 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Knowledge Distillation from Single to Multi Labels: an Empirical Study
Mar 15, 2023
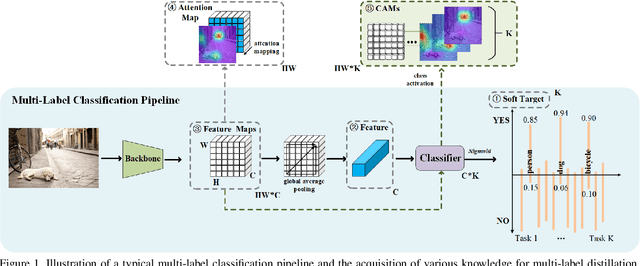
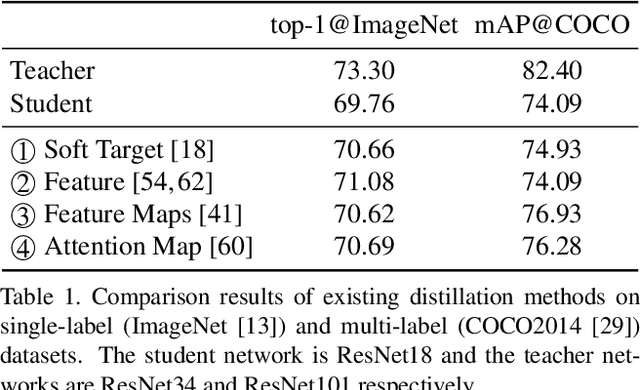
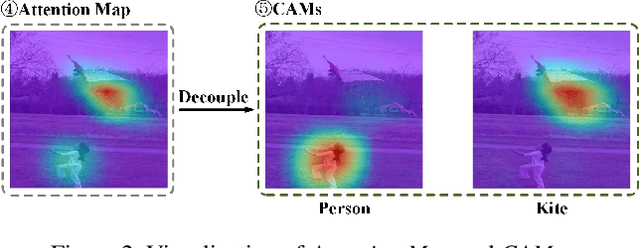
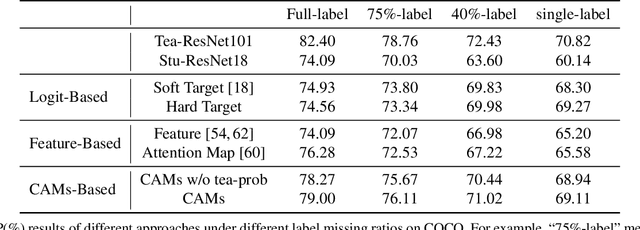
Knowledge distillation (KD) has been extensively studied in single-label image classification. However, its efficacy for multi-label classification remains relatively unexplored. In this study, we firstly investigate the effectiveness of classical KD techniques, including logit-based and feature-based methods, for multi-label classification. Our findings indicate that the logit-based method is not well-suited for multi-label classification, as the teacher fails to provide inter-category similarity information or regularization effect on student model's training. Moreover, we observe that feature-based methods struggle to convey compact information of multiple labels simultaneously. Given these limitations, we propose that a suitable dark knowledge should incorporate class-wise information and be highly correlated with the final classification results. To address these issues, we introduce a novel distillation method based on Class Activation Maps (CAMs), which is both effective and straightforward to implement. Across a wide range of settings, CAMs-based distillation consistently outperforms other methods.
GradMA: A Gradient-Memory-based Accelerated Federated Learning with Alleviated Catastrophic Forgetting
Mar 15, 2023
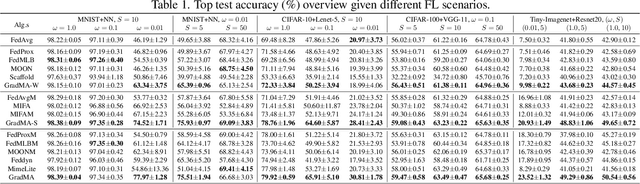
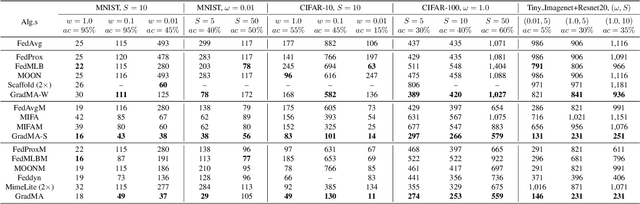
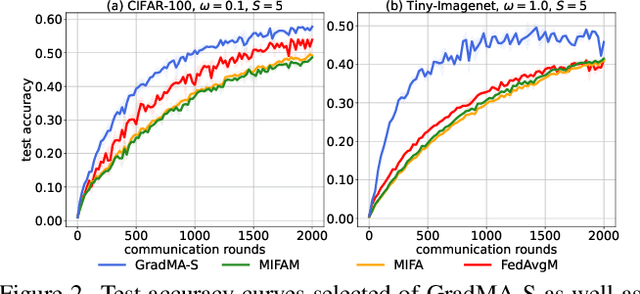
Federated Learning (FL) has emerged as a de facto machine learning area and received rapid increasing research interests from the community. However, catastrophic forgetting caused by data heterogeneity and partial participation poses distinctive challenges for FL, which are detrimental to the performance. To tackle the problems, we propose a new FL approach (namely GradMA), which takes inspiration from continual learning to simultaneously correct the server-side and worker-side update directions as well as take full advantage of server's rich computing and memory resources. Furthermore, we elaborate a memory reduction strategy to enable GradMA to accommodate FL with a large scale of workers. We then analyze convergence of GradMA theoretically under the smooth non-convex setting and show that its convergence rate achieves a linear speed up w.r.t the increasing number of sampled active workers. At last, our extensive experiments on various image classification tasks show that GradMA achieves significant performance gains in accuracy and communication efficiency compared to SOTA baselines.
Mining False Positive Examples for Text-Based Person Re-identification
Mar 15, 2023
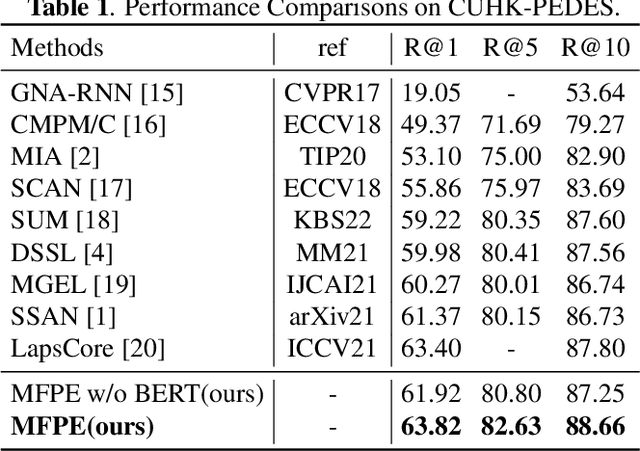
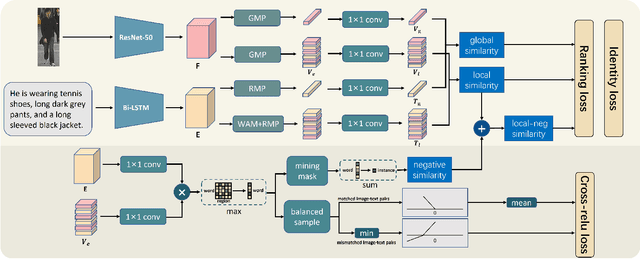
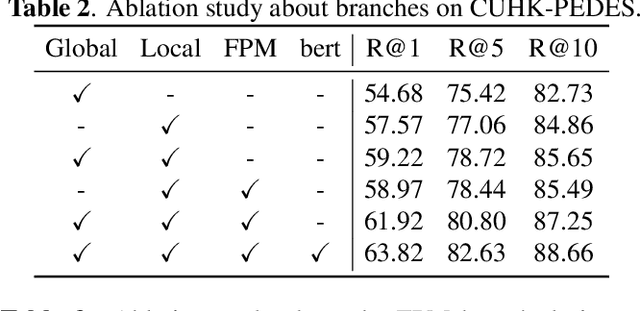
Text-based person re-identification (ReID) aims to identify images of the targeted person from a large-scale person image database according to a given textual description. However, due to significant inter-modal gaps, text-based person ReID remains a challenging problem. Most existing methods generally rely heavily on the similarity contributed by matched word-region pairs, while neglecting mismatched word-region pairs which may play a decisive role. Accordingly, we propose to mine false positive examples (MFPE) via a jointly optimized multi-branch architecture to handle this problem. MFPE contains three branches including a false positive mining (FPM) branch to highlight the role of mismatched word-region pairs. Besides, MFPE delicately designs a cross-relu loss to increase the gap of similarity scores between matched and mismatched word-region pairs. Extensive experiments on CUHK-PEDES demonstrate the superior effectiveness of MFPE. Our code is released at https://github.com/xx-adeline/MFPE.
Enhancing Unsupervised Audio Representation Learning via Adversarial Sample Generation
Mar 15, 2023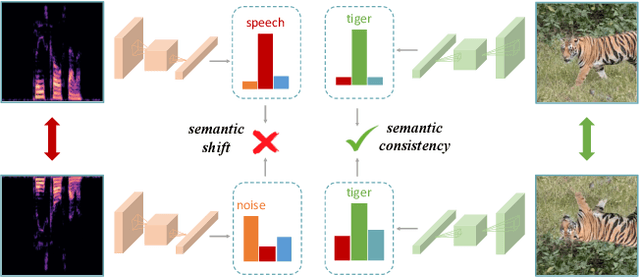
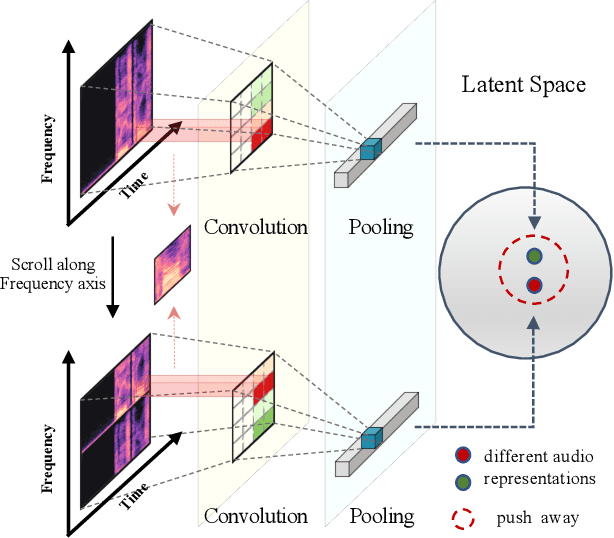
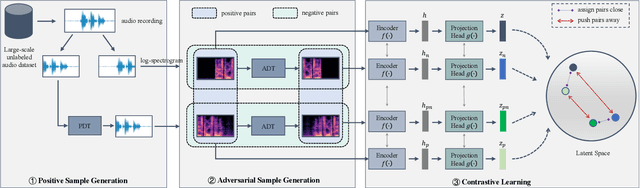
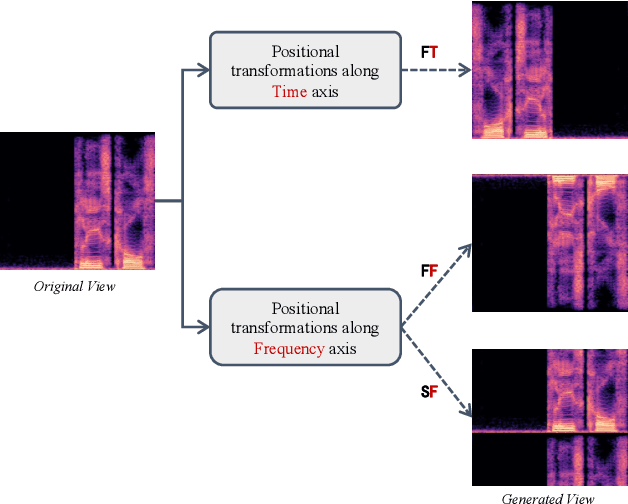
Existing audio analysis methods generally first transform the audio stream to spectrogram, and then feed it into CNN for further analysis. A standard CNN recognizes specific visual patterns over feature map, then pools for high-level representation, which overlooks the positional information of recognized patterns. However, unlike natural image, the semantic of an audio spectrogram is sensitive to positional change, as its vertical and horizontal axes indicate the frequency and temporal information of the audio, instead of naive rectangular coordinates. Thus, the insensitivity of CNN to positional change plays a negative role on audio spectrogram encoding. To address this issue, this paper proposes a new self-supervised learning mechanism, which enhances the audio representation by first generating adversarial samples (\textit{i.e.}, negative samples), then driving CNN to distinguish the embeddings of negative pairs in the latent space. Extensive experiments show that the proposed approach achieves best or competitive results on 9 downstream datasets compared with previous methods, which verifies its effectiveness on audio representation learning.
Economical Quaternion Extraction from a Human Skeletal Pose Estimate using 2-D Cameras
Mar 15, 2023
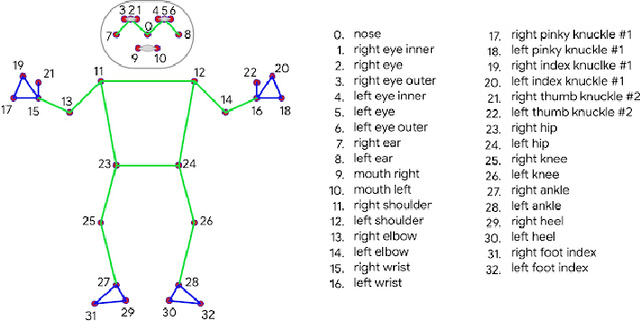
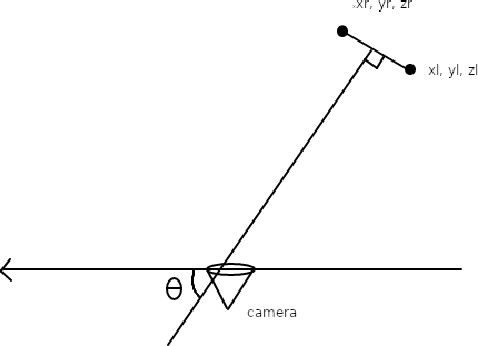
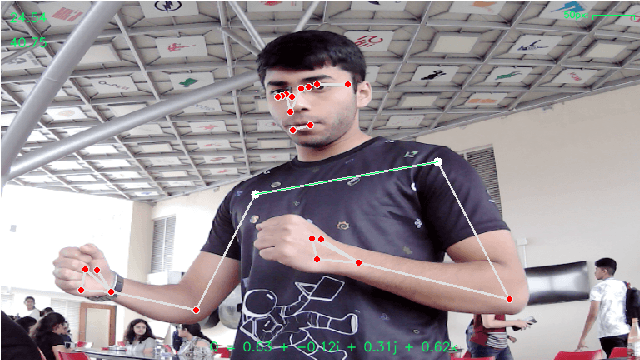
In this paper, we present a novel algorithm to extract a quaternion from a two dimensional camera frame for estimating a contained human skeletal pose. The problem of pose estimation is usually tackled through the usage of stereo cameras and intertial measurement units for obtaining depth and euclidean distance for measurement of points in 3D space. However, the usage of these devices comes with a high signal processing latency as well as a significant monetary cost. By making use of MediaPipe, a framework for building perception pipelines for human pose estimation, the proposed algorithm extracts a quaternion from a 2-D frame capturing an image of a human object at a sub-fifty millisecond latency while also being capable of deployment at edges with a single camera frame and a generally low computational resource availability, especially for use cases involving last-minute detection and reaction by autonomous robots. The algorithm seeks to bypass the funding barrier and improve accessibility for robotics researchers involved in designing control systems.
DiffusionSeg: Adapting Diffusion Towards Unsupervised Object Discovery
Mar 17, 2023
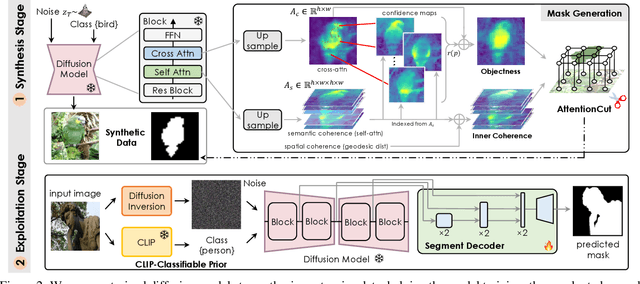

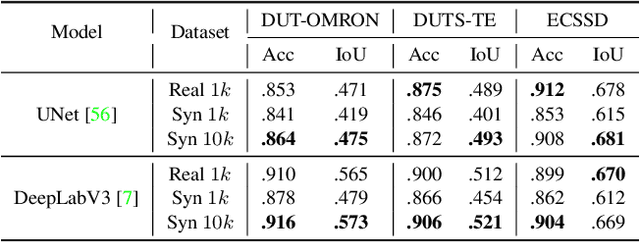
Learning from a large corpus of data, pre-trained models have achieved impressive progress nowadays. As popular generative pre-training, diffusion models capture both low-level visual knowledge and high-level semantic relations. In this paper, we propose to exploit such knowledgeable diffusion models for mainstream discriminative tasks, i.e., unsupervised object discovery: saliency segmentation and object localization. However, the challenges exist as there is one structural difference between generative and discriminative models, which limits the direct use. Besides, the lack of explicitly labeled data significantly limits performance in unsupervised settings. To tackle these issues, we introduce DiffusionSeg, one novel synthesis-exploitation framework containing two-stage strategies. To alleviate data insufficiency, we synthesize abundant images, and propose a novel training-free AttentionCut to obtain masks in the first synthesis stage. In the second exploitation stage, to bridge the structural gap, we use the inversion technique, to map the given image back to diffusion features. These features can be directly used by downstream architectures. Extensive experiments and ablation studies demonstrate the superiority of adapting diffusion for unsupervised object discovery.
CoDEPS: Online Continual Learning for Depth Estimation and Panoptic Segmentation
Mar 17, 2023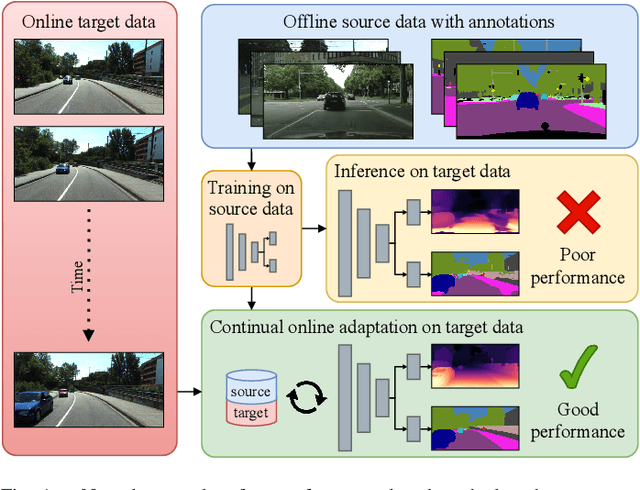
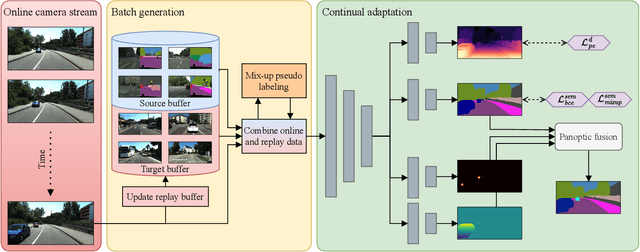
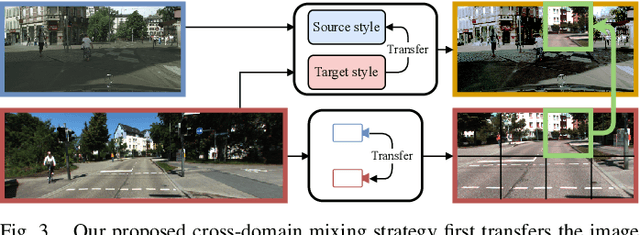
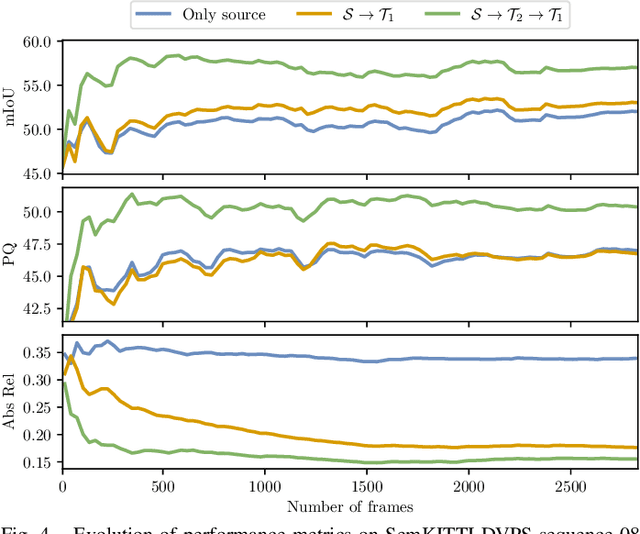
Operating a robot in the open world requires a high level of robustness with respect to previously unseen environments. Optimally, the robot is able to adapt by itself to new conditions without human supervision, e.g., automatically adjusting its perception system to changing lighting conditions. In this work, we address the task of continual learning for deep learning-based monocular depth estimation and panoptic segmentation in new environments in an online manner. We introduce CoDEPS to perform continual learning involving multiple real-world domains while mitigating catastrophic forgetting by leveraging experience replay. In particular, we propose a novel domain-mixing strategy to generate pseudo-labels to adapt panoptic segmentation. Furthermore, we explicitly address the limited storage capacity of robotic systems by proposing sampling strategies for constructing a fixed-size replay buffer based on rare semantic class sampling and image diversity. We perform extensive evaluations of CoDEPS on various real-world datasets demonstrating that it successfully adapts to unseen environments without sacrificing performance on previous domains while achieving state-of-the-art results. The code of our work is publicly available at http://codeps.cs.uni-freiburg.de.
GNNFormer: A Graph-based Framework for Cytopathology Report Generation
Mar 17, 2023
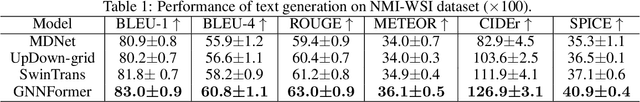
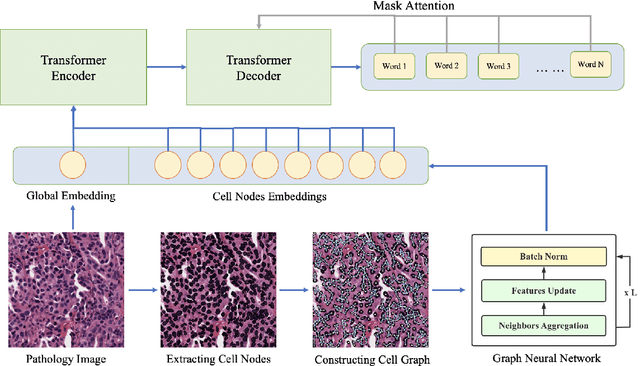
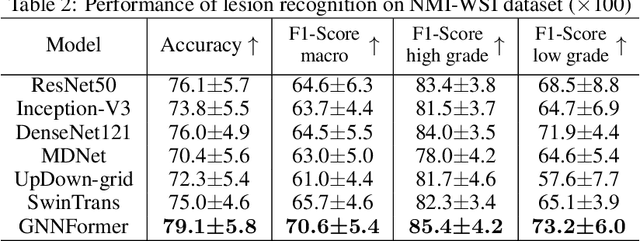
Cytopathology report generation is a necessary step for the standardized examination of pathology images. However, manually writing detailed reports brings heavy workloads for pathologists. To improve efficiency, some existing works have studied automatic generation of cytopathology reports, mainly by applying image caption generation frameworks with visual encoders originally proposed for natural images. A common weakness of these works is that they do not explicitly model the structural information among cells, which is a key feature of pathology images and provides significant information for making diagnoses. In this paper, we propose a novel graph-based framework called GNNFormer, which seamlessly integrates graph neural network (GNN) and Transformer into the same framework, for cytopathology report generation. To the best of our knowledge, GNNFormer is the first report generation method that explicitly models the structural information among cells in pathology images. It also effectively fuses structural information among cells, fine-grained morphology features of cells and background features to generate high-quality reports. Experimental results on the NMI-WSI dataset show that GNNFormer can outperform other state-of-the-art baselines.
CAPE: Camera View Position Embedding for Multi-View 3D Object Detection
Mar 17, 2023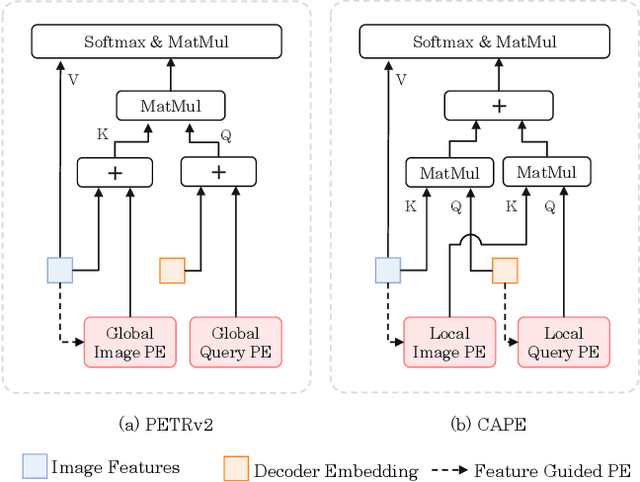
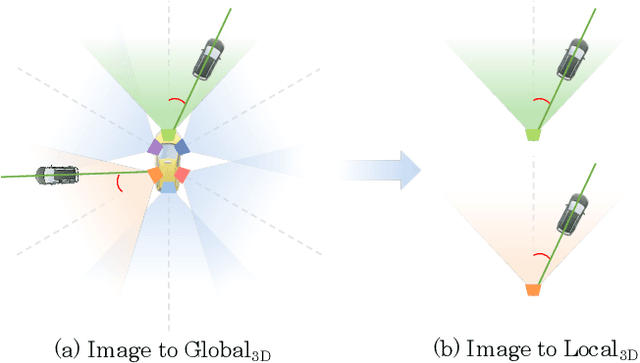
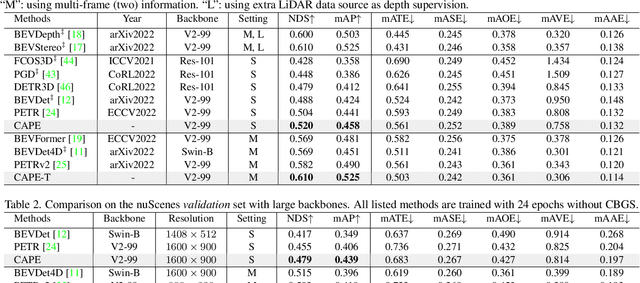
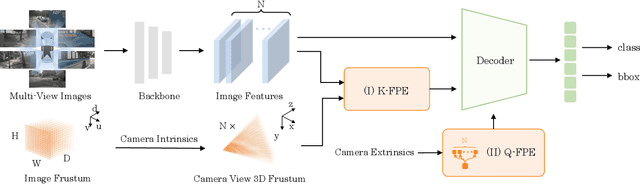
In this paper, we address the problem of detecting 3D objects from multi-view images. Current query-based methods rely on global 3D position embeddings (PE) to learn the geometric correspondence between images and 3D space. We claim that directly interacting 2D image features with global 3D PE could increase the difficulty of learning view transformation due to the variation of camera extrinsics. Thus we propose a novel method based on CAmera view Position Embedding, called CAPE. We form the 3D position embeddings under the local camera-view coordinate system instead of the global coordinate system, such that 3D position embedding is free of encoding camera extrinsic parameters. Furthermore, we extend our CAPE to temporal modeling by exploiting the object queries of previous frames and encoding the ego-motion for boosting 3D object detection. CAPE achieves state-of-the-art performance (61.0% NDS and 52.5% mAP) among all LiDAR-free methods on nuScenes dataset. Codes and models are available on \href{https://github.com/PaddlePaddle/Paddle3D}{Paddle3D} and \href{https://github.com/kaixinbear/CAPE}{PyTorch Implementation}.
Informing selection of performance metrics for medical image segmentation evaluation using configurable synthetic errors
Dec 30, 2022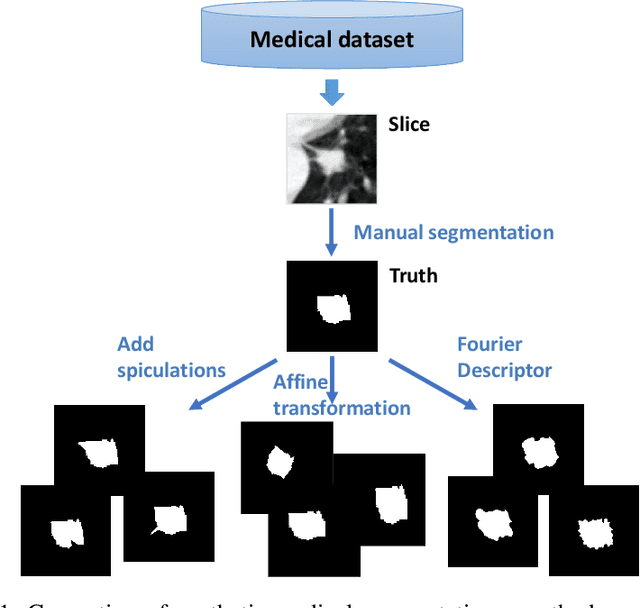
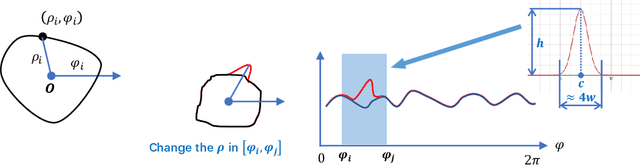
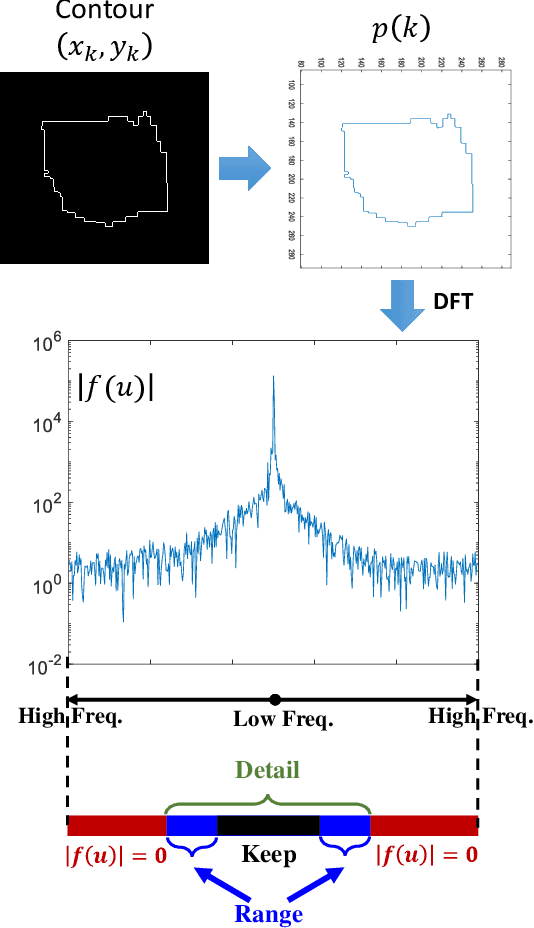
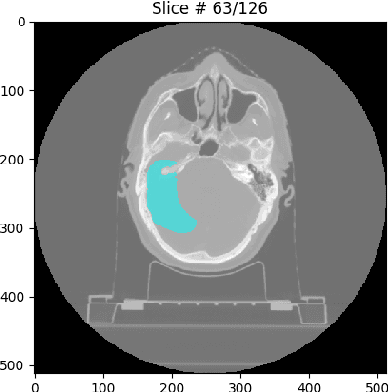
Machine learning-based segmentation in medical imaging is widely used in clinical applications from diagnostics to radiotherapy treatment planning. Segmented medical images with ground truth are useful for investigating the properties of different segmentation performance metrics to inform metric selection. Regular geometrical shapes are often used to synthesize segmentation errors and illustrate properties of performance metrics, but they lack the complexity of anatomical variations in real images. In this study, we present a tool to emulate segmentations by adjusting the reference (truth) masks of anatomical objects extracted from real medical images. Our tool is designed to modify the defined truth contours and emulate different types of segmentation errors with a set of user-configurable parameters. We defined the ground truth objects from 230 patient images in the Glioma Image Segmentation for Radiotherapy (GLIS-RT) database. For each object, we used our segmentation synthesis tool to synthesize 10 versions of segmentation (i.e., 10 simulated segmentors or algorithms), where each version has a pre-defined combination of segmentation errors. We then applied 20 performance metrics to evaluate all synthetic segmentations. We demonstrated the properties of these metrics, including their ability to capture specific types of segmentation errors. By analyzing the intrinsic properties of these metrics and categorizing the segmentation errors, we are working toward the goal of developing a decision-tree tool for assisting in the selection of segmentation performance metrics.