 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unproportional mosaicing
Mar 06, 2023

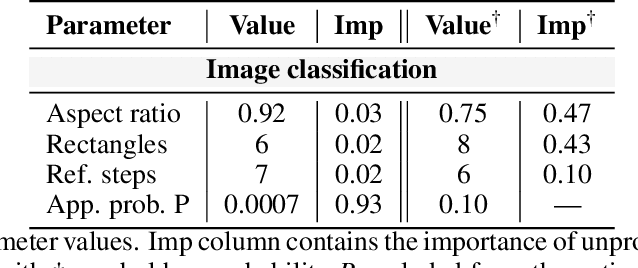

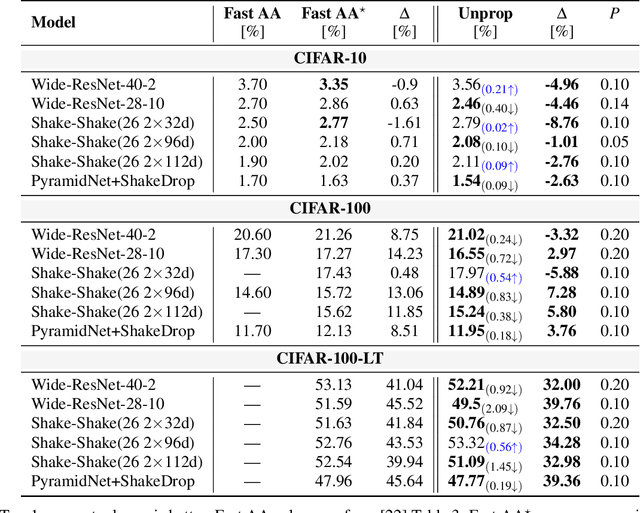
Data shift is a gap between data distribution used for training and data distribution encountered in the real-world. Data augmentations help narrow the gap by generating new data samples, increasing data variability, and data space coverage. We present a new data augmentation: Unproportional mosaicing (Unprop). Our augmentation randomly splits an image into various-sized blocks and swaps its content (pixels) while maintaining block sizes. Our method achieves a lower error rate when combined with other state-of-the-art augmentations.
Semantic-aware Texture-Structure Feature Collaboration for Underwater Image Enhancement
Nov 19, 2022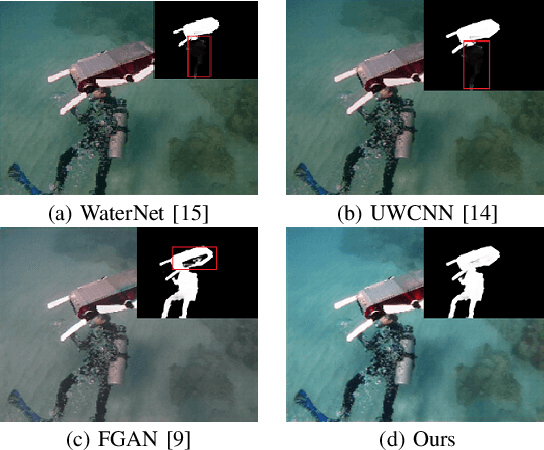
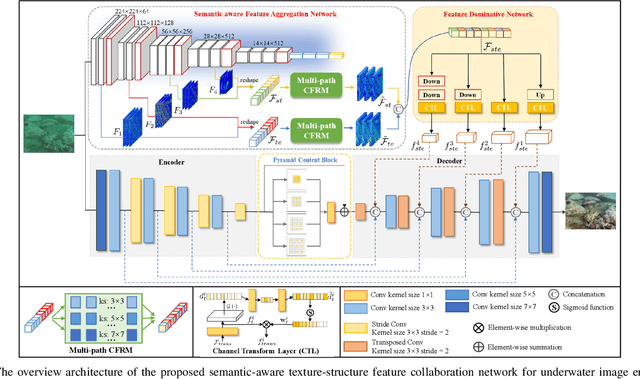
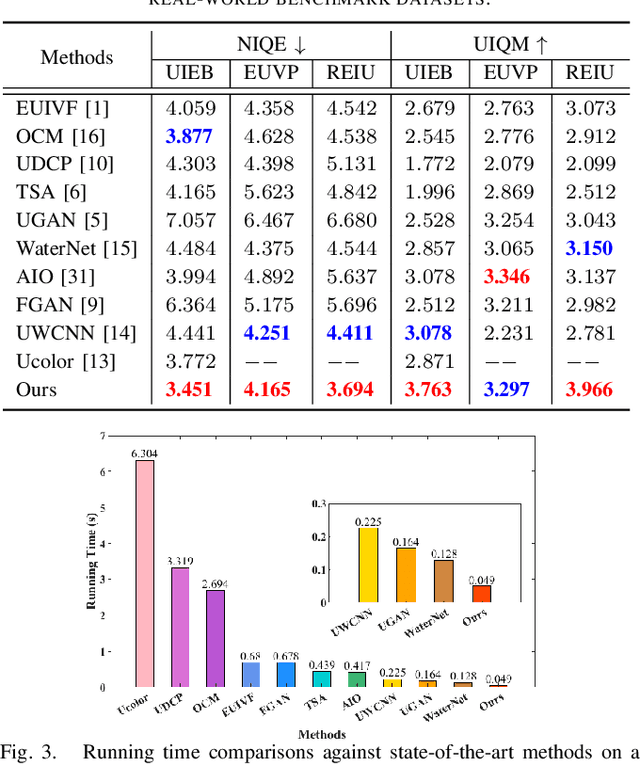

Underwater image enhancement has become an attractive topic as a significant technology in marine engineering and aquatic robotics. However, the limited number of datasets and imperfect hand-crafted ground truth weaken its robustness to unseen scenarios, and hamper the application to high-level vision tasks. To address the above limitations, we develop an efficient and compact enhancement network in collaboration with a high-level semantic-aware pretrained model, aiming to exploit its hierarchical feature representation as an auxiliary for the low-level underwater image enhancement. Specifically, we tend to characterize the shallow layer features as textures while the deep layer features as structures in the semantic-aware model, and propose a multi-path Contextual Feature Refinement Module (CFRM) to refine features in multiple scales and model the correlation between different features. In addition, a feature dominative network is devised to perform channel-wise modulation on the aggregated texture and structure features for the adaptation to different feature patterns of the enhancement network. Extensive experiments on benchmarks demonstrate that the proposed algorithm achieves more appealing results and outperforms state-of-the-art methods by large margins. We also apply the proposed algorithm to the underwater salient object detection task to reveal the favorable semantic-aware ability for high-level vision tasks. The code is available at STSC.
Whole-slide-imaging Cancer Metastases Detection and Localization with Limited Tumorous Data
Mar 18, 2023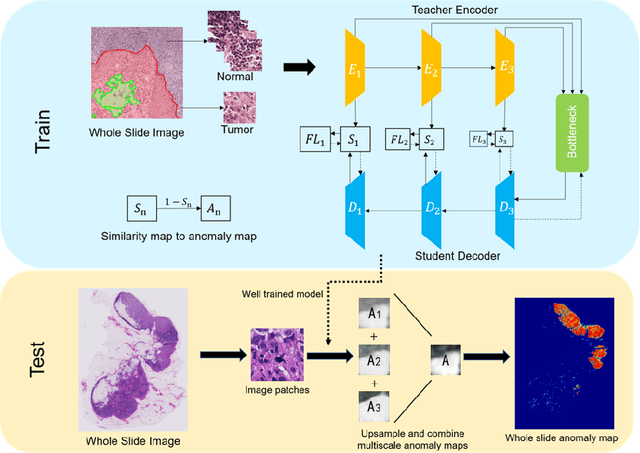
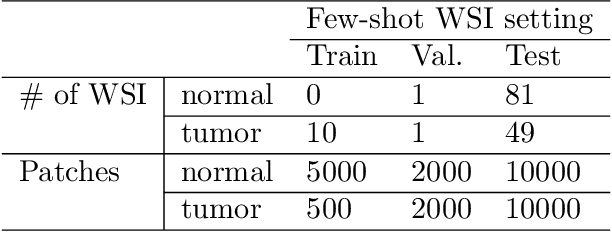

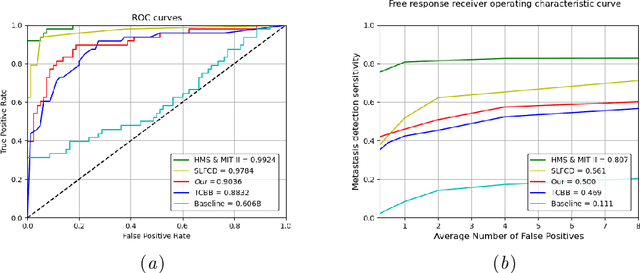
Recently, various deep learning methods have shown significant successes in medical image analysis, especially in the detection of cancer metastases in hematoxylin and eosin (H&E) stained whole-slide images (WSIs). However, in order to obtain good performance, these research achievements rely on hundreds of well-annotated WSIs. In this study, we tackle the tumor localization and detection problem under the setting of few labeled whole slide images and introduce a patch-based analysis pipeline based on the latest reverse knowledge distillation architecture. To address the extremely unbalanced normal and tumorous samples in training sample collection, we applied the focal loss formula to the representation similarity metric for model optimization. Compared with prior arts, our method achieves similar performance by less than ten percent of training samples on the public Camelyon16 dataset. In addition, this is the first work that show the great potential of the knowledge distillation models in computational histopathology.
LossMix: Simplify and Generalize Mixup for Object Detection and Beyond
Mar 18, 2023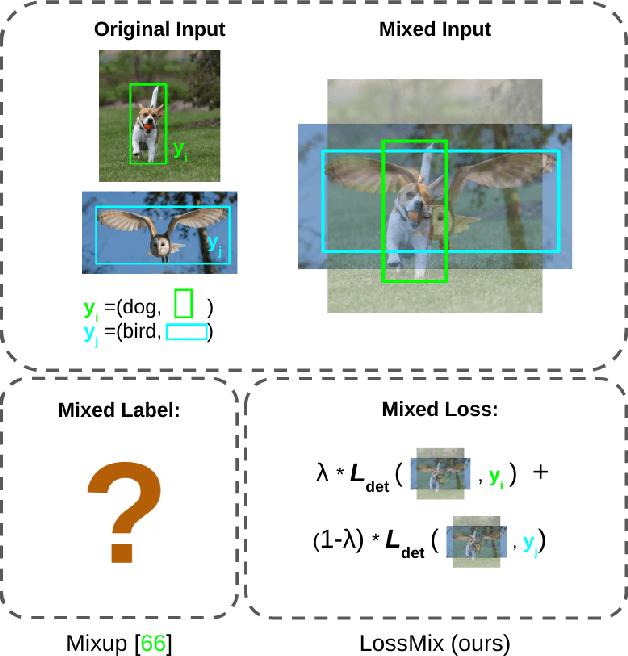
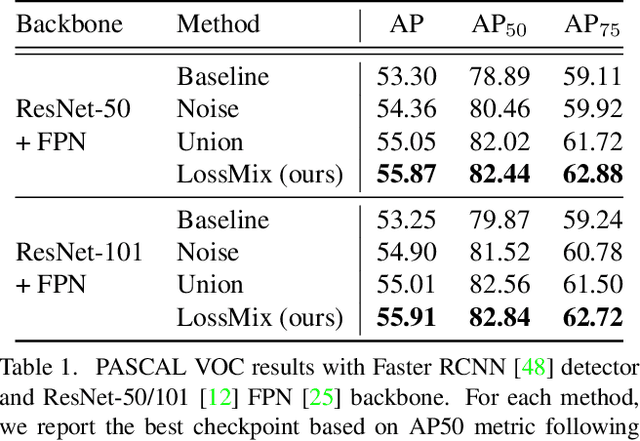
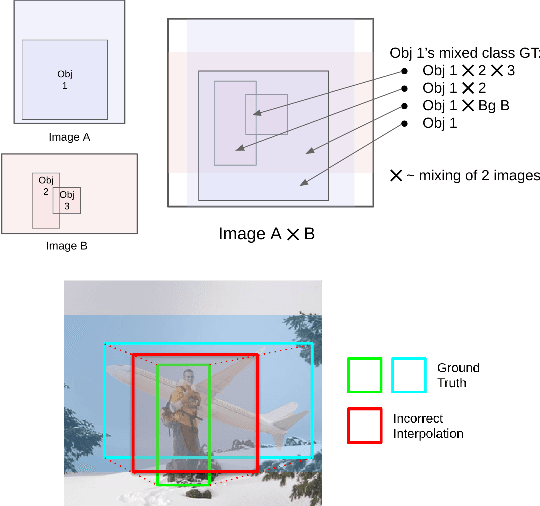
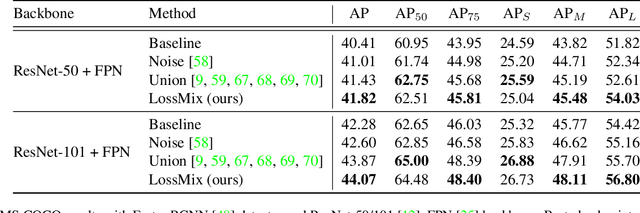
The success of data mixing augmentations in image classification tasks has been well-received. However, these techniques cannot be readily applied to object detection due to challenges such as spatial misalignment, foreground/background distinction, and plurality of instances. To tackle these issues, we first introduce a novel conceptual framework called Supervision Interpolation, which offers a fresh perspective on interpolation-based augmentations by relaxing and generalizing Mixup. Building on this framework, we propose LossMix, a simple yet versatile and effective regularization that enhances the performance and robustness of object detectors and more. Our key insight is that we can effectively regularize the training on mixed data by interpolating their loss errors instead of ground truth labels. Empirical results on the PASCAL VOC and MS COCO datasets demonstrate that LossMix consistently outperforms currently popular mixing strategies. Furthermore, we design a two-stage domain mixing method that leverages LossMix to surpass Adaptive Teacher (CVPR 2022) and set a new state of the art for unsupervised domain adaptation.
CFNet: Conditional Filter Learning with Dynamic Noise Estimation for Real Image Denoising
Nov 26, 2022
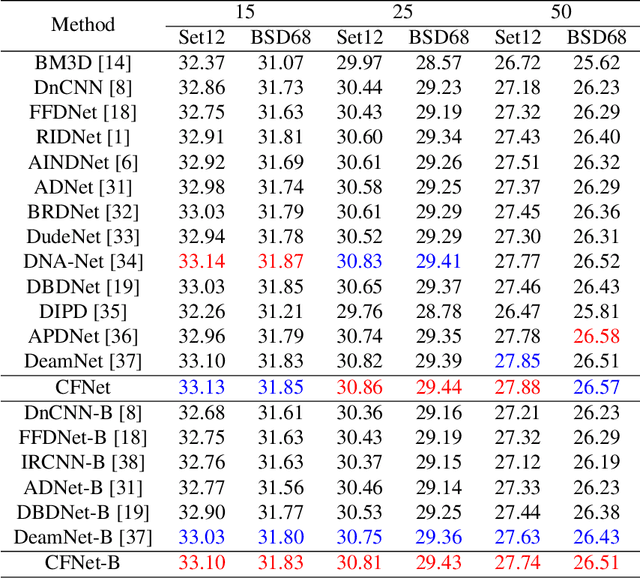
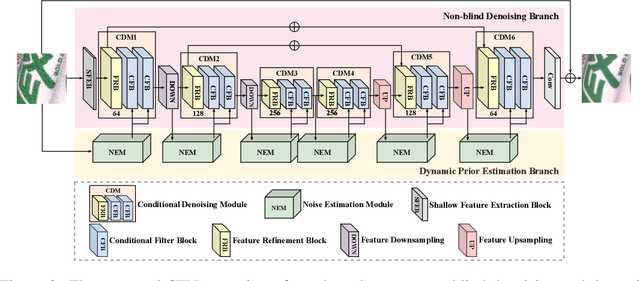
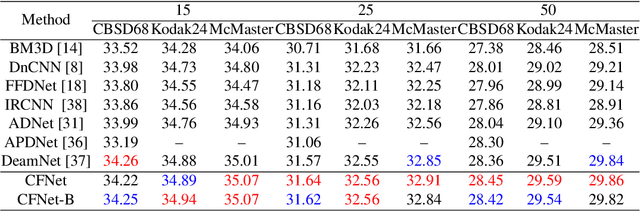
A mainstream type of the state of the arts (SOTAs) based on convolutional neural network (CNN) for real image denoising contains two sub-problems, i.e., noise estimation and non-blind denoising. This paper considers real noise approximated by heteroscedastic Gaussian/Poisson Gaussian distributions with in-camera signal processing pipelines. The related works always exploit the estimated noise prior via channel-wise concatenation followed by a convolutional layer with spatially sharing kernels. Due to the variable modes of noise strength and frequency details of all feature positions, this design cannot adaptively tune the corresponding denoising patterns. To address this problem, we propose a novel conditional filter in which the optimal kernels for different feature positions can be adaptively inferred by local features from the image and the noise map. Also, we bring the thought that alternatively performs noise estimation and non-blind denoising into CNN structure, which continuously updates noise prior to guide the iterative feature denoising. In addition, according to the property of heteroscedastic Gaussian distribution, a novel affine transform block is designed to predict the stationary noise component and the signal-dependent noise component. Compared with SOTAs, extensive experiments are conducted on five synthetic datasets and three real datasets, which shows the improvement of the proposed CFNet.
FAME-ViL: Multi-Tasking Vision-Language Model for Heterogeneous Fashion Tasks
Mar 04, 2023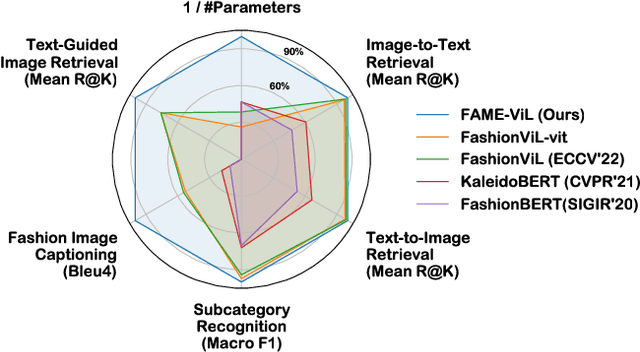
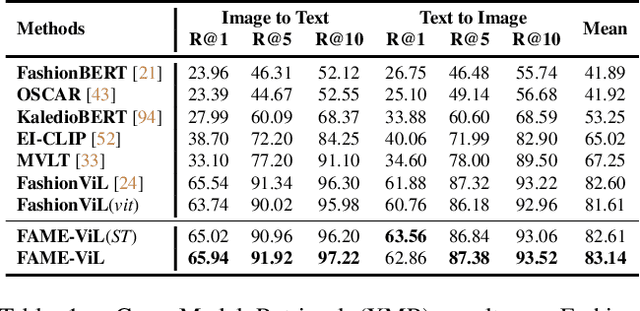

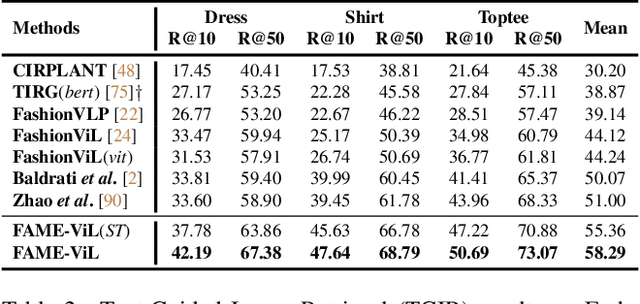
In the fashion domain, there exists a variety of vision-and-language (V+L) tasks, including cross-modal retrieval, text-guided image retrieval, multi-modal classification, and image captioning. They differ drastically in each individual input/output format and dataset size. It has been common to design a task-specific model and fine-tune it independently from a pre-trained V+L model (e.g., CLIP). This results in parameter inefficiency and inability to exploit inter-task relatedness. To address such issues, we propose a novel FAshion-focused Multi-task Efficient learning method for Vision-and-Language tasks (FAME-ViL) in this work. Compared with existing approaches, FAME-ViL applies a single model for multiple heterogeneous fashion tasks, therefore being much more parameter-efficient. It is enabled by two novel components: (1) a task-versatile architecture with cross-attention adapters and task-specific adapters integrated into a unified V+L model, and (2) a stable and effective multi-task training strategy that supports learning from heterogeneous data and prevents negative transfer. Extensive experiments on four fashion tasks show that our FAME-ViL can save 61.5% of parameters over alternatives, while significantly outperforming the conventional independently trained single-task models. Code is available at https://github.com/BrandonHanx/FAME-ViL.
CHiLS: Zero-Shot Image Classification with Hierarchical Label Sets
Feb 07, 2023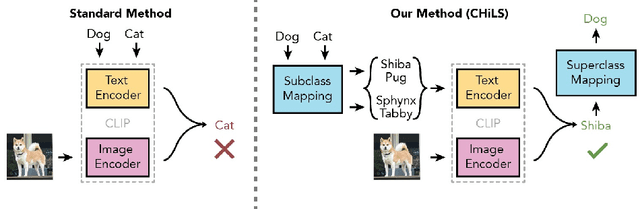
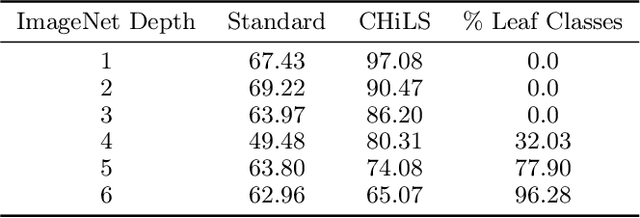

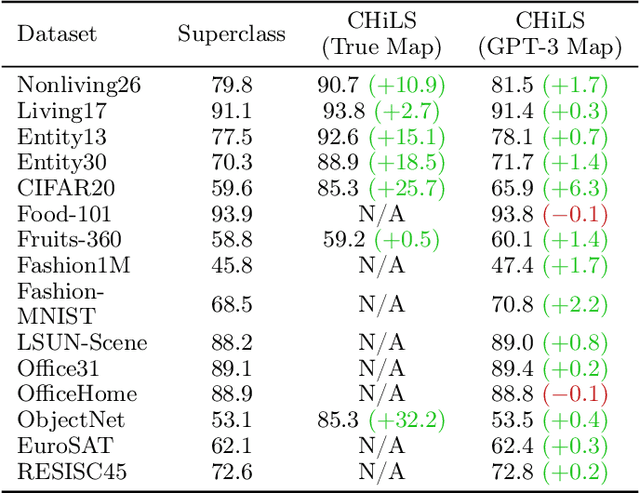
Open vocabulary models (e.g. CLIP) have shown strong performance on zero-shot classification through their ability generate embeddings for each class based on their (natural language) names. Prior work has focused on improving the accuracy of these models through prompt engineering or by incorporating a small amount of labeled downstream data (via finetuning). However, there has been little focus on improving the richness of the class names themselves, which can pose issues when class labels are coarsely-defined and uninformative. We propose Classification with Hierarchical Label Sets (or CHiLS), an alternative strategy for zero-shot classification specifically designed for datasets with implicit semantic hierarchies. CHiLS proceeds in three steps: (i) for each class, produce a set of subclasses, using either existing label hierarchies or by querying GPT-3; (ii) perform the standard zero-shot CLIP procedure as though these subclasses were the labels of interest; (iii) map the predicted subclass back to its parent to produce the final prediction. Across numerous datasets with underlying hierarchical structure, CHiLS leads to improved accuracy in situations both with and without ground-truth hierarchical information. CHiLS is simple to implement within existing CLIP pipelines and requires no additional training cost. Code is available at: https://github.com/acmi-lab/CHILS.
Empirical Assessment of End-to-End Iris Recognition System Capacity
Mar 20, 2023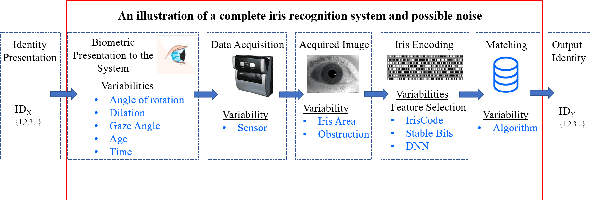
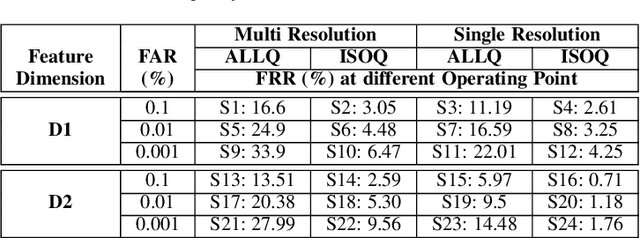
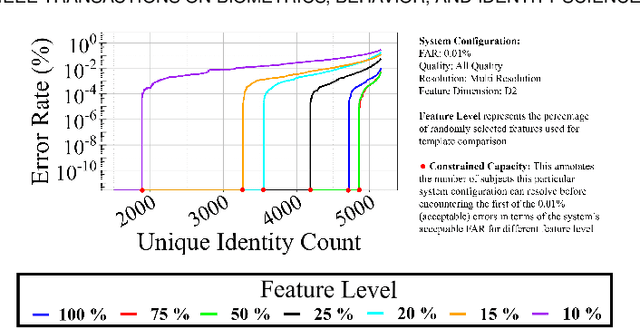
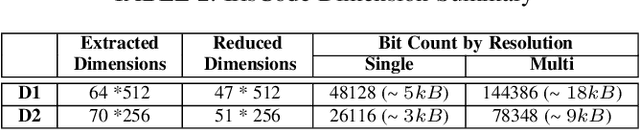
Iris is an established modality in biometric recognition applications including consumer electronics, e-commerce, border security, forensics, and de-duplication of identity at a national scale. In light of the expanding usage of biometric recognition, identity clash (when templates from two different people match) is an imperative factor of consideration for a system's deployment. This study explores system capacity estimation by empirically estimating the constrained capacity of an end-to-end iris recognition system (NIR systems with Daugman-based feature extraction) operating at an acceptable error rate i.e. the number of subjects a system can resolve before encountering an error. We study the impact of six system parameters on an iris recognition system's constrained capacity -- number of enrolled identities, image quality, template dimension, random feature elimination, filter resolution, and system operating point. In our assessment, we analyzed 13.2 million comparisons from 5158 unique identities for each of 24 different system configurations. This work provides a framework to better understand iris recognition system capacity as a function of biometric system configurations beyond the operating point, for large-scale applications.
A closer look at the training dynamics of knowledge distillation
Mar 20, 2023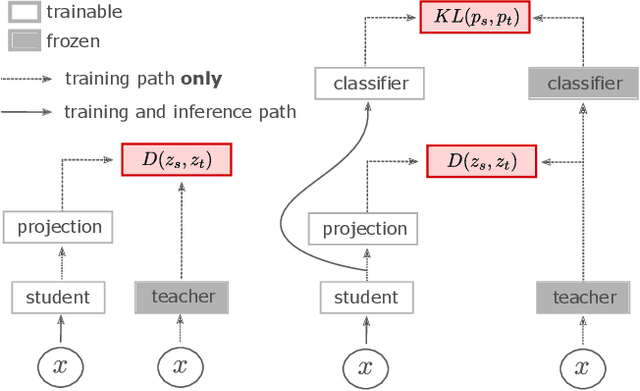
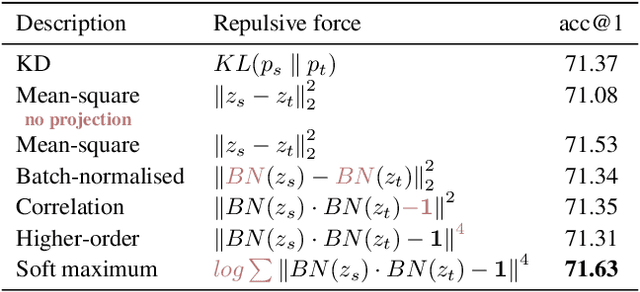
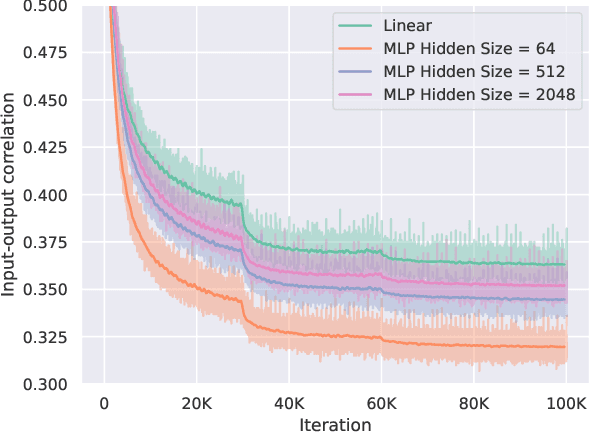

In this paper we revisit the efficacy of knowledge distillation as a function matching and metric learning problem. In doing so we verify three important design decisions, namely the normalisation, soft maximum function, and projection layers as key ingredients. We theoretically show that the projector implicitly encodes information on past examples, enabling relational gradients for the student. We then show that the normalisation of representations is tightly coupled with the training dynamics of this projector, which can have a large impact on the students performance. Finally, we show that a simple soft maximum function can be used to address any significant capacity gap problems. Experimental results on various benchmark datasets demonstrate that using these insights can lead to superior or comparable performance to state-of-the-art knowledge distillation techniques, despite being much more computationally efficient. In particular, we obtain these results across image classification (CIFAR100 and ImageNet), object detection (COCO2017), and on more difficult distillation objectives, such as training data efficient transformers, whereby we attain a 77.2% top-1 accuracy with DeiT-Ti on ImageNet.
Internal Structure Attention Network for Fingerprint Presentation Attack Detection from Optical Coherence Tomography
Mar 20, 2023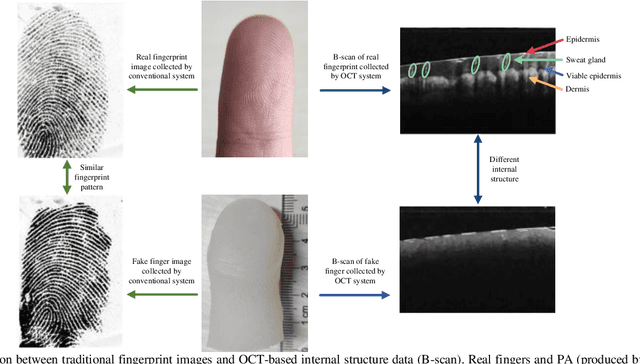
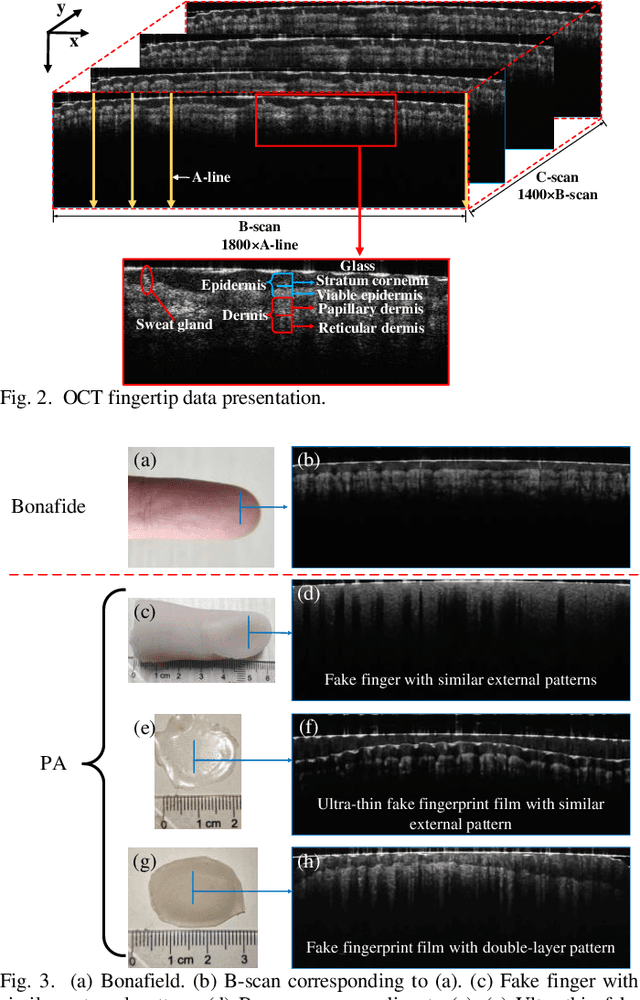
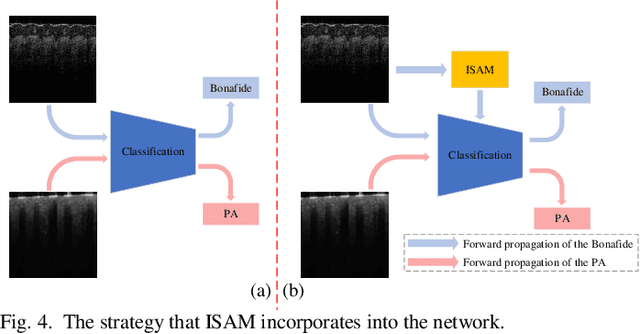
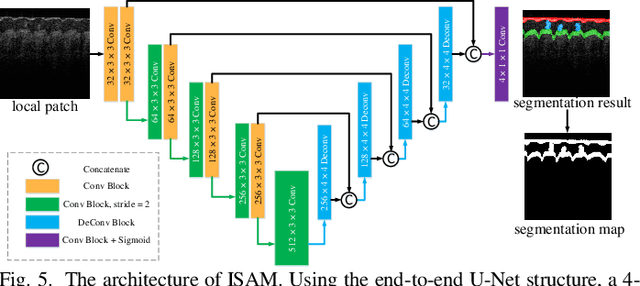
As a non-invasive optical imaging technique, optical coherence tomography (OCT) has proven promising for automatic fingerprint recognition system (AFRS) applications. Diverse approaches have been proposed for OCT-based fingerprint presentation attack detection (PAD). However, considering the complexity and variety of PA samples, it is extremely challenging to increase the generalization ability with the limited PA dataset. To solve the challenge, this paper presents a novel supervised learning-based PAD method, denoted as ISAPAD, which applies prior knowledge to guide network training and enhance the generalization ability. The proposed dual-branch architecture can not only learns global features from the OCT image, but also concentrate on layered structure feature which comes from the internal structure attention module (ISAM). The simple yet effective ISAM enables the proposed network to obtain layered segmentation features belonging only to Bonafide from noisy OCT volume data directly. Combined with effective training strategies and PAD score generation rules, ISAPAD obtains optimal PAD performance in limited training data. Domain generalization experiments and visualization analysis validate the effectiveness of the proposed method for OCT PAD.