 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Binary Noise for Binary Tasks: Masked Bernoulli Diffusion for Unsupervised Anomaly Detection
Mar 18, 2024
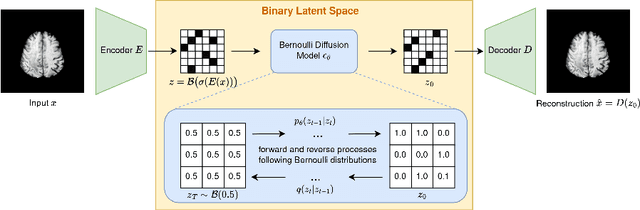
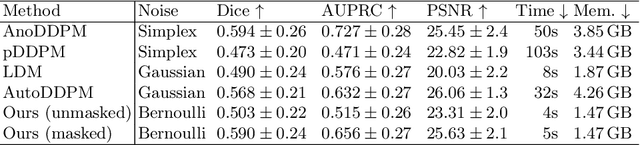
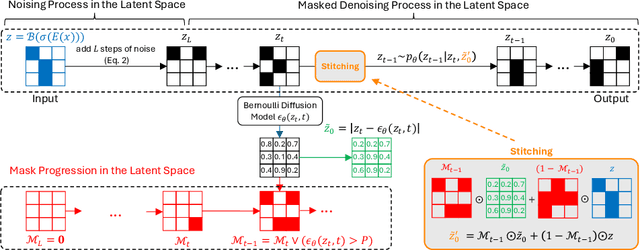
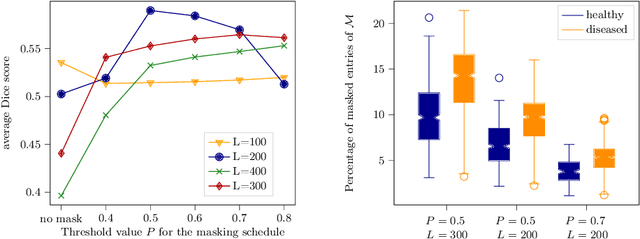
The high performance of denoising diffusion models for image generation has paved the way for their application in unsupervised medical anomaly detection. As diffusion-based methods require a lot of GPU memory and have long sampling times, we present a novel and fast unsupervised anomaly detection approach based on latent Bernoulli diffusion models. We first apply an autoencoder to compress the input images into a binary latent representation. Next, a diffusion model that follows a Bernoulli noise schedule is employed to this latent space and trained to restore binary latent representations from perturbed ones. The binary nature of this diffusion model allows us to identify entries in the latent space that have a high probability of flipping their binary code during the denoising process, which indicates out-of-distribution data. We propose a masking algorithm based on these probabilities, which improves the anomaly detection scores. We achieve state-of-the-art performance compared to other diffusion-based unsupervised anomaly detection algorithms while significantly reducing sampling time and memory consumption. The code is available at https://github.com/JuliaWolleb/Anomaly_berdiff.
LN3Diff: Scalable Latent Neural Fields Diffusion for Speedy 3D Generation
Mar 18, 2024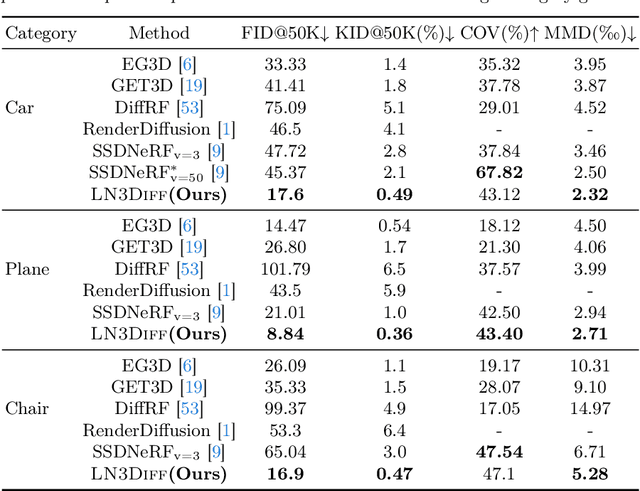
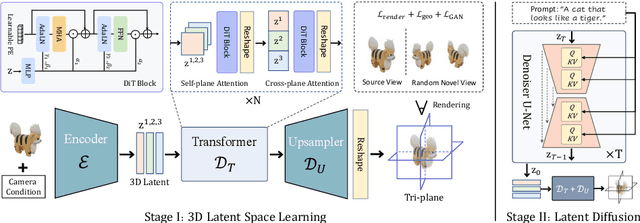

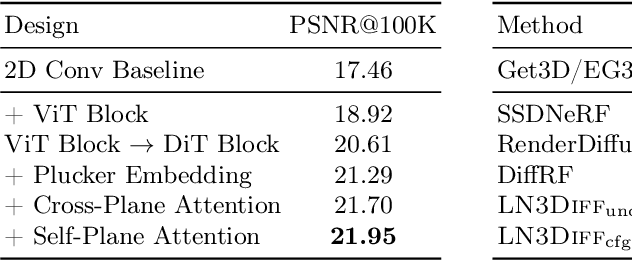
The field of neural rendering has witnessed significant progress with advancements in generative models and differentiable rendering techniques. Though 2D diffusion has achieved success, a unified 3D diffusion pipeline remains unsettled. This paper introduces a novel framework called LN3Diff to address this gap and enable fast, high-quality, and generic conditional 3D generation. Our approach harnesses a 3D-aware architecture and variational autoencoder (VAE) to encode the input image into a structured, compact, and 3D latent space. The latent is decoded by a transformer-based decoder into a high-capacity 3D neural field. Through training a diffusion model on this 3D-aware latent space, our method achieves state-of-the-art performance on ShapeNet for 3D generation and demonstrates superior performance in monocular 3D reconstruction and conditional 3D generation across various datasets. Moreover, it surpasses existing 3D diffusion methods in terms of inference speed, requiring no per-instance optimization. Our proposed LN3Diff presents a significant advancement in 3D generative modeling and holds promise for various applications in 3D vision and graphics tasks.
VFusion3D: Learning Scalable 3D Generative Models from Video Diffusion Models
Mar 18, 2024
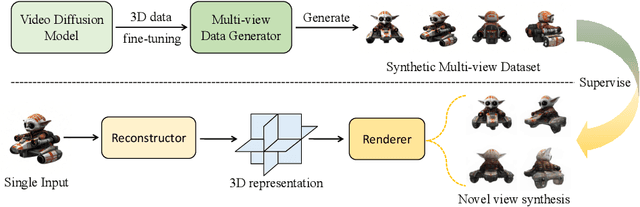
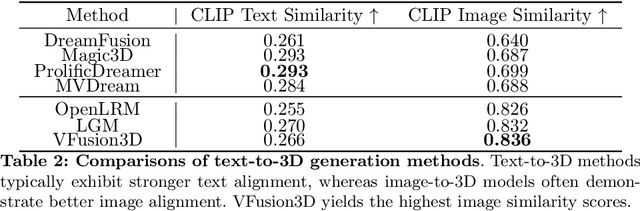

This paper presents a novel paradigm for building scalable 3D generative models utilizing pre-trained video diffusion models. The primary obstacle in developing foundation 3D generative models is the limited availability of 3D data. Unlike images, texts, or videos, 3D data are not readily accessible and are difficult to acquire. This results in a significant disparity in scale compared to the vast quantities of other types of data. To address this issue, we propose using a video diffusion model, trained with extensive volumes of text, images, and videos, as a knowledge source for 3D data. By unlocking its multi-view generative capabilities through fine-tuning, we generate a large-scale synthetic multi-view dataset to train a feed-forward 3D generative model. The proposed model, VFusion3D, trained on nearly 3M synthetic multi-view data, can generate a 3D asset from a single image in seconds and achieves superior performance when compared to current SOTA feed-forward 3D generative models, with users preferring our results over 70% of the time.
Sub-photon accuracy noise reduction of single shot coherent diffraction pattern with atomic model trained autoencoder
Mar 18, 2024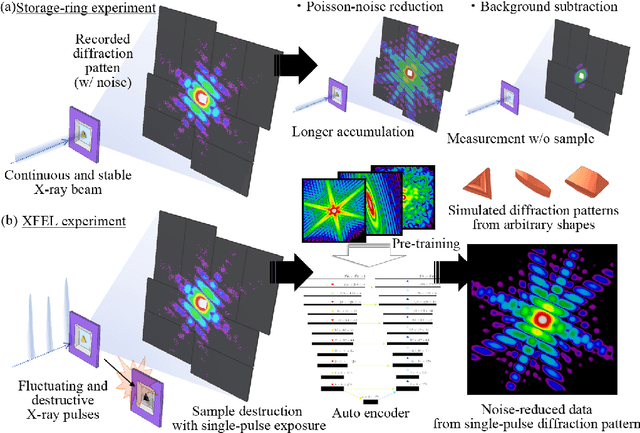
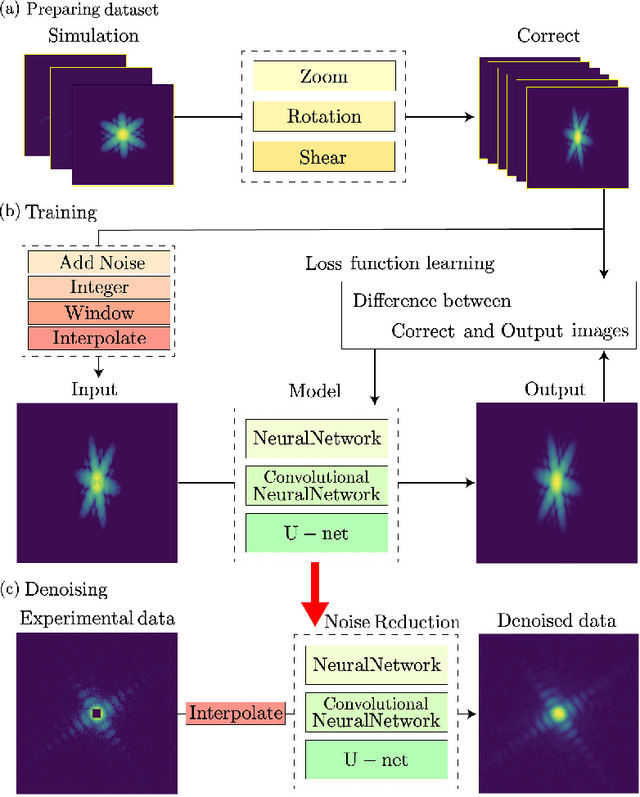
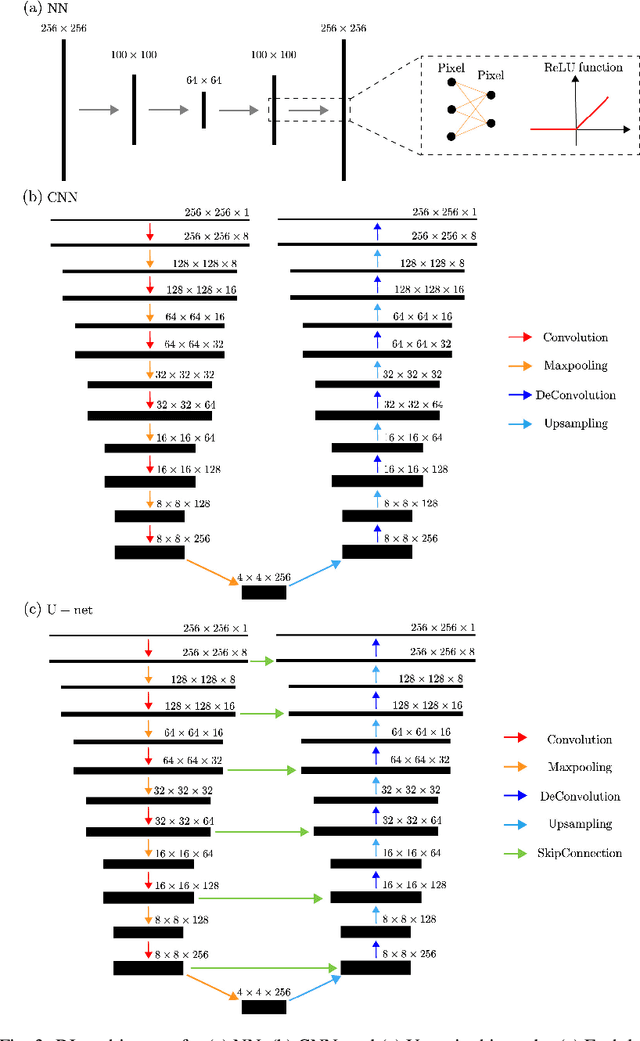
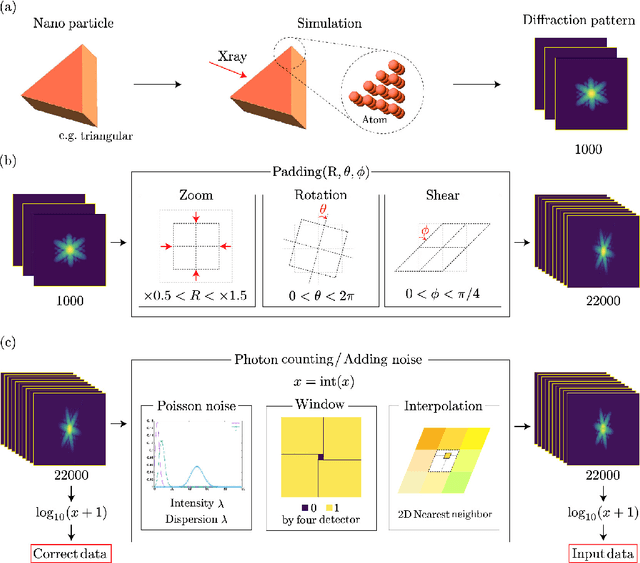
Single-shot imaging with femtosecond X-ray lasers is a powerful measurement technique that can achieve both high spatial and temporal resolution. However, its accuracy has been severely limited by the difficulty of applying conventional noise-reduction processing. This study uses deep learning to validate noise reduction techniques, with autoencoders serving as the learning model. Focusing on the diffraction patterns of nanoparticles, we simulated a large dataset treating the nanoparticles as composed of many independent atoms. Three neural network architectures are investigated: neural network, convolutional neural network and U-net, with U-net showing superior performance in noise reduction and subphoton reproduction. We also extended our models to apply to diffraction patterns of particle shapes different from those in the simulated data. We then applied the U-net model to a coherent diffractive imaging study, wherein a nanoparticle in a microfluidic device is exposed to a single X-ray free-electron laser pulse. After noise reduction, the reconstructed nanoparticle image improved significantly even though the nanoparticle shape was different from the training data, highlighting the importance of transfer learning.
Dynamic Tuning Towards Parameter and Inference Efficiency for ViT Adaptation
Mar 18, 2024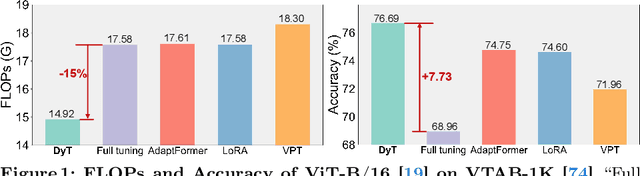

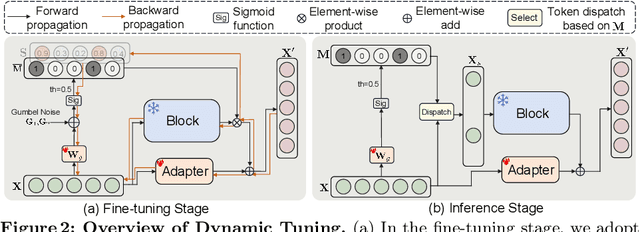

Existing parameter-efficient fine-tuning (PEFT) methods have achieved significant success on vision transformers (ViTs) adaptation by improving parameter efficiency. However, the exploration of enhancing inference efficiency during adaptation remains underexplored. This limits the broader application of pre-trained ViT models, especially when the model is computationally extensive. In this paper, we propose Dynamic Tuning (DyT), a novel approach to improve both parameter and inference efficiency for ViT adaptation. Specifically, besides using the lightweight adapter modules, we propose a token dispatcher to distinguish informative tokens from less important ones, allowing the latter to dynamically skip the original block, thereby reducing the redundant computation during inference. Additionally, we explore multiple design variants to find the best practice of DyT. Finally, inspired by the mixture-of-experts (MoE) mechanism, we introduce an enhanced adapter to further boost the adaptation performance. We validate DyT across various tasks, including image/video recognition and semantic segmentation. For instance, DyT achieves comparable or even superior performance compared to existing PEFT methods while evoking only 71%-85% of their FLOPs on the VTAB-1K benchmark.
Fed3DGS: Scalable 3D Gaussian Splatting with Federated Learning
Mar 18, 2024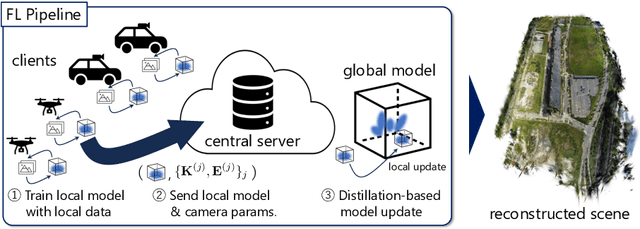
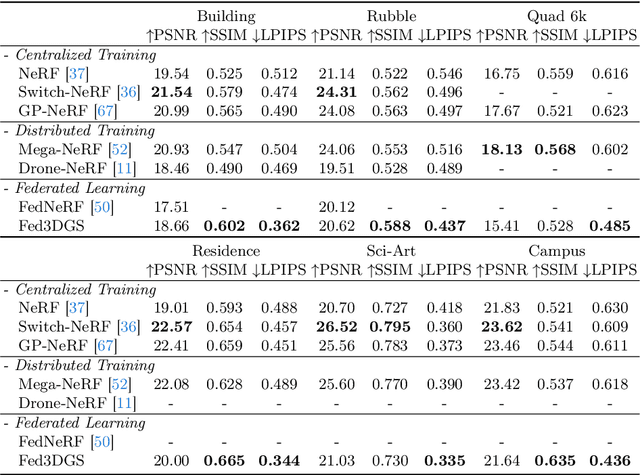
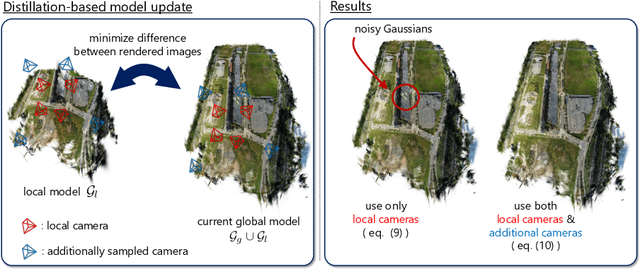

In this work, we present Fed3DGS, a scalable 3D reconstruction framework based on 3D Gaussian splatting (3DGS) with federated learning. Existing city-scale reconstruction methods typically adopt a centralized approach, which gathers all data in a central server and reconstructs scenes. The approach hampers scalability because it places a heavy load on the server and demands extensive data storage when reconstructing scenes on a scale beyond city-scale. In pursuit of a more scalable 3D reconstruction, we propose a federated learning framework with 3DGS, which is a decentralized framework and can potentially use distributed computational resources across millions of clients. We tailor a distillation-based model update scheme for 3DGS and introduce appearance modeling for handling non-IID data in the scenario of 3D reconstruction with federated learning. We simulate our method on several large-scale benchmarks, and our method demonstrates rendered image quality comparable to centralized approaches. In addition, we also simulate our method with data collected in different seasons, demonstrating that our framework can reflect changes in the scenes and our appearance modeling captures changes due to seasonal variations.
DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations
Mar 12, 2024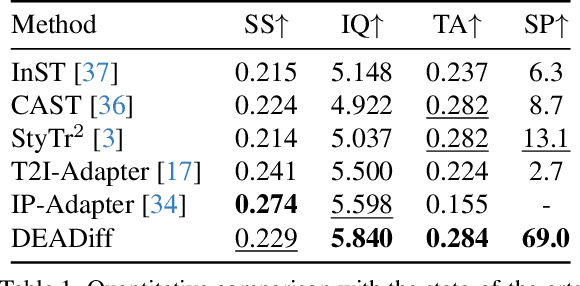
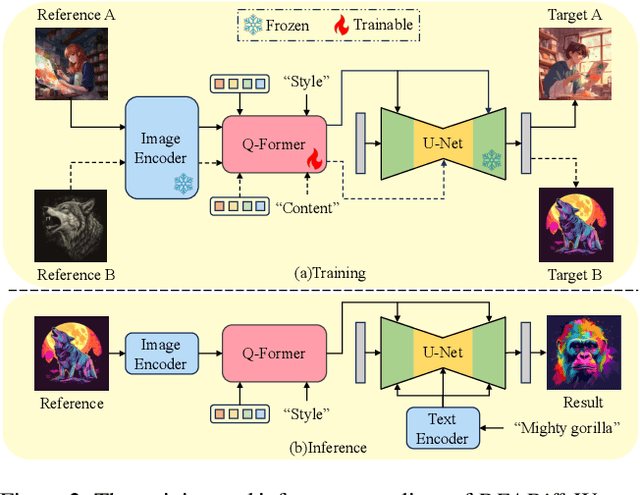
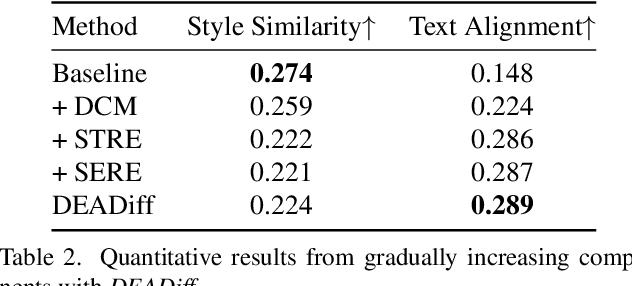
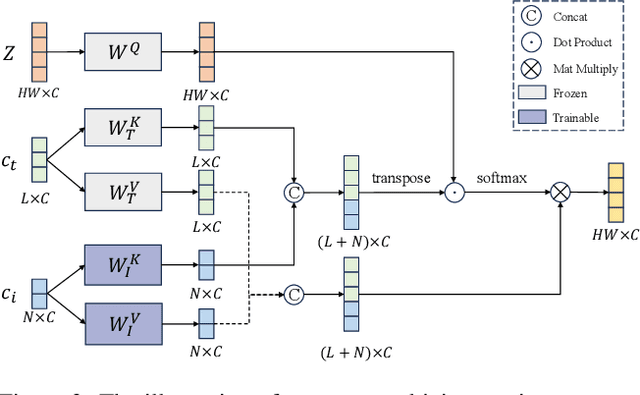
The diffusion-based text-to-image model harbors immense potential in transferring reference style. However, current encoder-based approaches significantly impair the text controllability of text-to-image models while transferring styles. In this paper, we introduce DEADiff to address this issue using the following two strategies: 1) a mechanism to decouple the style and semantics of reference images. The decoupled feature representations are first extracted by Q-Formers which are instructed by different text descriptions. Then they are injected into mutually exclusive subsets of cross-attention layers for better disentanglement. 2) A non-reconstructive learning method. The Q-Formers are trained using paired images rather than the identical target, in which the reference image and the ground-truth image are with the same style or semantics. We show that DEADiff attains the best visual stylization results and optimal balance between the text controllability inherent in the text-to-image model and style similarity to the reference image, as demonstrated both quantitatively and qualitatively. Our project page is https://tianhao-qi.github.io/DEADiff/.
Learning Dual-Level Deformable Implicit Representation for Real-World Scale Arbitrary Super-Resolution
Mar 16, 2024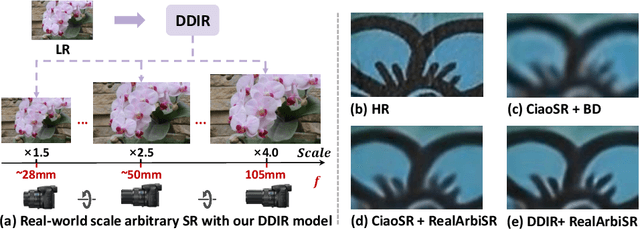
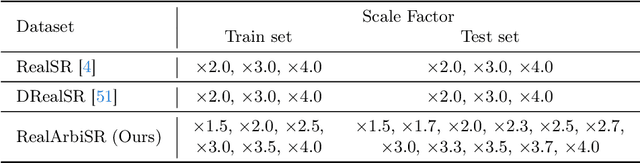

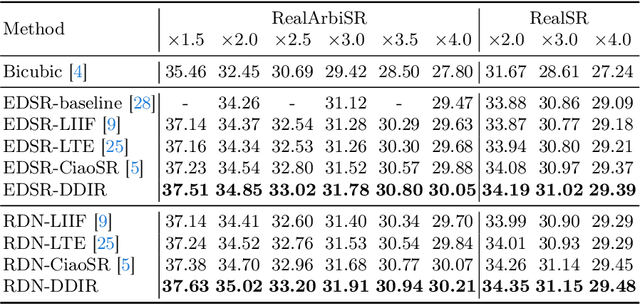
Scale arbitrary super-resolution based on implicit image function gains increasing popularity since it can better represent the visual world in a continuous manner. However, existing scale arbitrary works are trained and evaluated on simulated datasets, where low-resolution images are generated from their ground truths by the simplest bicubic downsampling. These models exhibit limited generalization to real-world scenarios due to the greater complexity of real-world degradations. To address this issue, we build a RealArbiSR dataset, a new real-world super-resolution benchmark with both integer and non-integer scaling factors for the training and evaluation of real-world scale arbitrary super-resolution. Moreover, we propose a Dual-level Deformable Implicit Representation (DDIR) to solve real-world scale arbitrary super-resolution. Specifically, we design the appearance embedding and deformation field to handle both image-level and pixel-level deformations caused by real-world degradations. The appearance embedding models the characteristics of low-resolution inputs to deal with photometric variations at different scales, and the pixel-based deformation field learns RGB differences which result from the deviations between the real-world and simulated degradations at arbitrary coordinates. Extensive experiments show our trained model achieves state-of-the-art performance on the RealArbiSR and RealSR benchmarks for real-world scale arbitrary super-resolution. Our dataset as well as source code will be publicly available.
Ambient Diffusion Posterior Sampling: Solving Inverse Problems with Diffusion Models trained on Corrupted Data
Mar 13, 2024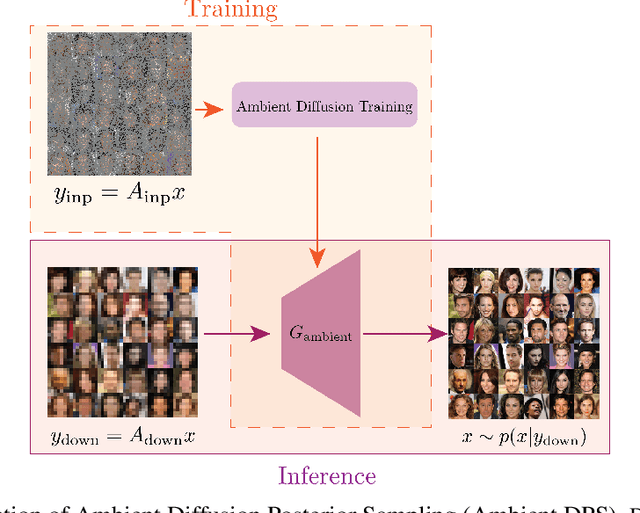
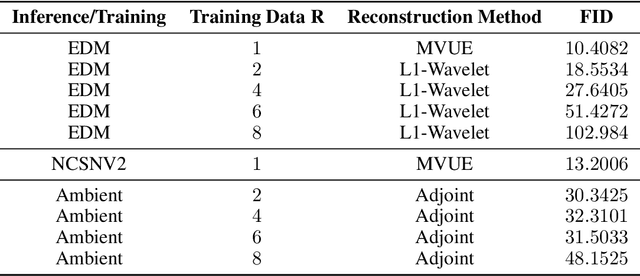
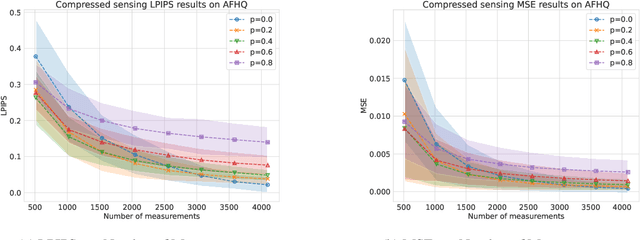
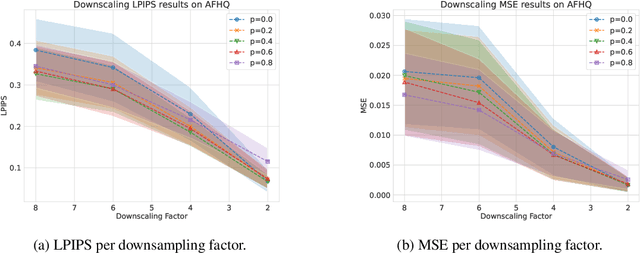
We provide a framework for solving inverse problems with diffusion models learned from linearly corrupted data. Our method, Ambient Diffusion Posterior Sampling (A-DPS), leverages a generative model pre-trained on one type of corruption (e.g. image inpainting) to perform posterior sampling conditioned on measurements from a potentially different forward process (e.g. image blurring). We test the efficacy of our approach on standard natural image datasets (CelebA, FFHQ, and AFHQ) and we show that A-DPS can sometimes outperform models trained on clean data for several image restoration tasks in both speed and performance. We further extend the Ambient Diffusion framework to train MRI models with access only to Fourier subsampled multi-coil MRI measurements at various acceleration factors (R=2, 4, 6, 8). We again observe that models trained on highly subsampled data are better priors for solving inverse problems in the high acceleration regime than models trained on fully sampled data. We open-source our code and the trained Ambient Diffusion MRI models: https://github.com/utcsilab/ambient-diffusion-mri .
Diffusion and Multi-Domain Adaptation Methods for Eosinophil Segmentation
Mar 17, 2024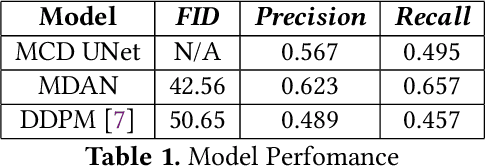
Eosinophilic Esophagitis (EoE) represents a challenging condition for medical providers today. The cause is currently unknown, the impact on a patient's daily life is significant, and it is increasing in prevalence. Traditional approaches for medical image diagnosis such as standard deep learning algorithms are limited by the relatively small amount of data and difficulty in generalization. As a response, two methods have arisen that seem to perform well: Diffusion and Multi-Domain methods with current research efforts favoring diffusion methods. For the EoE dataset, we discovered that a Multi-Domain Adversarial Network outperformed a Diffusion based method with a FID of 42.56 compared to 50.65. Future work with diffusion methods should include a comparison with Multi-Domain adaptation methods to ensure that the best performance is achieved.