 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Linearly Mapping from Image to Text Space
Sep 30, 2022

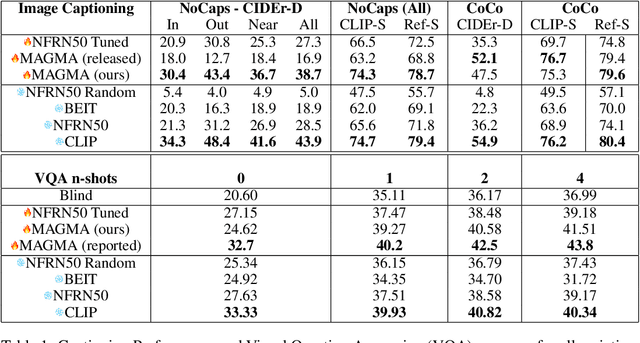

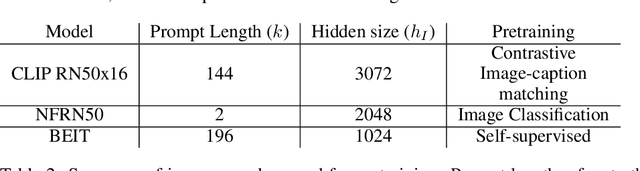
The extent to which text-only language models (LMs) learn to represent the physical, non-linguistic world is an open question. Prior work has shown that pretrained LMs can be taught to ``understand'' visual inputs when the models' parameters are updated on image captioning tasks. We test a stronger hypothesis: that the conceptual representations learned by text-only models are functionally equivalent (up to a linear transformation) to those learned by models trained on vision tasks. Specifically, we show that the image representations from vision models can be transferred as continuous prompts to frozen LMs by training only a single linear projection. Using these to prompt the LM achieves competitive performance on captioning and visual question answering tasks compared to models that tune both the image encoder and text decoder (such as the MAGMA model). We compare three image encoders with increasing amounts of linguistic supervision seen during pretraining: BEIT (no linguistic information), NF-ResNET (lexical category information), and CLIP (full natural language descriptions). We find that all three encoders perform equally well at transferring visual property information to the language model (e.g., whether an animal is large or small), but that image encoders pretrained with linguistic supervision more saliently encode category information (e.g., distinguishing hippo vs.\ elephant) and thus perform significantly better on benchmark language-and-vision tasks. Our results indicate that LMs encode conceptual information structurally similarly to vision-based models, even those that are solely trained on images.
Multi-site, Multi-domain Airway Tree Modeling (ATM'22): A Public Benchmark for Pulmonary Airway Segmentation
Mar 10, 2023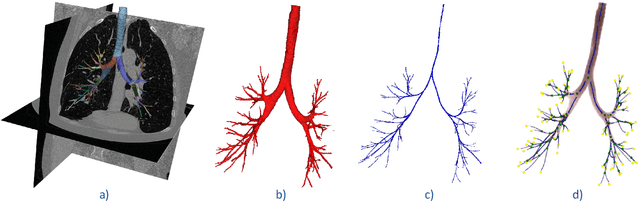

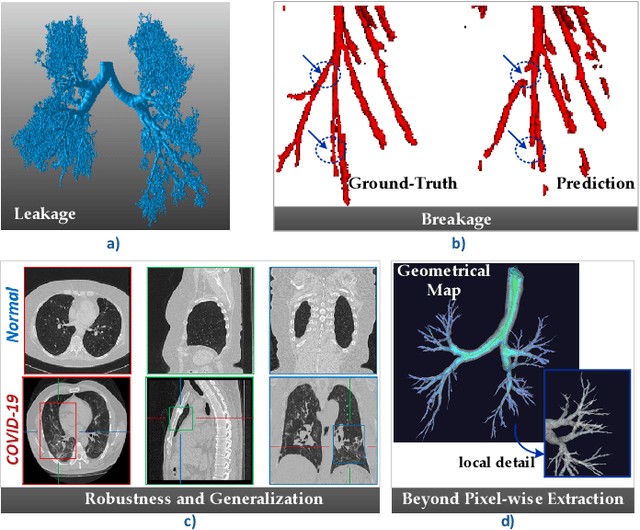

Open international challenges are becoming the de facto standard for assessing computer vision and image analysis algorithms. In recent years, new methods have extended the reach of pulmonary airway segmentation that is closer to the limit of image resolution. Since EXACT'09 pulmonary airway segmentation, limited effort has been directed to quantitative comparison of newly emerged algorithms driven by the maturity of deep learning based approaches and clinical drive for resolving finer details of distal airways for early intervention of pulmonary diseases. Thus far, public annotated datasets are extremely limited, hindering the development of data-driven methods and detailed performance evaluation of new algorithms. To provide a benchmark for the medical imaging community, we organized the Multi-site, Multi-domain Airway Tree Modeling (ATM'22), which was held as an official challenge event during the MICCAI 2022 conference. ATM'22 provides large-scale CT scans with detailed pulmonary airway annotation, including 500 CT scans (300 for training, 50 for validation, and 150 for testing). The dataset was collected from different sites and it further included a portion of noisy COVID-19 CTs with ground-glass opacity and consolidation. Twenty-three teams participated in the entire phase of the challenge and the algorithms for the top ten teams are reviewed in this paper. Quantitative and qualitative results revealed that deep learning models embedded with the topological continuity enhancement achieved superior performance in general. ATM'22 challenge holds as an open-call design, the training data and the gold standard evaluation are available upon successful registration via its homepage.
DDT: A Diffusion-Driven Transformer-based Framework for Human Mesh Recovery from a Video
Mar 23, 2023

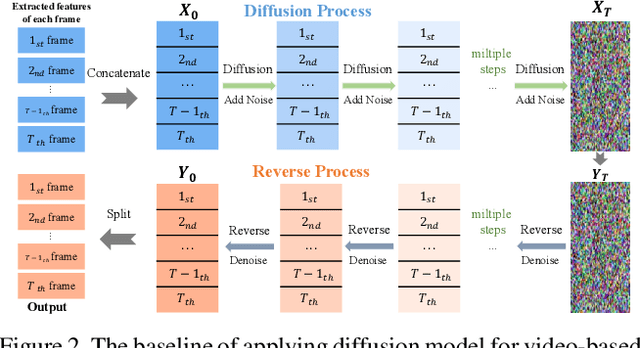
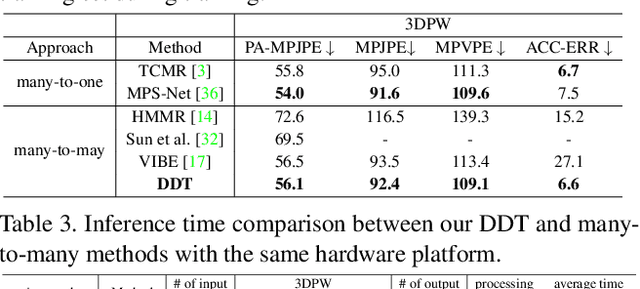
Human mesh recovery (HMR) provides rich human body information for various real-world applications such as gaming, human-computer interaction, and virtual reality. Compared to single image-based methods, video-based methods can utilize temporal information to further improve performance by incorporating human body motion priors. However, many-to-many approaches such as VIBE suffer from motion smoothness and temporal inconsistency. While many-to-one approaches such as TCMR and MPS-Net rely on the future frames, which is non-causal and time inefficient during inference. To address these challenges, a novel Diffusion-Driven Transformer-based framework (DDT) for video-based HMR is presented. DDT is designed to decode specific motion patterns from the input sequence, enhancing motion smoothness and temporal consistency. As a many-to-many approach, the decoder of our DDT outputs the human mesh of all the frames, making DDT more viable for real-world applications where time efficiency is crucial and a causal model is desired. Extensive experiments are conducted on the widely used datasets (Human3.6M, MPI-INF-3DHP, and 3DPW), which demonstrated the effectiveness and efficiency of our DDT.
Nearest-Neighbor Inter-Intra Contrastive Learning from Unlabeled Videos
Mar 13, 2023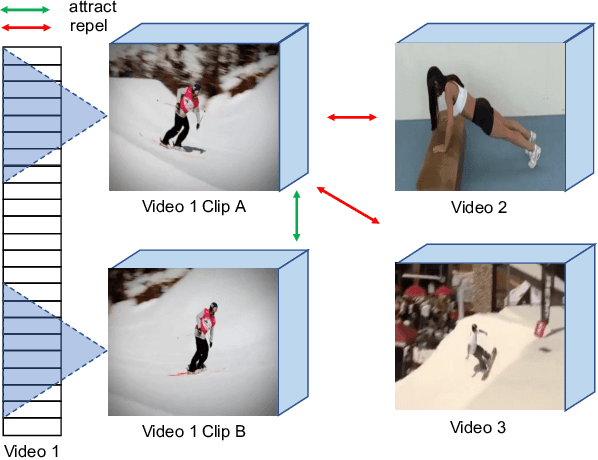
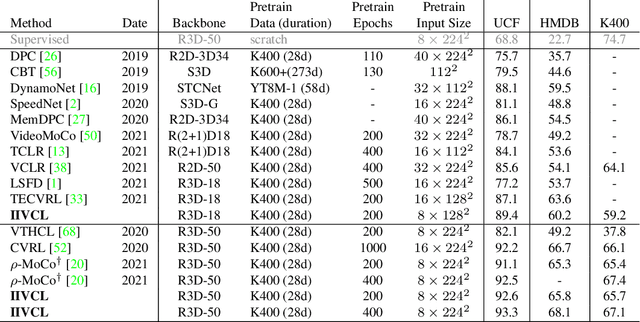
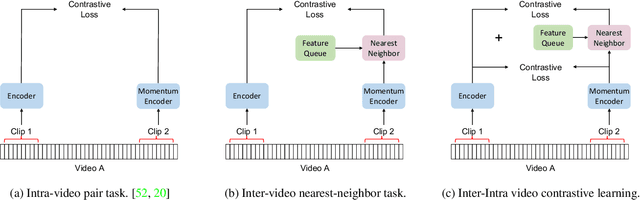
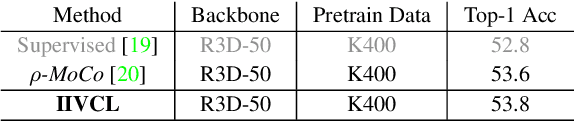
Contrastive learning has recently narrowed the gap between self-supervised and supervised methods in image and video domain. State-of-the-art video contrastive learning methods such as CVRL and $\rho$-MoCo spatiotemporally augment two clips from the same video as positives. By only sampling positive clips locally from a single video, these methods neglect other semantically related videos that can also be useful. To address this limitation, we leverage nearest-neighbor videos from the global space as additional positive pairs, thus improving positive key diversity and introducing a more relaxed notion of similarity that extends beyond video and even class boundaries. Our method, Inter-Intra Video Contrastive Learning (IIVCL), improves performance on a range of video tasks.
Vision Transformer for Adaptive Image Transmission over MIMO Channels
Oct 27, 2022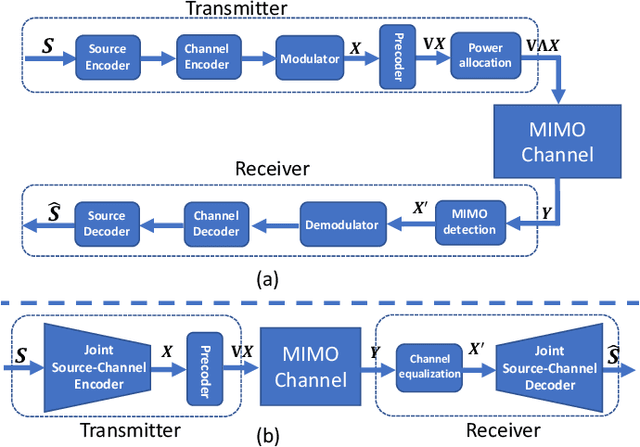
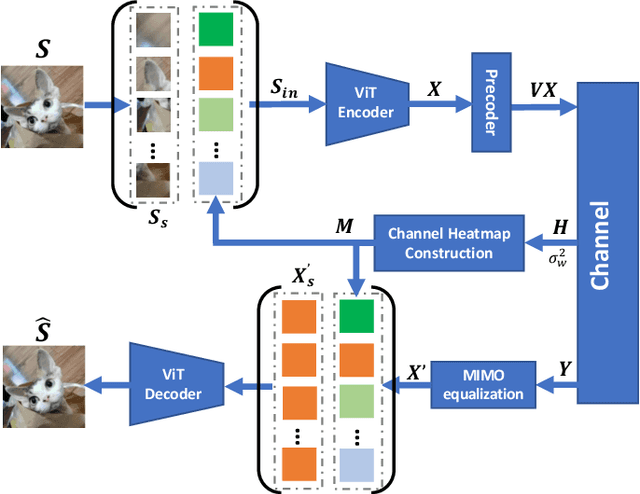
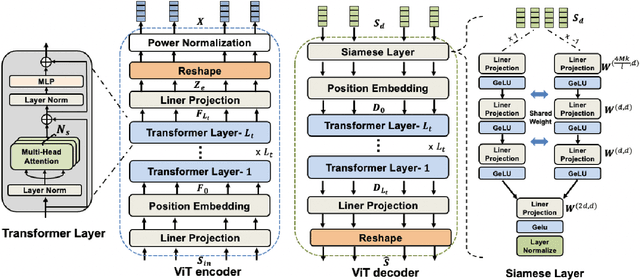
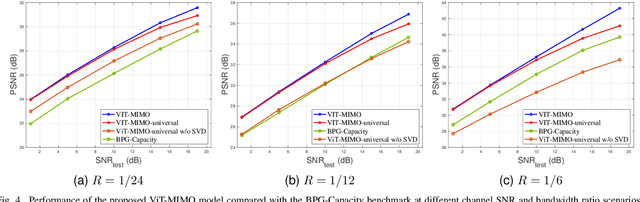
This paper presents a vision transformer (ViT) based joint source and channel coding (JSCC) scheme for wireless image transmission over multiple-input multiple-output (MIMO) systems, called ViT-MIMO. The proposed ViT-MIMO architecture, in addition to outperforming separation-based benchmarks, can flexibly adapt to different channel conditions without requiring retraining. Specifically, exploiting the self-attention mechanism of the ViT enables the proposed ViT-MIMO model to adaptively learn the feature mapping and power allocation based on the source image and channel conditions. Numerical experiments show that ViT-MIMO can significantly improve the transmission quality cross a large variety of scenarios, including varying channel conditions, making it an attractive solution for emerging semantic communication systems.
Enhanced detection of the presence and severity of COVID-19 from CT scans using lung segmentation
Mar 19, 2023Improving automated analysis of medical imaging will provide clinicians more options in providing care for patients. The 2023 AI-enabled Medical Image Analysis Workshop and Covid-19 Diagnosis Competition (AI-MIA-COV19D) provides an opportunity to test and refine machine learning methods for detecting the presence and severity of COVID-19 in patients from CT scans. This paper presents version 2 of Cov3d, a deep learning model submitted in the 2022 competition. The model has been improved through a preprocessing step which segments the lungs in the CT scan and crops the input to this region. It results in a validation macro F1 score for predicting the presence of COVID-19 in the CT scans at 93.2% which is significantly above the baseline of 74\%. It gives a macro F1 score for predicting the severity of COVID-19 on the validation set for task 2 as 72.8% which is above the baseline of 38%.
Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes
Mar 05, 2023
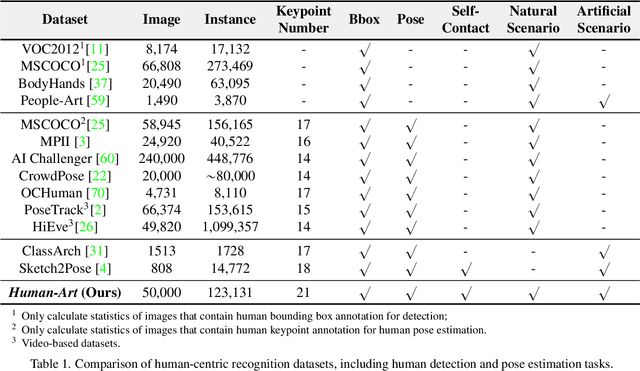
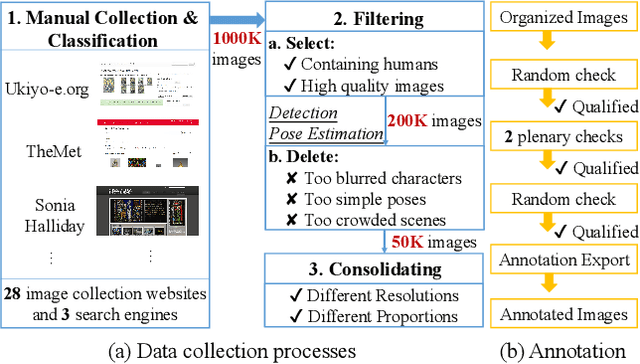
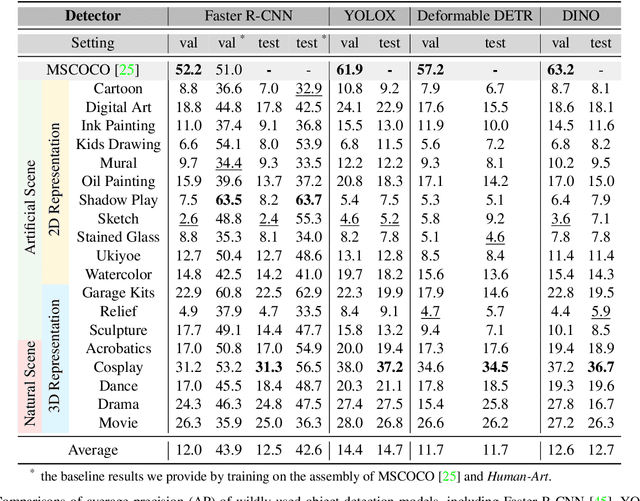
Humans have long been recorded in a variety of forms since antiquity. For example, sculptures and paintings were the primary media for depicting human beings before the invention of cameras. However, most current human-centric computer vision tasks like human pose estimation and human image generation focus exclusively on natural images in the real world. Artificial humans, such as those in sculptures, paintings, and cartoons, are commonly neglected, making existing models fail in these scenarios. As an abstraction of life, art incorporates humans in both natural and artificial scenes. We take advantage of it and introduce the Human-Art dataset to bridge related tasks in natural and artificial scenarios. Specifically, Human-Art contains 50k high-quality images with over 123k person instances from 5 natural and 15 artificial scenarios, which are annotated with bounding boxes, keypoints, self-contact points, and text information for humans represented in both 2D and 3D. It is, therefore, comprehensive and versatile for various downstream tasks. We also provide a rich set of baseline results and detailed analyses for related tasks, including human detection, 2D and 3D human pose estimation, image generation, and motion transfer. As a challenging dataset, we hope Human-Art can provide insights for relevant research and open up new research questions.
Multi-modal Prompting for Low-Shot Temporal Action Localization
Mar 21, 2023

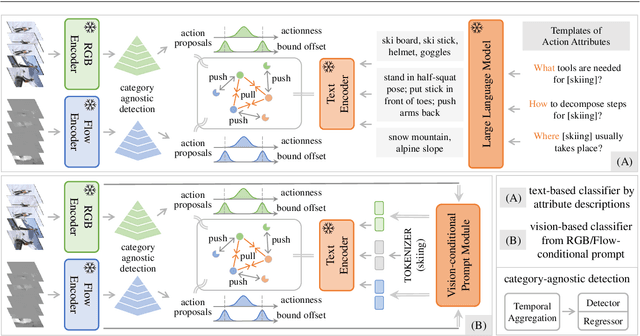
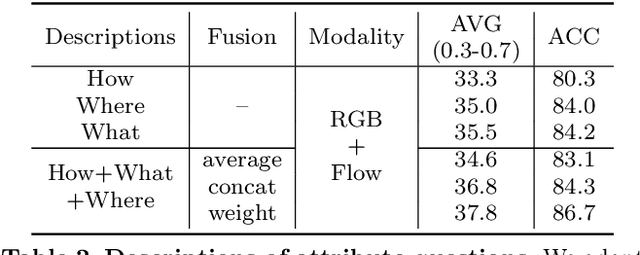
In this paper, we consider the problem of temporal action localization under low-shot (zero-shot & few-shot) scenario, with the goal of detecting and classifying the action instances from arbitrary categories within some untrimmed videos, even not seen at training time. We adopt a Transformer-based two-stage action localization architecture with class-agnostic action proposal, followed by open-vocabulary classification. We make the following contributions. First, to compensate image-text foundation models with temporal motions, we improve category-agnostic action proposal by explicitly aligning embeddings of optical flows, RGB and texts, which has largely been ignored in existing low-shot methods. Second, to improve open-vocabulary action classification, we construct classifiers with strong discriminative power, i.e., avoid lexical ambiguities. To be specific, we propose to prompt the pre-trained CLIP text encoder either with detailed action descriptions (acquired from large-scale language models), or visually-conditioned instance-specific prompt vectors. Third, we conduct thorough experiments and ablation studies on THUMOS14 and ActivityNet1.3, demonstrating the superior performance of our proposed model, outperforming existing state-of-the-art approaches by one significant margin.
Detecting the open-world objects with the help of the Brain
Mar 21, 2023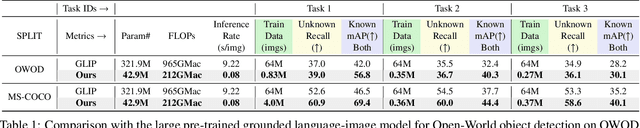
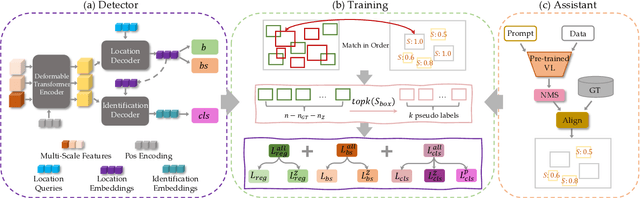
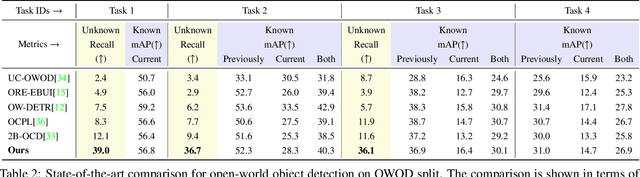
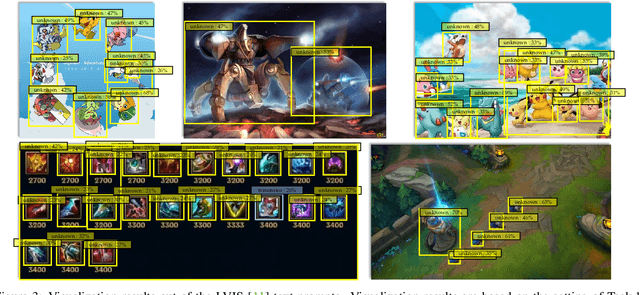
Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to detect unseen/unknown objects and incrementally learn them. The natural instinct of humans to identify unknown objects in their environments mainly depends on their brains' knowledge base. It is difficult for a model to do this only by learning from the annotation of several tiny datasets. The large pre-trained grounded language-image models - VL (\ie GLIP) have rich knowledge about the open world but are limited to the text prompt. We propose leveraging the VL as the ``Brain'' of the open-world detector by simply generating unknown labels. Leveraging it is non-trivial because the unknown labels impair the model's learning of known objects. In this paper, we alleviate these problems by proposing the down-weight loss function and decoupled detection structure. Moreover, our detector leverages the ``Brain'' to learn novel objects beyond VL through our pseudo-labeling scheme.
Deep Learning for Video-based Person Re-Identification: A Survey
Mar 21, 2023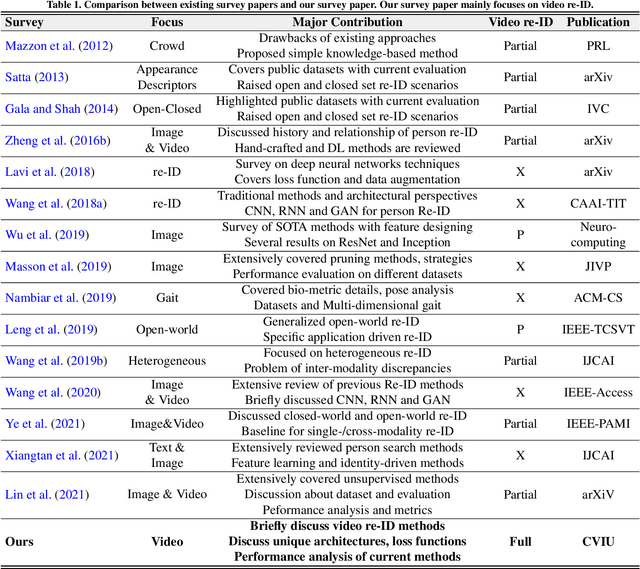


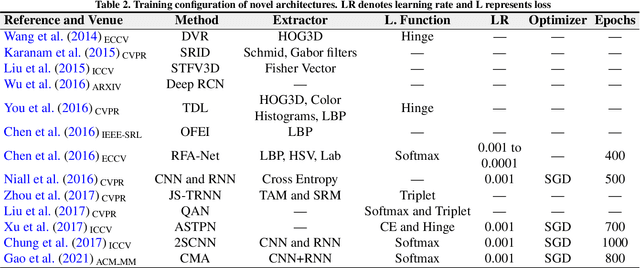
Video-based person re-identification (video re-ID) has lately fascinated growing attention due to its broad practical applications in various areas, such as surveillance, smart city, and public safety. Nevertheless, video re-ID is quite difficult and is an ongoing stage due to numerous uncertain challenges such as viewpoint, occlusion, pose variation, and uncertain video sequence, etc. In the last couple of years, deep learning on video re-ID has continuously achieved surprising results on public datasets, with various approaches being developed to handle diverse problems in video re-ID. Compared to image-based re-ID, video re-ID is much more challenging and complex. To encourage future research and challenges, this first comprehensive paper introduces a review of up-to-date advancements in deep learning approaches for video re-ID. It broadly covers three important aspects, including brief video re-ID methods with their limitations, major milestones with technical challenges, and architectural design. It offers comparative performance analysis on various available datasets, guidance to improve video re-ID with valuable thoughts, and exciting research directions.