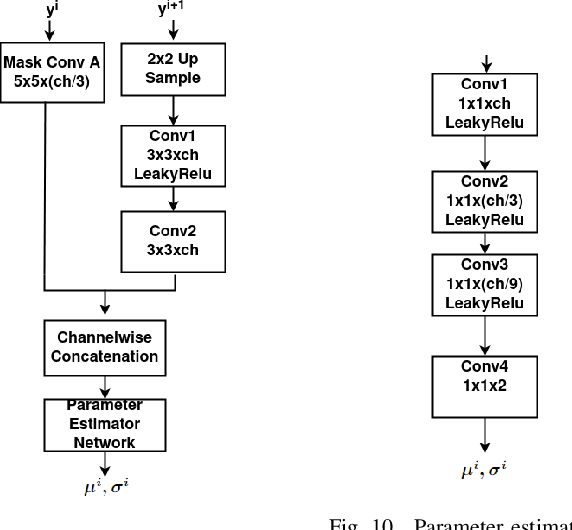
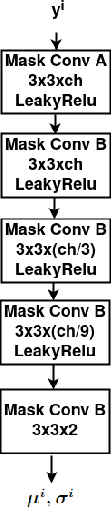
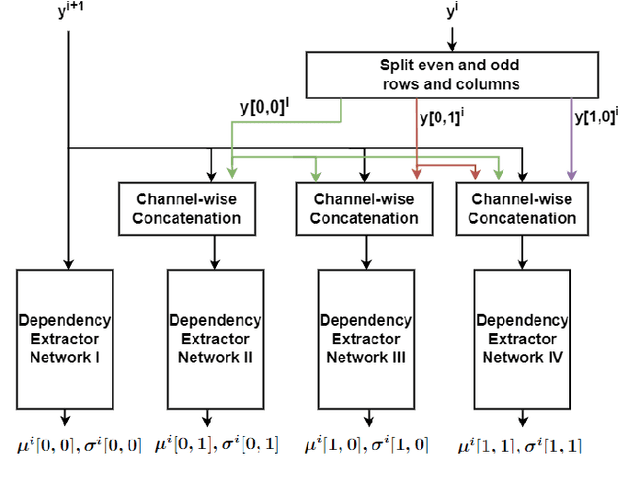
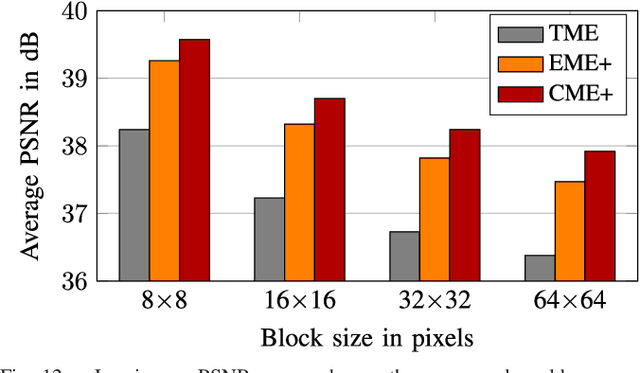
This paper explores learned image compression based on traditional and learned discrete wavelet transform (DWT) architectures and learned entropy models for coding DWT subband coefficients. A learned DWT is obtained through the lifting scheme with learned nonlinear predict and update filters. Several learned entropy models are proposed to exploit inter and intra-DWT subband coefficient dependencies, akin to traditional EZW, SPIHT, or EBCOT algorithms. Experimental results show that when the proposed learned entropy models are combined with traditional wavelet filters, such as the CDF 9/7 filters, compression performance that far exceeds that of JPEG2000 can be achieved. When the learned entropy models are combined with the learned DWT, compression performance increases further. The computations in the learned DWT and all entropy models, except one, can be simply parallelized, and the systems provide practical encoding and decoding times on GPUs.
Motion Estimation for Fisheye Video With an Application to Temporal Resolution Enhancement
Mar 01, 2023


Surveying wide areas with only one camera is a typical scenario in surveillance and automotive applications. Ultra wide-angle fisheye cameras employed to that end produce video data with characteristics that differ significantly from conventional rectilinear imagery as obtained by perspective pinhole cameras. Those characteristics are not considered in typical image and video processing algorithms such as motion estimation, where translation is assumed to be the predominant kind of motion. This contribution introduces an adapted technique for use in block-based motion estimation that takes into the account the projection function of fisheye cameras and thus compensates for the non-perspective properties of fisheye videos. By including suitable projections, the translational motion model that would otherwise only hold for perspective material is exploited, leading to improved motion estimation results without altering the source material. In addition, we discuss extensions that allow for a better prediction of the peripheral image areas, where motion estimation falters due to spatial constraints, and further include calibration information to account for lens properties deviating from the theoretical function. Simulations and experiments are conducted on synthetic as well as real-world fisheye video sequences that are part of a data set created in the context of this paper. Average synthetic and real-world gains of 1.45 and 1.51 dB in luminance PSNR are achieved compared against conventional block matching. Furthermore, the proposed fisheye motion estimation method is successfully applied to motion compensated temporal resolution enhancement, where average gains amount to 0.79 and 0.76 dB.
Considering Image Information and Self-similarity: A Compositional Denoising Network
Sep 14, 2022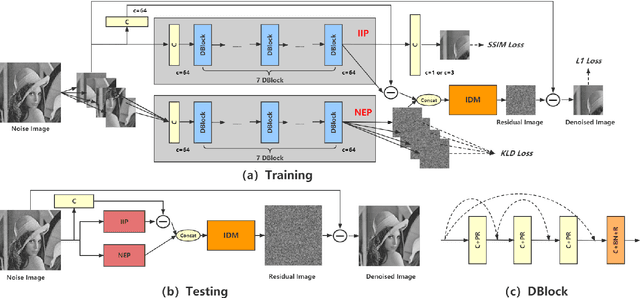
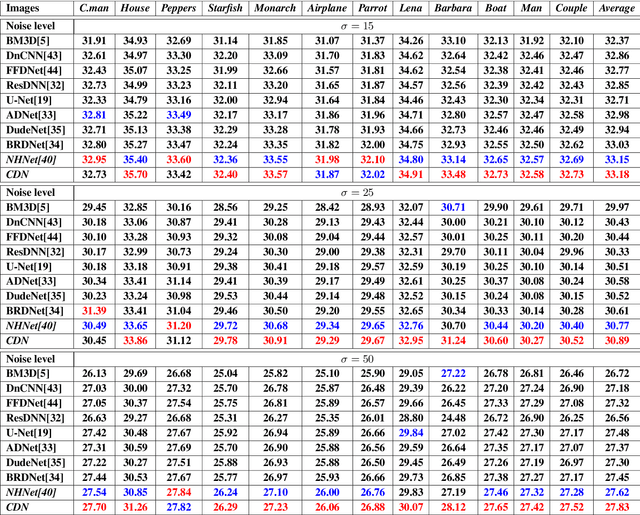
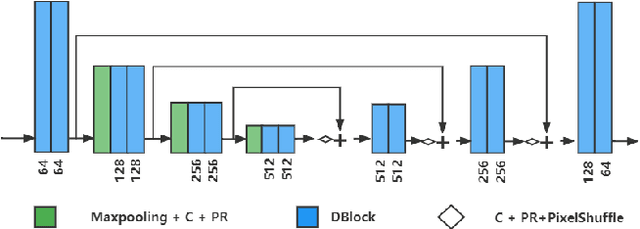

Recently, convolutional neural networks (CNNs) have been widely used in image denoising. Existing methods benefited from residual learning and achieved high performance. Much research has been paid attention to optimizing the network architecture of CNN but ignored the limitations of residual learning. This paper suggests two limitations of it. One is that residual learning focuses on estimating noise, thus overlooking the image information. The other is that the image self-similarity is not effectively considered. This paper proposes a compositional denoising network (CDN), whose image information path (IIP) and noise estimation path (NEP) will solve the two problems, respectively. IIP is trained by an image-to-image way to extract image information. For NEP, it utilizes the image self-similarity from the perspective of training. This similarity-based training method constrains NEP to output a similar estimated noise distribution for different image patches with a specific kind of noise. Finally, image information and noise distribution information will be comprehensively considered for image denoising. Experiments show that CDN achieves state-of-the-art results in synthetic and real-world image denoising. Our code will be released on https://github.com/JiaHongZ/CDN.
Dreamix: Video Diffusion Models are General Video Editors
Feb 02, 2023

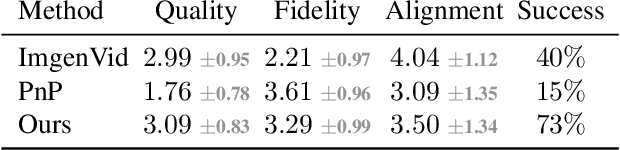
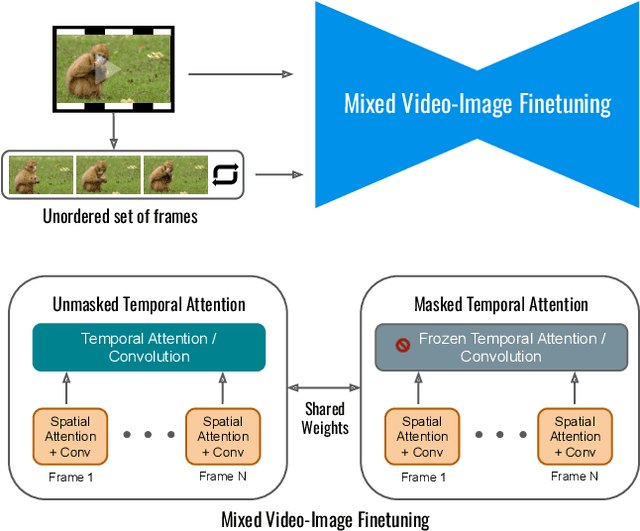
Text-driven image and video diffusion models have recently achieved unprecedented generation realism. While diffusion models have been successfully applied for image editing, very few works have done so for video editing. We present the first diffusion-based method that is able to perform text-based motion and appearance editing of general videos. Our approach uses a video diffusion model to combine, at inference time, the low-resolution spatio-temporal information from the original video with new, high resolution information that it synthesized to align with the guiding text prompt. As obtaining high-fidelity to the original video requires retaining some of its high-resolution information, we add a preliminary stage of finetuning the model on the original video, significantly boosting fidelity. We propose to improve motion editability by a new, mixed objective that jointly finetunes with full temporal attention and with temporal attention masking. We further introduce a new framework for image animation. We first transform the image into a coarse video by simple image processing operations such as replication and perspective geometric projections, and then use our general video editor to animate it. As a further application, we can use our method for subject-driven video generation. Extensive qualitative and numerical experiments showcase the remarkable editing ability of our method and establish its superior performance compared to baseline methods.
Is forgetting less a good inductive bias for forward transfer?
Mar 14, 2023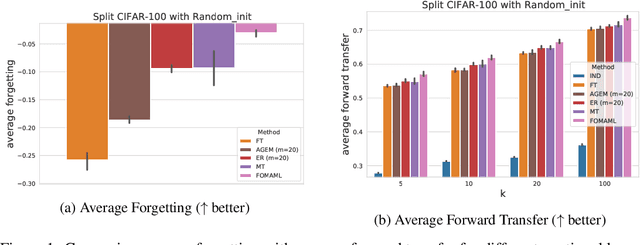
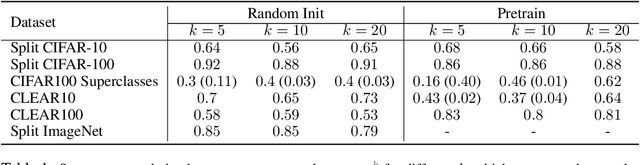
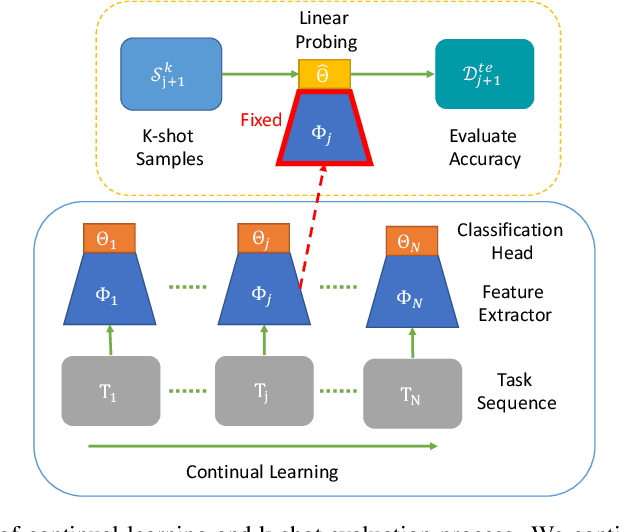
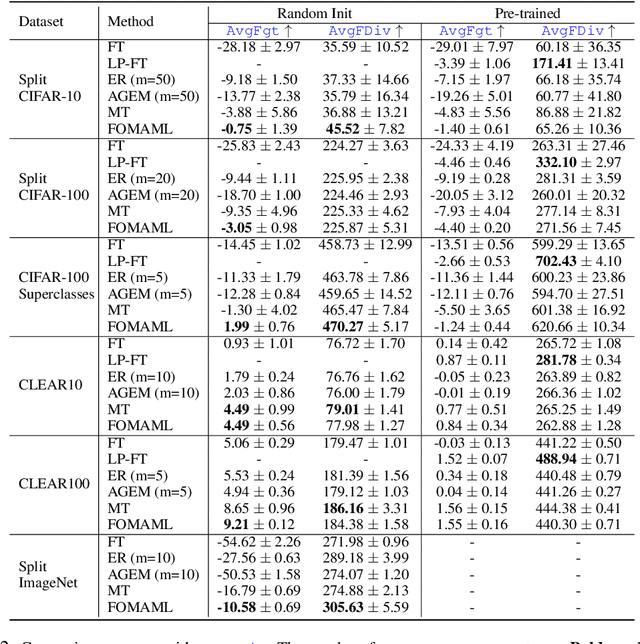
One of the main motivations of studying continual learning is that the problem setting allows a model to accrue knowledge from past tasks to learn new tasks more efficiently. However, recent studies suggest that the key metric that continual learning algorithms optimize, reduction in catastrophic forgetting, does not correlate well with the forward transfer of knowledge. We believe that the conclusion previous works reached is due to the way they measure forward transfer. We argue that the measure of forward transfer to a task should not be affected by the restrictions placed on the continual learner in order to preserve knowledge of previous tasks. Instead, forward transfer should be measured by how easy it is to learn a new task given a set of representations produced by continual learning on previous tasks. Under this notion of forward transfer, we evaluate different continual learning algorithms on a variety of image classification benchmarks. Our results indicate that less forgetful representations lead to a better forward transfer suggesting a strong correlation between retaining past information and learning efficiency on new tasks. Further, we found less forgetful representations to be more diverse and discriminative compared to their forgetful counterparts.
* Published as a conference paper at ICLR 2023
DynaMask: Dynamic Mask Selection for Instance Segmentation
Mar 14, 2023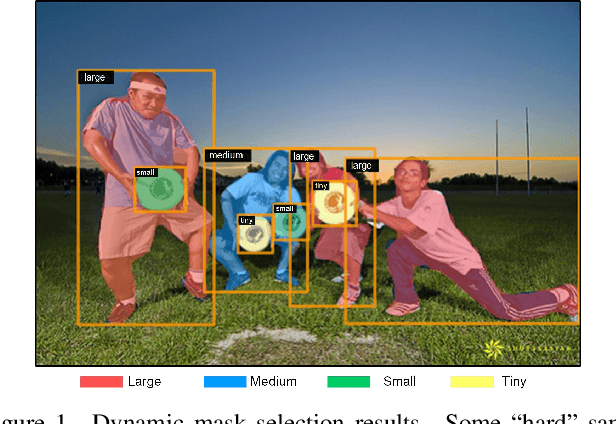
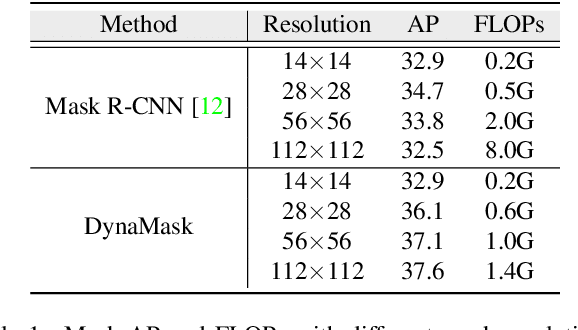
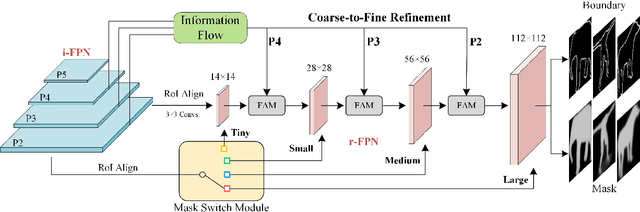
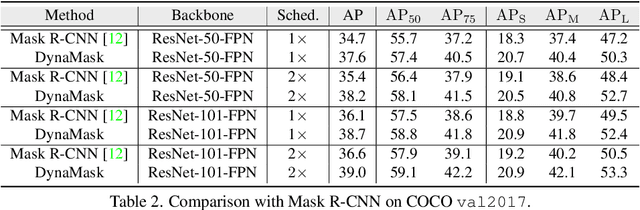
The representative instance segmentation methods mostly segment different object instances with a mask of the fixed resolution, e.g., 28*28 grid. However, a low-resolution mask loses rich details, while a high-resolution mask incurs quadratic computation overhead. It is a challenging task to predict the optimal binary mask for each instance. In this paper, we propose to dynamically select suitable masks for different object proposals. First, a dual-level Feature Pyramid Network (FPN) with adaptive feature aggregation is developed to gradually increase the mask grid resolution, ensuring high-quality segmentation of objects. Specifically, an efficient region-level top-down path (r-FPN) is introduced to incorporate complementary contextual and detailed information from different stages of image-level FPN (i-FPN). Then, to alleviate the increase of computation and memory costs caused by using large masks, we develop a Mask Switch Module (MSM) with negligible computational cost to select the most suitable mask resolution for each instance, achieving high efficiency while maintaining high segmentation accuracy. Without bells and whistles, the proposed method, namely DynaMask, brings consistent and noticeable performance improvements over other state-of-the-arts at a moderate computation overhead. The source code: https://github.com/lslrh/DynaMask.
SIM: Semantic-aware Instance Mask Generation for Box-Supervised Instance Segmentation
Mar 14, 2023
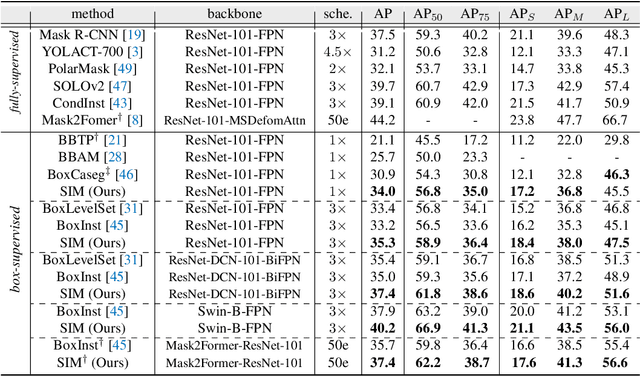
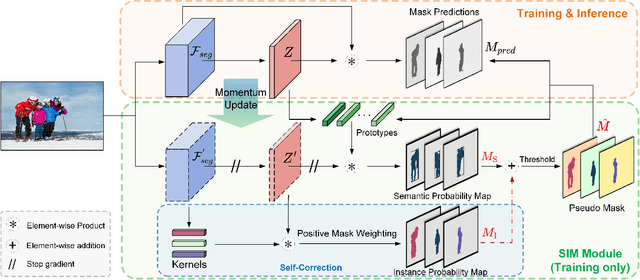
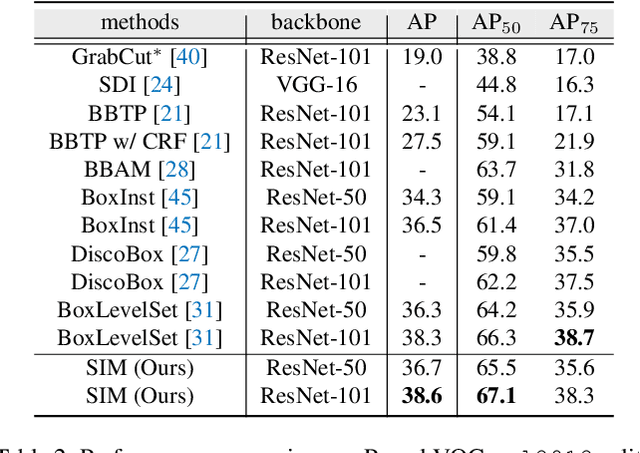
Weakly supervised instance segmentation using only bounding box annotations has recently attracted much research attention. Most of the current efforts leverage low-level image features as extra supervision without explicitly exploiting the high-level semantic information of the objects, which will become ineffective when the foreground objects have similar appearances to the background or other objects nearby. We propose a new box-supervised instance segmentation approach by developing a Semantic-aware Instance Mask (SIM) generation paradigm. Instead of heavily relying on local pair-wise affinities among neighboring pixels, we construct a group of category-wise feature centroids as prototypes to identify foreground objects and assign them semantic-level pseudo labels. Considering that the semantic-aware prototypes cannot distinguish different instances of the same semantics, we propose a self-correction mechanism to rectify the falsely activated regions while enhancing the correct ones. Furthermore, to handle the occlusions between objects, we tailor the Copy-Paste operation for the weakly-supervised instance segmentation task to augment challenging training data. Extensive experimental results demonstrate the superiority of our proposed SIM approach over other state-of-the-art methods. The source code: https://github.com/lslrh/SIM.
Sample-efficient Adversarial Imitation Learning
Mar 14, 2023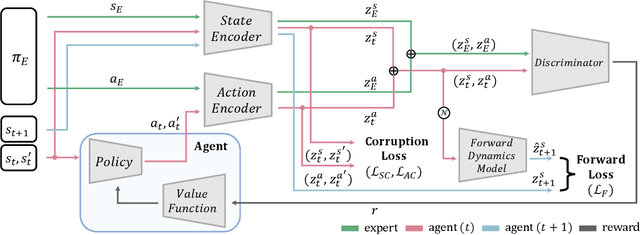


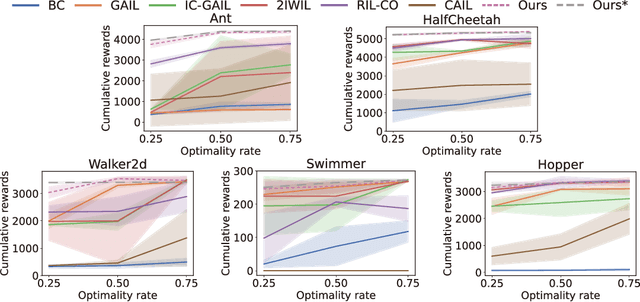
Imitation learning, in which learning is performed by demonstration, has been studied and advanced for sequential decision-making tasks in which a reward function is not predefined. However, imitation learning methods still require numerous expert demonstration samples to successfully imitate an expert's behavior. To improve sample efficiency, we utilize self-supervised representation learning, which can generate vast training signals from the given data. In this study, we propose a self-supervised representation-based adversarial imitation learning method to learn state and action representations that are robust to diverse distortions and temporally predictive, on non-image control tasks. In particular, in comparison with existing self-supervised learning methods for tabular data, we propose a different corruption method for state and action representations that is robust to diverse distortions. We theoretically and empirically observe that making an informative feature manifold with less sample complexity significantly improves the performance of imitation learning. The proposed method shows a 39% relative improvement over existing adversarial imitation learning methods on MuJoCo in a setting limited to 100 expert state-action pairs. Moreover, we conduct comprehensive ablations and additional experiments using demonstrations with varying optimality to provide insights into a range of factors.
Robotic Fabric Flattening with Wrinkle Direction Detection
Mar 10, 2023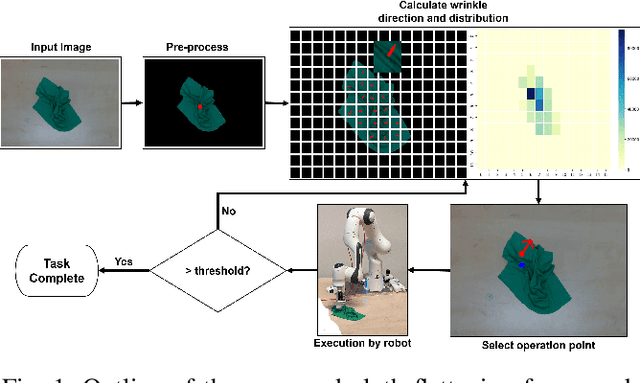

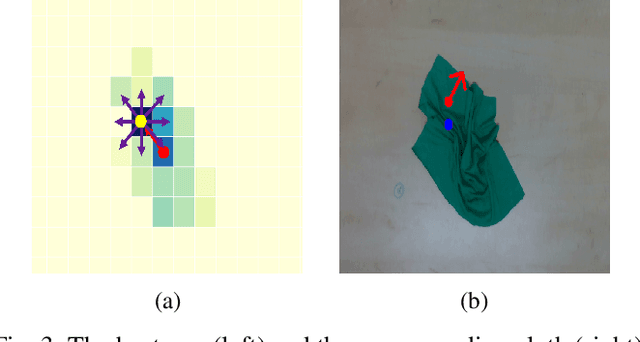
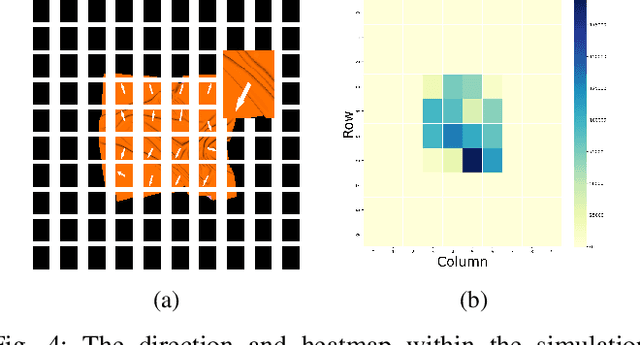
Deformable Object Manipulation (DOM) is an important field of research as it contributes to practical tasks such as automatic cloth handling, cable routing, surgical operation, etc. Perception is considered one of the major challenges in DOM due to the complex dynamics and high degree of freedom of deformable objects. In this paper, we develop a novel image-processing algorithm based on Gabor filters to extract useful features from cloth, and based on this, devise a strategy for cloth flattening tasks. We evaluate the overall framework experimentally, and compare it with three human operators. The results show that our algorithm can determine the direction of wrinkles on the cloth accurately in the simulation as well as the real robot experiments. Besides, the robot executing the flattening tasks using the dewrinkling strategy given by our algorithm achieves satisfying performance compared to other baseline methods. The experiment video is available on https://sites.google.com/view/robotic-fabric-flattening/home