 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NEF: Neural Edge Fields for 3D Parametric Curve Reconstruction from Multi-view Images
Mar 16, 2023
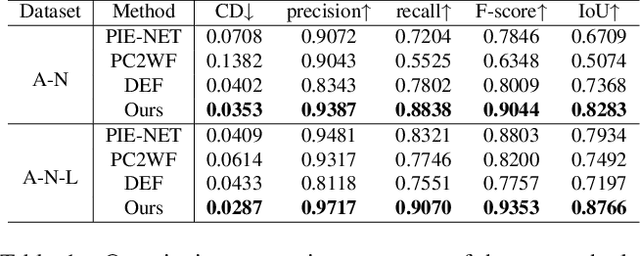
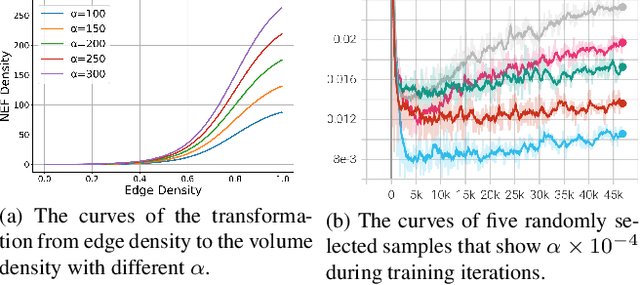
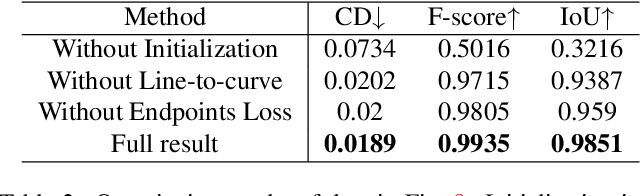
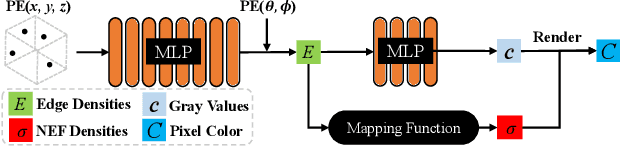
We study the problem of reconstructing 3D feature curves of an object from a set of calibrated multi-view images. To do so, we learn a neural implicit field representing the density distribution of 3D edges which we refer to as Neural Edge Field (NEF). Inspired by NeRF, NEF is optimized with a view-based rendering loss where a 2D edge map is rendered at a given view and is compared to the ground-truth edge map extracted from the image of that view. The rendering-based differentiable optimization of NEF fully exploits 2D edge detection, without needing a supervision of 3D edges, a 3D geometric operator or cross-view edge correspondence. Several technical designs are devised to ensure learning a range-limited and view-independent NEF for robust edge extraction. The final parametric 3D curves are extracted from NEF with an iterative optimization method. On our benchmark with synthetic data, we demonstrate that NEF outperforms existing state-of-the-art methods on all metrics. Project page: https://yunfan1202.github.io/NEF/.
Erasing Concepts from Diffusion Models
Mar 16, 2023
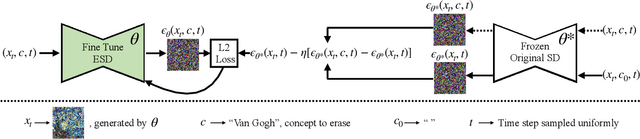
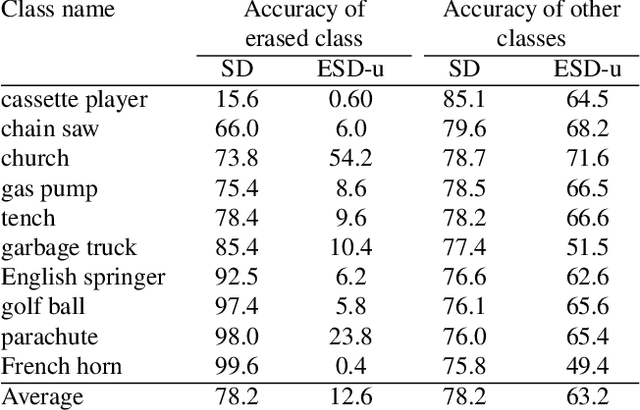

Motivated by recent advancements in text-to-image diffusion, we study erasure of specific concepts from the model's weights. While Stable Diffusion has shown promise in producing explicit or realistic artwork, it has raised concerns regarding its potential for misuse. We propose a fine-tuning method that can erase a visual concept from a pre-trained diffusion model, given only the name of the style and using negative guidance as a teacher. We benchmark our method against previous approaches that remove sexually explicit content and demonstrate its effectiveness, performing on par with Safe Latent Diffusion and censored training. To evaluate artistic style removal, we conduct experiments erasing five modern artists from the network and conduct a user study to assess the human perception of the removed styles. Unlike previous methods, our approach can remove concepts from a diffusion model permanently rather than modifying the output at the inference time, so it cannot be circumvented even if a user has access to model weights. Our code, data, and results are available at https://erasing.baulab.info/
Stereo Event-based Visual-Inertial Odometry
Mar 16, 2023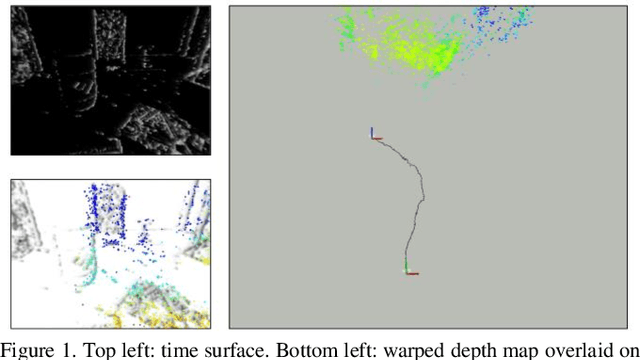
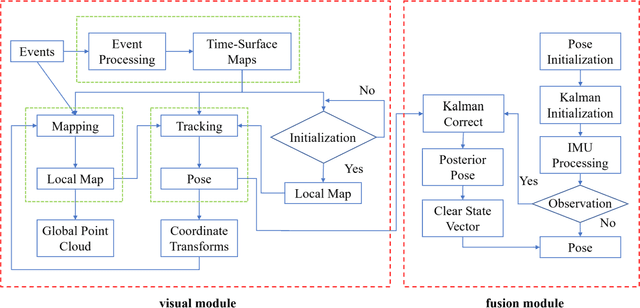
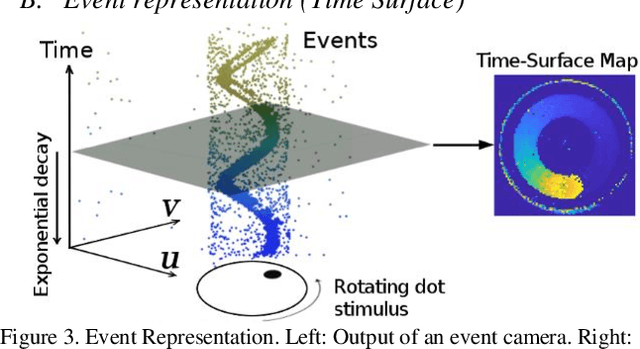
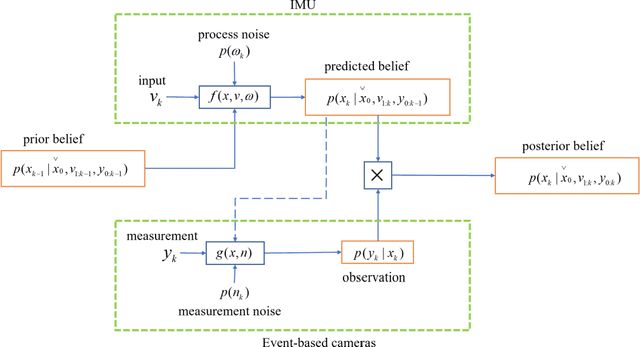
Event-based cameras are new type vision sensors whose pixels work independently and respond asynchronously to brightness change with microsecond resolution, instead of provide stand-ard intensity frames. Compared with traditional cameras, event-based cameras have low latency, no motion blur, and high dynamic range (HDR), which provide possibilities for robots to deal with some challenging scenes. We propose a visual-inertial odometry method for stereo event-cameras based on Kalman filtering. The visual module updates the camera pose relies on the edge alignment of a semi-dense 3D map to a 2D image, and the IMU module updates pose by midpoint method. We evaluate our method on public datasets in natural scenes with general 6-DoF motion and compare the results against ground truth. We show that the proposed pipeline provides improved accuracy over the result of a state-of-the-art visual odometry method for stereo event-cameras, while running in real-time on a standard CPU. To the best of our knowledge, this is the first published visual-inertial odometry algorithm for stereo event-cameras.
Automatic Geo-alignment of Artwork in Children's Story Books
Mar 16, 2023A study was conducted to prove AI software could be used to translate and generate illustrations without any human intervention. This was done with the purpose of showing and distributing it to the external customer, Pratham Books. The project aligns with the company's vision by leveraging the generalisation and scalability of Machine Learning algorithms, offering significant cost efficiency increases to a wide range of literary audiences in varied geographical locations. A comparative study methodology was utilised to determine the best performant method out of the 3 devised, Prompt Augmentation using Keywords, CLIP Embedding Mask, and Cross Attention Control with Editorial Prompts. A thorough evaluation process was completed using both quantitative and qualitative measures. Each method had its own strengths and weaknesses, but through the evaluation, method 1 was found to have the best yielding results. Promising future advancements may be made to further increase image quality by incorporating Large Language Models and personalised stylistic models. The presented approach can also be adapted to Video and 3D sculpture generation for novel illustrations in digital webbooks.
Your time series is worth a binary image: machine vision assisted deep framework for time series forecasting
Feb 28, 2023
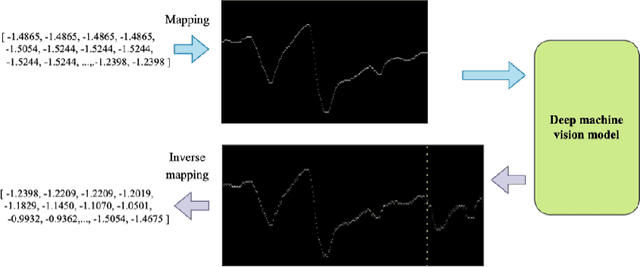

Time series forecasting (TSF) has been a challenging research area, and various models have been developed to address this task. However, almost all these models are trained with numerical time series data, which is not as effectively processed by the neural system as visual information. To address this challenge, this paper proposes a novel machine vision assisted deep time series analysis (MV-DTSA) framework. The MV-DTSA framework operates by analyzing time series data in a novel binary machine vision time series metric space, which includes a mapping and an inverse mapping function from the numerical time series space to the binary machine vision space, and a deep machine vision model designed to address the TSF task in the binary space. A comprehensive computational analysis demonstrates that the proposed MV-DTSA framework outperforms state-of-the-art deep TSF models, without requiring sophisticated data decomposition or model customization. The code for our framework is accessible at https://github.com/IkeYang/ machine-vision-assisted-deep-time-series-analysis-MV-DTSA-.
Text-Only Training for Image Captioning using Noise-Injected CLIP
Nov 01, 2022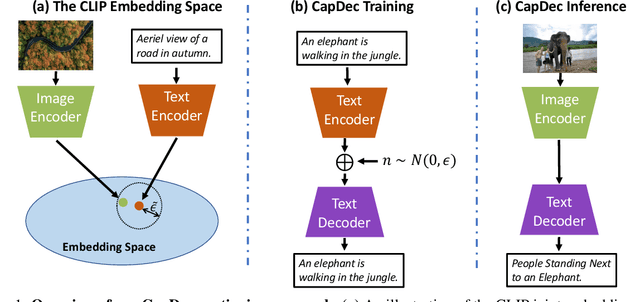
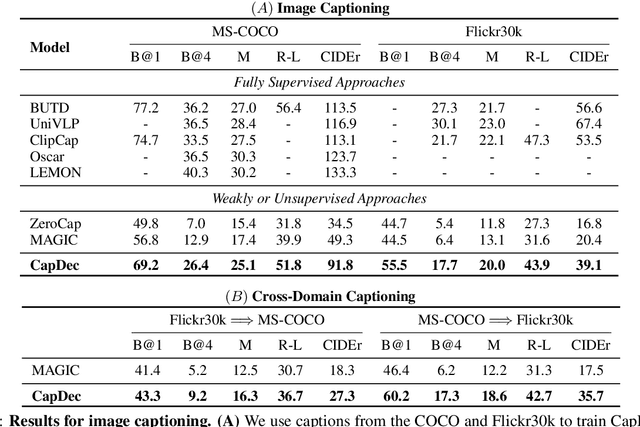
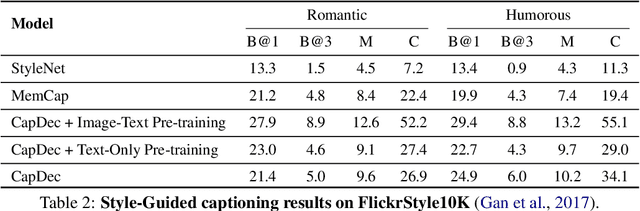

We consider the task of image-captioning using only the CLIP model and additional text data at training time, and no additional captioned images. Our approach relies on the fact that CLIP is trained to make visual and textual embeddings similar. Therefore, we only need to learn how to translate CLIP textual embeddings back into text, and we can learn how to do this by learning a decoder for the frozen CLIP text encoder using only text. We argue that this intuition is "almost correct" because of a gap between the embedding spaces, and propose to rectify this via noise injection during training. We demonstrate the effectiveness of our approach by showing SOTA zero-shot image captioning across four benchmarks, including style transfer. Code, data, and models are available on GitHub.
DistractFlow: Improving Optical Flow Estimation via Realistic Distractions and Pseudo-Labeling
Mar 24, 2023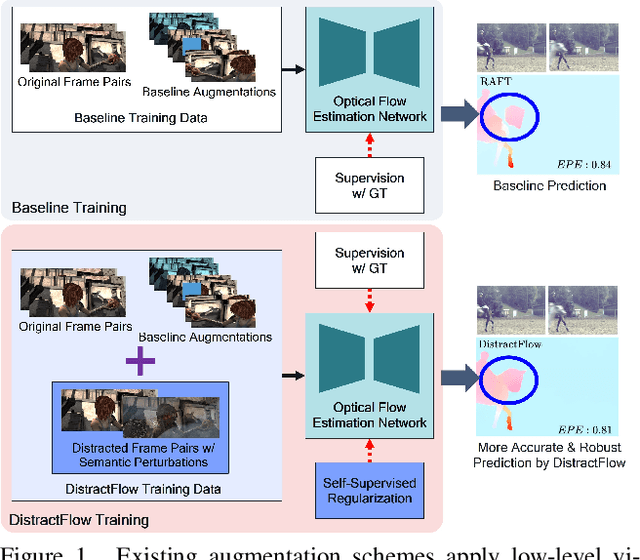
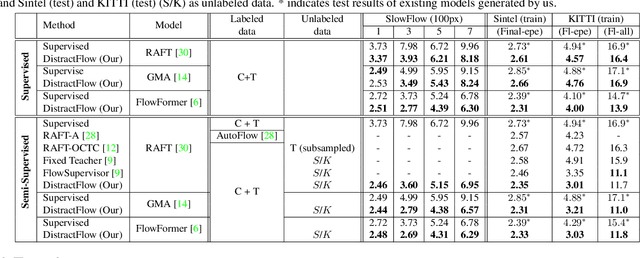
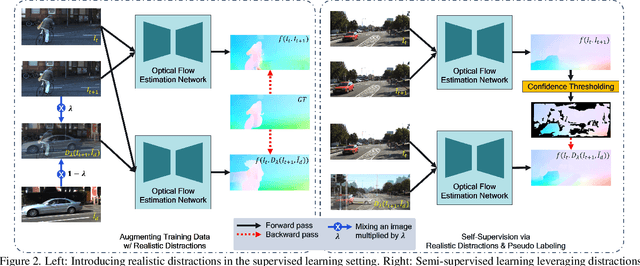
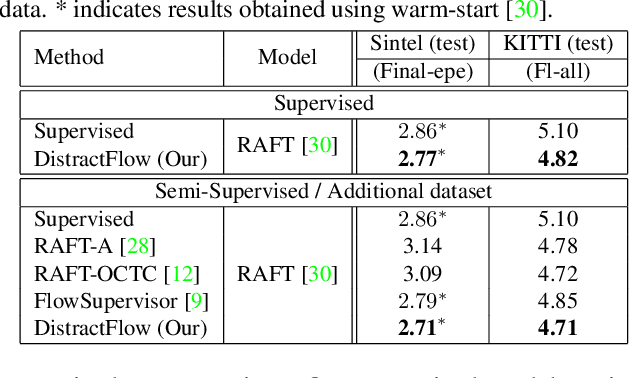
We propose a novel data augmentation approach, DistractFlow, for training optical flow estimation models by introducing realistic distractions to the input frames. Based on a mixing ratio, we combine one of the frames in the pair with a distractor image depicting a similar domain, which allows for inducing visual perturbations congruent with natural objects and scenes. We refer to such pairs as distracted pairs. Our intuition is that using semantically meaningful distractors enables the model to learn related variations and attain robustness against challenging deviations, compared to conventional augmentation schemes focusing only on low-level aspects and modifications. More specifically, in addition to the supervised loss computed between the estimated flow for the original pair and its ground-truth flow, we include a second supervised loss defined between the distracted pair's flow and the original pair's ground-truth flow, weighted with the same mixing ratio. Furthermore, when unlabeled data is available, we extend our augmentation approach to self-supervised settings through pseudo-labeling and cross-consistency regularization. Given an original pair and its distracted version, we enforce the estimated flow on the distracted pair to agree with the flow of the original pair. Our approach allows increasing the number of available training pairs significantly without requiring additional annotations. It is agnostic to the model architecture and can be applied to training any optical flow estimation models. Our extensive evaluations on multiple benchmarks, including Sintel, KITTI, and SlowFlow, show that DistractFlow improves existing models consistently, outperforming the latest state of the art.
4D iRIOM: 4D Imaging Radar Inertial Odometry and Mapping
Mar 24, 2023
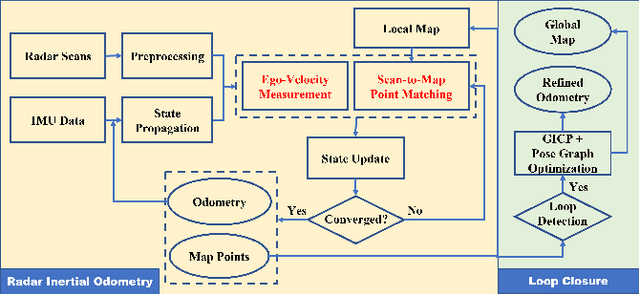

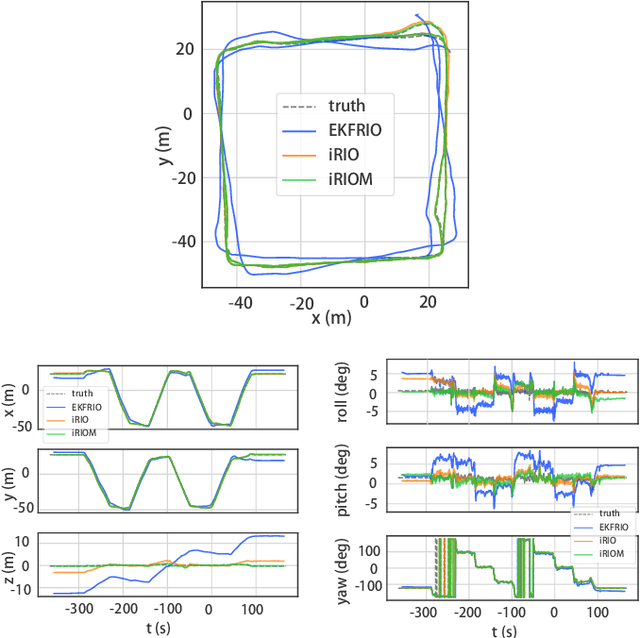
Millimeter wave radar can measure distances, directions, and Doppler velocity for objects in harsh conditions such as fog. The 4D imaging radar with both vertical and horizontal data resembling an image can also measure objects' height. Previous studies have used 3D radars for ego-motion estimation. But few methods leveraged the rich data of imaging radars, and they usually omitted the mapping aspect which is affected by the radar multipath returns, thus leading to inferior odometry accuracy. This paper presents a real-time imaging radar inertial odometry and mapping method, iRIOM, based on the submap concept. To fend off moving objects and multipath reflections, the iteratively reweighted least squares method is used for getting the ego-velocity from a single scan. To measure the agreement between sparse non-repetitive radar scan points and submap points, the distribution-to-multi-distribution distance for matches is adopted. The ego-velocity, scan-to-submap matches are fused with the 6D inertial data by an iterative extended Kalman filter to get the platform's 3D position and orientation. A loop closure module is also developed to curb the odometry module's drift. To our knowledge, iRIOM based on the two modules is the first 4D radar inertial SLAM system. On our and third-party data, we show iRIOM's favorable odometry accuracy and mapping consistency against the FastLIO-SLAM and the EKFRIO. Also, the ablation study reveal the benefit of inertial data versus the constant velocity model, the scan-to-submap matching versus the scan-to-scans matching, and loop closure.
GP-VTON: Towards General Purpose Virtual Try-on via Collaborative Local-Flow Global-Parsing Learning
Mar 24, 2023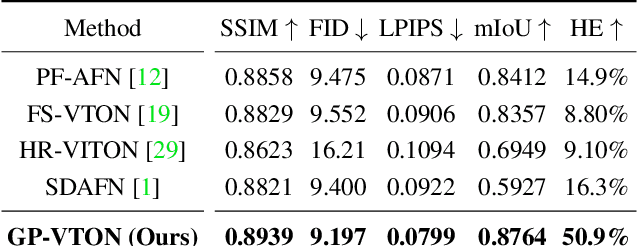
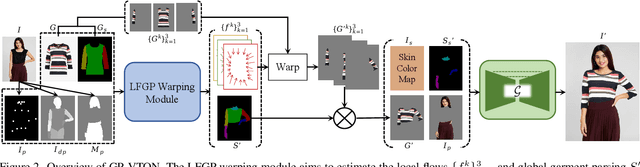

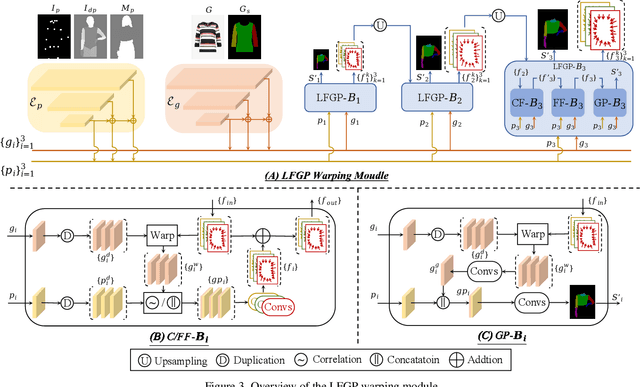
Image-based Virtual Try-ON aims to transfer an in-shop garment onto a specific person. Existing methods employ a global warping module to model the anisotropic deformation for different garment parts, which fails to preserve the semantic information of different parts when receiving challenging inputs (e.g, intricate human poses, difficult garments). Moreover, most of them directly warp the input garment to align with the boundary of the preserved region, which usually requires texture squeezing to meet the boundary shape constraint and thus leads to texture distortion. The above inferior performance hinders existing methods from real-world applications. To address these problems and take a step towards real-world virtual try-on, we propose a General-Purpose Virtual Try-ON framework, named GP-VTON, by developing an innovative Local-Flow Global-Parsing (LFGP) warping module and a Dynamic Gradient Truncation (DGT) training strategy. Specifically, compared with the previous global warping mechanism, LFGP employs local flows to warp garments parts individually, and assembles the local warped results via the global garment parsing, resulting in reasonable warped parts and a semantic-correct intact garment even with challenging inputs.On the other hand, our DGT training strategy dynamically truncates the gradient in the overlap area and the warped garment is no more required to meet the boundary constraint, which effectively avoids the texture squeezing problem. Furthermore, our GP-VTON can be easily extended to multi-category scenario and jointly trained by using data from different garment categories. Extensive experiments on two high-resolution benchmarks demonstrate our superiority over the existing state-of-the-art methods.
Text recognition on images using pre-trained CNN
Feb 10, 2023
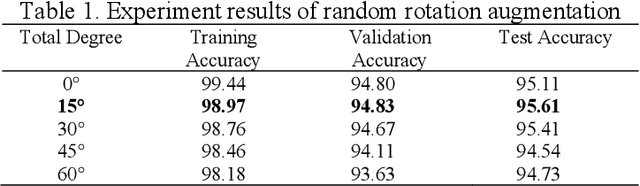

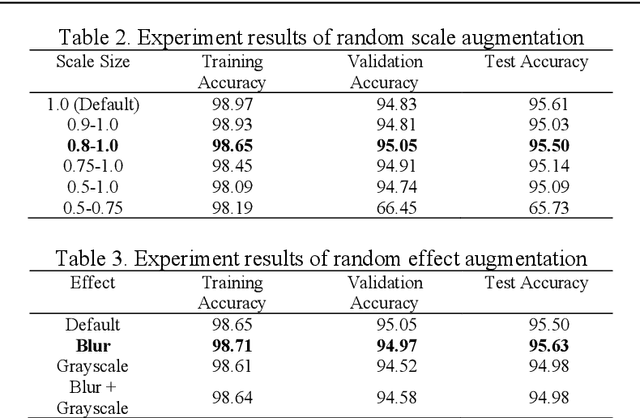
A text on an image often stores important information and directly carries high level semantics, makes it as important source of information and become a very active research topic. Many studies have shown that the use of CNN-based neural networks is quite effective and accurate for image classification which is the basis of text recognition. It can also be more enhanced by using transfer learning from pre-trained model trained on ImageNet dataset as an initial weight. In this research, the recognition is trained by using Chars74K dataset and the best model results then tested on some samples of IIIT-5K-Dataset. The research results showed that the best accuracy is the model that trained using VGG-16 architecture applied with image transformation of rotation 15{\deg}, image scale of 0.9, and the application of gaussian blur effect. The research model has an accuracy of 97.94% for validation data, 98.16% for test data, and 95.62% for the test data from IIIT-5K-Dataset. Based on these results, it can be concluded that pre-trained CNN can produce good accuracy for text recognition, and the model architecture that used in this study can be used as reference material in the development of text detection systems in the future