 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UniFormerV2: Spatiotemporal Learning by Arming Image ViTs with Video UniFormer
Nov 17, 2022
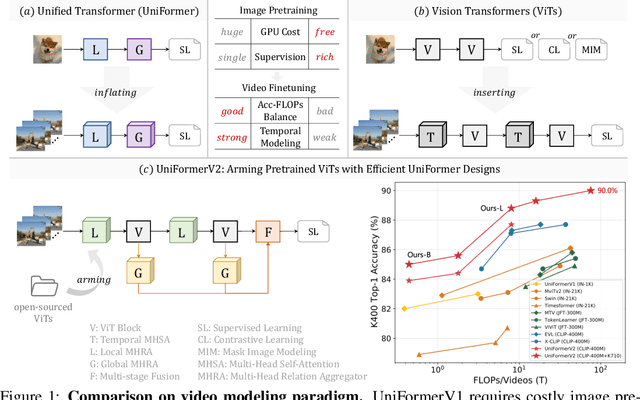
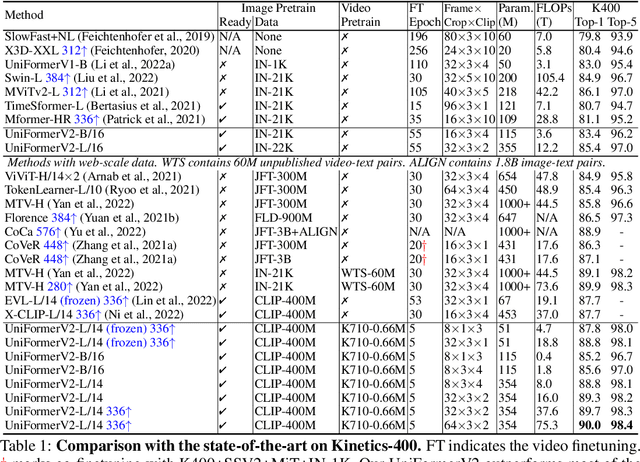
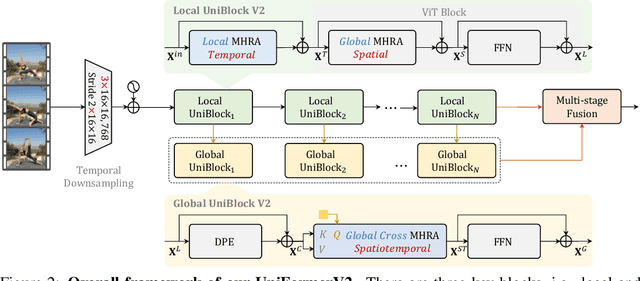
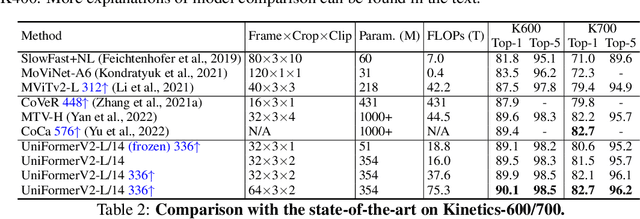
Learning discriminative spatiotemporal representation is the key problem of video understanding. Recently, Vision Transformers (ViTs) have shown their power in learning long-term video dependency with self-attention. Unfortunately, they exhibit limitations in tackling local video redundancy, due to the blind global comparison among tokens. UniFormer has successfully alleviated this issue, by unifying convolution and self-attention as a relation aggregator in the transformer format. However, this model has to require a tiresome and complicated image-pretraining phrase, before being finetuned on videos. This blocks its wide usage in practice. On the contrary, open-sourced ViTs are readily available and well-pretrained with rich image supervision. Based on these observations, we propose a generic paradigm to build a powerful family of video networks, by arming the pretrained ViTs with efficient UniFormer designs. We call this family UniFormerV2, since it inherits the concise style of the UniFormer block. But it contains brand-new local and global relation aggregators, which allow for preferable accuracy-computation balance by seamlessly integrating advantages from both ViTs and UniFormer. Without any bells and whistles, our UniFormerV2 gets the state-of-the-art recognition performance on 8 popular video benchmarks, including scene-related Kinetics-400/600/700 and Moments in Time, temporal-related Something-Something V1/V2, untrimmed ActivityNet and HACS. In particular, it is the first model to achieve 90% top-1 accuracy on Kinetics-400, to our best knowledge. Code will be available at https://github.com/OpenGVLab/UniFormerV2.
UKnow: A Unified Knowledge Protocol for Common-Sense Reasoning and Vision-Language Pre-training
Feb 14, 2023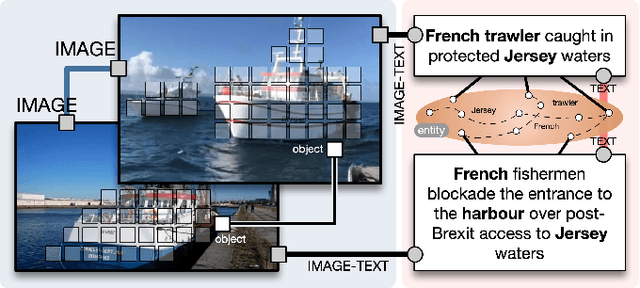
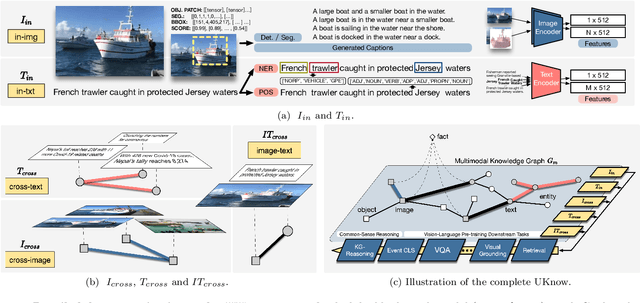
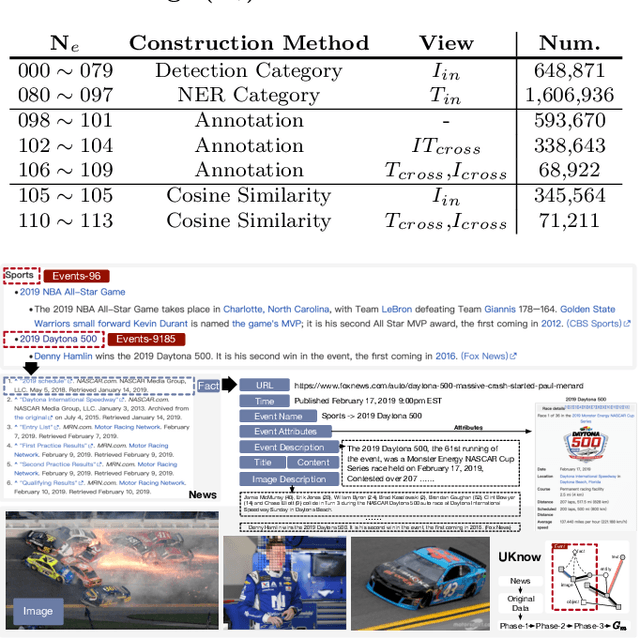
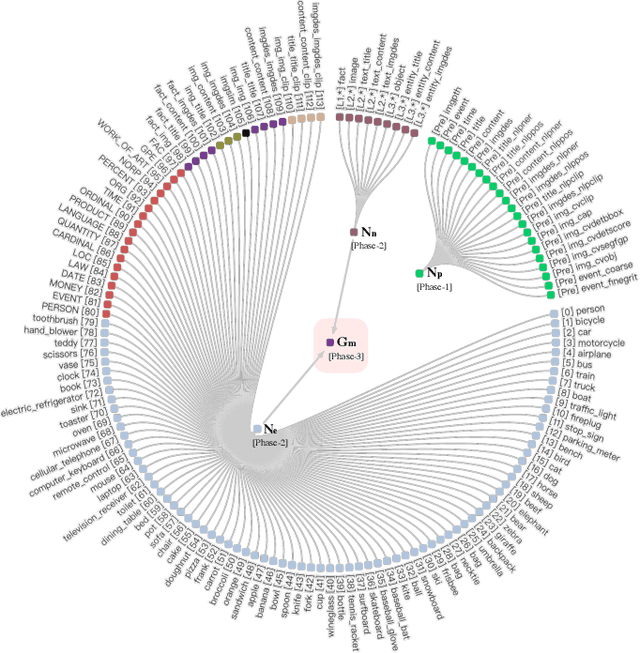
This work presents a unified knowledge protocol, called UKnow, which facilitates knowledge-based studies from the perspective of data. Particularly focusing on visual and linguistic modalities, we categorize data knowledge into five unit types, namely, in-image, in-text, cross-image, cross-text, and image-text. Following this protocol, we collect, from public international news, a large-scale multimodal knowledge graph dataset that consists of 1,388,568 nodes (with 571,791 vision-related ones) and 3,673,817 triplets. The dataset is also annotated with rich event tags, including 96 coarse labels and 9,185 fine labels, expanding its potential usage. To further verify that UKnow can serve as a standard protocol, we set up an efficient pipeline to help reorganize existing datasets under UKnow format. Finally, we benchmark the performance of some widely-used baselines on the tasks of common-sense reasoning and vision-language pre-training. Results on both our new dataset and the reformatted public datasets demonstrate the effectiveness of UKnow in knowledge organization and method evaluation. Code, dataset, conversion tool, and baseline models will be made public.
Guided Depth Map Super-resolution: A Survey
Feb 19, 2023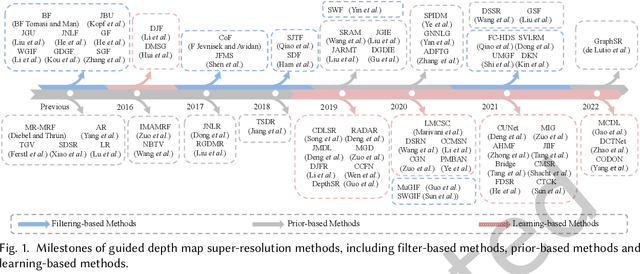

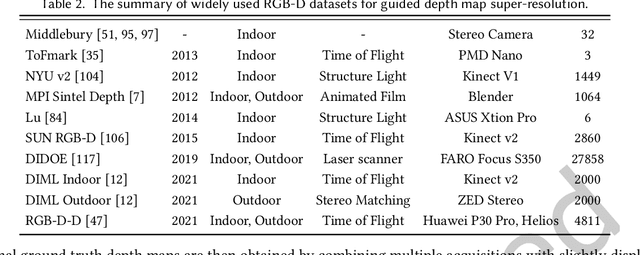
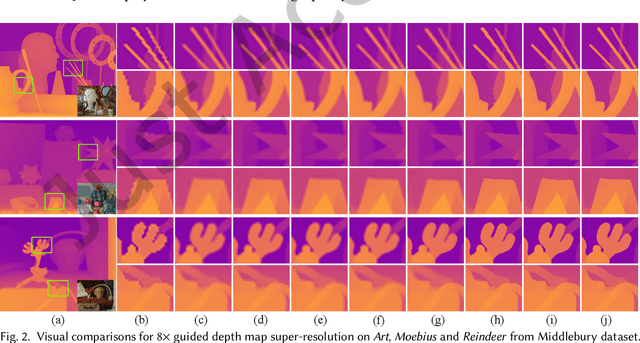
Guided depth map super-resolution (GDSR), which aims to reconstruct a high-resolution (HR) depth map from a low-resolution (LR) observation with the help of a paired HR color image, is a longstanding and fundamental problem, it has attracted considerable attention from computer vision and image processing communities. A myriad of novel and effective approaches have been proposed recently, especially with powerful deep learning techniques. This survey is an effort to present a comprehensive survey of recent progress in GDSR. We start by summarizing the problem of GDSR and explaining why it is challenging. Next, we introduce some commonly used datasets and image quality assessment methods. In addition, we roughly classify existing GDSR methods into three categories, i.e., filtering-based methods, prior-based methods, and learning-based methods. In each category, we introduce the general description of the published algorithms and design principles, summarize the representative methods, and discuss their highlights and limitations. Moreover, the depth related applications are introduced. Furthermore, we conduct experiments to evaluate the performance of some representative methods based on unified experimental configurations, so as to offer a systematic and fair performance evaluation to readers. Finally, we conclude this survey with possible directions and open problems for further research. All the related materials can be found at \url{https://github.com/zhwzhong/Guided-Depth-Map-Super-resolution-A-Survey}.
Exploit CAM by itself: Complementary Learning System for Weakly Supervised Semantic Segmentation
Mar 04, 2023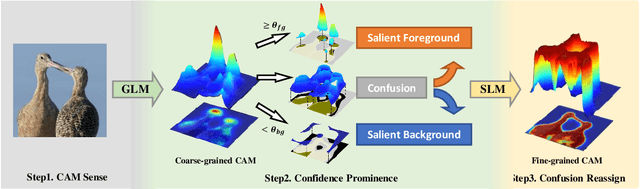
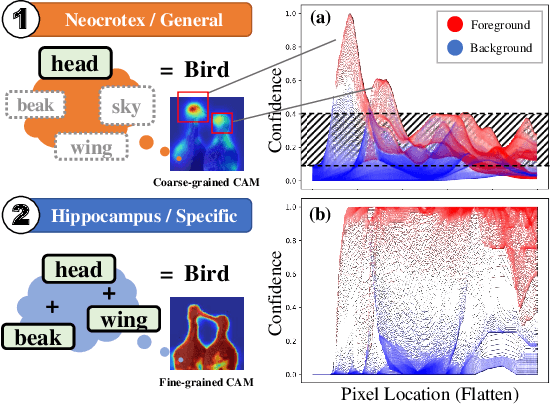
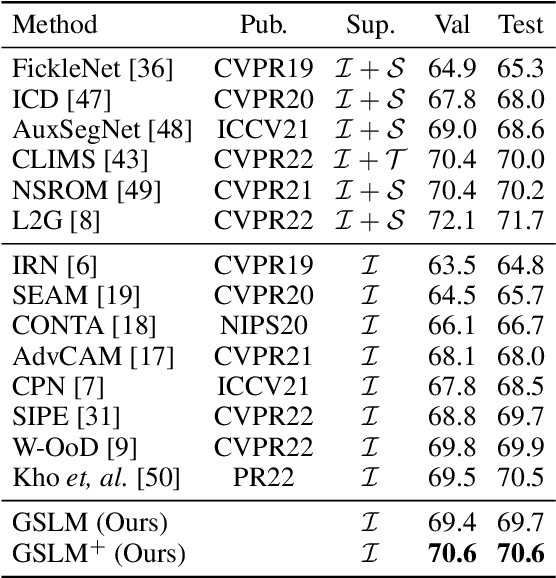
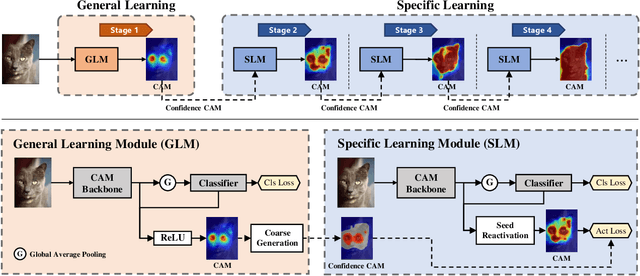
Weakly Supervised Semantic Segmentation (WSSS) with image-level labels has long been suffering from fragmentary object regions led by Class Activation Map (CAM), which is incapable of generating fine-grained masks for semantic segmentation. To guide CAM to find more non-discriminating object patterns, this paper turns to an interesting working mechanism in agent learning named Complementary Learning System (CLS). CLS holds that the neocortex builds a sensation of general knowledge, while the hippocampus specially learns specific details, completing the learned patterns. Motivated by this simple but effective learning pattern, we propose a General-Specific Learning Mechanism (GSLM) to explicitly drive a coarse-grained CAM to a fine-grained pseudo mask. Specifically, GSLM develops a General Learning Module (GLM) and a Specific Learning Module (SLM). The GLM is trained with image-level supervision to extract coarse and general localization representations from CAM. Based on the general knowledge in the GLM, the SLM progressively exploits the specific spatial knowledge from the localization representations, expanding the CAM in an explicit way. To this end, we propose the Seed Reactivation to help SLM reactivate non-discriminating regions by setting a boundary for activation values, which successively identifies more regions of CAM. Without extra refinement processes, our method is able to achieve breakthrough improvements for CAM of over 20.0% mIoU on PASCAL VOC 2012 and 10.0% mIoU on MS COCO 2014 datasets, representing a new state-of-the-art among existing WSSS methods.
IM: An R-Package for Computation of Image Moments and Moment Invariants
Oct 29, 2022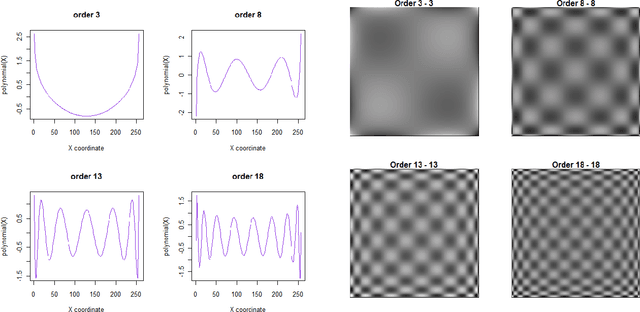
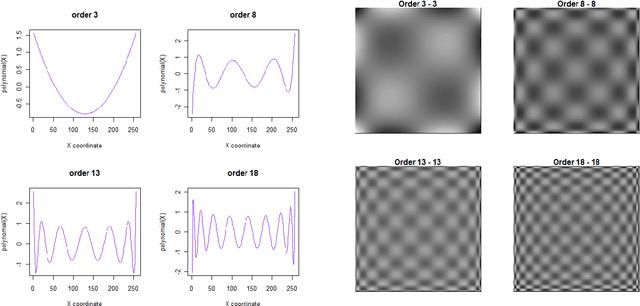
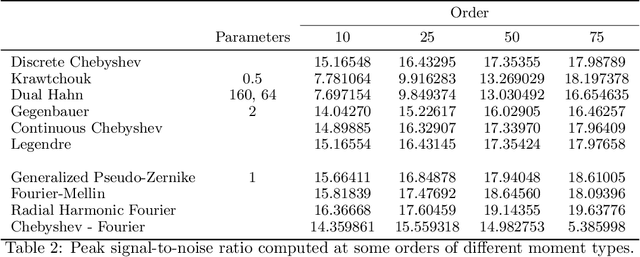
Moment invariants are well-established and effective shape descriptors for image classification. In this report, we introduce a package for R-language, named IM, that implements the calculation of moments for images and allows the reconstruction of images from moments within an object-oriented framework. Several types of moments may be computed using the IM library, including discrete and continuous Chebyshev, Gegenbauer, Legendre, Krawtchouk, dual Hahn, generalized pseudo-Zernike, Fourier-Mellin, and radial harmonic Fourier moments. In addition, custom bivariate types of moments can be calculated using combinations of two different types of polynomials. A method of polar transformation of pixel coordinates is used to provide an approximate invariance to rotation for moments that are orthogonal over a rectangle. The different types of polynomials used to calculate moments are discussed in this report, as well as comparisons of reconstruction and running time. Examples of image classification using image moments are provided.
EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
Mar 22, 2023
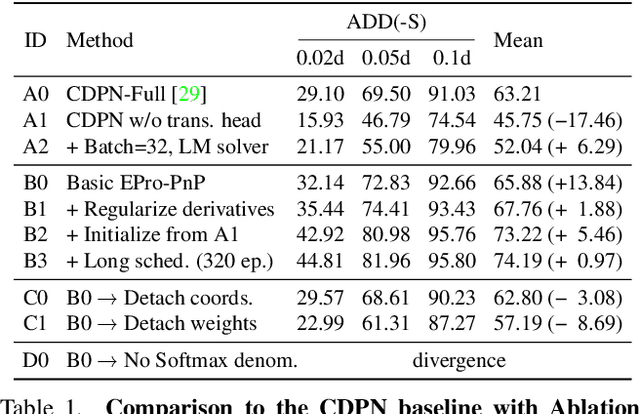
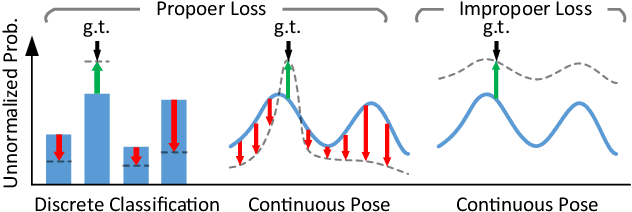
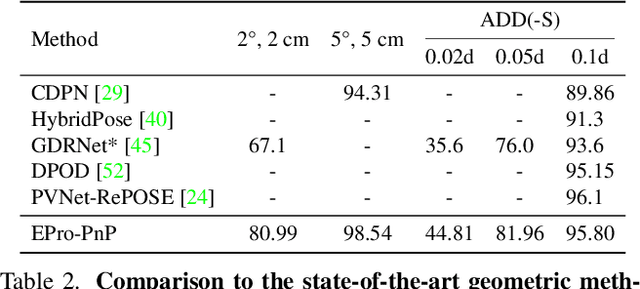
Locating 3D objects from a single RGB image via Perspective-n-Point (PnP) is a long-standing problem in computer vision. Driven by end-to-end deep learning, recent studies suggest interpreting PnP as a differentiable layer, allowing for partial learning of 2D-3D point correspondences by backpropagating the gradients of pose loss. Yet, learning the entire correspondences from scratch is highly challenging, particularly for ambiguous pose solutions, where the globally optimal pose is theoretically non-differentiable w.r.t. the points. In this paper, we propose the EPro-PnP, a probabilistic PnP layer for general end-to-end pose estimation, which outputs a distribution of pose with differentiable probability density on the SE(3) manifold. The 2D-3D coordinates and corresponding weights are treated as intermediate variables learned by minimizing the KL divergence between the predicted and target pose distribution. The underlying principle generalizes previous approaches, and resembles the attention mechanism. EPro-PnP can enhance existing correspondence networks, closing the gap between PnP-based method and the task-specific leaders on the LineMOD 6DoF pose estimation benchmark. Furthermore, EPro-PnP helps to explore new possibilities of network design, as we demonstrate a novel deformable correspondence network with the state-of-the-art pose accuracy on the nuScenes 3D object detection benchmark. Our code is available at https://github.com/tjiiv-cprg/EPro-PnP-v2.
Visual Watermark Removal Based on Deep Learning
Feb 07, 2023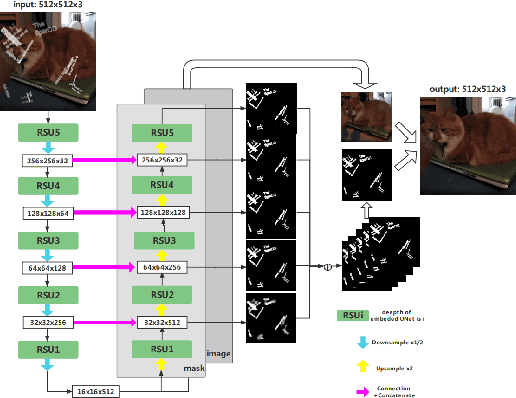
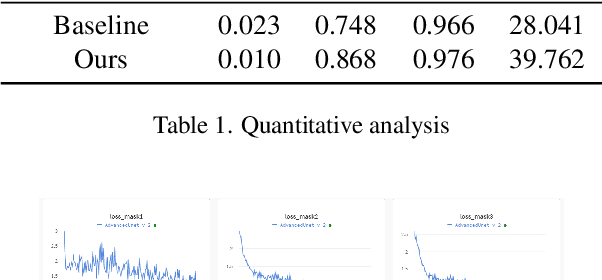
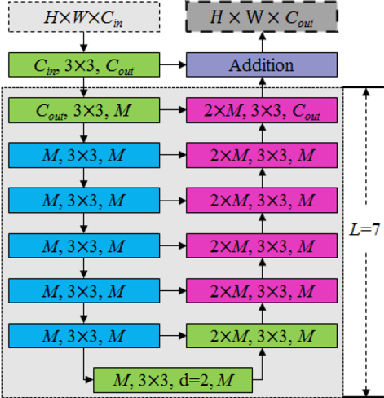
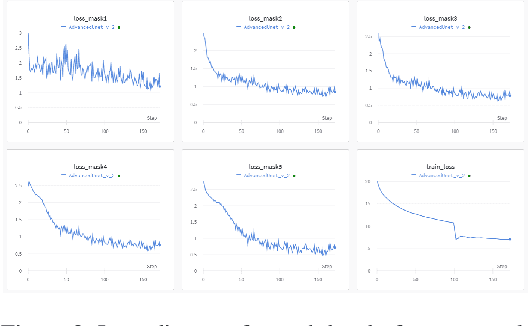
In recent years as the internet age continues to grow, sharing images on social media has become a common occurrence. In certain cases, watermarks are used as protection for the ownership of the image, however, in more cases, one may wish to remove these watermark images to get the original image without obscuring. In this work, we proposed a deep learning method based technique for visual watermark removal. Inspired by the strong image translation performance of the U-structure, an end-to-end deep neural network model named AdvancedUnet is proposed to extract and remove the visual watermark simultaneously. On the other hand, we embed some effective RSU module instead of the common residual block used in UNet, which increases the depth of the whole architecture without significantly increasing the computational cost. The deep-supervised hybrid loss guides the network to learn the transformation between the input image and the ground truth in a multi-scale and three-level hierarchy. Comparison experiments demonstrate the effectiveness of our method.
Text recognition on images using pre-trained CNN
Feb 10, 2023
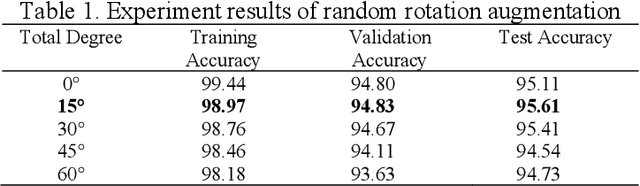

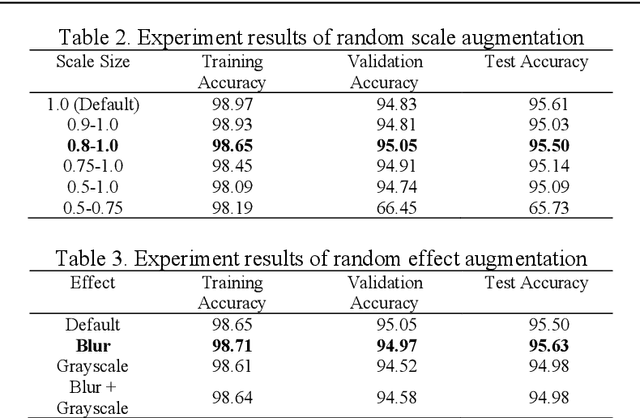
A text on an image often stores important information and directly carries high level semantics, makes it as important source of information and become a very active research topic. Many studies have shown that the use of CNN-based neural networks is quite effective and accurate for image classification which is the basis of text recognition. It can also be more enhanced by using transfer learning from pre-trained model trained on ImageNet dataset as an initial weight. In this research, the recognition is trained by using Chars74K dataset and the best model results then tested on some samples of IIIT-5K-Dataset. The research results showed that the best accuracy is the model that trained using VGG-16 architecture applied with image transformation of rotation 15{\deg}, image scale of 0.9, and the application of gaussian blur effect. The research model has an accuracy of 97.94% for validation data, 98.16% for test data, and 95.62% for the test data from IIIT-5K-Dataset. Based on these results, it can be concluded that pre-trained CNN can produce good accuracy for text recognition, and the model architecture that used in this study can be used as reference material in the development of text detection systems in the future
E2CoPre: Energy Efficient and Cooperative Collision Avoidance for UAV Swarms with Trajectory Prediction
Mar 11, 2023
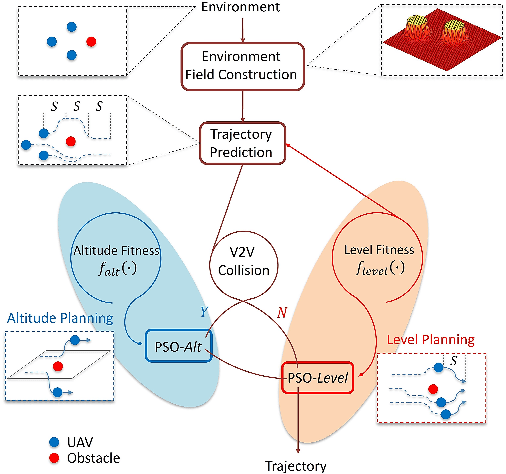
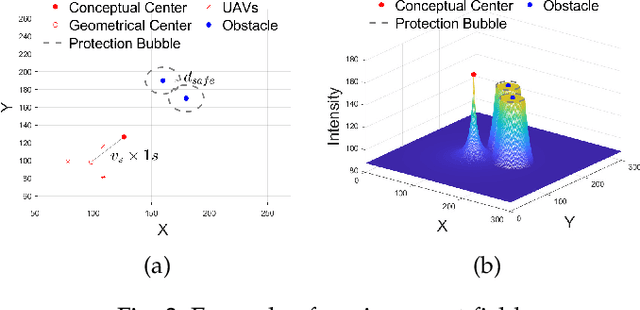
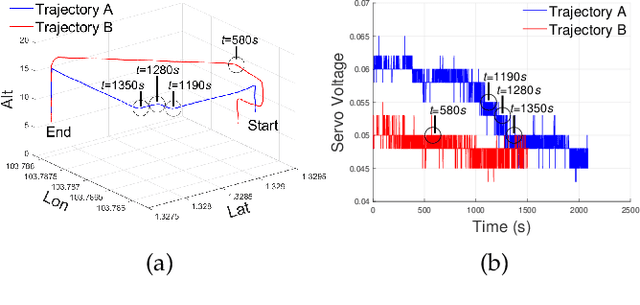
This paper addresses the collision avoidance problem of UAV swarms in three-dimensional (3D) space. The key challenges are energy efficiency and cooperation of swarm members. We propose to combine Artificial Potential Field (APF) with Particle Swarm Planning (PSO). APF provides environmental awareness and implicit coordination to UAVs. PSO searches for the optimal trajectories for each UAV in terms of safety and energy efficiency by minimizing a fitness function. The fitness function exploits the advantages of the Active Contour Model in image processing for trajectory planning. Lastly, vehicle-to-vehicle collisions are detected in advance based on trajectory prediction and are resolved by cooperatively adjusting the altitude of UAVs. Simulation results demonstrate that our method can save up to 80\% of energy compared to state-of-the-art schemes.
Exploring Structure-Wise Uncertainty for 3D Medical Image Segmentation
Nov 01, 2022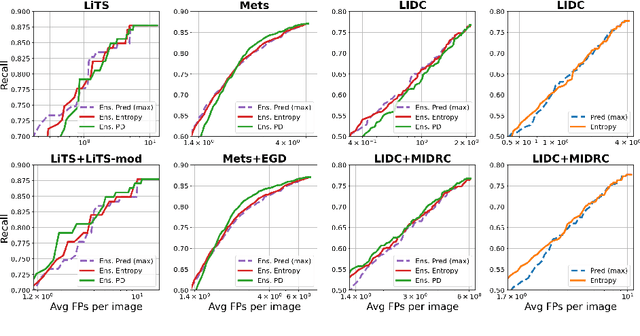
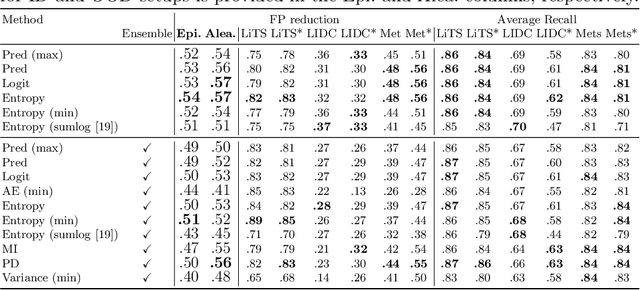
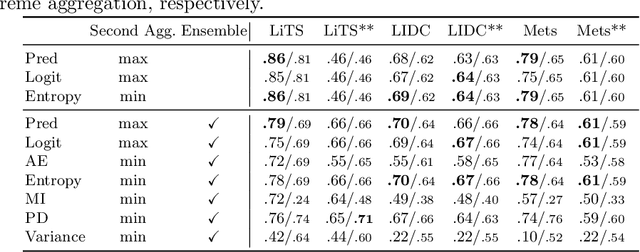
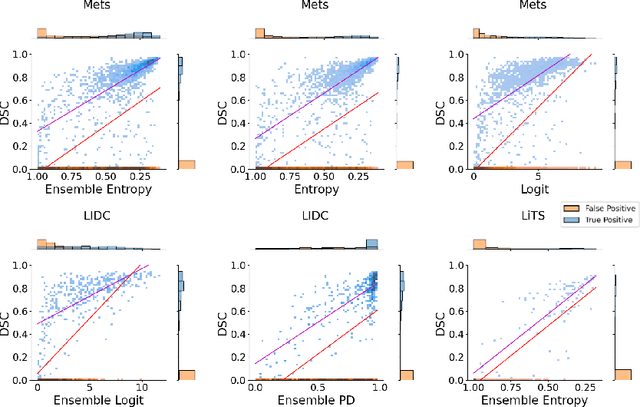
When applying a Deep Learning model to medical images, it is crucial to estimate the model uncertainty. Voxel-wise uncertainty is a useful visual marker for human experts and could be used to improve the model's voxel-wise output, such as segmentation. Moreover, uncertainty provides a solid foundation for out-of-distribution (OOD) detection, improving the model performance on the image-wise level. However, one of the frequent tasks in medical imaging is the segmentation of distinct, local structures such as tumors or lesions. Here, the structure-wise uncertainty allows more precise operations than image-wise and more semantic-aware than voxel-wise. The way to produce uncertainty for individual structures remains poorly explored. We propose a framework to measure the structure-wise uncertainty and evaluate the impact of OOD data on the model performance. Thus, we identify the best UE method to improve the segmentation quality. The proposed framework is tested on three datasets with the tumor segmentation task: LIDC-IDRI, LiTS, and a private one with multiple brain metastases cases.