 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diffusion-based Image Translation using Disentangled Style and Content Representation
Sep 30, 2022

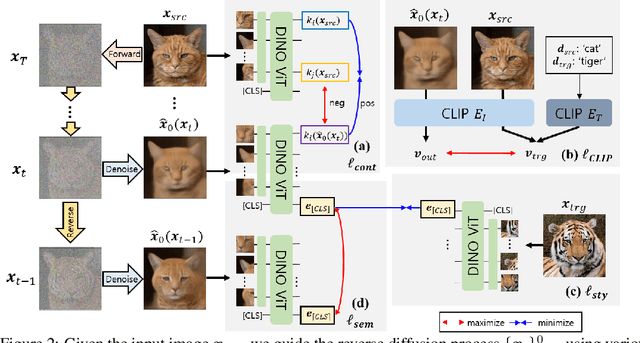
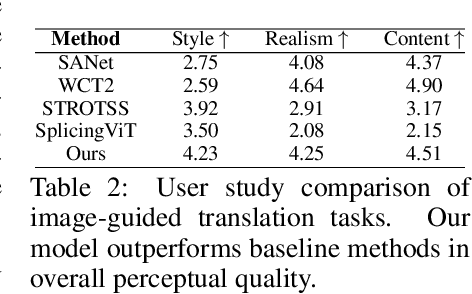

Diffusion-based image translation guided by semantic texts or a single target image has enabled flexible style transfer which is not limited to the specific domains. Unfortunately, due to the stochastic nature of diffusion models, it is often difficult to maintain the original content of the image during the reverse diffusion. To address this, here we present a novel diffusion-based unsupervised image translation method using disentangled style and content representation. Specifically, inspired by the splicing Vision Transformer, we extract intermediate keys of multihead self attention layer from ViT model and used them as the content preservation loss. Then, an image guided style transfer is performed by matching the [CLS] classification token from the denoised samples and target image, whereas additional CLIP loss is used for the text-driven style transfer. To further accelerate the semantic change during the reverse diffusion, we also propose a novel semantic divergence loss and resampling strategy. Our experimental results show that the proposed method outperforms state-of-the-art baseline models in both text-guided and image-guided translation tasks.
Text-Only Training for Image Captioning using Noise-Injected CLIP
Nov 01, 2022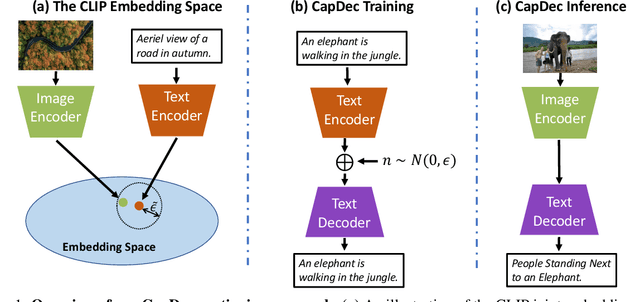
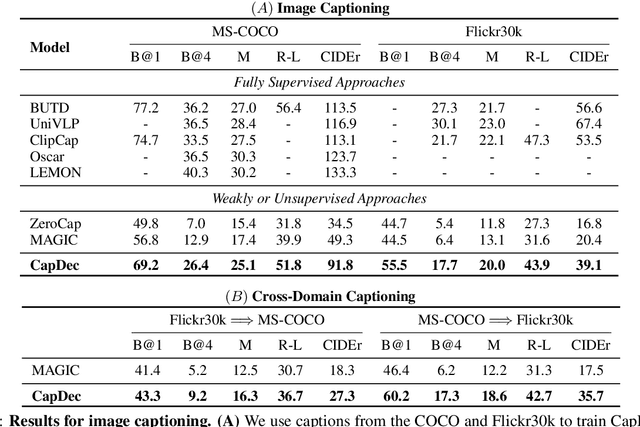
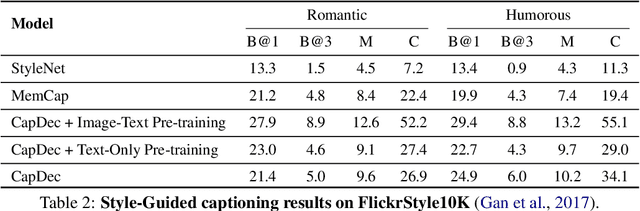

We consider the task of image-captioning using only the CLIP model and additional text data at training time, and no additional captioned images. Our approach relies on the fact that CLIP is trained to make visual and textual embeddings similar. Therefore, we only need to learn how to translate CLIP textual embeddings back into text, and we can learn how to do this by learning a decoder for the frozen CLIP text encoder using only text. We argue that this intuition is "almost correct" because of a gap between the embedding spaces, and propose to rectify this via noise injection during training. We demonstrate the effectiveness of our approach by showing SOTA zero-shot image captioning across four benchmarks, including style transfer. Code, data, and models are available on GitHub.
E2CoPre: Energy Efficient and Cooperative Collision Avoidance for UAV Swarms with Trajectory Prediction
Mar 11, 2023
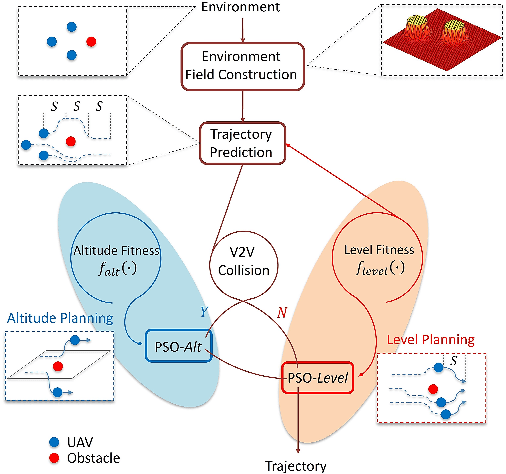
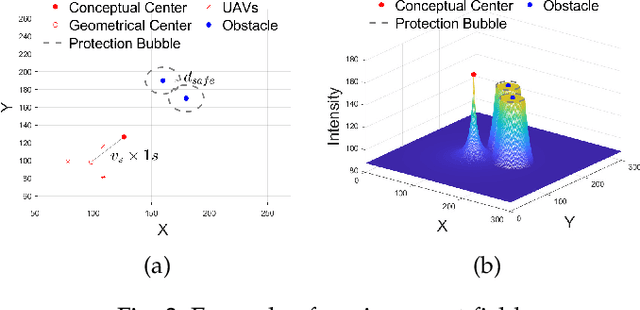
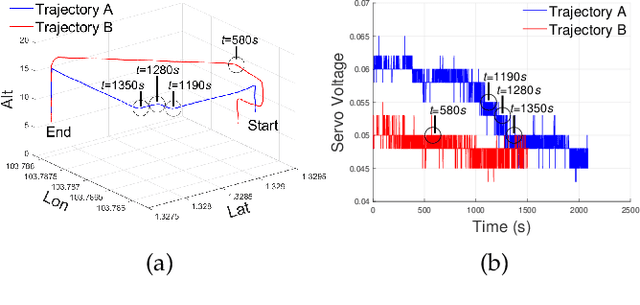
This paper addresses the collision avoidance problem of UAV swarms in three-dimensional (3D) space. The key challenges are energy efficiency and cooperation of swarm members. We propose to combine Artificial Potential Field (APF) with Particle Swarm Planning (PSO). APF provides environmental awareness and implicit coordination to UAVs. PSO searches for the optimal trajectories for each UAV in terms of safety and energy efficiency by minimizing a fitness function. The fitness function exploits the advantages of the Active Contour Model in image processing for trajectory planning. Lastly, vehicle-to-vehicle collisions are detected in advance based on trajectory prediction and are resolved by cooperatively adjusting the altitude of UAVs. Simulation results demonstrate that our method can save up to 80\% of energy compared to state-of-the-art schemes.
See Blue Sky: Deep Image Dehaze Using Paired and Unpaired Training Images
Oct 14, 2022
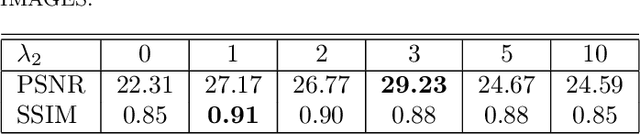
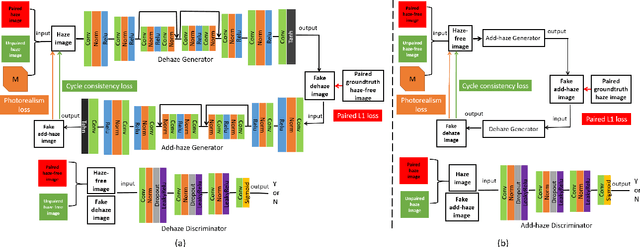
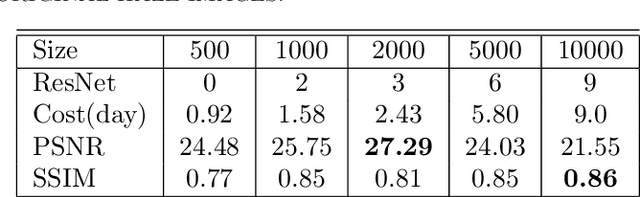
The issue of image haze removal has attracted wide attention in recent years. However, most existing haze removal methods cannot restore the scene with clear blue sky, since the color and texture information of the object in the original haze image is insufficient. To remedy this, we propose a cycle generative adversarial network to construct a novel end-to-end image dehaze model. We adopt outdoor image datasets to train our model, which includes a set of real-world unpaired image dataset and a set of paired image dataset to ensure that the generated images are close to the real scene. Based on the cycle structure, our model adds four different kinds of loss function to constrain the effect including adversarial loss, cycle consistency loss, photorealism loss and paired L1 loss. These four constraints can improve the overall quality of such degraded images for better visual appeal and ensure reconstruction of images to keep from distortion. The proposed model could remove the haze of images and also restore the sky of images to be clean and blue (like captured in a sunny weather).
Towards Effective Image Manipulation Detection with Proposal Contrastive Learning
Oct 16, 2022
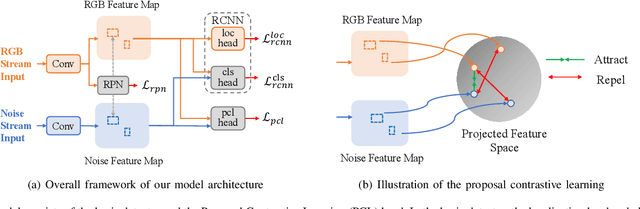
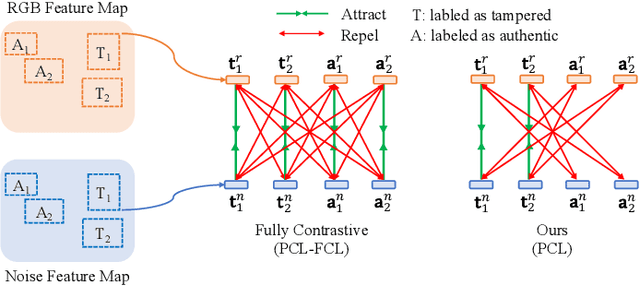
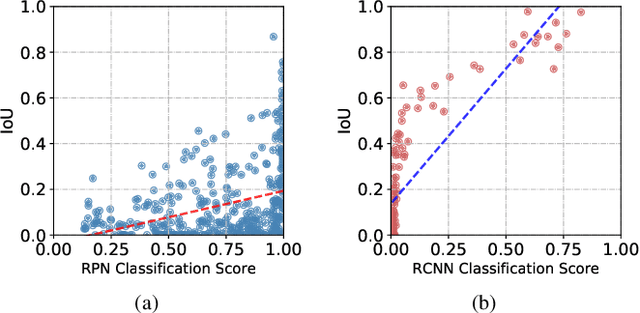
Deep models have been widely and successfully used in image manipulation detection, which aims to classify tampered images and localize tampered regions. Most existing methods mainly focus on extracting \textit{global features} from tampered images, while neglecting the \textit{relationships of local features} between tampered and authentic regions within a single tampered image. To exploit such spatial relationships, we propose Proposal Contrastive Learning (PCL) for effective image manipulation detection. Our PCL consists of a two-stream architecture by extracting two types of global features from RGB and noise views respectively. To further improve the discriminative power, we exploit the relationships of local features through a proxy proposal contrastive learning task by attracting/repelling proposal-based positive/negative sample pairs. Moreover, we show that our PCL can be easily adapted to unlabeled data in practice, which can reduce manual labeling costs and promote more generalizable features. Extensive experiments among several standard datasets demonstrate that our PCL can be a general module to obtain consistent improvement.
Natural Scene Image Annotation Using Local Semantic Concepts and Spatial Bag of Visual Words
Oct 17, 2022
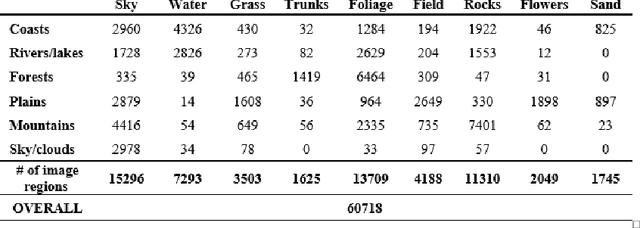
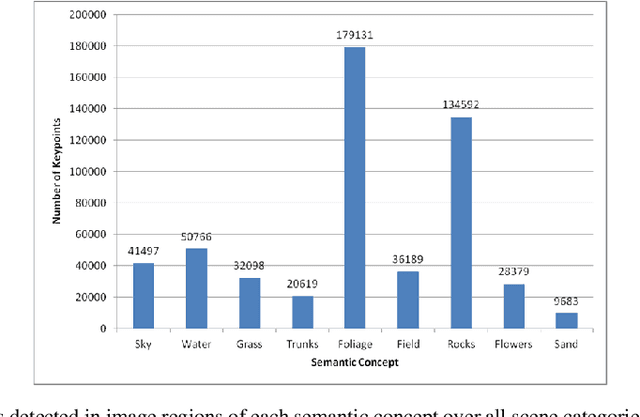
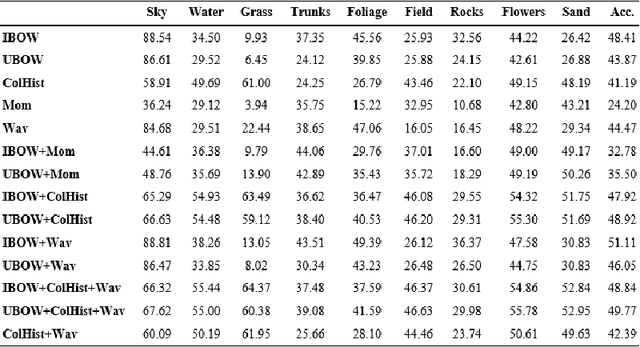
The use of bag of visual words (BOW) model for modelling images based on local invariant features computed at interest point locations has become a standard choice for many computer vision tasks. Visual vocabularies generated from image feature vectors are expected to produce visual words that are discriminative to improve the performance of image annotation systems. Most techniques that adopt the BOW model in annotating images declined favorable information that can be mined from image categories to build discriminative visual vocabularies. To this end, this paper introduces a detailed framework for automatically annotating natural scene images with local semantic labels from a predefined vocabulary. The framework is based on a hypothesis that assumes that, in natural scenes, intermediate semantic concepts are correlated with the local keypoints. Based on this hypothesis, image regions can be efficiently represented by BOW model and using a machine learning approach, such as SVM, to label image regions with semantic annotations. Another objective of this paper is to address the implications of generating visual vocabularies from image halves, instead of producing them from the whole image, on the performance of annotating image regions with semantic labels. All BOW-based approaches as well as baseline methods have been extensively evaluated on 6-categories dataset of natural scenes using the SVM and KNN classifiers. The reported results have shown the plausibility of using the BOW model to represent the semantic information of image regions and thus to automatically annotate image regions with labels.
Feature Alignment and Uniformity for Test Time Adaptation
Mar 20, 2023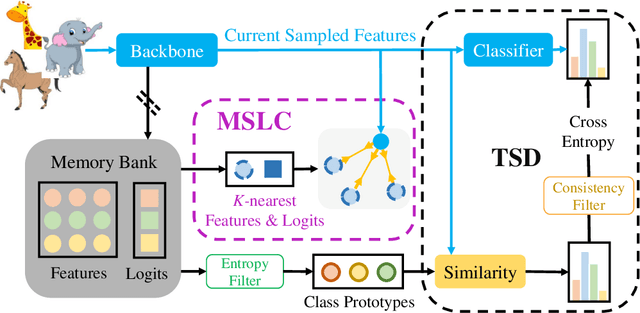
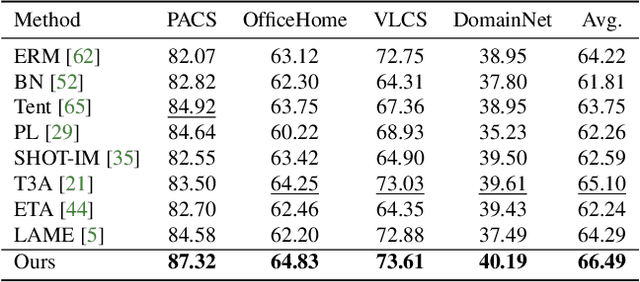
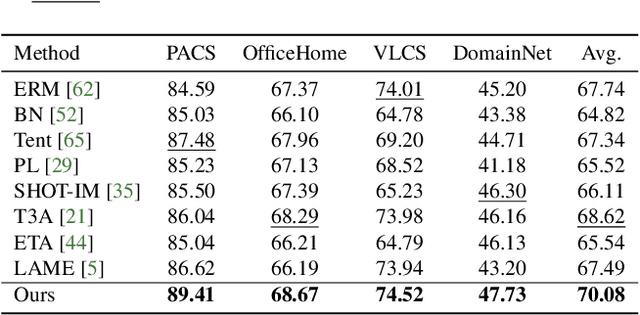
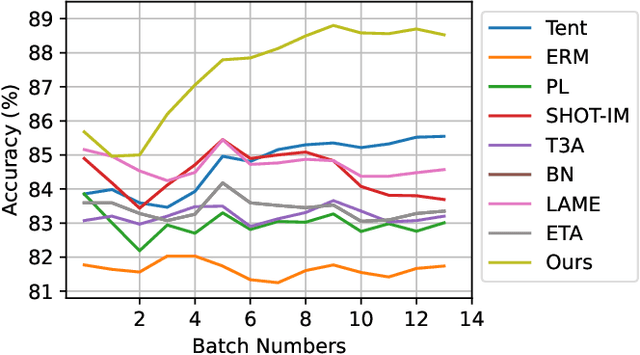
Test time adaptation (TTA) aims to adapt deep neural networks when receiving out of distribution test domain samples. In this setting, the model can only access online unlabeled test samples and pre-trained models on the training domains. We first address TTA as a feature revision problem due to the domain gap between source domains and target domains. After that, we follow the two measurements alignment and uniformity to discuss the test time feature revision. For test time feature uniformity, we propose a test time self-distillation strategy to guarantee the consistency of uniformity between representations of the current batch and all the previous batches. For test time feature alignment, we propose a memorized spatial local clustering strategy to align the representations among the neighborhood samples for the upcoming batch. To deal with the common noisy label problem, we propound the entropy and consistency filters to select and drop the possible noisy labels. To prove the scalability and efficacy of our method, we conduct experiments on four domain generalization benchmarks and four medical image segmentation tasks with various backbones. Experiment results show that our method not only improves baseline stably but also outperforms existing state-of-the-art test time adaptation methods.
Benchmarking Robustness of 3D Object Detection to Common Corruptions in Autonomous Driving
Mar 20, 2023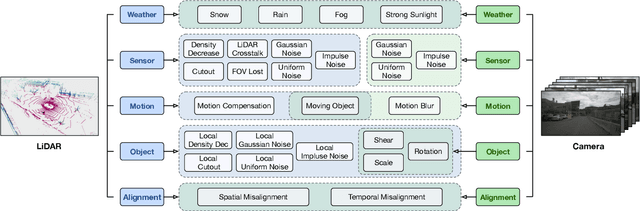
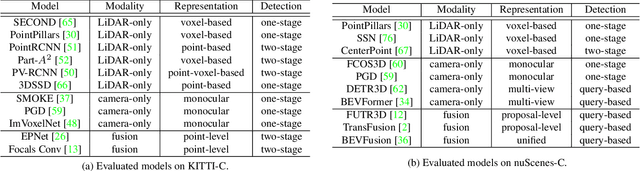

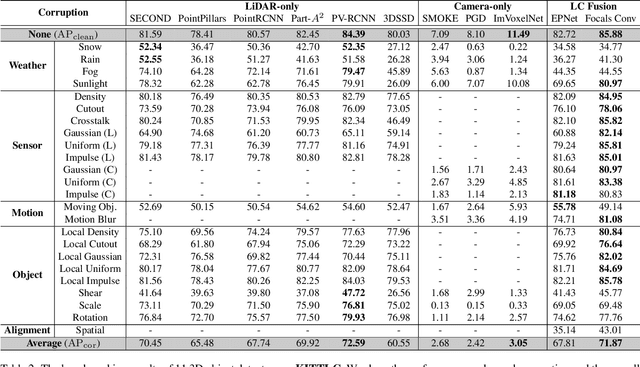
3D object detection is an important task in autonomous driving to perceive the surroundings. Despite the excellent performance, the existing 3D detectors lack the robustness to real-world corruptions caused by adverse weathers, sensor noises, etc., provoking concerns about the safety and reliability of autonomous driving systems. To comprehensively and rigorously benchmark the corruption robustness of 3D detectors, in this paper we design 27 types of common corruptions for both LiDAR and camera inputs considering real-world driving scenarios. By synthesizing these corruptions on public datasets, we establish three corruption robustness benchmarks -- KITTI-C, nuScenes-C, and Waymo-C. Then, we conduct large-scale experiments on 24 diverse 3D object detection models to evaluate their corruption robustness. Based on the evaluation results, we draw several important findings, including: 1) motion-level corruptions are the most threatening ones that lead to significant performance drop of all models; 2) LiDAR-camera fusion models demonstrate better robustness; 3) camera-only models are extremely vulnerable to image corruptions, showing the indispensability of LiDAR point clouds. We release the benchmarks and codes at https://github.com/kkkcx/3D_Corruptions_AD. We hope that our benchmarks and findings can provide insights for future research on developing robust 3D object detection models.
Open-World Pose Transfer via Sequential Test-Time Adaption
Mar 20, 2023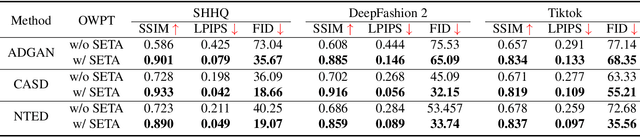
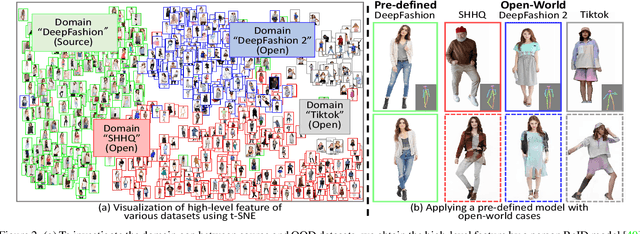
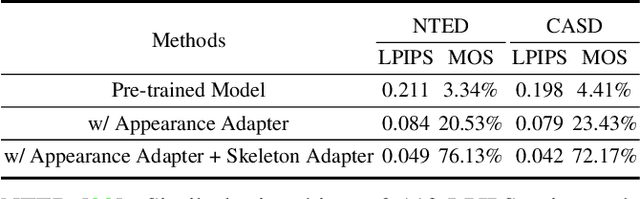
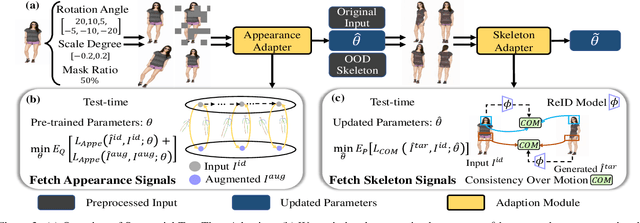
Pose transfer aims to transfer a given person into a specified posture, has recently attracted considerable attention. A typical pose transfer framework usually employs representative datasets to train a discriminative model, which is often violated by out-of-distribution (OOD) instances. Recently, test-time adaption (TTA) offers a feasible solution for OOD data by using a pre-trained model that learns essential features with self-supervision. However, those methods implicitly make an assumption that all test distributions have a unified signal that can be learned directly. In open-world conditions, the pose transfer task raises various independent signals: OOD appearance and skeleton, which need to be extracted and distributed in speciality. To address this point, we develop a SEquential Test-time Adaption (SETA). In the test-time phrase, SETA extracts and distributes external appearance texture by augmenting OOD data for self-supervised training. To make non-Euclidean similarity among different postures explicit, SETA uses the image representations derived from a person re-identification (Re-ID) model for similarity computation. By addressing implicit posture representation in the test-time sequentially, SETA greatly improves the generalization performance of current pose transfer models. In our experiment, we first show that pose transfer can be applied to open-world applications, including Tiktok reenactment and celebrity motion synthesis.
Weakly-Supervised Text Instance Segmentation
Mar 20, 2023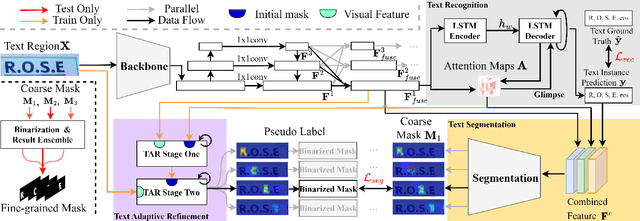
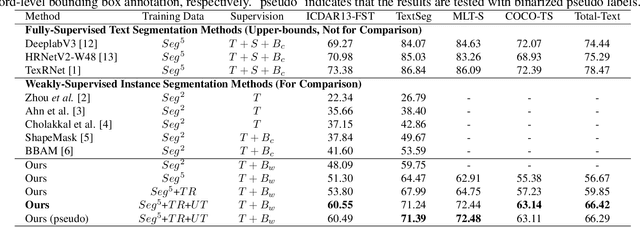


Text segmentation is a challenging vision task with many downstream applications. Current text segmentation methods require pixel-level annotations, which are expensive in the cost of human labor and limited in application scenarios. In this paper, we take the first attempt to perform weakly-supervised text instance segmentation by bridging text recognition and text segmentation. The insight is that text recognition methods provide precise attention position of each text instance, and the attention location can feed to both a text adaptive refinement head (TAR) and a text segmentation head. Specifically, the proposed TAR generates pseudo labels by performing two-stage iterative refinement operations on the attention location to fit the accurate boundaries of the corresponding text instance. Meanwhile, the text segmentation head takes the rough attention location to predict segmentation masks which are supervised by the aforementioned pseudo labels. In addition, we design a mask-augmented contrastive learning by treating our segmentation result as an augmented version of the input text image, thus improving the visual representation and further enhancing the performance of both recognition and segmentation. The experimental results demonstrate that the proposed method significantly outperforms weakly-supervised instance segmentation methods on ICDAR13-FST (18.95$\%$ improvement) and TextSeg (17.80$\%$ improvement) benchmarks.