 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffusionSeg: Adapting Diffusion Towards Unsupervised Object Discovery
Mar 17, 2023

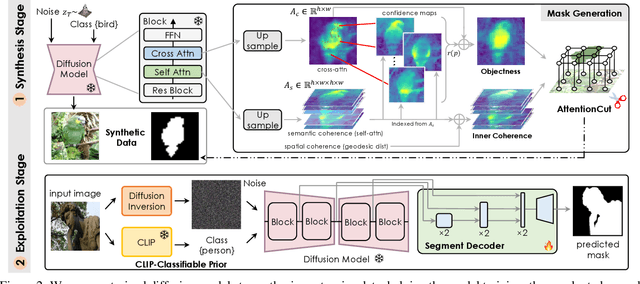

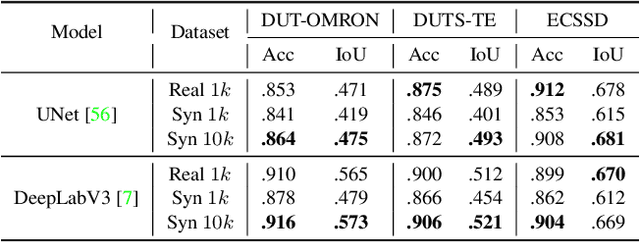
Learning from a large corpus of data, pre-trained models have achieved impressive progress nowadays. As popular generative pre-training, diffusion models capture both low-level visual knowledge and high-level semantic relations. In this paper, we propose to exploit such knowledgeable diffusion models for mainstream discriminative tasks, i.e., unsupervised object discovery: saliency segmentation and object localization. However, the challenges exist as there is one structural difference between generative and discriminative models, which limits the direct use. Besides, the lack of explicitly labeled data significantly limits performance in unsupervised settings. To tackle these issues, we introduce DiffusionSeg, one novel synthesis-exploitation framework containing two-stage strategies. To alleviate data insufficiency, we synthesize abundant images, and propose a novel training-free AttentionCut to obtain masks in the first synthesis stage. In the second exploitation stage, to bridge the structural gap, we use the inversion technique, to map the given image back to diffusion features. These features can be directly used by downstream architectures. Extensive experiments and ablation studies demonstrate the superiority of adapting diffusion for unsupervised object discovery.
CoDEPS: Online Continual Learning for Depth Estimation and Panoptic Segmentation
Mar 17, 2023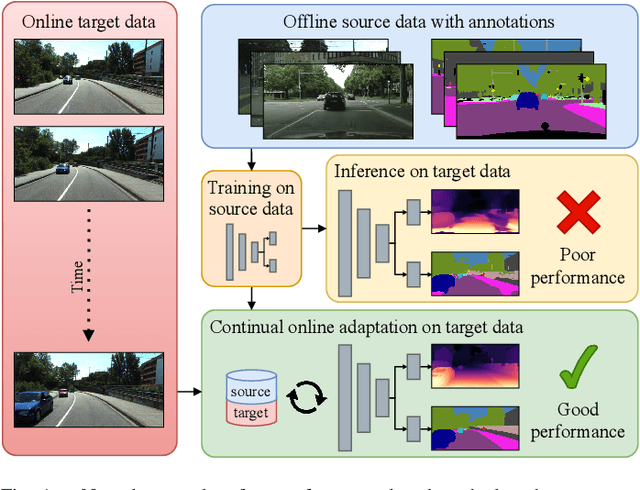
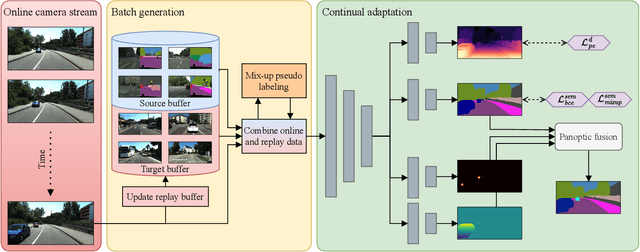
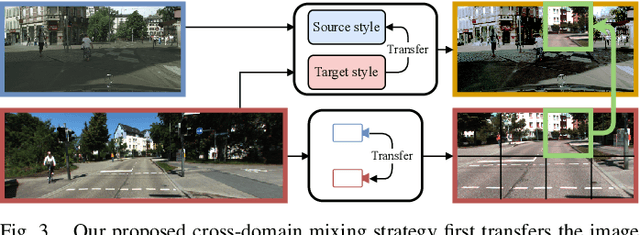
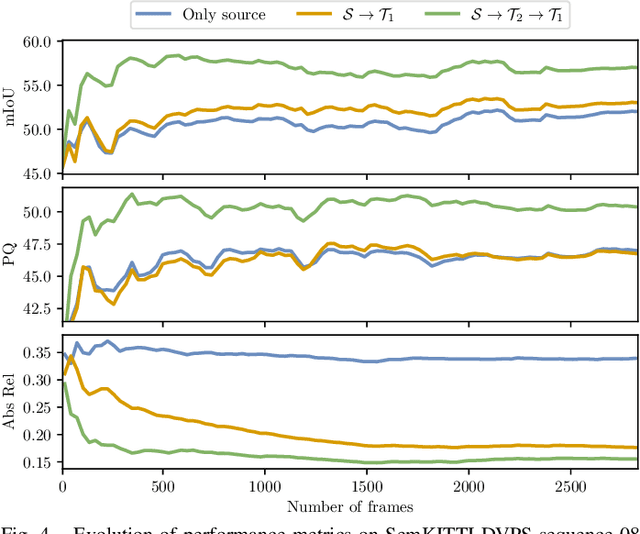
Operating a robot in the open world requires a high level of robustness with respect to previously unseen environments. Optimally, the robot is able to adapt by itself to new conditions without human supervision, e.g., automatically adjusting its perception system to changing lighting conditions. In this work, we address the task of continual learning for deep learning-based monocular depth estimation and panoptic segmentation in new environments in an online manner. We introduce CoDEPS to perform continual learning involving multiple real-world domains while mitigating catastrophic forgetting by leveraging experience replay. In particular, we propose a novel domain-mixing strategy to generate pseudo-labels to adapt panoptic segmentation. Furthermore, we explicitly address the limited storage capacity of robotic systems by proposing sampling strategies for constructing a fixed-size replay buffer based on rare semantic class sampling and image diversity. We perform extensive evaluations of CoDEPS on various real-world datasets demonstrating that it successfully adapts to unseen environments without sacrificing performance on previous domains while achieving state-of-the-art results. The code of our work is publicly available at http://codeps.cs.uni-freiburg.de.
GNNFormer: A Graph-based Framework for Cytopathology Report Generation
Mar 17, 2023
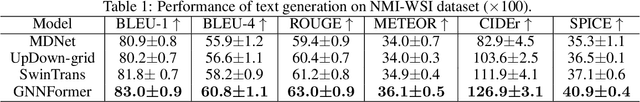
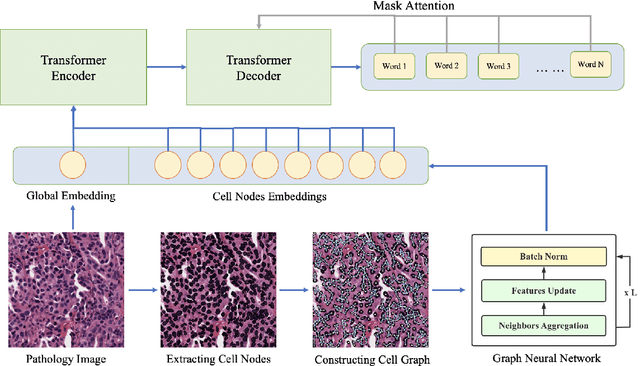
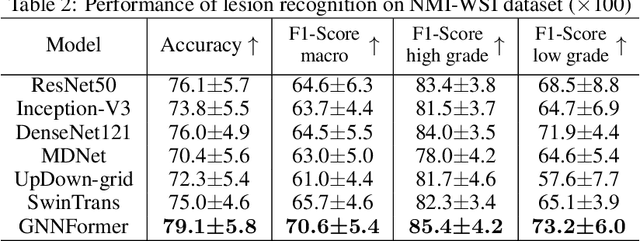
Cytopathology report generation is a necessary step for the standardized examination of pathology images. However, manually writing detailed reports brings heavy workloads for pathologists. To improve efficiency, some existing works have studied automatic generation of cytopathology reports, mainly by applying image caption generation frameworks with visual encoders originally proposed for natural images. A common weakness of these works is that they do not explicitly model the structural information among cells, which is a key feature of pathology images and provides significant information for making diagnoses. In this paper, we propose a novel graph-based framework called GNNFormer, which seamlessly integrates graph neural network (GNN) and Transformer into the same framework, for cytopathology report generation. To the best of our knowledge, GNNFormer is the first report generation method that explicitly models the structural information among cells in pathology images. It also effectively fuses structural information among cells, fine-grained morphology features of cells and background features to generate high-quality reports. Experimental results on the NMI-WSI dataset show that GNNFormer can outperform other state-of-the-art baselines.
CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
Mar 17, 2023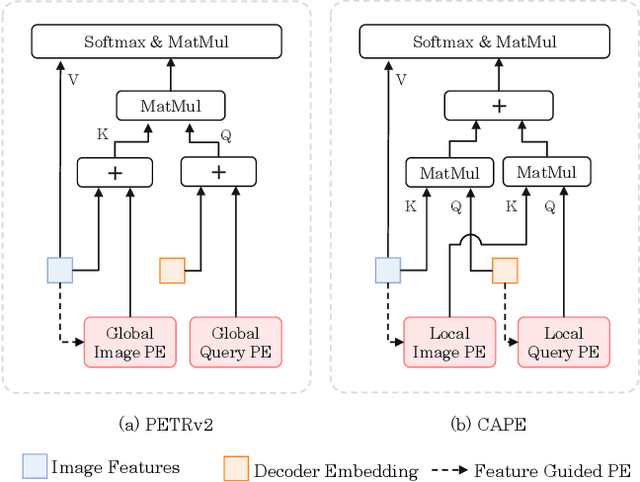
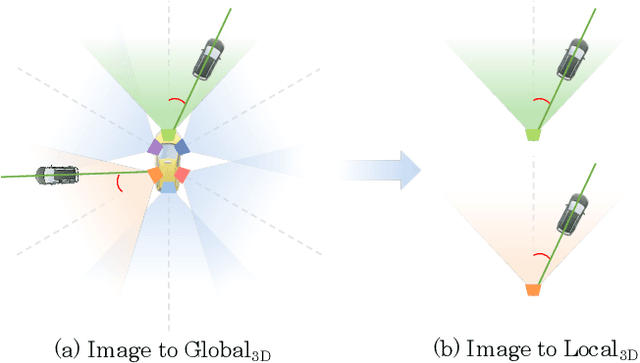
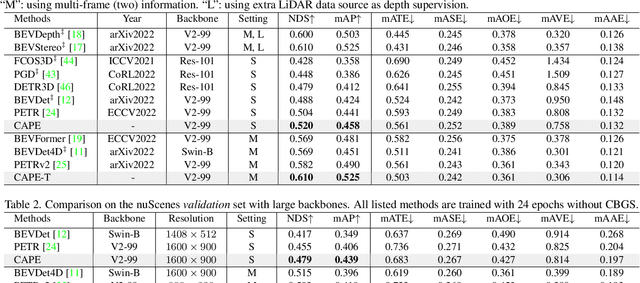
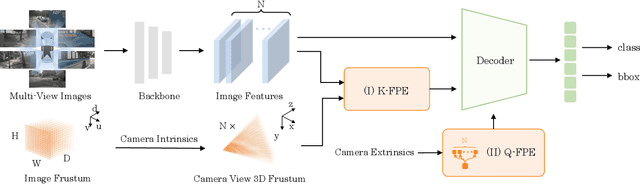
In this paper, we address the problem of detecting 3D objects from multi-view images. Current query-based methods rely on global 3D position embeddings (PE) to learn the geometric correspondence between images and 3D space. We claim that directly interacting 2D image features with global 3D PE could increase the difficulty of learning view transformation due to the variation of camera extrinsics. Thus we propose a novel method based on CAmera view Position Embedding, called CAPE. We form the 3D position embeddings under the local camera-view coordinate system instead of the global coordinate system, such that 3D position embedding is free of encoding camera extrinsic parameters. Furthermore, we extend our CAPE to temporal modeling by exploiting the object queries of previous frames and encoding the ego-motion for boosting 3D object detection. CAPE achieves state-of-the-art performance (61.0% NDS and 52.5% mAP) among all LiDAR-free methods on nuScenes dataset. Codes and models are available on \href{https://github.com/PaddlePaddle/Paddle3D}{Paddle3D} and \href{https://github.com/kaixinbear/CAPE}{PyTorch Implementation}.
Bayesian Metric Learning for Uncertainty Quantification in Image Retrieval
Feb 04, 2023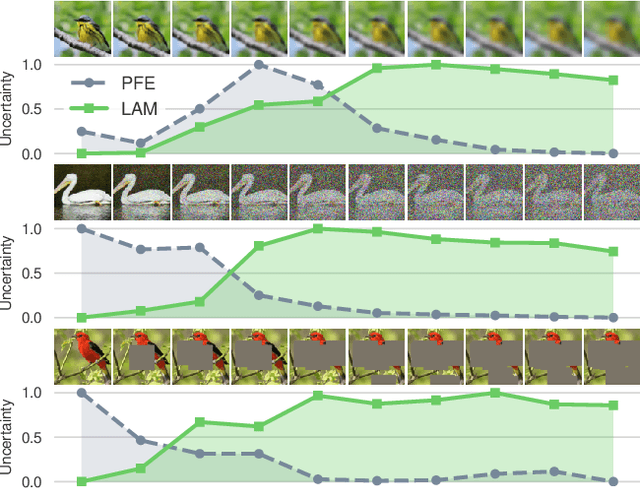
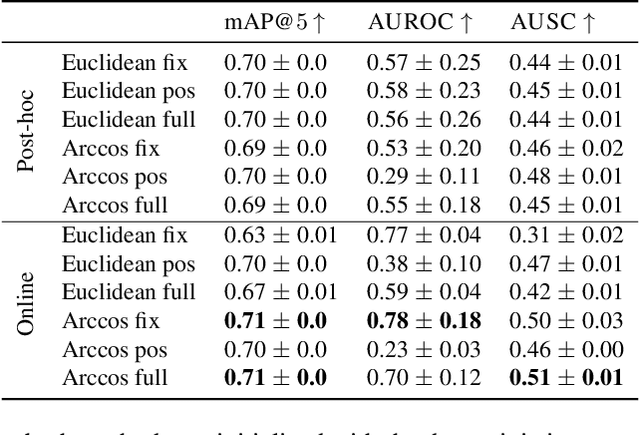

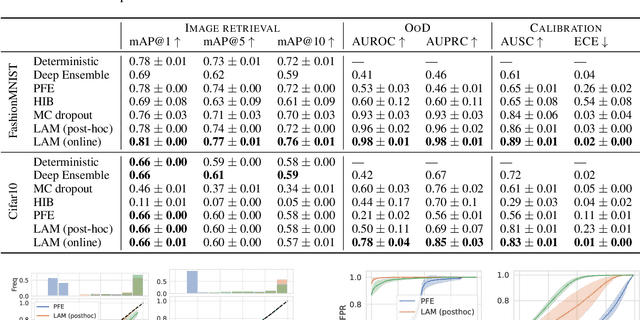
We propose the first Bayesian encoder for metric learning. Rather than relying on neural amortization as done in prior works, we learn a distribution over the network weights with the Laplace Approximation. We actualize this by first proving that the contrastive loss is a valid log-posterior. We then propose three methods that ensure a positive definite Hessian. Lastly, we present a novel decomposition of the Generalized Gauss-Newton approximation. Empirically, we show that our Laplacian Metric Learner (LAM) estimates well-calibrated uncertainties, reliably detects out-of-distribution examples, and yields state-of-the-art predictive performance.
LiT Tuned Models for Efficient Species Detection
Feb 12, 2023
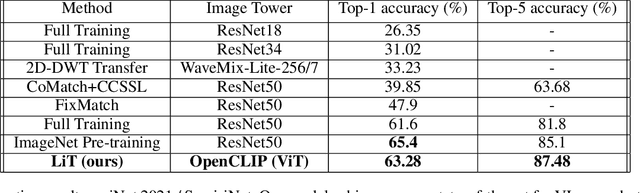
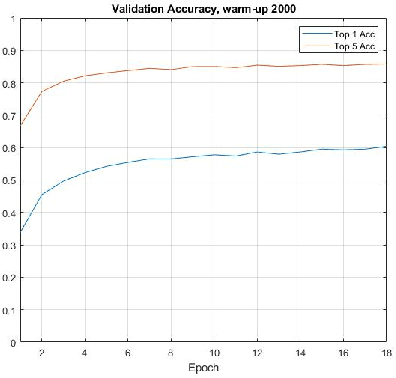
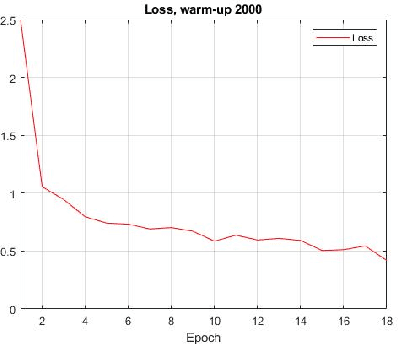
Recent advances in training vision-language models have demonstrated unprecedented robustness and transfer learning effectiveness; however, standard computer vision datasets are image-only, and therefore not well adapted to such training methods. Our paper introduces a simple methodology for adapting any fine-grained image classification dataset for distributed vision-language pretraining. We implement this methodology on the challenging iNaturalist-2021 dataset, comprised of approximately 2.7 million images of macro-organisms across 10,000 classes, and achieve a new state-of-the art model in terms of zero-shot classification accuracy. Somewhat surprisingly, our model (trained using a new method called locked-image text tuning) uses a pre-trained, frozen vision representation, proving that language alignment alone can attain strong transfer learning performance, even on fractious, long-tailed datasets. Our approach opens the door for utilizing high quality vision-language pretrained models in agriculturally relevant applications involving species detection.
ElegantSeg: End-to-End Holistic Learning for Extra-Large Image Semantic Segmentation
Nov 21, 2022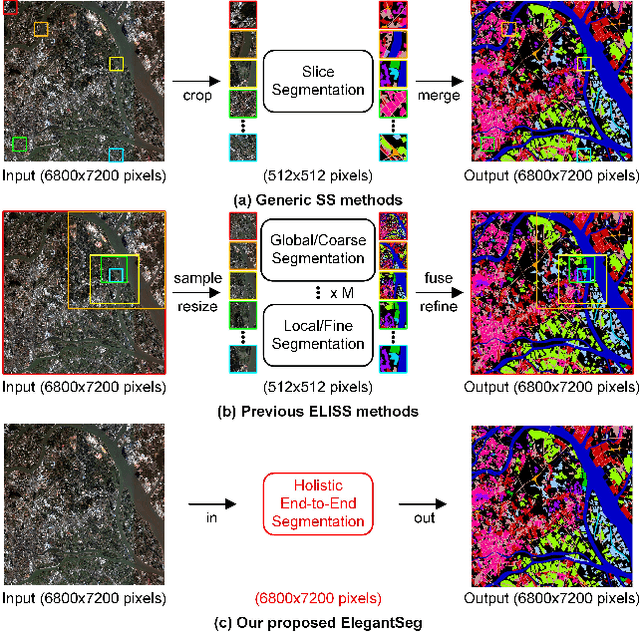
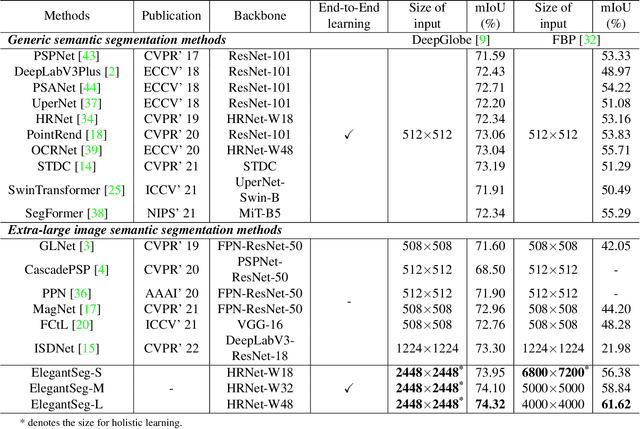


This paper presents a new paradigm for Extra-large image semantic Segmentation, called ElegantSeg, that capably processes holistic extra-large image semantic segmentation (ELISS). The extremely large sizes of extra-large images (ELIs) tend to cause GPU memory exhaustion. To tackle this issue, prevailing works either follow the global-local fusion pipeline or conduct the multi-stage refinement. These methods can only process limited information at one time, and they are not able to thoroughly exploit the abundant information in ELIs. Unlike previous methods, ElegantSeg can elegantly process holistic ELISS by extending the tensor storage from GPU memory to host memory. To the best of our knowledge, it is the first time that ELISS can be performed holistically. Besides, ElegantSeg is specifically designed with three modules to utilize the characteristics of ELIs, including the multiple large kernel module for developing long-range dependency, the efficient class relation module for building holistic contextual relationships, and the boundary-aware enhancement module for obtaining complete object boundaries. ElegantSeg outperforms previous state-of-the-art on two typical ELISS datasets. We hope that ElegantSeg can open a new perspective for ELISS. The code and models will be made publicly available.
Hypernetworks build Implicit Neural Representations of Sounds
Feb 09, 2023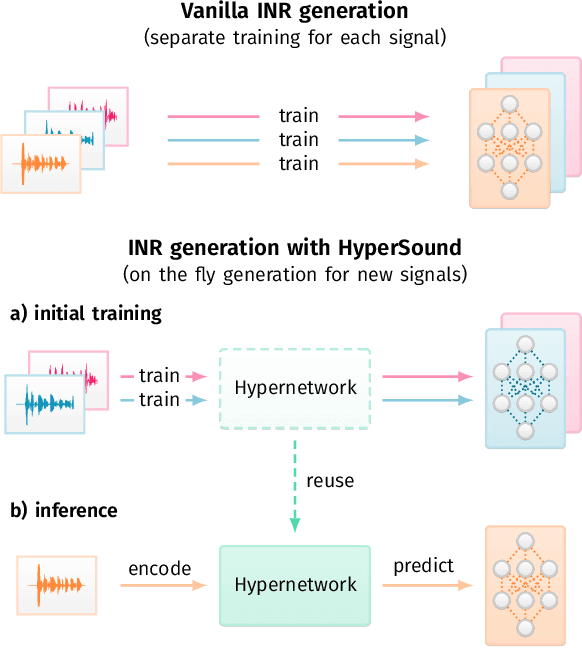

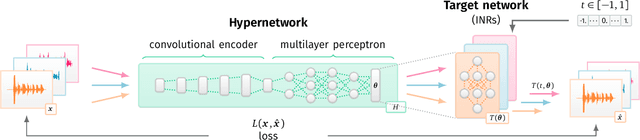
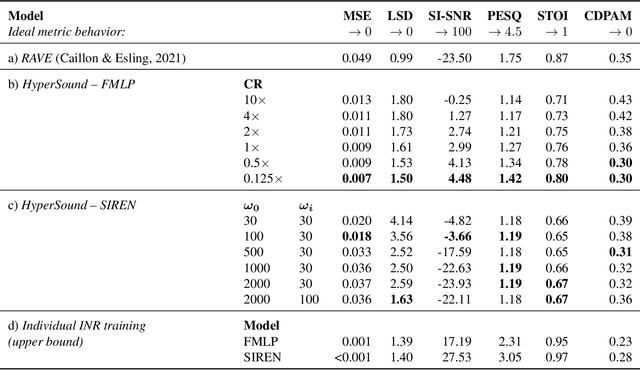
Implicit Neural Representations (INRs) are nowadays used to represent multimedia signals across various real-life applications, including image super-resolution, image compression, or 3D rendering. Existing methods that leverage INRs are predominantly focused on visual data, as their application to other modalities, such as audio, is nontrivial due to the inductive biases present in architectural attributes of image-based INR models. To address this limitation, we introduce HyperSound, the first meta-learning approach to produce INRs for audio samples that leverages hypernetworks to generalize beyond samples observed in training. Our approach reconstructs audio samples with quality comparable to other state-of-the-art models and provides a viable alternative to contemporary sound representations used in deep neural networks for audio processing, such as spectrograms.
Feature Extraction Matters More: Universal Deepfake Disruption through Attacking Ensemble Feature Extractors
Mar 01, 2023
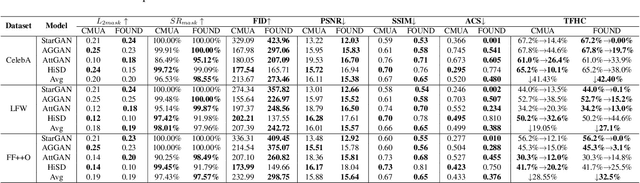
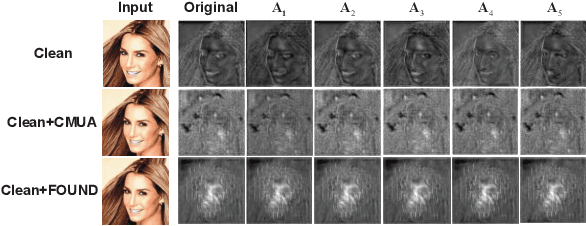

Adversarial example is a rising way of protecting facial privacy security from deepfake modification. To prevent massive facial images from being illegally modified by various deepfake models, it is essential to design a universal deepfake disruptor. However, existing works treat deepfake disruption as an End-to-End process, ignoring the functional difference between feature extraction and image reconstruction, which makes it difficult to generate a cross-model universal disruptor. In this work, we propose a novel Feature-Output ensemble UNiversal Disruptor (FOUND) against deepfake networks, which explores a new opinion that considers attacking feature extractors as the more critical and general task in deepfake disruption. We conduct an effective two-stage disruption process. We first disrupt multi-model feature extractors through multi-feature aggregation and individual-feature maintenance, and then develop a gradient-ensemble algorithm to enhance the disruption effect by simplifying the complex optimization problem of disrupting multiple End-to-End models. Extensive experiments demonstrate that FOUND can significantly boost the disruption effect against ensemble deepfake benchmark models. Besides, our method can fast obtain a cross-attribute, cross-image, and cross-model universal deepfake disruptor with only a few training images, surpassing state-of-the-art universal disruptors in both success rate and efficiency.
A Complementarity-Based Switch-Fuse System for Improved Visual Place Recognition
Mar 01, 2023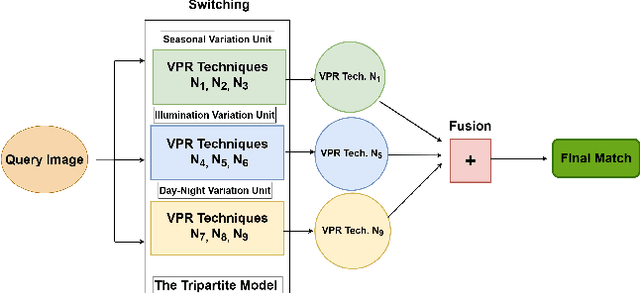
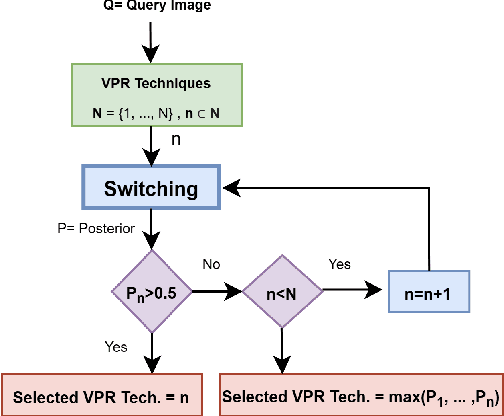
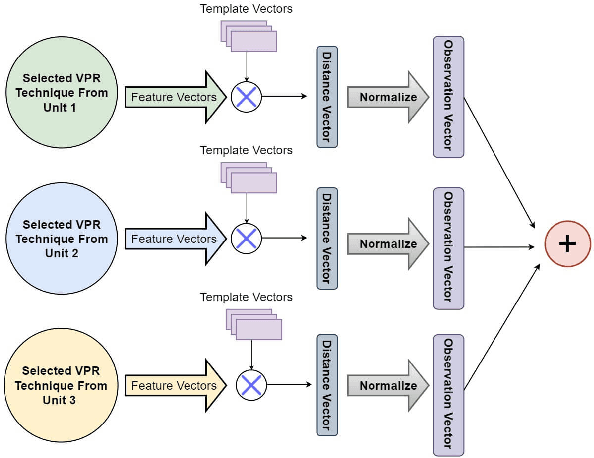

Recently several fusion and switching based approaches have been presented to solve the problem of Visual Place Recognition. In spite of these systems demonstrating significant boost in VPR performance they each have their own set of limitations. The multi-process fusion systems usually involve employing brute force and running all available VPR techniques simultaneously while the switching method attempts to negate this practise by only selecting the best suited VPR technique for given query image. But switching does fail at times when no available suitable technique can be identified. An innovative solution would be an amalgamation of the two otherwise discrete approaches to combine their competitive advantages while negating their shortcomings. The proposed, Switch-Fuse system, is an interesting way to combine both the robustness of switching VPR techniques based on complementarity and the force of fusing the carefully selected techniques to significantly improve performance. Our system holds a structure superior to the basic fusion methods as instead of simply fusing all or any random techniques, it is structured to first select the best possible VPR techniques for fusion, according to the query image. The system combines two significant processes, switching and fusing VPR techniques, which together as a hybrid model substantially improve performance on all major VPR data sets illustrated using PR curves.