 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interpretable ODE-style Generative Diffusion Model via Force Field Construction
Mar 15, 2023
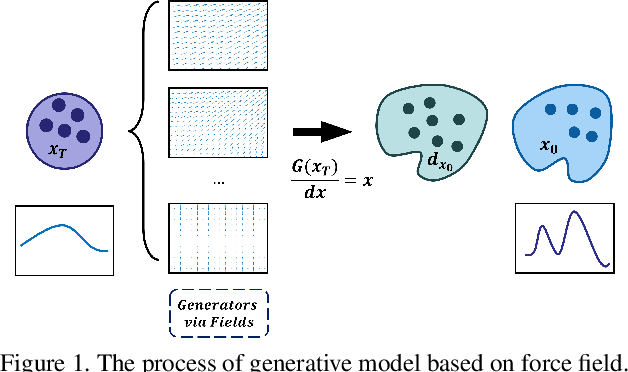
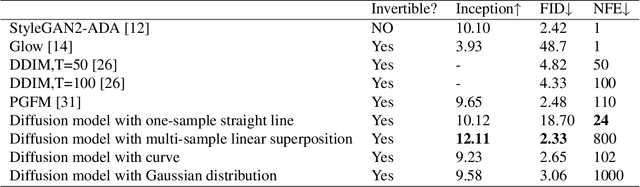

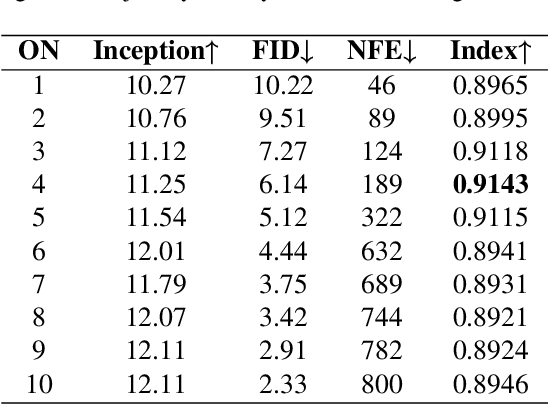
For a considerable time, researchers have focused on developing a method that establishes a deep connection between the generative diffusion model and mathematical physics. Despite previous efforts, progress has been limited to the pursuit of a single specialized method. In order to advance the interpretability of diffusion models and explore new research directions, it is essential to establish a unified ODE-style generative diffusion model. Such a model should draw inspiration from physical models and possess a clear geometric meaning. This paper aims to identify various physical models that are suitable for constructing ODE-style generative diffusion models accurately from a mathematical perspective. We then summarize these models into a unified method. Additionally, we perform a case study where we use the theoretical model identified by our method to develop a range of new diffusion model methods, and conduct experiments. Our experiments on CIFAR-10 demonstrate the effectiveness of our approach. We have constructed a computational framework that attains highly proficient results with regards to image generation speed, alongside an additional model that demonstrates exceptional performance in both Inception score and FID score. These results underscore the significance of our method in advancing the field of diffusion models.
Accelerating Diffusion Models via Pre-segmentation Diffusion Sampling for Medical Image Segmentation
Oct 27, 2022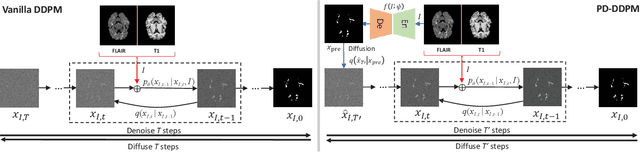
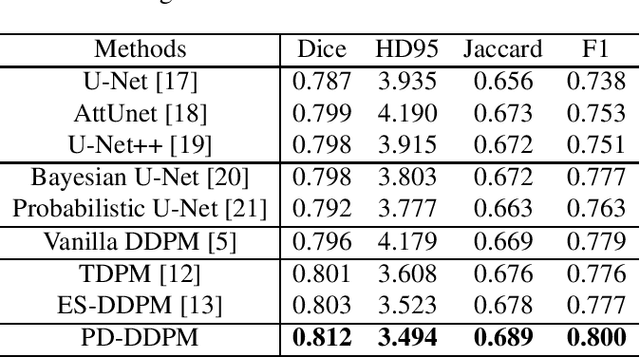

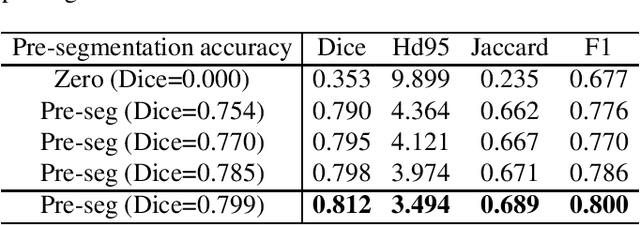
Based on the Denoising Diffusion Probabilistic Model (DDPM), medical image segmentation can be described as a conditional image generation task, which allows to compute pixel-wise uncertainty maps of the segmentation and allows an implicit ensemble of segmentations to boost the segmentation performance. However, DDPM requires many iterative denoising steps to generate segmentations from Gaussian noise, resulting in extremely inefficient inference. To mitigate the issue, we propose a principled acceleration strategy, called pre-segmentation diffusion sampling DDPM (PD-DDPM), which is specially used for medical image segmentation. The key idea is to obtain pre-segmentation results based on a separately trained segmentation network, and construct noise predictions (non-Gaussian distribution) according to the forward diffusion rule. We can then start with noisy predictions and use fewer reverse steps to generate segmentation results. Experiments show that PD-DDPM yields better segmentation results over representative baseline methods even if the number of reverse steps is significantly reduced. Moreover, PD-DDPM is orthogonal to existing advanced segmentation models, which can be combined to further improve the segmentation performance.
Spiking sampling network for image sparse representation and dynamic vision sensor data compression
Nov 08, 2022
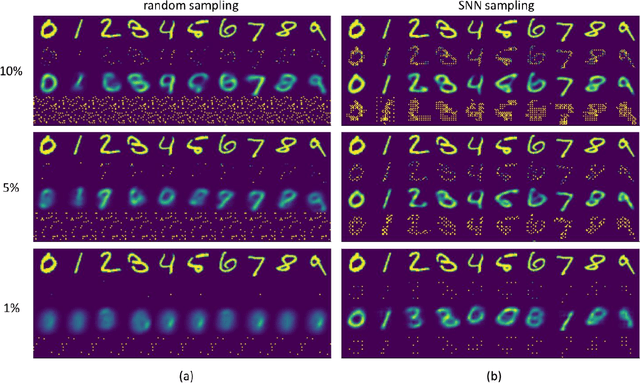
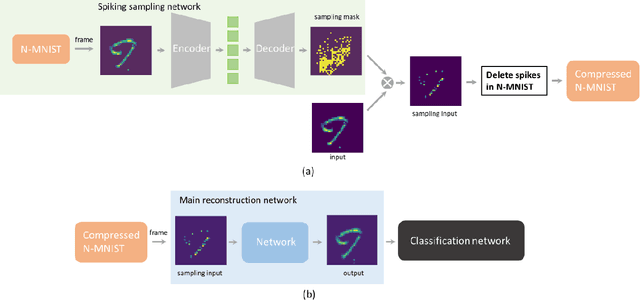
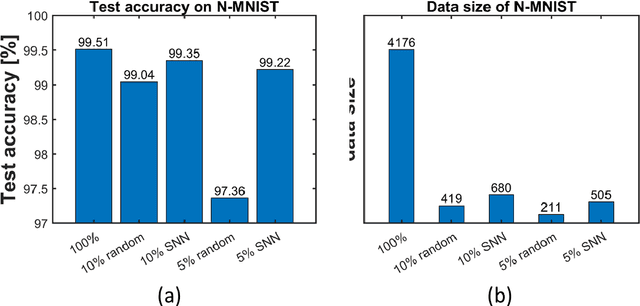
Sparse representation has attracted great attention because it can greatly save storage resources and find representative features of data in a low-dimensional space. As a result, it may be widely applied in engineering domains including feature extraction, compressed sensing, signal denoising, picture clustering, and dictionary learning, just to name a few. In this paper, we propose a spiking sampling network. This network is composed of spiking neurons, and it can dynamically decide which pixel points should be retained and which ones need to be masked according to the input. Our experiments demonstrate that this approach enables better sparse representation of the original image and facilitates image reconstruction compared to random sampling. We thus use this approach for compressing massive data from the dynamic vision sensor, which greatly reduces the storage requirements for event data.
DarkVisionNet: Low-Light Imaging via RGB-NIR Fusion with Deep Inconsistency Prior
Mar 13, 2023
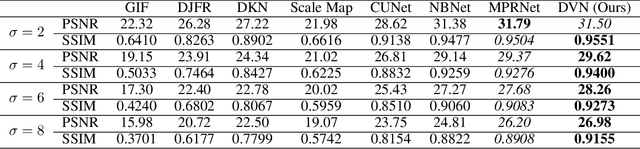
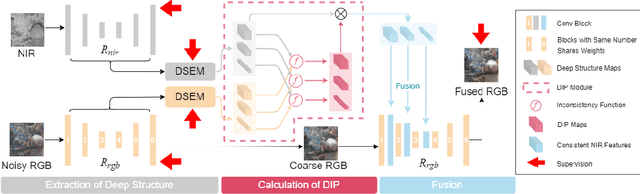
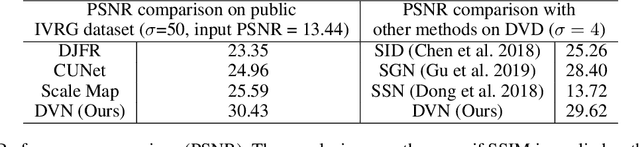
RGB-NIR fusion is a promising method for low-light imaging. However, high-intensity noise in low-light images amplifies the effect of structure inconsistency between RGB-NIR images, which fails existing algorithms. To handle this, we propose a new RGB-NIR fusion algorithm called Dark Vision Net (DVN) with two technical novelties: Deep Structure and Deep Inconsistency Prior (DIP). The Deep Structure extracts clear structure details in deep multiscale feature space rather than raw input space, which is more robust to noisy inputs. Based on the deep structures from both RGB and NIR domains, we introduce the DIP to leverage the structure inconsistency to guide the fusion of RGB-NIR. Benefiting from this, the proposed DVN obtains high-quality lowlight images without the visual artifacts. We also propose a new dataset called Dark Vision Dataset (DVD), consisting of aligned RGB-NIR image pairs, as the first public RGBNIR fusion benchmark. Quantitative and qualitative results on the proposed benchmark show that DVN significantly outperforms other comparison algorithms in PSNR and SSIM, especially in extremely low light conditions.
Erasing Concepts from Diffusion Models
Mar 13, 2023
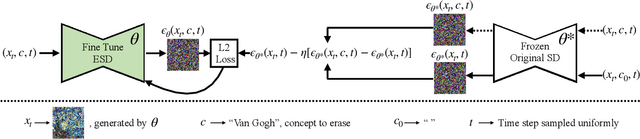
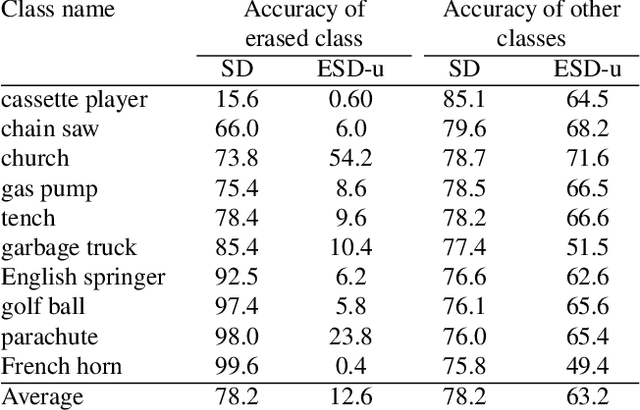

Motivated by recent advancements in text-to-image diffusion, we study erasure of specific concepts from the model's weights. While Stable Diffusion has shown promise in producing explicit or realistic artwork, it has raised concerns regarding its potential for misuse. We propose a fine-tuning method that can erase a visual concept from a pre-trained diffusion model, given only the name of the style and using negative guidance as a teacher. We benchmark our method against previous approaches that remove sexually explicit content and demonstrate its effectiveness, performing on par with Safe Latent Diffusion and censored training. To evaluate artistic style removal, we conduct experiments erasing five modern artists from the network and conduct a user study to assess the human perception of the removed styles. Unlike previous methods, our approach can remove concepts from a diffusion model permanently rather than modifying the output at the inference time, so it cannot be circumvented even if a user has access to model weights. Our code, data, and results are available at https://erasing.baulab.info/
Unsupervised Representation Learning in Partially Observable Atari Games
Mar 13, 2023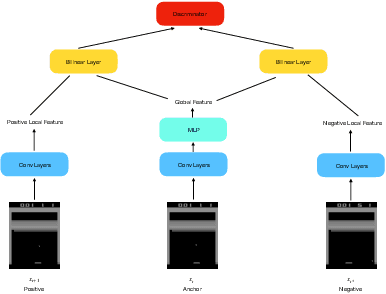

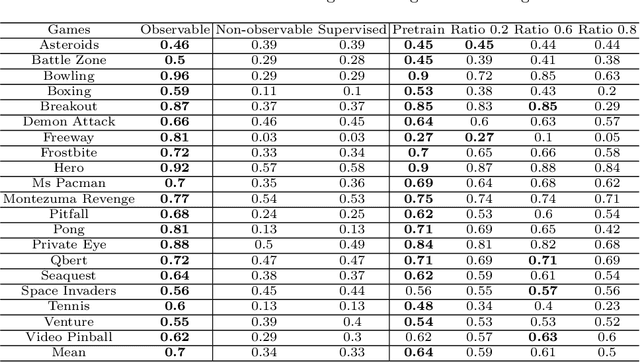
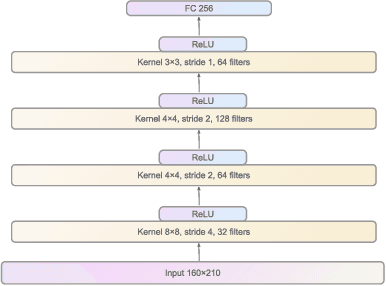
State representation learning aims to capture latent factors of an environment. Contrastive methods have performed better than generative models in previous state representation learning research. Although some researchers realize the connections between masked image modeling and contrastive representation learning, the effort is focused on using masks as an augmentation technique to represent the latent generative factors better. Partially observable environments in reinforcement learning have not yet been carefully studied using unsupervised state representation learning methods. In this article, we create an unsupervised state representation learning scheme for partially observable states. We conducted our experiment on a previous Atari 2600 framework designed to evaluate representation learning models. A contrastive method called Spatiotemporal DeepInfomax (ST-DIM) has shown state-of-the-art performance on this benchmark but remains inferior to its supervised counterpart. Our approach improves ST-DIM when the environment is not fully observable and achieves higher F1 scores and accuracy scores than the supervised learning counterpart. The mean accuracy score averaged over categories of our approach is ~66%, compared to ~38% of supervised learning. The mean F1 score is ~64% to ~33%.
Schrödinger's Camera: First Steps Towards a Quantum-Based Privacy Preserving Camera
Mar 13, 2023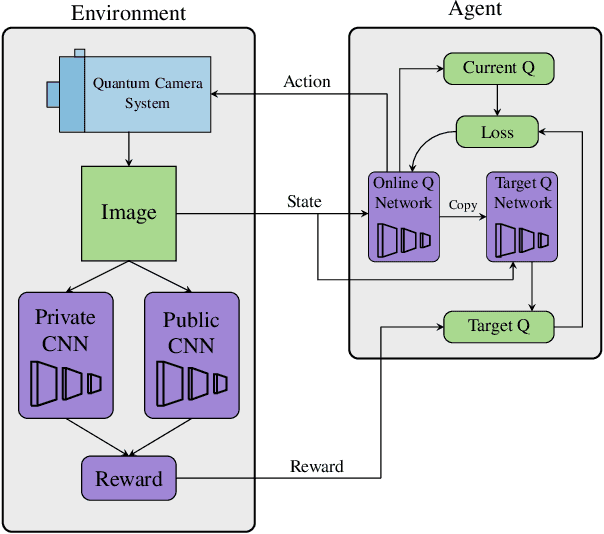

Privacy-preserving vision must overcome the dual challenge of utility and privacy. Too much anonymity renders the images useless, but too little privacy does not protect sensitive data. We propose a novel design for privacy preservation, where the imagery is stored in quantum states. In the future, this will be enabled by quantum imaging cameras, and, currently, storing very low resolution imagery in quantum states is possible. Quantum state imagery has the advantage of being both private and non-private till the point of measurement. This occurs even when images are manipulated, since every quantum action is fully reversible. We propose a control algorithm, based on double deep Q-learning, to learn how to anonymize the image before measurement. After learning, the RL weights are fixed, and new attack neural networks are trained from scratch to break the system's privacy. Although all our results are in simulation, we demonstrate, with these first steps, that it is possible to control both privacy and utility in a quantum-based manner.
DiffusionDepth: Diffusion Denoising Approach for Monocular Depth Estimation
Mar 13, 2023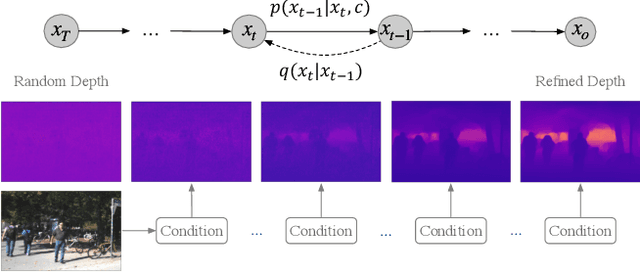
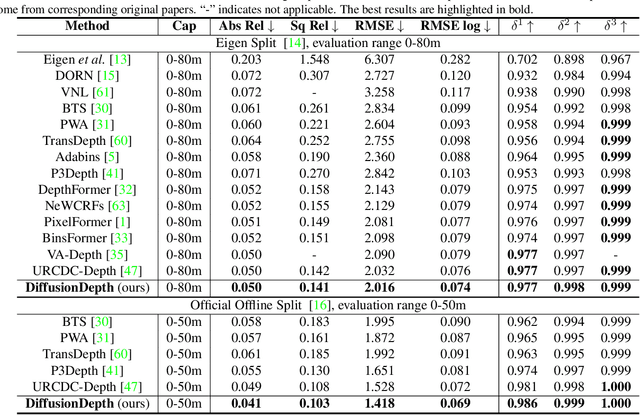
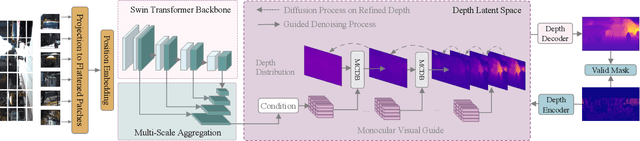
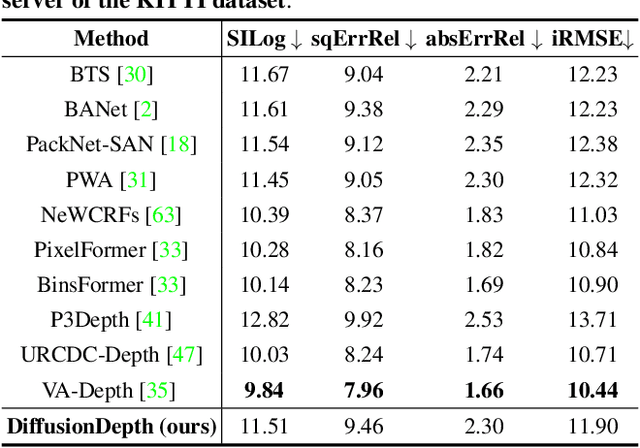
Monocular depth estimation is a challenging task that predicts the pixel-wise depth from a single 2D image. Current methods typically model this problem as a regression or classification task. We propose DiffusionDepth, a new approach that reformulates monocular depth estimation as a denoising diffusion process. It learns an iterative denoising process to `denoise' random depth distribution into a depth map with the guidance of monocular visual conditions. The process is performed in the latent space encoded by a dedicated depth encoder and decoder. Instead of diffusing ground truth (GT) depth, the model learns to reverse the process of diffusing the refined depth of itself into random depth distribution. This self-diffusion formulation overcomes the difficulty of applying generative models to sparse GT depth scenarios. The proposed approach benefits this task by refining depth estimation step by step, which is superior for generating accurate and highly detailed depth maps. Experimental results on KITTI and NYU-Depth-V2 datasets suggest that a simple yet efficient diffusion approach could reach state-of-the-art performance in both indoor and outdoor scenarios with acceptable inference time.
LocalEyenet: Deep Attention framework for Localization of Eyes
Mar 13, 2023
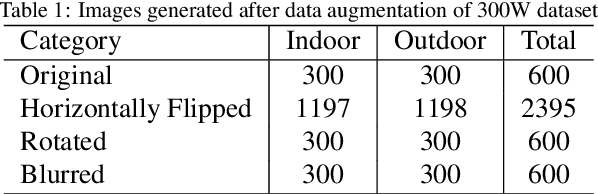
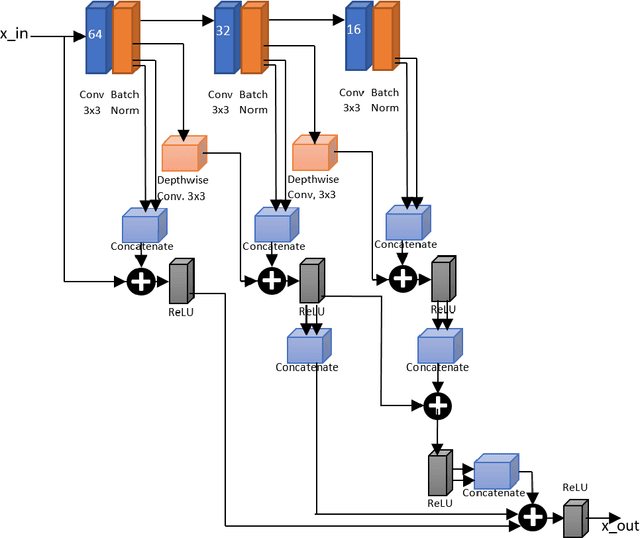
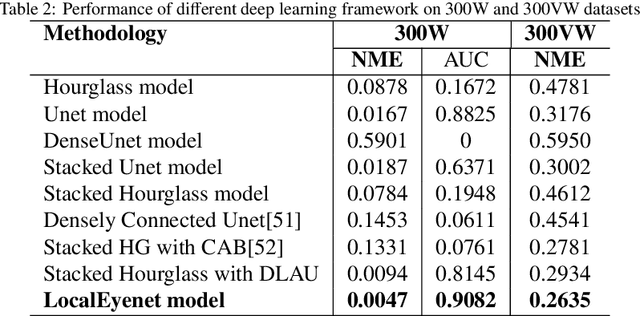
Development of human machine interface has become a necessity for modern day machines to catalyze more autonomy and more efficiency. Gaze driven human intervention is an effective and convenient option for creating an interface to alleviate human errors. Facial landmark detection is very crucial for designing a robust gaze detection system. Regression based methods capacitate good spatial localization of the landmarks corresponding to different parts of the faces. But there are still scope of improvements which have been addressed by incorporating attention. In this paper, we have proposed a deep coarse-to-fine architecture called LocalEyenet for localization of only the eye regions that can be trained end-to-end. The model architecture, build on stacked hourglass backbone, learns the self-attention in feature maps which aids in preserving global as well as local spatial dependencies in face image. We have incorporated deep layer aggregation in each hourglass to minimize the loss of attention over the depth of architecture. Our model shows good generalization ability in cross-dataset evaluation and in real-time localization of eyes.
MSINet: Twins Contrastive Search of Multi-Scale Interaction for Object ReID
Mar 13, 2023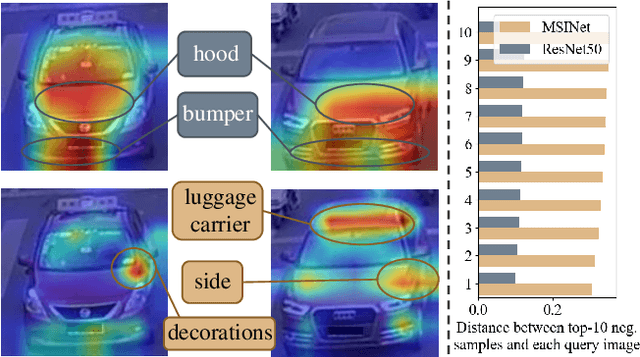

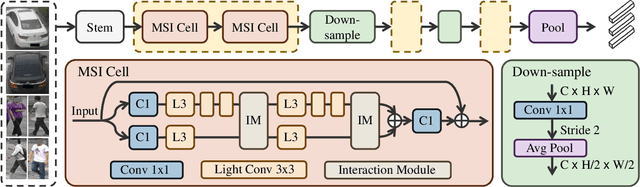
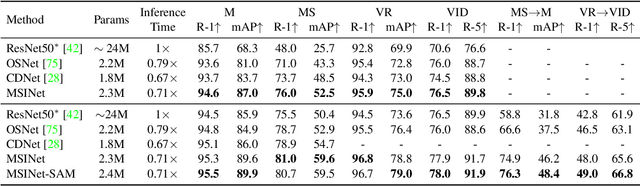
Neural Architecture Search (NAS) has been increasingly appealing to the society of object Re-Identification (ReID), for that task-specific architectures significantly improve the retrieval performance. Previous works explore new optimizing targets and search spaces for NAS ReID, yet they neglect the difference of training schemes between image classification and ReID. In this work, we propose a novel Twins Contrastive Mechanism (TCM) to provide more appropriate supervision for ReID architecture search. TCM reduces the category overlaps between the training and validation data, and assists NAS in simulating real-world ReID training schemes. We then design a Multi-Scale Interaction (MSI) search space to search for rational interaction operations between multi-scale features. In addition, we introduce a Spatial Alignment Module (SAM) to further enhance the attention consistency confronted with images from different sources. Under the proposed NAS scheme, a specific architecture is automatically searched, named as MSINet. Extensive experiments demonstrate that our method surpasses state-of-the-art ReID methods on both in-domain and cross-domain scenarios. Source code available in https://github.com/vimar-gu/MSINet.