 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Plug-and-Play Deep Energy Model for Inverse problems
Feb 15, 2023
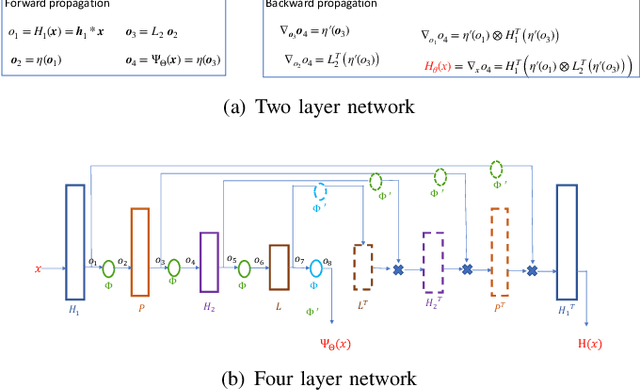
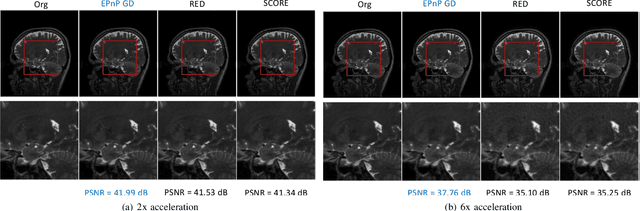
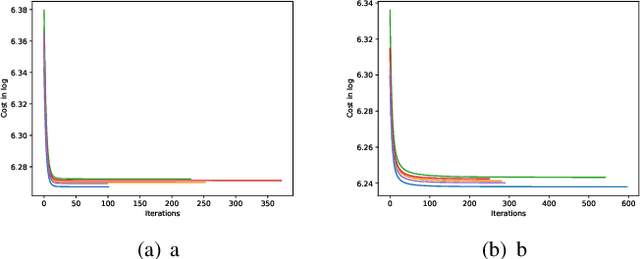

We introduce a novel energy formulation for Plug- and-Play (PnP) image recovery. Traditional PnP methods that use a convolutional neural network (CNN) do not have an energy based formulation. The primary focus of this work is to introduce an energy-based PnP formulation, which relies on a CNN that learns the log of the image prior from training data. The score function is evaluated as the gradient of the energy model, which resembles a UNET with shared encoder and decoder weights. The proposed score function is thus constrained to a conservative vector field, which is the key difference with classical PnP models. The energy-based formulation offers algorithms with convergence guarantees, even when the learned score model is not a contraction. The relaxation of the contraction constraint allows the proposed model to learn more complex priors, thus offering improved performance over traditional PnP schemes. Our experiments in magnetic resonance image reconstruction demonstrates the improved performance offered by the proposed energy model over traditional PnP methods.
Data Forensics in Diffusion Models: A Systematic Analysis of Membership Privacy
Feb 15, 2023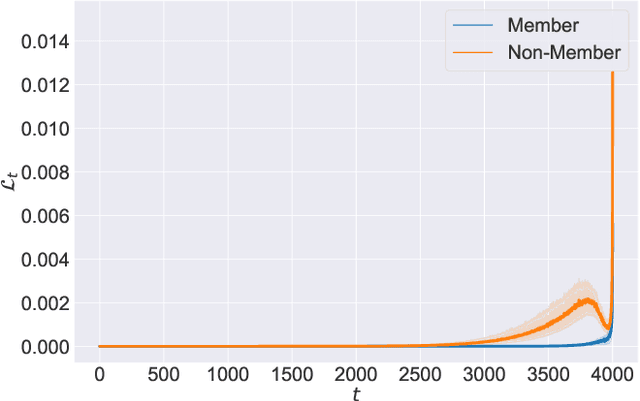
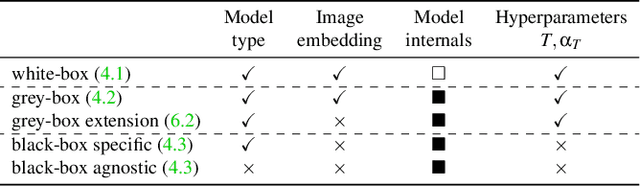
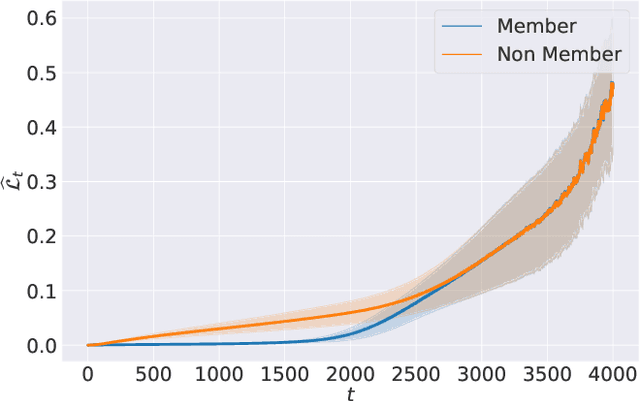
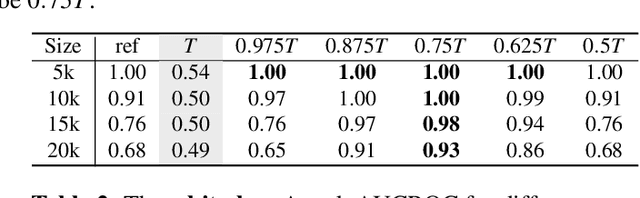
In recent years, diffusion models have achieved tremendous success in the field of image generation, becoming the stateof-the-art technology for AI-based image processing applications. Despite the numerous benefits brought by recent advances in diffusion models, there are also concerns about their potential misuse, specifically in terms of privacy breaches and intellectual property infringement. In particular, some of their unique characteristics open up new attack surfaces when considering the real-world deployment of such models. With a thorough investigation of the attack vectors, we develop a systematic analysis of membership inference attacks on diffusion models and propose novel attack methods tailored to each attack scenario specifically relevant to diffusion models. Our approach exploits easily obtainable quantities and is highly effective, achieving near-perfect attack performance (>0.9 AUCROC) in realistic scenarios. Our extensive experiments demonstrate the effectiveness of our method, highlighting the importance of considering privacy and intellectual property risks when using diffusion models in image generation tasks.
CLIP-RR: Improved CLIP Network for Relation-Focused Cross-Modal Information Retrieval
Feb 13, 2023
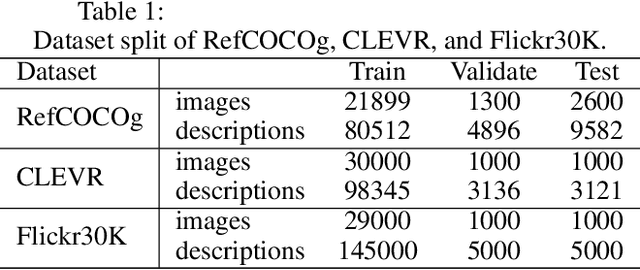
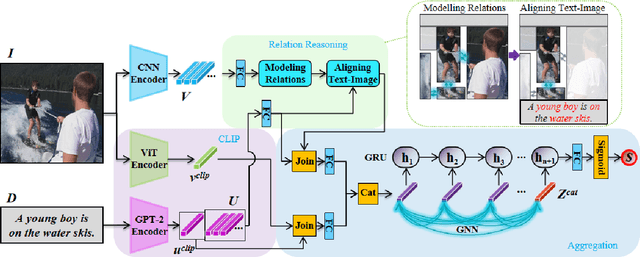
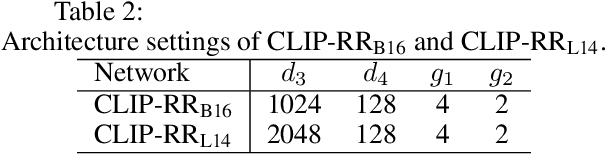
Relation-focused cross-modal information retrieval focuses on retrieving information based on relations expressed in user queries, and it is particularly important in information retrieval applications and next-generation search engines. To date, CLIP (Contrastive Language-Image Pre-training) achieved state-of-the-art performance in cross-modal learning tasks due to its efficient learning of visual concepts from natural language supervision. However, CLIP learns visual representations from natural language at a global level without the capability of focusing on image-object relations. This paper proposes a novel CLIP-based network for Relation Reasoning, CLIP-RR, that tackles relation-focused cross-modal information retrieval. The proposed network utilises CLIP to leverage its pre-trained knowledge, and it additionally comprises two main parts: (1) extends the capabilities of CLIP to extract and reason with object relations in images; and (2) aggregates the reasoned results for predicting the similarity scores between images and descriptions. Experiments were carried out by applying the proposed network to relation-focused cross-modal information retrieval tasks on the RefCOCOg, CLEVR, and Flickr30K datasets. The results revealed that the proposed network outperformed various other state-of-the-art networks including CLIP, VSE$\infty$, and VSRN++ on both image-to-text and text-to-image cross-modal information retrieval tasks.
Cutting-Splicing data augmentation: A novel technology for medical image segmentation
Oct 17, 2022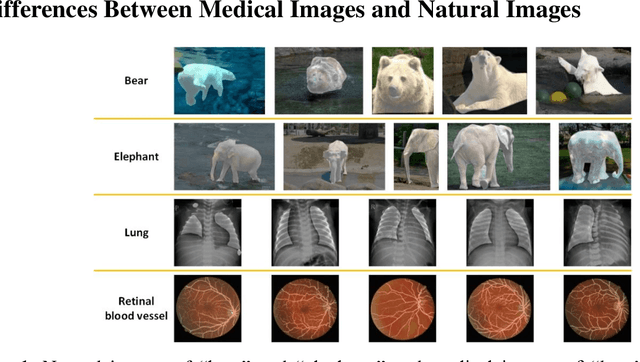
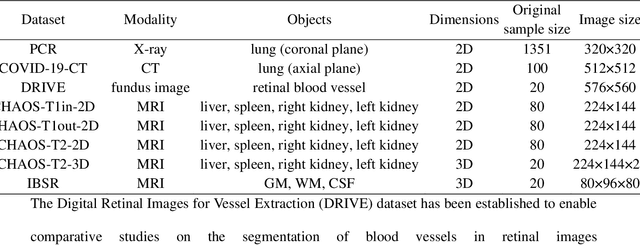
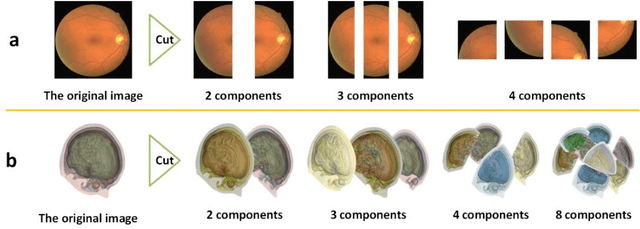
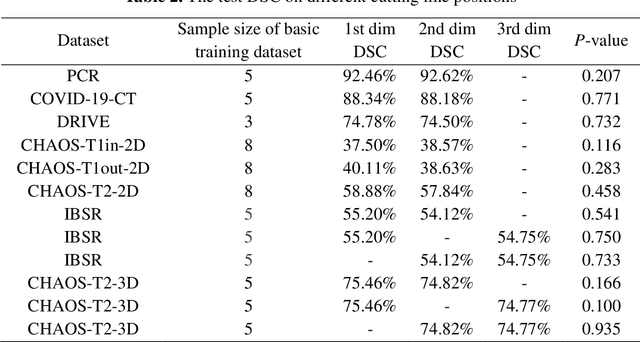
Background: Medical images are more difficult to acquire and annotate than natural images, which results in data augmentation technologies often being used in medical image segmentation tasks. Most data augmentation technologies used in medical segmentation were originally developed on natural images and do not take into account the characteristic that the overall layout of medical images is standard and fixed. Methods: Based on the characteristics of medical images, we developed the cutting-splicing data augmentation (CS-DA) method, a novel data augmentation technology for medical image segmentation. CS-DA augments the dataset by splicing different position components cut from different original medical images into a new image. The characteristics of the medical image result in the new image having the same layout as and similar appearance to the original image. Compared with classical data augmentation technologies, CS-DA is simpler and more robust. Moreover, CS-DA does not introduce any noise or fake information into the newly created image. Results: To explore the properties of CS-DA, many experiments are conducted on eight diverse datasets. On the training dataset with the small sample size, CS-DA can effectively increase the performance of the segmentation model. When CS-DA is used together with classical data augmentation technologies, the performance of the segmentation model can be further improved and is much better than that of CS-DA and classical data augmentation separately. We also explored the influence of the number of components, the position of the cutting line, and the splicing method on the CS-DA performance. Conclusions: The excellent performance of CS-DA in the experiment has confirmed the effectiveness of CS-DA, and provides a new data augmentation idea for the small sample segmentation task.
DeblurSR: Event-Based Motion Deblurring Under the Spiking Representation
Mar 15, 2023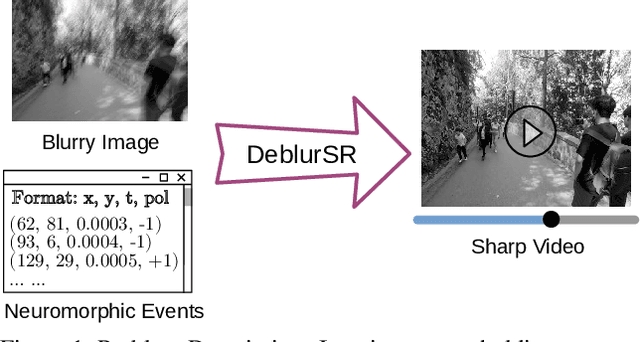

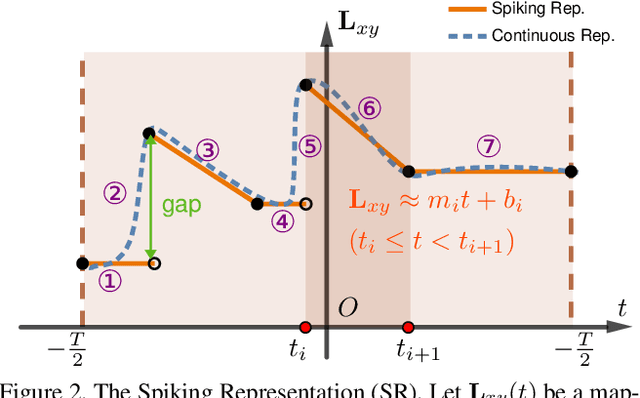

We present DeblurSR, a novel motion deblurring approach that converts a blurry image into a sharp video. DeblurSR utilizes event data to compensate for motion ambiguities and exploits the spiking representation to parameterize the sharp output video as a mapping from time to intensity. Our key contribution, the Spiking Representation (SR), is inspired by the neuromorphic principles determining how biological neurons communicate with each other in living organisms. We discuss why the spikes can represent sharp edges and how the spiking parameters are interpreted from the neuromorphic perspective. DeblurSR has higher output quality and requires fewer computing resources than state-of-the-art event-based motion deblurring methods. We additionally show that our approach easily extends to video super-resolution when combined with recent advances in implicit neural representation. The implementation and animated visualization of DeblurSR are available at https://github.com/chensong1995/DeblurSR.
Gated Compression Layers for Efficient Always-On Models
Mar 15, 2023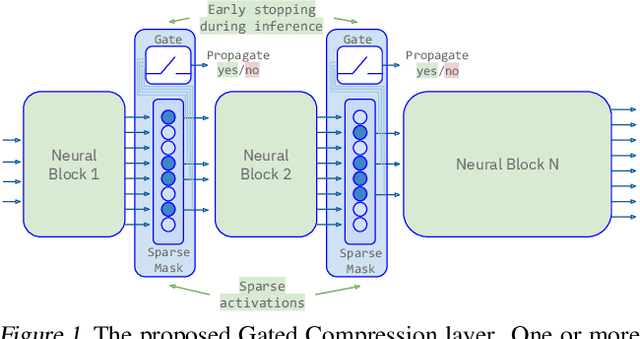
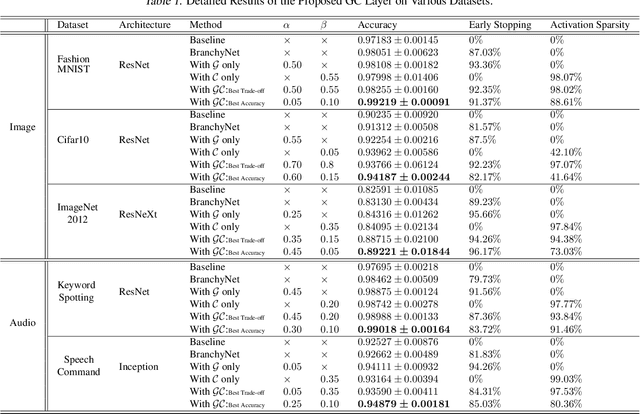
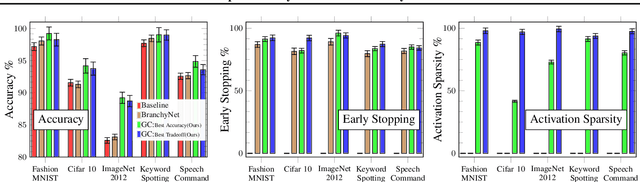
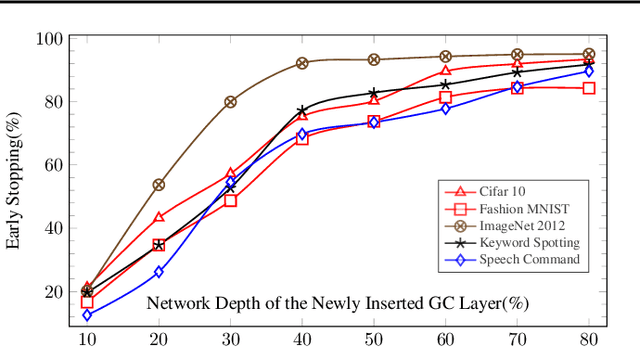
Mobile and embedded machine learning developers frequently have to compromise between two inferior on-device deployment strategies: sacrifice accuracy and aggressively shrink their models to run on dedicated low-power cores; or sacrifice battery by running larger models on more powerful compute cores such as neural processing units or the main application processor. In this paper, we propose a novel Gated Compression layer that can be applied to transform existing neural network architectures into Gated Neural Networks. Gated Neural Networks have multiple properties that excel for on-device use cases that help significantly reduce power, boost accuracy, and take advantage of heterogeneous compute cores. We provide results across five public image and audio datasets that demonstrate the proposed Gated Compression layer effectively stops up to 96% of negative samples, compresses 97% of positive samples, while maintaining or improving model accuracy.
Position-Guided Point Cloud Panoptic Segmentation Transformer
Mar 23, 2023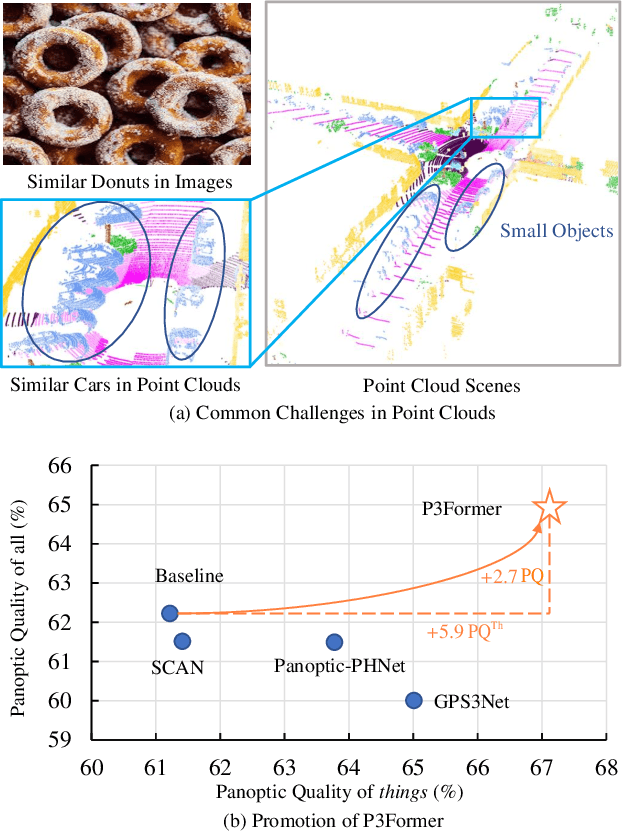
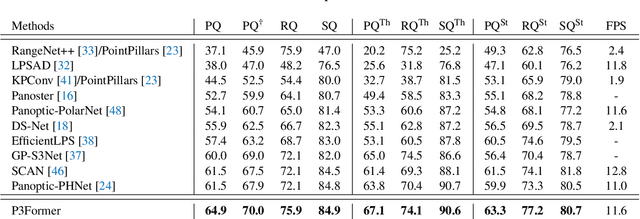
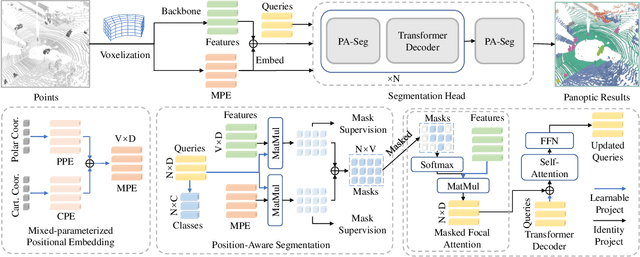
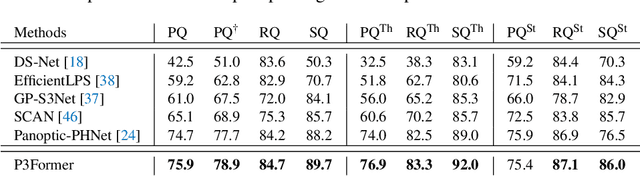
DEtection TRansformer (DETR) started a trend that uses a group of learnable queries for unified visual perception. This work begins by applying this appealing paradigm to LiDAR-based point cloud segmentation and obtains a simple yet effective baseline. Although the naive adaptation obtains fair results, the instance segmentation performance is noticeably inferior to previous works. By diving into the details, we observe that instances in the sparse point clouds are relatively small to the whole scene and often have similar geometry but lack distinctive appearance for segmentation, which are rare in the image domain. Considering instances in 3D are more featured by their positional information, we emphasize their roles during the modeling and design a robust Mixed-parameterized Positional Embedding (MPE) to guide the segmentation process. It is embedded into backbone features and later guides the mask prediction and query update processes iteratively, leading to Position-Aware Segmentation (PA-Seg) and Masked Focal Attention (MFA). All these designs impel the queries to attend to specific regions and identify various instances. The method, named Position-guided Point cloud Panoptic segmentation transFormer (P3Former), outperforms previous state-of-the-art methods by 3.4% and 1.2% PQ on SemanticKITTI and nuScenes benchmark, respectively. The source code and models are available at https://github.com/SmartBot-PJLab/P3Former .
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Mar 23, 2023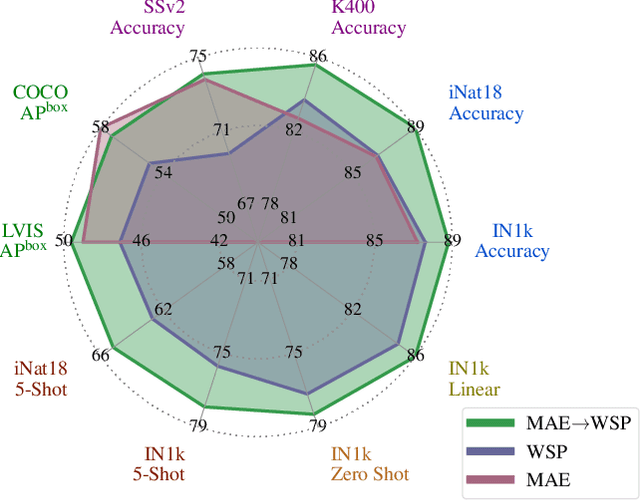

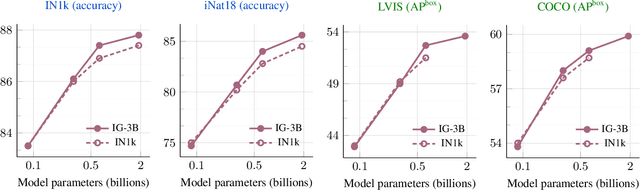
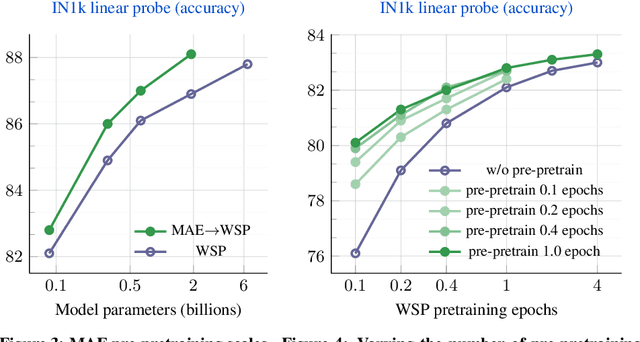
This paper revisits the standard pretrain-then-finetune paradigm used in computer vision for visual recognition tasks. Typically, state-of-the-art foundation models are pretrained using large scale (weakly) supervised datasets with billions of images. We introduce an additional pre-pretraining stage that is simple and uses the self-supervised MAE technique to initialize the model. While MAE has only been shown to scale with the size of models, we find that it scales with the size of the training dataset as well. Thus, our MAE-based pre-pretraining scales with both model and data size making it applicable for training foundation models. Pre-pretraining consistently improves both the model convergence and the downstream transfer performance across a range of model scales (millions to billions of parameters), and dataset sizes (millions to billions of images). We measure the effectiveness of pre-pretraining on 10 different visual recognition tasks spanning image classification, video recognition, object detection, low-shot classification and zero-shot recognition. Our largest model achieves new state-of-the-art results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%). Our study reveals that model initialization plays a significant role, even for web-scale pretraining with billions of images.
Semantic Ray: Learning a Generalizable Semantic Field with Cross-Reprojection Attention
Mar 23, 2023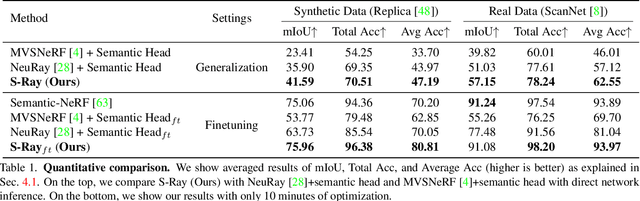
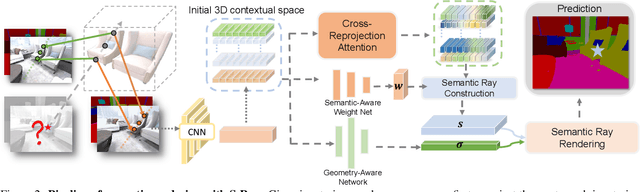
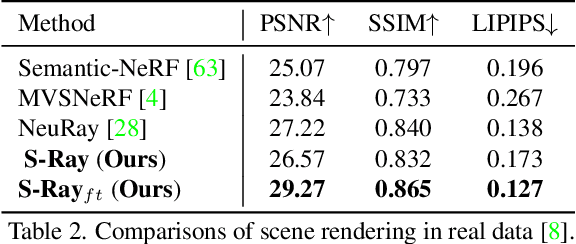
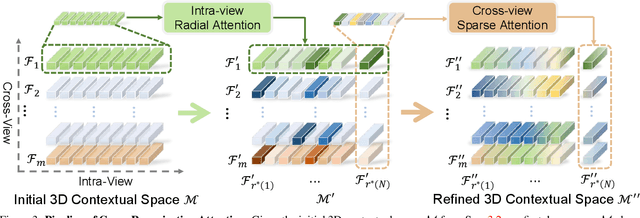
In this paper, we aim to learn a semantic radiance field from multiple scenes that is accurate, efficient and generalizable. While most existing NeRFs target at the tasks of neural scene rendering, image synthesis and multi-view reconstruction, there are a few attempts such as Semantic-NeRF that explore to learn high-level semantic understanding with the NeRF structure. However, Semantic-NeRF simultaneously learns color and semantic label from a single ray with multiple heads, where the single ray fails to provide rich semantic information. As a result, Semantic NeRF relies on positional encoding and needs to train one specific model for each scene. To address this, we propose Semantic Ray (S-Ray) to fully exploit semantic information along the ray direction from its multi-view reprojections. As directly performing dense attention over multi-view reprojected rays would suffer from heavy computational cost, we design a Cross-Reprojection Attention module with consecutive intra-view radial and cross-view sparse attentions, which decomposes contextual information along reprojected rays and cross multiple views and then collects dense connections by stacking the modules. Experiments show that our S-Ray is able to learn from multiple scenes, and it presents strong generalization ability to adapt to unseen scenes.
Weakly-Supervised Text Instance Segmentation
Mar 23, 2023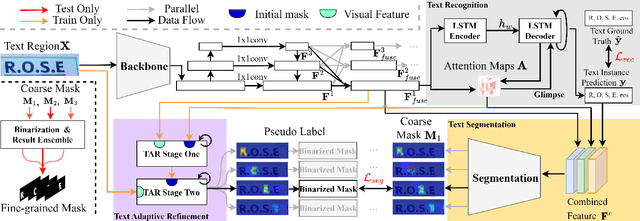
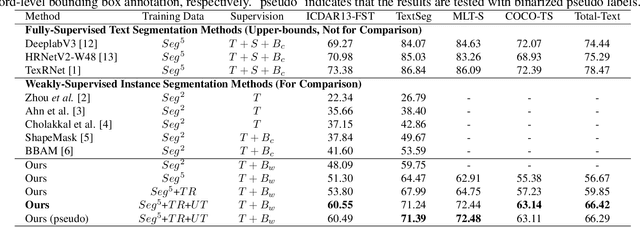


Text segmentation is a challenging vision task with many downstream applications. Current text segmentation methods require pixel-level annotations, which are expensive in the cost of human labor and limited in application scenarios. In this paper, we take the first attempt to perform weakly-supervised text instance segmentation by bridging text recognition and text segmentation. The insight is that text recognition methods provide precise attention position of each text instance, and the attention location can feed to both a text adaptive refinement head (TAR) and a text segmentation head. Specifically, the proposed TAR generates pseudo labels by performing two-stage iterative refinement operations on the attention location to fit the accurate boundaries of the corresponding text instance. Meanwhile, the text segmentation head takes the rough attention location to predict segmentation masks which are supervised by the aforementioned pseudo labels. In addition, we design a mask-augmented contrastive learning by treating our segmentation result as an augmented version of the input text image, thus improving the visual representation and further enhancing the performance of both recognition and segmentation. The experimental results demonstrate that the proposed method significantly outperforms weakly-supervised instance segmentation methods on ICDAR13-FST (18.95$\%$ improvement) and TextSeg (17.80$\%$ improvement) benchmarks.