 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GestureDiffuCLIP: Gesture Diffusion Model with CLIP Latents
Mar 26, 2023
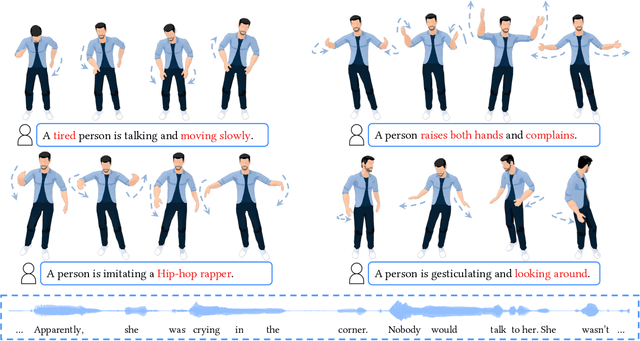
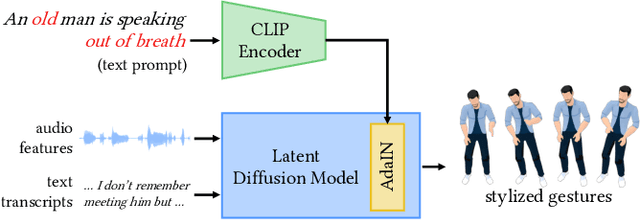


The automatic generation of stylized co-speech gestures has recently received increasing attention. Previous systems typically allow style control via predefined text labels or example motion clips, which are often not flexible enough to convey user intent accurately. In this work, we present GestureDiffuCLIP, a neural network framework for synthesizing realistic, stylized co-speech gestures with flexible style control. We leverage the power of the large-scale Contrastive-Language-Image-Pre-training (CLIP) model and present a novel CLIP-guided mechanism that extracts efficient style representations from multiple input modalities, such as a piece of text, an example motion clip, or a video. Our system learns a latent diffusion model to generate high-quality gestures and infuses the CLIP representations of style into the generator via an adaptive instance normalization (AdaIN) layer. We further devise a gesture-transcript alignment mechanism that ensures a semantically correct gesture generation based on contrastive learning. Our system can also be extended to allow fine-grained style control of individual body parts. We demonstrate an extensive set of examples showing the flexibility and generalizability of our model to a variety of style descriptions. In a user study, we show that our system outperforms the state-of-the-art approaches regarding human likeness, appropriateness, and style correctness.
Image-Based Fire Detection in Industrial Environments with YOLOv4
Dec 09, 2022
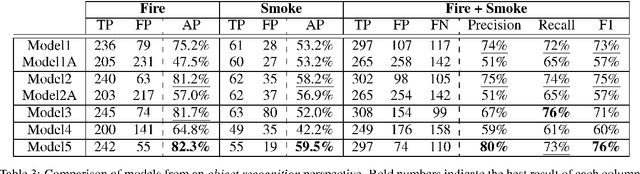

Fires have destructive power when they break out and affect their surroundings on a devastatingly large scale. The best way to minimize their damage is to detect the fire as quickly as possible before it has a chance to grow. Accordingly, this work looks into the potential of AI to detect and recognize fires and reduce detection time using object detection on an image stream. Object detection has made giant leaps in speed and accuracy over the last six years, making real-time detection feasible. To our end, we collected and labeled appropriate data from several public sources, which have been used to train and evaluate several models based on the popular YOLOv4 object detector. Our focus, driven by a collaborating industrial partner, is to implement our system in an industrial warehouse setting, which is characterized by high ceilings. A drawback of traditional smoke detectors in this setup is that the smoke has to rise to a sufficient height. The AI models brought forward in this research managed to outperform these detectors by a significant amount of time, providing precious anticipation that could help to minimize the effects of fires further.
TFS-ViT: Token-Level Feature Stylization for Domain Generalization
Mar 29, 2023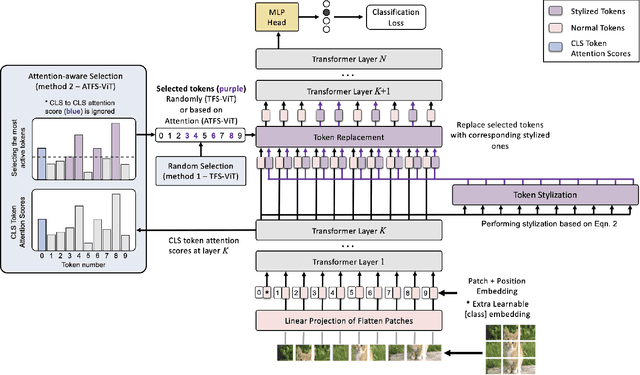
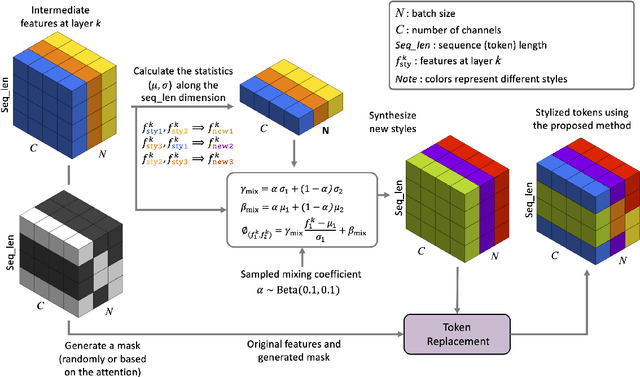
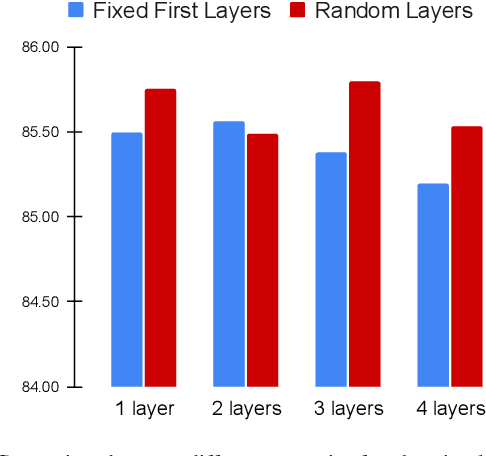
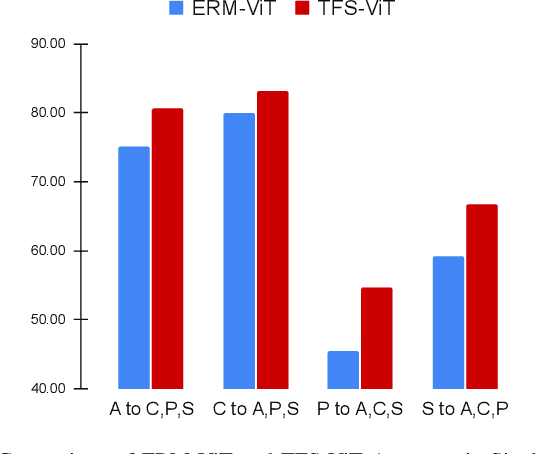
Standard deep learning models such as convolutional neural networks (CNNs) lack the ability of generalizing to domains which have not been seen during training. This problem is mainly due to the common but often wrong assumption of such models that the source and target data come from the same i.i.d. distribution. Recently, Vision Transformers (ViTs) have shown outstanding performance for a broad range of computer vision tasks. However, very few studies have investigated their ability to generalize to new domains. This paper presents a first Token-level Feature Stylization (TFS-ViT) approach for domain generalization, which improves the performance of ViTs to unseen data by synthesizing new domains. Our approach transforms token features by mixing the normalization statistics of images from different domains. We further improve this approach with a novel strategy for attention-aware stylization, which uses the attention maps of class (CLS) tokens to compute and mix normalization statistics of tokens corresponding to different image regions. The proposed method is flexible to the choice of backbone model and can be easily applied to any ViT-based architecture with a negligible increase in computational complexity. Comprehensive experiments show that our approach is able to achieve state-of-the-art performance on five challenging benchmarks for domain generalization, and demonstrate its ability to deal with different types of domain shifts. The implementation is available at: https://github.com/Mehrdad-Noori/TFS-ViT_Token-level_Feature_Stylization.
Structure-aware registration network for liver DCE-CT images
Mar 08, 2023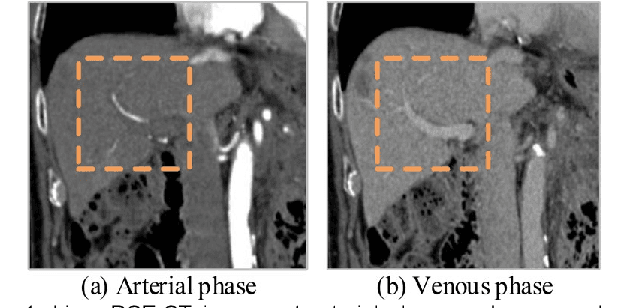
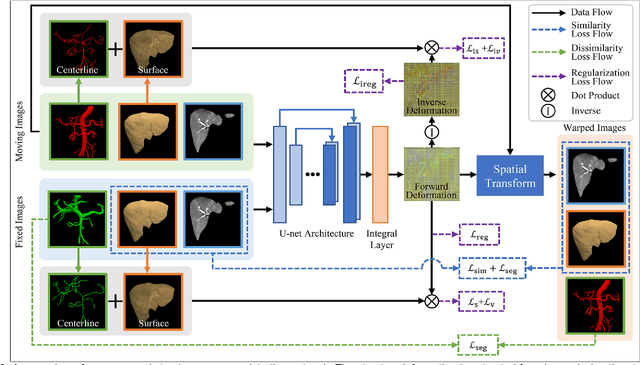
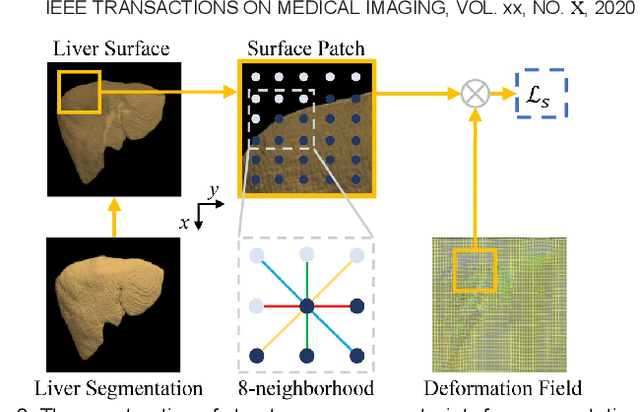
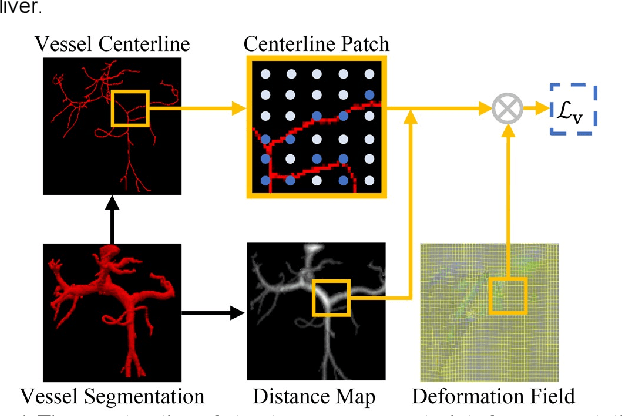
Image registration of liver dynamic contrast-enhanced computed tomography (DCE-CT) is crucial for diagnosis and image-guided surgical planning of liver cancer. However, intensity variations due to the flow of contrast agents combined with complex spatial motion induced by respiration brings great challenge to existing intensity-based registration methods. To address these problems, we propose a novel structure-aware registration method by incorporating structural information of related organs with segmentation-guided deep registration network. Existing segmentation-guided registration methods only focus on volumetric registration inside the paired organ segmentations, ignoring the inherent attributes of their anatomical structures. In addition, such paired organ segmentations are not always available in DCE-CT images due to the flow of contrast agents. Different from existing segmentation-guided registration methods, our proposed method extracts structural information in hierarchical geometric perspectives of line and surface. Then, according to the extracted structural information, structure-aware constraints are constructed and imposed on the forward and backward deformation field simultaneously. In this way, all available organ segmentations, including unpaired ones, can be fully utilized to avoid the side effect of contrast agent and preserve the topology of organs during registration. Extensive experiments on an in-house liver DCE-CT dataset and a public LiTS dataset show that our proposed method can achieve higher registration accuracy and preserve anatomical structure more effectively than state-of-the-art methods.
Inverse Image Frequency for Long-tailed Image Recognition
Sep 11, 2022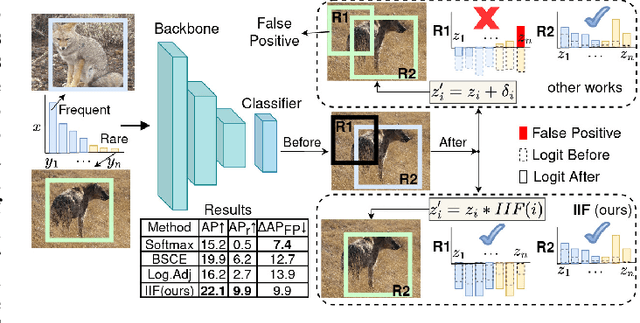
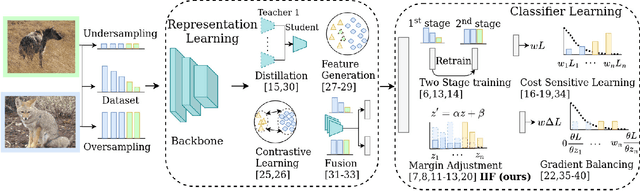
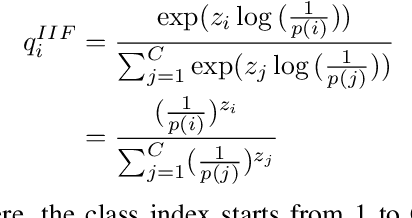
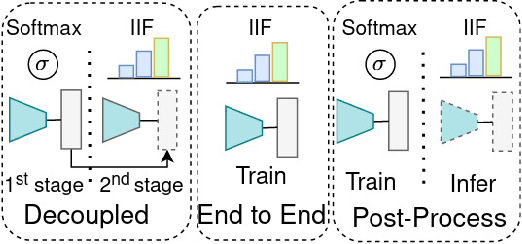
The long-tailed distribution is a common phenomenon in the real world. Extracted large scale image datasets inevitably demonstrate the long-tailed property and models trained with imbalanced data can obtain high performance for the over-represented categories, but struggle for the under-represented categories, leading to biased predictions and performance degradation. To address this challenge, we propose a novel de-biasing method named Inverse Image Frequency (IIF). IIF is a multiplicative margin adjustment transformation of the logits in the classification layer of a convolutional neural network. Our method achieves stronger performance than similar works and it is especially useful for downstream tasks such as long-tailed instance segmentation as it produces fewer false positive detections. Our extensive experiments show that IIF surpasses the state of the art on many long-tailed benchmarks such as ImageNet-LT, CIFAR-LT, Places-LT and LVIS, reaching 55.8% top-1 accuracy with ResNet50 on ImageNet-LT and 26.2% segmentation AP with MaskRCNN on LVIS. Code available at https://github.com/kostas1515/iif
Implicit Warping for Animation with Image Sets
Oct 04, 2022
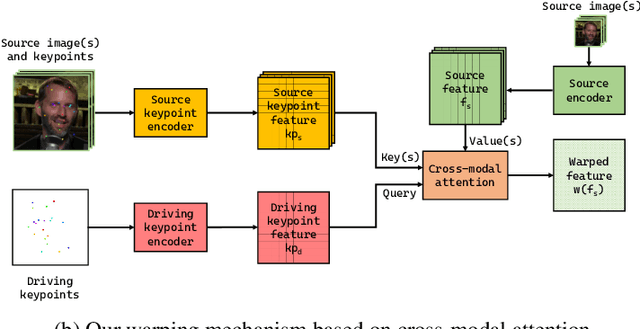
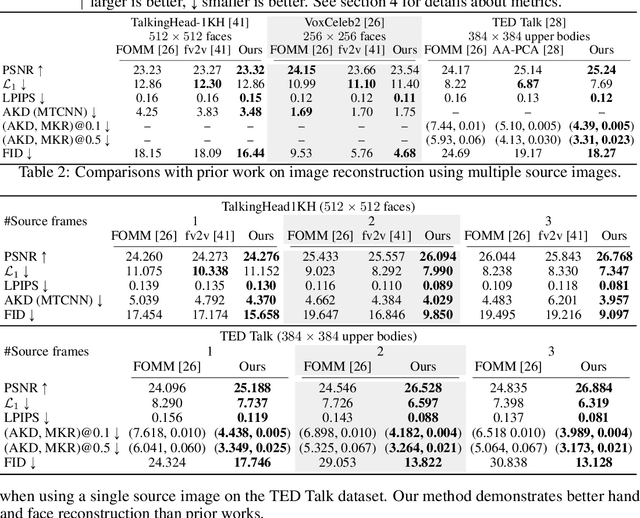
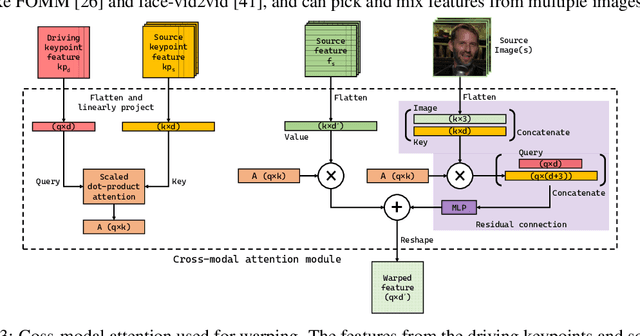
We present a new implicit warping framework for image animation using sets of source images through the transfer of the motion of a driving video. A single cross- modal attention layer is used to find correspondences between the source images and the driving image, choose the most appropriate features from different source images, and warp the selected features. This is in contrast to the existing methods that use explicit flow-based warping, which is designed for animation using a single source and does not extend well to multiple sources. The pick-and-choose capability of our framework helps it achieve state-of-the-art results on multiple datasets for image animation using both single and multiple source images. The project website is available at https://deepimagination.cc/implicit warping/
Spatio-Temporal AU Relational Graph Representation Learning For Facial Action Units Detection
Mar 19, 2023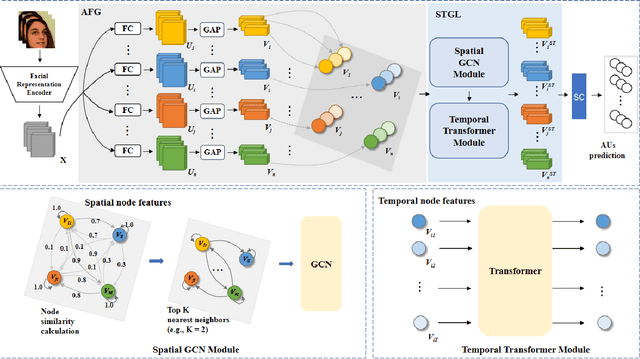

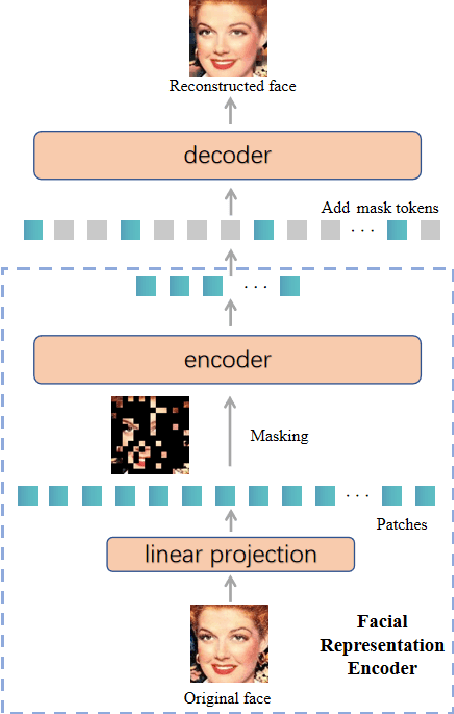

This paper presents our Facial Action Units (AUs) recognition submission to the fifth Affective Behavior Analysis in-the-wild Competition (ABAW). Our approach consists of three main modules: (i) a pre-trained facial representation encoder which produce a strong facial representation from each input face image in the input sequence; (ii) an AU-specific feature generator that specifically learns a set of AU features from each facial representation; and (iii) a spatio-temporal graph learning module that constructs a spatio-temporal graph representation. This graph representation describes AUs contained in all frames and predicts the occurrence of each AU based on both the modeled spatial information within the corresponding face and the learned temporal dynamics among frames. The experimental results show that our approach outperformed the baseline and the spatio-temporal graph representation learning allows the model to generate the best results among all ablation systems.
Universal Adversarial Perturbations: Efficiency on a small image dataset
Oct 10, 2022


Although neural networks perform very well on the image classification task, they are still vulnerable to adversarial perturbations that can fool a neural network without visibly changing an input image. A paper has shown the existence of Universal Adversarial Perturbations which when added to any image will fool the neural network with a very high probability. In this paper we will try to reproduce the experience of the Universal Adversarial Perturbations paper, but on a smaller neural network architecture and training set, in order to be able to study the efficiency of the computed perturbation.
The Cascaded Forward Algorithm for Neural Network Training
Mar 24, 2023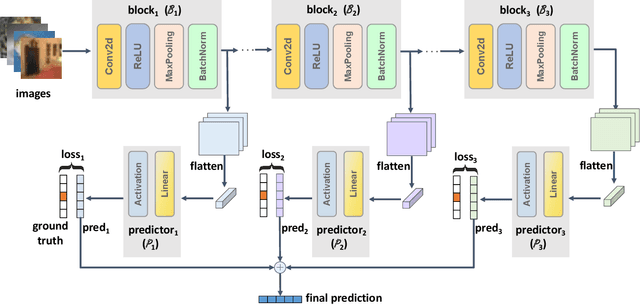
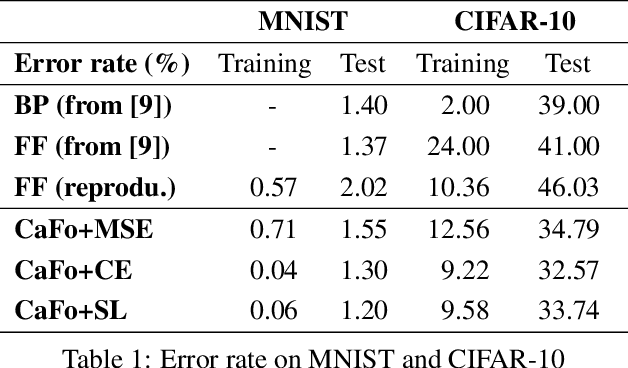
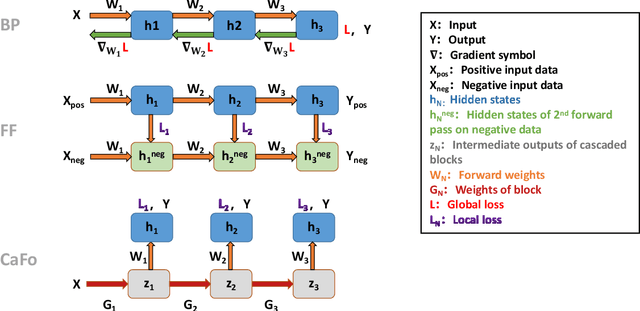
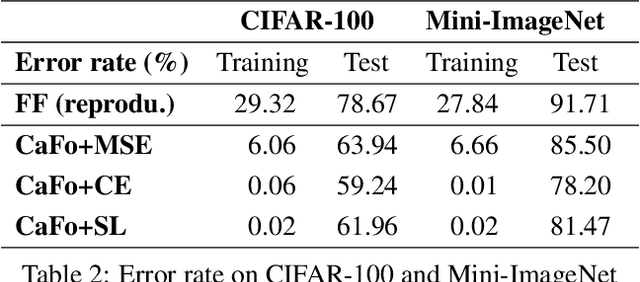
Backpropagation algorithm has been widely used as a mainstream learning procedure for neural networks in the past decade, and has played a significant role in the development of deep learning. However, there exist some limitations associated with this algorithm, such as getting stuck in local minima and experiencing vanishing/exploding gradients, which have led to questions about its biological plausibility. To address these limitations, alternative algorithms to backpropagation have been preliminarily explored, with the Forward-Forward (FF) algorithm being one of the most well-known. In this paper we propose a new learning framework for neural networks, namely Cascaded Forward (CaFo) algorithm, which does not rely on BP optimization as that in FF. Unlike FF, our framework directly outputs label distributions at each cascaded block, which does not require generation of additional negative samples and thus leads to a more efficient process at both training and testing. Moreover, in our framework each block can be trained independently, so it can be easily deployed into parallel acceleration systems. The proposed method is evaluated on four public image classification benchmarks, and the experimental results illustrate significant improvement in prediction accuracy in comparison with the baseline.
Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
Mar 24, 2023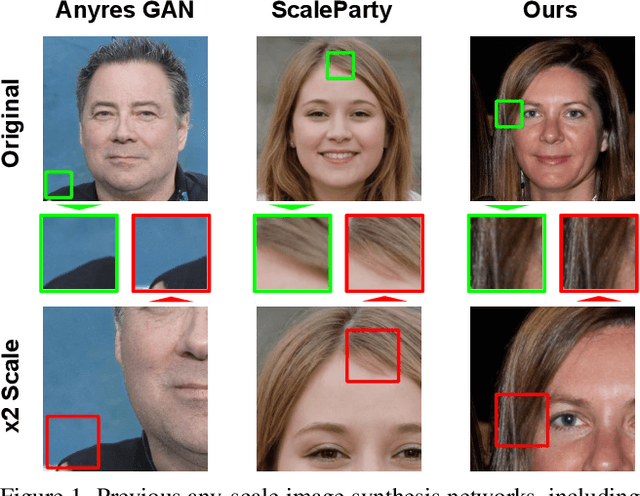
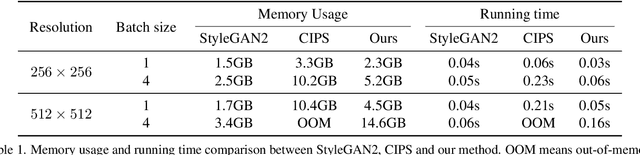
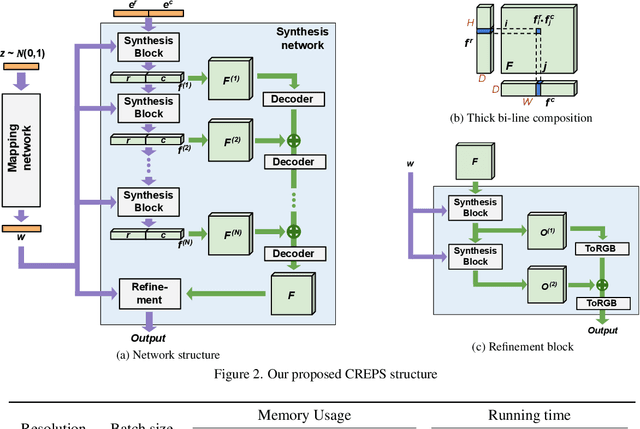

Any-scale image synthesis offers an efficient and scalable solution to synthesize photo-realistic images at any scale, even going beyond 2K resolution. However, existing GAN-based solutions depend excessively on convolutions and a hierarchical architecture, which introduce inconsistency and the $``$texture sticking$"$ issue when scaling the output resolution. From another perspective, INR-based generators are scale-equivariant by design, but their huge memory footprint and slow inference hinder these networks from being adopted in large-scale or real-time systems. In this work, we propose $\textbf{C}$olumn-$\textbf{R}$ow $\textbf{E}$ntangled $\textbf{P}$ixel $\textbf{S}$ynthesis ($\textbf{CREPS}$), a new generative model that is both efficient and scale-equivariant without using any spatial convolutions or coarse-to-fine design. To save memory footprint and make the system scalable, we employ a novel bi-line representation that decomposes layer-wise feature maps into separate $``$thick$"$ column and row encodings. Experiments on various datasets, including FFHQ, LSUN-Church, MetFaces, and Flickr-Scenery, confirm CREPS' ability to synthesize scale-consistent and alias-free images at any arbitrary resolution with proper training and inference speed. Code is available at https://github.com/VinAIResearch/CREPS.