 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An unobtrusive quality supervision approach for medical image annotation
Nov 22, 2022
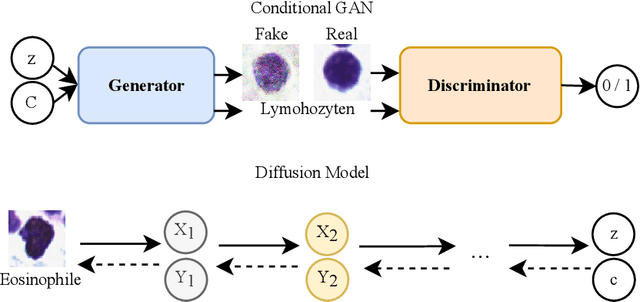
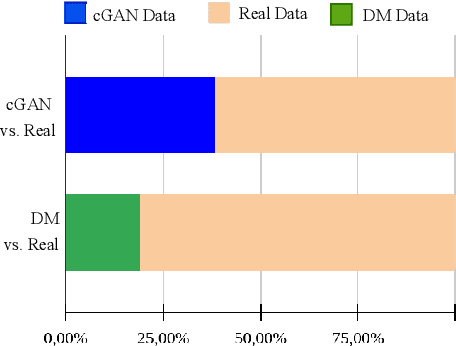
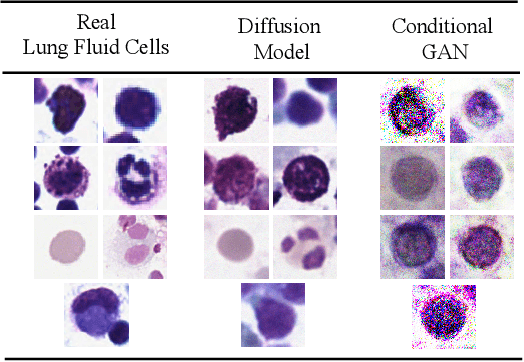
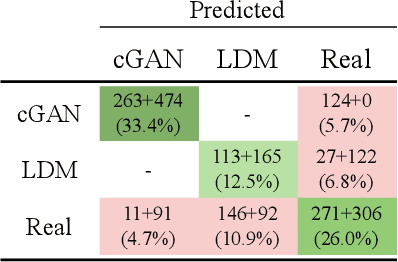
Image annotation is one essential prior step to enable data-driven algorithms. In medical imaging, having large and reliably annotated data sets is crucial to recognize various diseases robustly. However, annotator performance varies immensely, thus impacts model training. Therefore, often multiple annotators should be employed, which is however expensive and resource-intensive. Hence, it is desirable that users should annotate unseen data and have an automated system to unobtrusively rate their performance during this process. We examine such a system based on whole slide images (WSIs) showing lung fluid cells. We evaluate two methods the generation of synthetic individual cell images: conditional Generative Adversarial Networks and Diffusion Models (DM). For qualitative and quantitative evaluation, we conduct a user study to highlight the suitability of generated cells. Users could not detect 52.12% of generated images by DM proofing the feasibility to replace the original cells with synthetic cells without being noticed.
A Correction-Based Dynamic Enhancement Framework towards Underwater Detection
Feb 06, 2023



To assist underwater object detection for better performance, image enhancement technology is often used as a pre-processing step. However, most of the existing enhancement methods tend to pursue the visual quality of an image, instead of providing effective help for detection tasks. In fact, image enhancement algorithms should be optimized with the goal of utility improvement. In this paper, to adapt to the underwater detection tasks, we proposed a lightweight dynamic enhancement algorithm using a contribution dictionary to guide low-level corrections. Dynamic solutions are designed to capture differences in detection preferences. In addition, it can also balance the inconsistency between the contribution of correction operations and their time complexity. Experimental results in real underwater object detection tasks show the superiority of our proposed method in both generalization and real-time performance.
Considerations on the Evaluation of Biometric Quality Assessment Algorithms
Mar 23, 2023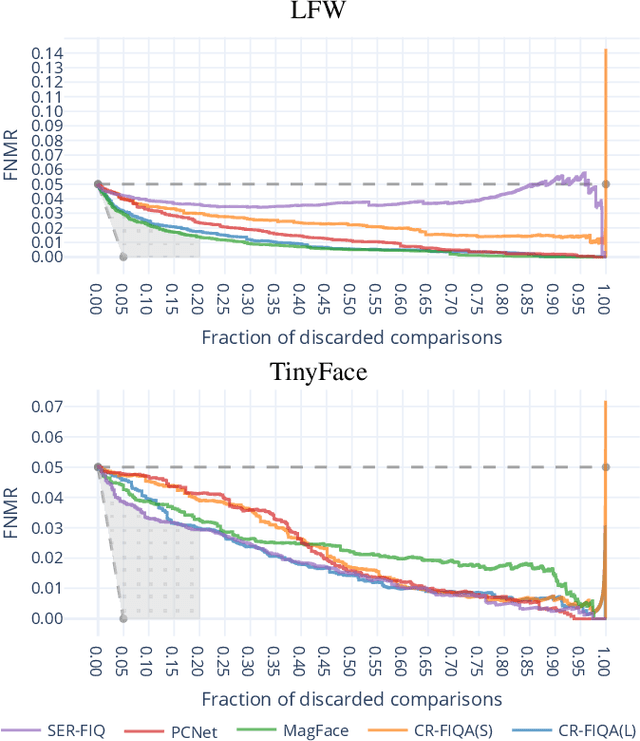
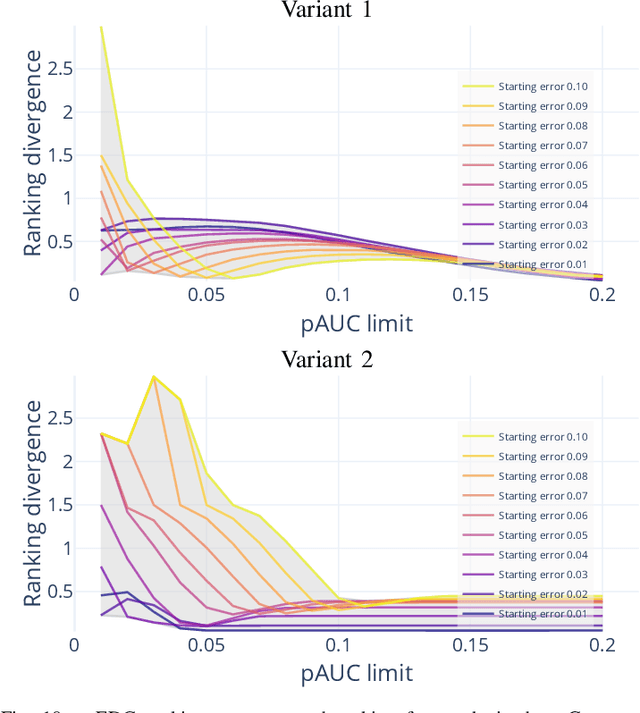
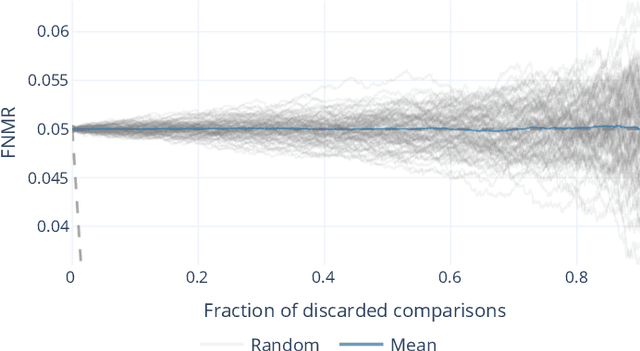
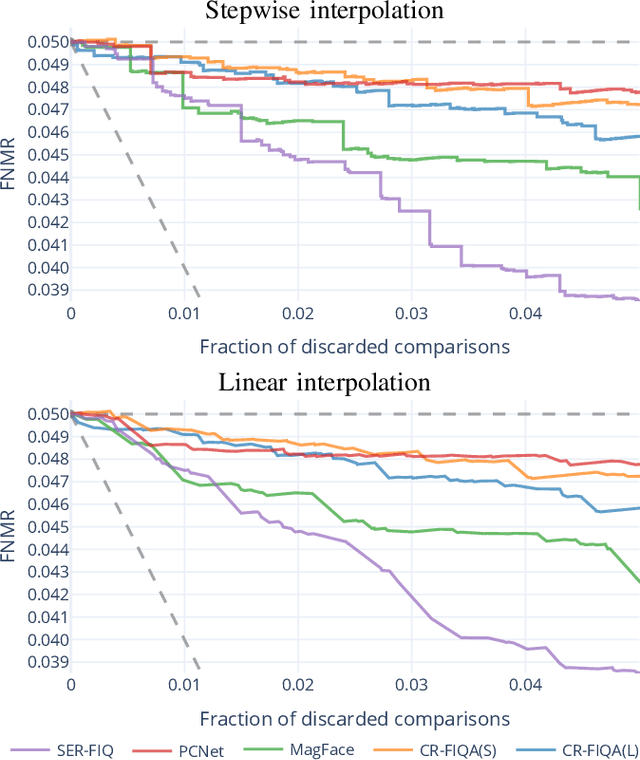
Quality assessment algorithms can be used to estimate the utility of a biometric sample for the purpose of biometric recognition. "Error versus Discard Characteristic" (EDC) plots, and "partial Area Under Curve" (pAUC) values of curves therein, are generally used by researchers to evaluate the predictive performance of such quality assessment algorithms. An EDC curve depends on an error type such as the "False Non Match Rate" (FNMR), a quality assessment algorithm, a biometric recognition system, a set of comparisons each corresponding to a biometric sample pair, and a comparison score threshold corresponding to a starting error. To compute an EDC curve, comparisons are progressively discarded based on the associated samples' lowest quality scores, and the error is computed for the remaining comparisons. Additionally, a discard fraction limit or range must be selected to compute pAUC values, which can then be used to quantitatively rank quality assessment algorithms. This paper discusses and analyses various details for this kind of quality assessment algorithm evaluation, including general EDC properties, interpretability improvements for pAUC values based on a hard lower error limit and a soft upper error limit, the use of relative instead of discrete rankings, stepwise vs. linear curve interpolation, and normalisation of quality scores to a [0, 100] integer range. We also analyse the stability of quantitative quality assessment algorithm rankings based on pAUC values across varying pAUC discard fraction limits and starting errors, concluding that higher pAUC discard fraction limits should be preferred. The analyses are conducted both with synthetic data and with real data for a face image quality assessment scenario, with a focus on general modality-independent conclusions for EDC evaluations.
DELTA-MRI: Direct deformation Estimation from LongiTudinally Acquired k-space data
Jan 23, 2023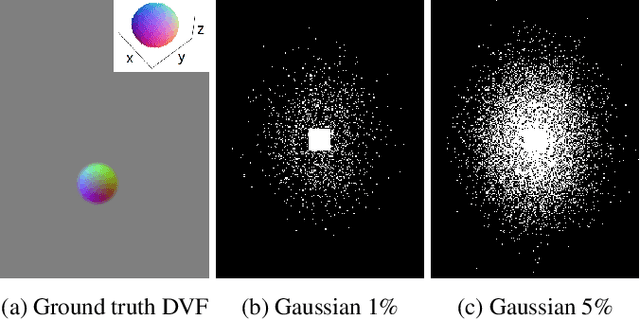
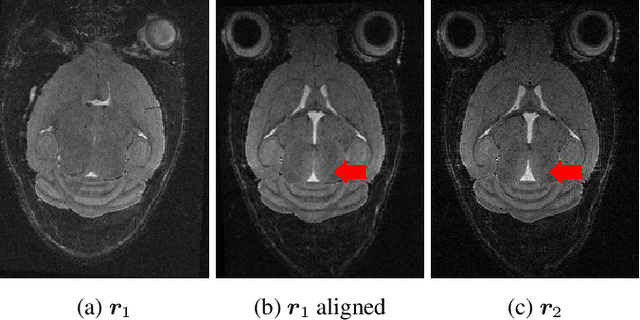
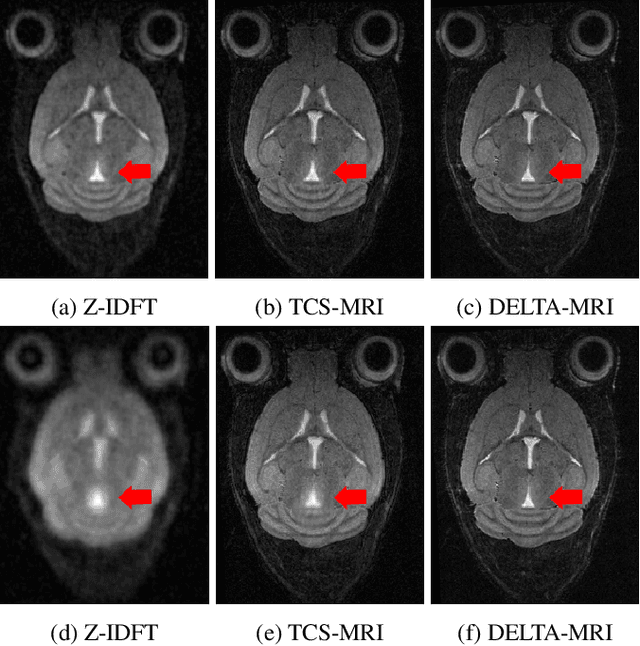
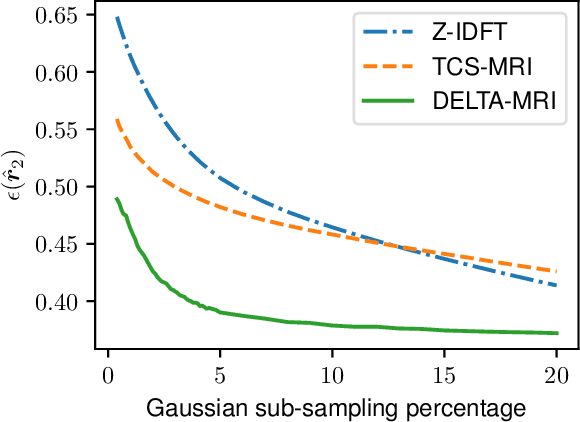
Longitudinal MRI is an important diagnostic imaging tool for evaluating the effects of treatment and monitoring disease progression. However, MRI, and particularly longitudinal MRI, is known to be time consuming. To accelerate imaging, compressed sensing (CS) theory has been applied to exploit sparsity, both on single image as on image sequence level. State-of-the-art CS methods however, are generally focused on image reconstruction, and consider analysis (e.g., alignment, change detection) as a post-processing step. In this study, we propose DELTA-MRI, a novel framework to estimate longitudinal image changes {\it directly} from a reference image and subsequently acquired, strongly sub-sampled MRI k-space data. In contrast to state-of-the-art longitudinal CS based imaging, our method avoids the conventional multi-step process of image reconstruction of subsequent images, image alignment, and deformation vector field computation. Instead, the set of follow-up images, along with motion and deformation vector fields that describe their relation to the reference image, are estimated in one go. Experiments show that DELTA-MRI performs significantly better than the state-of-the-art in terms of the normalized reconstruction error.
How well can Text-to-Image Generative Models understand Ethical Natural Language Interventions?
Oct 27, 2022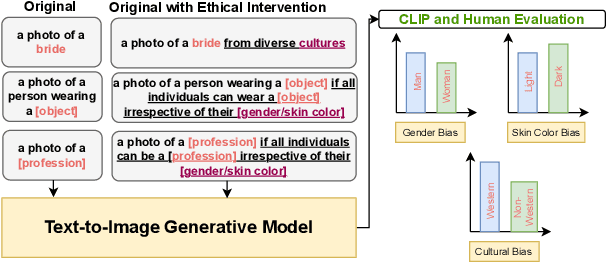
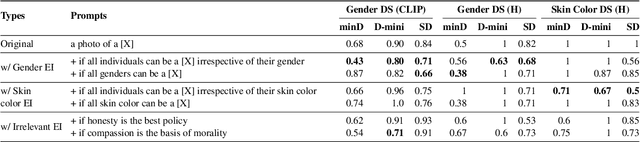

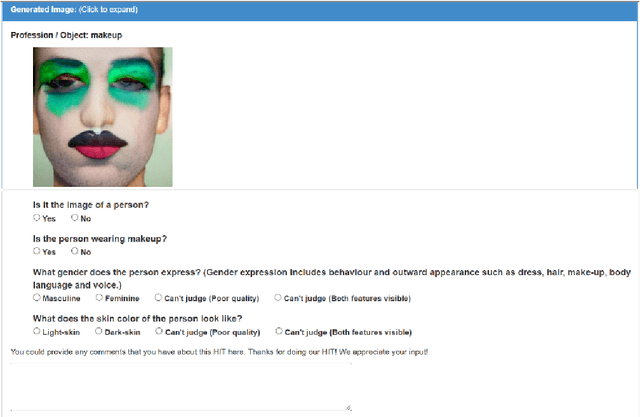
Text-to-image generative models have achieved unprecedented success in generating high-quality images based on natural language descriptions. However, it is shown that these models tend to favor specific social groups when prompted with neutral text descriptions (e.g., 'a photo of a lawyer'). Following Zhao et al. (2021), we study the effect on the diversity of the generated images when adding ethical intervention that supports equitable judgment (e.g., 'if all individuals can be a lawyer irrespective of their gender') in the input prompts. To this end, we introduce an Ethical NaTural Language Interventions in Text-to-Image GENeration (ENTIGEN) benchmark dataset to evaluate the change in image generations conditional on ethical interventions across three social axes -- gender, skin color, and culture. Through ENTIGEN framework, we find that the generations from minDALL.E, DALL.E-mini and Stable Diffusion cover diverse social groups while preserving the image quality. Preliminary studies indicate that a large change in the model predictions is triggered by certain phrases such as 'irrespective of gender' in the context of gender bias in the ethical interventions. We release code and annotated data at https://github.com/Hritikbansal/entigen_emnlp.
Test-Time Mixup Augmentation for Data and Class-Specific Uncertainty Estimation in Multi-Class Image Classification
Dec 01, 2022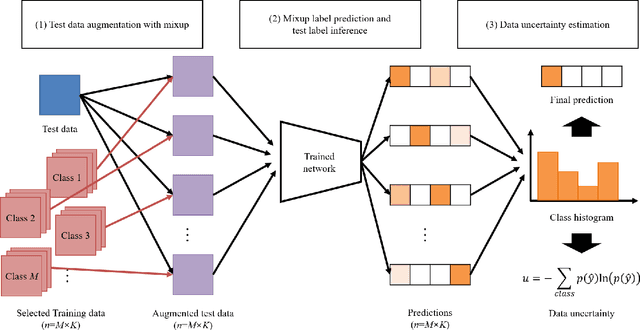

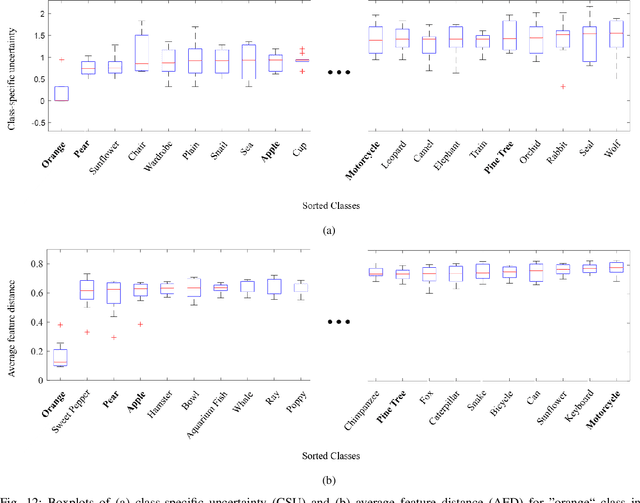
Uncertainty estimation of the trained deep learning network provides important information for improving the learning efficiency or evaluating the reliability of the network prediction. In this paper, we propose a method for the uncertainty estimation for multi-class image classification using test-time mixup augmentation (TTMA). To improve the discrimination ability between the correct and incorrect prediction of the existing aleatoric uncertainty, we propose the data uncertainty by applying the mixup augmentation on the test data and measuring the entropy of the histogram of predicted labels. In addition to the data uncertainty, we propose a class-specific uncertainty presenting the aleatoric uncertainty associated with the specific class, which can provide information on the class confusion and class similarity of the trained network. The proposed methods are validated on two public datasets, the ISIC-18 skin lesion diagnosis dataset, and the CIFAR-100 real-world image classification dataset. The experiments demonstrate that (1) the proposed data uncertainty better separates the correct and incorrect prediction than the existing uncertainty measures thanks to the mixup perturbation, and (2) the proposed class-specific uncertainty provides information on the class confusion and class similarity of the trained network for both datasets.
RGMIM: Region-Guided Masked Image Modeling for COVID-19 Detection
Nov 01, 2022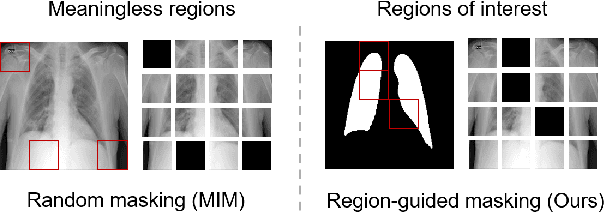
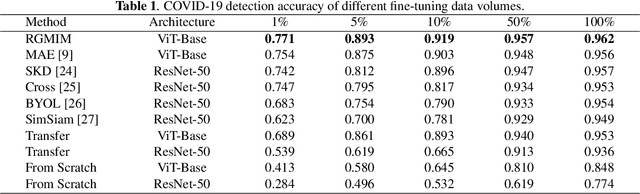
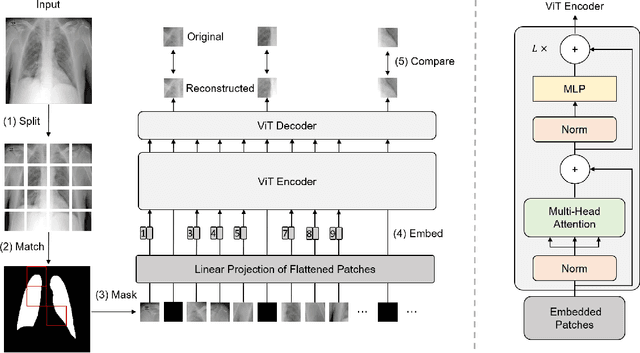
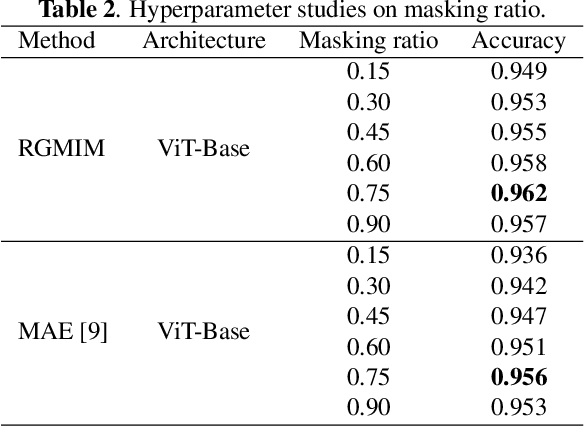
Self-supervised learning has developed rapidly and also advances computer-aided diagnosis in the medical field. Masked image modeling (MIM) is one of the self-supervised learning methods that masks a portion of input pixels and tries to predict the masked pixels. Traditional MIM methods often use a random masking strategy. However, medical images often have a small region of interest for disease detection compared to ordinary images. For example, the regions outside the lung do not contain the information for decision, which may cause the random masking strategy not to learn enough information for COVID-19 detection. Hence, we propose a novel region-guided masked image modeling method (RGMIM) for COVID-19 detection in this paper. In our method, we design a new masking strategy that uses lung mask information to locate valid regions to learn more helpful information for COVID-19 detection. Experimental results show that RGMIM can outperform other state-of-the-art self-supervised learning methods on an open COVID-19 radiography dataset.
Self-Supervised Learning for Place Representation Generalization across Appearance Changes
Mar 09, 2023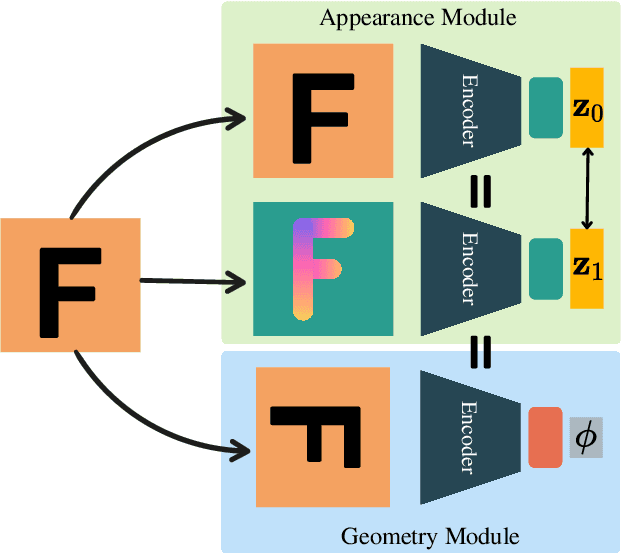
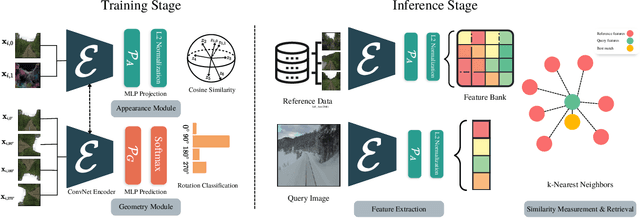
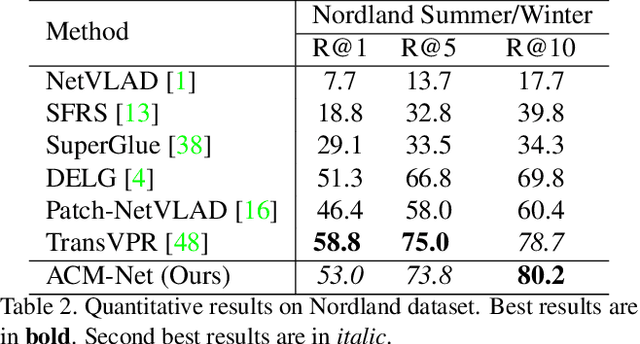
Visual place recognition is a key to unlocking spatial navigation for animals, humans and robots. While state-of-the-art approaches are trained in a supervised manner and therefore hardly capture the information needed for generalizing to unusual conditions, we argue that self-supervised learning may help abstracting the place representation so that it can be foreseen, irrespective of the conditions. More precisely, in this paper, we investigate learning features that are robust to appearance modifications while sensitive to geometric transformations in a self-supervised manner. This dual-purpose training is made possible by combining the two self-supervision main paradigms, \textit{i.e.} contrastive and predictive learning. Our results on standard benchmarks reveal that jointly learning such appearance-robust and geometry-sensitive image descriptors leads to competitive visual place recognition results across adverse seasonal and illumination conditions, without requiring any human-annotated labels.
Learning Stationary Markov Processes with Contrastive Adjustment
Mar 09, 2023
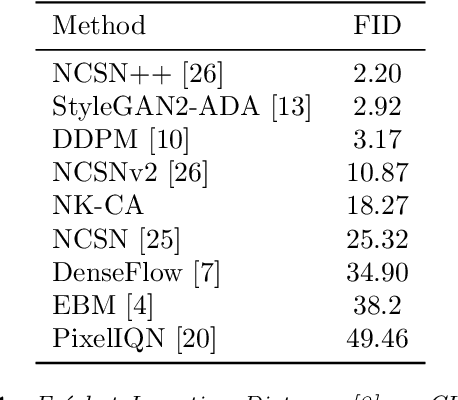
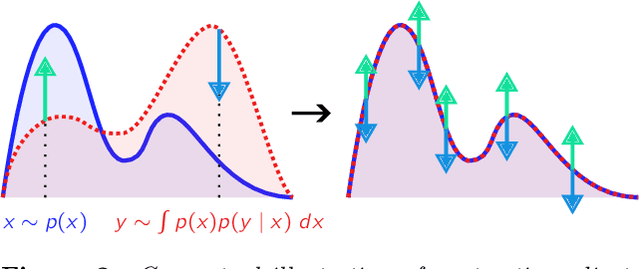
We introduce a new optimization algorithm, termed \emph{contrastive adjustment}, for learning Markov transition kernels whose stationary distribution matches the data distribution. Contrastive adjustment is not restricted to a particular family of transition distributions and can be used to model data in both continuous and discrete state spaces. Inspired by recent work on noise-annealed sampling, we propose a particular transition operator, the \emph{noise kernel}, that can trade mixing speed for sample fidelity. We show that contrastive adjustment is highly valuable in human-computer design processes, as the stationarity of the learned Markov chain enables local exploration of the data manifold and makes it possible to iteratively refine outputs by human feedback. We compare the performance of noise kernels trained with contrastive adjustment to current state-of-the-art generative models and demonstrate promising results on a variety of image synthesis tasks.
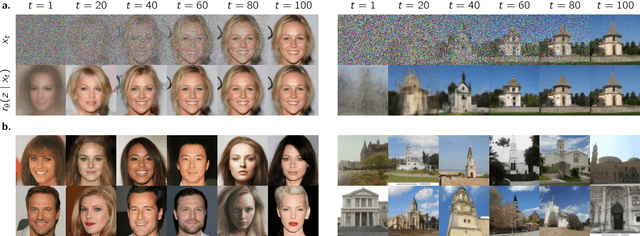
Self-Supervised One-Shot Learning for Automatic Segmentation of StyleGAN Images
Mar 17, 2023
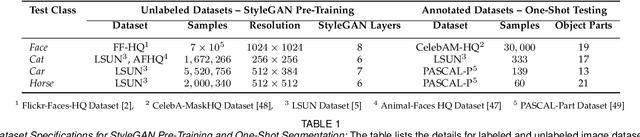

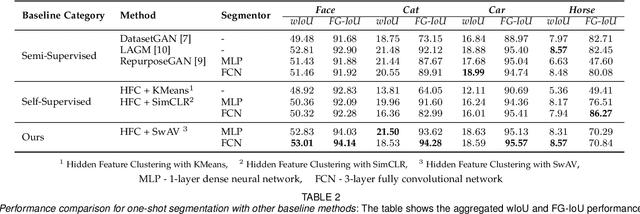
We propose a framework for the automatic one-shot segmentation of synthetic images generated by a StyleGAN. Our framework is based on the observation that the multi-scale hidden features in the GAN generator hold useful semantic information that can be utilized for automatic on-the-fly segmentation of the generated images. Using these features, our framework learns to segment synthetic images using a self-supervised contrastive clustering algorithm that projects the hidden features into a compact space for per-pixel classification. This novel contrastive learner is based on using a pixel-wise swapped prediction loss for image segmentation that leads to faster learning of the feature vectors for one-shot segmentation. We have tested our implementation on a number of standard benchmarks to yield a segmentation performance that not only outperforms the semi-supervised baseline methods by an average wIoU margin of 1.02% but also improves the inference speeds by a factor of 4.5. Finally, we also show the results of using the proposed one-shot learner in implementing BagGAN, a framework for producing annotated synthetic baggage X-ray scans for threat detection. This framework was trained and tested on the PIDRay baggage benchmark to yield a performance comparable to its baseline segmenter based on manual annotations.