 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NEF: Neural Edge Fields for 3D Parametric Curve Reconstruction from Multi-view Images
Mar 14, 2023
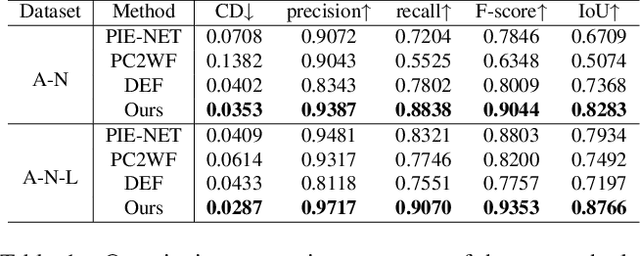
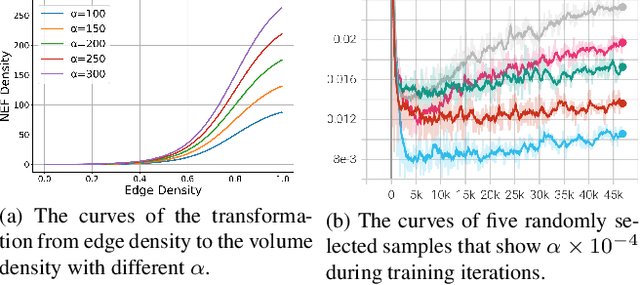
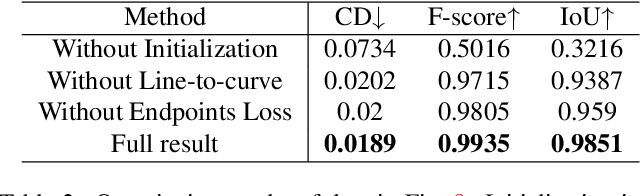
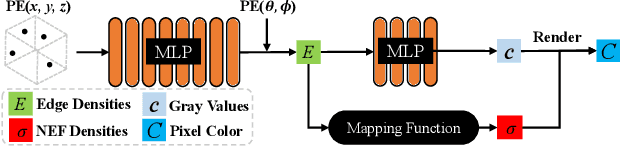
We study the problem of reconstructing 3D feature curves of an object from a set of calibrated multi-view images. To do so, we learn a neural implicit field representing the density distribution of 3D edges which we refer to as Neural Edge Field (NEF). Inspired by NeRF, NEF is optimized with a view-based rendering loss where a 2D edge map is rendered at a given view and is compared to the ground-truth edge map extracted from the image of that view. The rendering-based differentiable optimization of NEF fully exploits 2D edge detection, without needing a supervision of 3D edges, a 3D geometric operator or cross-view edge correspondence. Several technical designs are devised to ensure learning a range-limited and view-independent NEF for robust edge extraction. The final parametric 3D curves are extracted from NEF with an iterative optimization method. On our benchmark with synthetic data, we demonstrate that NEF outperforms existing state-of-the-art methods on all metrics. Project page: https://yunfan1202.github.io/NEF/.
Deep Learning for Identifying Iran's Cultural Heritage Buildings in Need of Conservation Using Image Classification and Grad-CAM
Feb 28, 2023
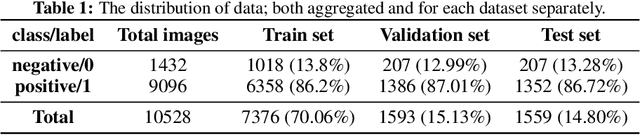

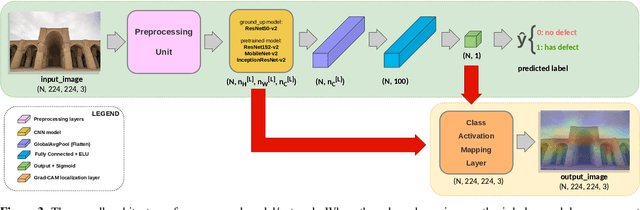
The cultural heritage buildings (CHB), which are part of mankind's history and identity, are in constant danger of damage or in extreme situations total destruction. That being said, it's of utmost importance to preserve them by identifying the existent, or presumptive, defects using novel methods so that renovation processes can be done in a timely manner and with higher accuracy. The main goal of this research is to use new deep learning (DL) methods in the process of preserving CHBs (situated in Iran); a goal that has been neglected especially in developing countries such as Iran, as these countries still preserve their CHBs using manual, and even archaic, methods that need direct human supervision. Having proven their effectiveness and performance when it comes to processing images, the convolutional neural networks (CNN) are a staple in computer vision (CV) literacy and this paper is not exempt. When lacking enough CHB images, training a CNN from scratch would be very difficult and prone to overfitting; that's why we opted to use a technique called transfer learning (TL) in which we used pre-trained ResNet, MobileNet, and Inception networks, for classification. Even more, the Grad-CAM was utilized to localize the defects to some extent. The final results were very favorable based on those of similar research. The final proposed model can pave the way for moving from manual to unmanned CHB conservation, hence an increase in accuracy and a decrease in human-induced errors.
A Method For Eliminating Contour Errors In Self-Encoder Reconstructed Images
Jan 25, 2023
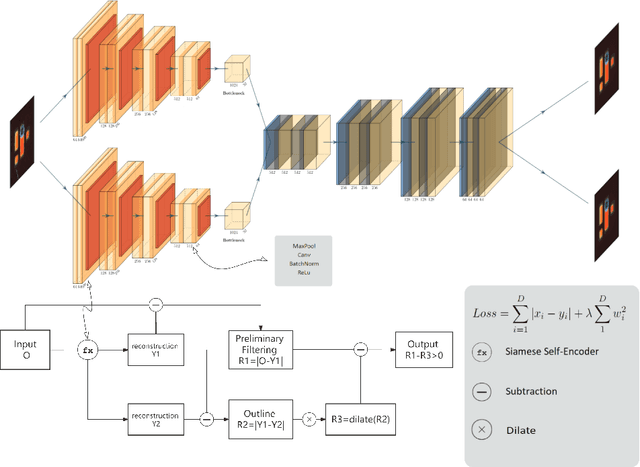
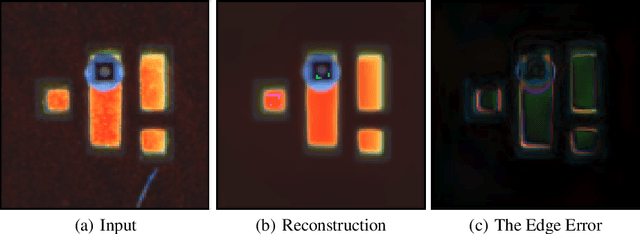
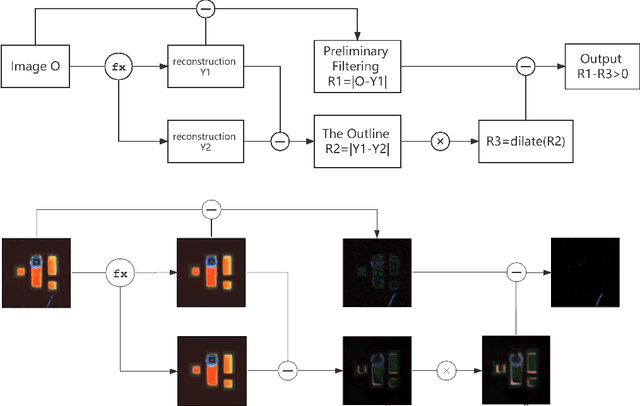
In this paper, we propose a self-supervised twin network approach based on this a priori. The method of generating the approximate10 edge information of an image and then differentially eliminating the edge errors11 in the reconstructed image with a dilate algorithm. This is used to improve the12 accuracy of the reconstructed image and to separate foreign matter and noise from13 the original image, so that it can be visualized in a more practical scene
RePrompt: Automatic Prompt Editing to Refine AI-Generative Art Towards Precise Expressions
Feb 19, 2023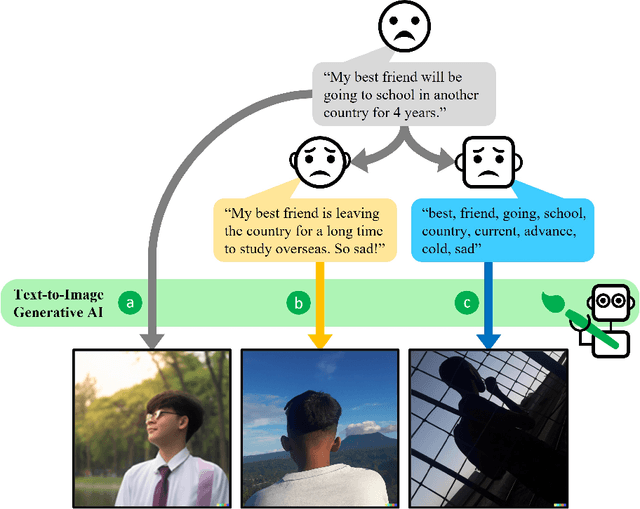
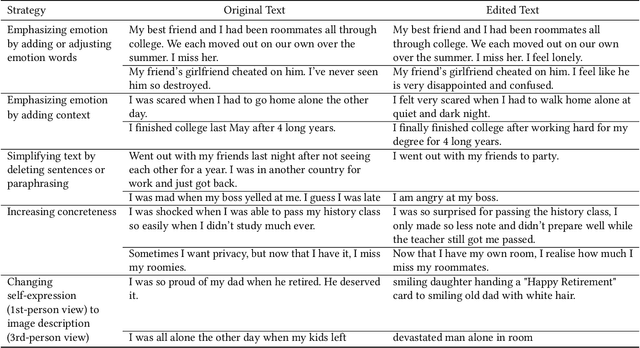
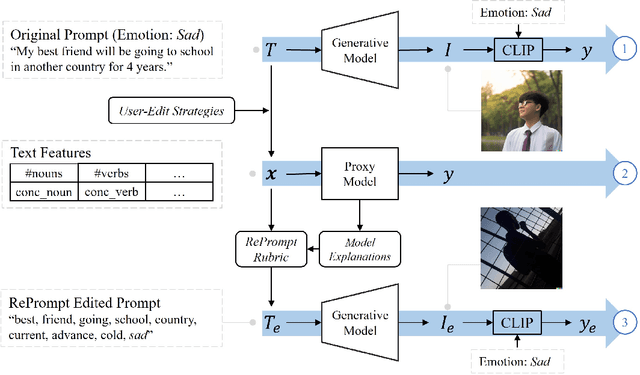

Generative AI models have shown impressive ability to produce images with text prompts, which could benefit creativity in visual art creation and self-expression. However, it is unclear how precisely the generated images express contexts and emotions from the input texts. We explored the emotional expressiveness of AI-generated images and developed RePrompt, an automatic method to refine text prompts toward precise expression of the generated images. Inspired by crowdsourced editing strategies, we curated intuitive text features, such as the number and concreteness of nouns, and trained a proxy model to analyze the feature effects on the AI-generated image. With model explanations of the proxy model, we curated a rubric to adjust text prompts to optimize image generation for precise emotion expression. We conducted simulation and user studies, which showed that RePrompt significantly improves the emotional expressiveness of AI-generated images, especially for negative emotions.
Deep Learning and Medical Imaging for COVID-19 Diagnosis: A Comprehensive Survey
Feb 13, 2023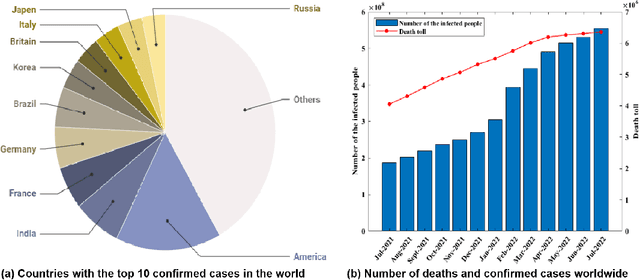
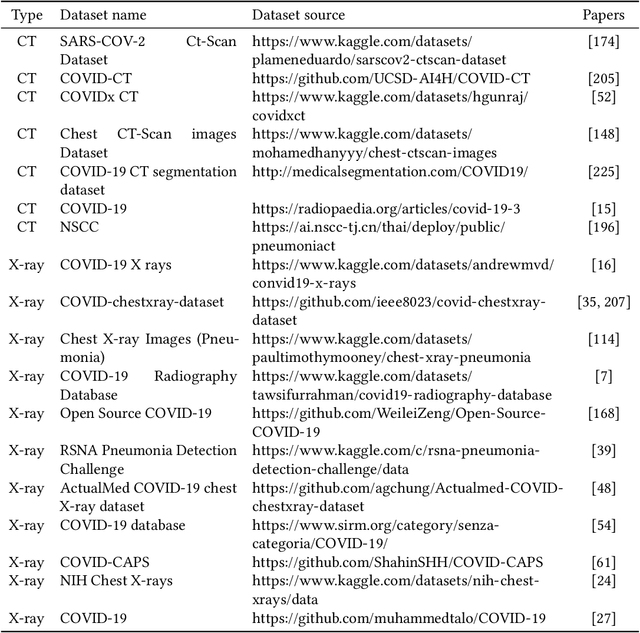
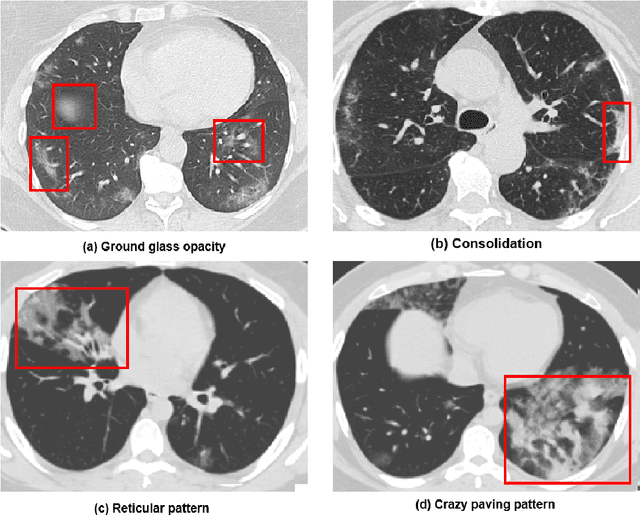

COVID-19 (Coronavirus disease 2019) has been quickly spreading since its outbreak, impacting financial markets and healthcare systems globally. Countries all around the world have adopted a number of extraordinary steps to restrict the spreading virus, where early COVID-19 diagnosis is essential. Medical images such as X-ray images and Computed Tomography scans are becoming one of the main diagnostic tools to combat COVID-19 with the aid of deep learning-based systems. In this survey, we investigate the main contributions of deep learning applications using medical images in fighting against COVID-19 from the aspects of image classification, lesion localization, and severity quantification, and review different deep learning architectures and some image preprocessing techniques for achieving a preciser diagnosis. We also provide a summary of the X-ray and CT image datasets used in various studies for COVID-19 detection. The key difficulties and potential applications of deep learning in fighting against COVID-19 are finally discussed. This work summarizes the latest methods of deep learning using medical images to diagnose COVID-19, highlighting the challenges and inspiring more studies to keep utilizing the advantages of deep learning to combat COVID-19.
Dynamical Hyperspectral Unmixing with Variational Recurrent Neural Networks
Mar 19, 2023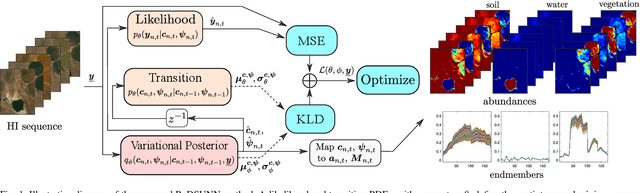
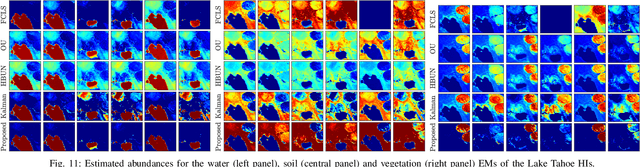
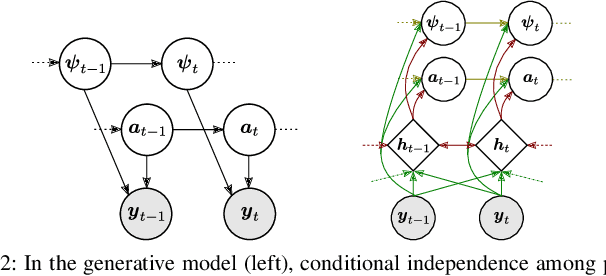
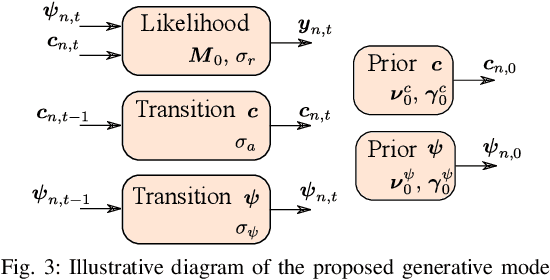
Multitemporal hyperspectral unmixing (MTHU) is a fundamental tool in the analysis of hyperspectral image sequences. It reveals the dynamical evolution of the materials (endmembers) and of their proportions (abundances) in a given scene. However, adequately accounting for the spatial and temporal variability of the endmembers in MTHU is challenging, and has not been fully addressed so far in unsupervised frameworks. In this work, we propose an unsupervised MTHU algorithm based on variational recurrent neural networks. First, a stochastic model is proposed to represent both the dynamical evolution of the endmembers and their abundances, as well as the mixing process. Moreover, a new model based on a low-dimensional parametrization is used to represent spatial and temporal endmember variability, significantly reducing the amount of variables to be estimated. We propose to formulate MTHU as a Bayesian inference problem. However, the solution to this problem does not have an analytical solution due to the nonlinearity and non-Gaussianity of the model. Thus, we propose a solution based on deep variational inference, in which the posterior distribution of the estimated abundances and endmembers is represented by using a combination of recurrent neural networks and a physically motivated model. The parameters of the model are learned using stochastic backpropagation. Experimental results show that the proposed method outperforms state of the art MTHU algorithms.
GlocalFuse-Depth: Fusing Transformers and CNNs for All-day Self-supervised Monocular Depth Estimation
Feb 20, 2023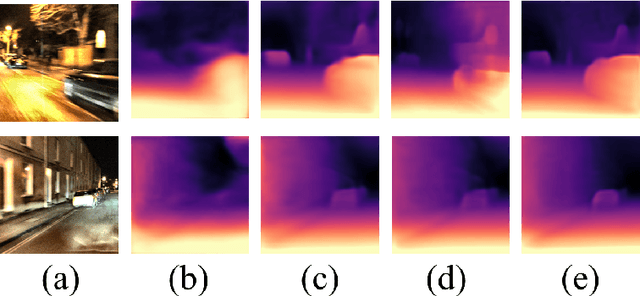
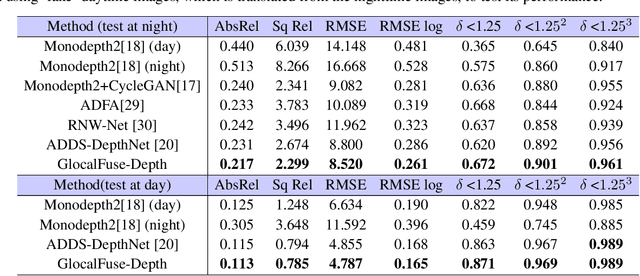
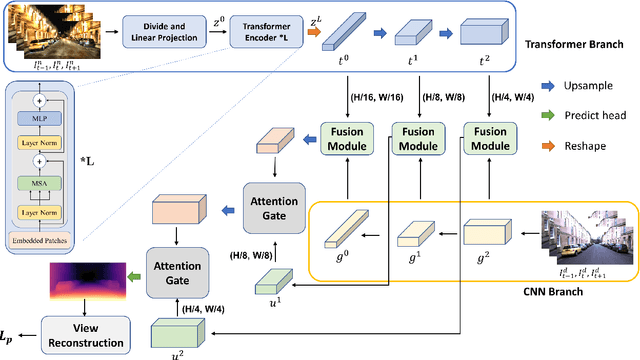
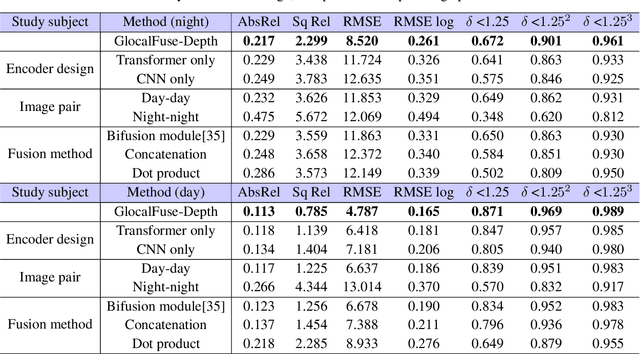
In recent years, self-supervised monocular depth estimation has drawn much attention since it frees of depth annotations and achieved remarkable results on standard benchmarks. However, most of existing methods only focus on either daytime or nighttime images, thus their performance degrades on the other domain because of the large domain shift between daytime and nighttime images. To address this problem, in this paper we propose a two-branch network named GlocalFuse-Depth for self-supervised depth estimation of all-day images. The daytime and nighttime image in input image pair are fed into the two branches: CNN branch and Transformer branch, respectively, where both fine-grained details and global dependency can be efficiently captured. Besides, a novel fusion module is proposed to fuse multi-dimensional features from the two branches. Extensive experiments demonstrate that GlocalFuse-Depth achieves state-of-the-art results for all-day images on the Oxford RobotCar dataset, which proves the superiority of our method.
Is synthetic data from generative models ready for image recognition?
Oct 14, 2022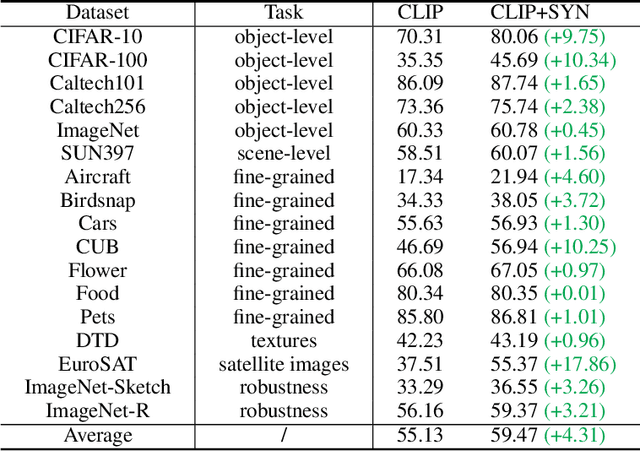
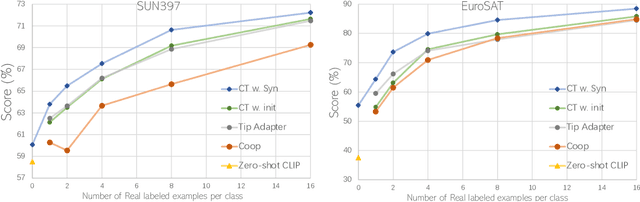
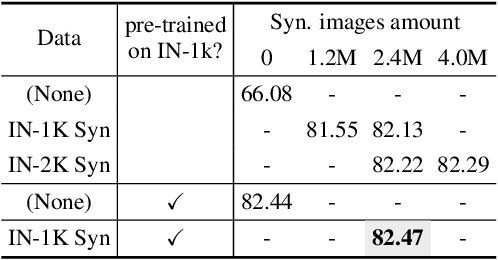

Recent text-to-image generation models have shown promising results in generating high-fidelity photo-realistic images. Though the results are astonishing to human eyes, how applicable these generated images are for recognition tasks remains under-explored. In this work, we extensively study whether and how synthetic images generated from state-of-the-art text-to-image generation models can be used for image recognition tasks, and focus on two perspectives: synthetic data for improving classification models in data-scarce settings (i.e. zero-shot and few-shot), and synthetic data for large-scale model pre-training for transfer learning. We showcase the powerfulness and shortcomings of synthetic data from existing generative models, and propose strategies for better applying synthetic data for recognition tasks. Code: https://github.com/CVMI-Lab/SyntheticData.
Dynamic Atomic Column Detection in Transmission Electron Microscopy Videos via Ridge Estimation
Feb 02, 2023
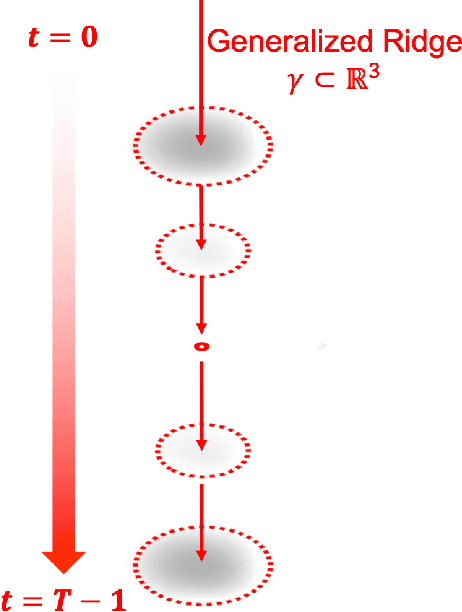
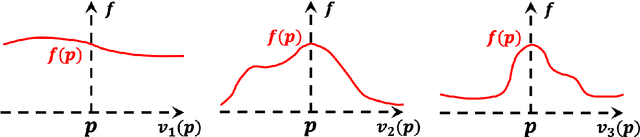
Ridge detection is a classical tool to extract curvilinear features in image processing. As such, it has great promise in applications to material science problems; specifically, for trend filtering relatively stable atom-shaped objects in image sequences, such as Transmission Electron Microscopy (TEM) videos. Standard analysis of TEM videos is limited to frame-by-frame object recognition. We instead harness temporal correlation across frames through simultaneous analysis of long image sequences, specified as a spatio-temporal image tensor. We define new ridge detection algorithms to non-parametrically estimate explicit trajectories of atomic-level object locations as a continuous function of time. Our approach is specially tailored to handle temporal analysis of objects that seemingly stochastically disappear and subsequently reappear throughout a sequence. We demonstrate that the proposed method is highly effective and efficient in simulation scenarios, and delivers notable performance improvements in TEM experiments compared to other material science benchmarks.
Style-Guided Inference of Transformer for High-resolution Image Synthesis
Oct 11, 2022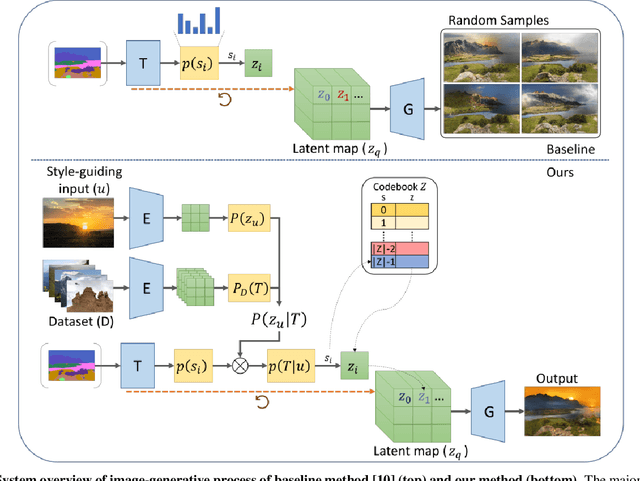


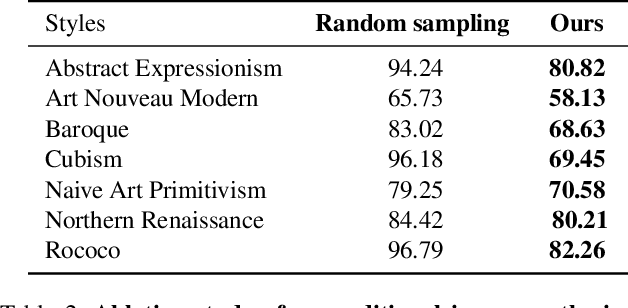
Transformer is eminently suitable for auto-regressive image synthesis which predicts discrete value from the past values recursively to make up full image. Especially, combined with vector quantised latent representation, the state-of-the-art auto-regressive transformer displays realistic high-resolution images. However, sampling the latent code from discrete probability distribution makes the output unpredictable. Therefore, it requires to generate lots of diverse samples to acquire desired outputs. To alleviate the process of generating lots of samples repetitively, in this article, we propose to take a desired output, a style image, as an additional condition without re-training the transformer. To this end, our method transfers the style to a probability constraint to re-balance the prior, thereby specifying the target distribution instead of the original prior. Thus, generated samples from the re-balanced prior have similar styles to reference style. In practice, we can choose either an image or a category of images as an additional condition. In our qualitative assessment, we show that styles of majority of outputs are similar to the input style.