 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Interactive Text Generation
Mar 02, 2023
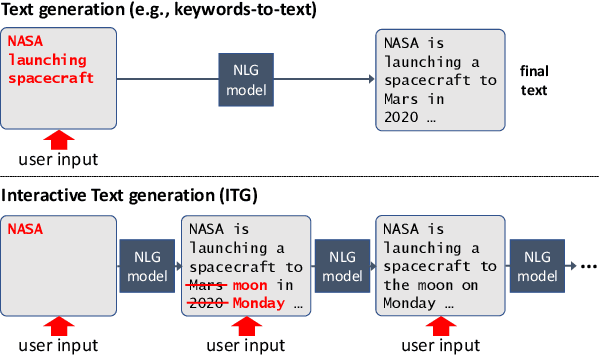
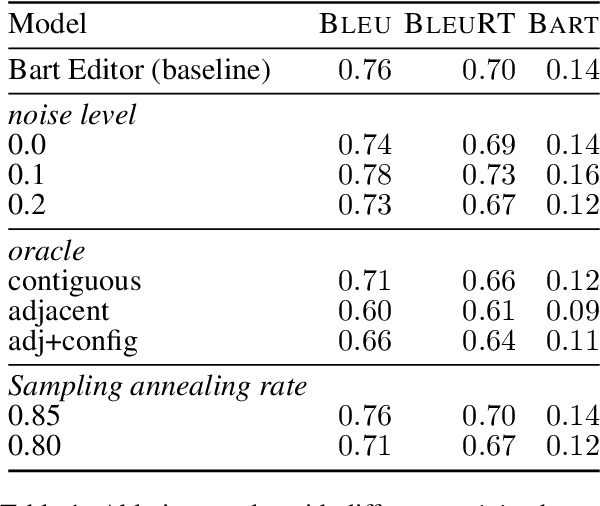
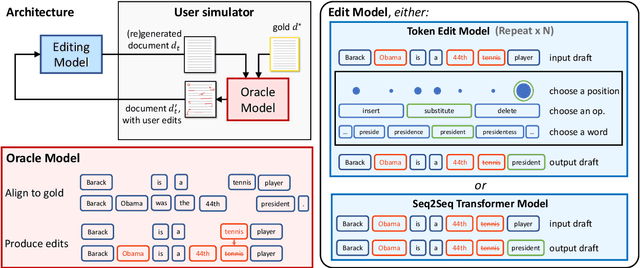
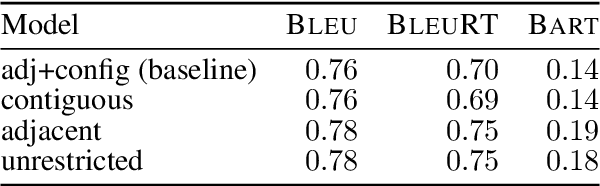
Users interact with text, image, code, or other editors on a daily basis. However, machine learning models are rarely trained in the settings that reflect the interactivity between users and their editor. This is understandable as training AI models with real users is not only slow and costly, but what these models learn may be specific to user interface design choices. Unfortunately, this means most of the research on text, code, and image generation has focused on non-interactive settings, whereby the model is expected to get everything right without accounting for any input from a user who may be willing to help. We introduce a new Interactive Text Generation task that allows training generation models interactively without the costs of involving real users, by using user simulators that provide edits that guide the model towards a given target text. We train our interactive models using Imitation Learning, and our experiments against competitive non-interactive generation models show that models trained interactively are superior to their non-interactive counterparts, even when all models are given the same budget of user inputs or edits.
VieCap4H - VLSP 2021: ObjectAoA -- Enhancing performance of Object Relation Transformer with Attention on Attention for Vietnamese image captioning
Nov 10, 2022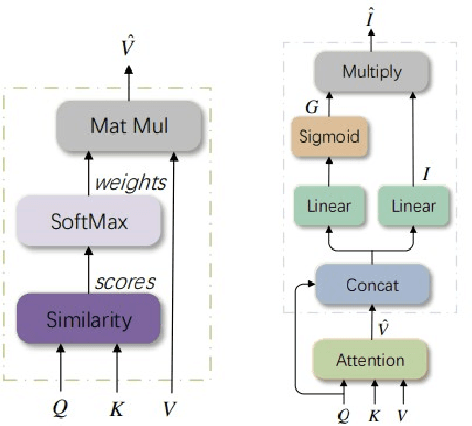

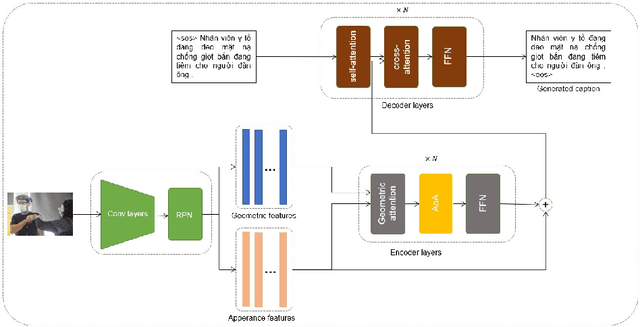

Image captioning is currently a challenging task that requires the ability to both understand visual information and use human language to describe this visual information in the image. In this paper, we propose an efficient way to improve the image understanding ability of transformer-based method by extending Object Relation Transformer architecture with Attention on Attention mechanism. Experiments on the VieCap4H dataset show that our proposed method significantly outperforms its original structure on both the public test and private test of the Image Captioning shared task held by VLSP.
SegViz: A Federated Learning Framework for Medical Image Segmentation from Distributed Datasets with Different and Incomplete Annotations
Jan 17, 2023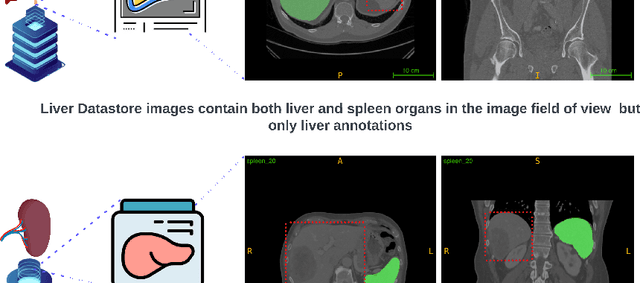
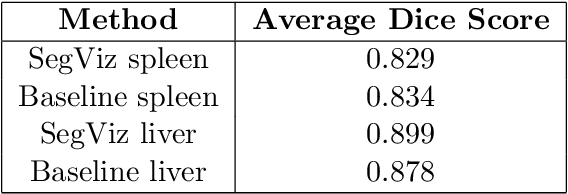
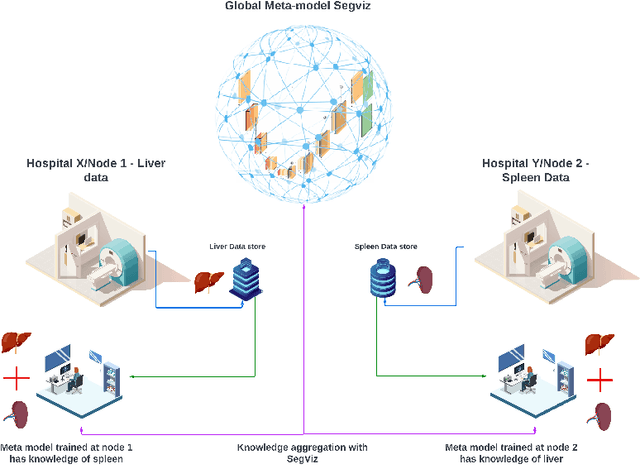
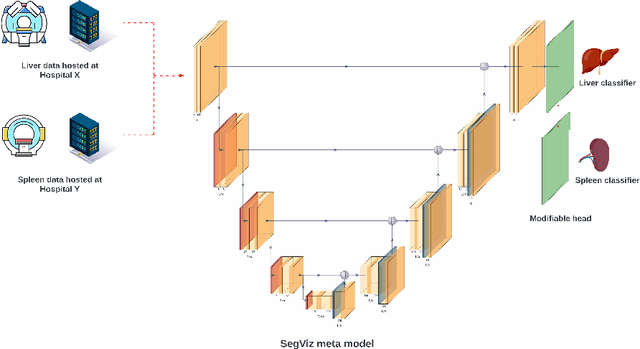
Segmentation is one of the primary tasks in the application of deep learning in medical imaging, owing to its multiple downstream clinical applications. As a result, many large-scale segmentation datasets have been curated and released for the segmentation of different anatomical structures. However, these datasets focus on the segmentation of a subset of anatomical structures in the body, therefore, training a model for each dataset would potentially result in hundreds of models and thus limit their clinical translational utility. Furthermore, many of these datasets share the same field of view but have different subsets of annotations, thus making individual dataset annotations incomplete. To that end, we developed SegViz, a federated learning framework for aggregating knowledge from distributed medical image segmentation datasets with different and incomplete annotations into a `global` meta-model. The SegViz framework was trained to build a single model capable of segmenting both liver and spleen aggregating knowledge from both these nodes by aggregating the weights after every 10 epochs. The global SegViz model was tested on an external dataset, Beyond the Cranial Vault (BTCV), comprising both liver and spleen annotations using the dice similarity (DS) metric. The baseline individual segmentation models for spleen and liver trained on their respective datasets produced a DS score of 0.834 and 0.878 on the BTCV test set. In comparison, the SegViz model produced comparable mean DS scores of 0.829 and 0.899 for the segmentation of the spleen and liver respectively. Our results demonstrate SegViz as an essential first step towards training clinically translatable multi-task segmentation models from distributed datasets with disjoint incomplete annotations with excellent performance.
N-Gram in Swin Transformers for Efficient Lightweight Image Super-Resolution
Nov 21, 2022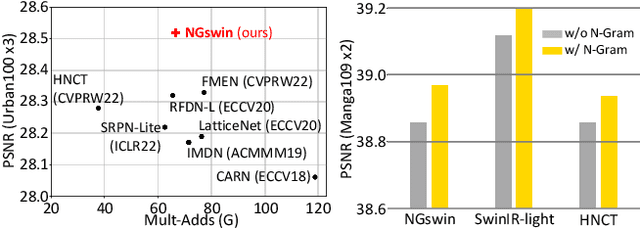
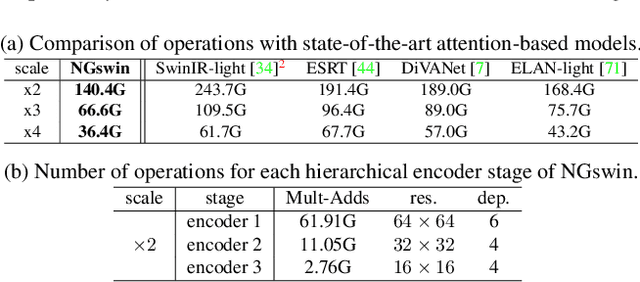
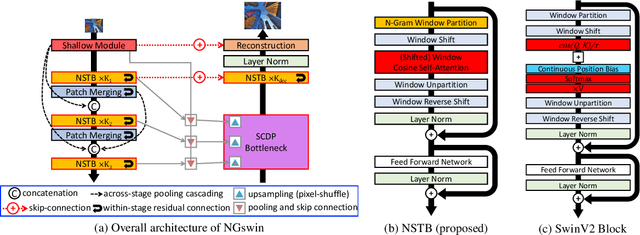
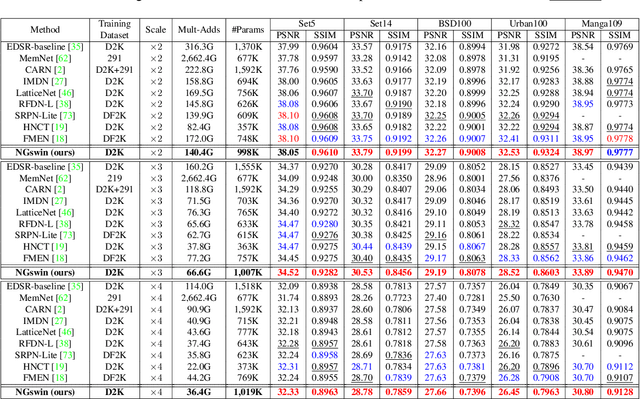
While some studies have proven that Swin Transformer (SwinT) with window self-attention (WSA) is suitable for single image super-resolution (SR), SwinT ignores the broad regions for reconstructing high-resolution images due to window and shift size. In addition, many deep learning SR methods suffer from intensive computations. To address these problems, we introduce the N-Gram context to the image domain for the first time in history. We define N-Gram as neighboring local windows in SwinT, which differs from text analysis that views N-Gram as consecutive characters or words. N-Grams interact with each other by sliding-WSA, expanding the regions seen to restore degraded pixels. Using the N-Gram context, we propose NGswin, an efficient SR network with SCDP bottleneck taking all outputs of the hierarchical encoder. Experimental results show that NGswin achieves competitive performance while keeping an efficient structure, compared with previous leading methods. Moreover, we also improve other SwinT-based SR methods with the N-Gram context, thereby building an enhanced model: SwinIR-NG. Our improved SwinIR-NG outperforms the current best lightweight SR approaches and establishes state-of-the-art results. Codes will be available soon.
Discriminative feature encoding for intrinsic image decomposition
Sep 25, 2022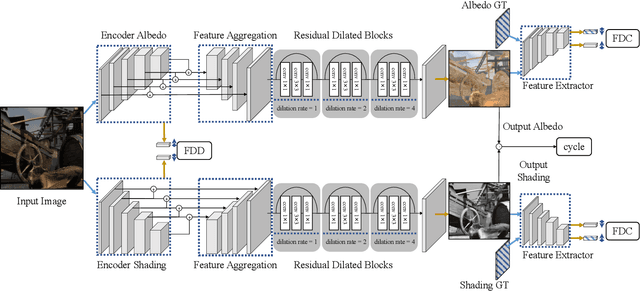



Intrinsic image decomposition is an important and long-standing computer vision problem. Given an input image, recovering the physical scene properties is ill-posed. Several physically motivated priors have been used to restrict the solution space of the optimization problem for intrinsic image decomposition. This work takes advantage of deep learning, and shows that it can solve this challenging computer vision problem with high efficiency. The focus lies in the feature encoding phase to extract discriminative features for different intrinsic layers from an input image. To achieve this goal, we explore the distinctive characteristics of different intrinsic components in the high dimensional feature embedding space. We define feature distribution divergence to efficiently separate the feature vectors of different intrinsic components. The feature distributions are also constrained to fit the real ones through a feature distribution consistency. In addition, a data refinement approach is provided to remove data inconsistency from the Sintel dataset, making it more suitable for intrinsic image decomposition. Our method is also extended to intrinsic video decomposition based on pixel-wise correspondences between adjacent frames. Experimental results indicate that our proposed network structure can outperform the existing state-of-the-art.
Universal Perturbation Attack on Differentiable No-Reference Image- and Video-Quality Metrics
Nov 01, 2022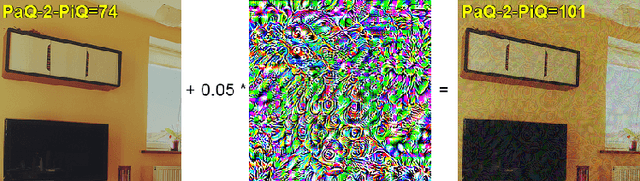
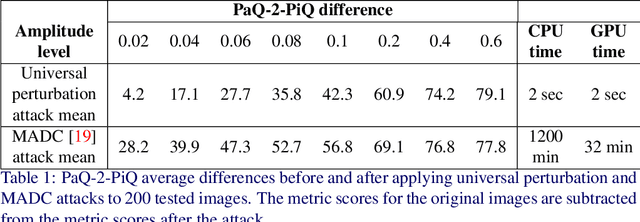
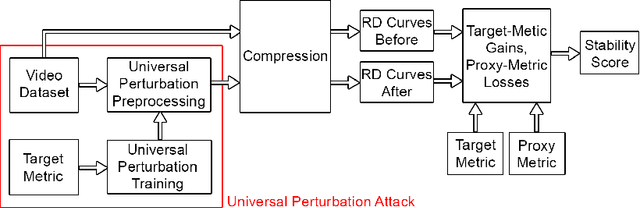
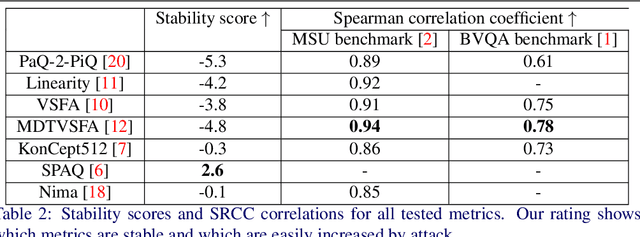
Universal adversarial perturbation attacks are widely used to analyze image classifiers that employ convolutional neural networks. Nowadays, some attacks can deceive image- and video-quality metrics. So sustainability analysis of these metrics is important. Indeed, if an attack can confuse the metric, an attacker can easily increase quality scores. When developers of image- and video-algorithms can boost their scores through detached processing, algorithm comparisons are no longer fair. Inspired by the idea of universal adversarial perturbation for classifiers, we suggest a new method to attack differentiable no-reference quality metrics through universal perturbation. We applied this method to seven no-reference image- and video-quality metrics (PaQ-2-PiQ, Linearity, VSFA, MDTVSFA, KonCept512, Nima and SPAQ). For each one, we trained a universal perturbation that increases the respective scores. We also propose a method for assessing metric stability and identify the metrics that are the most vulnerable and the most resistant to our attack. The existence of successful universal perturbations appears to diminish the metric's ability to provide reliable scores. We therefore recommend our proposed method as an additional verification of metric reliability to complement traditional subjective tests and benchmarks.
Rethinking Generative Methods for Image Restoration in Physics-based Vision: A Theoretical Analysis from the Perspective of Information
Dec 08, 2022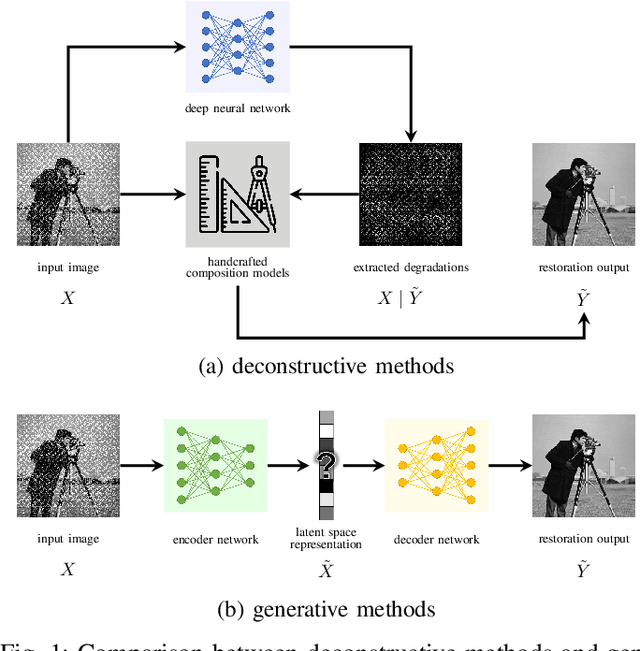
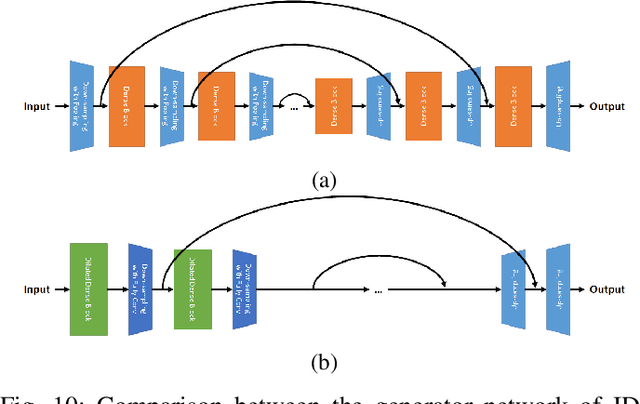
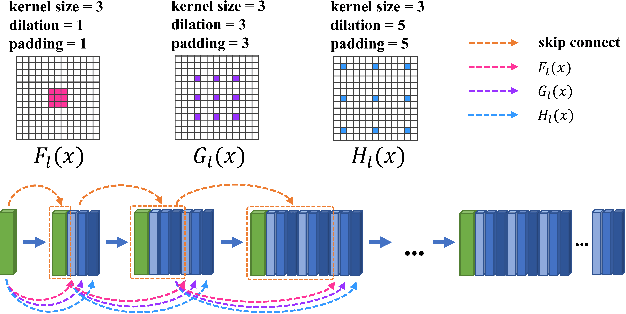
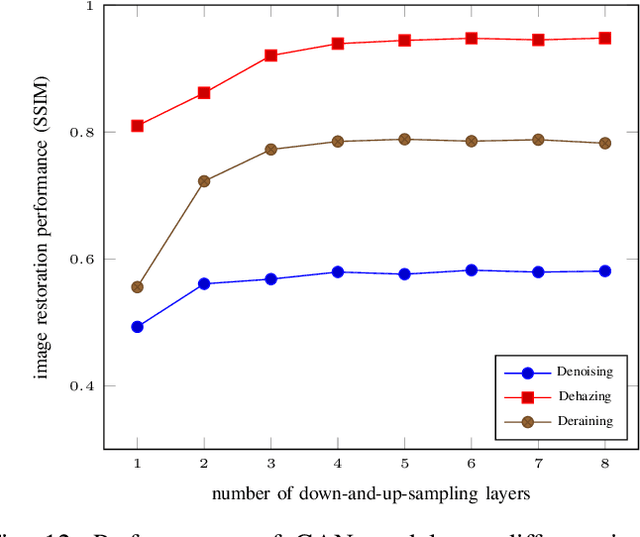
End-to-end generative methods are considered a more promising solution for image restoration in physics-based vision compared with the traditional deconstructive methods based on handcrafted composition models. However, existing generative methods still have plenty of room for improvement in quantitative performance. More crucially, these methods are considered black boxes due to weak interpretability and there is rarely a theory trying to explain their mechanism and learning process. In this study, we try to re-interpret these generative methods for image restoration tasks using information theory. Different from conventional understanding, we analyzed the information flow of these methods and identified three sources of information (extracted high-level information, retained low-level information, and external information that is absent from the source inputs) are involved and optimized respectively in generating the restoration results. We further derived their learning behaviors, optimization objectives, and the corresponding information boundaries by extending the information bottleneck principle. Based on this theoretic framework, we found that many existing generative methods tend to be direct applications of the general models designed for conventional generation tasks, which may suffer from problems including over-invested abstraction processes, inherent details loss, and vanishing gradients or imbalance in training. We analyzed these issues with both intuitive and theoretical explanations and proved them with empirical evidence respectively. Ultimately, we proposed general solutions or ideas to address the above issue and validated these approaches with performance boosts on six datasets of three different image restoration tasks.
Efficient Diffusion Training via Min-SNR Weighting Strategy
Mar 16, 2023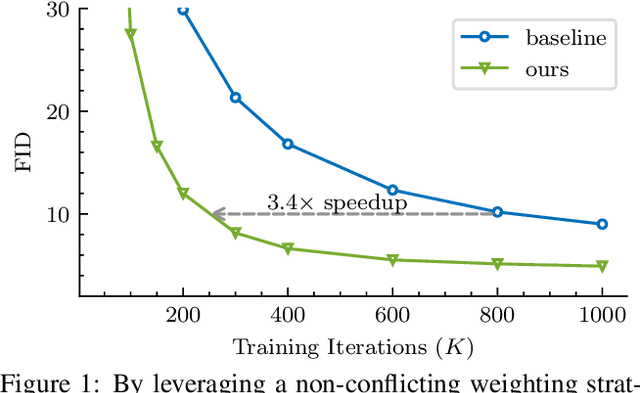
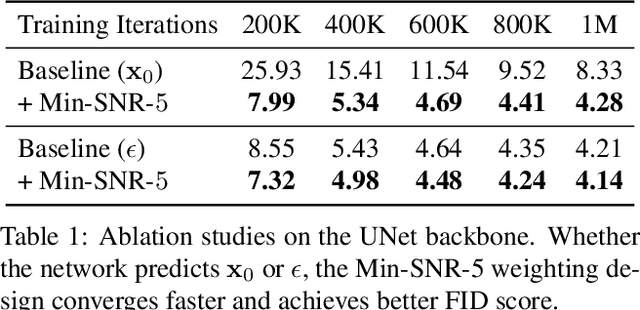
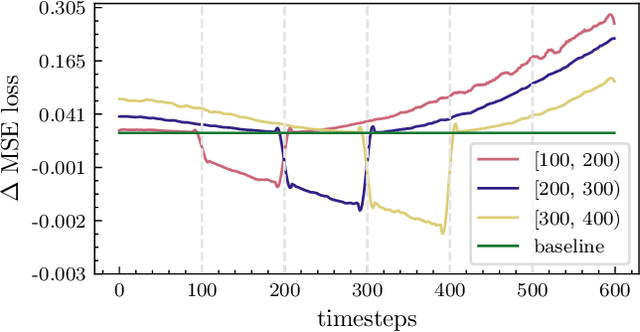
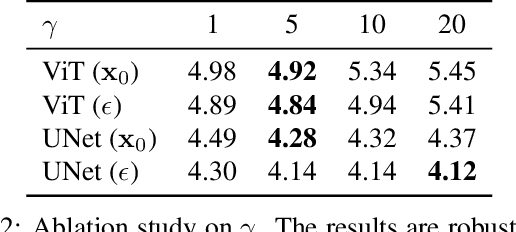
Denoising diffusion models have been a mainstream approach for image generation, however, training these models often suffers from slow convergence. In this paper, we discovered that the slow convergence is partly due to conflicting optimization directions between timesteps. To address this issue, we treat the diffusion training as a multi-task learning problem, and introduce a simple yet effective approach referred to as Min-SNR-$\gamma$. This method adapts loss weights of timesteps based on clamped signal-to-noise ratios, which effectively balances the conflicts among timesteps. Our results demonstrate a significant improvement in converging speed, 3.4$\times$ faster than previous weighting strategies. It is also more effective, achieving a new record FID score of 2.06 on the ImageNet $256\times256$ benchmark using smaller architectures than that employed in previous state-of-the-art.
UniCT DMI Solution for 3rd COV19D Competition on COVID-19 Detection trough attention deep learning for CT Scan
Mar 16, 2023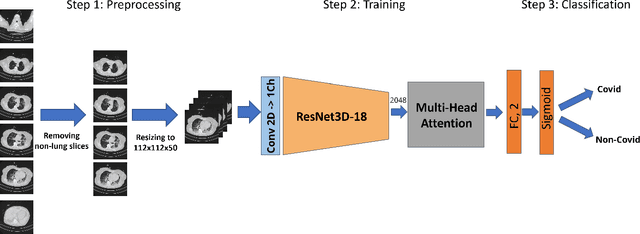
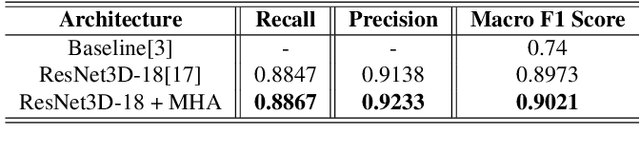
This paper presents our solution for the first challenge of the 3rd Covid-19 competition, which is part of the "AI-enabled Medical Image Analysis Workshop" organized by IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) 2023. Our proposed solution is based on a Resnet as a backbone network with the addition of attention mechanisms. The Resnet provides an effective feature extractor for the classification task, while the attention mechanisms improve the model's ability to focus on important regions of interest within the images. We conducted extensive experiments on the provided dataset and achieved promising results. Our proposed approach has the potential to assist in the accurate diagnosis of Covid-19 from chest computed tomography images, which can aid in the early detection and management of the disease.
3D Surface Reconstruction in the Wild by Deforming Shape Priors from Synthetic Data
Feb 24, 2023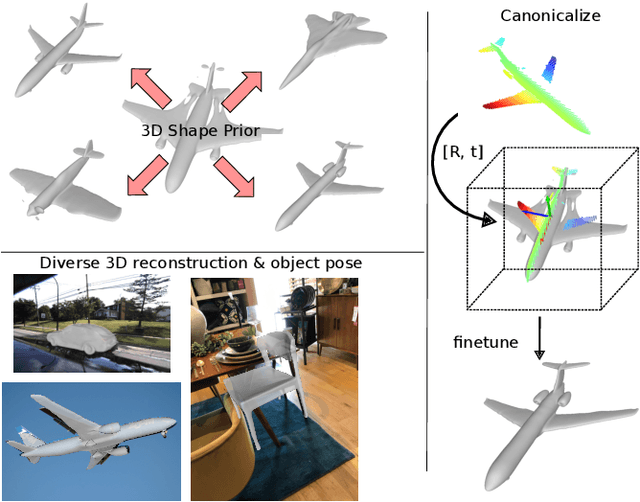
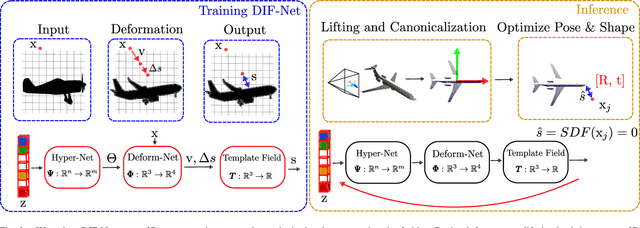


Reconstructing the underlying 3D surface of an object from a single image is a challenging problem that has received extensive attention from the computer vision community. Many learning-based approaches tackle this problem by learning a 3D shape prior from either ground truth 3D data or multi-view observations. To achieve state-of-the-art results, these methods assume that the objects are specified with respect to a fixed canonical coordinate frame, where instances of the same category are perfectly aligned. In this work, we present a new method for joint category-specific 3D reconstruction and object pose estimation from a single image. We show that one can leverage shape priors learned on purely synthetic 3D data together with a point cloud pose canonicalization method to achieve high-quality 3D reconstruction in the wild. Given a single depth image at test time, we first transform this partial point cloud into a learned canonical frame. Then, we use a neural deformation field to reconstruct the 3D surface of the object. Finally, we jointly optimize object pose and 3D shape to fit the partial depth observation. Our approach achieves state-of-the-art reconstruction performance across several real-world datasets, even when trained only on synthetic data. We further show that our method generalizes to different input modalities, from dense depth images to sparse and noisy LIDAR scans.