 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding
Mar 19, 2024

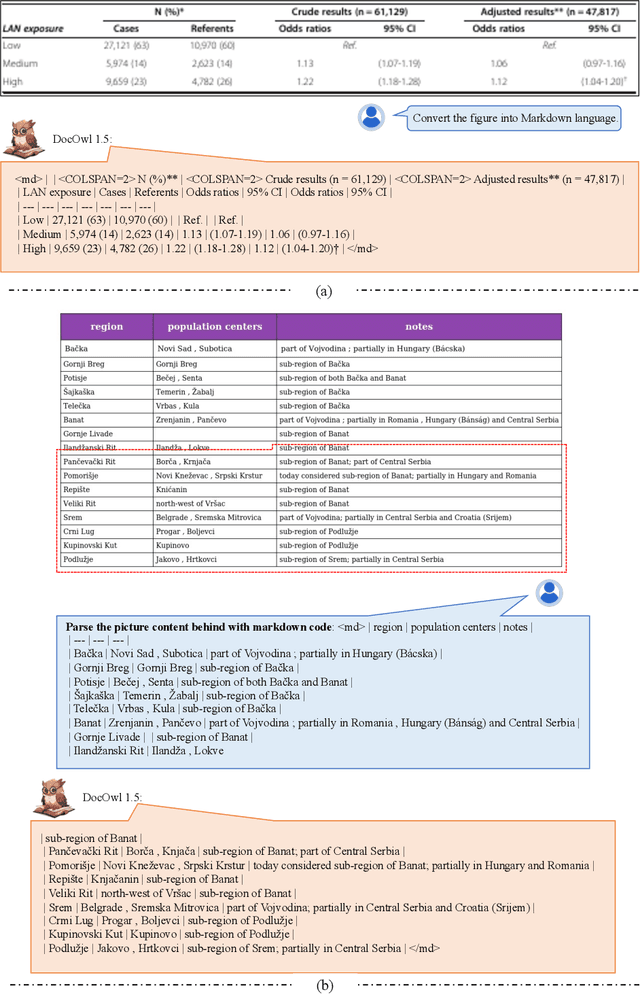

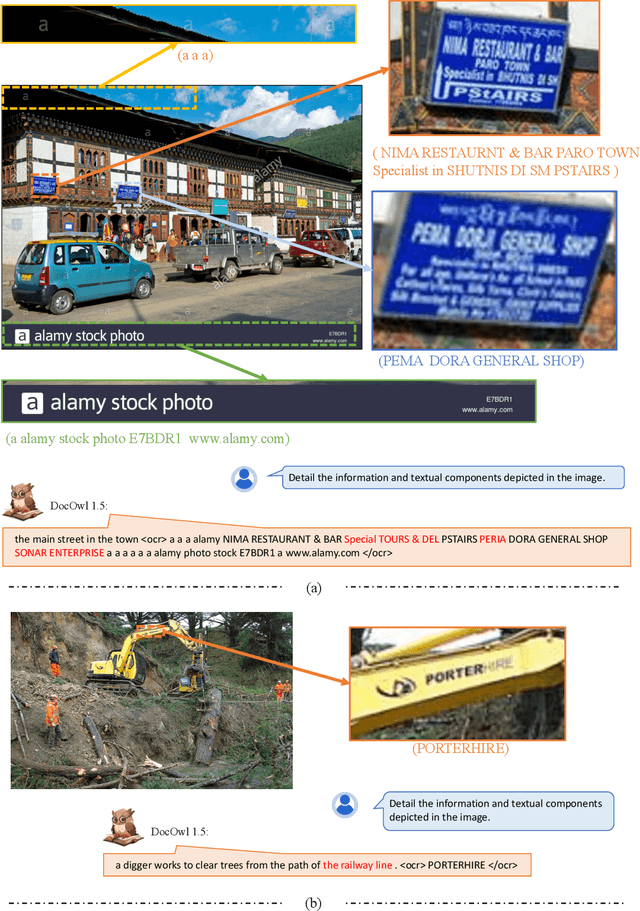
Structure information is critical for understanding the semantics of text-rich images, such as documents, tables, and charts. Existing Multimodal Large Language Models (MLLMs) for Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the Unified Structure Learning to boost the performance of MLLMs. Our Unified Structure Learning comprises structure-aware parsing tasks and multi-grained text localization tasks across 5 domains: document, webpage, table, chart, and natural image. To better encode structure information, we design a simple and effective vision-to-text module H-Reducer, which can not only maintain the layout information but also reduce the length of visual features by merging horizontal adjacent patches through convolution, enabling the LLM to understand high-resolution images more efficiently. Furthermore, by constructing structure-aware text sequences and multi-grained pairs of texts and bounding boxes for publicly available text-rich images, we build a comprehensive training set DocStruct4M to support structure learning. Finally, we construct a small but high-quality reasoning tuning dataset DocReason25K to trigger the detailed explanation ability in the document domain. Our model DocOwl 1.5 achieves state-of-the-art performance on 10 visual document understanding benchmarks, improving the SOTA performance of MLLMs with a 7B LLM by more than 10 points in 5/10 benchmarks. Our codes, models, and datasets are publicly available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5.
Ambient Diffusion Posterior Sampling: Solving Inverse Problems with Diffusion Models trained on Corrupted Data
Mar 13, 2024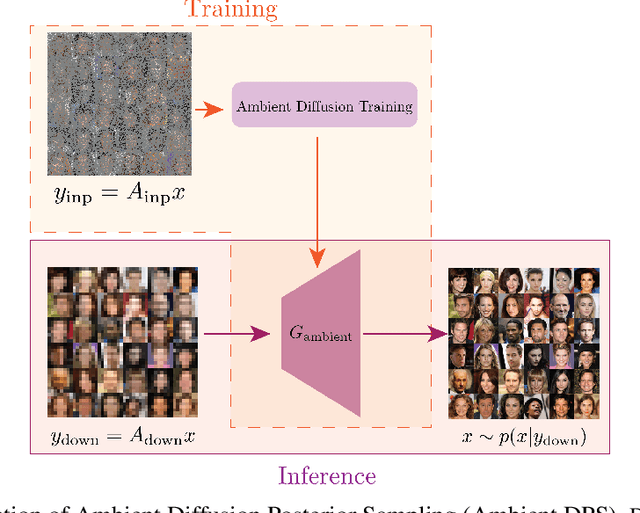
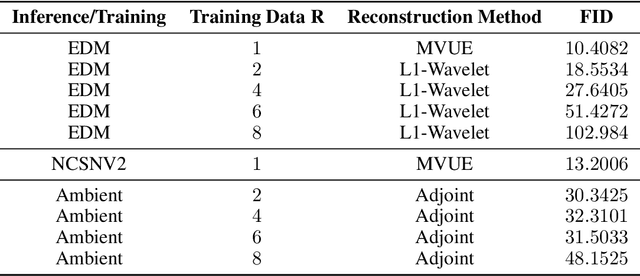
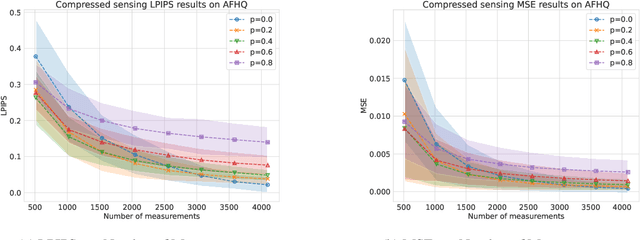
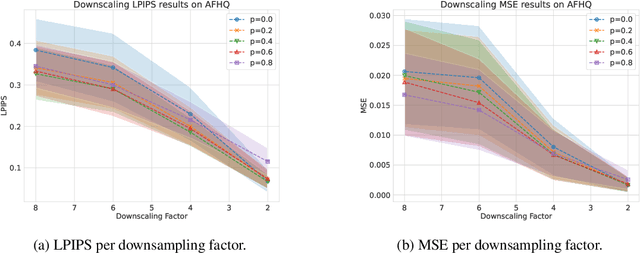
We provide a framework for solving inverse problems with diffusion models learned from linearly corrupted data. Our method, Ambient Diffusion Posterior Sampling (A-DPS), leverages a generative model pre-trained on one type of corruption (e.g. image inpainting) to perform posterior sampling conditioned on measurements from a potentially different forward process (e.g. image blurring). We test the efficacy of our approach on standard natural image datasets (CelebA, FFHQ, and AFHQ) and we show that A-DPS can sometimes outperform models trained on clean data for several image restoration tasks in both speed and performance. We further extend the Ambient Diffusion framework to train MRI models with access only to Fourier subsampled multi-coil MRI measurements at various acceleration factors (R=2, 4, 6, 8). We again observe that models trained on highly subsampled data are better priors for solving inverse problems in the high acceleration regime than models trained on fully sampled data. We open-source our code and the trained Ambient Diffusion MRI models: https://github.com/utcsilab/ambient-diffusion-mri .
AADNet: Attention aware Demoiréing Network
Mar 13, 2024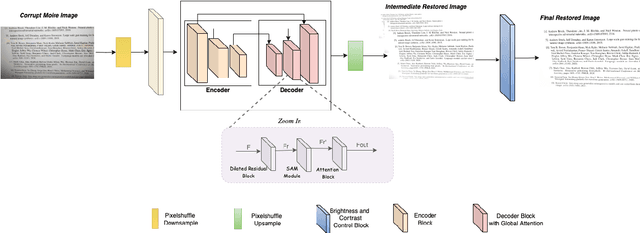
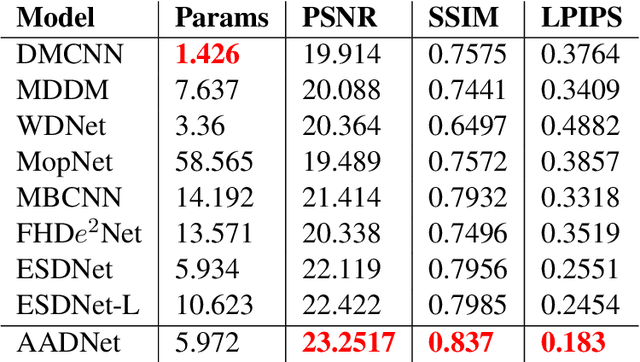

Moire pattern frequently appears in photographs captured with mobile devices and digital cameras, potentially degrading image quality. Despite recent advancements in computer vision, image demoire'ing remains a challenging task due to the dynamic textures and variations in colour, shape, and frequency of moire patterns. Most existing methods struggle to generalize to unseen datasets, limiting their effectiveness in removing moire patterns from real-world scenarios. In this paper, we propose a novel lightweight architecture, AADNet (Attention Aware Demoireing Network), for high-resolution image demoire'ing that effectively works across different frequency bands and generalizes well to unseen datasets. Extensive experiments conducted on the UHDM dataset validate the effectiveness of our approach, resulting in high-fidelity images.
3DFIRES: Few Image 3D REconstruction for Scenes with Hidden Surface
Mar 13, 2024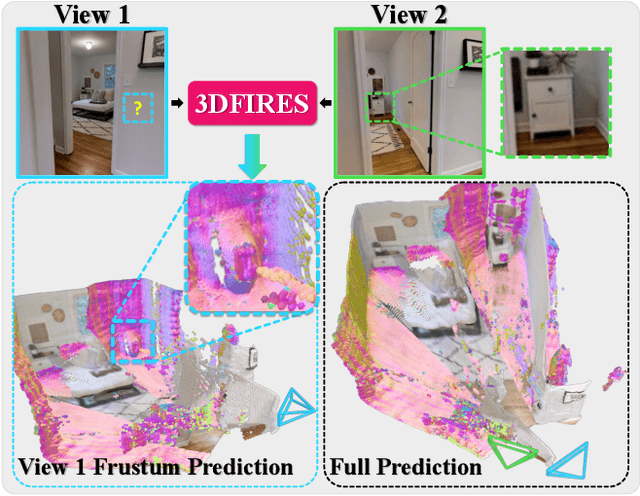

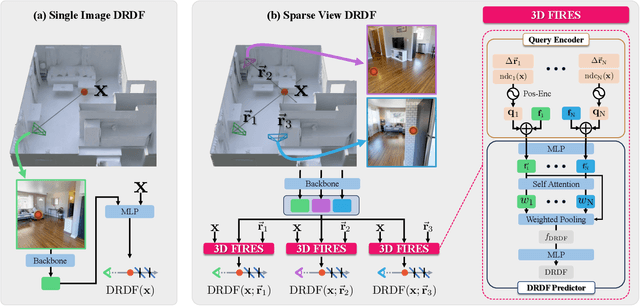
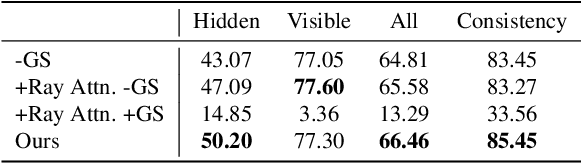
This paper introduces 3DFIRES, a novel system for scene-level 3D reconstruction from posed images. Designed to work with as few as one view, 3DFIRES reconstructs the complete geometry of unseen scenes, including hidden surfaces. With multiple view inputs, our method produces full reconstruction within all camera frustums. A key feature of our approach is the fusion of multi-view information at the feature level, enabling the production of coherent and comprehensive 3D reconstruction. We train our system on non-watertight scans from large-scale real scene dataset. We show it matches the efficacy of single-view reconstruction methods with only one input and surpasses existing techniques in both quantitative and qualitative measures for sparse-view 3D reconstruction.
Simulating Battery-Powered TinyML Systems Optimised using Reinforcement Learning in Image-Based Anomaly Detection
Mar 08, 2024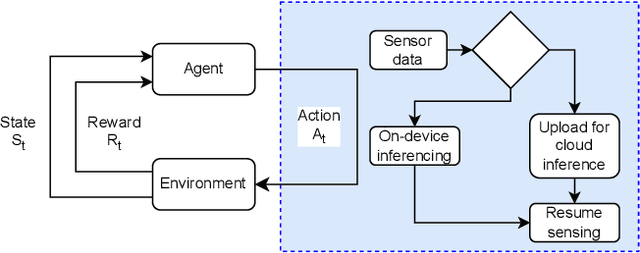
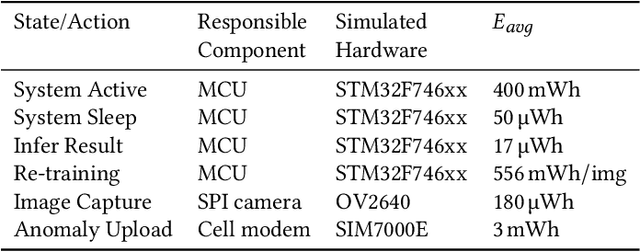
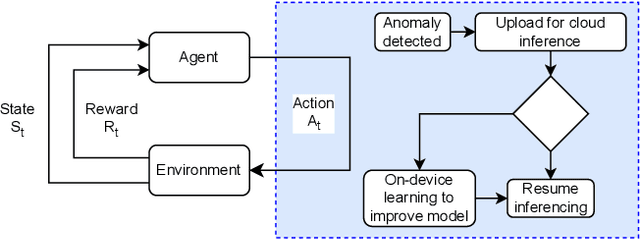
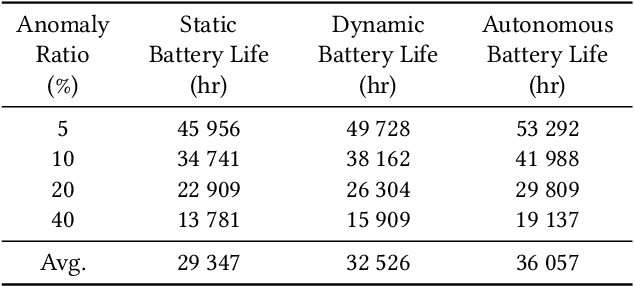
Advances in Tiny Machine Learning (TinyML) have bolstered the creation of smart industry solutions, including smart agriculture, healthcare and smart cities. Whilst related research contributes to enabling TinyML solutions on constrained hardware, there is a need to amplify real-world applications by optimising energy consumption in battery-powered systems. The work presented extends and contributes to TinyML research by optimising battery-powered image-based anomaly detection Internet of Things (IoT) systems. Whilst previous work in this area has yielded the capabilities of on-device inferencing and training, there has yet to be an investigation into optimising the management of such capabilities using machine learning approaches, such as Reinforcement Learning (RL), to improve the deployment battery life of such systems. Using modelled simulations, the battery life effects of an RL algorithm are benchmarked against static and dynamic optimisation approaches, with the foundation laid for a hardware benchmark to follow. It is shown that using RL within a TinyML-enabled IoT system to optimise the system operations, including cloud anomaly processing and on-device training, yields an improved battery life of 22.86% and 10.86% compared to static and dynamic optimisation approaches respectively. The proposed solution can be deployed to resource-constrained hardware, given its low memory footprint of 800 B, which could be further reduced. This further facilitates the real-world deployment of such systems, including key sectors such as smart agriculture.
Region-Adaptive Transform with Segmentation Prior for Image Compression
Mar 01, 2024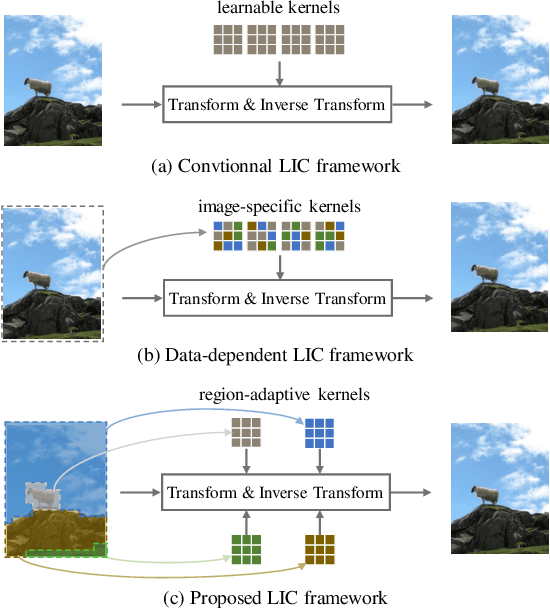
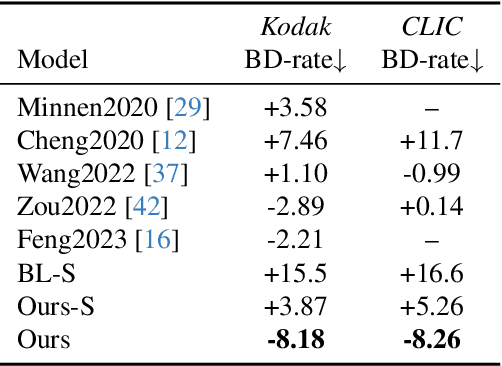
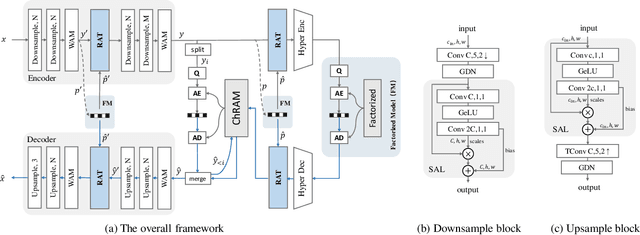
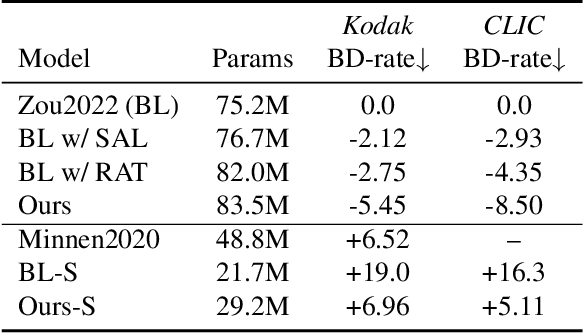
Learned Image Compression (LIC) has shown remarkable progress in recent years. Existing works commonly employ CNN-based or self-attention-based modules as transform methods for compression. However, there is no prior research on neural transform that focuses on specific regions. In response, we introduce the class-agnostic segmentation masks (i.e. semantic masks without category labels) for extracting region-adaptive contextual information. Our proposed module, Region-Adaptive Transform, applies adaptive convolutions on different regions guided by the masks. Additionally, we introduce a plug-and-play module named Scale Affine Layer to incorporate rich contexts from various regions. While there have been prior image compression efforts that involve segmentation masks as additional intermediate inputs, our approach differs significantly from them. Our advantages lie in that, to avoid extra bitrate overhead, we treat these masks as privilege information, which is accessible during the model training stage but not required during the inference phase. To the best of our knowledge, we are the first to employ class-agnostic masks as privilege information and achieve superior performance in pixel-fidelity metrics, such as Peak Signal to Noise Ratio (PSNR). The experimental results demonstrate our improvement compared to previously well-performing methods, with about 8.2% bitrate saving compared to VTM-17.0. The code will be released at https://github.com/GityuxiLiu/Region-Adaptive-Transform-with-Segmentation-Prior-for-Image-Compression.
MGIC: A Multi-Label Gradient Inversion Attack based on Canny Edge Detection on Federated Learning
Mar 13, 2024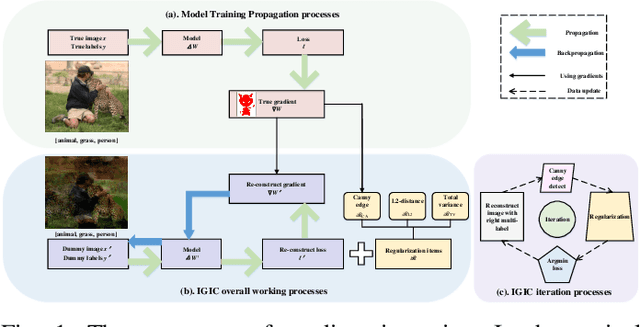
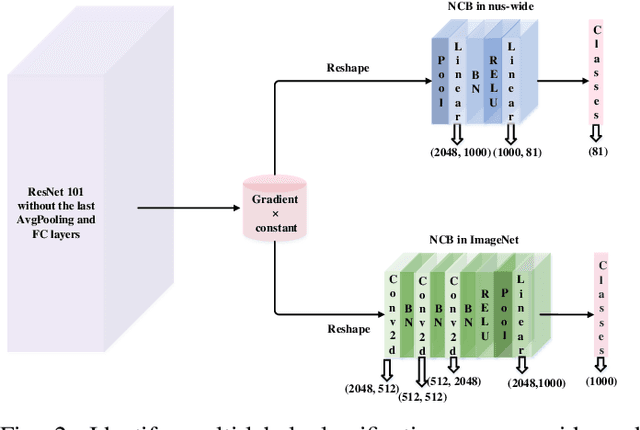


As a new distributed computing framework that can protect data privacy, federated learning (FL) has attracted more and more attention in recent years. It receives gradients from users to train the global model and releases the trained global model to working users. Nonetheless, the gradient inversion (GI) attack reflects the risk of privacy leakage in federated learning. Attackers only need to use gradients through hundreds of thousands of simple iterations to obtain relatively accurate private data stored on users' local devices. For this, some works propose simple but effective strategies to obtain user data under a single-label dataset. However, these strategies induce a satisfactory visual effect of the inversion image at the expense of higher time costs. Due to the semantic limitation of a single label, the image obtained by gradient inversion may have semantic errors. We present a novel gradient inversion strategy based on canny edge detection (MGIC) in both the multi-label and single-label datasets. To reduce semantic errors caused by a single label, we add new convolution layers' blocks in the trained model to obtain the image's multi-label. Through multi-label representation, serious semantic errors in inversion images are reduced. Then, we analyze the impact of parameters on the difficulty of input image reconstruction and discuss how image multi-subjects affect the inversion performance. Our proposed strategy has better visual inversion image results than the most widely used ones, saving more than 78% of time costs in the ImageNet dataset.
Rule-driven News Captioning
Mar 14, 2024
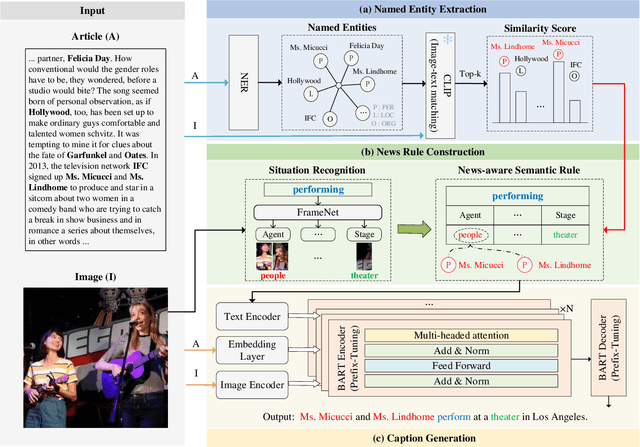
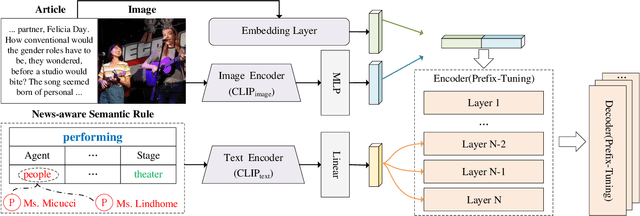
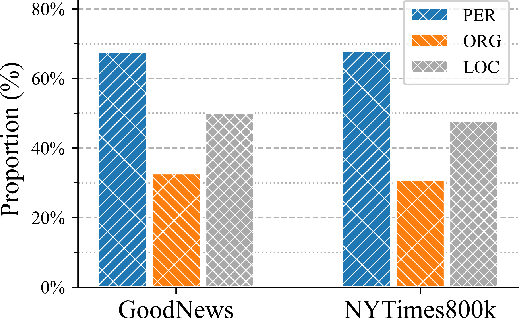
News captioning task aims to generate sentences by describing named entities or concrete events for an image with its news article. Existing methods have achieved remarkable results by relying on the large-scale pre-trained models, which primarily focus on the correlations between the input news content and the output predictions. However, the news captioning requires adhering to some fundamental rules of news reporting, such as accurately describing the individuals and actions associated with the event. In this paper, we propose the rule-driven news captioning method, which can generate image descriptions following designated rule signal. Specifically, we first design the news-aware semantic rule for the descriptions. This rule incorporates the primary action depicted in the image (e.g., "performing") and the roles played by named entities involved in the action (e.g., "Agent" and "Place"). Second, we inject this semantic rule into the large-scale pre-trained model, BART, with the prefix-tuning strategy, where multiple encoder layers are embedded with news-aware semantic rule. Finally, we can effectively guide BART to generate news sentences that comply with the designated rule. Extensive experiments on two widely used datasets (i.e., GoodNews and NYTimes800k) demonstrate the effectiveness of our method.
Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
Mar 14, 2024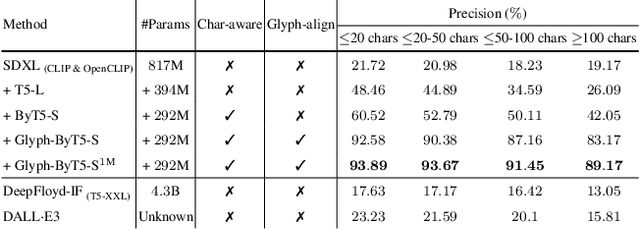

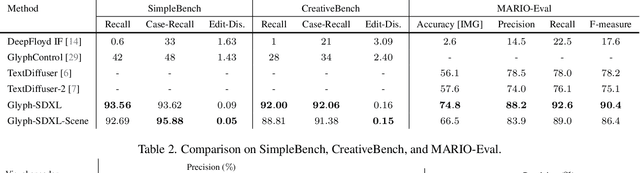

Visual text rendering poses a fundamental challenge for contemporary text-to-image generation models, with the core problem lying in text encoder deficiencies. To achieve accurate text rendering, we identify two crucial requirements for text encoders: character awareness and alignment with glyphs. Our solution involves crafting a series of customized text encoder, Glyph-ByT5, by fine-tuning the character-aware ByT5 encoder using a meticulously curated paired glyph-text dataset. We present an effective method for integrating Glyph-ByT5 with SDXL, resulting in the creation of the Glyph-SDXL model for design image generation. This significantly enhances text rendering accuracy, improving it from less than $20\%$ to nearly $90\%$ on our design image benchmark. Noteworthy is Glyph-SDXL's newfound ability for text paragraph rendering, achieving high spelling accuracy for tens to hundreds of characters with automated multi-line layouts. Finally, through fine-tuning Glyph-SDXL with a small set of high-quality, photorealistic images featuring visual text, we showcase a substantial improvement in scene text rendering capabilities in open-domain real images. These compelling outcomes aim to encourage further exploration in designing customized text encoders for diverse and challenging tasks.
Motion and temporal B0 shift corrections for quantitative susceptibility mapping (QSM) and R2* mapping using dual-echo spiral navigators and conjugate-phase reconstruction
Mar 18, 2024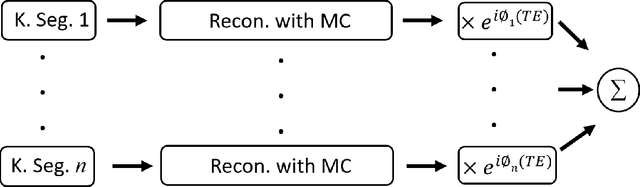
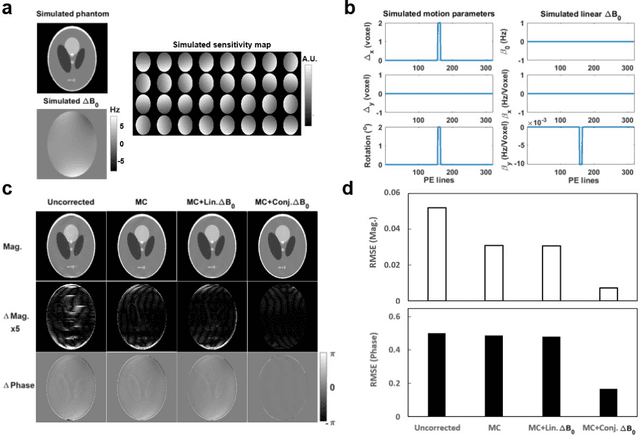
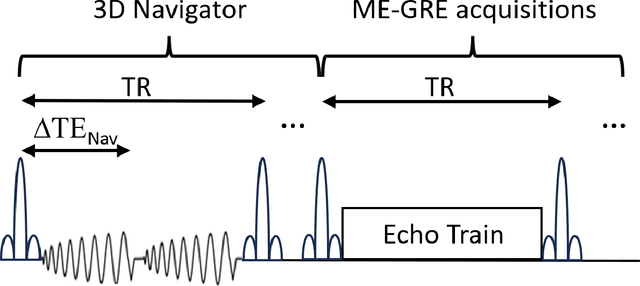
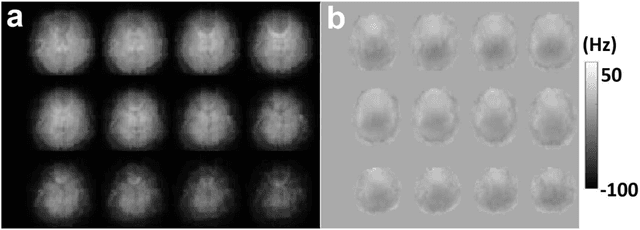
Purpose: To develop an efficient navigator-based motion and temporal B0 shift correction technique for 3D multi-echo gradient-echo (ME-GRE) MRI for quantitative susceptibility mapping (QSM) and R2* mapping. Theory and Methods: A dual-echo 3D spiral navigator was designed to interleave with the Cartesian ME-GRE acquisitions, allowing the acquisition of both low- and high-echo time signals. We additionally designed a novel conjugate-phase based reconstruction method for the joint correction of motion and temporal B0 shifts. We performed both numerical simulation and in vivo human scans to assess the performance of the methods. Results: Numerical simulation and human brain scans demonstrated that the proposed technique successfully corrected artifacts induced by both head motions and temporal B0 changes. Efficient B0-change correction with conjugate-phase reconstruction can be performed on less than 10 clustered k-space segments. In vivo scans showed that combining temporal B0 correction with motion correction further reduced artifacts and improved image quality in both R2* and QSM images. Conclusion: Our proposed approach of using 3D spiral navigators and a novel conjugate-phase reconstruction method can improve susceptibility-related measurements using MR.